Tabelle di inferenza per il monitoraggio e il debug dei modelli
Importante
Questa funzionalità è disponibile in anteprima pubblica.
Questo articolo descrive le tabelle di inferenza per il monitoraggio dei modelli serviti. Il diagramma seguente mostra un flusso di lavoro tipico con tabelle di inferenza. La tabella di inferenza acquisisce automaticamente le richieste in ingresso e le risposte in uscita per un endpoint di gestione del modello e le registra come tabella Delta del catalogo Unity. È possibile usare i dati in questa tabella per monitorare, eseguire il debug e migliorare i modelli di Machine Learning.
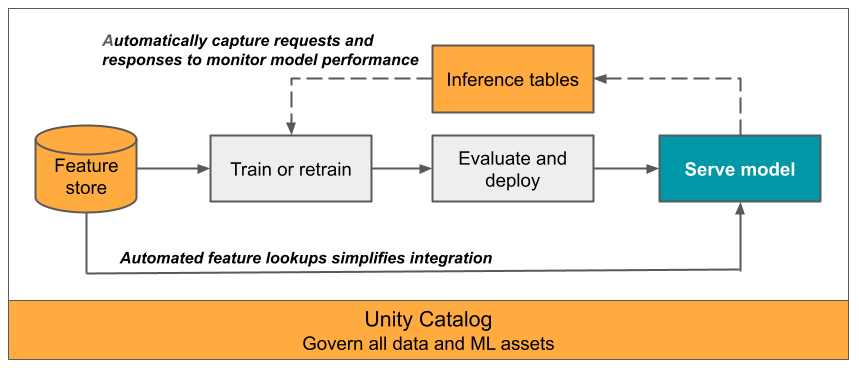
Che cosa sono le tabelle di inferenza?
Il monitoraggio delle prestazioni dei modelli nei flussi di lavoro di produzione è un aspetto importante del ciclo di vita del modello di Intelligenza artificiale e Machine Learning. Le tabelle di inferenza semplificano il monitoraggio e la diagnostica per i modelli registrando continuamente gli input e le risposte delle richieste (stime) dagli endpoint di gestione dei modelli di Databricks e salvandoli in una tabella Delta nel catalogo Unity. È quindi possibile usare tutte le funzionalità della piattaforma Databricks, ad esempio query DBSQL, notebook e Monitoraggio Lakehouse per monitorare, eseguire il debug e ottimizzare i modelli.
È possibile abilitare le tabelle di inferenza in qualsiasi endpoint del modello esistente o appena creato e le richieste a tale endpoint vengono quindi registrate automaticamente in una tabella in UC.
Di seguito sono riportate alcune applicazioni comuni per le tabelle di inferenza:
- Monitorare i dati e la qualità del modello. È possibile monitorare continuamente le prestazioni del modello e la deriva dei dati usando Il monitoraggio di Lakehouse. Il monitoraggio di Lakehouse genera automaticamente dashboard di qualità dei dati e dei modelli che è possibile condividere con gli stakeholder. Inoltre, è possibile abilitare gli avvisi per sapere quando è necessario ripetere il training del modello in base ai turni nei dati in ingresso o a riduzioni delle prestazioni del modello.
- Eseguire il debug dei problemi di produzione. Dati di log delle tabelle di inferenza, ad esempio codici di stato HTTP, tempi di esecuzione del modello e codice JSON di richiesta e risposta. È possibile usare questi dati sulle prestazioni a scopo di debug. È anche possibile usare i dati cronologici nelle tabelle di inferenza per confrontare le prestazioni del modello sulle richieste cronologiche.
- Creare un corpus di training. Unendo tabelle di inferenza con etichette di verità di base, è possibile creare un corpus di training che è possibile usare per eseguire nuovamente il training o ottimizzare e migliorare il modello. Usando i flussi di lavoro di Databricks, è possibile configurare un ciclo di feedback continuo e automatizzare il nuovo training.
Requisiti
- L'area di lavoro deve avere Unity Catalog abilitato.
- Per abilitare le tabelle di inferenza in un endpoint sia l'autore dell'endpoint che il modificatore necessitano delle autorizzazioni seguenti:
- AUTORIZZAZIONE CAN MANAGE per l'endpoint.
USE CATALOGautorizzazioni per il catalogo specificato.USE SCHEMAautorizzazioni per lo schema specificato.CREATE TABLEautorizzazioni nello schema.
Abilitare e disabilitare le tabelle di inferenza
Questa sezione illustra come abilitare o disabilitare le tabelle di inferenza usando l'interfaccia utente di Databricks. È anche possibile usare l'API; Per istruzioni, vedere Abilitare le tabelle di inferenza nei modelli che servono gli endpoint usando l'API .
