Panoramica della continuità aziendale e del ripristino di emergenza
La continuità aziendale e il ripristino di emergenza in Azure Esplora dati consentono all'azienda di continuare a funzionare in caso di interruzione. Questo articolo illustra la disponibilità (all'interno dell'area) e il ripristino di emergenza. Illustra in dettaglio le funzionalità native e le considerazioni sull'architettura per una distribuzione resiliente di Azure Esplora dati. Illustra in dettaglio il ripristino da errori umani, disponibilità elevata, seguito da più configurazioni di ripristino di emergenza. Queste configurazioni dipendono dai requisiti di resilienza, ad esempio l'obiettivo del punto di ripristino (RPO) e l'obiettivo del tempo di ripristino (RTO), gli sforzi necessari e i costi necessari.
Attenuare gli eventi di interruzione
- Errore umano
- Disponibilità elevata di Azure Esplora dati
- Interruzione di una zona di disponibilità di Azure
- Interruzione di un data center di Azure
- Interruzione di un'area di Azure
Errore umano
Gli errori umani sono inevitabili. Gli utenti possono eliminare accidentalmente un cluster, un database o una tabella.
Eliminazione accidentale del cluster o del database
L'eliminazione accidentale del cluster o del database è un'azione irreversibile. In qualità di proprietario della risorsa di Azure Esplora dati, è possibile evitare la perdita di dati abilitando la funzionalità di blocco di eliminazione, disponibile a livello di risorsa di Azure.
Eliminazione accidentale della tabella
Gli utenti con autorizzazioni di amministratore tabella o superiori possono eliminare le tabelle. Se uno di questi utenti elimina accidentalmente una tabella, è possibile recuperarla usando il .undo drop table comando . Affinché questo comando venga eseguito correttamente, è prima necessario abilitare la proprietà di recuperabilità nei criteri di conservazione.
Eliminazione accidentale di tabelle esterne
Le tabelle esterne sono entità dello schema di query Kusto che fanno riferimento ai dati archiviati all'esterno del database. L'eliminazione di una tabella esterna elimina solo i metadati della tabella. È possibile recuperarlo eseguendo di nuovo il comando di creazione della tabella. Usare la funzionalità di eliminazione temporanea per evitare l'eliminazione accidentale o la sovrascrittura di un file/BLOB per un periodo di tempo configurato dall'utente.
Disponibilità elevata di Azure Esplora dati
La disponibilità elevata si riferisce alla tolleranza di errore di Azure Esplora dati, ai relativi componenti e alle dipendenze sottostanti all'interno di un'area di Azure. Questa tolleranza di errore evita singoli punti di errore (SPOF) nell'implementazione. In Azure Esplora dati la disponibilità elevata include il livello di persistenza, il livello di calcolo e una configurazione leader-follower.
Livello di persistenza
Azure Esplora dati sfrutta Archiviazione di Azure come livello di persistenza durevole. Archiviazione di Azure offre automaticamente la tolleranza di errore, con l'impostazione predefinita che offre archiviazione con ridondanza locale all'interno di un data center. Vengono mantenute tre repliche. Se una replica viene persa durante l'uso, un'altra viene distribuita senza interruzioni. Un'ulteriore resilienza è possibile con l'archiviazione con ridondanza della zona che inserisce le repliche in modo intelligente nelle zone di disponibilità a livello di area di Azure per garantire la massima tolleranza di errore a un costo aggiuntivo. L'archiviazione abilitata per l'archiviazione con ridondanza della zona viene configurata automaticamente quando il cluster Esplora dati di Azure viene distribuito in zone di disponibilità.
Livello di calcolo
Azure Esplora dati è una piattaforma di elaborazione distribuita e può avere due o più nodi a seconda del tipo di ruolo di ridimensionamento e nodo. In fase di provisioning selezionare le zone di disponibilità per distribuire la distribuzione del nodo, tra le zone per ottenere la resilienza massima all'interno dell'area. Un errore della zona di disponibilità non comporterà un'interruzione completa, ma una riduzione delle prestazioni fino al ripristino della zona.
