Praktik terbaik konfigurasi HADR (SQL Server di Azure VM)
Berlaku untuk:![]() SQL Server di Azure VM
SQL Server di Azure VM
Kluster Failover Server Windows digunakan untuk ketersediaan tinggi dan pemulihan bencana (HADR) dengan SQL Server di Azure Virtual Machines (VM).
Artikel ini menyediakan praktik terbaik konfigurasi kluster untuk instans kluster failover (FCI) dan grup ketersediaan saat Anda menggunakannya dengan SQL Server di Microsoft Azure Virtual Machine.
Untuk mempelajari selengkapnya, lihat artikel lain dalam seri ini: Daftar periksa, Ukuran komputer virtual, Penyimpanan, Keamanan, Konfigurasi HADR, Mengumpulkan garis besar.
Daftar periksa
Tinjau daftar periksa berikut untuk mengetahui ringkasan singkat mengenai praktik terbaik HADR yang dibahas oleh artikel lainnya secara lebih detail.
Fitur ketersediaan tinggi dan pemulihan bencana (HADR), seperti grup ketersediaan Always On dan instans klaster failover, bergantung pada teknologi Klaster Failover Windows Server yang mendasarinya. Tinjau praktik terbaik untuk memodifikasi pengaturan HADR Anda guna mendukung lingkungan cloud dengan lebih baik.
Untuk klaster Windows Anda, pertimbangkan praktik terbaik ini:
- Sebarkan VM SQL Server Anda ke beberapa subnet bila memungkinkan untuk menghindari ketergantungan pada Azure Load Balancer atau nama jaringan terdistribusi (DNN) untuk merutekan lalu lintas ke solusi HADR Anda.
- Ubah klaster menjadi parameter yang lebih tidak agresif untuk menghindari pemadaman tidak terduga akibat kegagalan jaringan sementara atau pemeliharaan platform Azure. Untuk mempelajari lebih lanjut, lihat pengaturan heartbeat dan ambang. Untuk Windows Server 2012 dan yang lebih baru, gunakan nilai yang direkomendasikan berikut ini:
- SameSubnetDelay: 1 detik
- SameSubnetThreshold: 40 heartbeat
- CrossSubnetDelay: 1 detik
- CrossSubnetThreshold: 40 heartbeat
- Tempatkan komputer virtual Anda dalam set ketersediaan atau zona ketersediaan yang berbeda. Untuk mempelajari selengkapnya, lihat Pengaturan ketersediaan komputer virtual.
- Gunakan satu NIC per node kluster.
- Konfigurasikan klaster pemungutan suara kuorum untuk menggunakan 3 atau lebih jumlah suara ganjil. Jangan tetapkan suara ke wilayah DR.
- Pantau batas sumber daya dengan hati-hati untuk menghindari penghidupan ulang atau failover yang tidak terduga karena kendala sumber daya.
- Pastikan OS, driver, dan SQL Server Anda menggunakan build terbaru.
- Optimalkan performa untuk SQL Server di komputer virtual Azure. Tinjau bagian lain dalam artikel ini untuk mempelajari lebih lanjut.
- Mengurangi atau menyebarkan beban kerja untuk menghindari batas sumber daya.
- Pindah ke komputer virtual atau disk yang memiliki batas lebih tinggi untuk menghindari kendala.
Untuk grup ketersediaan SQL Server atau instans klaster failover Anda, pertimbangkan praktik terbaik ini:
- Jika Anda sering mengalami kegagalan yang tidak terduga, ikuti praktik terbaik performa yang diuraikan dalam sisa artikel ini.
- Jika mengoptimalkan performa komputer virtual SQL Server tidak menyelesaikan failover yang tidak terduga, pertimbangkan untuk melonggarkan pemantauan untuk grup ketersediaan atau instans kluster failover. Namun, hal itu mungkin tidak dapat mengatasi sumber utama masalah tersebut dan dapat menyembunyikan gejala dengan mengurangi kemungkinan kegagalan. Anda mungkin masih perlu menyelidiki dan mengatasi akar penyebab masalah tersebut. Untuk Windows Server 2012 atau yang lebih tinggi, gunakan nilai yang direkomendasikan berikut ini:
- Batas waktu sewa: Gunakan persamaan ini untuk menghitung nilai batas waktu sewa maksimum:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Dimulai dengan 40 detik. Jika Anda menggunakan nilai yang dilonggarkanSameSubnetThresholddanSameSubnetDelaydirekomendasikan sebelumnya, jangan melebihi 80 detik untuk nilai batas waktu sewa. - Kegagalan maksimal dalam periode tertentu: Tetapkan angka 6 untuk nilai ini.