Il proprietario delle tabelle di inferenza è l'utente che ha creato l'endpoint. Tutti gli elenchi di controllo di accesso (ACL) nella tabella seguono le autorizzazioni standard del catalogo Unity e possono essere modificati dal proprietario della tabella.
Avviso
La tabella di inferenza potrebbe essere danneggiata se si esegue una delle operazioni seguenti:
- Modificare lo schema della tabella.
- Modificare il nome della tabella.
- Eliminare la tabella.
- Perdono le autorizzazioni per il catalogo o lo schema di Unity Catalog.
In questo caso, lo auto_capture_config stato dell'endpoint mostra uno FAILED stato per la tabella del payload. In questo caso, è necessario creare un nuovo endpoint per continuare a usare le tabelle di inferenza.
Per abilitare le tabelle di inferenza durante la creazione dell'endpoint, seguire questa procedura:
Fare clic su Serve nell'interfaccia utente di Machine Learning di Databricks.
Fare clic su Crea endpoint di gestione.
Selezionare Abilita tabelle di inferenza.
Nei menu a discesa selezionare il catalogo e lo schema desiderati in cui si desidera trovare la tabella.
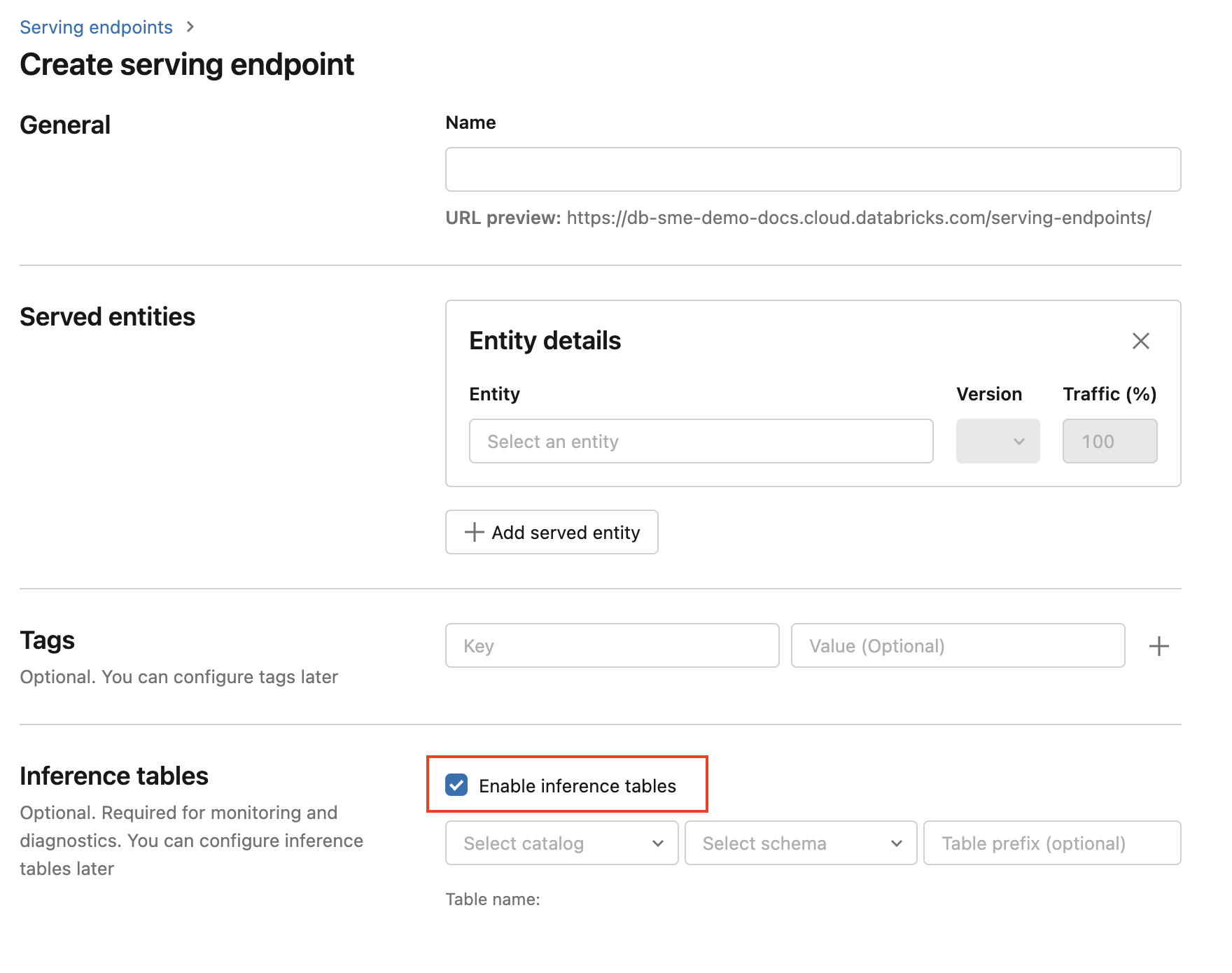
Il nome predefinito della tabella è
<catalog>.<schema>.<endpoint-name>_payload. Se lo si desidera, è possibile immettere un prefisso di tabella personalizzato.Fare clic su Crea endpoint di gestione.
È anche possibile abilitare le tabelle di inferenza in un endpoint esistente. Per modificare una configurazione dell'endpoint esistente, eseguire le operazioni seguenti:
- Passare alla pagina dell'endpoint.
- Fare clic su Modifica configurazione.
- Seguire le istruzioni precedenti, a partire dal passaggio 3.
- Al termine, fare clic su Aggiorna endpoint di gestione.
Seguire queste istruzioni per disabilitare le tabelle di inferenza:
Importante
Quando si disabilitano le tabelle di inferenza in un endpoint, non è possibile riabilitarle. Per continuare a usare le tabelle di inferenza, è necessario creare un nuovo endpoint e abilitare le tabelle di inferenza.
- Passare alla pagina dell'endpoint.
- Fare clic su Modifica configurazione.
- Fare clic su Abilita tabella di inferenza per rimuovere il segno di spunta.
- Dopo aver soddisfatto le specifiche dell'endpoint, fare clic su Aggiorna.
Flusso di lavoro: monitorare le prestazioni del modello usando le tabelle di inferenza
Per monitorare le prestazioni del modello usando le tabelle di inferenza, seguire questa procedura:
- Abilitare le tabelle di inferenza nell'endpoint, durante la creazione dell'endpoint o aggiornandole in seguito.
- Pianificare un flusso di lavoro per elaborare i payload JSON nella tabella di inferenza decomprimendoli in base allo schema dell'endpoint.
- (Facoltativo) Unire le richieste e le risposte decompresse con etichette di verità di base per consentire il calcolo delle metriche di qualità del modello.
- Creare un monitoraggio sulla tabella Delta risultante e aggiornare le metriche.
I notebook di avvio implementano questo flusso di lavoro.
Notebook di avvio per il monitoraggio di una tabella di inferenza
Il notebook seguente implementa i passaggi descritti in precedenza per decomprimere le richieste da una tabella di inferenza di Lakehouse Monitoring. Il notebook può essere eseguito su richiesta o su una pianificazione ricorrente usando i flussi di lavoro di Databricks.
Notebook iniziale di inferenza della tabella Lakehouse Monitoring
Notebook di avvio per il monitoraggio della qualità del testo dagli endpoint che servono IMS
Il notebook seguente decomprime le richieste da una tabella di inferenza, calcola un set di metriche di valutazione del testo (ad esempio leggibilità e tossicità) e abilita il monitoraggio su queste metriche. Il notebook può essere eseguito su richiesta o su una pianificazione ricorrente usando i flussi di lavoro di Databricks.
Notebook iniziale per l'inferenza LLM Lakehouse Monitoring
Eseguire query e analizzare i risultati nella tabella di inferenza
Dopo che i modelli serviti sono pronti, tutte le richieste effettuate ai modelli vengono registrate automaticamente nella tabella di inferenza, insieme alle risposte. È possibile visualizzare la tabella nell'interfaccia utente, eseguire query sulla tabella da DBSQL o da un notebook oppure eseguire query sulla tabella usando l'API REST.
Per visualizzare la tabella nell'interfaccia utente: nella pagina dell'endpoint fare clic sul nome della tabella di inferenza per aprire la tabella in Esplora cataloghi.

Per eseguire query sulla tabella da DBSQL o da un notebook di Databricks: è possibile eseguire codice simile al seguente per eseguire una query sulla tabella di inferenza.
SELECT * FROM <catalog>.<schema>.<payload_table>
Se sono state abilitate le tabelle di inferenza usando l'interfaccia utente, payload_table è il nome della tabella assegnato al momento della creazione dell'endpoint. Se sono state abilitate le tabelle di inferenza usando l'API, payload_table viene segnalato nella state sezione della auto_capture_config risposta. Per un esempio, vedere Abilitare le tabelle di inferenza nei modelli che servono gli endpoint usando l'API.
