Che cos'è sincronizzazione dati SQL per Azure?
Si applica a:![]() Database SQL di Azure
Database SQL di Azure
La sincronizzazione dati SQL è un servizio basato su Database SQL di Azure che sincronizza i dati selezionati bidirezionalmente tra più database, sia locali che nel cloud.
Importante
Al momento, la sincronizzazione dati SQL di Azure non supporta Istanza gestita di SQL di Azure o Azure Synapse Analytics.
Panoramica
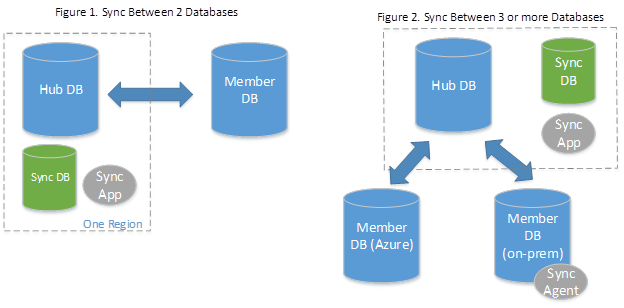
La sincronizzazione dati si basa sul concetto di gruppo di sincronizzazione. Un gruppo di sincronizzazione è un gruppo di database che si vuole sincronizzare.
La sincronizzazione dati usa una topologia hub-spoke per sincronizzare i dati. Uno dei database nel gruppo di sincronizzazione viene definito come database hub. Il resto dei database sono database membri. La sincronizzazione si verifica solo tra l'hub e i singoli membri.
- Il database hub deve essere un database SQL di Azure.
- I database membri possono essere database in database SQL di Azure o in istanze di SQL Server.
- Il database dei metadati di sincronizzazione contiene i metadati e il log per la sincronizzazione dati. Il database dei metadati di sincronizzazione deve essere un database SQL di Azure situato nella stessa area del database hub. Il database dei metadati di sincronizzazione viene creato dal cliente ed è di sua proprietà. È possibile avere un solo database dei metadati di sincronizzazione per area e sottoscrizione. Il database dei metadati di sincronizzazione non può essere eliminato o rinominato mentre esistono gruppi o agenti di sincronizzazione. Microsoft consiglia di creare un nuovo database vuoto da usare come Database dei metadati di sincronizzazione. La sincronizzazione dati crea tabelle in questo database ed esegue un carico di lavoro frequente.
Nota
Se si usa un database locale come database membro, è necessario installare e configurare un agente di sincronizzazione locale.
Di seguito sono elencate le proprietà di un gruppo di sincronizzazione:
- Lo schema di sincronizzazione descrive i dati da sincronizzare.
- La direzione di sincronizzazione può essere bidirezionale o unidirezionale. Ovvero, la direzione di sincronizzazione può essere dall'hub al membro o dal membro all'hub oppure entrambe.
- L'intervallo di sincronizzazione descrive la frequenza con cui viene eseguita la sincronizzazione.
- I criteri di risoluzione dei conflitti sono criteri a livello di gruppo e le impostazioni possono essere Priorità hub o Priorità client.
Quando utilizzare
La sincronizzazione dati è utile quando i dati devono essere mantenuti aggiornati in diversi database in Database SQL di Azure o SQL Server. Questi sono i principali casi d'uso per la sincronizzazione dati:
- Sincronizzazione dei dati ibrida: con la sincronizzazione dei dati è possibile mantenere i dati sincronizzati tra i database in SQL Server e database SQL di Azure per rendere possibili applicazioni ibride. Questa funzionalità può essere interessante per i clienti che stanno valutando il passaggio al cloud e vorrebbero trasferire alcune applicazioni in Azure.
- Applicazioni distribuite: in molti casi è vantaggioso separare carichi di lavoro diversi in database differenti. Ad esempio, se si dispone di un database di produzione di grandi dimensioni, ma è anche necessario eseguire un carico di lavoro di report o analisi su tali dati, può essere utile avere un secondo database per questo carico di lavoro aggiuntivo. Questo approccio riduce al minimo l'impatto a livello di prestazioni sul carico di lavoro di produzione. È possibile usare la sincronizzazione dati per mantenere sincronizzati i due database.
