Guida introduttiva: Flusso di lavoro di orchestrazione
Usare questo articolo per iniziare a usare i progetti del flusso di lavoro di orchestrazione usando Language Studio e l'API REST. Seguire questa procedura per provare un esempio.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito.
- Progetto di comprensione del linguaggio conversazionale .
Accedere a Language Studio
Passare a Language Studio e accedere con l'account Azure.
Nella finestra Scegliere una risorsa della lingua visualizzata individuare la sottoscrizione di Azure e scegliere la risorsa Lingua. Se non si ha una risorsa, è possibile crearne una nuova.
Dettagli dell'istanza Valore richiesto La sottoscrizione di Azure La sottoscrizione di Azure. Gruppo di risorse di Azure Il gruppo di risorse di Azure. Nome risorsa di Azure Nome della risorsa di Azure. Posizione Posizione valida per la risorsa di Azure. Ad esempio, "Stati Uniti occidentali 2". Piano tariffario Piano tariffario supportato per la risorsa di Azure. È possibile usare il livello Gratuito (F0) per provare il servizio. 

Creare un progetto flusso di lavoro di orchestrazione
Dopo aver creato una risorsa Language, creare un progetto flusso di lavoro di orchestrazione. Un progetto è un'area di lavoro per la creazione di modelli di Machine Learning personalizzati in base ai dati. L'accesso al progetto può essere eseguito solo dall'utente e da altri utenti che hanno accesso alla risorsa Language in uso.
Per questa guida introduttiva, completare l'argomento di avvio rapido per la comprensione del linguaggio conversazionale per creare un progetto di comprensione del linguaggio di conversazione che verrà usato in un secondo momento.
In Language Studio trovare la sezione Informazioni sulle domande e sul linguaggio di conversazione e selezionare Flusso di lavoro di orchestrazione.

Verrà visualizzata la pagina del progetto flusso di lavoro orchestrazione . Selezionare Crea nuovo progetto. Per creare un progetto, è necessario specificare i dettagli seguenti:

| Valore | Descrizione |
|---|---|
| Nome | Nome del progetto. |
| Descrizione | Descrizione facoltativa del progetto. |
| Linguaggio principale delle espressioni | Lingua principale del progetto. I dati di training devono trovarsi principalmente in questa lingua. |
Al termine, selezionare Avanti ed esaminare i dettagli. Selezionare Crea progetto per completare il processo. Verrà visualizzata la schermata Schema di compilazione nel progetto.
Schema di compilazione
Dopo aver completato la guida introduttiva alla comprensione del linguaggio di conversazione e aver creato un progetto di orchestrazione, il passaggio successivo consiste nell'aggiungere finalità.
Per connettersi al progetto di comprensione del linguaggio conversazionale creato in precedenza:
- Nella pagina dello schema di compilazione nel progetto di orchestrazione selezionare Aggiungi per aggiungere una finalità.
- Nella finestra visualizzata assegnare un nome alla finalità.
- Selezionare Sì, si vuole connetterlo a un progetto esistente.
- Nell'elenco a discesa servizi connessi selezionare Conversational Language Understanding.
- Nell'elenco a discesa nome progetto selezionare il progetto di comprensione del linguaggio conversazionale.
- Selezionare Aggiungi finalità per creare la finalità.
Eseguire training del modello
Per eseguire il training di un modello, è necessario avviare un processo di training. L'output di un processo di training riuscito è il modello sottoposto a training.
Per avviare il training del modello dall'interno di Language Studio:
Selezionare Processi di training dal menu a sinistra.
Selezionare Avvia un processo di training dal menu in alto.
Selezionare Esegui training di un nuovo modello e digitare il nome del modello nella casella di testo. È anche possibile sovrascrivere un modello esistente selezionando questa opzione e scegliendo il modello da sovrascrivere dal menu a discesa. La sovrascrittura di un modello sottoposto a training è irreversibile, ma non influisce sui modelli distribuiti fino a quando non si distribuisce il nuovo modello.
