Microsoft Entra Connect Sync: informazioni sull'architettura
Questo argomento illustra l'architettura di base per Microsoft Entra Connessione Sync. Se si ha familiarità con le tecnologie di sincronizzazione delle identità precedenti, anche il contenuto di questo argomento sarà familiare. Se invece non si ha esperienza con la sincronizzazione, è consigliabile leggere questo argomento. Non è tuttavia necessario conoscere i dettagli di questo argomento per poter apportare personalizzazioni a Microsoft Entra Connessione Sync (denominato motore di sincronizzazione in questo argomento).
Architettura
Il motore di sincronizzazione crea una visualizzazione integrata degli oggetti archiviati in più origini dati connesse e gestisce le informazioni sull'identità presenti in tali origini dati. Questa visualizzazione integrata viene determinata dalle informazioni sull'identità recuperate da origini dati connesse e da un set di regole che determinano come elaborare le informazioni.
Origini dati connesse e connettori
Il motore di sincronizzazione elabora le informazioni sull'identità provenienti da repository dati diversi, ad esempio Active Directory o un database SQL Server. Ogni repository che organizza i dati in formato database e che fornisce metodi standard di accesso ai dati è una potenziale origine dati candidata per il motore di sincronizzazione. I repository dati sincronizzati dal motore di sincronizzazione sono chiamati origini dati connesse o directory connesse (CD, Connected Directory).
Il motore di sincronizzazione incapsula l'interazione con un'origine dati connessa in un modulo chiamato connettore. Ogni tipo di origine dati connessa ha un connettore specifico. Il connettore converte un'operazione obbligatoria nel formato leggibile dall'origine dati connessa.
I connettori effettuano chiamate API per scambiare informazioni sull'identità (sia in lettura che in scrittura) con un'origine dati connessa. È anche possibile aggiungere un connettore personalizzato usando il framework di connettività estendibile. La figura seguente illustra come un connettore connette un'origine dati connessa al motore di sincronizzazione.
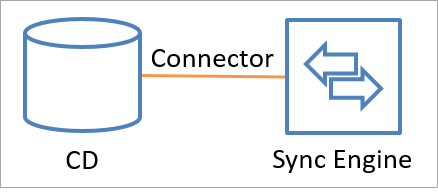
I dati possono scorrere in una direzione o nell'altra, ma non in entrambe contemporaneamente. In altre parole, un connettore può essere configurato per consentire ai dati di scorrere dall'origine dati connessa al motore di sincronizzazione o dal motore di sincronizzazione all'origine dati connessa, ma solo una di tali operazioni può essere in qualsiasi momento per un oggetto e un attributo. La direzione può essere diversa a seconda degli oggetti e degli attributi.
Per configurare un connettore, si specificano i tipi di oggetto che si vuole sincronizzare. Specificando i tipi di oggetto viene definito l'ambito degli oggetti inclusi nel processo di sincronizzazione. Il passaggio successivo prevede la selezione degli attributi da sincronizzare per cui viene usato un elenco di inclusione degli attributi. Queste impostazioni possono essere modificate in qualsiasi momento in risposta alle modifiche apportate alle regole di business. Quando si utilizza l'installazione guidata di Microsoft Entra Connessione, queste impostazioni vengono configurate automaticamente.
Per esportare gli oggetti in un'origine dati connessa, l'elenco di inclusione degli attributi deve includere almeno gli attributi minimi necessari per creare un tipo di oggetto specifico in un'origine dati connessa. Ad esempio, l'attributo sAMAccountName deve essere incluso nell'elenco di inclusione degli attributi per esportare un oggetto utente in Active Directory perché per tutti gli oggetti utente in Active Directory deve essere definito un attributo sAMAccountName. L'installazione guidata eseguirà la configurazione automaticamente.
Se l'origine dati connessa usa componenti strutturali, ad esempio partizioni o contenitori per organizzare gli oggetti, è possibile limitare le aree nell'origine dati connessa usate per una determinata soluzione.