- Batas waktu sewa: Gunakan persamaan ini untuk menghitung nilai batas waktu sewa maksimum:
- Saat menggunakan nama jaringan virtual (VNN) dan Azure Load Balancer untuk menyambungkan ke solusi HADR Anda, tentukan
MultiSubnetFailover = truedalam string koneksi, meskipun kluster Anda hanya mencakup satu subnet.- Jika klien tidak mendukung
MultiSubnetFailover = True, Anda mungkin perlu mengaturRegisterAllProvidersIP = 0danHostRecordTTL = 300menyimpan kredensial klien untuk durasi yang lebih singkat. Namun, hal itu dapat menyebabkan kueri tambahan ke server DNS.
- Jika klien tidak mendukung
- Untuk menyambungkan ke solusi HADR Anda menggunakan nama jaringan terdistribusi (DNN), pertimbangkan hal berikut:
- Anda harus menggunakan driver klien yang mendukung
MultiSubnetFailover = Truedan parameter ini harus berada dalam string koneksi. - Gunakan port DNN unik dalam string koneksi saat menghubungkan ke pendengar DNN untuk grup ketersediaan.
- Anda harus menggunakan driver klien yang mendukung
- Gunakan string koneksi pencerminan database untuk grup ketersediaan dasar guna menghindari kebutuhan penyeimbang muatan (load balancer) atau DNN.
- Validasikan ukuran sektor VHD Anda sebelum menerapkan solusi ketersediaan tinggi untuk menghindari I/O yang tidak selaras. Lihat KB3009974 untuk mempelajari lebih lanjut.
- Jika mesin database SQL Server, pendengar grup ketersediaan Always On, atau probe kesehatan instans kluster failover dikonfigurasi untuk menggunakan port antara 49.152 dan 65.536 (rentang port dinamis default untuk TCP/IP), tambahkan pengecualian untuk setiap port. Melakukannya mencegah sistem lain ditetapkan secara dinamis ke port yang sama. Contoh berikut membuat pengecualian untuk port 59999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Untuk membandingkan daftar periksa HADR dengan praktik terbaik lainnya, lihat daftar periksa praktik terbaik Performa yang komprehensif.
Pengaturan ketersediaan VM
Untuk mengurangi efek waktu henti, pertimbangkan pengaturan ketersediaan terbaik VM berikut:
- Gunakan grup penempatan kedekatan bersama dengan jaringan yang dipercepat untuk latensi terendah.
- Tempatkan simpul kluster komputer virtual di zona ketersediaan terpisah untuk melindungi dari kegagalan tingkat pusat data atau dalam satu set ketersediaan untuk redundansi latensi lebih rendah dalam pusat data yang sama.
- Gunakan OS dan disk data yang dikelola premium untuk VM dalam set ketersediaan.
- Konfigurasikan setiap tingkat aplikasi ke dalam set ketersediaan terpisah.
Kuorum
Meskipun kluster dua node berfungsi tanpa sumber daya kuorum, pelanggan benar-benar diharuskan menggunakan sumber daya kuorum untuk memiliki dukungan produksi. Validasi kluster tidak melewati kluster apa pun tanpa sumber daya kuorum.
Secara teknis, kluster tiga node dapat bertahan dari kehilangan node tunggal (turun ke dua node) tanpa sumber daya kuorum, tetapi setelah kluster turun ke dua node, jika ada kehilangan node lain atau kegagalan komunikasi, maka ada risiko bahwa sumber daya terkluster akan offline untuk mencegah skenario split-brain. Mengonfigurasi sumber daya kuorum memungkinkan kluster untuk terus online hanya dengan satu simpul online.
Bukti disk adalah opsi kuorum yang paling tangguh, tetapi untuk menggunakan bukti disk pada SQL Server di Azure VM, Anda harus menggunakan Disk Bersama Azure, yang memberlakukan beberapa batasan pada solusi ketersediaan tinggi. Dengan demikian, gunakan bukti disk saat Anda mengonfigurasi instans kluster failover dengan Azure Shared Disks, jika tidak, gunakan bukti cloud jika memungkinkan.
Tabel berikut ini mencantumkan opsi kuorum yang tersedia untuk Microsoft SQL Server di Azure VMs:
| Bukti cloud | Bukti disk | Bukti file bersama | |
|---|---|---|---|
| OS yang didukung | Windows Server 2016+ | Semua | Semua |
- Bukti cloud sangat ideal untuk penyebaran di beberapa situs, beberapa zona, dan beberapa wilayah. Gunakan bukti cloud jika memungkinkan, kecuali jika Anda menggunakan solusi kluster penyimpanan bersama.
- Bukti disk adalah opsi kuorum yang paling tangguh dan banyak dipilih untuk setiap kluster yang menggunakan Disk Bersama Azure (atau solusi disk bersama seperti SCSI, iSCSI, atau fiber SAN yang digunakan bersama). Volume Bersama Terkluster tidak dapat digunakan sebagai bukti disk.
- Bukti fileshare dapat digunakan jika opsi bukti disk dan bukti cloud tidak tersedia.
Untuk memulai, lihat Konfigurasikan kuorum kluster.
