Usare le tabelle online per la gestione delle funzionalità in tempo reale
Importante
Le tabelle online sono in anteprima pubblica. Durante l'anteprima, l'inserimento di dati nelle tabelle online utilizza le UNITÀ DI database SQL Serverless. I prezzi finali per le tabelle online verranno resi disponibili in una data futura.
L'anteprima delle tabelle online è disponibile nelle aree seguenti: westus, eastuseastus2, westeuropenortheurope.
Una tabella online è una copia di sola lettura di una tabella Delta archiviata in formato orientato alle righe ottimizzata per l'accesso online. Le tabelle online sono tabelle completamente serverless che ridimensionano automaticamente la capacità di velocità effettiva con il carico delle richieste e forniscono un accesso a bassa latenza e velocità effettiva elevata ai dati di qualsiasi scala. Le tabelle online sono progettate per lavorare con le applicazioni di databricks Model Serving, Feature Serving e di generazione aumentata (RAG) in cui vengono usate per ricerche rapide dei dati.
È anche possibile usare tabelle online nelle query usando Lakehouse Federation. Quando si usa La federazione lakehouse, è necessario usare un serverless SQL Warehouse per accedere alle tabelle online. Sono supportate solo le operazioni di lettura (SELECT). Questa funzionalità è destinata solo a scopi interattivi o di debug e non deve essere usata per carichi di lavoro di produzione o cruciali.
La creazione di una tabella online tramite l'interfaccia utente di Databricks è un processo in un unico passaggio. È sufficiente selezionare la tabella Delta in Esplora cataloghi e selezionare Crea tabella online. È anche possibile usare l'API REST o Databricks SDK per creare e gestire tabelle online. Vedere Usare tabelle online usando le API.
Requisiti
- L'area di lavoro deve essere abilitata per il catalogo unity. Seguire la documentazione per creare un metastore del catalogo Unity, abilitarlo in un'area di lavoro e creare un catalogo.
- Per accedere alle tabelle online, è necessario registrare un modello in Unity Catalog.
Usare le tabelle online usando l'interfaccia utente
Questa sezione descrive come creare ed eliminare tabelle online e come controllare lo stato e attivare gli aggiornamenti delle tabelle online.
Creare una tabella online usando l'interfaccia utente
Si crea una tabella online usando Esplora cataloghi. Per informazioni sulle autorizzazioni necessarie, vedere Autorizzazioni utente.
Per creare una tabella online, la tabella Delta di origine deve avere una chiave primaria. Se la tabella Delta da usare non dispone di una chiave primaria, crearne una seguendo queste istruzioni: Usare una tabella Delta esistente in Unity Catalog come tabella delle funzionalità.
In Esplora cataloghi passare alla tabella di origine da sincronizzare con una tabella online. Dal menu Crea selezionare Tabella online.
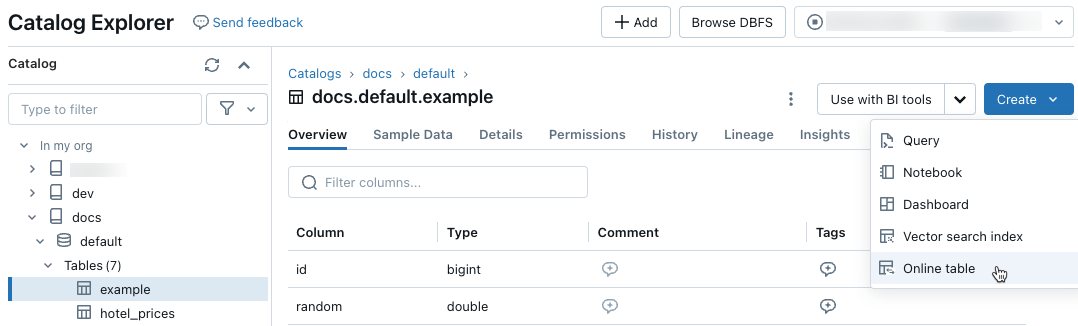
Usare i selettori nella finestra di dialogo per configurare la tabella online.
