Mapping dello schema e del tipo di dati nell'attività di copia
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita.
Questo articolo descrive come l'attività di copia di Azure Data Factory esegue il mapping dello schema e il mapping dei tipi di dati dai dati di origine ai dati sink.
Mapping dello schema
Mapping predefinito
Per impostazione predefinita, l'attività di copia esegue il mapping dei dati di origine al sink in base ai nomi di colonna in modo con distinzione tra maiuscole e minuscole. Se il sink non esiste, ad esempio la scrittura in file, i nomi dei campi di origine verranno mantenuti come nomi di sink. Se il sink esiste già, deve contenere tutte le colonne copiate dall'origine. Tale mapping predefinito supporta schemi flessibili e deviazioni dello schema dall'origine al sink dall'esecuzione all'esecuzione. Tutti i dati restituiti dall'archivio dati di origine possono essere copiati nel sink.
Se l'origine è un file di testo senza riga di intestazione, il mapping esplicito è necessario perché l'origine non contiene nomi di colonna.
Mapping esplicito
È anche possibile specificare il mapping esplicito per personalizzare il mapping di colonne/campi dall'origine al sink in base alle esigenze. Con il mapping esplicito, è possibile copiare solo i dati di origine parziale nel sink o eseguire il mapping dei dati di origine al sink con nomi diversi o modificare la forma dei dati tabulari/gerarchici. Attività di copia:
- Legge i dati dall'origine e determina lo schema di origine.
- Applica il mapping definito.
- Scrive i dati nel sink.
Altre informazioni su:
- Origine tabulare in sink tabulare
- Origine gerarchica in sink tabulare
- Origine tabulare/gerarchica nel sink gerarchico
È possibile configurare il mapping nella scheda Creazione interfaccia utente -> attività di copia -> mapping oppure specificare il mapping a livello di codice nell'attività di copia ->translator proprietà . Le proprietà seguenti sono supportate in translator -mappings> matrice -> oggetti ->source e sink, che puntano alla colonna/campo specifico per eseguire il mapping dei dati.
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| name | Nome della colonna/campo di origine o sink. Applicare per l'origine tabulare e il sink. | Sì |
| ordinal | Indice di colonna. Inizia da 1. Applicare e obbligatorio quando si usa testo delimitato senza riga di intestazione. |
No |
| path | Espressione di percorso JSON per ogni campo da estrarre o mappare. Applicare per origini gerarchiche e sink, ad esempio Azure Cosmos DB, MongoDB o connettori REST. Per i campi nell'oggetto radice, il percorso JSON inizia con radice $; per i campi all'interno della matrice scelta dalla collectionReference proprietà , il percorso JSON inizia dall'elemento della matrice senza $. |
No |
| type | Tipo di dati provvisorio della colonna di origine o sink. In generale, non è necessario specificare o modificare questa proprietà. Altre informazioni sul mapping dei tipi di dati. | No |
| Impostazioni cultura | Impostazioni cultura della colonna di origine o sink. Applicare quando il tipo è Datetime o Datetimeoffset. Il valore predefinito è en-us.In generale, non è necessario specificare o modificare questa proprietà. Altre informazioni sul mapping dei tipi di dati. |
No |
| format | Stringa di formato da usare quando il tipo è Datetime o Datetimeoffset. Per informazioni su come formattare datetime, vedere Stringhe di formato di data e ora personalizzato. In generale, non è necessario specificare o modificare questa proprietà. Altre informazioni sul mapping dei tipi di dati. |
No |
Le proprietà seguenti sono supportate translator in oltre a mappings:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| collectionReference | Applicare quando si copiano dati da un'origine gerarchica, ad esempio Azure Cosmos DB, MongoDB o connettori REST. Per eseguire l'iterazione dei dati ed estrarli dagli oggetti presenti nel campo di una matrice con lo stesso modello e convertirli in una struttura per riga e per oggetto, specificare il percorso JSON di tale matrice per eseguire il cross apply. |
No |
Origine tabulare in sink tabulare
Ad esempio, per copiare dati da Salesforce in database SQL di Azure ed eseguire il mapping esplicito di tre colonne:
Nella scheda Copy Activity - Mapping (Attività di copia -> mapping) fare clic sul pulsante Import schemas (Importa schemi ) per importare gli schemi di origine e sink.