Se il progetto è stato abilitato per suddividere manualmente i dati quando si contrassegnano le espressioni, verranno visualizzate due opzioni di suddivisione dei dati:
- Suddivisione automatica del set di test dai dati di training: le espressioni con tag verranno suddivise in modo casuale tra i set di training e di test, in base alle percentuali scelte. La divisione percentuale predefinita è l'80% per il training e il 20% per i test. Per modificare questi valori, scegliere il set da modificare e digitare nel nuovo valore.
Nota
Se si sceglie l'opzione Suddivisione automatica del set di test dai dati di training , solo le espressioni nel set di training verranno suddivise in base alle percentuali specificate.
- Usare una suddivisione manuale dei dati di training e test: assegnare ogni espressione al training o al set di test durante il passaggio di assegnazione di tag del progetto.
Nota
Usare una suddivisione manuale dei dati di training e test verrà abilitata solo se si aggiungono espressioni al set di test nella pagina dei dati dei tag. In caso contrario, verrà disabilitato.
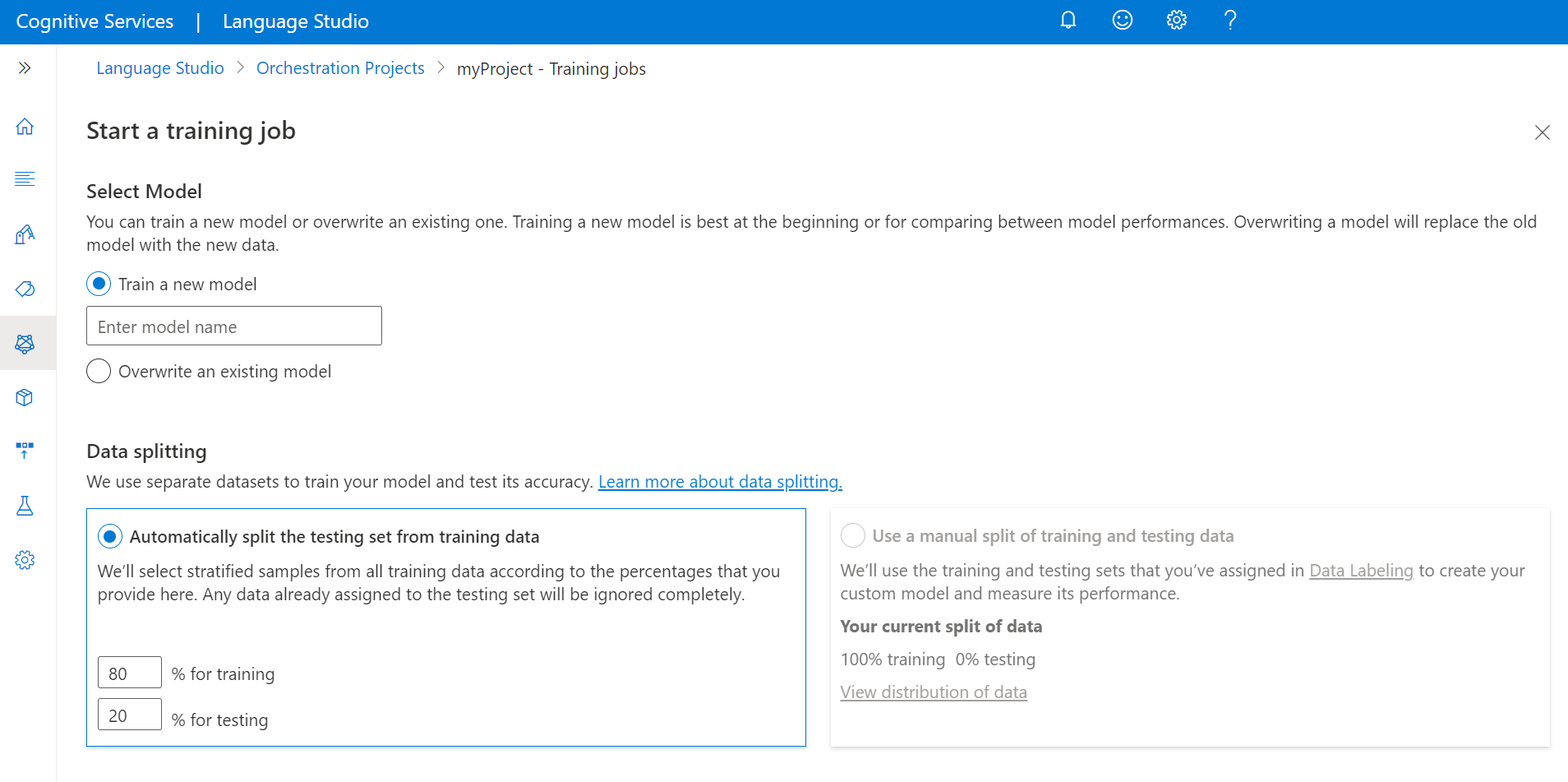
Selezionare il pulsante Train (Esegui training ).