- Applicazioni distribuite a livello globale: molte aziende sono estese a più aree, a volte anche in paesi diversi. Per ridurre al minimo la latenza di rete, è consigliabile posizionare i dati in un'area vicina. Con sincronizzazione dati è possibile mantenere facilmente sincronizzati i database in aree in tutto il mondo.
La sincronizzazione dati non è la soluzione preferita per gli scenari seguenti:
| Scenario | Alcune soluzioni raccomandate |
|---|---|
| Ripristino di emergenza | Backup con ridondanza geografica di Azure |
| Scalabilità in lettura | Utilizzo di repliche di sola lettura per bilanciare il carico dei carichi di lavoro di query di sola lettura |
| ETL (da OLTP a OLAP) | Azure Data Factory o SQL Server Integration Services |
| Migrazione da SQL Server al database SQL di Azure. Tuttavia, è possibile usare sincronizzazione dati SQL dopo il completamento della migrazione per assicurarsi che l'origine e la destinazione vengano mantenute sincronizzate. | Servizio Migrazione del database di Azure |
Funzionamento
- Rilevamento delle modifiche ai dati: sincronizzazione dati tiene traccia delle modifiche tramite trigger di inserimento, aggiornamento ed eliminazione. Le modifiche vengono registrate in una tabella laterale nel database utente. Si noti che BULK INSERT non attiva i trigger per impostazione predefinita. Se non si specifica FIRE_TRIGGERS, non viene eseguito alcun trigger di inserimento. Aggiungere l'opzione FIRE_TRIGGERS in modo che la sincronizzazione dei dati possa tenere traccia di tali inserimenti.
- Sincronizzazione dei dati: il servizio di sincronizzazione dati è progettato in base a un modello hub-spoke. L'hub sincronizza singolarmente ogni membro. Le modifiche dall'hub vengono scaricate nel membro e quindi le modifiche dal membro vengono caricate nell'hub.
- Risoluzione dei conflitti: sincronizzazione dati offre due opzioni per la risoluzione dei conflitti, ovvero Priorità hub o Priorità client.
- Se si seleziona Priorità hub, le modifiche nell'hub sovrascrivono sempre le modifiche nel membro.
- Se si seleziona Priorità client, le modifiche nel membro sovrascrivono sempre le modifiche nell'hub. In presenza di più di un membro, il valore finale dipende dal membro sincronizzato per primo.
Confronto con la replica transazionale
| Sincronizzazione dei dati | Replica transazionale | |
|---|---|---|
| Vantaggi | - Supporto attivo/attivo - Bidirezionale tra database locali e database SQL di Azure |
- Latenza inferiore - Coerenza delle transazioni - Riutilizzo topologia esistente dopo la migrazione - Supporto per Istanza gestita di SQL di Azure |
| Svantaggi | - Nessuna coerenza delle transazioni - Maggiore impatto sulle prestazioni |
- Impossibilità di pubblicare da Database SQL di Azure - Alti costi di manutenzione |
Collegamento privato per sincronizzazione dati
Nota
Il collegamento privato sincronizzazione dati SQL è diverso dal collegamento privato di Azure.
La nuova funzionalità collegamento privato consente di scegliere un endpoint privato gestito dal servizio per stabilire una connessione sicura tra il servizio di sincronizzazione e i database membri/hub durante il processo di sincronizzazione dei dati. Un endpoint privato gestito dal servizio è un indirizzo IP privato all'interno di una rete virtuale e di una subnet specifiche. All'interno di sincronizzazione dati, l'endpoint privato gestito dal servizio viene creato da Microsoft e viene usato esclusivamente dal servizio di sincronizzazione dati per una determinata operazione di sincronizzazione.
Prima di configurare il collegamento privato, leggere i requisiti generali per la funzionalità.

