Train PyTorch Model
Artikel ini menjelaskan cara menggunakan komponen Train PyTorch Model di perancang Azure Machine Learning untuk melatih model PyTorch seperti DenseNet. Pelatihan berlangsung setelah Anda menentukan model dan mengatur parameternya, dan memerlukan data berlabel.
Saat ini, komponen Train PyTorch Model mendukung pelatihan node tunggal dan terdistribusi.
Cara menggunakan Train PyTorch Model
Tambahkan komponen DenseNet atau ResNet ke draf alur Anda di perancang.
Tambahkan komponen Train PyTorch Model ke alur. Anda dapat menemukan komponen ini di bawah kategori Pelatihan Model. Luaskan Latih, lalu seret komponen Train PyTorch Model ke dalam alur Anda.
Catatan
Komponen Train PyTorch Model lebih baik dijalankan pada komputasi jenis GPU untuk himpunan data besar, jika tidak, alur Anda akan gagal. Anda dapat memilih komputasi untuk komponen tertentu di panel kanan komponen dengan mengatur Gunakan target komputasi lain.
Di input kiri, lampirkan model yang tidak terlatih. Lampirkan himpunan pelatihan dan himpunan data validasi ke input tengah dan kanan Train PyTorch Model.
Untuk model tidak terlatih, ini harus menjadi model PyTorch seperti DenseNet; jika tidak, 'InvalidModelDirectoryError' akan muncul.
Untuk himpunan data, himpunan data pelatihan harus berupa direktori gambar berlabel. Lihat Mengonversi ke Direktori Gambar untuk mengetahui cara mendapatkan direktori gambar berlabel. Jika tidak diberi label, 'NotLabeledDatasetError' akan muncul.
Kumpulan data pelatihan dan kumpulan data validasi memiliki kategori label yang sama, jika tidak, InvalidDatasetError akan muncul.
Untuk Epoch, tentukan berapa banyak periode yang ingin Anda latih. Seluruh himpunan data akan diulang di setiap epoch, secara default 5.
Untuk Ukuran batch, tentukan berapa banyak instans yang akan dilatih dalam satu batch, secara default 16.
Untuk Jumlah langkah pemanasan, tentukan berapa banyak epoch yang diinginkan untuk melakukan pemanasan pelatihan, jika tingkat pembelajaran awal sedikit terlalu besar untuk memulai konvergensi, secara default 0.
Untuk Tingkat pembelajaran, tentukan nilai untuk tingkat pembelajaran, dan nilai defaultnya adalah 0,001. Tingkat pembelajaran mengontrol ukuran langkah yang digunakan dalam pengoptimal seperti sgd setiap kali model diuji dan diperbaiki.
Dengan mengatur tingkat lebih kecil, Anda dapat lebih sering menguji model, dengan risiko kemungkinan terjebak dalam kestabilan lokal. Dengan mengatur tingkat lebih besar, Anda dapat melakukan konvergensi lebih cepat, dengan risiko melampaui tingkat minimal yang sebenarnya.
Catatan
Jika kehilangan latihan menjadi varian selama pelatihan, yang mungkin disebabkan oleh tingkat pembelajaran yang terlalu besar, menurunkan tingkat pembelajaran mungkin dapat membantu. Dalam pelatihan terdistribusi, untuk menjaga penurunan gradien tetap stabil, tingkat pembelajaran aktual dihitung oleh
lr * torch.distributed.get_world_size()karena ukuran batch dari grup proses adalah kelipatan ukuran dunia dari proses tunggal. Pembusukan tingkat pembelajaran polinomial diterapkan dan dapat membantu menghasilkan model dengan performa lebih baik.Untuk Benih acak, secara opsional ketik nilai bilangan bulat untuk digunakan sebagai benih. Sebaiknya gunakan benih jika Anda ingin memastikan reproduktifitas eksperimen seluruh pekerjaan.
Untuk Kesabaran, tentukan berapa banyak epoch untuk berhenti pelatihan lebih awal jika kehilangan validasi tidak berkurang berturut-turut. secara default 3.
Untuk Frekuensi cetak, tentukan frekuensi cetak log pelatihan selama perulangan di setiap epoch, secara default 10.
Kirim alur. Jika himpunan data Anda memiliki ukuran yang lebih besar, prosesnya akan memakan waktu beberapa saat dan komputasi GPU direkomendasikan.
