Questo articolo presenta un albero delle decisioni ed esempi di opzioni di disponibilità elevata e ripristino di emergenza quando si distribuiscono app IaaS (infrastruttura distribuita come servizio) multilivello in Azure.
Architettura
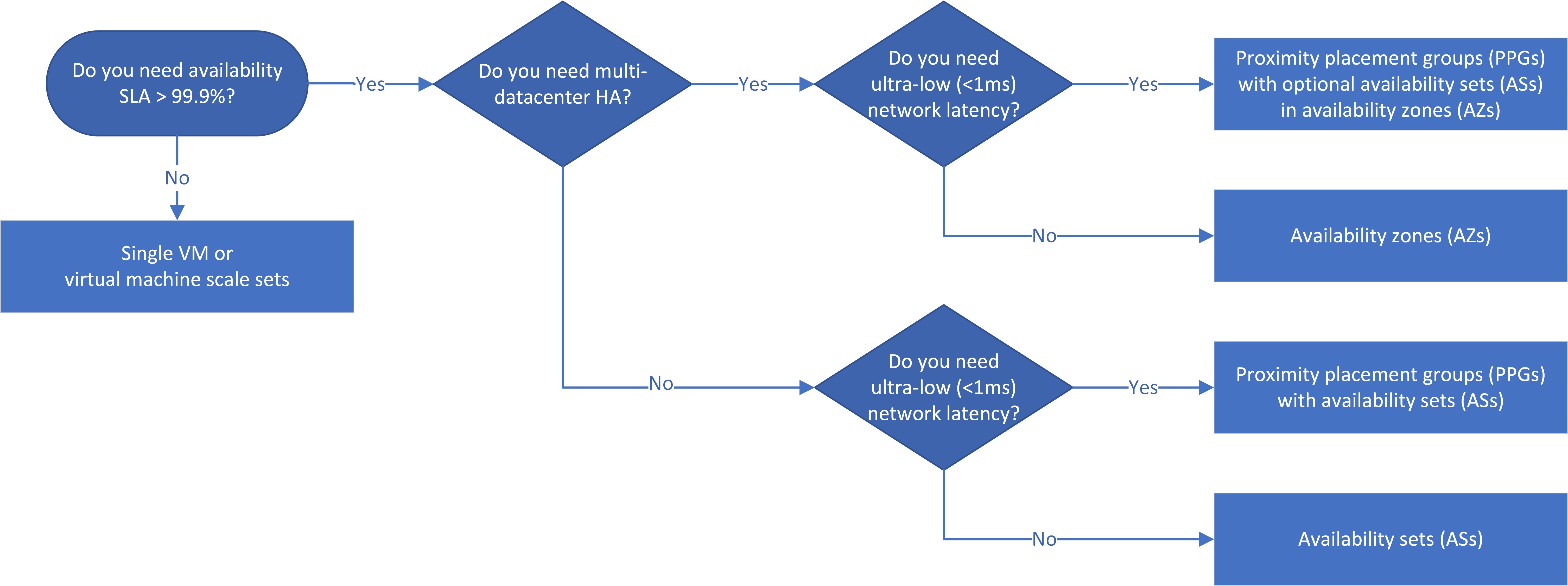
Workflow
I set di disponibilità forniscono ridondanza e disponibilità delle macchine virtuali all'interno di un data center distribuendo le macchine virtuali tra più nodi hardware isolati. Un subset di macchine virtuali rimane in esecuzione durante i tempi di inattività pianificati o non pianificati, quindi l'intera app rimane disponibile e operativa.
Le zone di disponibilità sono località fisiche univoche che si estendono su data center all'interno di un'area di Azure. Ogni zona di disponibilità accede a uno o più data center con alimentazione, raffreddamento e rete indipendenti e ogni area di Azure abilitata per le zone di disponibilità ha almeno tre zone di disponibilità separate. La separazione fisica delle zone di disponibilità all'interno di un'area protegge le macchine virtuali distribuite da errori del data center.
Il diagramma di flusso decisionale riflette il principio secondo cui le app a disponibilità elevata devono usare le zone di disponibilità, se possibile. Tra zone e quindi tra data center, la disponibilità elevata offre un contratto di servizio > del 99,99% a causa della resilienza agli errori del data center.