Eseguire il mapping dei campi necessari ed escludere/eliminare il resto.

Lo stesso mapping può essere configurato come segue nel payload dell'attività di copia (vedere translator):
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "SalesforceSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "name": "Id" },
"sink": { "name": "CustomerID" }
},
{
"source": { "name": "Name" },
"sink": { "name": "LastName" }
},
{
"source": { "name": "LastModifiedDate" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Per copiare dati da file di testo delimitati senza riga di intestazione, le colonne sono rappresentate da ordinali anziché da nomi.
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "DelimitedTextSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "ordinal": "1" },
"sink": { "name": "CustomerID" }
},
{
"source": { "ordinal": "2" },
"sink": { "name": "LastName" }
},
{
"source": { "ordinal": "3" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Origine gerarchica in sink tabulare
Quando si copiano dati dall'origine gerarchica al sink tabulare, l'attività di copia supporta le funzionalità seguenti:
- Estrarre dati da oggetti e matrici.
- Applicare più oggetti con lo stesso modello da una matrice, nel qual caso per convertire un oggetto JSON in più record nel risultato tabulare.
Per una trasformazione da gerarchica a tabulare più avanzata, è possibile usare Flusso di dati.
Ad esempio, se si dispone di un documento MongoDB di origine con il contenuto seguente:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
E si vuole copiarlo in un file di testo nel formato seguente con la riga di intestazione, appiattindo i dati all'interno della matrice (order_pd e order_price) e cross join con le informazioni radice comuni (numero, data e città):
| orderNumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
È possibile definire tale mapping nell'interfaccia utente di creazione di Data Factory:
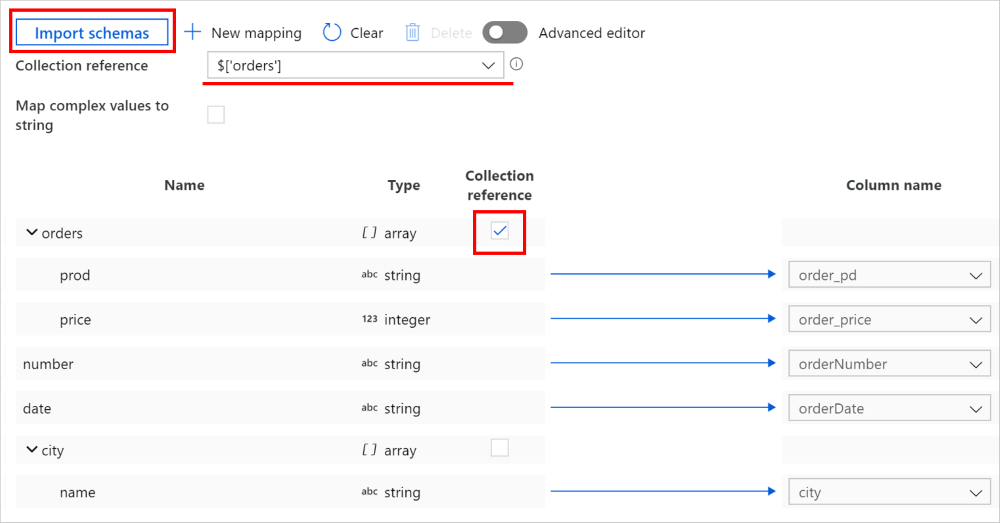
Nella scheda Copy Activity - Mapping (Attività di copia -> mapping) fare clic sul pulsante Import schemas (Importa schemi ) per importare gli schemi di origine e sink. Man mano che il servizio esegue l'esempio dei primi oggetti durante l'importazione dello schema, se un campo non viene visualizzato, è possibile aggiungerlo al livello corretto nella gerarchia. Passare il puntatore del mouse su un nome di campo esistente e scegliere di aggiungere un nodo, un oggetto o una matrice.