Nota
- Solo i processi di training completati correttamente genereranno modelli.
- Il training può richiedere tempo tra un paio di minuti e un paio di ore in base alle dimensioni dei dati con tag.
- È possibile eseguire un solo processo di training alla volta. Non è possibile avviare altri processi di training con lo stesso progetto fino al completamento del processo in esecuzione.
Distribuire il modello
In genere, dopo il training di un modello, esaminare i dettagli di valutazione. In questa guida introduttiva si distribuirà semplicemente il modello e lo si renderà disponibile per provare in Language Studio oppure è possibile chiamare l'API di stima.
Per distribuire il modello da Language Studio:
Selezionare Deploying a model (Distribuzione di un modello ) dal menu a sinistra.
Selezionare Aggiungi distribuzione per avviare un nuovo processo di distribuzione.

Selezionare Crea nuova distribuzione per creare una nuova distribuzione e assegnare un modello sottoposto a training nell'elenco a discesa seguente. È anche possibile sovrascrivere una distribuzione esistente selezionando questa opzione e selezionando il modello sottoposto a training da assegnare all'app dall'elenco a discesa seguente.
Nota
La sovrascrittura di una distribuzione esistente non richiede modifiche alla chiamata API di stima , ma i risultati ottenuti saranno basati sul modello appena assegnato.

Se si connettono una o più applicazioni LUIS o progetti di comprensione del linguaggio di conversazione , è necessario specificare il nome della distribuzione.
Non sono necessarie configurazioni per la risposta alle domande personalizzate o per finalità non collegate.
I progetti LUIS devono essere pubblicati nello slot configurato durante la distribuzione dell'orchestrazione e le domande personalizzate devono essere pubblicate anche negli slot di produzione.