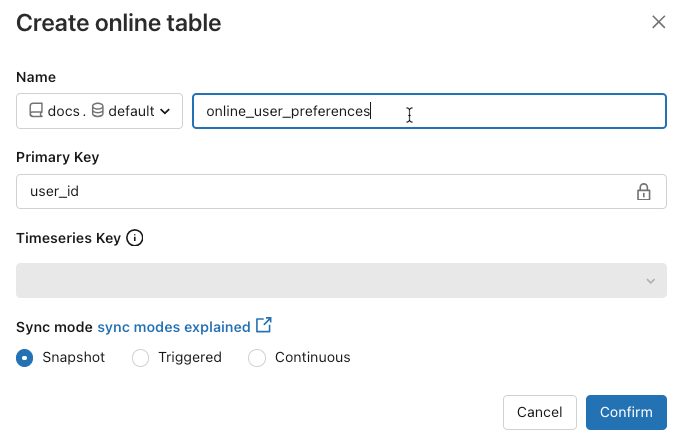
Nome: nome da usare per la tabella online nel catalogo unity.
Chiave primaria: colonne nella tabella di origine da usare come chiavi primarie nella tabella online.
Chiave Timeseries: (facoltativo). Colonna nella tabella di origine da usare come chiave timeseries. Se specificato, la tabella online include solo la riga con il valore della chiave timeseries più recente per ogni chiave primaria.
Modalità di sincronizzazione: specifica il modo in cui la pipeline di sincronizzazione aggiorna la tabella online. Selezionare uno snapshot, attivato o continuo.
Criterio Descrizione Snapshot La pipeline viene eseguita una volta per creare uno snapshot della tabella di origine e copiarla nella tabella online. Le modifiche successive alla tabella di origine vengono riflesse automaticamente nella tabella online creando un nuovo snapshot dell'origine e creando una nuova copia. Il contenuto della tabella online viene aggiornato in modo atomico. Attivato La pipeline viene eseguita una volta per creare una copia snapshot iniziale della tabella di origine nella tabella online. A differenza della modalità di sincronizzazione snapshot, quando la tabella online viene aggiornata, vengono recuperate e applicate alla tabella online solo le modifiche apportate dall'ultima esecuzione della pipeline. L'aggiornamento incrementale può essere attivato manualmente o attivato automaticamente in base a una pianificazione. Continuo La pipeline viene eseguita continuamente. Le modifiche successive alla tabella di origine vengono applicate in modo incrementale alla tabella online in modalità di streaming in tempo reale. Non è necessario alcun aggiornamento manuale.
Nota
Per supportare la modalità di sincronizzazione attivata o continua , la tabella di origine deve avere abilitato il feed di dati delle modifiche.
- Al termine, fare clic su Conferma. Viene visualizzata la pagina della tabella online.
- La nuova tabella online viene creata nel catalogo, nello schema e nel nome specificati nella finestra di dialogo di creazione. In Esplora cataloghi la tabella online è indicata da
 .
.
Ottenere lo stato e attivare gli aggiornamenti usando l'interfaccia utente
Per controllare lo stato della tabella online, fare clic sul nome della tabella nel catalogo per aprirlo. La pagina della tabella online viene visualizzata con la scheda Panoramica aperta. La sezione Inserimento dati mostra lo stato dell'aggiornamento più recente. Per attivare un aggiornamento, fare clic su Sincronizza ora. La sezione Inserimento dati include anche un collegamento alla pipeline delta live tables che aggiorna la tabella.

Eliminare una tabella online usando l'interfaccia utente
Nella pagina della tabella online selezionare Elimina dal  menu kebab.
menu kebab.
Usare le tabelle online usando le API
È anche possibile usare Databricks SDK o l'API REST per creare e gestire tabelle online.
Per informazioni di riferimento, vedere la documentazione di riferimento per Databricks SDK per Python o l'API REST.
Requisiti
Databricks SDK versione 0.20 o successiva.