Selezionare la matrice da cui eseguire l'iterazione ed estrarre i dati. Verrà popolato automaticamente come riferimento alla raccolta. Si noti che per tale operazione è supportata solo una singola matrice.
Eseguire il mapping dei campi necessari al sink. Il servizio determina automaticamente i percorsi JSON corrispondenti per il lato gerarchico.
Nota
Per i record in cui la matrice contrassegnata come riferimento alla raccolta è vuota e la casella di controllo è selezionata, l'intero record viene ignorato.
È anche possibile passare all'editor avanzato, nel qual caso è possibile visualizzare e modificare direttamente i percorsi JSON dei campi. Se si sceglie di aggiungere un nuovo mapping in questa visualizzazione, specificare il percorso JSON.
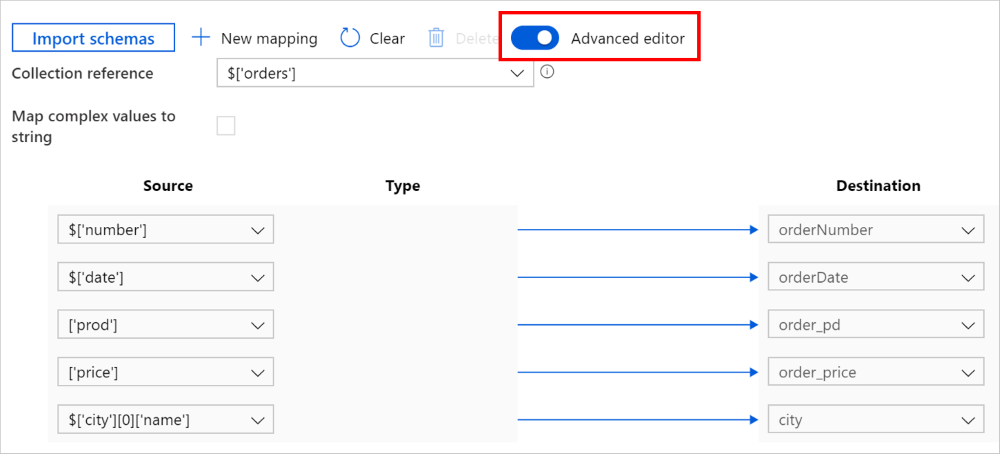
Lo stesso mapping può essere configurato come segue nel payload dell'attività di copia (vedere translator):
{
"name": "CopyActivityHierarchicalToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "MongoDbV2Source" },
"sink": { "type": "DelimitedTextSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "path": "$['number']" },
"sink": { "name": "orderNumber" }
},
{
"source": { "path": "$['date']" },
"sink": { "name": "orderDate" }
},
{
"source": { "path": "['prod']" },
"sink": { "name": "order_pd" }
},
{
"source": { "path": "['price']" },
"sink": { "name": "order_price" }
},
{
"source": { "path": "$['city'][0]['name']" },
"sink": { "name": "city" }
}
],
"collectionReference": "$['orders']"
}
},
...
}
Origine tabulare/gerarchica nel sink gerarchico
Il flusso dell'esperienza utente è simile all'origine gerarchica al sink tabulare.
Quando si copiano dati dall'origine tabulare al sink gerarchico, la scrittura in matrice all'interno dell'oggetto non è supportata.
Quando si copiano dati dall'origine gerarchica al sink gerarchico, è anche possibile mantenere la gerarchia dell'intero livello selezionando l'oggetto/matrice e mappandolo al sink senza toccare i campi interni.
Per una trasformazione della forma dei dati più avanzata, è possibile usare Flusso di dati.
Parametrizzare il mapping
Se si vuole creare una pipeline templatizzata per copiare dinamicamente un numero elevato di oggetti, determinare se è possibile sfruttare il mapping predefinito o definire il mapping esplicito per i rispettivi oggetti.