Pemungutan Suara Kuorum
Dimungkinkan untuk mengubah suara kuorum dari node yang berpartisipasi dalam Kluster Failover Windows Server.
Saat memodifikasi pengaturan pemungutan suara node, ikuti panduan berikut:
| Panduan pemungutan suara kuorum |
|---|
| Mulailah dengan setiap node tidak memiliki suara secara default. Setiap node hanya boleh memiliki suara dengan pembenaran eksplisit. |
| Aktifkan suara untuk node kluster yang menghosting replika utama grup ketersediaan, atau pemilik pilihan instans kluster failover. |
| Aktifkan pemungutan suara untuk pemilik failover otomatis. Setiap node yang dapat menghosting replika utama atau FCI sebagai akibat dari failover otomatis harus memiliki suara. |
| Jika grup ketersediaan memiliki lebih dari satu replika sekunder, hanya aktifkan suara untuk replika yang memiliki failover otomatis. |
| Nonaktifkan suara untuk node yang berada di situs pemulihan bencana sekunder. Simpul di situs sekunder tidak boleh berkontribusi pada keputusan mengambil kluster secara offline jika tidak ada yang salah dengan situs utama. |
| Miliki jumlah suara ganjil, dengan minimal tiga suara kuorum. Tambahkan bukti kuorum untuk pemungutan suara tambahan jika perlu dalam kluster dua simpul. |
| Menilai kembali penugasan suara pasca-kegagalan. Anda tidak ingin gagal dalam konfigurasi kluster yang tidak mendukung kuorum yang sehat. |
Konektivitas
Untuk mencocokkan pengalaman lokal untuk menyambungkan ke listener grup ketersediaan atau instans kluster failover, gunakan VM SQL Server Anda ke beberapa subnet dalam jaringan virtual yang sama. Memiliki beberapa subnet meniadakan kebutuhan akan ketergantungan ekstra pada Azure Load Balancer, atau nama jaringan terdistribusi untuk mengarahkan lalu lintas Anda ke listener Anda.
Untuk menyederhanakan solusi HADR Anda, sebarkan VM SQL Server Anda ke beberapa subnet bila memungkinkan. Untuk mempelajari selengkapnya, lihat Multi-subnet AG,dan Multi-subnet FCI.
Jika VM SQL Server Anda berada dalam satu subnet, Anda dapat mengonfigurasi nama jaringan virtual (VNN) dan Azure Load Balancer, atau nama jaringan terdistribusi (DNN) untuk instans kluster failover dan listener grup ketersediaan.
Nama jaringan terdistribusi adalah opsi konektivitas yang direkomendasikan, jika tersedia:
- Solusi menyeluruh lebih andal karena Anda tidak lagi harus mempertahankan sumber daya penyeimbang muatan.
- Menghilangkan pemeriksaan penyeimbang muatan meminimalkan durasi kegagalan.
- DNN menyederhanakan provisi dan pengelolaan instans kluster failover atau listener grup ketersediaan dengan SQL Server di komputer virtual Azure.
Pertimbangkan batasan berikut:
- Driver klien harus mendukung parameter
MultiSubnetFailover=True. - Fitur DNN tersedia mulai dari SQL Server 2016 SP3, SQL Server 2017 CU25, dan SQL Server 2019 CU8 di Windows Server 2016 dan yang lebih baru.
Untuk mempelajari selengkapnya, lihat Gambaran umum Kluster Failover Server Windows.
Untuk mengonfigurasi konektivitas, lihat artikel berikut:
- Grup ketersediaan: Mengonfigurasi DNN, Mengonfigurasi VNN
- Instans kluster failover: Mengonfigurasi DNN, Mengonfigurasi VNN.
Sebagian besar fitur SQL Server bekerja secara transparan dengan FCI dan grup ketersediaan saat menggunakan DNN, tetapi ada fitur tertentu yang mungkin memerlukan pertimbangan khusus. Lihat Interoperabilitas FCI dan DNN dan Interoperabilitas AG dan DNN untuk mempelajari lebih lanjut.
Tip
Setel parameter MultiSubnetFailover = true dalam string koneksi bahkan untuk solusi HADR yang menjangkau satu subnet untuk mendukung rentang subnet di masa mendatang tanpa perlu memperbarui string koneksi.
Heartbeat dan ambang
Ubah heartbeat kluster dan pengaturan ambang ke pengaturan yang dilonggarkan. Pengaturan heartbeat dan kluster ambang default dirancang untuk jaringan lokal yang sangat disetel dan tidak mempertimbangkan kemungkinan peningkatan latensi di lingkungan cloud. Jaringan heartbeat dipertahankan dengan UDP 3343, yang secara tradisional lebih dapat diandalkan daripada TCP dan lebih rentan terhadap percakapan yang tidak lengkap.