Creare una tabella online usando le API
Databricks SDK - Python
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import *
w = WorkspaceClient(host='https://xxx.databricks.com', token='xxx')
# Create an online table
spec = OnlineTableSpec(
primary_key_columns=["pk_col"],
source_table_full_name="main.default.source_table",
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'})
)
w.online_tables.create(name='main.default.my_online_table', spec=spec)
API REST
curl --request POST "https://xxx.databricks.com/api/2.0/online-tables" \
--header "Authorization: Bearer xxx" \
--data '{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["a"]
}
}'
La tabella online avvia automaticamente la sincronizzazione dopo la creazione.
Ottenere lo stato e attivare l'aggiornamento usando le API
È possibile visualizzare lo stato e la specifica della tabella online seguendo l'esempio seguente. Se la tabella online non è continua e si vuole attivare un aggiornamento manuale dei dati, è possibile usare l'API della pipeline per farlo.
Usare l'ID pipeline associato alla tabella online nella specifica di tabella online e avviare un nuovo aggiornamento nella pipeline per attivare l'aggiornamento. Equivale a fare clic su Sincronizza ora nell'interfaccia utente della tabella online in Esplora cataloghi.
Databricks SDK - Python
pprint(w.online_tables.get('main.default.my_online_table'))
# Sample response
OnlineTable(name='main.default.my_online_table',
spec=OnlineTableSpec(perform_full_copy=None,
pipeline_id='some-pipeline-id',
primary_key_columns=['pk_col'],
run_continuously=None,
run_triggered={},
source_table_full_name='main.default.source_table',
timeseries_key=None),
status=OnlineTableStatus(continuous_update_status=None,
detailed_state=OnlineTableState.PROVISIONING,
failed_status=None,
message='Online Table creation is '
'pending. Check latest status in '
'Delta Live Tables: '
'https://xxx.databricks.com/pipelines/some-pipeline-id',
provisioning_status=None,
triggered_update_status=None))
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
w.pipelines.start_update(pipeline_id='some-pipeline-id', full_refresh=True)
API REST
curl --request GET \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
# Sample response
{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["pk_col"],
"pipeline_id": "some-pipeline-id"
},
"status": {
"detailed_state": "PROVISIONING",
"message": "Online Table creation is pending. Check latest status in Delta Live Tables: https://xxx.databricks.com#joblist/pipelines/some-pipeline-id"
}
}
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
curl --request POST "https://xxx.databricks.com/api/2.0/pipelines/some-pipeline-id/updates" \
--header "Authorization: Bearer xxx" \
--data '{
"full_refresh": true
}'
Eliminare una tabella online usando le API
Databricks SDK - Python
w.online_tables.delete('main.default.my_online_table')
API REST
curl --request DELETE \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
L'eliminazione della tabella online interrompe la sincronizzazione dei dati in corso e rilascia tutte le relative risorse.
Gestire i dati delle tabelle online usando un endpoint di gestione delle funzionalità
Per i modelli e le applicazioni ospitati all'esterno di Databricks, è possibile creare un endpoint di gestione delle funzionalità per gestire le funzionalità dalle tabelle online. L'endpoint rende disponibili le funzionalità a bassa latenza usando un'API REST.
Creare una specifica di funzionalità.
Quando si crea una specifica di funzionalità, specificare la tabella Delta di origine. In questo modo, la specifica di funzionalità può essere usata sia in scenari offline che online. Per le ricerche online, l'endpoint di gestione usa automaticamente la tabella online per eseguire ricerche di funzionalità a bassa latenza.
La tabella Delta di origine e la tabella online devono usare la stessa chiave primaria.
La specifica di funzionalità può essere visualizzata nella scheda Funzione in Esplora cataloghi.
from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup fe = FeatureEngineeringClient() fe.create_feature_spec( name="catalog.default.user_preferences_spec", features=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ] )Creare un endpoint di gestione delle funzionalità.
Questo passaggio presuppone che sia stata creata una tabella online denominata
user_preferences_online_tableche sincronizza i dati dalla tabellauser_preferencesDelta . Usare la specifica di funzionalità per creare un endpoint di gestione delle funzionalità. L'endpoint rende i dati disponibili tramite un'API REST usando la tabella online associata.Nota
L'utente che esegue questa operazione deve essere il proprietario della tabella offline e della tabella online.
Databricks SDK - Python
from databricks.sdk import WorkspaceClient from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput workspace = WorkspaceClient() # Create endpoint endpoint_name = "fse-location" workspace.serving_endpoints.create_and_wait( name=endpoint_name, config=EndpointCoreConfigInput( served_entities=[ ServedEntityInput( entity_name=feature_spec_name, scale_to_zero_enabled=True, workload_size="Small" ) ] ) )API Python
fe.create_feature_serving_endpoint( name="user-preferences", config=EndpointCoreConfig( served_entities=ServedEntity( feature_spec_name="catalog.default.user_preferences_spec", workload_size="Small", scale_to_zero_enabled=True ) ) )Ottenere dati dall'endpoint di gestione delle funzionalità.
Per accedere all'endpoint API, inviare una richiesta HTTP GET all'URL dell'endpoint. L'esempio illustra come eseguire questa operazione usando le API Python. Per altri linguaggi e strumenti, vedere Funzionalità di gestione delle funzionalità.
# Set up credentials export DATABRICKS_TOKEN=...url = "https://{workspace_url}/serving-endpoints/user-preferences/invocations" headers = {'Authorization': f'Bearer {DATABRICKS_TOKEN}', 'Content-Type': 'application/json'} data = { "dataframe_records": [{"user_id": user_id}] } data_json = json.dumps(data, allow_nan=True) response = requests.request(method='POST', headers=headers, url=url, data=data_json) if response.status_code != 200: raise Exception(f'Request failed with status {response.status_code}, {response.text}') print(response.json()['outputs'][0]['hotel_preference'])
Usare tabelle online con applicazioni RAG
Le applicazioni RAG sono un caso d'uso comune per le tabelle online. È possibile creare una tabella online per i dati strutturati necessari all'applicazione RAG e ospitarli in un endpoint di gestione delle funzionalità. L'applicazione RAG usa l'endpoint di gestione delle funzionalità per cercare i dati pertinenti dalla tabella online.
I passaggi tipici sono i seguenti:
- Creare un endpoint di gestione delle funzionalità.
- Creare un LangChainTool che usa l'endpoint per cercare i dati pertinenti.
- Usare lo strumento nell'agente LangChain per recuperare i dati pertinenti.
- Creare un endpoint di gestione del modello per ospitare l'applicazione LangChain.
Per istruzioni dettagliate, vedere il notebook di esempio seguente.
Esempi di notebook
Il notebook seguente illustra come pubblicare funzionalità nelle tabelle online per la gestione in tempo reale e la ricerca automatica delle funzionalità.
Notebook demo delle tabelle online
Il notebook seguente illustra come usare le tabelle online di Databricks e gli endpoint di gestione delle funzionalità per le applicazioni di generazione aumentata (RAG).
Notebook demo delle tabelle online con applicazioni RAG
Usare tabelle online con Databricks Model Serving
È possibile usare le tabelle online per cercare le funzionalità per la gestione dei modelli di Databricks. Quando si sincronizza una tabella delle funzionalità in una tabella online, i modelli sottoposti a training usando le funzionalità di tale tabella di funzionalità cercano automaticamente i valori delle funzionalità dalla tabella online durante l'inferenza. Non è necessaria alcuna configurazione aggiuntiva.
Usare un
FeatureLookupoggetto per eseguire il training del modello.Per il training del modello, usare le funzionalità della tabella delle funzionalità offline nel set di training del modello, come illustrato nell'esempio seguente:
training_set = fe.create_training_set( df=id_rt_feature_labels, label='quality', feature_lookups=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ], exclude_columns=['user_id'], )Gestire il modello con Databricks Model Serving. Il modello cerca automaticamente le funzionalità dalla tabella online. Per informazioni dettagliate, vedere Ricerca automatica delle funzionalità con modelli MLflow in Databricks .
Autorizzazioni utente
Per creare una tabella online, è necessario disporre delle autorizzazioni seguenti:
SELECTprivilegio nella tabella di origine.USE_CATALOGprivilegio nel catalogo di destinazione.USE_SCHEMAeCREATE_TABLEprivilegi per lo schema di destinazione.
Per gestire la pipeline di sincronizzazione dei dati di una tabella online, è necessario essere il proprietario della tabella online o concedere il privilegio REFRESH nella tabella online. Gli utenti che non dispongono di privilegi U edizione Standard_CATALOG e U edizione Standard_SCHEMA nel catalogo non vedranno la tabella online in Esplora cataloghi.
Il metastore del catalogo Unity deve avere il modello di privilegio versione 1.0.
Modello di autorizzazione dell'endpoint
Un'entità servizio di sistema univoca viene creata automaticamente per una funzionalità che serve o un modello che gestisce un endpoint con autorizzazioni limitate necessarie per eseguire query sui dati ed eseguire funzioni. Questa entità servizio consente agli endpoint di accedere ai dati e alle risorse di funzione indipendentemente dall'utente che ha creato la risorsa e garantisce che l'endpoint possa continuare a funzionare se l'autore lascia l'area di lavoro.
La durata di questa entità servizio di sistema è la durata dell'endpoint. I log di controllo possono indicare record generati dal sistema per il proprietario del catalogo di Unity, concedendo privilegi necessari a questa entità servizio di sistema.
Limiti
- Per tabella di origine è supportata una sola tabella online.
- Una tabella online e la relativa tabella di origine possono contenere al massimo 1000 colonne.
- Le colonne di tipi di dati ARRAY, MAP o STRUCT non possono essere usate come chiavi primarie nella tabella online.
- Se una colonna viene utilizzata come chiave primaria nella tabella online, tutte le righe della tabella di origine in cui la colonna contiene valori Null vengono ignorate.
- Le tabelle esterne, di sistema e interne non sono supportate come tabelle di origine.
- Le tabelle di origine senza feed di dati delle modifiche Delta abilitate supportano solo la modalità di sincronizzazione snapshot .
- Le tabelle di condivisione differenziale sono supportate solo nella modalità di sincronizzazione snapshot .
- I nomi di catalogo, schema e tabella della tabella online possono contenere solo caratteri alfanumerici e caratteri di sottolineatura e non devono iniziare con i numeri. I trattini (
-) non sono consentiti. - Le colonne di tipo String sono limitate a 64 KB.
- I nomi delle colonne sono limitati a 64 caratteri.
- La dimensione massima della riga è 2 MB.
- La dimensione massima di una tabella online durante l'anteprima pubblica controllata è di 200 GB di dati utente non compressi.
- Le dimensioni combinate di tutte le tabelle online in un metastore di Unity Catalog durante l'anteprima pubblica controllata sono 1 TB di dati utente non compressi.
- Il numero massimo di query al secondo (QPS) è 200. Questo limite può essere aumentato a 25.000 o più. Contattare il team dell'account Databricks per aumentare il limite.
Risoluzione dei problemi
"Crea tabella online" non viene visualizzata in Esplora cataloghi.
La causa è in genere che la tabella da cui si sta tentando di eseguire la sincronizzazione (la tabella di origine) non è un tipo supportato. Assicurarsi che il tipo a protezione diretta della tabella di origine (illustrato nella scheda Dettagli esplora cataloghi) sia una delle opzioni supportate di seguito:
TABLE_EXTERNALTABLE_DELTATABLE_DELTA_EXTERNALTABLE_DELTASHARINGTABLE_DELTASHARING_MUTABLETABLE_STREAMING_LIVE_TABLETABLE_STANDARDTABLE_FEATURE_STORETABLE_FEATURE_STORE_EXTERNALTABLE_VIEWTABLE_VIEW_DELTASHARINGTABLE_MATERIALIZED_VIEW
Non è possibile selezionare le modalità di sincronizzazione "Attivata" o "Continua" durante la creazione di una tabella online.
Ciò si verifica se la tabella di origine non dispone di feed di dati delle modifiche Delta abilitato o se si tratta di una vista vista o materializzata. Per usare la modalità di sincronizzazione incrementale , abilitare il feed di dati delle modifiche nella tabella di origine o usare una tabella non vista.