Se è necessario eseguire il mapping esplicito, è possibile:
Definire un parametro con tipo di oggetto a livello di pipeline,
mappingad esempio .Parametrizza il mapping: nella scheda Attività di copia -> Mapping scegliere di aggiungere contenuto dinamico e selezionare il parametro precedente. Il payload dell'attività sarà il seguente:
{ "name": "CopyActivityHierarchicalToTabular", "type": "Copy", "typeProperties": { "source": {...}, "sink": {...}, "translator": { "value": "@pipeline().parameters.mapping", "type": "Expression" }, ... } }Costruire il valore da passare al parametro di mapping. Deve essere l'intero oggetto della
translatordefinizione, fare riferimento agli esempi nella sezione di mapping esplicito . Ad esempio, per l'origine tabulare in una copia sink tabulare, il valore deve essere{"type":"TabularTranslator","mappings":[{"source":{"name":"Id"},"sink":{"name":"CustomerID"}},{"source":{"name":"Name"},"sink":{"name":"LastName"}},{"source":{"name":"LastModifiedDate"},"sink":{"name":"ModifiedDate"}}]}.
Mapping del tipo di dati
attività Copy esegue il mapping dei tipi di origine ai tipi di sink con il flusso seguente:
- Eseguire la conversione da tipi di dati nativi di origine a tipi di dati provvisori usati dalle pipeline di Azure Data Factory e Synapse.
- Convertire automaticamente il tipo di dati provvisorio in base alle esigenze per trovare le corrispondenze con i tipi di sink corrispondenti, applicabili sia per il mapping predefinito che per il mapping esplicito.
- Eseguire la conversione da tipi di dati provvisori a tipi di dati nativi sink.
attività Copy supporta attualmente i tipi di dati provvisori seguenti: Boolean, Byte, Byte array, Datetime, DatetimeOffset, Decimal, Double, GUID, Int16, Int32, Int64, SByte, Single, String, Timespan, UInt16, UInt32 e UInt64.
Le conversioni dei tipi di dati seguenti sono supportate tra i tipi provvisori dall'origine al sink.
| Origine\Sink | Booleano | Matrice di byte | Data/ora | Decimale | Virgola mobile | GUID | Intero | String | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| Booleano | ✓ | ✓ | ✓ | ✓ | |||||
| Matrice di byte | ✓ | ✓ | |||||||
| Data/ora | ✓ | ✓ | |||||||
| Decimale | ✓ | ✓ | ✓ | ✓ | |||||
| Virgola mobile | ✓ | ✓ | ✓ | ✓ | |||||
| GUID | ✓ | ✓ | |||||||
| Intero | ✓ | ✓ | ✓ | ✓ | |||||
| String | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| TimeSpan | ✓ | ✓ |
(1) Date/Time include DateTime e DateTimeOffset.
(2) Float-point include Single e Double.
(3) Integer include SByte, Byte, Int16, UInt16, Int32, UInt32, Int64 e UInt64.
Nota
- Attualmente questa conversione del tipo di dati è supportata durante la copia tra dati tabulari. Le origini/sink gerarchiche non sono supportate, il che significa che non esiste alcuna conversione del tipo di dati definito dal sistema tra i tipi provvisori di origine e sink.
- Questa funzionalità funziona con il modello di set di dati più recente. Se questa opzione non viene visualizzata dall'interfaccia utente, provare a creare un nuovo set di dati.
