Trasformazione dell'origine nei flussi di dati di mapping
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
I flussi di dati sono disponibili sia in Azure Data Factory che in Azure Synapse Pipelines. Questo articolo si applica ai flussi di dati di mapping. Se non si ha esperienza con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati usando un flusso di dati di mapping.
Una trasformazione di origine configura l'origine dati per il flusso di dati. Quando si progettano flussi di dati, il primo passaggio consiste sempre nella configurazione di una trasformazione di origine. Per aggiungere un'origine, selezionare la casella Aggiungi origine nell'area di disegno del flusso di dati.
Ogni flusso di dati richiede almeno una trasformazione di origine, ma è possibile aggiungere tutte le origini necessarie per completare le trasformazioni dei dati. È possibile unire tali origini con un join, una ricerca o una trasformazione unione.
Ogni trasformazione di origine è associata esattamente a un set di dati o a un servizio collegato. Il set di dati definisce la forma e la posizione dei dati da cui scrivere o leggere. Se si usa un set di dati basato su file, è possibile usare caratteri jolly ed elenchi di file nell'origine per lavorare con più file alla volta.
Set di dati inline
La prima decisione presa quando si crea una trasformazione di origine è se le informazioni di origine vengono definite all'interno di un oggetto set di dati o all'interno della trasformazione di origine. La maggior parte dei formati è disponibile solo in uno o nell'altro. Per informazioni su come usare un connettore specifico, vedere il documento del connettore appropriato.
Quando un formato è supportato sia inline che in un oggetto set di dati, esistono vantaggi per entrambi. Gli oggetti set di dati sono entità riutilizzabili che possono essere usate in altri flussi di dati e attività, ad esempio Copy. Queste entità riutilizzabili sono particolarmente utili quando si usa uno schema con protezione avanzata. I set di dati non sono basati su Spark. In alcuni casi, potrebbe essere necessario eseguire l'override di determinate impostazioni o proiezione dello schema nella trasformazione di origine.
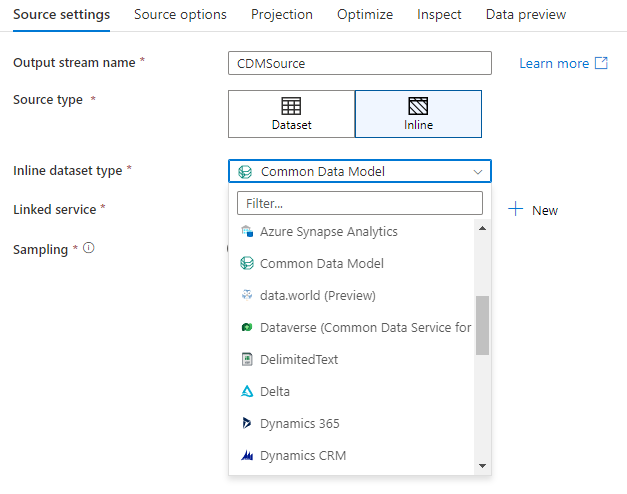
I set di dati inline sono consigliati quando si usano schemi flessibili, istanze di origine occasionali o origini con parametri. Se l'origine è fortemente parametrizzata, i set di dati inline consentono di non creare un oggetto fittizio. I set di dati inline sono basati su Spark e le relative proprietà sono native del flusso di dati.
Per usare un set di dati inline, selezionare il formato desiderato nel selettore Tipo di origine . Invece di selezionare un set di dati di origine, selezionare il servizio collegato a cui connettersi.
Opzioni schema
Poiché un set di dati inline viene definito all'interno del flusso di dati, non esiste uno schema definito associato al set di dati inline. Nella scheda Proiezione è possibile importare lo schema dei dati di origine e archiviare tale schema come proiezione di origine. In questa scheda è disponibile un pulsante "Opzioni schema" che consente di definire il comportamento del servizio di individuazione dello schema di Azure Data Factory.
- Usare lo schema proiettato: questa opzione è utile quando si dispone di un numero elevato di file di origine che ADF analizza come origine. Il comportamento predefinito di ADF consiste nell'individuare lo schema di ogni file di origine. Tuttavia, se si dispone di una proiezione predefinita già archiviata nella trasformazione di origine, è possibile impostarla su true e ADF ignora l'individuazione automatica di ogni schema. Con questa opzione attivata, la trasformazione di origine può leggere tutti i file in modo molto più veloce, applicando lo schema predefinito a ogni file.
- Consenti deriva dello schema: attivare la deriva dello schema in modo che il flusso di dati consenta nuove colonne non già definite nello schema di origine.
- Convalida schema: se si imposta questa opzione, il flusso di dati non riesce se una colonna e un tipo definito nella proiezione non corrispondono allo schema individuato dei dati di origine.
- Tipi di colonna derivati inferti: quando le nuove colonne deviate vengono identificate da ADF, tali nuove colonne vengono cast al tipo di dati appropriato usando l'inferenza automatica del tipo di ADF.
Database dell'area di lavoro (solo aree di lavoro di Synapse)
Nelle aree di lavoro di Azure Synapse è presente un'opzione aggiuntiva nelle trasformazioni dell'origine del flusso di dati denominate Workspace DB. In questo modo è possibile selezionare direttamente un database dell'area di lavoro di qualsiasi tipo disponibile come dati di origine senza richiedere servizi o set di dati collegati aggiuntivi. I database creati tramite i modelli di database di Azure Synapse sono accessibili anche quando si seleziona Database dell'area di lavoro.

Tipi di origine supportati
Il flusso di dati di mapping segue un approccio di estrazione, caricamento e trasformazione (ELT) e funziona con i set di dati di staging tutti in Azure. Attualmente, i set di dati seguenti possono essere usati in una trasformazione di origine.
Impostazioni specifici di questi connettori si trovano nel Scheda Opzioni di origine. Informazioni ed esempi di script del flusso di dati in queste impostazioni sono disponibili nella documentazione del connettore.
Le pipeline di Azure Data Factory e Synapse hanno accesso a più di 90 connettori nativi. Per includere dati da queste origini aggiuntive nel flusso di dati, usare l'attività di copia per caricare i dati in una delle aree di staging supportate.
Impostazioni origine
Dopo aver aggiunto un'origine, configurare tramite la scheda Impostazioni origine. Qui è possibile selezionare o creare il set di dati in corrispondenza dei punti di origine. È anche possibile selezionare le opzioni di schema e campionamento per i dati.
I valori di sviluppo per i parametri del set di dati possono essere configurati nelle impostazioni di debug. La modalità di debug deve essere attivata.
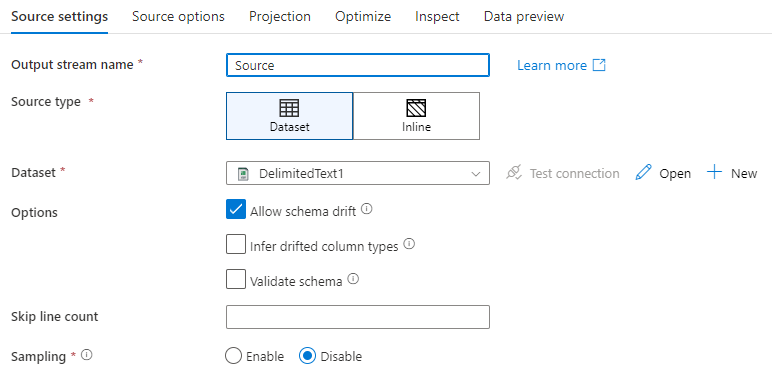
Nome del flusso di output: nome della trasformazione di origine.
Tipo di origine: scegliere se si vuole usare un set di dati inline o un oggetto set di dati esistente.
Test connessione: verificare se il servizio Spark del flusso di dati può connettersi correttamente al servizio collegato usato nel set di dati di origine. Per abilitare questa funzionalità, è necessario che la modalità di debug sia attivata.
Deriva dello schema: la deriva dello schema è la possibilità del servizio di gestire in modo nativo schemi flessibili nei flussi di dati senza dover definire in modo esplicito le modifiche alle colonne.
Selezionare la casella di controllo Consenti deriva dello schema se le colonne di origine cambiano spesso. Questa impostazione consente a tutti i campi di origine in ingresso di scorrere le trasformazioni nel sink.