Oleh karena itu, ketika menjalankan simpul kluster untuk SQL Server pada solusi ketersediaan tinggi Azure VM, ubah pengaturan kluster ke status pemantauan yang lebih longgar untuk menghindari kegagalan sementara karena kemungkinan peningkatan latensi atau kegagalan jaringan, pemeliharaan Azure, atau kemacetan sumber daya.
Pengaturan penundaan dan ambang memiliki efek kumulatif terhadap deteksi kesehatan total. Misalnya, pengaturan CrossSubnetDelay untuk mengirim heartbeat setiap 2 detik dan pengaturan CrossSubnetThreshold untuk 10 heartbeat yang terlewat sebelum melakukan pemulihan, berarti kluster dapat memiliki toleransi jaringan total 20 detik sebelum tindakan pemulihan diambil. Secara umum, terus mengirimkan heartbeat dengan intensitas sering tetapi memiliki ambang yang lebih besar lebih disukai.
Untuk memastikan pemulihan selama penghentian yang sah sambil memberikan toleransi yang lebih besar untuk masalah sementara, longgarkan penundaan dan pengaturan ambang Anda ke nilai yang direkomendasikan, yang dirinci dalam tabel berikut:
| Pengaturan | Windows Server 2012 atau yang lebih baru | Windows Server 2008 R2 |
|---|---|---|
| SameSubnetDelay | 1 detik | 2 detik |
| SameSubnetThreshold | 40 heartbeat | 10 heartbeat (maks) |
| CrossSubnetDelay | 1 detik | 2 detik |
| CrossSubnetThreshold | 40 heartbeat | 20 heartbeat (maks) |
Gunakan PowerShell untuk mengubah parameter kluster Anda:
(get-cluster).SameSubnetThreshold = 40
(get-cluster).CrossSubnetThreshold = 40
Gunakan PowerShell untuk memverifikasi perubahan Anda:
get-cluster | fl *subnet*
Pertimbangkan hal berikut:
- Perubahan ini segera dilakukan, memulai ulang kluster atau sumber daya apa pun tidak diperlukan.
- Nilai subnet yang sama tidak boleh lebih besar dari nilai lintas subnet.
- SameSubnetThreshold <= CrossSubnetThreshold
- SameSubnetDelay <= CrossSubnetDelay
Pilih nilai yang dilonggarkan berdasarkan seberapa banyak waktu henti yang dapat ditoleransi dan durasi sebelum tindakan korektif harus dilakukan, tergantung pada aplikasi Anda, kebutuhan bisnis, dan lingkungan Anda. Jika Anda tidak dapat melebihi nilai default Windows Server 2019, setidaknya cobalah untuk mencocokkannya, jika memungkinkan:
Sebagai referensi, tabel berikut memberikan perincian nilai default:
| Pengaturan | Windows Server 2019 | Server Windows 2016 | Windows Server 2008 - 2012 R2 |
|---|---|---|---|
| SameSubnetDelay | 1 detik | 1 detik | 1 detik |
| SameSubnetThreshold | 20 heartbeat | 10 heartbeat | 5 heartbeat |
| CrossSubnetDelay | 1 detik | 1 detik | 1 detik |
| CrossSubnetThreshold | 20 heartbeat | 10 heartbeat | 5 heartbeat |
Untuk mempelajari selengkapnya, lihat Menyesuaikan Ambang Jaringan Kluster Failover.
Pemantauan yang dilonggarkan
Jika menyetel pengaturan heartbeat dan ambang kluster seperti yang direkomendasikan tidak cukup toleransi dan Anda masih melihat failover karena masalah sementara daripada pemadaman sejati, Anda dapat mengonfigurasi pemantauan AG atau FCI Anda agar lebih santai. Dalam beberapa skenario, melonggarkan pemantauan untuk sementara waktu berdasarkan tingkat aktivitas mungkin akan berguna. Misalnya, Anda mungkin ingin melonggarkan pemantauan saat melakukan beban kerja intensif IO seperti pencadangan database, pemeliharaan indeks, DBCC CHECKDB, dll. Setelah aktivitas selesai, atur pemantauan Anda ke nilai yang kurang longgar.
Peringatan
Mengubah pengaturan tersebut dapat menutupi masalah mendasar, dan akan digunakan sebagai solusi sementara untuk mengurangi, bukan menghilangkan, kemungkinan kegagalan. Masalah mendasar masih harus diselidiki dan ditangani.