Struttura interna dello spazio dei nomi del motore di sincronizzazione
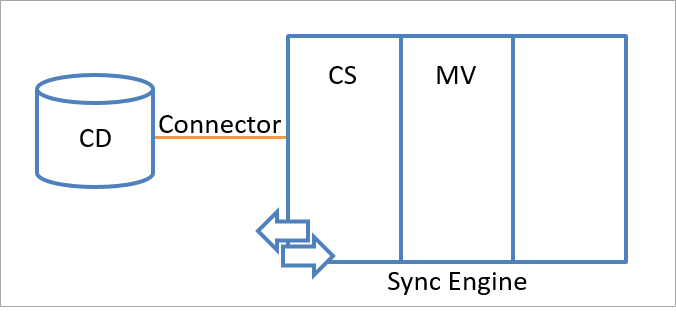
L'intero spazio dei nomi del motore di sincronizzazione è costituito da due spazi dei nomi in cui vengono archiviate le informazioni sull'identità. I due spazi dei nomi sono:
- Spazio connettore (CS, Connector Space)
- Metaverse (MV)
Lo spazio connettore è un'area di staging che contiene le rappresentazioni degli oggetti designati provenienti da un'origine dati connessa e gli attributi specificati nell'elenco di inclusione degli attributi. Il motore di sincronizzazione usa lo spazio connettore per determinare che cosa è stato modificato nell'origine dati connessa e per inserire temporaneamente le modifiche in ingresso. Il motore di sincronizzazione usa lo spazio connettore anche per inserire temporaneamente le modifiche in uscita da esportare nell'origine dati connessa. Il motore di sincronizzazione gestisce uno spazio connettore distinto come area di staging per ogni connettore.
Usando un'area di staging, il motore di sincronizzazione resta indipendente dalle origini dati connesse e non viene influenzato dalla disponibilità e dall'accessibilità. Di conseguenza, è possibile elaborare le informazioni sull'identità in qualsiasi momento usando i dati nell'area di staging. Il motore di sincronizzazione può richiedere solo le modifiche apportate nell'origine dati connessa dalla fine dell'ultima sessione di comunicazione o effettuare il push solo delle modifiche apportate alle informazioni sull'identità non ancora ricevute dall'origine dati connessa, il che riduce il traffico di rete tra il motore di sincronizzazione e l'origine dati connessa.
Inoltre il motore di sincronizzazione archivia le informazioni sullo stato di tutti gli oggetti inseriti temporaneamente nello spazio connettore. Quando vengono ricevuti nuovi dati, il motore di sincronizzazione valuta sempre se i dati sono già stati sincronizzati.
Il metaverse è un'area di archiviazione che contiene le informazioni sull'identità aggregate da più origini dati connesse, offrendo un'unica visualizzazione globale integrata di tutti gli oggetti combinati. Gli oggetti metaverse vengono creati in base alle informazioni sull'identità recuperate dalle origini dati connesse e a un set di regole che consentono di personalizzare il processo di sincronizzazione.
La figura seguente illustra lo spazio dei nomi dello spazio connettore e lo spazio dei nomi del metaverse nel motore di sincronizzazione.
Oggetti identità del motore di sincronizzazione
Gli oggetti nel motore di sincronizzazione sono rappresentazioni degli oggetti nell'origine dati connessa o della visualizzazione integrata di tali oggetti offerta dal motore di sincronizzazione. Ogni oggetto del motore di sincronizzazione deve avere un identificatore univoco globale (GUID). I GUID garantiscono l'integrità dei dati ed esprimono le relazioni tra gli oggetti.
Oggetti dello spazio connettore
Quando il motore di sincronizzazione comunica con un'origine dati connessa, legge le informazioni sull'identità nell'origine dati connessa e usa tali informazioni per creare una rappresentazione dell'oggetto identità nello spazio connettore. Non è possibile creare o eliminare tali oggetti singolarmente. È tuttavia possibile eliminare manualmente tutti gli oggetti in uno spazio connettore.
Tutti gli oggetti nello spazio connettore hanno due attributi:
- Un identificatore univoco globale (GUID)
- Un nome distinto (noto anche come DN)
Se l'origine dati connessa assegna un attributo univoco all'oggetto, anche gli oggetti nello spazio connettore possono avere un attributo di ancoraggio. L'attributo di ancoraggio identifica in modo univoco un oggetto nell'origine dati connessa. Il motore di sincronizzazione usa l'ancoraggio per individuare la rappresentazione corrispondente di questo oggetto nell'origine dati connessa. Il motore di sincronizzazione presuppone che l'ancoraggio di un oggetto non venga mai modificato per tutta la durata dell'oggetto.
Molti connettori usano un identificatore univoco noto per generare automaticamente un ancoraggio per ogni oggetto quando viene importato. Active Directory Connector, ad esempio, usa l'attributo objectGUID per un ancoraggio. Per le origini dati connesse che non forniscono un identificatore univoco chiaramente definito, è possibile specificare la generazione dell'ancoraggio durante la configurazione del connettore.