Pelatihan yang didistribusikan
Dalam pelatihan terdistribusi, beban kerja untuk melatih model dipisah dan dibagikan di antara beberapa prosesor mini, yang disebut simpul pekerja. Simpul pekerja ini bekerja secara paralel untuk mempercepat pelatihan model. Saat ini perancang mendukung pelatihan yang didistribusikan untuk komponen Train PyTorch Model.
Waktu pelatihan
Pelatihan terdistribusi memungkinkan pelatihan pada himpunan data besar seperti ImageNet (1000 kelas, 1,2 juta gambar) hanya dalam beberapa jam oleh Train PyTorch Model. Tabel berikut menunjukkan waktu dan performa pelatihan selama melatih 50 epoch Restnet50 di ImageNet dari awal berdasarkan perangkat yang berbeda.
| Perangkat | Waktu Pelatihan | Throughput Pelatihan | Akurasi Validasi Top-1 | Akurasi Validasi Top-5 |
|---|---|---|---|---|
| 16 GPU V100 | 6j22mnt | ~3200 Gambar/Dtk | 68,83% | 88,84% |
| 8 GPU V100 | 12j21mnt | ~1670 Gambar/Dtk | 68,84% | 88,74% |
Klik pada tab 'Metrik' komponen ini dan lihat grafik metrik pelatihan, seperti 'Latih gambar per detik' dan 'Akurasi 1 teratas'.

Cara mengaktifkan pelatihan terdistribusi
Untuk mengaktifkan pelatihan terdistribusi untuk komponen Model Train PyTorch, Anda dapat mengatur di Pengaturan pekerjaan di panel kanan komponen. Hanya Kluster Komputasi AML yang didukung untuk pelatihan terdistribusi.
Catatan
Beberapa GPU diperlukan untuk mengaktifkan pelatihan terdistribusi karena komponen Train PyTorch Model backend NCCL menggunakan kebutuhan cuda.
Pilih komponen dan buka panel kanan. Perluas bagian Pengaturan pekerjaan.
