Creare endpoint di gestione di modelli personalizzati
Questo articolo descrive come creare endpoint di gestione di modelli che gestiscono modelli personalizzati usando Databricks Model Serving.
La gestione dei modelli offre le opzioni seguenti per la creazione di endpoint:
- Interfaccia utente di servizio
- REST API
- MLflow Deployments SDK
Per la creazione di endpoint che servono modelli di base di intelligenza artificiale generativi, vedere Creare un modello di base che gestisce gli endpoint.
Requisiti
- L'area di lavoro deve trovarsi in un'area supportata.
- Se si usano librerie o librerie personalizzate da un server mirror privato con il modello, vedere Usare librerie Python personalizzate con Model Serving prima di creare l'endpoint del modello.
- Per creare endpoint con MLflow Deployments SDK, è necessario installare il client di distribuzione MLflow. Per installarlo, eseguire:
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Controllo di accesso
Per informazioni sulle opzioni di controllo di accesso per la gestione degli endpoint del modello, vedere Gestire le autorizzazioni per l'endpoint di gestione del modello.
È anche possibile aggiungere variabili di ambiente per archiviare le credenziali per la gestione del modello. Vedere Configurare l'accesso alle risorse dagli endpoint di gestione del modello
Creare un endpoint
Interfaccia utente di gestione
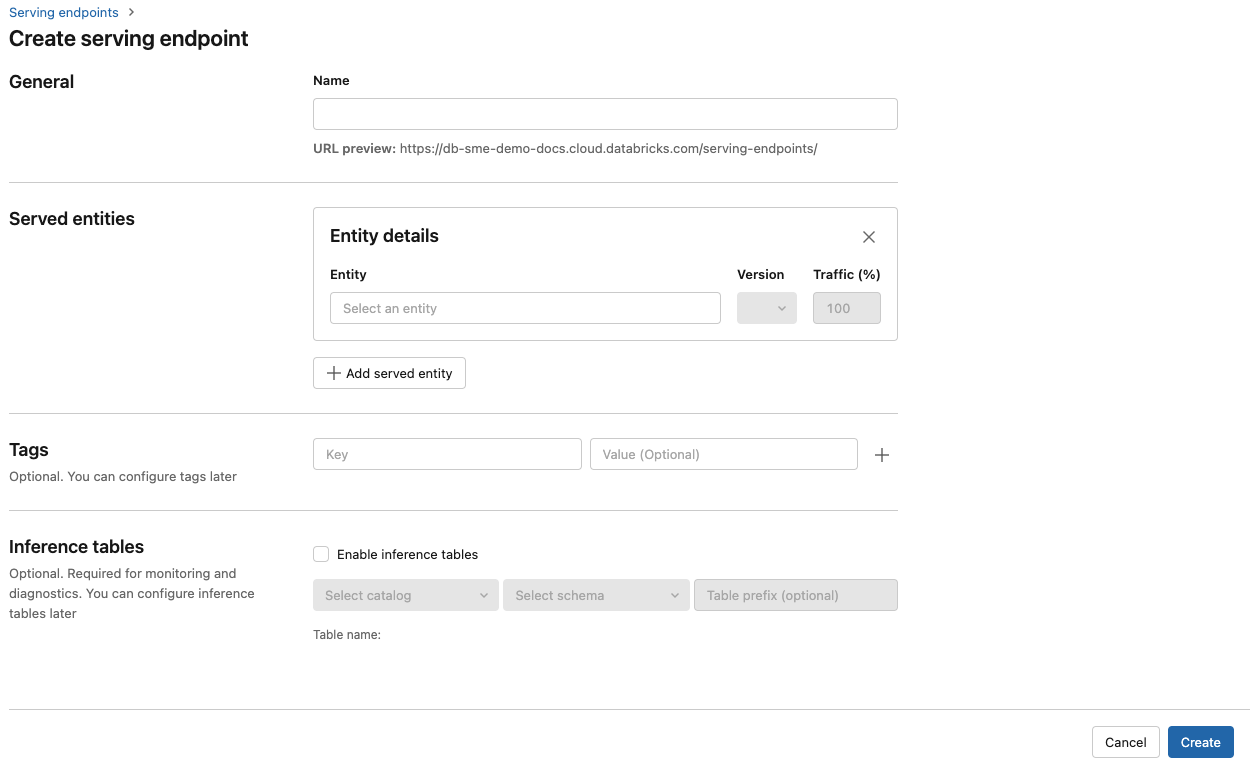
È possibile creare un endpoint per la gestione del modello con l'interfaccia utente Di servizio .
Fare clic su Serve nella barra laterale per visualizzare l'interfaccia utente Di servizio.
Fare clic su Crea endpoint di gestione.

Per i modelli registrati nel Registro modelli dell'area di lavoro o nei modelli nel catalogo unity:
Nel campo Nome specificare un nome per l'endpoint.
Nella sezione Entità servite
- Fare clic nel campo Entità per aprire il modulo Seleziona entità servita.
- Selezionare il tipo di modello da usare. Il modulo viene aggiornato dinamicamente in base alla selezione.
- Selezionare il modello e la versione del modello da usare.
- Selezionare la percentuale di traffico da instradare al modello servito.
- Selezionare le dimensioni da usare. È possibile usare le risorse di calcolo della CPU o della GPU per i carichi di lavoro. Per altre informazioni sui calcoli GPU disponibili, vedere Tipi di carico di lavoro GPU.
- In Scalabilità di calcolo selezionare le dimensioni della scalabilità orizzontale di calcolo corrispondente al numero di richieste che questo modello servito può elaborare contemporaneamente. Questo numero deve essere approssimativamente uguale al tempo di esecuzione del modello QPS x.
- Le dimensioni disponibili sono Piccole per 0-4 richieste, richieste medio 8-16 e Large per 16-64 richieste.
- Specificare se l'endpoint deve essere ridimensionato su zero quando non è in uso.
Fai clic su Crea. La pagina Gestione degli endpoint viene visualizzata con Lo stato dell'endpoint di servizio visualizzato come Non pronto.
API REST
È possibile creare endpoint usando l'API REST. Vedere POST /api/2.0/serving-endpoints per i parametri di configurazione degli endpoint.
Nell'esempio seguente viene creato un endpoint che gestisce la prima versione del ads1 modello registrata nel Registro di sistema del modello. Per specificare un modello dal catalogo unity, specificare il nome completo del modello, incluso il catalogo padre e lo schema, ad esempio . catalog.schema.example-model
POST /api/2.0/serving-endpoints
{
"name": "workspace-model-endpoint",
"config":{
"served_entities": [
{
"name": "ads-entity"
"entity_name": "my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
},
{
"entity_name": "my-ads-model",
"entity_version": "4",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":{
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
},
{
"served_model_name": "my-ads-model-4",
"traffic_percentage": 20
}
]
}
},
"tags": [
{
"key": "team",
"value": "data science"
}
]
}
Di seguito è riportata una risposta di esempio. Lo stato dell'endpoint config_update è NOT_UPDATING e il modello servito è in READY uno stato.
{
"name": "workspace-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "my-ads-model-3",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
},
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
Sdk per le distribuzioni mlflow
Le distribuzioni MLflow forniscono un'API per le attività di creazione, aggiornamento ed eliminazione. Le API per queste attività accettano gli stessi parametri dell'API REST per la gestione degli endpoint. Vedere POST /api/2.0/serving-endpoints per i parametri di configurazione degli endpoint.
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="workspace-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
}
}
)
È anche possibile:
- Configurare l'endpoint per la gestione di più modelli.
- Configurare l'endpoint per accedere alle risorse esterne usando i segreti di Databricks.
- Abilitare le tabelle di inferenza per acquisire automaticamente le richieste in ingresso e le risposte in uscita agli endpoint di gestione del modello.
Tipi di carico di lavoro GPU
La distribuzione GPU è compatibile con le versioni del pacchetto seguenti:
- Pytorch 1.13.0 - 2.0.1
- TensorFlow 2.5.0 - 2.13.0
- MLflow 2.4.0 e versioni successive
Per distribuire i modelli usando GPU, includere il workload_type campo nella configurazione dell'endpoint durante la creazione dell'endpoint o come aggiornamento della configurazione dell'endpoint usando l'API. Per configurare l'endpoint per i carichi di lavoro GPU con l'interfaccia utente Di servizio , selezionare il tipo di GPU desiderato dall'elenco a discesa Tipo di calcolo.
{
"served_entities": [{
"name": "ads1",
"entity_version": "2",
"workload_type": "GPU_LARGE",
"workload_size": "Small",
"scale_to_zero_enabled": false,
}]
}
La tabella seguente riepiloga i tipi di carico di lavoro GPU disponibili supportati.
| Tipo di carico di lavoro GPU | Istanza GPU | Memoria GPU |
|---|---|---|
GPU_SMALL |
1xT4 | 16 GB |
GPU_LARGE |
1xA100 | 80 GB |
GPU_LARGE_2 |
2xA100 | 160 GB |
Modificare un endpoint modello personalizzato
Dopo aver abilitato un endpoint modello personalizzato, è possibile aggiornare la configurazione di calcolo in base alle esigenze. Questa configurazione è particolarmente utile se sono necessarie risorse aggiuntive per il modello. Le dimensioni del carico di lavoro e la configurazione di calcolo svolgono un ruolo chiave nelle risorse allocate per gestire il modello.
Fino a quando la nuova configurazione non è pronta, la configurazione precedente continua a gestire il traffico di stima. Mentre è in corso un aggiornamento, non è possibile eseguire un altro aggiornamento. Tuttavia, è possibile annullare un aggiornamento in corso dall'interfaccia utente Di servizio.
Interfaccia utente di gestione
Dopo aver abilitato un endpoint del modello, selezionare Modifica endpoint per modificare la configurazione di calcolo dell'endpoint.
Puoi eseguire quanto segue:
- Scegliere tra alcune dimensioni del carico di lavoro e la scalabilità automatica viene configurata automaticamente entro le dimensioni del carico di lavoro.
- Specificare se l'endpoint deve essere ridotto a zero quando non è in uso.
- Modificare la percentuale di traffico per instradare al modello servito.
È possibile annullare un aggiornamento della configurazione in corso selezionando Annulla aggiornamento nella parte superiore destra della pagina dei dettagli dell'endpoint. Questa funzionalità è disponibile solo nell'interfaccia utente Di servizio.
API REST
Di seguito è riportato un esempio di aggiornamento della configurazione dell'endpoint usando l'API REST. Vedere PUT /api/2.0/serving-endpoints/{name}/config.
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "workspace-model-endpoint",
"config":{
"served_entities": [
{
"name": "ads-entity"
"entity_name": "my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
Sdk per le distribuzioni mlflow
MLflow Deployments SDK usa gli stessi parametri dell'API REST, vedere PUT /api/2.0/serving-endpoints/{name}/config per i dettagli dello schema di richiesta e risposta.
L'esempio di codice seguente usa un modello dal registro dei modelli del catalogo Unity:
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
Assegnazione di punteggi a un endpoint del modello
Per assegnare un punteggio al modello, inviare richieste all'endpoint di gestione del modello.
- Vedere Eseguire query sugli endpoint per i modelli personalizzati.
- Vedere Modelli di base di query.
Risorse aggiuntive
- Gestire gli endpoint di gestione del modello.
- Eseguire query sugli endpoint per i modelli personalizzati.
- Eseguire query sui modelli di base.
- Modelli esterni in Databricks Model Serving.
- Tabelle di inferenza per il monitoraggio e il debug dei modelli.
- Se si preferisce usare Python, è possibile usare Databricks sdk in tempo reale.
Esempi di notebook
I notebook seguenti includono modelli registrati di Databricks diversi che è possibile usare per iniziare a usare i modelli che gestiscono gli endpoint.
Gli esempi di modello possono essere importati nell'area di lavoro seguendo le istruzioni riportate in Importare un notebook. Dopo aver scelto e creato un modello da uno degli esempi, registrarlo nel Registro modelli MLflow e quindi seguire i passaggi del flusso di lavoro dell'interfaccia utente per la gestione del modello.
Eseguire il training e registrare un modello scikit-learn per il notebook di gestione dei modelli
Eseguire il training e registrare un modello HuggingFace per il notebook di gestione dei modelli
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per