In tal caso, l'ancoraggio viene creato in base a uno o più attributi univoci di un tipo di oggetto, nessuno dei quali viene modificato e che identifica in modo univoco l'oggetto nello spazio connettore (ad esempio, un numero dipendente o un ID utente).
Un oggetto spazio connettore può essere:
- Un oggetto di staging
- Un segnaposto
Oggetti di staging
Un oggetto di staging rappresenta un'istanza dei tipi di oggetto designati dall'origine dati connessa. Oltre al GUID e al nome distinto, un oggetto di staging ha sempre un valore che indica il tipo di oggetto.
Gli oggetti di staging importati hanno sempre un valore per l'attributo di ancoraggio. I nuovi oggetti di staging di cui è stato effettuato il provisioning e di cui è in corso la creazione nell'origine dati connessa non hanno un valore per l'attributo di ancoraggio.
Gli oggetti di staging includono anche i valori correnti degli attributi aziendali e le informazioni operative necessarie al motore di sincronizzazione per eseguire il processo di sincronizzazione. Le informazioni operative includono i flag che indicano il tipo di aggiornamenti inseriti temporaneamente nell'oggetto di staging. Se un oggetto di staging ha ricevuto nuove informazioni sull'identità dall'origine dati connessa che non sono ancora state elaborate, l'oggetto viene contrassegnato come pending import. Se un oggetto di staging ha nuove informazioni sull'identità che non sono ancora state esportate nell'origine dati connessa, l'oggetto viene contrassegnato come pending export.
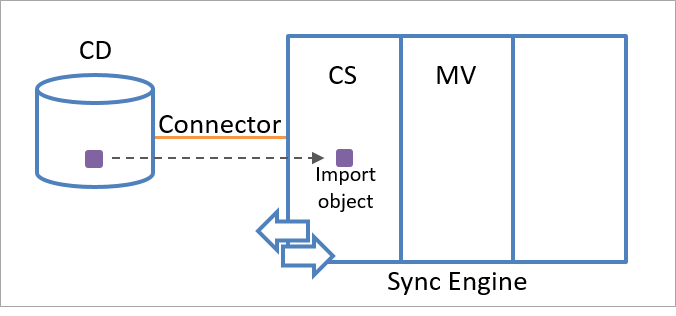
Un oggetto di staging può essere un oggetto di importazione o un oggetto di esportazione. Il motore di sincronizzazione crea un oggetto di importazione usando le informazioni sull'oggetto ricevute dall'origine dati connessa. Quando il motore di sincronizzazione riceve informazioni sull'esistenza di un nuovo oggetto che corrisponde a uno dei tipi di oggetto selezionati nel connettore, crea un oggetto di importazione nello spazio connettore come rappresentazione dell'oggetto nell'origine dati connessa.
La figura seguente illustra un oggetto di importazione che rappresenta un oggetto nell'origine dati connessa.
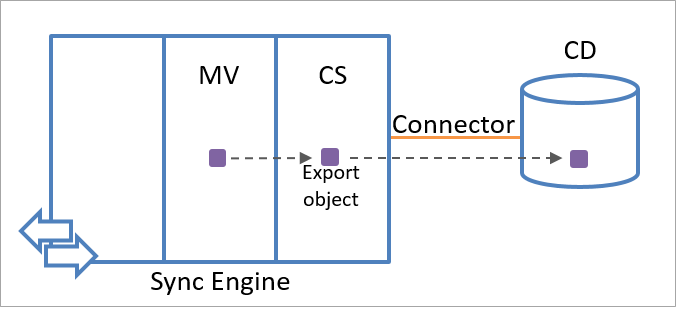
Il motore di sincronizzazione crea un oggetto di esportazione usando le informazioni sull'oggetto nel metaverse. Gli oggetti di esportazione vengono esportati nell'origine dati connessa durante la sessione di comunicazione successiva. Dal punto di vista del motore di sincronizzazione, gli oggetti di esportazione non esistono ancora nell'origine dati connessa. Quindi l'attributo di ancoraggio per un oggetto di esportazione non è disponibile. L'origine dati connessa, dopo avere ricevuto l'oggetto dal motore di sincronizzazione, crea un valore univoco per l'attributo di ancoraggio dell'oggetto.
La figura seguente illustra come viene creato un oggetto di esportazione usando le informazioni sull'identità nel metaverse.
Il motore di sincronizzazione conferma l'esportazione dell'oggetto reimportando l'oggetto dall'origine dati connessa. Gli oggetti di esportazione diventano oggetti di importazione quando il motore di sincronizzazione li riceve durante l'importazione successiva da tale origine dati connessa.