Nota sulle prestazioni
Dopo aver richiamato l'endpoint, è possibile visualizzare la chiamata registrata nella tabella di inferenza entro 10 minuti dall'invio di una richiesta di assegnazione dei punteggi. Inoltre, Azure Databricks garantisce che il recapito dei log avvenga almeno una volta, quindi è possibile, anche se improbabile, che vengano inviati log duplicati.
Schema della tabella di inferenza del catalogo Unity
Ogni richiesta e risposta registrata in una tabella di inferenza viene scritta in una tabella Delta con lo schema seguente:
Nota
Se si richiama l'endpoint con un batch di input, l'intero batch viene registrato come una riga.
| Nome colonna | Descrizione | Tipo |
|---|---|---|
databricks_request_id |
Identificatore di richiesta generato da Azure Databricks associato a tutte le richieste di gestione del modello. | STRING |
client_request_id |
Identificatore di richiesta generato dal client facoltativo che può essere specificato nel corpo della richiesta di gestione del modello. Per altre informazioni, vedere Specificare client_request_id . |
STRING |
date |
Data UTC in cui è stata ricevuta la richiesta di gestione del modello. | DATE |
timestamp_ms |
Timestamp in millisecondi di periodo in cui è stata ricevuta la richiesta di gestione del modello. | LONG |
status_code |
Codice di stato HTTP restituito dal modello. | INT |
sampling_fraction |
Frazione di campionamento utilizzata nel caso in cui la richiesta sia stata campionata. Questo valore è compreso tra 0 e 1, dove 1 indica che è stato incluso il 100% delle richieste in ingresso. | DOUBLE |
execution_time_ms |
Tempo di esecuzione in millisecondi per il quale il modello ha eseguito l'inferenza. Ciò non include latenze di rete sovraccariche e rappresenta solo il tempo impiegato per generare stime dal modello. | LONG |
request |
Corpo JSON della richiesta non elaborato inviato all'endpoint di gestione del modello. | STRING |
response |
Corpo JSON della risposta non elaborata restituito dall'endpoint di gestione del modello. | STRING |
request_metadata |
Mappa dei metadati correlati all'endpoint di gestione del modello associato alla richiesta. Questa mappa contiene il nome dell'endpoint, il nome del modello e la versione del modello usati per l'endpoint. | MAP<STRING, STRING> |
Specificare client_request_id
Il client_request_id campo è un valore facoltativo che l'utente può fornire nel corpo della richiesta di gestione del modello. In questo modo l'utente può fornire il proprio identificatore per una richiesta che viene visualizzata nella tabella di inferenza finale in client_request_id e può essere usata per unire la richiesta ad altre tabelle che usano l'etichetta client_request_id, ad esempio l'etichetta di verità di base join. Per specificare un client_request_idoggetto , includerlo come chiave di primo livello del payload della richiesta. Se non viene specificato alcun valore client_request_id , il valore viene visualizzato come Null nella riga corrispondente alla richiesta.
{
"client_request_id": "<user-provided-id>",
"dataframe_records": [
{
"sepal length (cm)": 5.1,
"sepal width (cm)": 3.5,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.9,
"sepal width (cm)": 3,
"petal length (cm)": 1.4,
"petal width (cm)": 0.2
},
{
"sepal length (cm)": 4.7,
"sepal width (cm)": 3.2,
"petal length (cm)": 1.3,
"petal width (cm)": 0.2
}
]
}
Può client_request_id essere usato in un secondo momento per i join di etichette di verità di base se sono presenti altre tabelle con etichette associate all'oggetto client_request_id.
Limiti
- Le chiavi gestite dal cliente non sono supportate.
- Per gli endpoint che ospitano modelli di base, le tabelle di inferenza sono supportate solo nei carichi di lavoro con velocità effettiva con provisioning.
- Le tabelle di inferenza sugli endpoint di velocità effettiva con provisioning non supportano la registrazione delle richieste di streaming.
- Le tabelle di inferenza non sono supportate sugli endpoint che ospitano modelli esterni.
- Firewall di Azure non è supportato e può causare errori durante la creazione della tabella Delta del catalogo Unity.
- Quando le tabelle di inferenza sono abilitate, il limite per la concorrenza massima totale in tutti i modelli serviti in un singolo endpoint è 128. Contattare il team dell'account Azure Databricks per richiedere un aumento di questo limite.
- Se una tabella di inferenza contiene più di 500.000 file, non vengono registrati dati aggiuntivi. Per evitare di superare questo limite, eseguire OPTIMIZE o configurare la conservazione nella tabella eliminando i dati meno recenti. Per controllare il numero di file nella tabella, eseguire
DESCRIBE DETAIL <catalog>.<schema>.<payload_table>.
Per informazioni generali sulle limitazioni degli endpoint, vedere Limiti e aree di gestione dei modelli.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per