Nota
È necessario approvare manualmente l'endpoint privato gestito dal servizio, nella pagina Connessioni a endpoint privato del portale di Azure durante la distribuzione del gruppo di sincronizzazione o usando PowerShell.
Operazioni preliminari
Configurare la sincronizzazione dati nel portale di Azure
- Configurare la sincronizzazione dati SQL
- Agente di sincronizzazione dei dati: Agente di sincronizzazione dei dati per la sincronizzazione dati SQL di Azure
Configurare la sincronizzazione dati con PowerShell
- Usare PowerShell per effettuare la sincronizzazione tra più database nel database SQL di Azure
- Usare PowerShell: Usare PowerShell per eseguire la sincronizzazione tra un database SQL di Azure e un database in un’istanza di SQL Server
Configurare sincronizzazione dati con l'API REST
Rivedere le procedure consigliate per la sincronizzazione dati
Nel caso in cui si siano verificati problemi
Coerenza e prestazioni
Coerenza finale
Dato che la sincronizzazione dati è basata su trigger, la coerenza delle transazioni non è garantita. Microsoft garantisce che tutte le modifiche vengono apportate alla fine e che la sincronizzazione dati non causi perdite di dati.
Impatto sulle prestazioni
La sincronizzazione dati usa trigger di inserimento, aggiornamento ed eliminazione per il rilevamento delle modifiche e crea tabelle laterali nel database utente per il rilevamento delle modifiche. Queste attività di rilevamento delle modifiche hanno un impatto sul carico di lavoro del database. Valutare il livello di servizio e aggiornare se necessario.
Sulle prestazioni del database possono incidere anche il provisioning e il deprovisioning eseguiti durante la creazione, l'aggiornamento e l'eliminazione dei gruppi di sincronizzazione.
Requisiti e limitazioni
Requisiti generali
- Ogni tabella deve avere una chiave primaria. Non modificare il valore della chiave primaria in alcuna riga. Se è necessario modificare un valore della chiave primaria, eliminare la riga e ricrearla con il nuovo valore della chiave primaria.
Importante
La modifica del valore di una chiave primaria esistente comporterà il comportamento difettoso seguente:
- I dati tra hub e membro possono essere persi anche se la sincronizzazione non segnala alcun problema.
- La sincronizzazione può non riuscire perché la tabella di rilevamento ha una riga non esistente dall'origine a causa della modifica della chiave primaria.
L'isolamento dello snapshot deve essere abilitato sia per i membri di sincronizzazione che per l'hub. Per altre informazioni, vedere Isolamento dello snapshot in SQL Server.
Per usare il link privato della sincronizzazione di dati, sia i database hub che i database membri devono essere ospitati in Azure, in aree identiche o diverse, e nello stesso tipo di cloud, ad esempio entrambi nel cloud pubblico o entrambi nel cloud per enti pubblici. Inoltre, per usare il collegamento privato, i provider di risorse
Microsoft.Networkdevono essere registrati per le sottoscrizioni che ospitano l'hub e i server membri. Infine, è necessario approvare manualmente il collegamento privato per sincronizzazione dati durante la configurazione di sincronizzazione, all'interno della sezione "Connessioni endpoint private" nel portale di Azure o tramite PowerShell. Per altre informazioni su come approvare il collegamento privato, vedere Configurare sincronizzazione dati SQL. Dopo aver approvato l'endpoint privato gestito dal servizio, tutte le comunicazioni tra il servizio di sincronizzazione e i database membro/hub avvengono tramite il collegamento privato. È possibile aggiornare i gruppi di sincronizzazione esistenti per abilitare questa funzionalità.
Limitazioni generali
- Una tabella non può includere una colonna Identity che non sia la chiave primaria.
- Una chiave primaria non può includere i tipi di dati seguenti: sql_variant, binary, varbinary, image, xml.
- Usare i tipi di dati che seguono come chiave primaria con la massima cautela, perché supportano solo la precisione al secondo: time, datetime, datetime2, datetimeoffset.