Segnaposto
Il motore di sincronizzazione usa uno spazio dei nomi flat per archiviare gli oggetti. Tuttavia, alcune origini dati connesse, ad esempio Active Directory, usano uno spazio dei nomi gerarchico. Per trasformare le informazioni da uno spazio dei nomi piatto in uno spazio dei nomi gerarchico, il motore di sincronizzazione usa i segnaposto per mantenere la gerarchia.
Ogni segnaposto rappresenta un componente (ad esempio, un'unità organizzativa) del nome gerarchico di un oggetto che non è stato importato nel motore di sincronizzazione, ma è necessario per costruire il nome gerarchico. Riempiono i vuoti creati dai riferimenti nell'origine dati connessa agli oggetti che non sono oggetti di staging nello spazio connettore.
Il motore di sincronizzazione usa i segnaposto anche per archiviare gli oggetti di riferimento che non sono ancora stati importati. Se, ad esempio, la sincronizzazione è configurata per includere l'attributo manager per l'oggetto Abbie Spencer e il valore ricevuto è un oggetto che non è ancora stato importato, come CN=Lee Sperry,CN=Users,DC=fabrikam,DC=com, le informazioni sul manager vengono archiviate come segnaposto nello spazio connettore. Se in seguito l'oggetto manager viene importato, l'oggetto segnaposto viene sovrascritto dall'oggetto di staging che rappresenta il manager.
Oggetti del metaverse
Un oggetto del metaverse contiene la visualizzazione aggregata offerta dal motore di sincronizzazione degli oggetti di staging nello spazio connettore. Il motore di sincronizzazione crea gli oggetti del metaverse usando le informazioni negli oggetti di importazione. Più oggetti dello spazio connettore possono essere collegati a un solo oggetto del metaverse, ma un oggetto dello spazio connettore non può essere collegato a più di un oggetto del metaverse.
Gli oggetti del metaverse non possono essere creati o eliminati manualmente. Il motore di sincronizzazione elimina automaticamente gli oggetti del metaverse senza un collegamento ad alcun oggetto nello spazio connettore.
Per eseguire il mapping degli oggetti in un'origine dati connessa a un tipo di oggetto corrispondente nel metaverse, il motore di sincronizzazione fornisce uno schema estendibile con un set predefinito di tipi di oggetto e di attributi associati. È possibile creare nuovi tipi di oggetto e attributi per gli oggetti del metaverse. Gli attributi possono essere a valore singolo o multivalore e i tipi di attributo possono essere stringhe, riferimenti, numeri e valori booleani.
Relazioni tra oggetti di staging e oggetti del metaverse
Nello spazio dei nomi del motore di sincronizzazione il flusso di dati è abilitato dalla relazione di collegamento tra oggetti di staging e oggetti del metaverse. Un oggetto di staging collegato a un oggetto del metaverse è chiamato oggetto unito (o oggetto connettore). Un oggetto di staging non collegato a un oggetto del metaverse è chiamato oggetto separato (o oggetto sezionatore). Si preferisce usare i termini unito e separato per non creare confusione con i connettori responsabili dell'importazione e dell'esportazione dei dati da una directory connessa.
I segnaposto non sono mai collegati a un oggetto del metaverse
Un oggetto unito è costituito da un oggetto di staging e dalle relazioni collegate a un singolo oggetto del metaverse. Gli oggetti uniti vengono usati per sincronizzare i valori degli attributi tra un oggetto dello spazio connettore e un oggetto del metaverse.
Quando un oggetto di staging diventa un oggetto unito durante la sincronizzazione, gli attributi possono scorrere tra l'oggetto di staging e l'oggetto del metaverse. Il flusso degli attributi è bidirezionale e viene configurato usando le regole di importazione degli attributi e le regole di esportazione degli attributi.
Un singolo oggetto dello spazio connettore può essere collegato a un solo oggetto del metaverse. Ogni oggetto del metaverse, tuttavia, può essere collegato a più oggetti dello spazio connettore nello stesso spazio connettore o in spazi connettore diversi, come illustrato nella figura seguente.
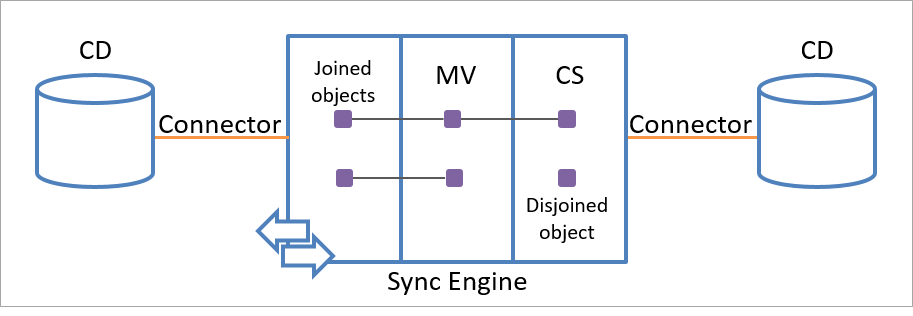
La relazione collegata tra l'oggetto di staging e un oggetto del metaverse è persistente e può essere rimossa solo dalle regole specificate.
Un oggetto separato è un oggetto di staging non collegato ad alcun oggetto del metaverse. I valori degli attributi di un oggetto separato non vengono elaborati ulteriormente nel metaverse. I valori degli attributi dell'oggetto corrispondente nell'origine dati connessa non vengono aggiornati dal motore di sincronizzazione.
Usando gli oggetti separati è possibile archiviare le informazioni sull'identità nel motore di sincronizzazione ed elaborarle in seguito. La presenza di un oggetto di staging come oggetto separato nello spazio connettore presenta diversi vantaggi. Poiché il sistema ha già inserito temporaneamente le informazioni richieste su questo oggetto, non è necessario creare di nuovo una rappresentazione dell'oggetto durante la successiva importazione dall'origine dati connessa. In questo modo, il motore di sincronizzazione ha sempre uno snapshot completo dell'origine dati connessa, anche se non è stata stabilita una connessione all'origine dati connessa. Gli oggetti separati possono essere convertiti in oggetti uniti e viceversa, a seconda delle regole specificate.
Un oggetto di importazione viene creato come oggetto separato. Un oggetto di esportazione deve essere un oggetto unito. La logica di sistema applica questa regola ed elimina ogni oggetto di esportazione che non sia un oggetto unito.
Processo di gestione delle identità del motore di sincronizzazione
Il processo di gestione delle identità controlla come vengono aggiornate le informazioni sull'identità tra origini dati connesse diverse. La gestione delle identità viene eseguita in tre processi:
- Import
- Sincronizzazione
- Esportazione
Durante il processo di importazione, il motore di sincronizzazione valuta le informazioni sull'identità in ingresso da un'origine dati connessa. Quando vengono rilevate modifiche, crea nuovi oggetti di staging o aggiorna quelli esistenti nello spazio connettore per la sincronizzazione.
Durante il processo di sincronizzazione, il motore di sincronizzazione aggiorna il metaverse rispecchiando le modifiche apportate nello spazio connettore e aggiorna lo spazio connettore rispecchiando le modifiche apportate nel metaverse.
Durante il processo di esportazione, il motore di sincronizzazione effettua il push delle modifiche inserite temporaneamente negli oggetti di staging e contrassegnate come pending export.
La figura seguente illustra dove avviene ogni processo mentre le informazioni sull'identità scorrono da un'origine dati connessa a un'altra.

Processo di importazione
Durante il processo di importazione, il motore di sincronizzazione valuta gli aggiornamenti alle informazioni sull'identità. Il motore di sincronizzazione confronta le informazioni sull'identità ricevute dall'origine dati connessa con le informazioni sull'identità di un oggetto di staging e determina se l'oggetto di staging richiede aggiornamenti. Se l'oggetto di staging deve essere aggiornato con nuovi dati, viene contrassegnato come pending import.
Inserendo temporaneamente gli oggetti di staging nello spazio connettore prima della sincronizzazione, il motore di sincronizzazione può elaborare solo le informazioni sull'identità modificate. Questo processo offre i vantaggi seguenti:
- Sincronizzazione efficiente. La quantità di dati elaborati durante la sincronizzazione viene ridotta al minimo.
- Risincronizzazione efficiente. È possibile modificare il modo in cui il motore di sincronizzazione elabora le informazioni sull'identità senza riconnettere il motore di sincronizzazione all'origine dati.
- Opportunità di visualizzare in anteprima la sincronizzazione. È possibile visualizzare in anteprima la sincronizzazione per verificare che i presupposti sul processo di gestione delle identità siano corretti.
Per ogni oggetto specificato nel connettore, il motore di sincronizzazione prima di tutto cerca di individuare una rappresentazione dell'oggetto nello spazio connettore del connettore. Il motore di sincronizzazione esamina tutti gli oggetti di staging nello spazio connettore e cerca di trovare un oggetto di staging correlato con un attributo di ancoraggio corrispondente. Se nessun oggetto di staging esistente ha un attributo di ancoraggio corrispondente, il motore di sincronizzazione cerca di trovare un oggetto di staging corrispondente con lo stesso nome distinto.
Quando il motore di sincronizzazione trova un oggetto di staging che corrisponde per il nome distinto, ma non per l'ancoraggio, si verifica il seguente particolare comportamento:
- Se l'oggetto che si trova nello spazio connettore non ha ancoraggi, il motore di sincronizzazione rimuove questo oggetto dallo spazio connettore e contrassegna l'oggetto del metaverse a cui è collegato come retry provisioning on next synchronization run. Quindi crea il nuovo oggetto di importazione.
- Se l'oggetto che si trova nello spazio connettore ha un ancoraggio, il motore di sincronizzazione presuppone che questo oggetto sia stato rinominato o eliminato nella directory connessa. Assegna un nuovo nome distinto temporaneo per l'oggetto dello spazio connettore per poter inserire temporaneamente l'oggetto in ingresso. Il vecchio oggetto diventa temporaneo, in attesa che il connettore importi l'operazione di ridenominazione o eliminazione per risolvere la situazione.
Gli oggetti temporanei non sono sempre un problema e potrebbero essere visualizzati anche in un ambiente integro. Con l'API endpoint Sync V2 di Microsoft Entra Connessione, gli oggetti temporanei devono essere risolti automaticamente nei cicli di sincronizzazione differenziali successivi. Un esempio comune in cui è possibile trovare oggetti temporanei generati si verifica nei server microsoft Entra Connessione installati in modalità di gestione temporanea, quando un amministratore elimina definitivamente un oggetto direttamente in Microsoft Entra ID usando PowerShell e successivamente sincronizza nuovamente l'oggetto.
Se il motore di sincronizzazione individua un oggetto di staging che corrisponde all'oggetto specificato nel connettore, determina la tipologia di modifiche da applicare. Ad esempio, il motore di sincronizzazione può rinominare o eliminare l'oggetto nell'origine dati connessa oppure solo aggiornare i valori degli attributi dell'oggetto.
Gli oggetti di staging con dati aggiornati vengono contrassegnati come pending import. Sono disponibili tipi di diversi di importazioni in sospeso. A seconda del risultato del processo di importazione, un oggetto di staging nello spazio connettore ha uno dei tipi di importazione in sospeso seguenti:
- Nessuno. Non sono disponibili modifiche a nessuno degli attributi dell'oggetto di staging. Il motore di sincronizzazione non contrassegna questo tipo come importazione in sospeso.
- Add. L'oggetto di staging è un nuovo oggetto di importazione nello spazio connettore. Il motore di sincronizzazione contrassegna questo tipo come importazione in sospeso per un'ulteriore elaborazione nel metaverse.
- Aggiornamento. Il motore di sincronizzazione trova un oggetto di staging corrispondente nello spazio connettore e contrassegna questo tipo come importazione in sospeso in modo che gli aggiornamenti agli attributi possano essere elaborati nel metaverse. Gli aggiornamenti includono la ridenominazione degli oggetti.
- Elimina. Il motore di sincronizzazione trova un oggetto di staging corrispondente nello spazio connettore e contrassegna questo tipo come importazione in sospeso in modo che l'oggetto unito possa essere eliminato.
- Delete/Add. Il motore di sincronizzazione trova un oggetto di staging corrispondente nello spazio connettore, ma i tipi di oggetto non corrispondono. In questo caso, viene inserita temporaneamente una modifica di eliminazione/aggiunta. Una modifica di eliminazione/aggiunta indica al motore di sincronizzazione che deve essere eseguita una risincronizzazione completa di questo oggetto perché, quando il tipo di oggetto verrà modificato, a questo oggetto verranno applicati set di regole diversi.
Impostando lo stato di importazione in sospeso di un oggetto di staging, è possibile ridurre considerevolmente la quantità di dati elaborati durante la sincronizzazione perché in questo modo il sistema può elaborare solo gli oggetti con dati aggiornati.
Processo sincronizzazione
La sincronizzazione è costituita da due processi correlati:
- Sincronizzazione in ingresso, quando il contenuto del metaverse viene aggiornato usando i dati nello spazio connettore.
- Sincronizzazione in uscita, quando il contenuto dello spazio connettore viene aggiornato usando i dati nel metaverse.
