Esercitazione: Distribuire ed eseguire query su un modello personalizzato
Questo articolo illustra i passaggi di base per la distribuzione e l'esecuzione di query su un modello personalizzato, ovvero un modello di Machine Learning tradizionale, installato nel catalogo Unity o registrato nel registro dei modelli dell'area di lavoro usando il modello di Azure Databricks che gestisce il modello.
Di seguito sono riportate le guide che descrivono la gestione e la distribuzione di un modello di base per l'intelligenza artificiale generativa e LLM:
Passaggio 1: Registrare il modello nel Registro di sistema del modello
Esistono diversi modi per registrare il modello per la gestione del modello:
| Tecnica di registrazione | Descrizione |
|---|---|
| Registrazione automatica | Questa opzione viene attivata automaticamente quando si usa Databricks Runtime per l'apprendimento automatico. È il modo più semplice, ma ti dà meno controllo. |
| Registrazione con le versioni predefinite di MLflow | È possibile registrare manualmente il modello con le versioni predefinite del modello di MLflow. |
Registrazione personalizzata con pyfunc |
Usare questa opzione se si dispone di un modello personalizzato o se sono necessari passaggi aggiuntivi prima o dopo l'inferenza. |
L'esempio seguente illustra come registrare il modello MLflow usando il transformer tipo e specificare i parametri necessari per il modello.
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
Dopo aver registrato il modello, assicurarsi di verificare che il modello sia registrato nel catalogo unity di MLflow o nel Registro di sistema dei modelli.
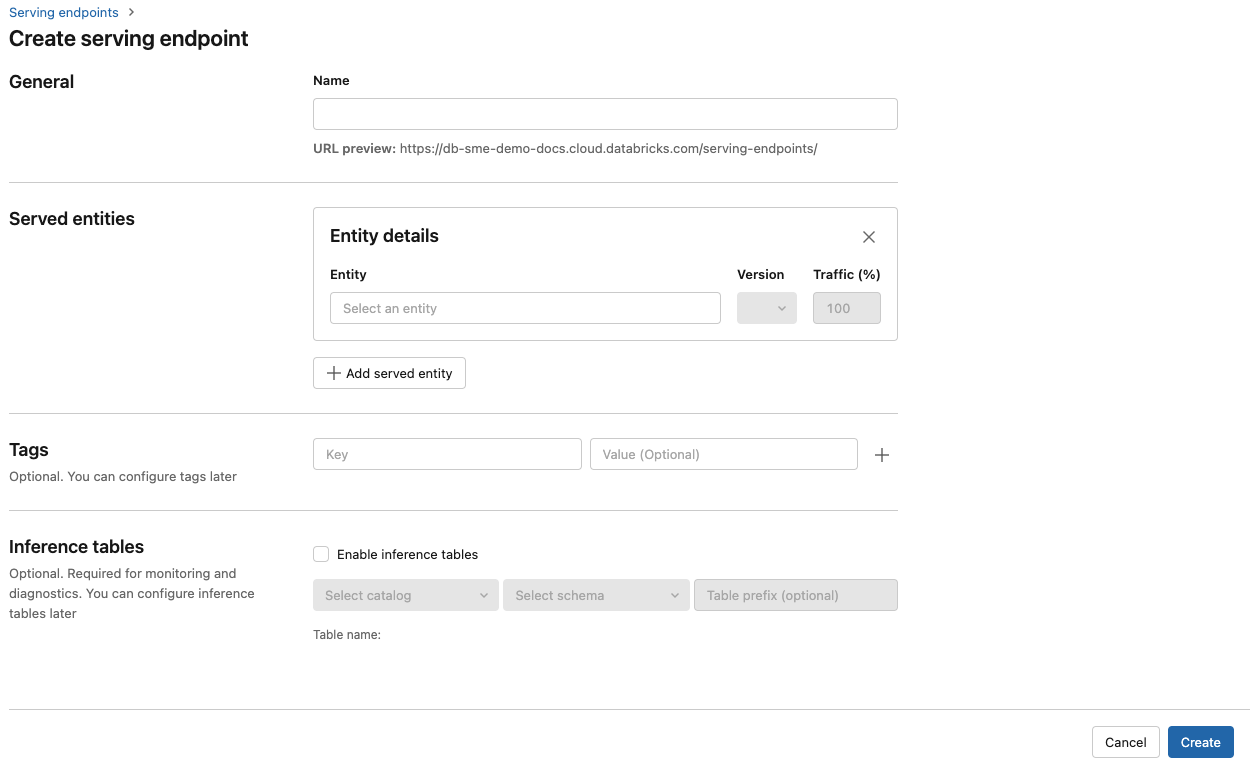
Passaggio 2: Creare un endpoint usando l'interfaccia utente di gestione
Dopo aver registrato il modello registrato e averla usata, è possibile creare un endpoint di gestione del modello usando l'interfaccia utente Di servizio .