Se si seleziona Infer drifted column types (Infer drifted column types) viene indicato al servizio di rilevare e definire i tipi di dati per ogni nuova colonna individuata. Con questa funzionalità disattivata, tutte le colonne deviate sono di tipo string.
Convalida schema: se è selezionata l'opzione Convalida schema , il flusso di dati non viene eseguito se i dati di origine in ingresso non corrispondono allo schema definito del set di dati.
Ignora conteggio righe: il campo Conteggio righe ignora specifica il numero di righe da ignorare all'inizio del set di dati.
Campionamento: abilitare il campionamento per limitare il numero di righe dall'origine. Usare questa impostazione per testare o campionare i dati dell'origine a scopo di debug. Ciò è molto utile quando si eseguono flussi di dati in modalità di debug da una pipeline.
Per verificare che l'origine sia configurata correttamente, attivare la modalità di debug e recuperare un'anteprima dei dati. Per altre informazioni, vedere Modalità di debug.
Nota
Quando la modalità di debug è attivata, la configurazione del limite di riga nelle impostazioni di debug sovrascrive l'impostazione di campionamento nell'origine durante l'anteprima dei dati.
Opzioni di origine
La scheda Opzioni origine contiene impostazioni specifiche del connettore e del formato scelto. Per altre informazioni ed esempi, vedere la documentazione del connettore pertinente. Sono inclusi dettagli come il livello di isolamento per le origini dati che lo supportano (ad esempio SQL Server locali, database SQL di Azure e istanze gestite di SQL di Azure) e altre impostazioni specifiche dell'origine dati.
Projection
Analogamente agli schemi nei set di dati, la proiezione in un'origine definisce le colonne di dati, i tipi e i formati dei dati di origine. Per la maggior parte dei tipi di set di dati, ad esempio SQL e Parquet, la proiezione in un'origine è fissa per riflettere lo schema definito in un set di dati. Quando i file di origine non sono fortemente tipizzato (ad esempio, file flat .csv anziché file Parquet), è possibile definire i tipi di dati per ogni campo nella trasformazione di origine.
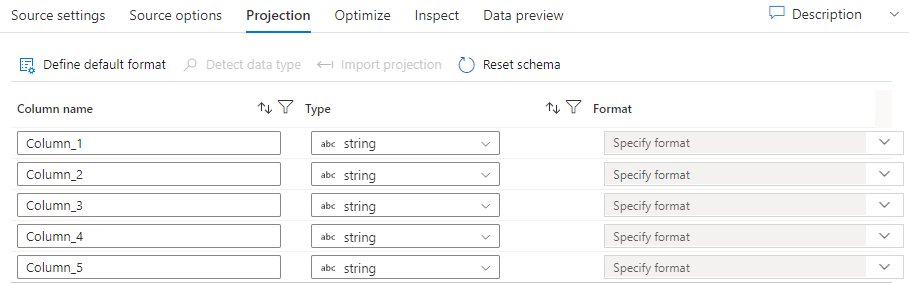
Se il file di testo non ha uno schema definito, selezionare Rileva tipo di dati in modo che il servizio eseduca i tipi di dati. Selezionare Definisci formato predefinito per impostare automaticamente i formati di dati predefiniti.
Reimposta lo schema reimposta la proiezione su ciò che viene definito nel set di dati a cui si fa riferimento.
Lo schema di sovrascrittura consente di modificare i tipi di dati proiettati qui nell'origine, sovrascrivendo i tipi di dati definiti dallo schema. In alternativa, è possibile modificare i tipi di dati della colonna in una trasformazione colonna derivata downstream. Usare una trasformazione select per modificare i nomi delle colonne.
Importa schema
Selezionare il pulsante Importa schema nella scheda Proiezione per usare un cluster di debug attivo per creare una proiezione dello schema. È disponibile in ogni tipo di origine. L'importazione dello schema esegue l'override della proiezione definita nel set di dati. L'oggetto set di dati non verrà modificato.
L'importazione dello schema è utile nei set di dati come Avro e Azure Cosmos DB che supportano strutture di dati complesse che non richiedono definizioni dello schema presenti nel set di dati. Per i set di dati inline, l'importazione dello schema è l'unico modo per fare riferimento ai metadati delle colonne senza deriva dello schema.
Ottimizzare la trasformazione dell'origine
La scheda Ottimizza consente di modificare le informazioni sulla partizione in ogni passaggio di trasformazione. Nella maggior parte dei casi, usare l'ottimizzazione del partizionamento corrente per la struttura di partizionamento ideale per un'origine.
Se si legge da un'origine database SQL di Azure, il partizionamento dell'origine personalizzato legge probabilmente i dati più velocemente. Il servizio legge query di grandi dimensioni effettuando connessioni al database in parallelo. Questo partizionamento di origine può essere eseguito su una colonna o usando una query.
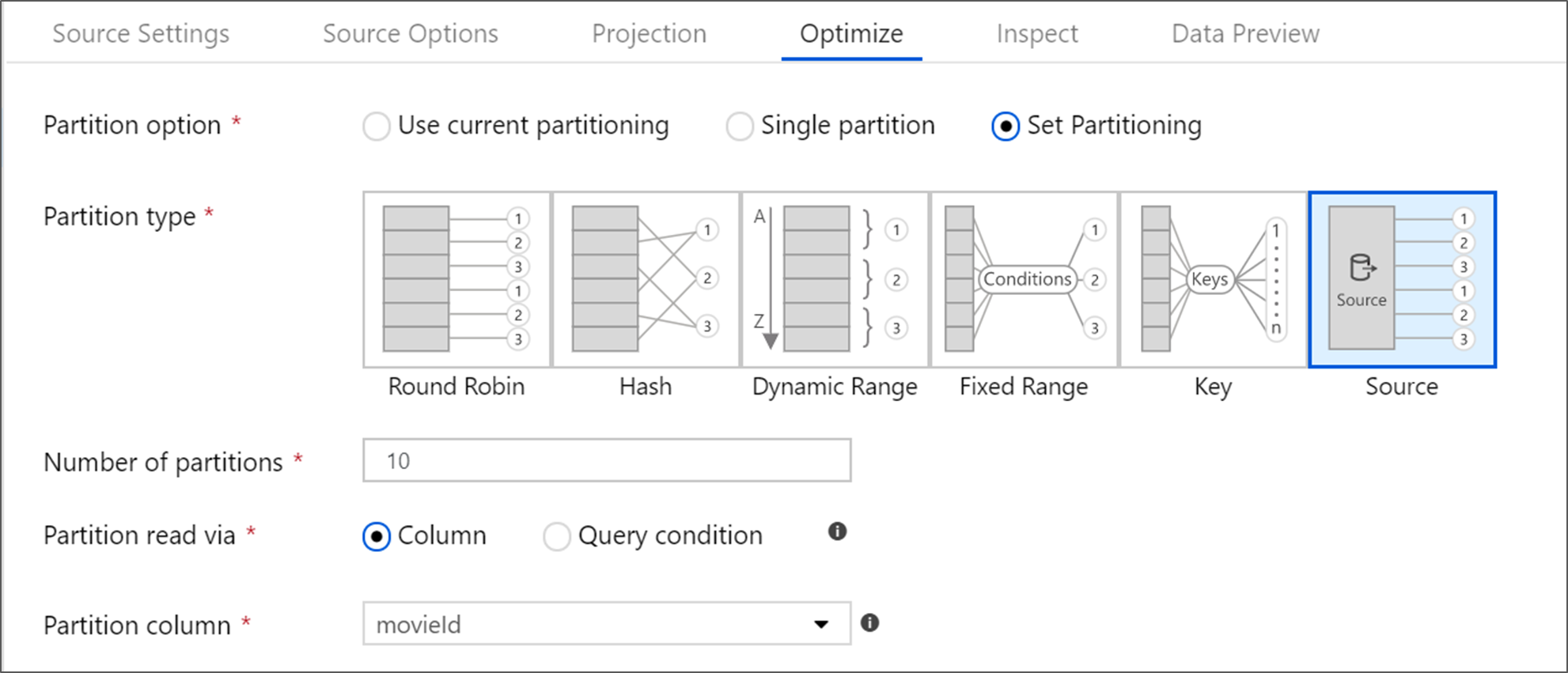
Per altre informazioni sull'ottimizzazione all'interno del flusso di dati di mapping, vedere la scheda Ottimizza.
Contenuto correlato
Iniziare a creare il flusso di dati con una trasformazione colonna derivata e una trasformazione select.