Mulailah dengan meningkatkan parameter berikut dari nilai defaultnya untuk pemantauan yang dilonggarkan, dan sesuaikan seperlunya:
| Parameter | Nilai default | Nilai yang Dilonggarkan | Deskripsi |
|---|---|---|---|
| Batas waktu pemeriksaan kesehatan | 30000 | 60000 | Menentukan kesehatan simpul atau replika utama. DLL sp_server_diagnostics sumber daya kluster mengembalikan hasil pada interval yang sama dengan 1/3 dari ambang batas waktu pemeriksaan kesehatan. Jika sp_server_diagnostics lambat atau tidak mengembalikan informasi, DLL sumber daya menunggu interval penuh ambang batas waktu pemeriksaan kesehatan sebelum menentukan bahwa sumber daya tidak responsif, dan memulai failover otomatis, jika dikonfigurasi untuk melakukannya. |
| Tingkat Kondisi Kegagalan | 3 | 2 | Kondisi yang memicu failover otomatis. Ada lima tingkat kondisi kegagalan, yang berkisar dari yang paling longgar (tingkat satu) hingga yang paling ketat (tingkat lima) |
Gunakan Transact-SQL (T-SQL) untuk mengubah pemeriksaan kesehatan dan kondisi kegagalan untuk AG dan FCI.
Untuk grup ketersediaan:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);
Untuk instans kluster failover:
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY HealthCheckTimeout = 60000;
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY FailureConditionLevel = 2;
Khusus untuk grup ketersediaan, mulailah dengan parameter yang direkomendasikan berikut, dan sesuaikan seperlunya:
| Parameter | Nilai default | Nilai yang Dilonggarkan | Deskripsi |
|---|---|---|---|
| Batas waktu sewa | 20000 | 40000 | Mencegah split-brain. |
| Batas waktu sesi | 10000 | 20000 | Memeriksa masalah komunikasi antar-replika. Periode batas waktu sesi adalah properti replika yang mengontrol durasi (dalam detik) replika ketersediaan menunggu respons ping dari replika yang tersambung sebelum menganggap koneksi telah gagal. Secara default, replika menunggu respons ping selama 10 detik. Properti replika ini hanya berlaku untuk koneksi antara replika sekunder tertentu dan replika utama grup ketersediaan. |
| Maksimal kegagalan dalam periode tertentu | 2 | 6 | Digunakan untuk menghindari pergerakan yang tidak terbatas dari sumber daya berkluster dalam beberapa kegagalan simpul. Nilai yang terlalu rendah dapat menyebabkan grup ketersediaan berada dalam status gagal. Tingkatkan nilai untuk mencegah gangguan singkat dari masalah performa karena nilai yang terlalu rendah dapat menyebabkan AG berada dalam status gagal. |
Sebelum membuat perubahan, pertimbangkan hal-hal berikut:
- Jangan menurunkan nilai batas waktu di bawah nilai defaultnya.
- Gunakan persamaan ini untuk menghitung nilai batas waktu sewa maksimum:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Dimulai dengan 40 detik. Jika Anda menggunakan nilai yang dilonggarkanSameSubnetThresholddanSameSubnetDelaydirekomendasikan sebelumnya, jangan melebihi 80 detik untuk nilai batas waktu sewa. - Untuk replika synchronous-commit, mengubah batas waktu sesi ke nilai tinggi dapat meningkatkan waktu tunggu HADR_sync_commit.
Batas waktu sewa
Gunakan Pengelola kluster Failover untuk mengubah pengaturan batas waktu sewa untuk grup ketersediaan Anda. Lihat dokumentasi SQL Server pemeriksaan kesehatan sewa grup ketersediaan untuk langkah-langkah mendetail.
Batas waktu sesi
Gunakan Transact-SQL (T-SQL) untuk mengubah batas waktu sesi untuk grup ketersediaan:
ALTER AVAILABILITY GROUP AG1
MODIFY REPLICA ON 'INSTANCE01' WITH (SESSION_TIMEOUT = 20);
Maksimal kegagalan dalam periode tertentu
Gunakan Pengelola Kluster Failover untuk mengubah nilai Kegagalan maksimal dalam periode tertentu:
- Pilih Peran di panel navigasi.
- Di Peran, klik kanan sumber daya berkluster dan pilih Properti.
- Pilih tab Failover, dan tingkatkan nilai Kegagalan maksimum dalam periode tertentu sesuai keinginan.
Batas Sumber Daya
Batas VM atau disk dapat mengakibatkan hambatan sumber daya yang berdampak pada kesehatan kluster, dan menghambat pemeriksaan kesehatan. Jika Anda mengalami masalah dengan batas sumber daya, pertimbangkan hal berikut:
- Pastikan OS, driver, dan SQL Server Anda menggunakan build terbaru.
- Optimalkan SQL Server di lingkungan Azure VM seperti yang dijelaskan dalam panduan performa untuk SQL Server di Azure Virtual Machines
- Mengurangi atau menyebarkan beban kerja guna mengurangi penggunaan tanpa melebihi batas sumber daya
- Menyetel beban kerja SQL Server jika ada peluang, seperti
- Menambahkan/mengoptimalkan indeks
- Memperbarui statistik jika diperlukan dan jika memungkinkan, dengan pemindaian penuh
- Gunakan fitur seperti pengatur sumber daya (dimulai dengan SQL Server 2014, khusus perusahaan) untuk membatasi penggunaan sumber daya selama beban kerja tertentu, seperti pencadangan atau pemeliharaan indeks.
- Pindahkan ke VM atau disk yang memiliki batas lebih tinggi untuk memenuhi atau melampaui tuntutan beban kerja Anda.
Jaringan
Sebarkan VM SQL Server Anda ke beberapa subnet bila memungkinkan untuk menghindari ketergantungan pada Azure Load Balancer atau nama jaringan terdistribusi (DNN) untuk merutekan lalu lintas ke solusi HADR Anda.
Gunakan satu NIC per server (node kluster). Jaringan Azure memiliki redundansi fisik, yang membuat NIC tambahan tidak diperlukan pada kluster tamu mesin virtual Azure. Laporan validasi kluster memperingatkan Anda bahwa simpul hanya dapat dijangkau pada satu jaringan. Anda dapat mengabaikan peringatan ini pada kluster failover tamu komputer virtual Azure.
Batas bandwidth untuk VM tertentu dibagikan di seluruh NIC dan menambahkan NIC tambahan tidak meningkatkan performa grup ketersediaan untuk SQL Server di Azure VM. Dengan demikian, tidak perlu menambahkan NIC kedua.
Layanan DHCP yang tidak mematuhi RFC di Azure dapat menyebabkan pembuatan konfigurasi kluster failover tertentu gagal. Kegagalan ini terjadi karena nama jaringan kluster diberi alamat IP duplikat, seperti alamat IP yang sama dengan salah satu node kluster. Ini adalah masalah ketika Anda menggunakan grup ketersediaan, yang bergantung pada fitur kluster failover Windows.
Pertimbangkan skenario ketika kluster dua node dibuat dan aktif secara online:
- Kluster online, dan kemudian NODE1 meminta alamat IP yang ditetapkan secara dinamis untuk nama jaringan kluster.
- Layanan DHCP tidak memberikan alamat IP apa pun selain alamat IP NODE1 sendiri, karena layanan DHCP mengakui bahwa permintaan tersebut berasal dari NODE1 itu sendiri.
- Windows mendeteksi bahwa alamat duplikat ditetapkan baik ke NODE1 maupun ke nama jaringan kluster failover, dan grup kluster default pun gagal online.
- Grup kluster default berpindah ke NODE2. NODE2 menganggap alamat IP NODE1 sebagai alamat IP kluster dan membuat grup kluster default online.
- Ketika NODE2 mencoba untuk membangun konektivitas dengan NODE1, paket yang diarahkan ke NODE1 tidak pernah meninggalkan NODE2 karena menggunakan alamat IP NODE1 untuk dirinya sendiri. NODE2 tidak dapat membangun konektivitas dengan NODE1, dan kemudian kehilangan kuorum dan mematikan kluster.
- NODE1 dapat mengirim paket ke NODE2, tetapi NODE2 tidak dapat membalas. NODE1 kehilangan kuorum dan mematikan kluster.
Anda dapat menghindari skenario ini dengan menetapkan alamat IP statis yang tidak digunakan ke nama jaringan kluster agar nama jaringan kluster online dan menambahkan alamat IP ke Azure Load Balancer.
Jika mesin database SQL Server, pendengar grup ketersediaan AlwaysOn, pemeriksaan kesehatan instans kluster failover, titik akhir pencerminan database, sumber daya IP inti kluster, atau sumber daya SQL lainnya dikonfigurasi untuk menggunakan port antara 49.152 dan 65.536 ( rentang port dinamis default untuk TCP/IP), tambahkan pengecualian untuk setiap port. Melakukannya mencegah proses sistem lain ditetapkan secara dinamis pada port yang sama. Contoh berikut membuat pengecualian untuk port 59999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Penting untuk mengonfigurasi pengecualian port ketika port tidak digunakan, jika tidak, perintah gagal dengan pesan seperti "Proses tidak dapat mengakses file karena sedang digunakan oleh proses lain."
Untuk mengonfirmasi bahwa pengecualian telah dikonfigurasi dengan benar, gunakan perintah berikut: netsh int ipv4 show excludedportrange tcp.
Mengatur pengecualian ini untuk port pemeriksaan IP peran grup ketersediaan harus mencegah peristiwa seperti ID Peristiwa: 1069 dengan status 10048. Kejadian ini dapat dilihat dalam peristiwa kluster Failover Windows dengan pesan berikut:
Cluster resource '<IP name in AG role>' of type 'IP Address' in cluster role '<AG Name>' failed.
An Event ID: 1069 with status 10048 can be identified from cluster logs with events like:
Resource IP Address 10.0.1.0 called SetResourceStatusEx: checkpoint 5. Old state OnlinePending, new state OnlinePending, AppSpErrorCode 0, Flags 0, nores=false
IP Address <IP Address 10.0.1.0>: IpaOnlineThread: **Listening on probe port 59999** failed with status **10048**
Status [**10048**](/windows/win32/winsock/windows-sockets-error-codes-2) refers to: **This error occurs** if an application attempts to bind a socket to an **IP address/port that has already been used** for an existing socket.