Selezionare Distribuisci per inviare il processo di distribuzione
Al termine della distribuzione, accanto verrà visualizzata una data di scadenza. La scadenza della distribuzione è quando il modello distribuito non sarà disponibile per la stima, che in genere si verifica dodici mesi dopo la scadenza di una configurazione di training.


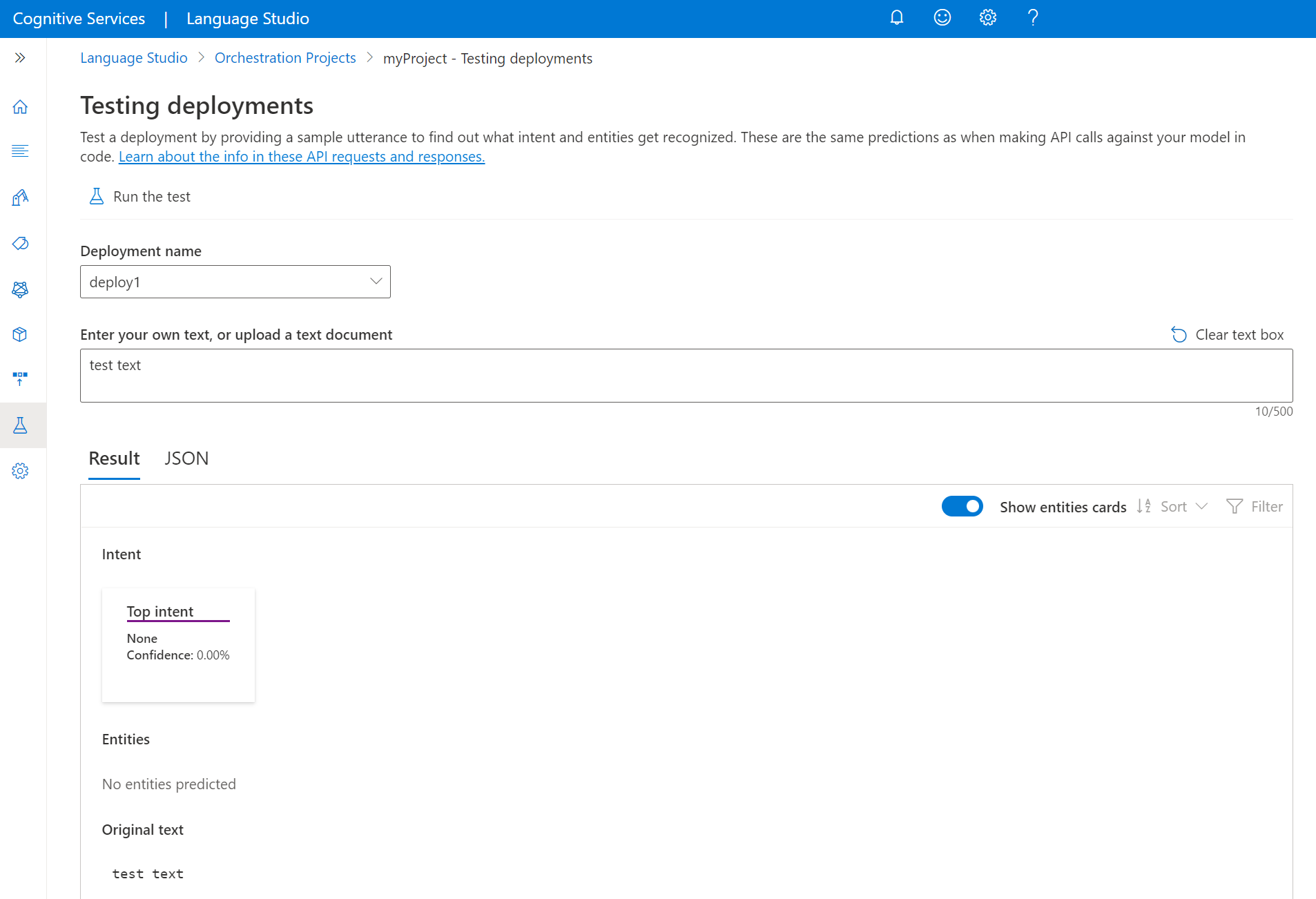
Modello di test
Dopo aver distribuito il modello, è possibile iniziare a usarlo per eseguire stime tramite l'API Stima. Per questa guida introduttiva si userà Language Studio per inviare un'espressione, ottenere stime e visualizzare i risultati.
Per testare il modello da Language Studio
Selezionare Test delle distribuzioni dal menu a sinistra.
Selezionare il modello da testare. È possibile testare solo i modelli assegnati alle distribuzioni.
Nell'elenco a discesa Nome distribuzione selezionare il nome della distribuzione.
Nella casella di testo immettere un'espressione da testare.
Nel menu in alto selezionare Esegui il test.
Dopo aver eseguito il test, verrà visualizzata la risposta del modello nel risultato. È possibile visualizzare i risultati nella visualizzazione schede delle entità o visualizzarlo in formato JSON.

Pulire le risorse
Quando il progetto non è più necessario, è possibile eliminare il progetto usando Language Studio. Selezionare Progetti dal menu di spostamento a sinistra, selezionare il progetto da eliminare e quindi selezionare Elimina dal menu in alto.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito.
Creare una risorsa language da portale di Azure
Creare una nuova risorsa dal portale di Azure
Passare alla portale di Azure per creare una nuova risorsa del linguaggio di intelligenza artificiale di Azure.
Selezionare Continua per creare la risorsa
Creare una risorsa Language con i dettagli seguenti.
Dettagli dell'istanza Valore richiesto Region Una delle aree supportate. Nome Nome della risorsa Lingua. Piano tariffario Uno dei piani tariffari supportati.
Ottenere le chiavi di risorsa e l'endpoint
Passare alla pagina di panoramica delle risorse nel portale di Azure.
Dal menu a sinistra selezionare Chiavi ed Endpoint. Si useranno l'endpoint e la chiave per le richieste API


Creare un progetto flusso di lavoro di orchestrazione
Dopo aver creato una risorsa Language, creare un progetto flusso di lavoro di orchestrazione. Un progetto è un'area di lavoro per la creazione di modelli di Machine Learning personalizzati in base ai dati. L'accesso al progetto può essere eseguito solo dall'utente e da altri utenti che hanno accesso alla risorsa Language in uso.
Per questa guida introduttiva, completare la guida introduttiva di CLU per creare un progetto CLU da usare nel flusso di lavoro di orchestrazione.
Inviare una richiesta PATCH usando l'URL, le intestazioni e il corpo JSON seguenti per creare un nuovo progetto.
URL richiesta
Usare l'URL seguente durante la creazione della richiesta API. Sostituire i valori segnaposto seguenti con i valori personalizzati.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{API-VERSION} |
Versione dell'API che si sta chiamando. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | Valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per autenticare le richieste API. |
Corpo
Usare il codice JSON di esempio seguente come corpo.
{
"projectName": "{PROJECT-NAME}",
"language": "{LANGUAGE-CODE}",
"projectKind": "Orchestration",
"description": "Project description"
}
| Chiave | Segnaposto | Valore | Esempio |
|---|---|---|---|
projectName |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | EmailApp |
language |
{LANGUAGE-CODE} |
Stringa che specifica il codice della lingua per le espressioni usate nel progetto. Se il progetto è un progetto multilingue, scegliere il codice linguistico della maggior parte delle espressioni. | en-us |
Schema di compilazione
Dopo aver completato la guida introduttiva CLU e aver creato un progetto di orchestrazione, il passaggio successivo consiste nell'aggiungere finalità.
Inviare una richiesta POST usando l'URL, le intestazioni e il corpo JSON seguenti per importare il progetto.
URL richiesta
Usare l'URL seguente durante la creazione della richiesta API. Sostituire i valori segnaposto seguenti con i valori personalizzati.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:import?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{API-VERSION} |
Versione dell'API che si sta chiamando. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | Valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per autenticare le richieste API. |
Corpo
Nota
Ogni finalità deve essere di un solo tipo da (CLU, LUIS e qna)
Usare il codice JSON di esempio seguente come corpo.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "Orchestration",
"settings": {
"confidenceThreshold": 0
},
"projectName": "{PROJECT-NAME}",
"description": "Project description",
"language": "{LANGUAGE-CODE}"
},
"assets": {
"projectKind": "Orchestration",
"intents": [
{
"category": "string",
"orchestration": {
"kind": "luis",
"luisOrchestration": {
"appId": "00000000-0000-0000-0000-000000000000",
"appVersion": "string",
"slotName": "string"
},
"cluOrchestration": {
"projectName": "string",
"deploymentName": "string"
},
"qnaOrchestration": {
"projectName": "string"
}
}
}
],
"utterances": [
{
"text": "Trying orchestration",
"language": "{LANGUAGE-CODE}",
"intent": "string"
}
]
}
}
| Chiave | Segnaposto | Valore | Esempio |
|---|---|---|---|
api-version |
{API-VERSION} |
Versione dell'API che si sta chiamando. La versione usata qui deve essere la stessa versione dell'API nell'URL. | 2022-03-01-preview |
projectName |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | EmailApp |
language |
{LANGUAGE-CODE} |
Stringa che specifica il codice del linguaggio per le espressioni usate nel progetto. Se il progetto è un progetto multilingue, scegliere il codice del linguaggio della maggior parte delle espressioni. | en-us |
Eseguire training del modello
Per eseguire il training di un modello, è necessario avviare un processo di training. L'output di un processo di training riuscito è il modello sottoposto a training.
Creare una richiesta POST usando l'URL, le intestazioni e il corpo JSON seguenti per inviare un processo di training.