Configurazione del cluster leader-follower
Azure Esplora dati offre una funzionalità di follower facoltativa per un cluster leader da seguire da altri cluster follower per l'accesso in sola lettura ai dati e ai metadati del leader. Le modifiche apportate al leader, ad esempio create, appende drop vengono sincronizzate automaticamente con il follower. Anche se i leader possono estendersi su aree di Azure, i cluster follower devono essere ospitati nella stessa area o nelle stesse aree del leader. Se il cluster leader è inattivo o i database o le tabelle vengono accidentalmente eliminati, i cluster follower perderanno l'accesso fino a quando l'accesso non viene ripristinato nel leader.
Interruzione di una zona di disponibilità di Azure
Le zone di disponibilità di Azure sono posizioni fisiche univoche all'interno della stessa area di Azure. Possono proteggere le risorse di calcolo e i dati di un cluster di Azure Esplora dati da un errore parziale dell'area. L'errore della zona è uno scenario di disponibilità perché si trova all'interno dell'area.
Aggiungere un cluster Esplora dati di Azure alla stessa zona delle altre risorse di Azure connesse. Per altre informazioni sull'abilitazione delle zone di disponibilità, vedere Creare un cluster.
Nota
La distribuzione nelle zone di disponibilità è possibile quando si crea un cluster o è possibile eseguirne la migrazione in un secondo momento.
Interruzione di un data center di Azure
Le zone di disponibilità di Azure hanno un costo e alcuni clienti scelgono di eseguire la distribuzione senza ridondanza di zona. Con tale distribuzione di Azure Esplora dati, un'interruzione del data center di Azure comporterà un'interruzione del cluster. La gestione di un'interruzione del data center di Azure è quindi identica a quella di un'interruzione dell'area di Azure.
Interruzione di un'area di Azure
Azure Esplora dati non offre protezione automatica contro l'interruzione di un'intera area di Azure. Per ridurre al minimo l'impatto aziendale in caso di interruzione di questo tipo, più cluster di Azure Esplora dati tra aree abbinate di Azure. In base all'obiettivo del tempo di ripristino (RTO), all'obiettivo del punto di ripristino (RPO), nonché alle considerazioni relative ai costi e alle attività, esistono più configurazioni di ripristino di emergenza. Le ottimizzazioni dei costi e delle prestazioni sono possibili con le raccomandazioni di Azure Advisor e la configurazione della scalabilità automatica .
Configurazioni di ripristino di emergenza
In questa sezione vengono fornite informazioni dettagliate su più configurazioni di ripristino di emergenza in base ai requisiti di resilienza (RPO e RTO), alle esigenze e ai costi.
L'obiettivo del tempo di ripristino (RTO) fa riferimento al tempo necessario per il ripristino da un'interruzione. Ad esempio, RTO di 2 ore indica che l'applicazione deve essere operativa entro due ore da un'interruzione. L'obiettivo del punto di ripristino (RPO) fa riferimento all'intervallo di tempo che può trascorrere durante un'interruzione prima che la quantità di dati persi durante tale periodo sia maggiore della soglia consentita. Ad esempio, se l'RPO è di 24 ore e un'applicazione ha dati a partire da 15 anni fa, sono ancora all'interno dei parametri dell'RPO concordato.
I processi di inserimento, elaborazione e cura necessitano di una progettazione diligente durante la pianificazione del ripristino di emergenza. L'inserimento si riferisce ai dati integrati in Azure Esplora dati da diverse origini; l'elaborazione si riferisce a trasformazioni e attività simili; la cura si riferisce a viste materializzate, esportazioni nel data lake e così via.
Di seguito sono riportate le configurazioni di ripristino di emergenza più diffuse e ognuna è descritta in dettaglio di seguito.