Ini dapat disebabkan oleh proses internal yang mengambil port yang sama yang didefinisikan sebagai port probe. Ingat bahwa port pemeriksaan digunakan untuk memeriksa status instans kumpulan backend dari Azure Load Balancer.
Jika pemeriksaan kesehatan gagal mendapatkan respons dari instans backend, maka tidak ada koneksi baru yang akan dikirim ke instans backend tersebut hingga pemeriksaan kesehatan berhasil lagi.
Masalah yang diketahui
Tinjau resolusi untuk beberapa masalah dan kesalahan yang umum diketahui.
Ketidakcocokan sumber daya (IO khususnya) menyebabkan failover
Kapasitas I/O atau CPU yang melelahkan untuk VM dapat menyebabkan grup ketersediaan Anda gagal. Mengidentifikasi ketidakcocokan yang terjadi tepat sebelum failover adalah cara yang paling dapat diandalkan untuk mengidentifikasi apa yang menyebabkan failover otomatis. Pantau Azure Virtual Machines untuk melihat metrik Pemanfaatan IO Penyimpanan untuk memahami latensi tingkat VM atau disk.
Ikuti langkah-langkah ini untuk meninjau peristiwa Kelelahan IO Keseluruhan Azure VM:
Navigasi ke Komputer Virtual Anda di portal Azure - bukan komputer virtual SQL.
Pilih Metrik di bawah Pemantauan untuk membuka halaman Metrik .
Pilih Waktu lokal untuk menentukan rentang waktu yang Anda minati, dan zona waktu, baik lokal ke VM, atau UTC/GMT.
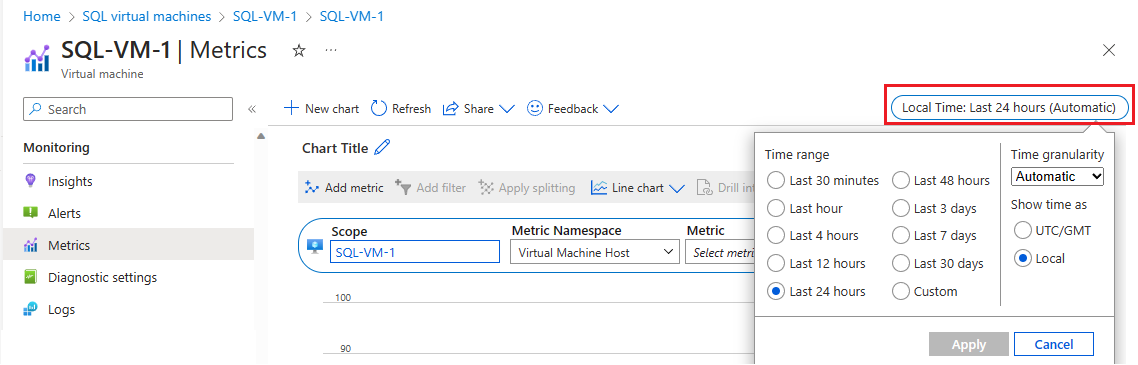
Pilih Tambahkan metrik untuk menambahkan dua metrik berikut untuk melihat grafik:
- Persentase Penggunaan Bandwidth Cache VM
- Persentase Penggunaan Bandwidth Yang Tidak Di-cache VM
Azure VM HostEvents menyebabkan failover
Ada kemungkinan bahwa HostEvent Azure VM menyebabkan grup ketersediaan Anda gagal. Jika Anda yakin HostEvent Azure VM menyebabkan failover, Anda dapat memeriksa log Aktivitas Azure Monitor, dan gambaran umum Azure VM Resource Health.
Log aktivitas Azure Monitor adalah log platform, di Azure, yang memberikan wawasan tentang peristiwa tingkat langganan. Log aktivitas mencakup informasi seperti ketika sumber daya dimodifikasi, atau komputer virtual dimulai. Anda dapat melihat log aktivitas di portal Azure, atau mengambil entri dengan PowerShell dan Azure CLI.
Untuk memeriksa log aktivitas Azure Monitor, ikuti langkah-langkah berikut:
Navigasikan ke Komputer Virtual Anda di portal Azure
Pilih Log Aktivitas di panel Komputer Virtual
Pilih Rentang Waktu lalu pilih jangka waktu saat grup ketersediaan Anda gagal. Pilih Terapkan.
Jika Azure memiliki informasi lebih lanjut tentang akar penyebab tidak tersedianya platform, informasi tersebut dapat diposting di halaman gambaran umum Azure VM - Resource Health hingga 72 jam setelah tidak tersedia awal. Informasi ini hanya tersedia untuk mesin virtual saat ini.
- Navigasikan ke Komputer Virtual Anda di portal Azure
- Pilih Kesehatan Sumber Daya di bawah panel Kesehatan .