Le proprietà seguenti sono supportate nell'attività di copia per la conversione dei tipi di dati (nella translator sezione relativa alla creazione a livello di codice):
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| typeConversion | Abilitare la nuova esperienza di conversione dei tipi di dati. Il valore predefinito è false a causa della compatibilità con le versioni precedenti. Per le nuove attività di copia create tramite l'interfaccia utente di creazione di Data Factory a partire dalla fine di giugno 2020, questa conversione dei tipi di dati è abilitata per impostazione predefinita per un'esperienza ottimale ed è possibile visualizzare le impostazioni di conversione dei tipi seguenti nell'attività di copia-> scheda mapping per gli scenari applicabili. Per creare la pipeline a livello di codice, è necessario impostare in modo esplicito la proprietà su typeConversion true per abilitarla.Per le attività di copia esistenti create prima del rilascio di questa funzionalità, non verranno visualizzate le opzioni di conversione dei tipi nell'interfaccia utente di creazione per garantire la compatibilità con le versioni precedenti. |
No |
| typeConversion Impostazioni | Gruppo di impostazioni di conversione dei tipi. Applica quando typeConversion è impostato su true. Tutte le proprietà seguenti sono incluse in questo gruppo. |
No |
Sotto typeConversionSettings |
||
| allowDataTruncation | Consente il troncamento dei dati durante la conversione dei dati di origine in sink con tipo diverso durante la copia, ad esempio da decimale a integer, da DatetimeOffset a Datetime. Il valore predefinito è true. |
No |
| treatBooleanAsNumber | Considerare i valori booleani come numeri, ad esempio true come 1. Il valore predefinito è false. |
No |
| Datetimeformat | Stringa di formato durante la conversione tra date senza offset del fuso orario e stringhe, ad esempio yyyy-MM-dd HH:mm:ss.fff. Per informazioni dettagliate, vedere Stringhe di formato di data e ora personalizzate. |
No |
| dateTimeOffsetFormat | Formattare la stringa durante la conversione tra date con offset di fuso orario e stringhe, yyyy-MM-dd HH:mm:ss.fff zzzad esempio . Per informazioni dettagliate, vedere Stringhe di formato di data e ora personalizzate. |
No |
| timeSpanFormat | Stringa di formato durante la conversione tra periodi di tempo e stringhe, ad esempio dd\.hh\:mm. Per informazioni dettagliate, vedere Stringhe di formato TimeSpan personalizzate. |
No |
| Impostazioni cultura | Informazioni sulle impostazioni cultura da usare per convertire i tipi, ad esempio en-us o fr-fr. |
No |
Esempio:
{
"name": "CopyActivity",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ParquetSource"
},
"sink": {
"type": "SqlSink"
},
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": true,
"dateTimeFormat": "yyyy-MM-dd HH:mm:ss.fff",
"dateTimeOffsetFormat": "yyyy-MM-dd HH:mm:ss.fff zzz",
"timeSpanFormat": "dd\.hh\:mm",
"culture": "en-gb"
}
}
},
...
}
Modalità legacy
Nota
I modelli seguenti per eseguire il mapping di colonne/campi di origine al sink sono ancora supportati perché sono compatibili con le versioni precedenti. È consigliabile usare il nuovo modello indicato nel mapping dello schema. L'interfaccia utente di creazione è passata alla generazione del nuovo modello.
Mapping di colonne alternativo (modello legacy)
È possibile specificare l'attività di copia :>translator>columnMappings per eseguire il mapping tra dati a forma tabulare. In questo caso, la sezione "structure" è necessaria sia per i set di dati di input che per i set di dati di output. Il mapping di colonne supporta il mapping di tutte le colonne o di un sottoinsieme delle colonne nella "struttura" del set di dati di origine a tutte le colonne della "struttura" del set di dati del sink. Le seguenti sono condizioni di errore che generano un'eccezione:
- Il risultato della query dell'archivio dati di origine non ha un nome colonna specificato nella sezione "struttura" del set di dati di input.
- L'archivio dati sink (con schema predefinito) non ha un nome colonna specificato nella sezione "struttura" del set di dati di output.
- Un numero inferiore o superiore di colonne nella "struttura" del set di dati di sink rispetto a quanto specificato nel mapping.
- Mapping duplicato.
Nell'esempio seguente il set di dati di input ha una struttura e punta a una tabella in un database Oracle locale.
