Disponibilità generale del mapping di flussi di dati in Azure Data Factory
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
Che cosa sono i flussi di dati di mapping?
I flussi di dati di mapping sono trasformazioni dei dati progettate visivamente in Azure Data Factory. I flussi di dati consentono ai data engineer di sviluppare la logica di trasformazione dei dati senza scrivere codice. I flussi di dati risultanti vengono eseguiti come attività all'interno delle pipeline di Azure Data Factory usando cluster Apache Spark con scale-out. Le attività dei flussi di dati possono essere rese operative tramite le funzionalità esistenti di pianificazione, controllo, flusso e monitoraggio di Azure Data Factory.
I flussi di dati di mapping offrono un'esperienza visiva completamente priva di codifica necessaria. I flussi di dati vengono eseguiti in cluster di esecuzione gestiti da Azure Data Factory per l'elaborazione scale-out dei dati. Azure Data Factory gestisce automaticamente tutte le attività di conversione del codice, ottimizzazione dei percorsi ed esecuzione dei processi dei flussi di dati.
Attività iniziali
I flussi di dati vengono creati dal riquadro delle risorse factory, ad esempio pipeline e set di dati. Per creare un flusso di dati, selezionare il segno più accanto a Risorse factory e quindi selezionare Flusso di dati.
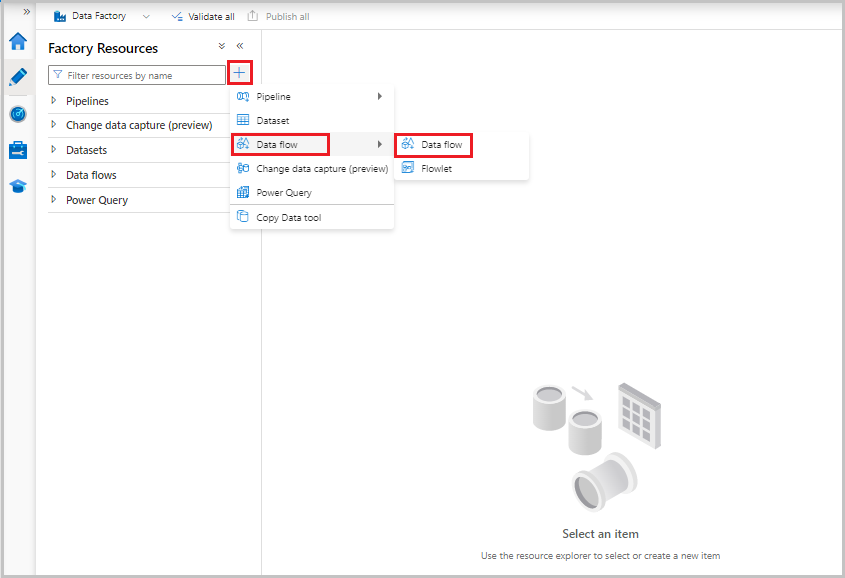 Questa azione consente di accedere all'area di disegno del flusso di dati, in cui è possibile creare la logica di trasformazione. Selezionare Aggiungi origine per iniziare a configurare la trasformazione di origine. Per altre informazioni, vedere Trasformazione origine.
Questa azione consente di accedere all'area di disegno del flusso di dati, in cui è possibile creare la logica di trasformazione. Selezionare Aggiungi origine per iniziare a configurare la trasformazione di origine. Per altre informazioni, vedere Trasformazione origine.
Creazione di flussi di dati
Il flusso di dati di mapping ha un'area di disegno di creazione univoca progettata per semplificare la creazione della logica di trasformazione. L'area di disegno del flusso di dati è suddivisa in tre parti: la barra superiore, il grafico e il pannello di configurazione.
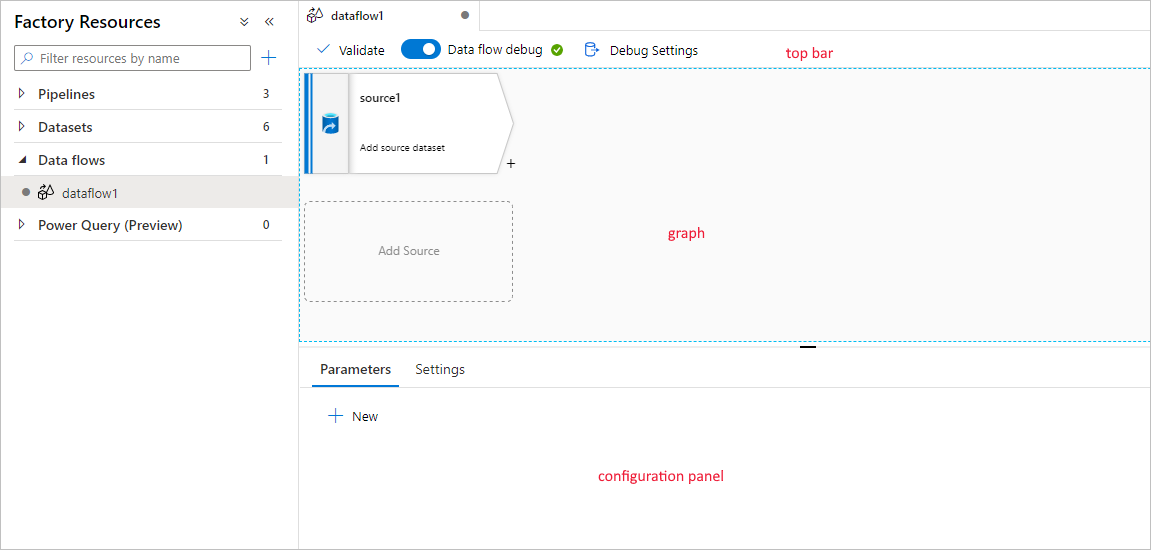
Grafico
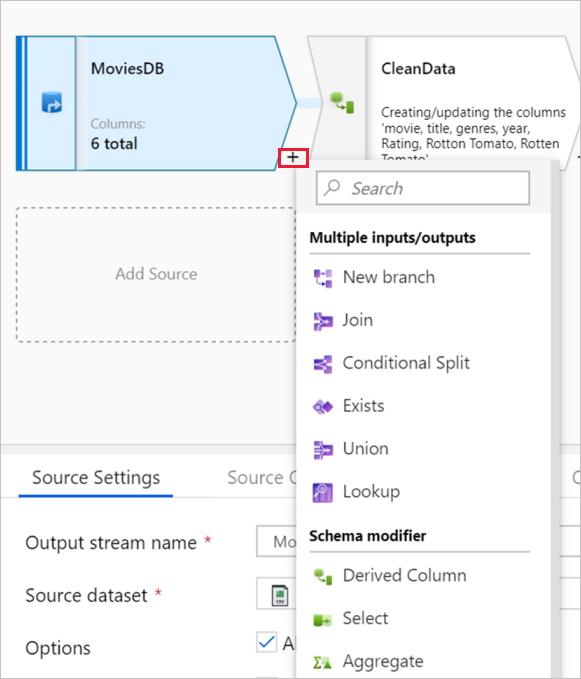
Il grafico visualizza il flusso di trasformazione. Mostra la derivazione dei dati di origine durante il flusso in uno o più sink. Per aggiungere una nuova origine, selezionare Aggiungi origine. Per aggiungere una nuova trasformazione, selezionare il segno più in basso a destra di una trasformazione esistente. Altre informazioni su come gestire il grafico del flusso di dati.
Pannello di configurazione
Il pannello di configurazione mostra le impostazioni specifiche della trasformazione attualmente selezionata. Se non è selezionata alcuna trasformazione, viene visualizzato il flusso di dati. Nella configurazione complessiva del flusso di dati è possibile aggiungere parametri tramite la scheda Parametri . Per altre informazioni, vedere Mapping dei parametri del flusso di dati.
Ogni trasformazione contiene almeno quattro schede di configurazione.
Impostazioni di trasformazione
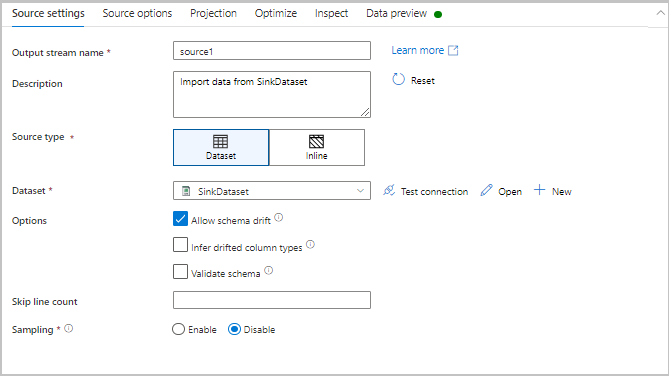
La prima scheda nel riquadro di configurazione di ogni trasformazione contiene le impostazioni specifiche di tale trasformazione. Per altre informazioni, vedere la pagina della documentazione della trasformazione.
Ottimizzazione
La scheda Ottimizza contiene le impostazioni per configurare gli schemi di partizionamento. Per altre informazioni su come ottimizzare i flussi di dati, vedere la guida alle prestazioni del flusso di dati di mapping.
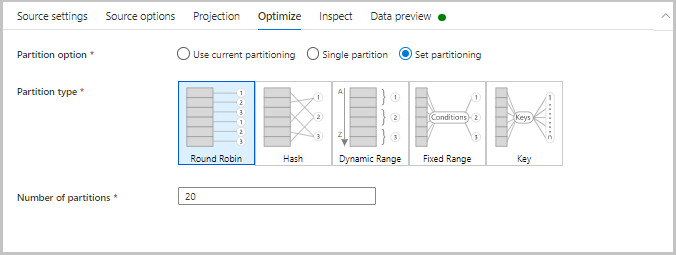
Controllare
La scheda Ispeziona fornisce una visualizzazione nei metadati del flusso di dati che si sta trasformando. È possibile visualizzare i conteggi delle colonne, le colonne modificate, le colonne aggiunte, i tipi di dati, l'ordine delle colonne e i riferimenti alle colonne. Inspect è una visualizzazione di sola lettura dei metadati. Non è necessario che la modalità di debug sia abilitata per visualizzare i metadati nel riquadro Ispeziona .
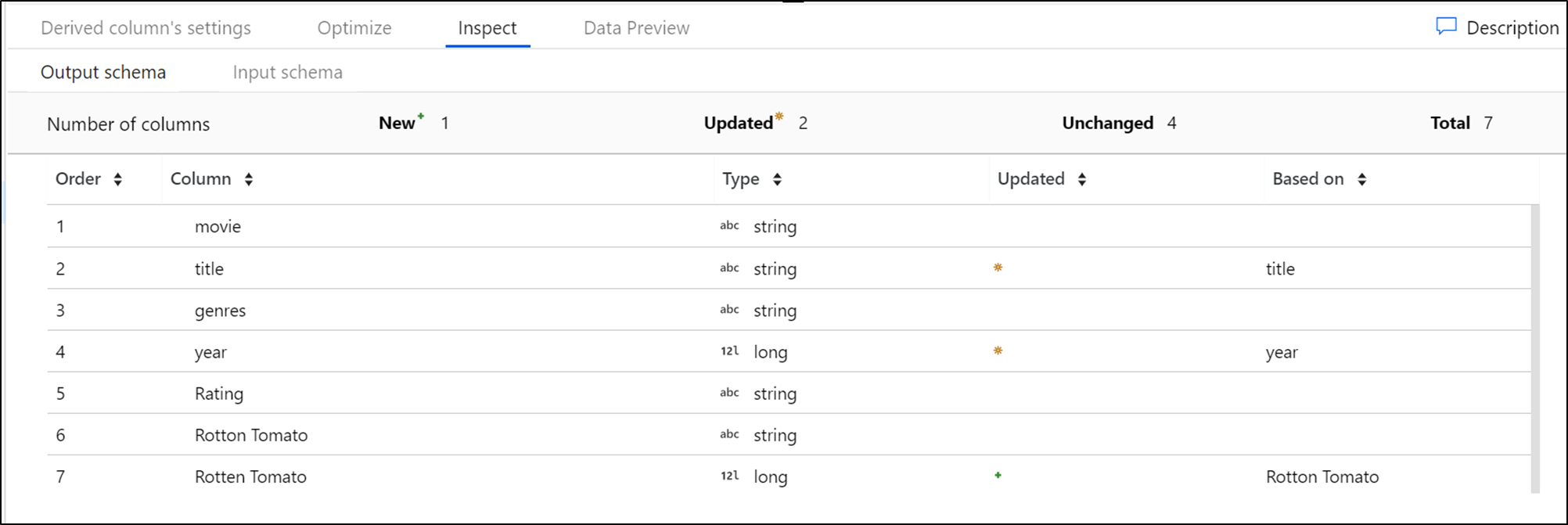
Quando si modifica la forma dei dati tramite trasformazioni, il flusso delle modifiche ai metadati verrà visualizzato nel riquadro Ispeziona . Se nella trasformazione di origine non è presente uno schema definito, i metadati non saranno visibili nel riquadro Ispeziona . La mancanza di metadati è comune negli scenari di deriva dello schema.
Anteprima dati
Se la modalità di debug è attivata, la scheda Anteprima dati fornisce uno snapshot interattivo dei dati in ogni trasformazione. Per altre informazioni, vedere Anteprima dei dati in modalità di debug.
Barra superiore
La barra superiore contiene azioni che influiscono sull'intero flusso di dati, ad esempio il salvataggio e la convalida. È anche possibile visualizzare il codice JSON sottostante e lo script del flusso di dati della logica di trasformazione. Per altre informazioni, vedere Lo script del flusso di dati.
Trasformazioni disponibili
Visualizzare la panoramica della trasformazione del flusso di dati per il mapping per ottenere un elenco delle trasformazioni disponibili.
Tipi di dati del flusso di dati
- array
- binary
- boolean
- complex
- decimal (include precisione)
- data
- float
- integer
- long
- mappa
- short
- string
- timestamp
Attività flusso di dati
I flussi di dati di mapping vengono operativi all'interno delle pipeline di Azure Data Factory usando l'attività del flusso di dati. È necessario specificare il runtime di integrazione da usare e passare i valori dei parametri. Per altre informazioni, vedere Runtime di integrazione di Azure.
Modalità di debug
La modalità di debug consente di visualizzare in modo interattivo i risultati di ogni passaggio di trasformazione durante la compilazione e il debug dei flussi di dati. La sessione di debug può essere usata sia in quando si compila la logica del flusso di dati che si esegue il debug della pipeline con le attività del flusso di dati. Per altre informazioni, vedere la documentazione sulla modalità di debug.
Monitoraggio dei flussi di dati
Il flusso di dati per mapping si integra con le funzionalità di monitoraggio di Azure Data Factory esistenti. Per informazioni su come comprendere l'output di monitoraggio del flusso di dati, vedere Monitoraggio dei flussi di dati di mapping.
Il team di Azure Data Factory ha creato una guida all'ottimizzazione delle prestazioni per ottimizzare il tempo di esecuzione dei flussi di dati dopo la compilazione della logica di business.
Aree disponibili
I flussi di dati di mapping sono disponibili nelle aree seguenti in Azure Data Factory:
| Regione Azure | Flussi di dati in Azure Data Factory |
|---|---|
| Australia centrale | |
| Australia centrale 2 | |
| Australia orientale | ✓ |
| Australia sud-orientale | ✓ |
| Brasile meridionale | ✓ |
| Canada centrale | ✓ |
| India centrale | ✓ |
| Stati Uniti centrali | ✓ |
| Cina orientale | |
| Cina orientale 2 | |
| Cina (non a livello di area) | |
| Cina settentrionale | ✓ |
| Cina settentrionale 2 | ✓ |
| Cina settentrionale 3 | ✓ |
| Asia orientale | ✓ |
| Stati Uniti orientali | ✓ |
| Stati Uniti orientali 2 | ✓ |
| Francia centrale | ✓ |
| Francia meridionale | |
| Germania centrale (sovrano) | |
| Germania non a livello di area (sovrano) | |
| Germania settentrionale (pubblico) | |
| Germania nord-orientale (sovrano) | |
| Germania centro-occidentale (pubblico) | ✓ |
| Giappone orientale | ✓ |
| Giappone occidentale | ✓ |
| Corea centrale | ✓ |
| Corea meridionale | |
| Stati Uniti centro-settentrionali | ✓ |
| Europa settentrionale | ✓ |
| Norvegia orientale | ✓ |
| Norvegia occidentale | |
| Sudafrica settentrionale | ✓ |
| Sudafrica occidentale | |
| Stati Uniti centro-meridionali | |
| India meridionale | ✓ |
| Asia sud-orientale | ✓ |
| Svizzera settentrionale | ✓ |
| Svizzera occidentale | |
| Emirati Arabi Uniti centrali | |
| Emirati Arabi Uniti settentrionali | ✓ |
| Regno Unito meridionale | ✓ |
| Regno Unito occidentale | |
| US DoD Central | |
| US DoD East | |
| US Gov Arizona | ✓ |
| US Gov (non a livello di area) | |
| US Gov Texas | |
| US Gov Virginia | ✓ |
| Stati Uniti centro-occidentali | |
| Europa occidentale | ✓ |
| India occidentale | ✓ |
| Stati Uniti occidentali | ✓ |
| Stati Uniti occidentali 2 | ✓ |
| Stati Uniti occidentali 3 | ✓ |
Contenuto correlato
- Informazioni su come creare una trasformazione di origine.
- Informazioni su come compilare i flussi di dati in modalità di debug.