- Configurazione di Active-Active-Active (always-on)
- Configurazione attiva-attiva
- Configurazione di Active-Hot Standby
- Configurazione del cluster di ripristino dei dati su richiesta
Configurazione active-active-active-active
Questa configurazione è detta anche "always-on". Per le distribuzioni di applicazioni critiche senza tolleranza per le interruzioni, è consigliabile usare più cluster di Azure Esplora dati tra aree abbinate di Azure. Configurare l'inserimento, l'elaborazione e la cura in parallelo a tutti i cluster. Lo SKU del cluster deve essere lo stesso in tutte le aree. Azure garantisce che gli aggiornamenti vengano implementati e sfalsati tra aree abbinate di Azure. Un'interruzione dell'area di Azure non causerà un'interruzione dell'applicazione. È possibile che si verifichi una latenza o una riduzione delle prestazioni.

| Configuration | RPO | RTO | Lavoro richiesto | Costi |
|---|---|---|---|---|
| Active-Active-Active-n | 0 ore | 0 ore | Minore | Più alta |
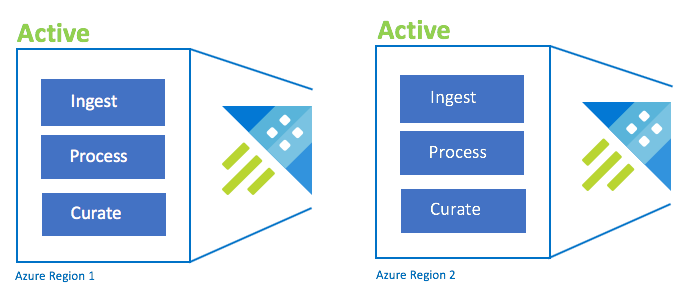
configurazione di Active-Active
Questa configurazione è identica alla configurazione attiva-attiva-attiva, ma include solo due aree abbinate di Azure. Configurare doppia inserimento, elaborazione e cura. Gli utenti vengono indirizzati all'area più vicina. Lo SKU del cluster deve essere lo stesso tra le aree.
| Configuration | RPO | RTO | Lavoro richiesto | Costi |
|---|---|---|---|---|
| Active-Active | 0 ore | 0 ore | Minore | Alto |
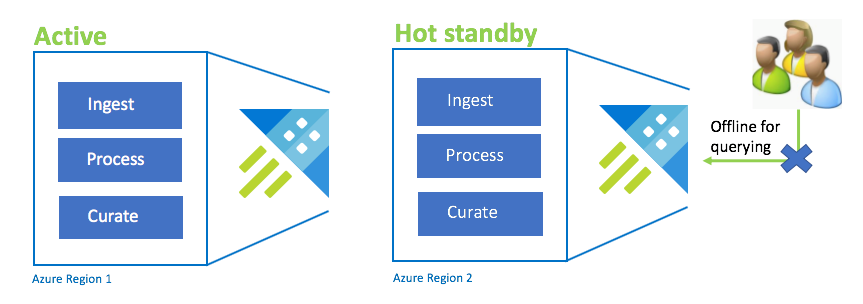
Active-Hot configurazione standby
La configurazione Active-Hot è simile alla configurazione Active-Active in doppia inserimento, elaborazione e cura. Mentre il cluster standby è online per l'inserimento, il processo e la cura, non è disponibile per la query. Il cluster di standby non deve trovarsi nello stesso SKU del cluster primario. Può essere di uno SKU e una scalabilità più piccola, che può comportare una minore prestazioni. In uno scenario di emergenza, gli utenti vengono reindirizzati al cluster standby, che può essere ridimensionato facoltativamente per aumentare le prestazioni.