Non è garantito che i set e le zone di disponibilità per livelli di app diversi siano all'interno degli stessi data center. Se la latenza dell'app è un problema di primaria importanza, è consigliabile spostare i servizi in un singolo data center usando i gruppi di posizionamento di prossimità con set e zone di disponibilità.
Componenti
Alternative
In alternativa al ripristino di emergenza a livello di area tramite Azure Site Recovery, se l'app può replicare i dati in modo nativo, è possibile implementare il ripristino di emergenza in più aree usando server hot/cold standby, ad esempio un cluster esteso per il solo ripristino di emergenza. Questa alternativa non è illustrata in modo specifico negli esempi, ma può essere aggiunta a una qualsiasi delle soluzioni. Si noti che la replica tra aree è asincrona e si prevede una perdita di dati.
In alternativa, se si dispone della propria tecnologia di replica dei dati, è possibile usarla per creare una zona secondaria nell'area per il ripristino di emergenza. A seconda dell'area dei carichi di lavoro, potrebbe anche essere possibile usare Azure Site Recovery per replicare gli elementi in una zona alternativa, è possibile controllare la disponibilità a livello di area e altre informazioni su questa funzionalità in Abilitare il ripristino di emergenza da zona a zona per le macchine virtuali di Azure.
La disponibilità elevata tra più aree è possibile, ma richiede un servizio di bilanciamento del carico globale, ad esempio Frontdoor o Gestione traffico. Per altre informazioni, vedere Eseguire un'applicazione a più livelli in più aree di Azure per una disponibilità elevata.
Dettagli dello scenario
Le architetture multilivello o a più livelli sono comuni nelle app locali tradizionali, quindi rappresentano una scelta naturale per la migrazione delle app locali al cloud o per lo sviluppo di app per ambienti locali e cloud. Le architetture a più livelli vengono in genere implementate come app IaaS suddivise in livelli logici e fisici, con un livello Web o presentazione superiore, un livello aziendale intermedio e un livello dati.
In un'app IaaS a più livelli, ogni livello viene eseguito in un set separato di macchine virtuali. I livelli Web e aziendale sono senza stato, ovvero qualsiasi macchina virtuale nel livello può gestire qualsiasi richiesta per tale livello. Il livello dati è un database replicato, un archivio oggetti o un archivio file. Più macchine virtuali in ogni livello offrono resilienza in caso di errore di una macchina virtuale e i servizi di bilanciamento del carico distribuiscono le richieste tra le macchine virtuali.
È possibile scalare orizzontalmente i livelli aggiungendo altre macchine virtuali ai pool e usare i set di scalabilità di macchine virtuali per aumentare le istanze di macchine virtuali identiche automaticamente. Poiché si usano i servizi di bilanciamento del carico, è possibile scalare orizzontalmente i livelli senza influire sul tempo di attività dell'app.
Se il contratto di servizio per un'app IaaS richiede una disponibilità > del 99%, è possibile inserire le macchine virtuali in set di disponibilità, zone di disponibilità di disponibilità e gruppi di posizionamento di prossimità per configurare la disponibilità elevata per l'app. Le soluzioni di disponibilità elevata e ripristino di emergenza selezionate dipendono dal contratto di servizio, dalle considerazioni sulla latenza e dai requisiti di ripristino di emergenza a livello di area richiesti.
Potenziali casi d'uso
- Eseguire la migrazione di un'app a più livelli dall'ambiente locale al cloud.
- Distribuire un'app a più livelli sia in locale che nel cloud.
- Configurare la disponibilità elevata e il ripristino di emergenza per app IaaS.
Questa soluzione può essere usata per qualsiasi settore, inclusi gli scenari seguenti:
- Applicazioni del settore pubblico
- Banche (settore finanziario)
- Settore sanitario
Considerazioni
Le zone di disponibilità non sono disponibili in tutte le aree di Azure.
Decidere quale opzione di distribuzione si vuole usare prima di compilare la soluzione. Anche se possibile, non è facile passare da un'opzione a un'altra dopo la distribuzione. È necessario eliminare le macchine virtuali e ricrearle dai dischi gestiti sottostanti, che è un processo più impegnativo.
Assicurarsi di poter eseguire il mapping dell'applicazione alla soluzione selezionata. Molti modelli e progettazioni di resilienza a livello di app non sono nell'ambito di questo albero delle decisioni.
