Questo articolo illustra come creare un servizio di ricerca che consente agli utenti di cercare documenti in base al contenuto del documento, oltre a tutti i metadati associati ai file.
È possibile implementare questo servizio usando più indicizzatori in Ricerca di intelligenza artificiale di Azure.
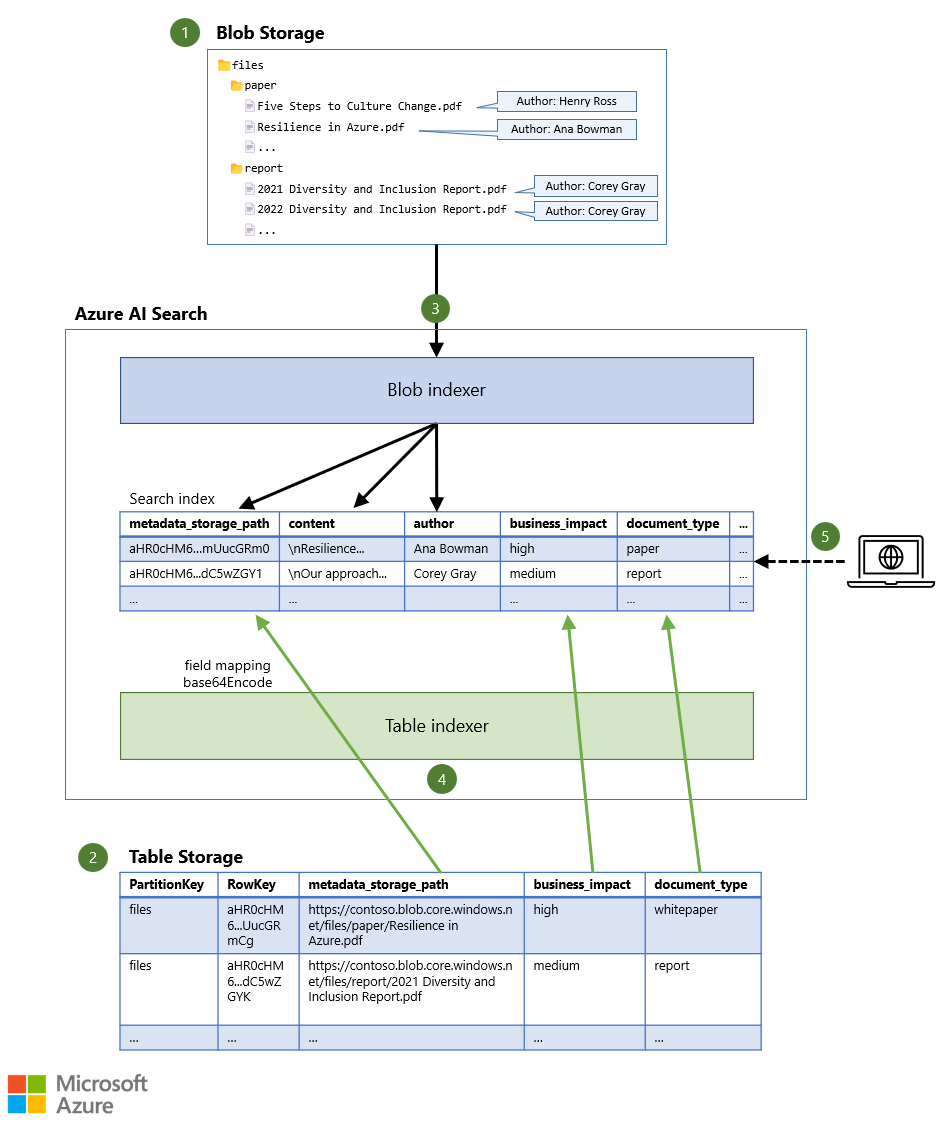
Questo articolo usa un carico di lavoro di esempio per illustrare come creare un singolo indice di ricerca basato su file in Archiviazione BLOB di Azure. I metadati del file vengono archiviati nella Archiviazione tabella di Azure.
Architettura
Scaricare un file PowerPoint di questa architettura.
Flusso di dati
- I file vengono archiviati in Archiviazione BLOB, possibilmente insieme a una quantità limitata di metadati (ad esempio, l'autore del documento).
- I metadati aggiuntivi vengono archiviati in Table Archiviazione, che può archiviare significativamente più informazioni per ogni documento.
- Un indicizzatore legge il contenuto di ogni file, insieme ai metadati del BLOB e archivia i dati nell'indice di ricerca.
- Un altro indicizzatore legge i metadati aggiuntivi dalla tabella e lo archivia nello stesso indice di ricerca.
- Una query di ricerca viene inviata al servizio di ricerca. La query restituisce documenti corrispondenti, in base al contenuto del documento e ai metadati del documento.
Componenti
- Blob Archiviazione offre un'archiviazione cloud conveniente per i dati dei file, inclusi i dati in formati come PDF, HTML e CSV e nei file di Microsoft 365.
- La tabella Archiviazione fornisce spazio di archiviazione per i dati strutturati non relazionali. In questo scenario viene usato per archiviare i metadati per ogni documento.
- Ricerca di intelligenza artificiale di Azure è un servizio di ricerca completamente gestito che fornisce infrastruttura, API e strumenti per creare un'esperienza di ricerca avanzata.
Alternative
Questo scenario usa gli indicizzatori in Ricerca di intelligenza artificiale di Azure per individuare automaticamente nuovi contenuti nelle origini dati supportate, ad esempio l'archiviazione BLOB e tabelle, e quindi aggiungerlo all'indice di ricerca. In alternativa, è possibile usare le API fornite da Ricerca di intelligenza artificiale di Azure per eseguire il push dei dati nell'indice di ricerca. In questo caso, tuttavia, è necessario scrivere codice per eseguire il push dei dati nell'indice di ricerca e anche per analizzare ed estrarre testo dai documenti binari da cercare. L'indicizzatore blob Archiviazione supporta molti formati di documento, semplificando in modo significativo il processo di estrazione e indicizzazione del testo.
Inoltre, se si usano indicizzatori, è possibile arricchire facoltativamente i dati come parte di una pipeline di indicizzazione. Ad esempio, è possibile usare i servizi di intelligenza artificiale di Azure per eseguire il riconoscimento ottico dei caratteri (OCR) o l'analisi visiva delle immagini nei documenti, rilevare la lingua dei documenti o tradurre documenti. È anche possibile definire competenze personalizzate per arricchire i dati in modi rilevanti per lo scenario aziendale.
Questa architettura usa l'archiviazione BLOB e tabelle perché è conveniente ed efficiente. Questa progettazione consente anche l'archiviazione combinata dei documenti e dei metadati in un singolo account di archiviazione. Le origini dati alternative supportate per i documenti stessi includono azure Data Lake Archiviazione e File di Azure. I metadati dei documenti possono essere archiviati in qualsiasi altra origine dati supportata che contiene dati strutturati, ad esempio database SQL di Azure e Azure Cosmos DB.
Dettagli dello scenario
Ricerca di contenuto di file
Questa soluzione consente agli utenti di cercare documenti in base al contenuto dei file e ai metadati aggiuntivi archiviati separatamente per ogni documento. Oltre a cercare il contenuto di testo di un documento, un utente potrebbe voler cercare l'autore del documento, il tipo di documento (ad esempio carta o report) o il relativo impatto aziendale (alto, medio o basso).
Ricerca di intelligenza artificiale di Azure è un servizio di ricerca completamente gestito che può creare indici di ricerca contenenti le informazioni che si vuole consentire agli utenti di cercare.
Poiché i file cercati in questo scenario sono documenti binari, è possibile archiviarli in blob Archiviazione. In questo caso, è possibile usare l'indicizzatore BLOB predefinito Archiviazione in Ricerca di intelligenza artificiale di Azure per estrarre automaticamente testo dai file e aggiungerlo all'indice di ricerca.
Ricerca di metadati di file
Se si desidera includere informazioni aggiuntive sui file, è possibile associare direttamente i metadati ai BLOB, senza usare un archivio separato. Il BLOB predefinito Archiviazione indicizzatore di ricerca può anche leggere questi metadati e inserirli nell'indice di ricerca. In questo modo gli utenti possono cercare i metadati insieme al contenuto del file. Tuttavia, la quantità di metadati è limitata a 8 KB per BLOB, quindi la quantità di informazioni che è possibile inserire in ogni BLOB è piuttosto piccola. È possibile scegliere di archiviare solo le informazioni più critiche direttamente nei BLOB. In questo scenario, solo l'autore del documento viene archiviato nel BLOB.
Per superare questa limitazione di archiviazione, è possibile inserire metadati aggiuntivi in un'altra origine dati con un indicizzatore supportato, ad esempio Table Archiviazione. È possibile aggiungere il tipo di documento, l'impatto aziendale e altri valori di metadati come colonne separate nella tabella. Se si configura l'indicizzatore table Archiviazione predefinito per specificare lo stesso indice di ricerca dell'indicizzatore BLOB, i metadati di archiviazione BLOB e tabelle vengono combinati per ogni documento nell'indice di ricerca.
Uso di più origini dati per un singolo indice di ricerca
Per garantire che entrambi gli indicizzatori puntino allo stesso documento nell'indice di ricerca, la chiave del documento nell'indice di ricerca viene impostata su un identificatore univoco del file. Questo identificatore univoco viene quindi usato per fare riferimento al file in entrambe le origini dati. Per impostazione predefinita, l'indicizzatore metadata_storage_path BLOB usa come chiave del documento. La metadata_storage_path proprietà archivia l'URL completo del file nel BLOB Archiviazione, ad esempio https://contoso.blob.core.windows.net/files/paper/Resilience in Azure.pdf. L'indicizzatore esegue la codifica Base64 sul valore per assicurarsi che nella chiave del documento non siano presenti caratteri non validi. Il risultato è una chiave di documento univoca, ad esempio aHR0cHM6...mUucGRm0.
Se si aggiunge metadata_storage_path come colonna in Table Archiviazione, si conosce esattamente il BLOB a cui appartengono i metadati nelle altre colonne, in modo da poter usare qualsiasi PartitionKey valore e RowKey nella tabella. Ad esempio, è possibile usare il nome del contenitore BLOB come PartitionKey e l'URL completo con codifica Base64 del BLOB come RowKey, assicurandosi che in queste chiavi non siano presenti caratteri non validi.
È quindi possibile usare un mapping dei campi nell'indicizzatore di tabella per eseguire il mapping della metadata_storage_path colonna (o di un'altra colonna) in Table Archiviazione al metadata_storage_path campo chiave del documento nell'indice di ricerca. Se si applica la funzione base64Encode al mapping dei campi, si finisce con la stessa chiave del documento (aHR0cHM6...mUucGRm0 nell'esempio precedente) e i metadati di Table Archiviazione vengono aggiunti allo stesso documento estratto dalla Archiviazione BLOB.
Nota
La documentazione dell'indicizzatore di tabelle indica che non è consigliabile definire un mapping di campi a un campo stringa univoco alternativo nella tabella. Questo perché l'indicizzatore concatena PartitionKey e RowKey come chiave del documento, per impostazione predefinita. Poiché la chiave del documento è già basata sulla chiave del documento configurata dall'indicizzatore BLOB (ovvero l'URL completo con codifica Base64 del BLOB), la creazione di un mapping dei campi per garantire che entrambi gli indicizzatori facciano riferimento allo stesso documento nell'indice di ricerca siano appropriati e supportati per questo scenario.
In alternativa, è possibile eseguire il mapping RowKey diretto (impostato sull'URL completo con codifica Base64 del BLOB) alla metadata_storage_path chiave del documento, senza archiviarlo separatamente e codifica Base64 come parte del mapping dei campi. Tuttavia, mantenere l'URL non codificato in una colonna separata chiarisce il BLOB a cui fa riferimento e consente di scegliere qualsiasi partizione e chiavi di riga senza influire sull'indicizzatore di ricerca.
Potenziali casi d'uso
Questo scenario si applica alle applicazioni che richiedono la possibilità di cercare documenti in base al contenuto e ai metadati aggiuntivi.
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di set di principi guida che è possibile usare per migliorare la qualità di un carico di lavoro. Per altre informazioni, vedere Framework ben progettato di Microsoft Azure.
Affidabilità
L'affidabilità garantisce che l'applicazione possa soddisfare gli impegni assunti dai clienti. Per altre informazioni, vedere Panoramica del pilastro dell'affidabilità.
Ricerca di intelligenza artificiale di Azure offre un contratto di servizio elevato per le letture (query) se sono presenti almeno due repliche. Fornisce un contratto di servizio elevato per gli aggiornamenti (aggiornamento degli indici di ricerca) se sono presenti almeno tre repliche. È quindi consigliabile effettuare il provisioning di almeno due repliche se si vuole che gli utenti possano eseguire ricerche in modo affidabile e tre se le modifiche effettive all'indice devono essere operazioni a disponibilità elevata.
Archiviazione di Azure archivia sempre più copie dei dati per proteggerli da eventi pianificati e non pianificati. Archiviazione di Azure offre opzioni di ridondanza aggiuntive per la replica dei dati tra aree. Queste misure di sicurezza si applicano ai dati nell'archiviazione BLOB e tabelle.
Sicurezza
La sicurezza offre garanzie contro attacchi intenzionali e l'abuso di dati e sistemi preziosi. Per altre informazioni, vedere Panoramica del pilastro della sicurezza.
Ricerca di intelligenza artificiale di Azure offre controlli di sicurezza affidabili che consentono di implementare sicurezza di rete, autenticazione e autorizzazione, residenza e protezione dei dati e controlli amministrativi che consentono di mantenere sicurezza, privacy e conformità.
Quando possibile, usare l'autenticazione Di Microsoft Entra per fornire l'accesso al servizio di ricerca stesso e connettere il servizio di ricerca ad altre risorse di Azure (ad esempio l'archiviazione BLOB e tabelle in questo scenario) usando un'identità gestita.
È possibile connettersi dal servizio di ricerca all'account di archiviazione usando un endpoint privato. Quando si usa un endpoint privato, gli indicizzatori possono usare una connessione privata senza richiedere che l'archiviazione BLOB e tabelle sia accessibile pubblicamente.
Ottimizzazione dei costi
L'ottimizzazione dei costi riguarda la riduzione delle spese non necessarie e il miglioramento dell'efficienza operativa. Per altre informazioni, vedere Panoramica del pilastro di ottimizzazione dei costi.
Per informazioni sui costi di esecuzione di questo scenario, vedere questa stima preconfigurata nel calcolatore prezzi di Azure. Tutti i servizi descritti di seguito sono configurati in questa stima. La stima è relativa a un carico di lavoro con dimensioni totali del documento di 20 GB in BLOB Archiviazione e 1 GB di metadati nella tabella Archiviazione. Due unità di ricerca vengono usate per soddisfare il contratto di servizio a scopo di lettura, come descritto nella sezione Affidabilità di questo articolo. Per vedere come cambiano i prezzi per un caso d'uso specifico, modificare le variabili appropriate in modo che corrispondano all'utilizzo previsto.
Se si esamina la stima, è possibile notare che il costo dell'archiviazione BLOB e tabelle è relativamente basso. La maggior parte dei costi è sostenuta da Ricerca di intelligenza artificiale di Azure, perché esegue l'indicizzazione e il calcolo effettivi per l'esecuzione di query di ricerca.
Distribuire lo scenario
Per distribuire questo carico di lavoro di esempio, vedere Indicizzazione del contenuto e dei metadati dei file in Ricerca di intelligenza artificiale di Azure. È possibile usare questo esempio per:
- Creare i servizi di Azure necessari.
- Caricare alcuni documenti di esempio in Archiviazione BLOB.
- Popolare il valore dei metadati dell'autore nel BLOB.
- Archiviare i valori dei metadati relativi al tipo di documento e all'impatto aziendale in Table Archiviazione.
- Creare gli indicizzatori che mantengono l'indice di ricerca.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Jelle Druyts | Principal Customer Experience Engineer
Altro collaboratore:
- Mick Alberts | Writer tecnico
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Passaggi successivi
- Introduzione a Ricerca intelligenza artificiale di Azure
- Aumentare la pertinenza usando la ricerca semantica in Ricerca di intelligenza artificiale di Azure
- Filtri di sicurezza per il taglio dei risultati in Ricerca di intelligenza artificiale di Azure
- Esercitazione: Indicizzare da più origini dati usando .NET SDK