| Configuration | RPO | RTO | Lavoro richiesto | Costi |
|---|---|---|---|---|
| Standby attivo a caldo | 0 ore | Basso | Medio | Livello medio |
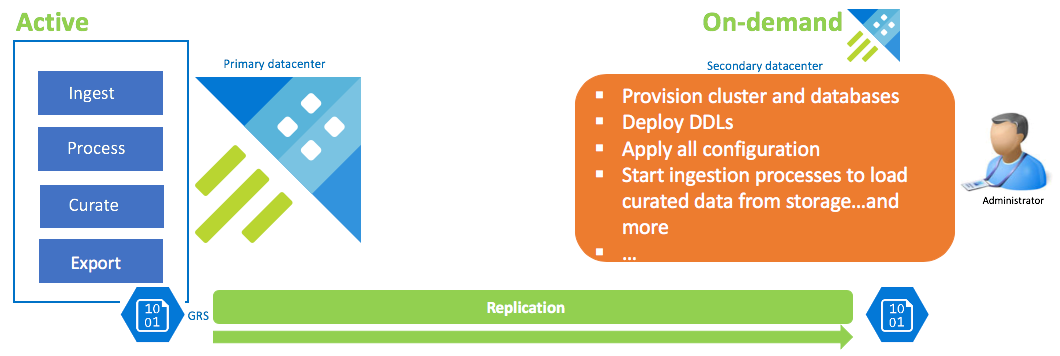
Configurazione del ripristino dei dati su richiesta
Questa soluzione offre la resilienza minima (rpo e RTO più alta), è il più basso in costo e il massimo sforzo. In questa configurazione non è presente alcun cluster di ripristino dei dati. Configurare l'esportazione continua di dati curati (a meno che non siano necessari anche dati non elaborati e intermedi) in un account di archiviazione configurato (archiviazione con ridondanza geografica). Se si verifica uno scenario di ripristino di emergenza, un cluster di ripristino dati viene eseguito. In quel momento, vengono applicati DDLs, configurazione, criteri e processi. I dati vengono inseriti dall'archiviazione con la proprietà di inserimento kustoCreationTime per eseguire il over-ride del tempo di inserimento predefinito per il tempo di sistema.
| Configuration | RPO | RTO | Lavoro richiesto | Costi |
|---|---|---|---|---|
| Cluster di ripristino dei dati su richiesta | Più alta | Più alta | Più alta | Più bassa |
Riepilogo delle opzioni di configurazione del ripristino di emergenza
| Configuration | Resilienza | RPO | RTO | Lavoro richiesto | Costi |
|---|---|---|---|---|---|
| Active-Active-Active-n | Più alta | 0 ore | 0 ore | Minore | Più alta |
| Active-Active | Alto | 0 ore | 0 ore | Minore | Alto |
| Standby attivo a caldo | Medio | 0 ore | Basso | Medio | Livello medio |
| Cluster di ripristino dei dati su richiesta | Più bassa | Più alta | Più alta | Più alta | Più bassa |
Procedure consigliate
Indipendentemente dalla configurazione del ripristino di emergenza scelta, seguire queste procedure consigliate:
- Tutti gli oggetti di database, i criteri e le configurazioni devono essere mantenuti nel controllo del codice sorgente in modo che possano essere rilasciati al cluster dallo strumento di automazione della versione. Per altre informazioni, vedere Supporto di Azure DevOps per Azure Esplora dati.
- Progettare, sviluppare e implementare routine di convalida per garantire che tutti i cluster siano sincronizzati da un punto di vista dei dati. Azure Esplora dati supporta i join tra cluster. Un semplice conteggio o righe tra tabelle può essere utile per convalidare.
- Le procedure di rilascio devono includere controlli e bilanciamenti della governance che garantiscono il mirroring dei cluster.
- Essere completamente consapevoli delle operazioni necessarie per creare un cluster da zero.
- Creare un elenco di controllo delle unità di distribuzione. L'elenco sarà univoco per le esigenze, ma deve includere: script di distribuzione, connessioni di inserimento, strumenti bi e altre configurazioni importanti.
Passaggio successivo
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per