Tre scenari possono causare il riavvio delle macchine virtuali di Azure: manutenzione hardware non pianificata, tempi di inattività imprevisti e manutenzione pianificata. Per altre informazioni su questi eventi e sulle procedure consigliate di disponibilità elevata per ridurre l'impatto, vedere Informazioni su riavvii, manutenzione e tempi di inattività delle macchine virtuali.
Macchine virtuali singole
Se un'app non richiede una disponibilità > del 99,9%, non è necessario configurarla per la disponibilità elevata ed è possibile distribuire macchine virtuali singole. È possibile usare i set di scalabilità di macchine virtuali per aumentare automaticamente le istanze di macchine virtuali identiche. Distribuire singole macchine virtuali senza specificare una zona, in modo che siano distribuite in un'area. Queste app hanno un contratto di servizio del 99,9% se si usano i dischi SSD Premium di Azure.
Le singole macchine virtuali usano la funzionalità di correzione del servizio predefinita integrata in tutti i data center di Azure. Per gli errori prevedibili, questa funzionalità usa in genere la migrazione in tempo reale, ma durante eventi imprevedibili, le macchine virtuali potrebbero essere riavviate o rese non disponibili.
Disponibilità elevata
Se l'app richiede un contratto di servizio > del 99,9%, progettare l'app per la disponibilità elevata. Usare le zone di disponibilità, se possibile, perché forniscono la tolleranza di errore del data center. È possibile usare i set invece delle zone di disponibilità, ma l'uso di set di disponibilità riduce la disponibilità dal 99,99% al 99,95%, perché i set di disponibilità non possono tollerare gli errori del data center.
Le zone di disponibilità sono adatte per molti scenari di app in cluster, inclusi i cluster di SQL AlwaysOn, che usano i livelli attivo-attivo, attivo-passivo o una combinazione di entrambi i livelli di disponibilità elevata a ogni livello con failover rapido. La replica sincrona è possibile tra qualsiasi nodo del sistema di gestione di database, grazie alla bassa latenza della rete tra più zone. È anche possibile eseguire una configurazione di cluster esteso tra zone, con una latenza più elevata e che supporta la replica asincrona.
Se si vuole usare un arbitro del cluster basato su macchine virtuali, ad esempio un controllo di condivisione file, posizionarlo nella terza zona di disponibilità, per assicurarsi di non perdere il quorum in caso di errore di una zona. In alternativa, è possibile usare un controllo basato sul cloud in un'altra area.
Tutte le macchine virtuali in una zona di disponibilità sono in un singolo dominio di errore e di aggiornamento, ovvero condividono una fonte di alimentazione e un commutatore di rete comuni e possono essere tutte riavviate contemporaneamente. Se si creano macchine virtuali tra diverse zone di disponibilità, le macchine virtuali vengono distribuite in modo efficace tra diversi domini di errore e di aggiornamento, in modo che non restituiscano errore o si riavviino tutte contemporaneamente. Se si vogliono avere macchine virtuali ridondanti in zona e macchine virtuali tra zone, è consigliabile inserire le macchine virtuali in zona in set di disponibilità in gruppi di posizionamento di prossimità, per assicurarsi che non verranno riavviate tutte contemporaneamente. Anche per i carichi di lavoro di macchine virtuali a istanza singola che non sono attualmente ridondanti è comunque possibile usare i set di disponibilità nei gruppi di posizionamento di prossimità, per consentirne la crescita e la flessibilità in futuro.
Per la distribuzione di set di scalabilità di macchine virtuali tra zone di disponibilità, è consigliabile usare la modalità di orchestrazione, attualmente in anteprima pubblica, che consente la combinazione di domini di errore e zone di disponibilità.
Le zone di disponibilità con gruppi di posizionamento di prossimità all'interno della zona consentono una delle latenze di rete più basse in Azure e un contratto di servizio di almeno il 99,99% a causa della resilienza di più data center. Se possibile, usare la rete accelerata nelle macchine virtuali.
Questa soluzione può presentare uno scenario in cui un servizio in esecuzione in una macchina virtuale in una zona deve interagire con un servizio in un'altra zona. Ad esempio, potrebbe essere presente un livello Web attivo-attivo e un livello di database attivo-passivo tra le zone. Alcune richieste attraverseranno le zone, introducendo la latenza. Anche se la latenza tra zone è ancora molto bassa, se è necessario garantire la latenza più bassa possibile, mantenere tutte le comunicazioni di rete tra i livelli dell'app all'interno di una zona.
Considerazioni sulla latenza
La latenza di rete dipende, tra le altre cose, dalla distanza fisica tra le macchine virtuali distribuite. Se un'app richiede una latenza molto bassa tra i livelli, è possibile distribuirla in un singolo data center, usando un gruppo di posizionamento di prossimità con set di scalabilità per ogni livello. Se possibile, usare la rete accelerata nelle macchine virtuali. Questo scenario consente una delle latenze di rete più basse in Azure e un contratto di servizio del 99,95%.
Per ottenere informazioni più dettagliate sulle condizioni di latenza in un'ampia gamma di scenari, è possibile usare gli strumenti seguenti:
- Per testare la latenza tra le macchine virtuali, vedere Testare la latenza di rete delle macchine virtuali.
- Per testare la latenza tra le zone, usare AvZone-Latency-Test. Questo test consente di determinare quali zone logiche hanno la latenza più bassa per la sottoscrizione.
- Per testare la latenza tra aree di Azure, usare http://www.azurespeed.com/. Questo strumento aggiornato regolarmente può essere utile quando si prende in considerazione la replica asincrona tra aree.
Ripristino di emergenza
Le considerazioni sul ripristino di emergenza includono la disponibilità, la capacità dell'app di mantenere l'esecuzione in uno stato di integrità, la durabilità dei dati e la conservazione dei dati in caso di emergenza.
Il failover a disponibilità elevata deve essere veloce, senza perdita di dati e avere un effetto molto limitato sul servizio. Al contrario, un failover di ripristino di emergenza tradizionale potrebbe avere un obiettivo del tempo di ripristino (RTO) e un obiettivo del punto di ripristino (RPO) associato più a lungo ed è asincrono, con potenziale perdita di dati.
È possibile sfruttare le zone di disponibilità sia per la disponibilità elevata che per il ripristino di emergenza usando una zona di disponibilità diversa per la soluzione di ripristino di emergenza. Le zone di disponibilità sono sufficienti per avere connessioni a bassa latenza ad altre zone di disponibilità (latenza round trip di meno di 2 ms). Tuttavia, sono abbastanza distanti per ridurre la probabilità che interruzioni locali o meteo possano influire su più zone di disponibilità. Per i carichi di lavoro cruciali, è consigliabile prendere in considerazione una soluzione che usa più aree oltre a più zone di disponibilità.
Azure Site Recovery consente di replicare le macchine virtuali in un'altra area di Azure per il ripristino di emergenza a livello di area e la continuità aziendale. È possibile usare Azure Site Recovery per ripristinare le app in caso di interruzioni dell'area di origine o per eseguire esercitazioni periodiche sul ripristino di emergenza per assicurarsi di soddisfare i requisiti di conformità.
Se l'app supporta Azure Site Recovery, è possibile fornire una soluzione di ripristino di emergenza a livello di area per una maggiore protezione, se la criticità dell'app lo richiede. Tuttavia, la sola disponibilità elevata tra più data center potrebbe essere sufficiente, perché se un'app è completamente resiliente agli errori del data center, non dovrebbero esserci tempi di inattività o perdita di dati.
Ottimizzazione dei costi
Non sono previsti costi aggiuntivi per le macchine virtuali distribuite in zone di disponibilità. Potrebbero essere previsti costi aggiuntivi per il trasferimento dei dati tra MACCHINE virtuali e macchine virtuali. Per altre informazioni, vedere la pagina Prezzi di Larghezza di banda.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Shaun Croucher | Consulente senior
Passaggi successivi
- Set di disponibilità
- Zone di disponibilità
- Set di scalabilità di macchine virtuali
- Abilitare il ripristino di emergenza da zona a zona per le macchine virtuali di Azure
Risorse correlate
- Stile dell'architettura a più livelli
- Applicazione Web multilivello per disponibilità elevata e ripristino di emergenza in Azure
- Eseguire un'applicazione Web con ridondanza della zona per la disponibilità elevata
- Eseguire un'applicazione Web in più aree di Azure per una disponibilità elevata
- Eseguire un'applicazione a più livelli in più aree di Azure per una disponibilità elevata