Anda juga dapat mengonfigurasi pemberitahuan berdasarkan peristiwa kesehatan dari halaman ini.
Simpul kluster dihapus dari keanggotaan
Jika pengaturan heartbeat dan ambang Kluster Windows terlalu agresif untuk lingkungan Anda, Anda mungkin sering melihat pesan berikut di log peristiwa sistem.
Error 1135
Cluster node 'Node1' was removed from the active failover cluster membership.
The Cluster service on this node may have stopped. This could also be due to the node having
lost communication with other active nodes in the failover cluster. Run the Validate a
Configuration Wizard to check your network configuration. If the condition persists, check
for hardware or software errors related to the network adapters on this node. Also check for
failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Untuk informasi selengkapnya, tinjau Pemecahan masalah kluster dengan ID Peristiwa 1135.
Sewa telah kedaluwarsa / Sewa tidak lagi valid
Jika pemantauan terlalu agresif untuk lingkungan Anda, Anda mungkin sering melihat grup ketersediaan atau FCI memulai ulang, kegagalan, atau failover. Selain untuk grup ketersediaan, Anda dapat melihat pesan berikut di log kesalahan SQL Server:
Error 19407: The lease between availability group 'PRODAG' and the Windows Server Failover Cluster has expired.
A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster.
To determine whether the availability group is failing over correctly, check the corresponding availability group
resource in the Windows Server Failover Cluster
Error 19419: The renewal of the lease between availability group '%.*ls' and the Windows Server Failover Cluster
failed because the existing lease is no longer valid.
Waktu koneksi habis
Jika batas waktu sesi terlalu agresif untuk lingkungan grup ketersediaan, Anda mungkin sering melihat pesan berikut:
Error 35201: A connection timeout has occurred while attempting to establish a connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or firewall issue exists,
or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Error 35206
A connection timeout has occurred on a previously established connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or a firewall issue
exists, or the availability replica has transitioned to the resolving role.
Grup tidak gagal
Jika nilai Kegagalan Maksimum dalam Periode yang Ditentukan terlalu rendah dan Anda mengalami kegagalan yang berselang karena masalah sementara, grup ketersediaan Anda dapat berakhir dalam status gagal. Tingkatkan nilai ini untuk mentolerir lebih banyak kegagalan sementara.
Not failing over group <Resource name>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2.
Peristiwa 1196 - Sumber daya nama jaringan gagal pendaftaran nama DNS terkait
- Periksa pengaturan NIC pada setiap node kluster Anda untuk memastikan tidak ada catatan DNS eksternal
- Pastikan catatan A untuk kluster Anda tersedia di server DNS internal Anda. Jika tidak, buat manual Catatan A baru di Server DNS untuk objek Kontrol Akses Kluster dan centang tombol Perbolehkan pengguna yang diautentikasi untuk memperbarui Catatan DNS dengan nama pemilik yang sama.
- Pilih Sumber Daya "Nama Kluster" dengan Sumber Daya IP offline dan perbaiki.
Peristiwa 157 - Disk telah terkejut dihapus.
Ini dapat terjadi jika properti Ruang Penyimpanan AutomaticClusteringEnabled diatur untukTrue lingkungan AG. Ubah menjadi False. Selain itu, menjalankan opsi Laporan Validasi dengan Penyimpanan dapat memicu reset disk atau peristiwa yang dihapus mendadak. Sistem penyimpanan Pembatasan juga dapat memicu peristiwa penghapusan disk mendadak.
Peristiwa 1206 - Sumber daya nama jaringan kluster tidak dapat dibawa secara online.
Objek komputer yang terkait dengan sumber daya tidak dapat diperbarui di domain. Pastikan Anda memiliki izin yang sesuai pada domain
Kesalahan Pengklusteran Windows
Anda mungkin mengalami masalah saat menyiapkan kluster failover Windows atau konektivitasnya jika Anda tidak membuka Port Layanan Kluster untuk komunikasi.
Jika Anda berada di Windows Server 2019, dan Anda tidak melihat IP Kluster Windows, Anda telah mengonfigurasi Nama Jaringan Terdistribusi, yang hanya didukung pada SQL Server 2019. Jika Anda memiliki versi SQL Server sebelumnya, Anda dapat menghapus dan Membuat ulang Kluster menggunakan Nama Jaringan.
Tinjau Kesalahan Peristiwa Pengklusteran Failover Windows lainnya dan Solusinya di sini
Langkah berikutnya
Untuk mempelajari selengkapnya, lihat:
- Pengaturan HADR untuk SQL Server di Azure VM
- Kluster Failover Windows Server dengan Microsoft SQL Server di Azure VM
- Grup Ketersediaan Always On dengan SQL Server di Azure VM
- Kluster Failover Windows Server dengan SQL Server di Azure VM
- Instans kluster failover dengan Microsoft SQL Server di Azure VM
- Gambaran umum instans kluster failover
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk