Panoramica dei tipi di modello in Microsoft Syntex
Si applica a: ✓ Tutti i modelli personalizzati | ✓ Tutti i modelli predefiniti
La comprensione del contenuto in Microsoft Syntex inizia con i modelli di elaborazione dei documenti. I modelli di elaborazione dei documenti consentono di identificare e classificare i documenti caricati nelle raccolte documenti di SharePoint e quindi di estrarre le informazioni necessarie da ogni file.
Se applicato a una raccolta documenti di SharePoint, il modello è associato a un tipo di contenuto e dispone di colonne per archiviare le informazioni da estrarre. Il tipo di contenuto creato è archiviato nella raccolta tipi di contenuto di SharePoint. È anche possibile scegliere di usare i tipi di contenuto esistenti per usare il loro schema.
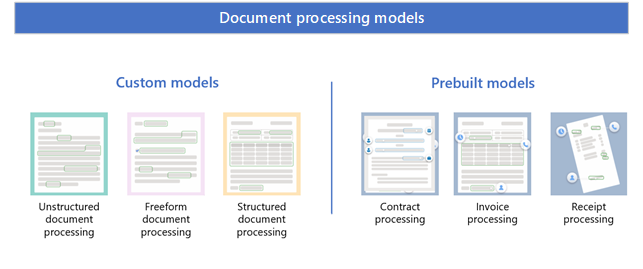
Syntex usa modelli personalizzati e modelli predefiniti.
I modelli possono essere modelli aziendali, creati in un centro contenuti, o modelli locali, creati nel sito di SharePoint locale.
Modelli personalizzati
Il tipo di modello personalizzato scelto dipenderà dai tipi di file usati, dal formato e dalla struttura dei file e dalla posizione in cui si vuole applicare il modello.
I modelli personalizzati includono:
- Elaborazione di documenti non strutturati
- Elaborazione documenti a mano libera
- Elaborazione di documenti strutturati
Per visualizzare le differenze affiancate nei modelli personalizzati, vedere Confrontare i modelli personalizzati.
Quando si crea un modello personalizzato, si selezionerà il metodo di training associato al tipo di modello. Ad esempio, se si vuole creare un modello di elaborazione documenti non strutturato, nella pagina Opzioni per la creazione del modello in cui si crea un modello, si sceglierà l'opzione Metodo di insegnamento . Nella tabella seguente viene illustrato il metodo di training associato a ogni tipo di modello personalizzato.
| Destrutturati elaborazione dei documenti |
Freeform elaborazione dei documenti |
Strutturati elaborazione dei documenti |
|---|---|---|
 |
 |
 |
Nota
Per rendere disponibili agli utenti il metodo di selezione a mano libera e le opzioni del metodo Layout, è necessario configurarli prima nel interfaccia di amministrazione di Microsoft 365.
Elaborazione di documenti non strutturati
Usare il modello di elaborazione documenti non strutturato per classificare automaticamente i documenti ed estrarre informazioni da essi. Funziona meglio con documenti non strutturati, ad esempio lettere o contratti. Questi documenti devono contenere un testo che possa essere identificato in base a frasi o schemi. Il testo identificato designa sia il tipo di file (la classificazione) che l'elemento che si vuole estrarre (l’estrattore).
Ad esempio, un documento non strutturato potrebbe essere una lettera di rinnovo contrattuale che può essere scritta in modi diversi. Tuttavia, le informazioni sono presenti in modo coerente nel corpo di ogni documento di rinnovo del contratto, ad esempio la stringa di testo "Data di inizio del servizio" seguita da una data effettiva.
Questo tipo di modello supporta la più ampia gamma di tipi di file e supporta più di 40 lingue.
Quando si crea un modello di elaborazione documenti non strutturato, usare l'opzione Metodo di insegnamento .
Per altre informazioni, vedere Panoramica dell'elaborazione di documenti non strutturati.
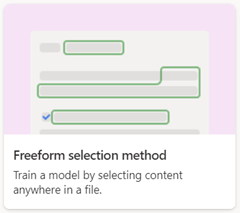
Elaborazione documenti a mano libera
Usare il modello di elaborazione documenti a mano libera per estrarre automaticamente informazioni da documenti non strutturati e a mano libera, ad esempio lettere e contratti, in cui le informazioni possono essere visualizzate in qualsiasi punto del documento.
I modelli di elaborazione documenti a mano libera usano Microsoft Power Apps AI Builder per creare ed eseguire il training di modelli all'interno di Syntex.
Nota
Il modello di elaborazione documenti a mano libera non è ancora disponibile in alcune aree. Per altre informazioni, vedere Disponibilità delle funzionalità in base all'area.
Poiché l'organizzazione riceve lettere e documenti in grandi quantità da varie origini, ad esempio posta, fax e posta elettronica, l'elaborazione di questi documenti e l'immissione manuale in un database può richiedere molto tempo. Usando l'intelligenza artificiale per estrarre il testo e altre informazioni da questi documenti, questo modello automatizza questo processo.
Questo tipo di modello è l'opzione migliore per i documenti in file PDF o immagini quando non è necessaria la classificazione automatica del tipo di documento e supporta più di 40 lingue.
Quando si crea un modello di elaborazione documenti a mano libera, usare l'opzione Metodo di selezione a mano libera .
Per altre informazioni, vedere Panoramica dell'elaborazione di documenti strutturati e a mano libera.
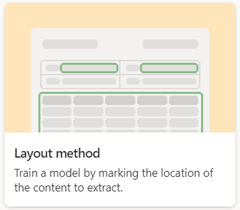
Elaborazione di documenti strutturati
Usare il modello di elaborazione di documenti strutturati per identificare automaticamente i valori di campo e tabella. Funziona meglio per i documenti strutturati o semistrutturati, ad esempio moduli e fatture.
I modelli di elaborazione dei documenti strutturati usano l'elaborazione di documenti di Microsoft Power Apps AI Builder (in precedenza nota come elaborazione dei moduli) per creare ed eseguire il training di modelli all'interno di Syntex.
Questo tipo di modello supporta la più ampia gamma di lingue ed è sottoposto a training per comprendere il layout del modulo da documenti di esempio e quindi apprende di cercare i dati necessari per l'estrazione da posizioni simili. I moduli hanno in genere un layout più strutturato in cui le entità si trovano nella stessa posizione (ad esempio, un numero di previdenza sociale in un modulo fiscale).
Quando si crea un modello di elaborazione di documenti strutturati, usare l'opzione Metodo layout .
Per altre informazioni, vedere Panoramica dell'elaborazione di documenti strutturati e a mano libera.
Modelli predefiniti
Se non è necessario compilare un modello personalizzato, è possibile usare un modello di elaborazione documenti predefinito di cui è già stato eseguito il training per documenti strutturati specifici.
I modelli predefiniti includono:

I modelli predefiniti sono sottoposti a training per riconoscere i documenti e le informazioni strutturate nei documenti. Anziché creare un nuovo modello personalizzato da zero, è possibile eseguire l'iterazione su un modello già sottoposto a training esistente per aggiungere campi specifici che soddisfano le esigenze dell'organizzazione.
Elaborazione del contratto
Il modello di elaborazione del contratto analizza ed estrae le informazioni chiave dai documenti del contratto. L'API analizza i contratti in vari formati ed estrae informazioni chiave sul contratto, ad esempio il nome del client o della parte, l'indirizzo di fatturazione, la giurisdizione e la data di scadenza.
Per altre informazioni sui modelli di elaborazione dei contratti predefiniti, vedere Usare un modello predefinito per estrarre informazioni dai contratti.
Elaborazione della fattura
Il modello di elaborazione delle fatture analizza ed estrae le informazioni chiave dalle fatture di vendita. L'API analizza le fatture in vari formati ed estrae informazioni chiave sulla fattura, ad esempio il nome del cliente, l'indirizzo di fatturazione, la data di scadenza e l'importo dovuto.
Per altre informazioni sui modelli di elaborazione delle fatture predefiniti, vedere Usare un modello predefinito per estrarre informazioni dalle fatture.
Elaborazione delle ricevute
Il modello di elaborazione delle ricevute predefinito analizza ed estrae le informazioni chiave dalle ricevute di vendita. L'API analizza le ricevute stampate e scritte a mano ed estrae informazioni sulle ricevute chiave, ad esempio il nome del commerciante, il numero di telefono del commerciante, la data della transazione, le imposte e il totale delle transazioni.
Per altre informazioni sui modelli di elaborazione delle ricevute predefiniti, vedere Usare un modello predefinito per estrarre informazioni dalle ricevute.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per