{
"name": "OracleDataset",
"properties": {
"structure":
[
{ "name": "UserId"},
{ "name": "Name"},
{ "name": "Group"}
],
"type": "OracleTable",
"linkedServiceName": {
"referenceName": "OracleLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SourceTable"
}
}
}
In questo esempio il set di dati di output ha una struttura e punta a una tabella in Salesforce.
{
"name": "SalesforceDataset",
"properties": {
"structure":
[
{ "name": "MyUserId"},
{ "name": "MyName" },
{ "name": "MyGroup"}
],
"type": "SalesforceObject",
"linkedServiceName": {
"referenceName": "SalesforceLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SinkTable"
}
}
}
Il codice JSON seguente definisce un'attività di copia in una pipeline. Colonne di origine mappate alle colonne nel sink usando la proprietà translator ->columnMappings .
{
"name": "CopyActivity",
"type": "Copy",
"inputs": [
{
"referenceName": "OracleDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "SalesforceDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": { "type": "OracleSource" },
"sink": { "type": "SalesforceSink" },
"translator":
{
"type": "TabularTranslator",
"columnMappings":
{
"UserId": "MyUserId",
"Group": "MyGroup",
"Name": "MyName"
}
}
}
}
La sintassi di "columnMappings": "UserId: MyUserId, Group: MyGroup, Name: MyName" per specificare il mapping di colonne è ancora supportata.
Mapping dello schema alternativo (modello legacy)
È possibile specificare l'attività di copia:>translator>schemaMapping per eseguire il mapping tra dati a forma gerarchica e dati a forma tabulare, ad esempio copiare da MongoDB/REST a file di testo e copiare da Oracle ad Azure Cosmos DB per MongoDB. Nella sezione translator dell'attività di copia sono supportate le proprietà seguenti:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| type | La proprietà type del traduttore dell'attività di copia deve essere impostata su: Tabulare Traduttore | Sì |
| schemaMapping | Raccolta di coppie chiave-valore, che rappresenta la relazione di mapping dal lato origine al lato sink. - Chiave: rappresenta l'origine. Per l'origine tabulare, specificare il nome della colonna come definito nella struttura del set di dati. Per l'origine gerarchica, specificare l'espressione di percorso JSON per ogni campo da estrarre e mappare. - Valore: rappresenta il sink. Per il sink tabulare, specificare il nome della colonna come definito nella struttura del set di dati. Per il sink gerarchico, specificare l'espressione di percorso JSON per ogni campo da estrarre ed eseguire il mapping. Nel caso dei dati gerarchici, per i campi nell'oggetto radice, il percorso JSON inizia con root $; per i campi all'interno della matrice scelta dalla collectionReference proprietà , il percorso JSON inizia dall'elemento della matrice. |
Sì |
| collectionReference | Per eseguire l'iterazione dei dati ed estrarli dagli oggetti presenti nel campo di una matrice con lo stesso modello e convertirli in una struttura per riga e per oggetto, specificare il percorso JSON di tale matrice per eseguire il cross apply. Questa proprietà è supportata solo quando l'origine è costituita da dati gerarchici. | No |
Esempio: copiare da MongoDB a Oracle:
Se ad esempio si ha un il documento di MongoDB con il contenuto seguente:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
e si vuole copiare tale contenuto in una tabella SQL di Azure nel formato seguente, rendendo flat i dati nella matrice (order_pd e order_price) e nel crossjoin con le informazioni radice comuni (numero, data e città):
| orderNumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Configurare la regola di mapping dello schema come l'esempio JSON seguente di attività di copia:
{
"name": "CopyFromMongoDBToOracle",
"type": "Copy",
"typeProperties": {
"source": {
"type": "MongoDbV2Source"
},
"sink": {
"type": "OracleSink"
},
"translator": {
"type": "TabularTranslator",
"schemaMapping": {
"$.number": "orderNumber",
"$.date": "orderDate",
"prod": "order_pd",
"price": "order_price",
"$.city[0].name": "city"
},
"collectionReference": "$.orders"
}
}
}
Contenuto correlato
Vedere gli altri articoli relativi all'attività di copia: