Usare le funzionalità nell'archivio delle funzionalità dell'area di lavoro
Nota
Questa documentazione illustra l'archivio funzionalità dell'area di lavoro. Databricks consiglia di usare Progettazione funzionalità nel catalogo unity. L'archivio delle funzionalità dell'area di lavoro sarà deprecato in futuro.
Questa pagina descrive come creare e usare tabelle delle funzionalità nell'Archivio funzionalità dell'area di lavoro.
Nota
Se l'area di lavoro è abilitata per Unity Catalog, qualsiasi tabella gestita da Unity Catalog con una chiave primaria è automaticamente una tabella delle funzionalità che è possibile usare per il training e l'inferenza del modello. Tutte le funzionalità del catalogo Unity, ad esempio sicurezza, derivazione, assegnazione di tag e accesso tra aree di lavoro, sono automaticamente disponibili per la tabella delle funzionalità. Per informazioni sull'uso delle tabelle delle funzionalità in un'area di lavoro abilitata per il catalogo unity, vedere Progettazione delle funzionalità nel catalogo unity.
Per informazioni sulla derivazione e l'aggiornamento delle funzionalità di rilevamento, vedere Individuare le funzionalità e tenere traccia della derivazione delle funzionalità.
Nota
I nomi di tabelle di database e funzionalità possono contenere solo caratteri alfanumerici e caratteri di sottolineatura (_).
Creare un database per le tabelle delle funzionalità
Prima di creare tabelle di funzionalità, è necessario creare un database per archiviarli.
%sql CREATE DATABASE IF NOT EXISTS <database-name>
Le tabelle delle funzionalità vengono archiviate come tabelle Delta. Quando si crea una tabella delle funzionalità con create_table (client di Feature Store v0.3.6 e versioni successive) o create_feature_table (v0.3.5 e versioni successive), è necessario specificare il nome del database. Ad esempio, questo argomento crea una tabella Delta denominata customer_features nel database recommender_system.
name='recommender_system.customer_features'
Quando si pubblica una tabella delle funzionalità in un archivio online, la tabella predefinita e il nome del database sono quelli specificati al momento della creazione della tabella; è possibile specificare nomi diversi usando il publish_table metodo .
L'interfaccia utente di Databricks Feature Store mostra il nome della tabella e del database nell'archivio online, insieme ad altri metadati.
Creare una tabella delle funzionalità in Databricks Feature Store
Nota
È anche possibile registrare una tabella Delta esistente come tabella delle funzionalità. Vedere Registrare una tabella Delta esistente come tabella delle funzionalità.
I passaggi di base per la creazione di una tabella delle funzionalità sono:
- Scrivere le funzioni Python per calcolare le funzionalità. L'output di ogni funzione deve essere un dataframe Apache Spark con una chiave primaria univoca. La chiave primaria può essere costituita da una o più colonne.
- Creare una tabella delle funzionalità creando un'istanza
FeatureStoreClientdi e usandocreate_table(v0.3.6 e versioni successive) ocreate_feature_table(v0.3.5 e versioni successive). - Popolare la tabella delle funzionalità usando
write_table.
Per informazioni dettagliate sui comandi e sui parametri usati negli esempi seguenti, vedere le informazioni di riferimento sulle API Python di Feature Store.
V0.3.6 e versioni successive
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
name='recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_table call
# customer_feature_table = fs.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
V0.3.5 e versioni successive
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
Registrare una tabella Delta esistente come tabella delle funzionalità
Con v0.3.8 e versioni successive, è possibile registrare una tabella Delta esistente come tabella delle funzionalità. La tabella Delta deve esistere nel metastore.
Nota
Per aggiornare una tabella delle funzionalità registrata, è necessario usare l'API Python di Feature Store.
fs.register_table(
delta_table='recommender.customer_features',
primary_keys='customer_id',
description='Customer features'
)
Controllare l'accesso alle tabelle delle funzionalità
Vedere Controllare l'accesso alle tabelle delle funzionalità.
Aggiornare una tabella delle funzionalità
È possibile aggiornare una tabella delle funzionalità aggiungendo nuove funzionalità o modificando righe specifiche in base alla chiave primaria.
Non è possibile aggiornare i metadati della tabella delle funzionalità seguenti:
- Chiave primaria
- Chiave di partizione
- Nome o tipo di una funzionalità esistente
Aggiungere nuove funzionalità a una tabella delle funzionalità esistente
È possibile aggiungere nuove funzionalità a una tabella delle funzionalità esistente in uno dei due modi seguenti:
- Aggiornare la funzione di calcolo delle funzionalità esistente ed eseguire
write_tablecon il dataframe restituito. Questo aggiorna lo schema della tabella delle funzionalità e unisce nuovi valori di funzionalità in base alla chiave primaria. - Creare una nuova funzione di calcolo delle funzionalità per calcolare i nuovi valori di funzionalità. Il dataframe restituito da questa nuova funzione di calcolo deve contenere le chiavi primarie e le chiavi di partizione delle tabelle delle funzionalità ,se definite. Eseguire
write_tablecon il dataframe per scrivere le nuove funzionalità nella tabella delle funzionalità esistente usando la stessa chiave primaria.
Aggiornare solo righe specifiche in una tabella delle funzionalità
Usare mode = "merge" in write_table. Le righe la cui chiave primaria non esiste nel dataframe inviato nella write_table chiamata rimangono invariate.
fs.write_table(
name='recommender.customer_features',
df = customer_features_df,
mode = 'merge'
)
Pianificare un processo per aggiornare una tabella delle funzionalità
Per garantire che le funzionalità nelle tabelle delle funzionalità abbiano sempre i valori più recenti, Databricks consiglia di creare un processo che esegue un notebook per aggiornare la tabella delle funzionalità a intervalli regolari, ad esempio ogni giorno. Se è già stato creato un processo non pianificato, è possibile convertirlo in un processo pianificato per assicurarsi che i valori delle funzionalità siano sempre aggiornati.
Il codice per aggiornare una tabella delle funzionalità usa mode='merge', come illustrato nell'esempio seguente.
fs = FeatureStoreClient()
customer_features_df = compute_customer_features(data)
fs.write_table(
df=customer_features_df,
name='recommender_system.customer_features',
mode='merge'
)
Archiviare i valori passati delle funzionalità giornaliere
Definire una tabella delle funzionalità con una chiave primaria composita. Includere la data nella chiave primaria. Ad esempio, per una tabella store_purchasesdelle funzionalità , è possibile usare una chiave primaria composita (date, user_id) e una chiave date di partizione per letture efficienti.
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
È quindi possibile creare codice da leggere dal filtro date della tabella delle funzionalità al periodo di tempo di interesse.
È anche possibile creare una tabella delle funzionalità della serie temporale specificando la date colonna come chiave timestamp usando l'argomento timestamp_keys .
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
timestamp_keys=['date'],
schema=customer_features_df.schema,
description='Customer timeseries features'
)
Ciò consente ricerche temporizzato quando si usa create_training_set o score_batch. Il sistema esegue un join as-of-timestamp, usando l'oggetto timestamp_lookup_key specificato.
Per mantenere aggiornata la tabella delle funzionalità, configurare un processo pianificato regolarmente per scrivere funzionalità o trasmettere nuovi valori delle funzionalità nella tabella delle funzionalità.
Creare una pipeline di calcolo delle funzionalità di streaming per aggiornare le funzionalità
Per creare una pipeline di calcolo delle funzionalità di streaming, passare un flusso DataFrame come argomento a write_table. Il metodo restituisce un oggetto StreamingQuery.
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass # not shown
customer_transactions = spark.readStream.load("dbfs:/events/customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fs.write_table(
df=stream_df,
name='recommender_system.customer_features',
mode='merge'
)
Leggere da una tabella delle funzionalità
Usare read_table per leggere i valori delle funzionalità.
fs = feature_store.FeatureStoreClient()
customer_features_df = fs.read_table(
name='recommender.customer_features',
)
Cercare ed esplorare le tabelle delle funzionalità
Usare l'interfaccia utente di Feature Store per cercare o esplorare le tabelle delle funzionalità.
Nella barra laterale selezionare Machine Learning > Feature Store per visualizzare l'interfaccia utente di Feature Store.
Nella casella di ricerca immettere tutto o parte del nome di una tabella di funzionalità, una funzionalità o un'origine dati usata per il calcolo delle funzionalità. È anche possibile immettere tutto o parte della chiave o del valore di un tag. Il testo di ricerca non fa distinzione tra maiuscole e minuscole.

Ottenere i metadati della tabella delle funzionalità
L'API per ottenere i metadati della tabella delle funzionalità dipende dalla versione del runtime di Databricks in uso. Con v0.3.6 e versioni successive, usare get_table. Con v0.3.5 e versioni successive, usare get_feature_table.
# this example works with v0.3.6 and above
# for v0.3.5, use `get_feature_table`
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.get_table("feature_store_example.user_feature_table")
Usare i tag delle tabelle delle funzionalità
I tag sono coppie chiave-valore che è possibile creare e usare per cercare le tabelle delle funzionalità. È possibile creare, modificare ed eliminare tag usando l'interfaccia utente di Feature Store o l'API Python di Feature Store.
Usare i tag di tabella delle funzionalità nell'interfaccia utente
Usare l'interfaccia utente di Feature Store per cercare o esplorare le tabelle delle funzionalità. Per accedere all'interfaccia utente, nella barra laterale selezionare Machine Learning > Feature Store.
Aggiungere un tag usando l'interfaccia utente di Feature Store
Fare clic
 se non è già aperto. Viene visualizzata la tabella dei tag.
se non è già aperto. Viene visualizzata la tabella dei tag.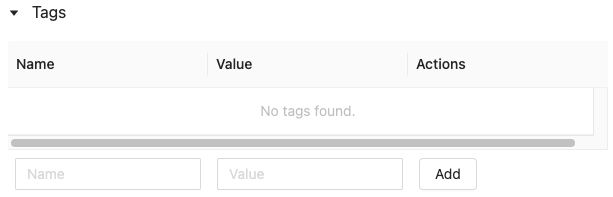
Fare clic nei campi Nome e Valore e immettere la chiave e il valore per il tag.
Fare clic su Aggiungi.
Modificare o eliminare un tag usando l'interfaccia utente di Feature Store
Per modificare o eliminare un tag esistente, usare le icone nella colonna Azioni .
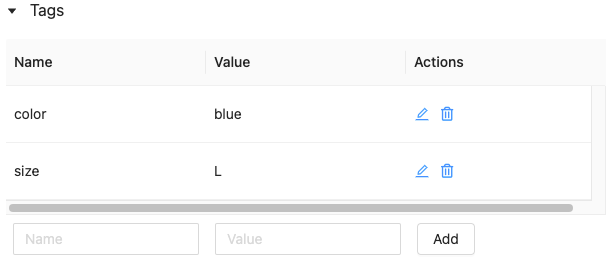
Usare i tag di tabella delle funzionalità usando l'API Python di Feature Store
Nei cluster che eseguono v0.4.1 e versioni successive è possibile creare, modificare ed eliminare tag usando l'API Python di Feature Store.
Requisiti
Client di Feature Store v0.4.1 e versioni successive
Creare una tabella delle funzionalità con tag usando l'API Python di Feature Store
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
...
tags={"tag_key_1": "tag_value_1", "tag_key_2": "tag_value_2", ...},
...
)
Aggiungere, aggiornare ed eliminare tag usando l'API Python di Feature Store
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Upsert a tag
fs.set_feature_table_tag(table_name="my_table", key="quality", value="gold")
# Delete a tag
fs.delete_feature_table_tag(table_name="my_table", key="quality")
Aggiornare le origini dati per una tabella delle funzionalità
L'archivio funzionalità tiene traccia automaticamente delle origini dati usate per calcolare le funzionalità. È anche possibile aggiornare manualmente le origini dati usando l'API Python di Feature Store.
Requisiti
Client di Feature Store v0.5.0 e versioni successive
Aggiungere origini dati usando l'API Python di Feature Store
Di seguito sono riportati alcuni comandi di esempio. Per informazioni dettagliate, vedere la documentazione dell'API.
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Use `source_type="table"` to add a table in the metastore as data source.
fs.add_data_sources(feature_table_name="clicks", data_sources="user_info.clicks", source_type="table")
# Use `source_type="path"` to add a data source in path format.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="dbfs:/FileStore/user_metrics.json", source_type="path")
# Use `source_type="custom"` if the source is not a table or a path.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="user_metrics.txt", source_type="custom")
Eliminare le origini dati usando l'API Python di Feature Store
Per informazioni dettagliate, vedere la documentazione dell'API.
Nota
Il comando seguente elimina le origini dati di tutti i tipi ("table", "path" e "custom") che corrispondono ai nomi di origine.
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.delete_data_sources(feature_table_name="clicks", sources_names="user_info.clicks")
Eliminare una tabella delle funzionalità
È possibile eliminare una tabella delle funzionalità usando l'interfaccia utente di Feature Store o l'API Python di Feature Store.
Nota
- L'eliminazione di una tabella di funzionalità può causare errori imprevisti nei producer upstream e nei consumer downstream (modelli, endpoint e processi pianificati). È necessario eliminare gli archivi online pubblicati con il provider di servizi cloud.
- Quando si elimina una tabella di funzionalità usando l'API, viene eliminata anche la tabella Delta sottostante. Quando si elimina una tabella delle funzionalità dall'interfaccia utente, è necessario eliminare separatamente la tabella Delta sottostante.
Eliminare una tabella delle funzionalità usando l'interfaccia utente
Nella pagina tabella delle funzionalità fare clic
 a destra del nome della tabella delle funzionalità e selezionare Elimina. Se non si dispone dell'autorizzazione CAN MANAGE per la tabella delle funzionalità, questa opzione non verrà visualizzata.
a destra del nome della tabella delle funzionalità e selezionare Elimina. Se non si dispone dell'autorizzazione CAN MANAGE per la tabella delle funzionalità, questa opzione non verrà visualizzata.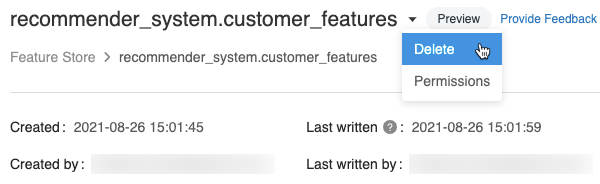
Nella finestra di dialogo Elimina tabella funzionalità fare clic su Elimina per confermare.
Se si vuole eliminare anche la tabella Delta sottostante, eseguire il comando seguente in un notebook.
%sql DROP TABLE IF EXISTS <feature-table-name>;
Eliminare una tabella delle funzionalità usando l'API Python di Feature Store
Con il client di Feature Store v0.4.1 e versioni successive, è possibile usare drop_table per eliminare una tabella delle funzionalità. Quando si elimina una tabella con drop_table, viene eliminata anche la tabella Delta sottostante.
fs.drop_table(
name='recommender_system.customer_features'
)