Fare clic su Serve nella barra laterale per visualizzare l'interfaccia utente Di servizio .
Fare clic su Crea endpoint di gestione.

Nel campo Nome specificare un nome per l'endpoint.
Nella sezione Entità servite
- Fare clic nel campo Entità per aprire il modulo Seleziona entità servita.
- Selezionare il tipo di modello da usare. Il modulo viene aggiornato dinamicamente in base alla selezione.
- Selezionare il modello e la versione del modello da usare.
- Selezionare la percentuale di traffico da instradare al modello servito.
- Selezionare le dimensioni da usare. È possibile usare le risorse di calcolo della CPU o della GPU per i carichi di lavoro. Il supporto per la gestione dei modelli nella GPU è disponibile in anteprima pubblica. Per altre informazioni sui calcoli GPU disponibili, vedere Tipi di carico di lavoro GPU.
- In Scalabilità di calcolo selezionare le dimensioni della scalabilità orizzontale di calcolo corrispondente al numero di richieste che questo modello servito può elaborare contemporaneamente. Questo numero deve essere approssimativamente uguale al tempo di esecuzione del modello QPS x.
- Le dimensioni disponibili sono Piccole per 0-4 richieste, richieste medio 8-16 e Large per 16-64 richieste.
- Specificare se l'endpoint deve essere ridimensionato su zero quando non è in uso.
Fai clic su Crea. La pagina Gestione degli endpoint viene visualizzata con Lo stato dell'endpoint di servizio visualizzato come Non pronto.
Se si preferisce creare un endpoint a livello di codice con l'API Di gestione di Databricks, vedere Creare endpoint di gestione di modelli personalizzati.
Passaggio 3: Eseguire una query sull'endpoint
Il modo più semplice e rapido per testare e inviare richieste di assegnazione dei punteggi al modello servito consiste nell'usare l'interfaccia utente Di servizio .
Nella pagina Endpoint di servizio selezionare Endpoint di query.
Inserire i dati di input del modello in formato JSON e fare clic su Invia richiesta. Se il modello è stato registrato con un esempio di input, fare clic su Mostra esempio per caricare l'esempio di input.
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
Per inviare richieste di assegnazione dei punteggi, costruire un codice JSON con una delle chiavi supportate e un oggetto JSON corrispondente al formato di input. Vedere Eseguire query sugli endpoint per i modelli personalizzati per i formati supportati e indicazioni su come inviare richieste di assegnazione dei punteggi usando l'API.
Se si prevede di accedere all'endpoint di servizio all'esterno dell'interfaccia utente di Azure Databricks Serving, è necessario un .DATABRICKS_API_TOKEN
Importante
Come procedura consigliata per la sicurezza per gli scenari di produzione, Databricks consiglia di usare token OAuth da computer a computer per l'autenticazione durante l'ambiente di produzione.
Per il test e lo sviluppo, Databricks consiglia di usare un token di accesso personale appartenente alle entità servizio anziché agli utenti dell'area di lavoro. Per creare token per le entità servizio, vedere Gestire i token per un'entità servizio.
Notebook di esempio
Vedere il notebook seguente per la gestione di un modello MLflow transformers con Model Serving.
Distribuire un notebook del modello Hugging Face transformers
Vedere il notebook seguente per la gestione di un modello MLflow pyfunc con Model Serving. Per altri dettagli sulla personalizzazione delle distribuzioni del modello, vedere Distribuire il codice Python con Model Serving.
Distribuire un notebook del modello MLflow pyfunc
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per