URL richiesta
Usare l'URL seguente durante la creazione della richiesta API. Sostituire i valori segnaposto seguenti con i propri valori.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | EmailApp |
{API-VERSION} |
Versione dell'API che si sta chiamando. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | Valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per autenticare le richieste API. |
Testo della richiesta
Usare l'oggetto seguente nella richiesta. Il modello verrà denominato MyModel una volta completato il training.
{
"modelLabel": "{MODEL-NAME}",
"trainingMode": "standard",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"testingSplitPercentage": 20,
"trainingSplitPercentage": 80
}
}
| Chiave | Segnaposto | Valore | Esempio |
|---|---|---|---|
modelLabel |
{MODEL-NAME} |
Nome modello. | Model1 |
trainingMode |
standard |
Modalità di training. Solo una modalità per il training è disponibile nell'orchestrazione, ovvero standard. |
standard |
trainingConfigVersion |
{CONFIG-VERSION} |
Versione del modello di configurazione del training. Per impostazione predefinita, viene usata la versione più recente del modello . | 2022-05-01 |
kind |
percentage |
Metodi di divisione. I possibili valori sono percentage o manual. Per altre informazioni, vedere come eseguire il training di un modello . |
percentage |
trainingSplitPercentage |
80 |
Percentuale dei dati contrassegnati da includere nel set di training. Il valore consigliato è 80. |
80 |
testingSplitPercentage |
20 |
Percentuale dei dati contrassegnati da includere nel set di test. Il valore consigliato è 20. |
20 |
Nota
L'oggetto trainingSplitPercentage e testingSplitPercentage sono necessari solo se Kind è impostato su percentage e la somma di entrambe le percentuali deve essere uguale a 100.
Dopo aver inviato la richiesta API, si riceverà una 202 risposta che indica l'esito positivo. Nelle intestazioni di risposta estrarre il operation-location valore. Verrà formattato come segue:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
È possibile usare questo URL per ottenere lo stato del processo di training.
Get Training Status
Il training potrebbe richiedere qualche ora tra 10 e 30 minuti. È possibile usare la richiesta seguente per mantenere il polling dello stato del processo di training fino a quando non viene completato correttamente.
Usare la richiesta GET seguente per ottenere lo stato dell'avanzamento del training del modello. Sostituire i valori segnaposto seguenti con i propri valori.
URL richiesta
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{YOUR-ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | EmailApp |
{JOB-ID} |
ID per individuare lo stato di training del modello. Questo è il valore dell'intestazione location ricevuto quando è stato inviato il processo di training. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Versione dell'API che si sta chiamando. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | Valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per autenticare le richieste API. |
Corpo della risposta
Dopo aver inviato la richiesta, si otterrà la risposta seguente. Continuare a eseguire il polling di questo endpoint fino a quando il parametro di stato non viene modificato in "riuscito".
{
"result": {
"modelLabel": "{MODEL-LABEL}",
"trainingConfigVersion": "{TRAINING-CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "xxxxxx-xxxxx-xxxxxx-xxxxxx",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
| Chiave | Valore | Esempio |
|---|---|---|
modelLabel |
Nome del modello | Model1 |
trainingConfigVersion |
Versione di configurazione del training. Per impostazione predefinita, viene usata la versione più recente . | 2022-05-01 |
startDateTime |
L'ora di avvio del training | 2022-04-14T10:23:04.2598544Z |
status |
Stato del processo di formazione | running |
estimatedEndDateTime |
Tempo stimato per il completamento del processo di training | 2022-04-14T10:29:38.2598544Z |
jobId |
ID processo di training | xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx |
createdDateTime |
Data e ora di creazione dei processi di training | 2022-04-14T10:22:42Z |
lastUpdatedDateTime |
Processo di training ultima data e ora aggiornate | 2022-04-14T10:23:45Z |
expirationDateTime |
Data e ora del processo di training | 2022-04-14T10:22:42Z |
Distribuire il modello
In genere dopo il training di un modello si esaminerebbero i dettagli di valutazione. In questa guida introduttiva si distribuirà il modello e si chiamerà l'API di stima per eseguire query sui risultati.
Inviare il processo di distribuzione
Creare una richiesta PUT usando l'URL, le intestazioni e il corpo JSON seguenti per iniziare a distribuire un modello di flusso di lavoro di orchestrazione.
URL richiesta
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{DEPLOYMENT-NAME} |
Nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | staging |
{API-VERSION} |
Versione dell'API che si sta chiamando. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | Valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per autenticare le richieste API. |
Corpo della richiesta
{
"trainedModelLabel": "{MODEL-NAME}",
}
| Chiave | Segnaposto | Valore | Esempio |
|---|---|---|---|
| trainingedModelLabel | {MODEL-NAME} |
Nome del modello che verrà assegnato alla distribuzione. È possibile assegnare solo modelli sottoposti a training. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myModel |
Dopo aver inviato la richiesta API, si riceverà una 202 risposta che indica l'esito positivo. Nelle intestazioni di risposta estrarre il operation-location valore. Verrà formattato come segue:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
È possibile usare questo URL per ottenere lo stato del processo di distribuzione.
Ottenere lo stato del processo di distribuzione
Usare la richiesta GET seguente per ottenere lo stato del processo di distribuzione. Sostituire i valori segnaposto seguenti con i propri valori.
URL richiesta
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{DEPLOYMENT-NAME} |
Nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | staging |
{JOB-ID} |
ID per individuare lo stato di training del modello. Questo è il location valore dell'intestazione ricevuto dall'API in risposta alla richiesta di distribuzione del modello. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Versione dell'API che si sta chiamando. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | Valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per autenticare le richieste API. |
Corpo della risposta
Dopo aver inviato la richiesta, si otterrà la risposta seguente. Continuare a eseguire il polling di questo endpoint fino a quando il parametro di stato non viene modificato in "riuscito".
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Modello di query
Dopo aver distribuito il modello, è possibile iniziare a usarlo per effettuare stime tramite l'API di stima.
Una volta completata la distribuzione, è possibile iniziare a eseguire query sul modello distribuito per le stime.
Creare una richiesta POST usando l'URL, le intestazioni e il corpo JSON seguenti per avviare il test di un modello di flusso di lavoro di orchestrazione.
URL richiesta
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Versione dell'API che si sta chiamando. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | Valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per autenticare le richieste API. |
Corpo della richiesta
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"text": "Text1",
"participantId": "1",
"id": "1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"directTarget": "qnaProject",
"targetProjectParameters": {
"qnaProject": {
"targetProjectKind": "QuestionAnswering",
"callingOptions": {
"context": {
"previousUserQuery": "Meet Surface Pro 4",
"previousQnaId": 4
},
"top": 1,
"question": "App Service overview"
}
}
}
}
}
Corpo della risposta
Dopo aver inviato la richiesta, si otterrà la risposta seguente per la stima.
{
"kind": "ConversationResult",
"result": {
"query": "App Service overview",
"prediction": {
"projectKind": "Orchestration",
"topIntent": "qnaTargetApp",
"intents": {
"qnaTargetApp": {
"targetProjectKind": "QuestionAnswering",
"confidenceScore": 1,
"result": {
"answers": [
{
"questions": [
"App Service overview"
],
"answer": "The compute resources you use are determined by the *App Service plan* that you run your apps on.",
"confidenceScore": 0.7384000000000001,
"id": 1,
"source": "https://learn.microsoft.com/azure/app-service/overview",
"metadata": {},
"dialog": {
"isContextOnly": false,
"prompts": []
}
}
]
}
}
}
}
}
}
Pulire le risorse
Quando non è più necessario il progetto, è possibile eliminare il progetto usando le API.
Creare una richiesta DELETE usando l'URL, le intestazioni e il corpo JSON seguenti per eliminare un progetto di comprensione del linguaggio di conversazione.
URL richiesta
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{API-VERSION} |
Versione dell'API che si sta chiamando. | 2023-04-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | Valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per autenticare le richieste API. |
Dopo aver inviato la richiesta API, si riceverà una 202 risposta che indica l'esito positivo, il che significa che il progetto è stato eliminato.