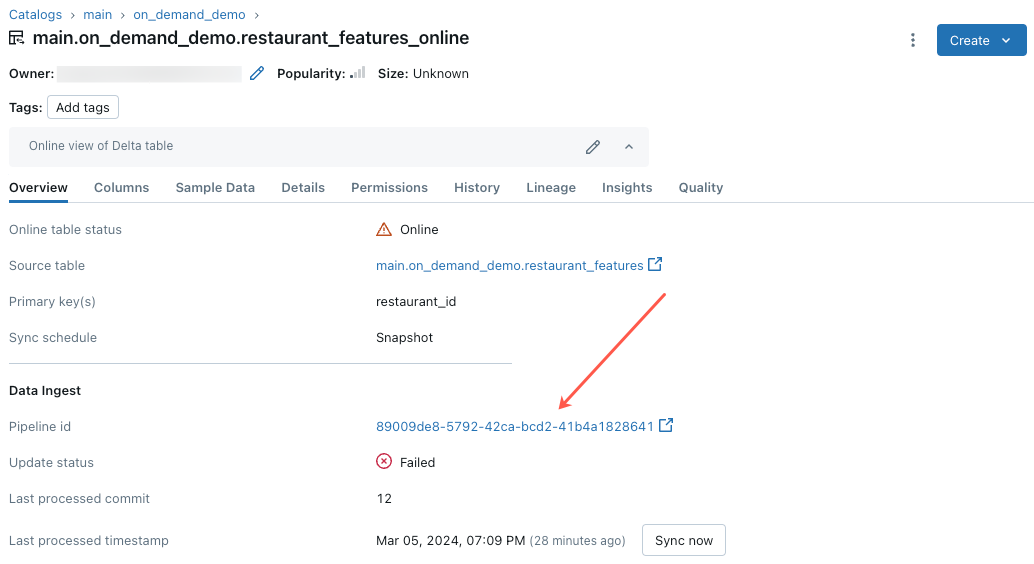
L'aggiornamento della tabella online ha esito negativo o lo stato mostra offline
Per iniziare a risolvere questo errore, fare clic sull'ID pipeline visualizzato nella scheda Panoramica della tabella online in Esplora cataloghi.
Nella pagina dell'interfaccia utente della pipeline visualizzata fare clic sulla voce "Failed to resolve flow '__online_table".
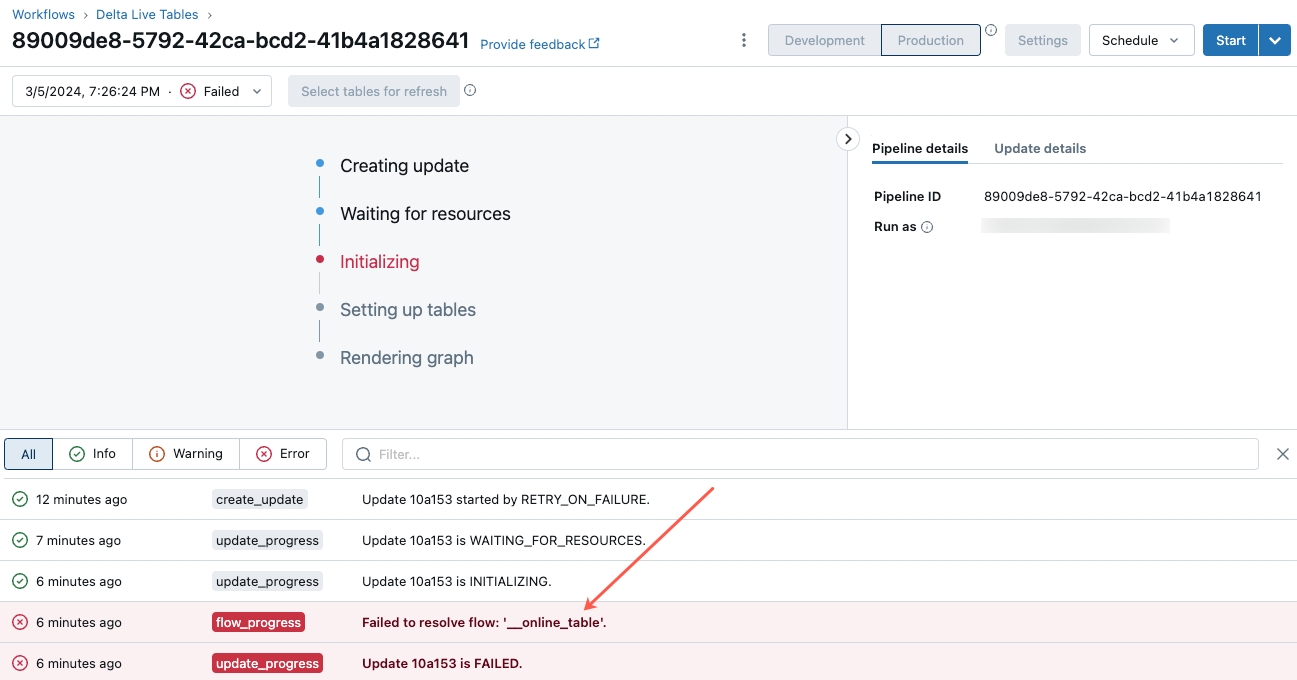
Viene visualizzata una finestra popup con i dettagli nella sezione Dettagli errore.
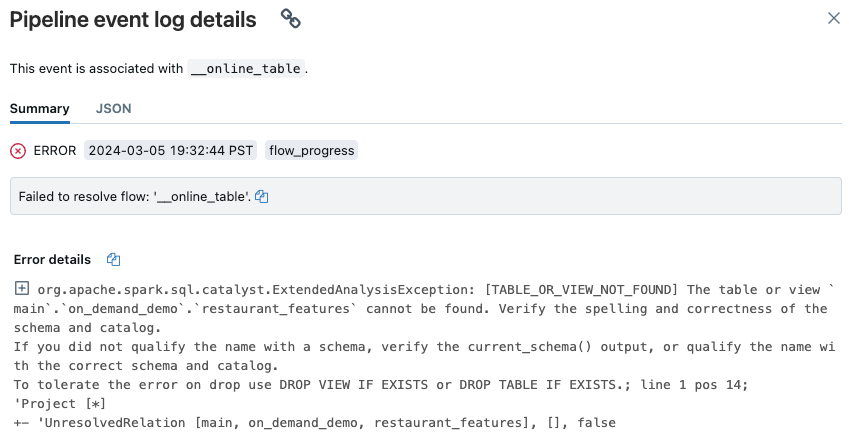
Le cause comuni degli errori includono:
La tabella di origine è stata eliminata o eliminata e ricreata con lo stesso nome, mentre la tabella online è stata sincronizzata. Ciò è particolarmente comune con le tabelle online continue, perché sono costantemente sincronizzate.
Non è possibile accedere alla tabella di origine tramite calcolo serverless a causa delle impostazioni del firewall. In questo caso, la sezione Dettagli errore potrebbe visualizzare il messaggio di errore "Impossibile avviare il servizio DLT nel cluster xxx...".
Le dimensioni aggregate delle tabelle online superano il limite di 1 tib (dimensioni non compresse) a livello di metastore. Il limite 1 TiB si riferisce alle dimensioni non compresse dopo aver espanso la tabella Delta in formato orientato alle righe. Le dimensioni della tabella in formato riga possono essere notevolmente maggiori delle dimensioni della tabella Delta mostrata in Esplora cataloghi, che fa riferimento alle dimensioni compresse della tabella in un formato orientato alle colonne. La differenza può essere pari a 100x, a seconda del contenuto della tabella.
Per stimare le dimensioni non compresse e espanse delle righe di una tabella Delta, usare la query seguente da un'istanza di SQL Warehouse serverless. La query restituisce le dimensioni stimate della tabella espansa in byte. L'esecuzione corretta di questa query conferma anche che l'ambiente di calcolo serverless può accedere alla tabella di origine.
SELECT sum(length(to_csv(struct(*)))) FROM `source_table`;
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per