Elaborare file di testo a lunghezza fissa usando flussi di dati di mapping di Data Factory
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
Usando i flussi di dati di mapping in Microsoft Azure Data Factory, è possibile trasformare i dati da file di testo a larghezza fissa. Nell'attività seguente si definirà un set di dati per un file di testo senza un delimitatore e quindi si configureranno divisioni di sottostringa in base alla posizione ordinale.
Creare una pipeline
Selezionare +Nuova pipeline per creare una nuova pipeline.
Aggiungere un'attività del flusso di dati che verrà usata per l'elaborazione di file a larghezza fissa:
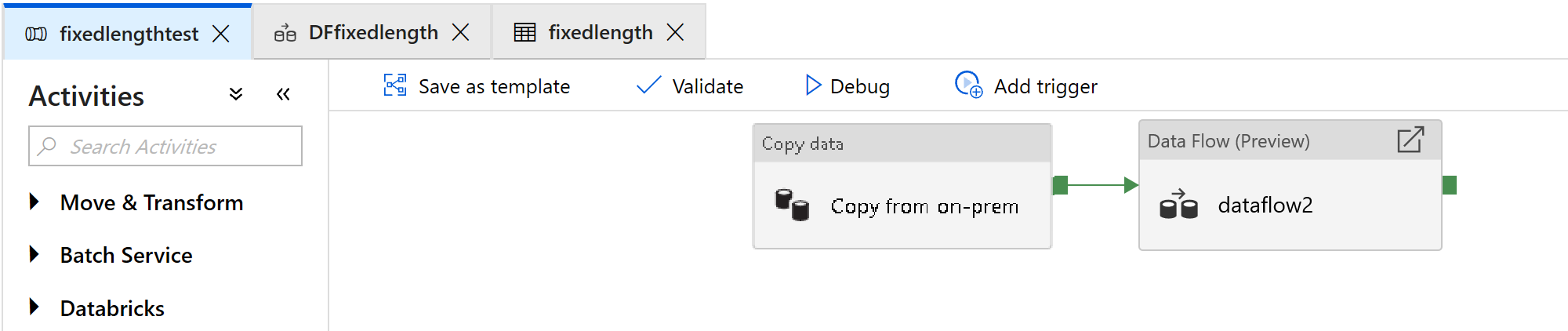
Nell'attività flusso di dati selezionare Nuovo flusso di dati di mapping.
Aggiungere una trasformazione Origine, Colonna derivata, Seleziona e Sink:
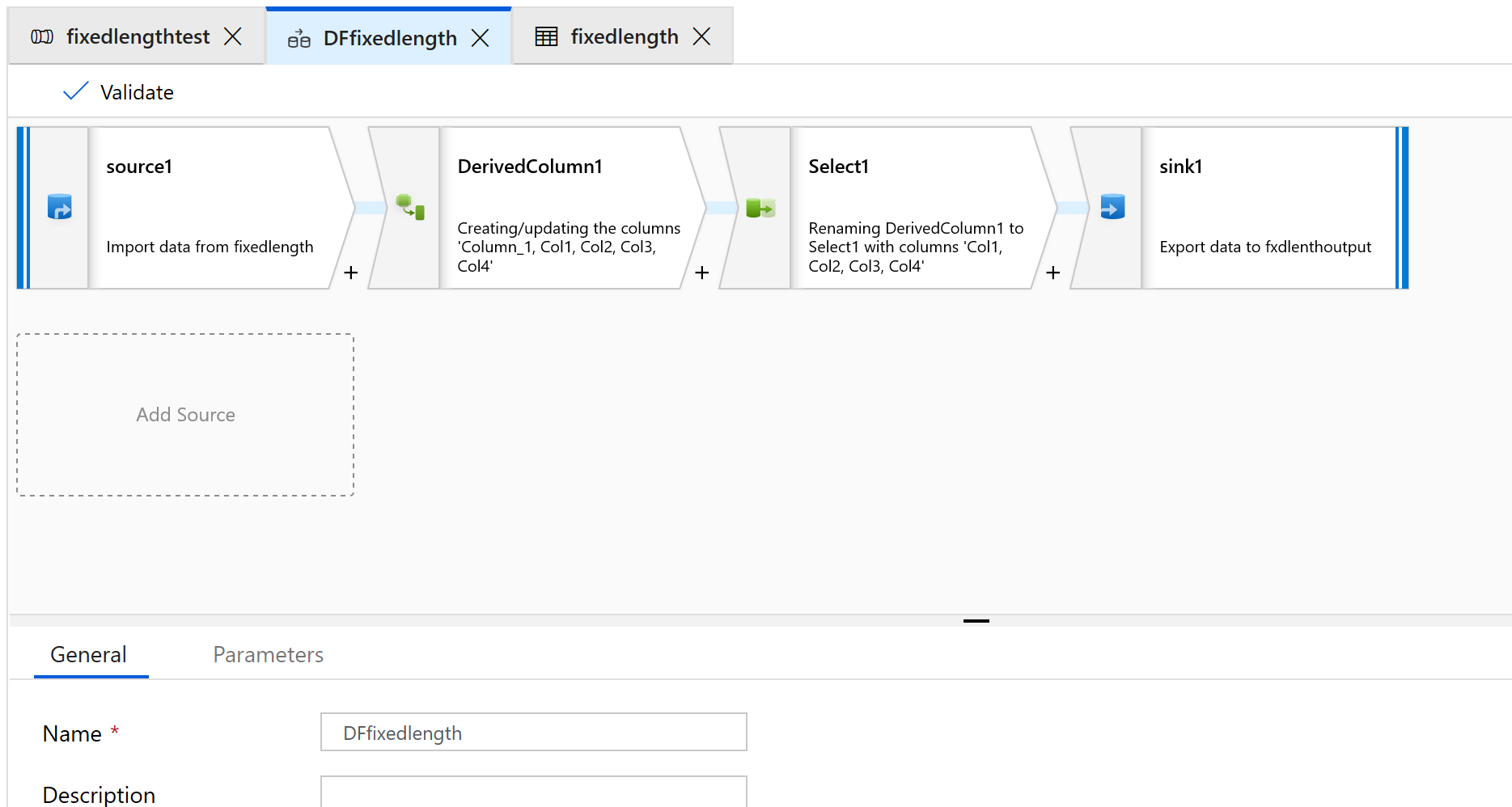
Configurare la trasformazione Origine per l'uso di un nuovo set di dati, che sarà di tipo Testo delimitato.
Non impostare alcun delimitatore o intestazione di colonna.
A questo punto verranno impostati i punti iniziali e le lunghezze dei campi per il contenuto di questo file:
1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468Nella scheda Proiezione della trasformazione Origine dovrebbe essere visualizzata una colonna stringa denominata Column_1.
Nella colonna Derivata creare una nuova colonna.
Verranno specificati i nomi semplici delle colonne, ad esempio col1.
Nel generatore di espressioni digitare quanto segue:
substring(Column_1,1,4)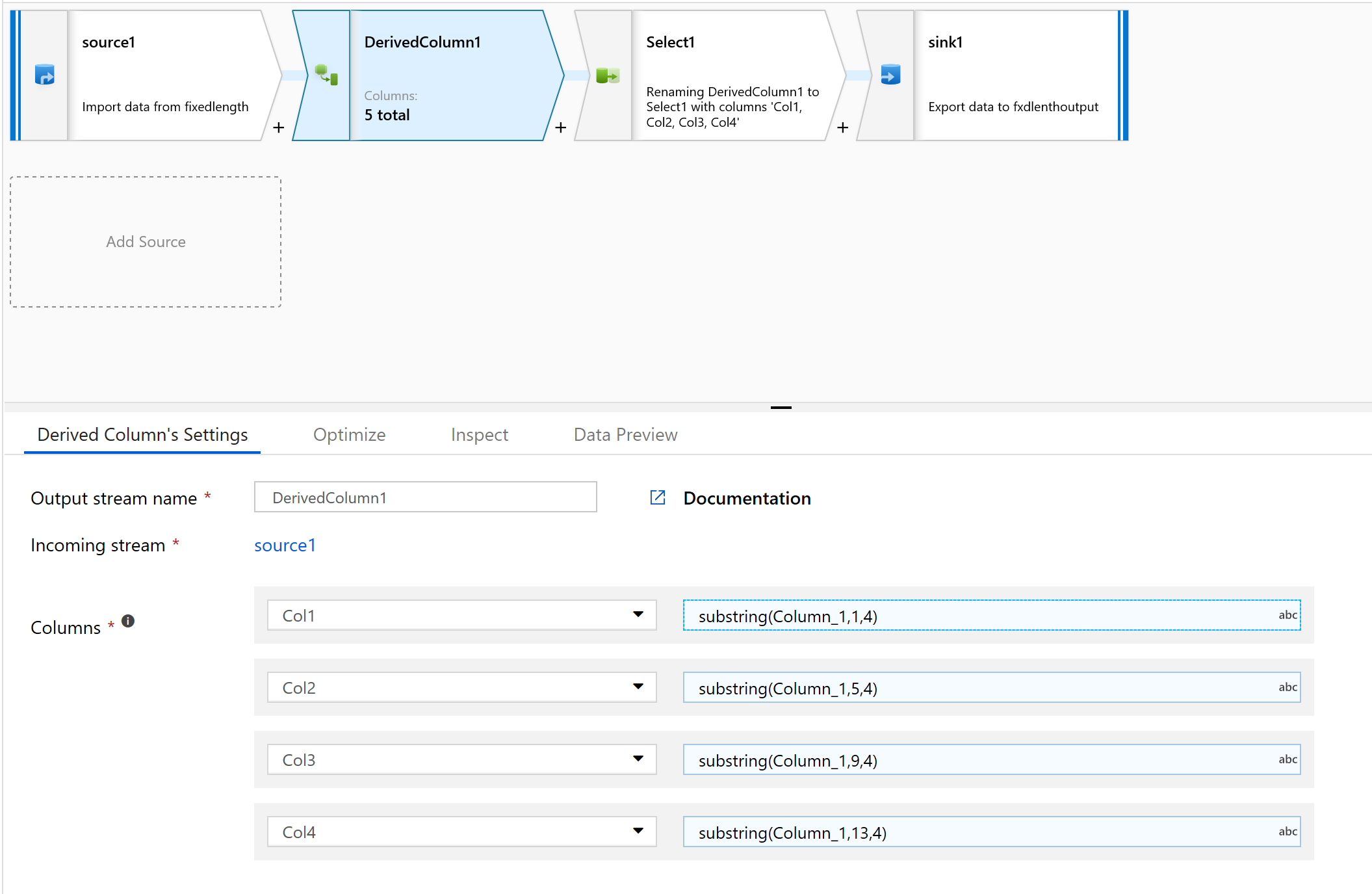
Ripetere il passaggio 10 per tutte le colonne da analizzare.