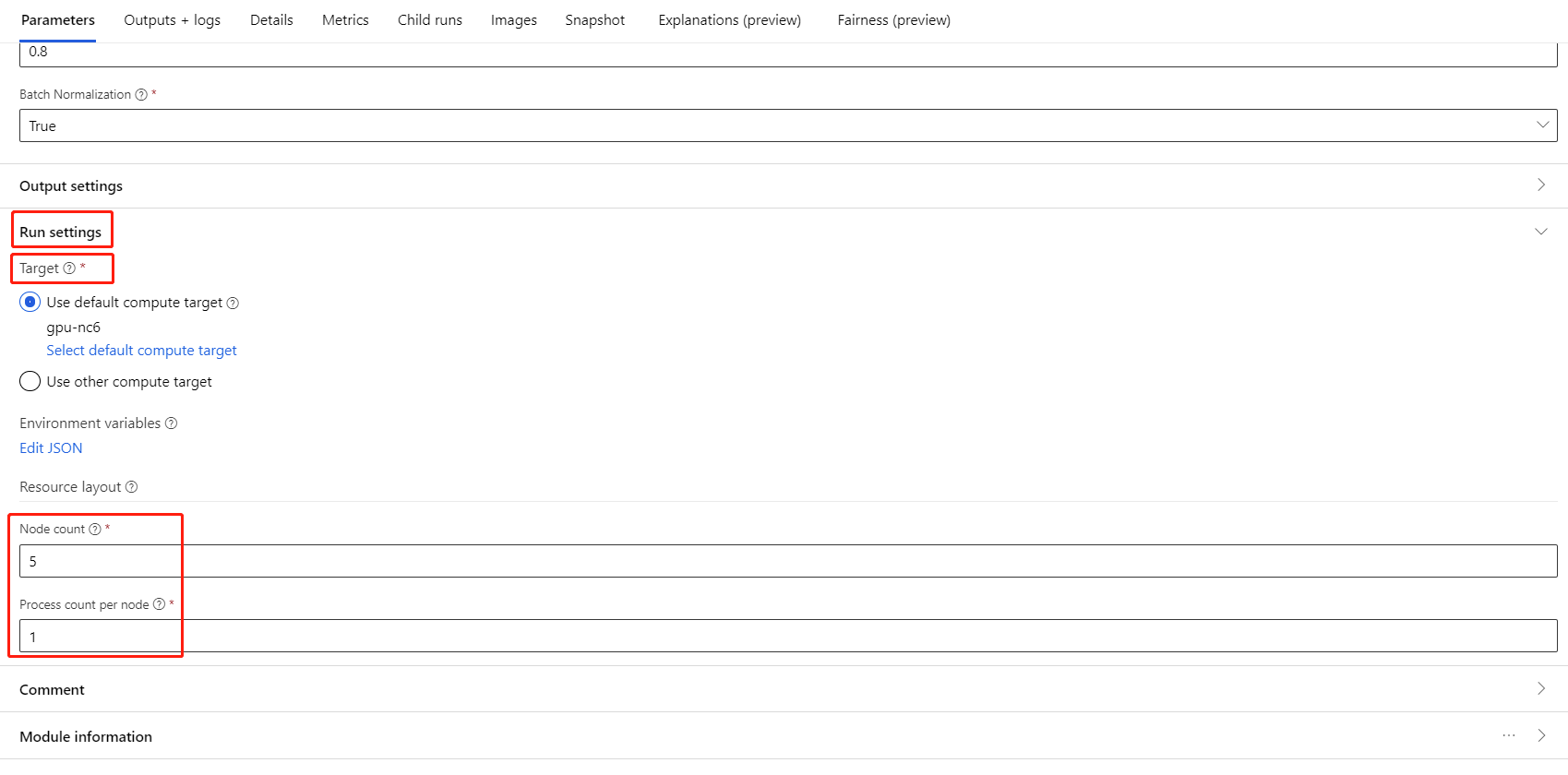
Pastikan Anda telah memilih komputasi AML untuk target komputasi.
Di bagian Tata letak sumber daya, Anda perlu mengatur nilai berikut:
Jumlah simpul : Jumlah simpul dalam target komputasi yang digunakan untuk pelatihan. Jumlah ini harus kurang dari atau sama denganjumlah maksimum simpul untuk kluster komputasi Anda. Jumlah defaultnya adalah 1, yang berarti pekerjaan simpul tunggal.
Jumlah proses per simpul: Jumlah proses yang dipicu per simpul. Jumlah ini harus kurang dari atau sama denganUnit Pemrosesan komputasi Anda. Jumlah defaultnya adalah 1, yang berarti pekerjaan proses tunggal.
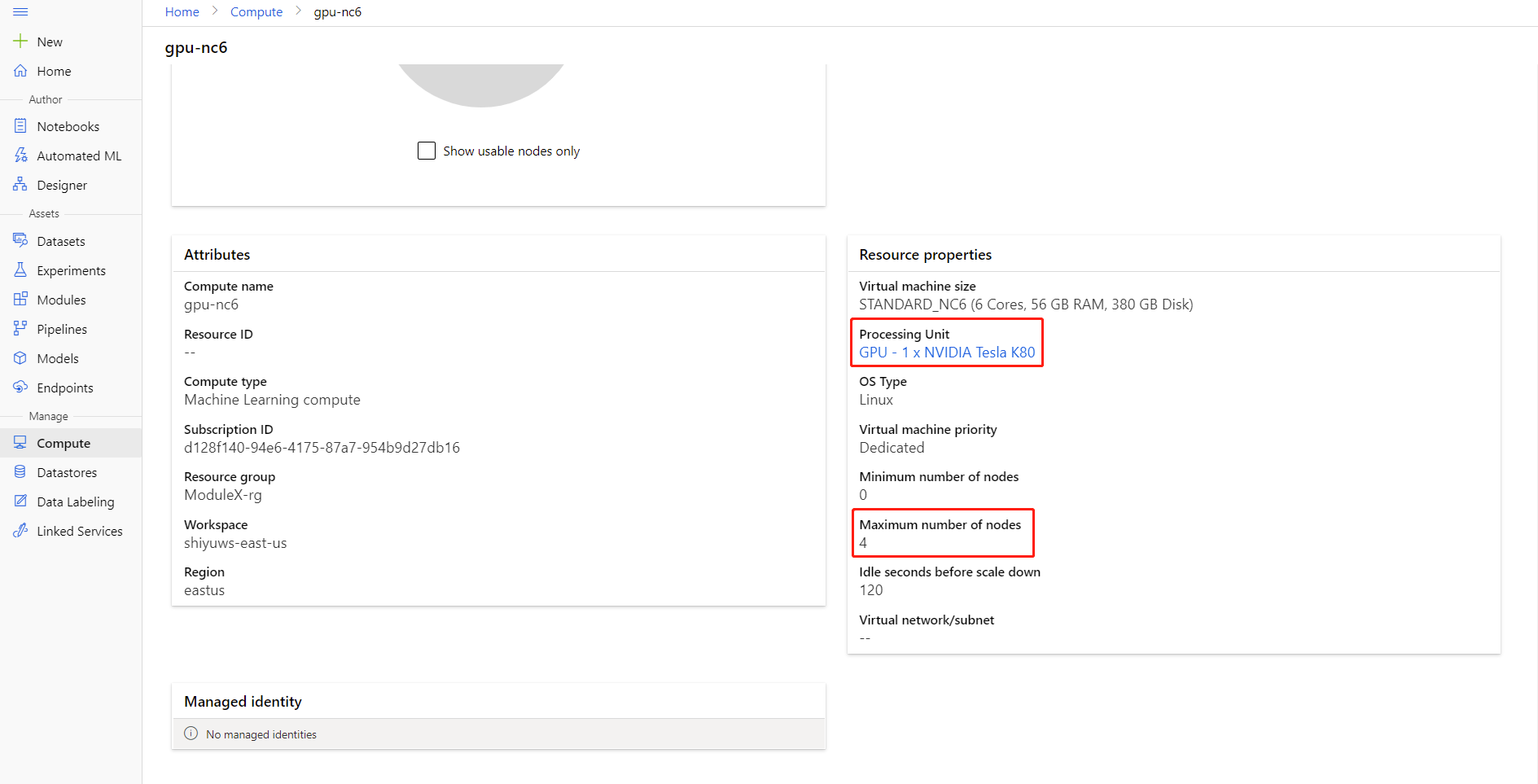
Anda dapat memeriksa jumlah maksimum simpul dan Unit Pemrosesan komputasi Anda dengan mengklik nama komputasi ke halaman detail komputasi.


Anda dapat mempelajari lebih lanjut pelatihan terdistribusi di Azure Machine Learning di sini.
Pemecahan masalah pelatihan terdistribusi
Jika Anda mengaktifkan pelatihan terdistribusi untuk komponen ini, akan ada log driver untuk setiap proses. 70_driver_log_0 adalah untuk proses utama. Anda dapat memeriksa log driver untuk mendapatkan detail kesalahan setiap proses di tab Output+log di panel kanan.

Jika pelatihan terdistribusi yang diaktifkan komponen gagal tanpa log 70_driver apa pun, Anda dapat memeriksa 70_mpi_log untuk detail kesalahan.
Contoh berikut menunjukkan kesalahan umum, yaitu Jumlah proses per simpul lebih besar dari Unit Pemrosesan komputasi.

Anda dapat melihat artikel ini untuk detail selengkapnya tentang pemecahan masalah komponen.
Hasil
Setelah pekerjaan alur selesai, untuk menggunakan model pada penilaian, sambungkan Model Train PyTorch ke Model Score Image, untuk memprediksi nilai bagi contoh input baru.
Catatan teknis
Input yang diharapkan
| Nama | Jenis | Deskripsi |
|---|---|---|
| Model tak terlatih | UntrainedModelDirectory | Model yang tidak terlatih, memerlukan PyTorch |
| Himpunan data pelatihan | ImageDirectory | Himpunan data pelatihan |
| Himpunan data validasi | ImageDirectory | Himpunan data validasi untuk evaluasi setiap epoch |
Parameter komponen
| Nama | Rentang | Jenis | Default | Deskripsi |
|---|---|---|---|---|
| Epoch | >0 | Bilangan bulat | 5 | Memilih kolom yang berisi label atau kolom hasil |
| Ukuran batch | >0 | Bilangan bulat | 16 | Berapa banyak contoh untuk dilatih dalam batch |
| Jumlah langkah pemanasan | >=0 | Bilangan bulat | 0 | Berapa banyak epoch untuk pemanasan pelatihan |
| Tingkat pembelajaran | >=double.Epsilon | Mengambang | 0.1 | Tingkat pembelajaran awal untuk pengoptimal Stochastic Gradient Descent. |
| Benih acak | Apa pun | Bilangan bulat | 1 | Benih untuk generator angka acak yang digunakan oleh model. |
| Kesabaran | >0 | Bilangan bulat | 3 | Berapa banyak epoch untuk menghentikan pelatihan lebih awal |
| Frekuensi cetak | >0 | Bilangan bulat | 10 | Frekuensi cetak log pelatihan selama perulangan di setiap epoch |
Output
| Nama | Jenis | Deskripsi |
|---|---|---|
| Model terlatih | ModelDirectory | Model terlatih |
Langkah berikutnya
Lihat set komponen yang tersedia untuk Azure Machine Learning.