Usando le informazioni gestite nello spazio connettore, il processo di sincronizzazione in ingresso crea una visualizzazione integrata dei dati nel metaverse archiviato nelle origini dati connesse. Vengono aggregati tutti gli oggetti di staging o solo quelli con informazioni di importazione in sospeso, a seconda di come vengono configurate le regole.
Il processo di sincronizzazione in uscita aggiorna gli oggetti di esportazione quando gli oggetti del metaverse vengono modificati.
La sincronizzazione in ingresso crea nel metaverse la visualizzazione integrata delle informazioni sull'identità ricevute dalle origini dati connesse. Il motore di sincronizzazione può elaborare le informazioni sull'identità in qualsiasi momento usando le informazioni sull'identità più recenti disponibili nell'origine dati connessa.
Sincronizzazione in ingresso
La sincronizzazione in ingresso include i processi seguenti:
- Provision (chiamato anche proiezione se è importante distinguere questo processo dal provisioning della sincronizzazione in uscita). Il motore di sincronizzazione crea un nuovo oggetto del metaverse basato su un oggetto di staging e li collega. Il provisioning è un'operazione a livello di oggetto.
- Join. Il motore di sincronizzazione collega un oggetto di staging a un oggetto del metaverse esistente. Un join è un'operazione a livello di oggetto.
- Importazione del flusso degli attributi. Il motore di sincronizzazione aggiorna i valori degli attributi, chiamati flusso degli attributi, dell'oggetto nel metaverse. L'importazione del flusso degli attributi è un'operazione a livello di attributo che richiede un collegamento tra un oggetto di staging e un oggetto del metaverse.
Il provisioning è il solo processo che crea oggetti nel metaverse. Il provisioning ha effetto solo sugli oggetti di importazione che sono oggetti separati. Durante il provisioning, il motore di sincronizzazione crea un oggetto del metaverse che corrisponde al tipo di oggetto dell'oggetto di importazione e stabilisce un collegamento tra entrambi gli oggetti, creando in tal modo un oggetto unito.
Anche il processo di join stabilisce un collegamento tra gli oggetti di importazione e un oggetto del metaverse. La differenza tra il join e il provisioning è che il processo di join richiede che l'oggetto di importazione sia collegato a un oggetto del metaverse esistente, mentre il processo di provisioning crea un nuovo oggetto del metaverse.
Il motore di sincronizzazione cerca di aggiungere un oggetto di importazione a un oggetto del metaverse usando i criteri specificati nella configurazione delle regole di sincronizzazione.
Durante i processi di provisioning e di join, il motore di sincronizzazione collega un oggetto separato a un oggetto del metaverse e in questo modo li unisce. Al termine di queste operazioni a livello di oggetto, il motore di sincronizzazione può aggiornare i valori degli attributi dell'oggetto del metaverse associato. Questo processo viene chiamato importazione del flusso degli attributi.
L'importazione del flusso degli attributi viene eseguita su tutti gli oggetti di importazione contenenti nuovi dati e collegati a un oggetto del metaverse.
Sincronizzazione in uscita
La sincronizzazione in uscita aggiorna gli oggetti di esportazione quando un oggetto del metaverse viene modificato, ma non eliminato. L'obiettivo della sincronizzazione in uscita è valutare se le modifiche agli oggetti del metaverse richiedono aggiornamenti agli oggetti di staging negli spazi connettore. In alcuni casi, le modifiche possono richiedere che vengano aggiornati gli oggetti di staging in tutti gli spazi connettore. Gli oggetti di staging modificati vengono contrassegnati come pending export e in questo modo diventano oggetti di esportazione. In seguito, durante il processo di esportazione, viene eseguito il push di questi oggetti di esportazione nell'origine dati connessa.
La sincronizzazione in uscita include tre processi:
- Provisioning
- Deprovisioning
- Esportazione del flusso degli attributi
Il provisioning e il deprovisioning sono entrambi operazioni a livello di oggetto. Il deprovisioning dipende dal provisioning perché solo il provisioning può avviarlo. Il deprovisioning viene attivato quando il provisioning rimuove il collegamento tra un oggetto del metaverse e un oggetto di esportazione.
Il provisioning viene sempre attivato quando vengono applicate modifiche agli oggetti nel metaverse. Quando vengono apportate modifiche agli oggetti del metaverse, il motore di sincronizzazione può eseguire tutte le attività seguenti durante il processo di provisioning:
- Creare oggetti uniti, dove un oggetto del metaverse viene collegato a un nuovo oggetto di esportazione creato.
- Rinominare un oggetto unito.
- Separare i collegamenti tra un oggetto del metaverse e gli oggetti di staging, creando un oggetto separato.
Se il provisioning richiede al motore di sincronizzazione di creare un nuovo oggetto connettore, l'oggetto di staging a cui l'oggetto del metaverse è collegato è sempre un oggetto di esportazione, perché l'oggetto non esiste ancora nell'origine dati connessa.
Se il provisioning richiede al motore di sincronizzazione di separare un oggetto unito, creando un oggetto separato, viene attivato il deprovisioning. Il processo di deprovisioning elimina l'oggetto.
Durante il deprovisioning, l'eliminazione di un oggetto di esportazione non comporta l'eliminazione fisica dell'oggetto. L'oggetto viene contrassegnato come deleted, a indicare che l'operazione di eliminazione viene inserita temporaneamente nell'oggetto.
L'esportazione del flusso degli attributi viene eseguita anche durante il processo di sincronizzazione in uscita, analogamente a come l'importazione del flusso degli attributi viene eseguita durante la sincronizzazione in ingresso. L'esportazione del flusso dagli attributi viene eseguita solo tra gli oggetti del metaverse e di esportazione uniti.
Processo di esportazione
Durante il processo di esportazione, il motore di sincronizzazione esamina tutti gli oggetti di esportazione contrassegnati come pending export nello spazio connettore e quindi invia gli aggiornamenti all'origine dati connessa.
Il motore di sincronizzazione può determinare la riuscita di un'operazione di esportazione, ma non riesce a determinare che il processo di gestione delle identità è stato completato. Gli oggetti nell'origine dati connessa possono sempre essere modificati da altri processi. Poiché il motore di sincronizzazione non ha una connessione persistente all'origine dati connessa, non è sufficiente fare ipotesi sulle proprietà di un oggetto nell'origine dati connessa basandosi solo su una notifica di esportazione riuscita.
Ad esempio, un processo nell'origine dati connessa può reimpostare gli attributi dell'oggetto sui valori originali, ovvero l'origine dati connessa può sovrascrivere i valori subito dopo il push dei dati da parte del motore di sincronizzazione e l'applicazione dei dati stessi nell'origine dati connessa.
Il motore di sincronizzazione archivia le informazioni sullo stato dell'importazione e dell'esportazione di ogni oggetto di staging. Se i valori degli attributi specificati nell'elenco di inclusione degli attributi sono stati modificati dopo l'ultima esportazione, l'archiviazione dello stato dell'importazione e dell'esportazione consente al motore di sincronizzazione di reagire in modo appropriato. Il motore di sincronizzazione usa il processo di importazione per confermare i valori degli attributi esportati nell'origine dati connessa. Un confronto tra le informazioni importate e quelle esportate, come illustrato nella figura seguente, consente al motore di sincronizzazione di determinare se l'esportazione è riuscita o se è necessario ripeterla.
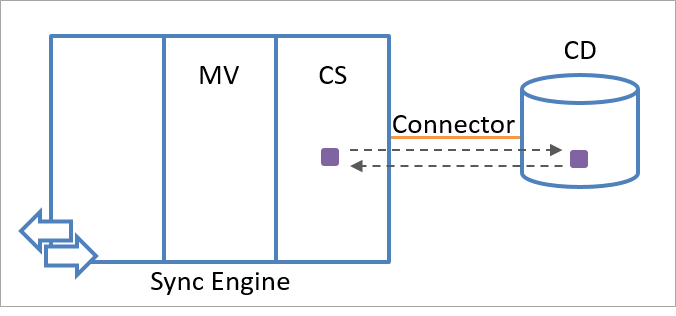
Il motore di sincronizzazione, ad esempio, se esporta l'attributo C, che ha valore 5, in un'origine dati connessa, archivia C=5 nella memoria degli stati di esportazione. Ogni ulteriore esportazione eseguita su questo oggetto comporta un tentativo di esportare di nuovo C=5 nell'origine dati connessa perché il motore di sincronizzazione presuppone che questo valore non sia stato applicato in modo persistente all'oggetto (a meno che di recente non sia stato importato un valore diverso dall'origine dati connessa). La memoria di esportazione viene cancellata quando C=5 viene ricevuto durante un'operazione di importazione eseguita sull'oggetto.
Passaggi successivi
Altre informazioni sulla configurazione di Microsoft Entra Connessione Sync.
Altre informazioni sull'integrazione delle identità locali con Microsoft Entra ID.