- I nomi degli oggetti (database, tabelle e colonne) non possono contenere i caratteri stampabili punto (
.), parentesi quadra aperta ([) o parentesi quadra chiusa (]). - Un nome di tabella non può contenere caratteri stampabili:
! " # $ % ' ( ) * + -o spazio. - L'autenticazione Microsoft Entra (in precedenza Azure Active Directory) non è supportata.
- Se sono presenti tabelle con lo stesso nome ma uno schema diverso, ad esempio
dbo.customersesales.customers) solo una delle tabelle può essere aggiunta nella sincronizzazione. - Le colonne con tipi di dati definiti dall'utente non sono supportate.
- Lo spostamento dei server tra sottoscrizioni diverse non è supportato.
- Se due chiavi primarie sono diverse solo nel caso, ad esempio
Fooefoo), Sincronizzazione dati non supporterà questo scenario. - Il troncamento delle tabelle non è un'operazione supportata da Sincronizzazione dati (le modifiche non verranno tracciate).
- L'uso di un database Hyperscale di Azure SQL come database dell'hub o dei metadati di sincronizzazione non è supportato. Tuttavia, un database Hyperscale può essere un database membro in una topologia di sincronizzazione dati.
- Le tabelle ottimizzate per la memoria non sono supportate.
- Le modifiche allo schema non vengono replicate automaticamente. È possibile creare una soluzione personalizzata per automatizzare la replica delle modifiche dello schema.
- Sincronizzazione dati supporta solo le due proprietà di indice seguenti: Univoco, Clustered/Non Clustered. Altre proprietà di un indice come IGNORE_DUP_KEY o il filtro WHERE e così via non sono supportate e l'indice di destinazione viene effettuato senza queste proprietà anche se l'indice di origine dispone di tali proprietà impostate.
- Un database dei processi elastici di Azure non può essere usato come database dei metadati sincronizzazione dati SQL e viceversa.
- sincronizzazione dati SQL non è supportato per i database libro mastro.
Tipi di dati non supportati
- FileStream
- Tipo definito dall'utente (UDT) SQL/CLR
- XMLSchemaCollection (supportato da XML)
- Cursor, RowVersion, Timestamp, Hierarchyid
Tipi di colonna non supportati
La sincronizzazione dati non sincronizza le colonne di sola lettura o generate dal sistema. Ad esempio:
- Colonne calcolate.
- Colonne generate dal sistema per le tabelle temporali.
Limitazioni alle dimensioni del servizio e del database
| Dimensioni | Limite | Soluzione alternativa |
|---|---|---|
| Numero massimo di gruppi di sincronizzazione a cui può appartenere qualsiasi database. | 5 | |
| Numero massimo di endpoint in un singolo gruppo di sincronizzazione | 30 | |
| Numero massimo di endpoint locali in un singolo gruppo di sincronizzazione. | 5 | Creare più gruppi di sincronizzazione |
| Nomi di database, tabella, schema e colonna | 50 caratteri per nome | |
| Tabelle in un gruppo di sincronizzazione | 500 | Creare più gruppi di sincronizzazione |
| Colonne in una tabella in un gruppo di sincronizzazione | 1000 | |
| Dimensioni delle righe di dati in una tabella | 24 MB |
Nota
Se è presente un unico gruppo di sincronizzazione, questo può contenere fino a 30 endpoint. Se esistono più gruppi di sincronizzazione, il numero totale di endpoint in tutti i gruppi di sincronizzazione non può essere maggiore di 30. Se un database appartiene a più gruppi di sincronizzazione, vale come più endpoint.
Requisiti di rete
Nota
Se si usa Il collegamento privato Sincronizza, questi requisiti di rete non si applicano.
Quando viene stabilito il gruppo di sincronizzazione, il servizio sincronizzazione dati deve connettersi al database hub. Quando si stabilisce il gruppo di sincronizzazione, le impostazioni Firewalls and virtual networks del server SQL di Azure devono essere configurate nel seguente modo:
- L'opzione Nega l'accesso alla rete pubblica è impostata su Off.
- Consentire ai servizi e alle risorse di Azure di accedere a questo server deve essere impostato su Sì oppure è necessario creare regole IP per gli indirizzi IP usati dal servizio sincronizzazione dati.
Dopo aver creato e effettuato il provisioning del gruppo di sincronizzazione, è possibile disabilitare queste impostazioni. L'agente di sincronizzazione si connette direttamente al database hub ed è possibile usare le regole IP del firewall del server o gli endpoint privati per consentire all'agente di accedere al server di hub.
Nota
Se si modificano le impostazioni dello schema del gruppo di sincronizzazione, sarà necessario consentire al servizio sincronizzazione dati di accedere nuovamente al server in modo che il database hub possa essere nuovamente sottoposto a provisioning.
Residenza dei dati a livello di area
Se si sincronizzano i dati all'interno della stessa area, sincronizzazione dati SQL non archivia o elabora i dati dei clienti all'esterno dell'area in cui viene distribuita l'istanza del servizio. Se si sincronizzano i dati tra aree diverse, sincronizzazione dati SQL replica i dati dei clienti nelle aree abbinate.
Domande frequenti sulla sincronizzazione dati SQL
Quanto costa il servizio di sincronizzazione dati SQL?
Non viene applicato alcun addebito per il servizio di sincronizzazione dati SQL di per sé. Tuttavia, si accumuleranno ancora gli addebiti per il trasferimento dei dati dovuti allo spostamento dei dati da e verso l'istanza di database SQL. Per altre informazioni, vedere addebiti per il trasferimento dei dati.
Quali aree supportano la sincronizzazione dati?
La sincronizzazione dati SQL è disponibile in tutte le aree geografiche.
È necessario disporre di un account di database SQL?
Sì. È necessario disporre di un account di database SQL per ospitare il database hub.
È possibile usare la sincronizzazione dei dati solo tra database SQL Server?
Non direttamente. Tuttavia, è possibile sincronizzare in maniera indiretta tra i database SQL Server creando un database hub in Azure e aggiungendo i database locali al gruppo di sincronizzazione.
È possibile configurare la sincronizzazione dei dati per eseguire la sincronizzazione tra database SQL di Azure che appartengono a sottoscrizioni diverse?
Sì. È possibile configurare la sincronizzazione tra database appartenenti a gruppi di risorse di proprietà di sottoscrizioni diverse, anche se le sottoscrizioni appartengono a tenant diversi.
- Se le sottoscrizioni appartengono allo stesso tenant e sono disponibili le autorizzazioni per tutte le sottoscrizioni, è possibile configurare il gruppo di sincronizzazione nel portale di Azure.
- In caso contrario, è necessario usare PowerShell per aggiungere i membri di sincronizzazione.
È possibile usare la sincronizzazione dei dati per eseguire la sincronizzazione tra database SQL appartenenti a cloud diversi (come il cloud pubblico di Azure e ad Azure operato da 21Vianet)?
Sì. È possibile configurare la sincronizzazione tra database appartenenti a cloud diversi. È necessario usare PowerShell per aggiungere i membri di sincronizzazione che appartengono a sottoscrizioni diverse.
È possibile usare la sincronizzazione dati per effettuare il seeding dei dati da un database di produzione a un database vuoto e quindi sincronizzarli?
Sì. Creare manualmente lo schema nel nuovo database effettuando lo scripting dall'originale. Dopo aver creato lo schema, aggiungere le tabelle a un gruppo di sincronizzazione per copiare i dati e mantenerli sincronizzati.
È necessario usare la sincronizzazione dati SQL per eseguire il backup e il ripristino dei database?
Non è consigliabile usare la sincronizzazione dati SQL per creare un backup dei dati. Non è possibile eseguire il backup e il ripristino in un punto specifico nel tempo, perché le sincronizzazioni della sincronizzazione dati SQL sono senza versione. Inoltre, la sincronizzazione dati SQL non esegue il backup di altri oggetti SQL, ad esempio le stored procedure, e non esegue rapidamente l'equivalente di un'operazione di ripristino.
Per una tecnica di backup consigliata, vedere Copiare un database in database SQL di Azure.
Con la sincronizzazione dei dati si possono sincronizzare tabelle e colonne crittografate?
- Se un database usa Always Encrypted, è possibile sincronizzare solo le tabelle e colonne non crittografate. Non è possibile sincronizzare le colonne crittografate, perché la sincronizzazione dei dati non può decrittografare i dati.
- Se una colonna usa la crittografia a livello di colonna (CLE), è possibile sincronizzare la colonna, purché le dimensioni delle righe siano minori rispetto alle dimensioni massime di 24 MB. La sincronizzazione dei dati considera la colonna crittografata in base alla chiave (CLE) come normali dati binari. Per decrittografare i dati in altri membri di sincronizzazione, è necessario avere lo stesso certificato.
Le regole di confronto sono supportate nella sincronizzazione dati SQL?
Sì. La sincronizzazione dati SQL supporta le regole di confronto negli scenari seguenti:
- Se le tabelle dello schema di sincronizzazione selezionate non sono già nel database hub o membro, quando si distribuisce il gruppo di sincronizzazione, il servizio crea automaticamente le tabelle e le colonne corrispondenti con le impostazioni delle regole di confronto selezionate nei database di destinazione vuoti.
- Se le tabelle da sincronizzare sono già presenti sia nel database hub che nel database membro, la sincronizzazione dati SQL richiede che le colonne chiavi primarie abbiano le stesse regole di confronto in entrambi i database hub e membro per una distribuzione corretta del gruppo di sincronizzazione. Per le colonne diverse dalle colonne chiavi primarie non sono previste restrizioni relative alle regole di confronto.
La federazione è supportata nella sincronizzazione dati SQL?
Il database radice di federazione può essere usato nel servizio di sincronizzazione dati SQL senza alcuna limitazione. Non è possibile aggiungere l'endpoint del database federato alla versione corrente della sincronizzazione dati SQL.
È possibile usare la sincronizzazione dei dati per sincronizzare i dati esportati da Dynamics 365 usando la funzionalità BYOD (Bring Your Own Database)?
La funzionalità Dynamics 365 bring your own database consente agli amministratori di esportare le entità dati dall'applicazione nel proprio database SQL di Microsoft Azure. sincronizzazione dati possibile usare per sincronizzare questi dati in altri database se i dati vengono esportati tramite push incrementale (il push completo non è supportato) e abilitare i trigger nel database di destinazione è impostato su sì.
Ricerca per categorie creare sincronizzazione dati nel gruppo failover per supportare il ripristino di emergenza?
- Per assicurarsi che le operazioni di sincronizzazione dei dati nell'area di failover siano uguali all'area primaria, dopo il failover è necessario ricreare manualmente il gruppo di sincronizzazione nell'area di failover con le stesse impostazioni dell'area primaria.
Passaggi successivi
Aggiornare lo schema di un database sincronizzato
È necessario aggiornare lo schema di un database in un gruppo di sincronizzazione? Le modifiche allo schema non vengono replicate automaticamente. Per alcune soluzioni, vedere gli articoli seguenti:
- Automatizzare la replica delle modifiche dello schema con la sincronizzazione dati SQL di Azure
- Usare PowerShell per aggiornare lo schema di sincronizzazione in un gruppo di sincronizzazione esistente
Monitorare e risolvere i problemi
La sincronizzazione dati SQL ha le prestazioni previste? Per monitorare l'attività e risolvere i problemi, vedere gli articoli seguenti:
- Monitorare la sincronizzazione dati SQL con i log di Monitoraggio di Azure
- Risolvere i problemi della sincronizzazione dati SQL di Azure
Ulteriori informazioni sul database SQL di Azure
Per altre informazioni sul database SQL di Azure, vedere gli articoli seguenti:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per