Selezionare la scheda Inspect (Ispeziona) per visualizzare le nuove colonne che verranno generate:
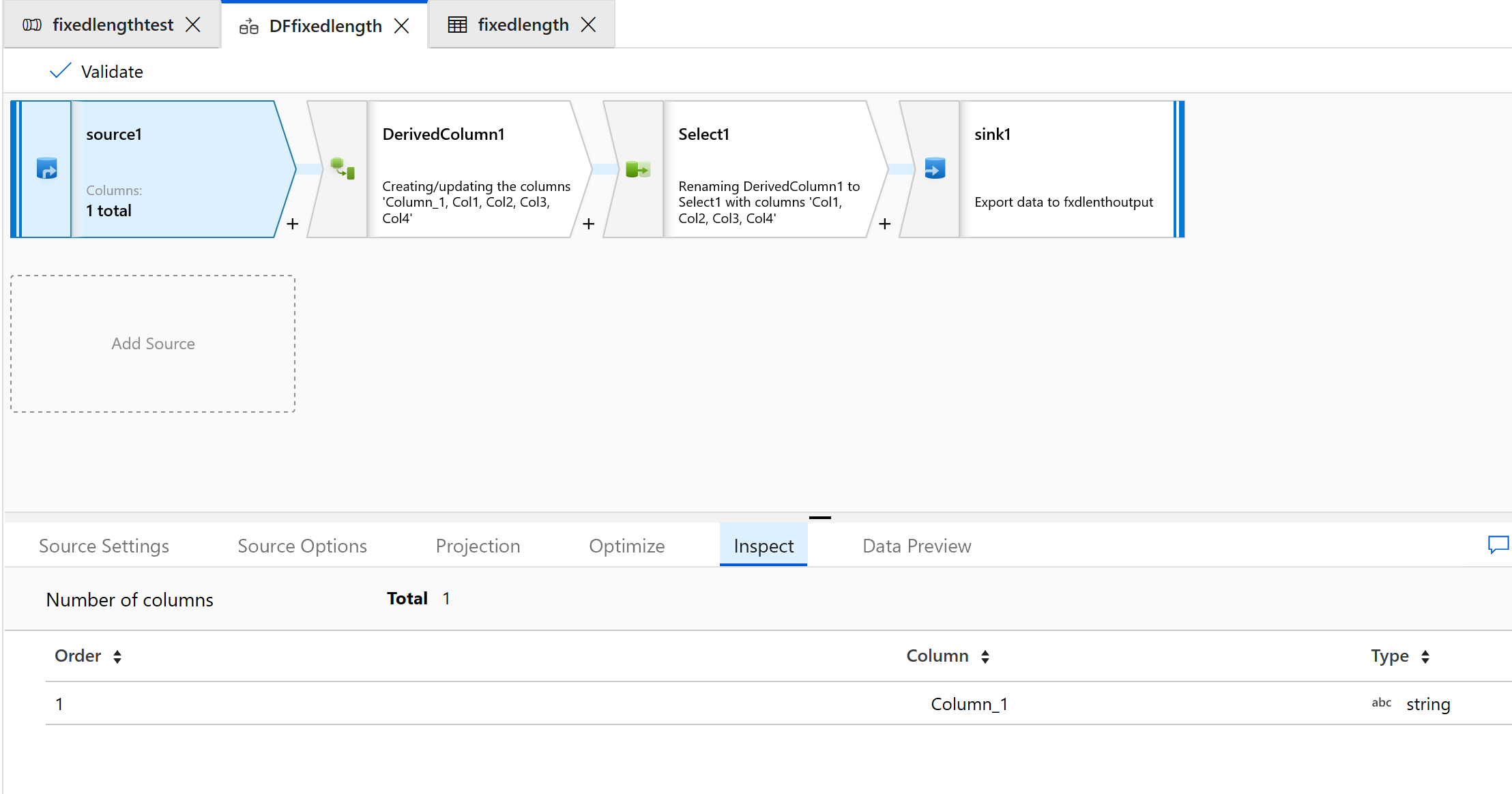
Usare la trasformazione Select per rimuovere una delle colonne che non sono necessarie per la trasformazione:
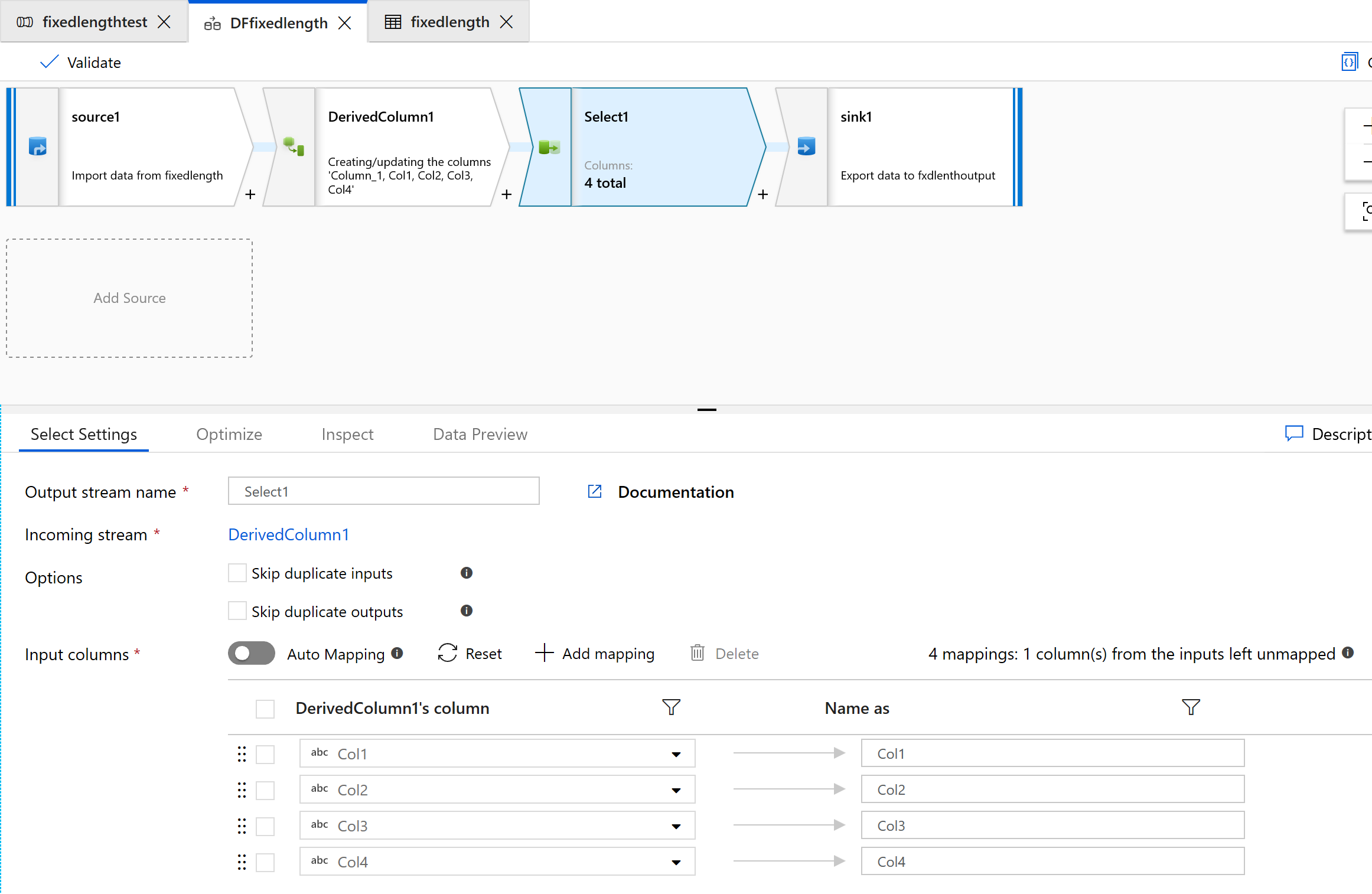
Usare Sink per restituire i dati in una cartella:
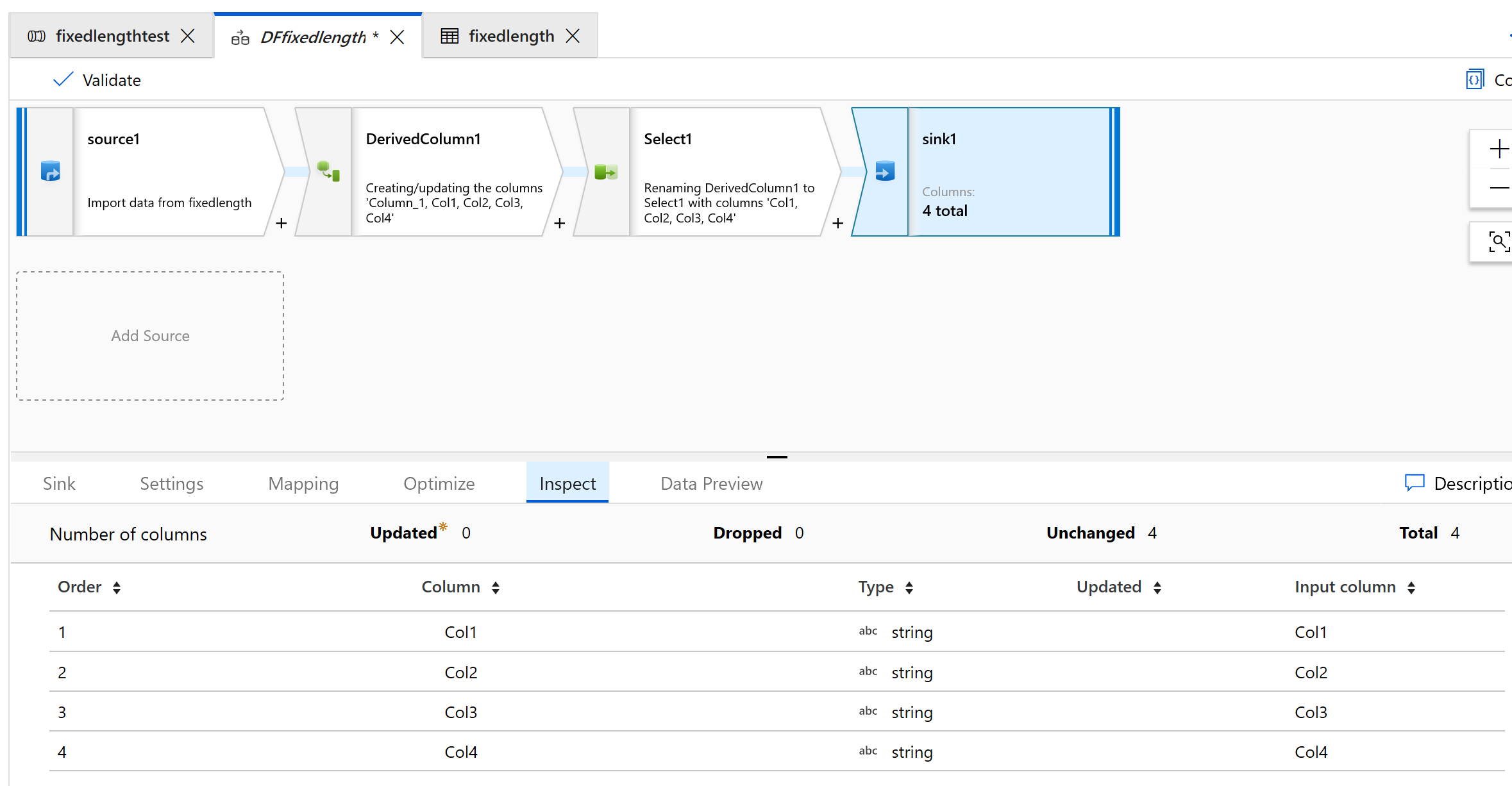
L'output è il seguente:
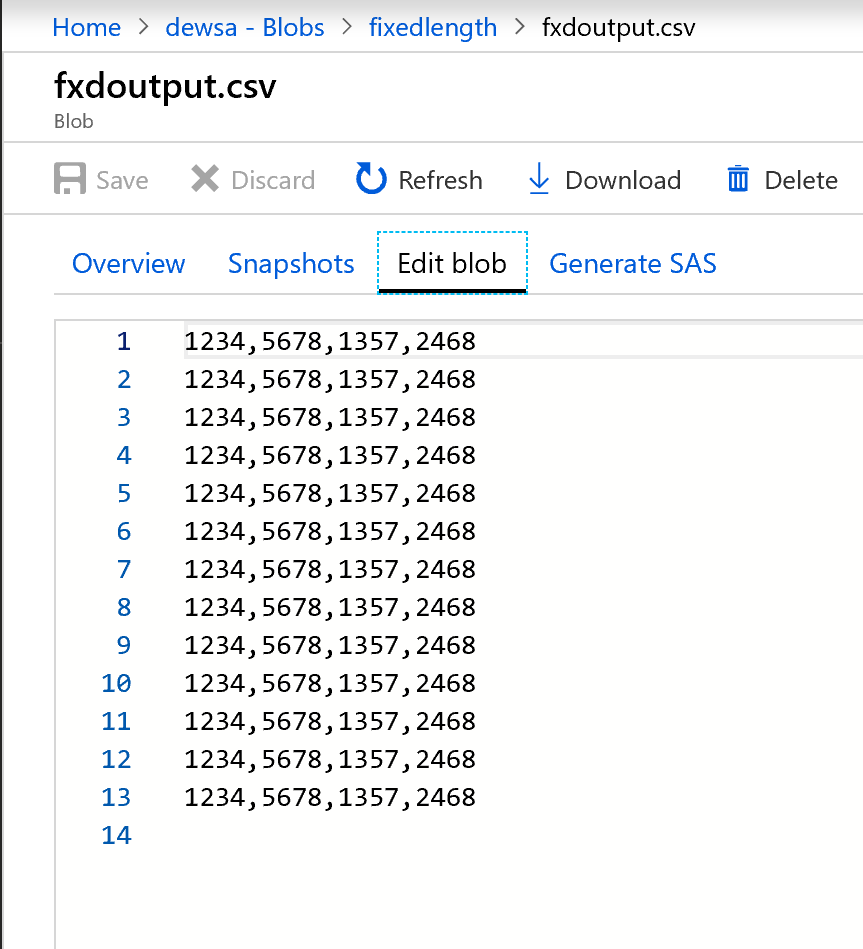
I dati a larghezza fissa sono ora suddivisi, con quattro caratteri ciascuno e assegnati a Col1, Col2, Col3, Col4 e così via. In base all'esempio precedente, i dati vengono suddivisi in quattro colonne.
Contenuto correlato
- Creare il resto della logica del flusso di dati usando le trasformazioni dei flussi di dati di mapping.