Questa architettura di esempio si basa sull'architettura di esempio dell'applicazione Web Basic ed estenderla per visualizzare:
- Procedure comprovate per migliorare la scalabilità e le prestazioni in un'applicazione Web del servizio app Azure
- Come eseguire un'applicazione di servizio app Azure in più aree per ottenere una disponibilità elevata
Architettura
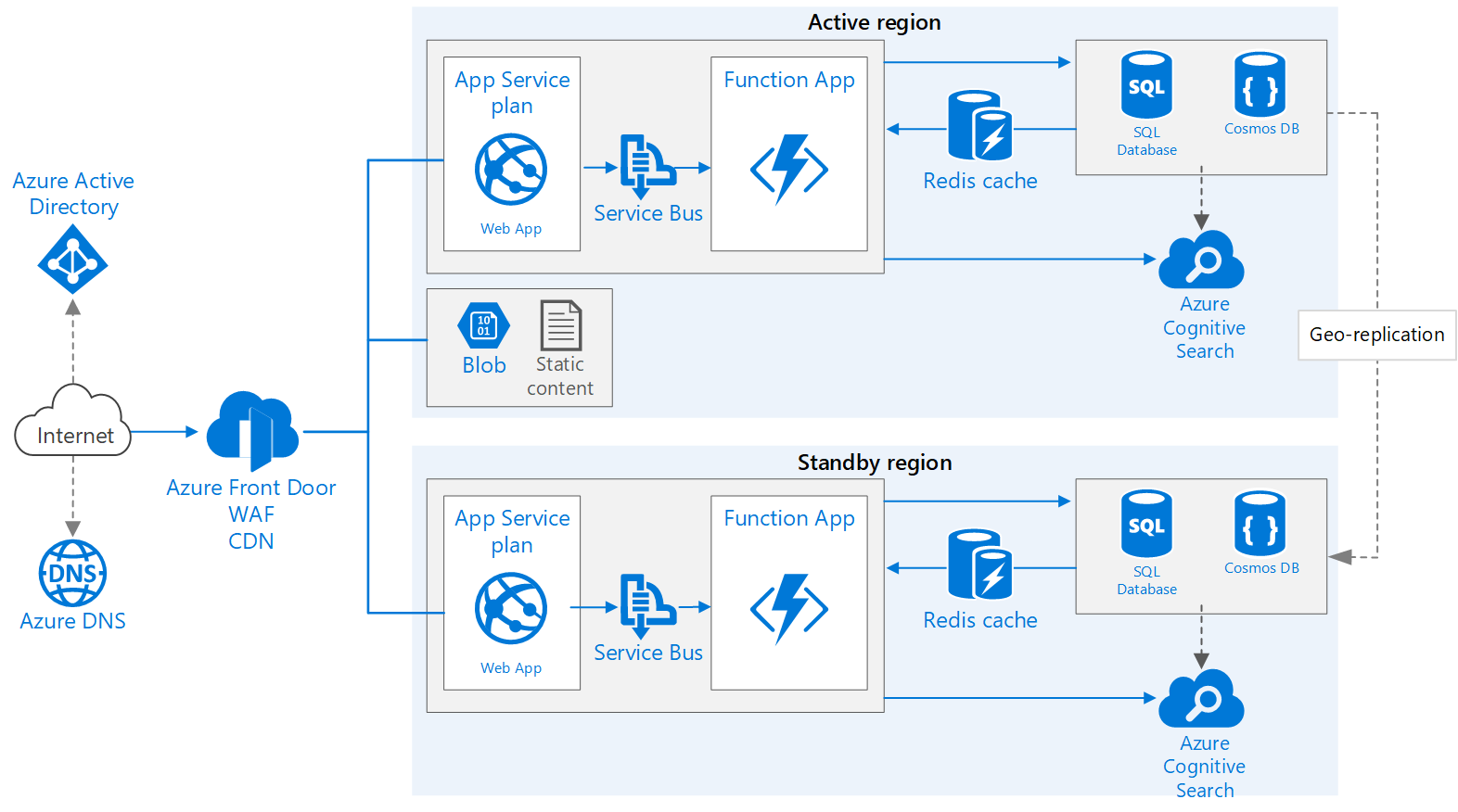
Scaricare un file di Visio di questa architettura.
Workflow
Questo flusso di lavoro affronta gli aspetti in più aree dell'architettura e si basa sull'applicazione Web Basic.
- Aree primarie e secondarie. Questa architettura si basa sull'uso di due aree per ottenere una maggiore disponibilità. L'applicazione viene distribuita in ognuna delle aree. Durante il normale funzionamento, il traffico di rete viene indirizzato all'area primaria. Se l'area primaria non è più disponibile, il traffico viene indirizzato all'area secondaria.
- Frontdoor. Frontdoor di Azure è il servizio di bilanciamento del carico consigliato per le implementazioni in più aree. Si integra con web application firewall (WAF) per proteggersi da exploit comuni e usa la funzionalità di memorizzazione nella cache del contenuto nativo di Frontdoor. In questa architettura Frontdoor è configurato per il routing con priorità , che invia tutto il traffico all'area primaria, a meno che non diventi non disponibile. Se l'area primaria non è più disponibile, Frontdoor instrada tutto il traffico all'area secondaria.
- Replica geografica di account Archiviazione, database SQL e/o Azure Cosmos DB.
Nota
Per una panoramica dettagliata dell'uso di Frontdoor di Azure per le architetture in più aree, tra cui in una configurazione protetta dalla rete, vedere Implementazione di ingresso sicura di rete.
Componenti
Tecnologie chiave usate per implementare questa architettura:
- Microsoft Entra ID è un servizio di gestione delle identità e degli accessi basato sul cloud che consente ai dipendenti di accedere alle app cloud sviluppate per l'organizzazione.
- DNS di Azure è un servizio di hosting per i domini DNS, che fornisce la risoluzione dei nomi usando l'infrastruttura di Microsoft Azure. Ospitando i domini in Azure, è possibile gestire i record DNS usando le stesse credenziali, API, strumenti e fatturazione come per gli altri servizi Azure. Per usare un nome di dominio personalizzato ( ad esempio
contoso.com), creare record DNS che eseguono il mapping del nome di dominio personalizzato all'indirizzo IP. Per ulteriori informazioni, vedere Configurare un nome di dominio personalizzato nel servizio app di Azure. - Azure rete per la distribuzione di contenuti è una soluzione globale per distribuire contenuto a larghezza di banda elevata memorizzandolo nella cache in nodi fisici posizionati in modo strategico in tutto il mondo.
- Frontdoor di Azure è un servizio di bilanciamento del carico di livello 7. In questa architettura, instrada le richieste HTTP al front-end Web. Frontdoor fornisce anche un web application firewall (WAF) che protegge l'applicazione da exploit e vulnerabilità comuni. Frontdoor viene usato anche per una soluzione rete per la distribuzione di contenuti (rete CDN) in questa progettazione.
- app Azure Service è una piattaforma completamente gestita per la creazione e la distribuzione di applicazioni cloud. Consente di definire un set di risorse di calcolo per l'esecuzione di un'app Web, la distribuzione di app Web e la configurazione degli slot di distribuzione.
- Le app per le funzioni di Azure possono essere usate per eseguire attività in background. Le funzioni vengono richiamate da un trigger, ad esempio un evento del timer o l'inserimento di un messaggio in una coda. Per attività con stato ed esecuzione prolungata, usare Durable Functions.
- Archiviazione di Azure è una soluzione di archiviazione cloud per scenari moderni di archiviazione dei dati, che offre un'archiviazione a disponibilità elevata, scalabile, durevole e sicura per un'ampia gamma di oggetti dati nel cloud.
- Cache Redis di Azure è un servizio di memorizzazione nella cache ad alte prestazioni che fornisce un archivio dati in memoria per un recupero più rapido dei dati, in base all'implementazione open source della cache Redis.
- database SQL di Azure è un database relazionale come servizio nel cloud. Il database SQL condivide la base di codice con il motore di database di Microsoft SQL Server.
- Azure Cosmos DB è un database multimodello distribuito a livello globale, completamente gestito, a bassa latenza, multimodello e API per la gestione dei dati su larga scala.
- Ricerca cognitiva di Azure può essere usato per aggiungere funzionalità di ricerca, ad esempio suggerimenti di ricerca, ricerca fuzzy e ricerca specifica della lingua. Il servizio Ricerca di Azure viene in genere usato in combinazione con un altro archivio dati, soprattutto se l'archivio dati primario richiede la coerenza assoluta. In questo approccio, archiviare i dati autorevoli nell'altro archivio dati e l'indice di ricerca in Ricerca di Azure. Ricerca di Azure può essere usato anche per creare un unico indice di ricerca da più archivi dati.
Dettagli dello scenario
Esistono diversi approcci generali per ottenere la disponibilità elevata tra aree:
Attivo/Passivo con hot standby: il traffico passa a un'area, mentre l'altro attende in hot standby. Hot standby indica che la servizio app nell'area secondaria viene allocata ed è sempre in esecuzione.
Attivo/Passivo con standby a freddo: il traffico passa a un'area, mentre l'altro attende in standby a freddo. Standby a freddo indica che il servizio app nell'area secondaria non viene allocato fino a quando non è necessario per il failover. Questo approccio presenta costi inferiori in termini di esecuzione, ma in genere richiederà più tempo per portare online le risorse in caso di errore.
Attivo/Attivo: entrambe le aree sono attive e le richieste vengono bilanciate tra di esse. Se un'area non è più disponibile, viene estratta dalla rotazione.
Questo riferimento è incentrato su attivo/passivo con hot standby.
Potenziali casi d'uso
Questi casi d'uso possono trarre vantaggio da una distribuzione in più aree:
Progettare un piano di continuità aziendale e ripristino di emergenza per le applicazioni LoB.
Distribuire applicazioni cruciali eseguite in Windows o Linux.
Migliorare l'esperienza utente mantenendo disponibili le applicazioni.
Consigli
I requisiti della propria organizzazione potrebbero essere diversi da quelli dell'architettura descritta in questo articolo. Seguire le raccomandazioni contenute in questa sezione come punto di partenza.
Coppie di aree
Ogni area di Azure è abbinata a un'altra area con la stessa collocazione geografica. In generale, è consigliabile scegliere aree della stessa coppia di aree (ad esempio, Stati Uniti orientali 2 e Stati Uniti centrali). I vantaggi di questi armadietti sono:
- Se si verifica un'interruzione generale, il ripristino di almeno un'area all'esterno di ogni coppia è prioritario.
- Gli aggiornamenti di sistema di Azure pianificati vengono implementati in sequenza tra le aree abbinate per ridurre al minimo l'eventuale tempo di inattività.
- Nella maggior parte dei casi le coppie di aree si trovano nella stessa area geografica per soddisfare i requisiti di residenza dei dati.
Assicurarsi tuttavia che entrambe le aree supportino tutti i servizi di Azure necessari per l'applicazione. Vedere i servizi disponibili in base all'area. Per altre informazioni sulle coppie di aree, vedere Continuità aziendale e ripristino di emergenza nelle aree geografiche abbinate di Azure.
Gruppi di risorse
Valutare la possibilità di inserire l'area primaria, l'area secondaria e Frontdoor in gruppi di risorse separati. Questa allocazione consente di gestire le risorse distribuite in ogni area come singola raccolta.
App del servizio app
È consigliabile creare l'applicazione Web e l'API Web come app del servizio app separate. In questo modo potranno essere eseguite in piani di servizio app separati ed essere scalate in maniera indipendente. Se inizialmente questo livello di scalabilità non è necessario, è possibile distribuire le app nello stesso piano e successivamente spostarle in piani distinti, se necessario.
Nota
Per i piani Basic, Standard, Premium e Isolato, vengono fatturate le istanze di macchina virtuale nel piano, non per app. Vedere Prezzi di Servizio app .
Configurazione di Frontdoor
Routing. Frontdoor supporta diversi meccanismi di routing. Per lo scenario descritto in questo articolo, usare il routing con priorità . Con questa impostazione, Frontdoor invia tutte le richieste all'area primaria a meno che l'endpoint per tale area non diventi raggiungibile. A questo punto, viene automaticamente effettuato il failover all'area secondaria. Impostare il pool di origine con valori di priorità diversi, 1 per l'area attiva e 2 o versione successiva per l'area di standby o passiva.
Probe di integrità. Frontdoor usa un probe HTTPS per monitorare la disponibilità di ogni back-end. Il probe fornisce a Frontdoor un test superato/negativo per il failover nell'area secondaria. che funziona inviando una richiesta a un percorso URL specificato. In caso di una risposta diversa da 200 entro un periodo di timeout, il probe ha esito negativo. È possibile configurare la frequenza del probe di integrità, il numero di campioni necessari per la valutazione e il numero di campioni riusciti necessari per contrassegnare l'origine come integro. Se Frontdoor contrassegna l'origine come danneggiata, esegue il failover nell'altra origine. Per informazioni dettagliate, vedere Probe di integrità.
Come procedura consigliata, creare un percorso probe di integrità nell'origine dell'applicazione che segnala l'integrità complessiva dell'applicazione. Questo probe di integrità deve controllare le dipendenze critiche, ad esempio le app servizio app, la coda di archiviazione e database SQL. In caso contrario, il probe potrebbe segnalare un'origine integra quando parti critiche dell'applicazione hanno effettivamente esito negativo. D'altra parte, non usare il probe di integrità per controllare i servizi con una priorità più bassa. Ad esempio, se un servizio di posta elettronica si arresta, l'applicazione può passare a un secondo provider o semplicemente inviare i messaggi in un secondo momento. Per altre informazioni su questo modello di progettazione, vedere Modello di monitoraggio degli endpoint di integrità.
La protezione delle origini da Internet è una parte fondamentale dell'implementazione di un'app accessibile pubblicamente. Per informazioni sui modelli di progettazione e implementazione consigliati di Microsoft per proteggere le comunicazioni in ingresso dell'app con Frontdoor, vedere Implementazione sicura della rete.
Rete CDN. Usare la funzionalità di rete CDN nativa di Frontdoor per memorizzare nella cache il contenuto statico. Il vantaggio principale di una rete CDN è quello di ridurre la latenza per gli utenti, in quanto il contenuto viene memorizzato nella cache di un server perimetrale geograficamente vicino all'utente. La rete CDN può anche ridurre il carico sull'applicazione, poiché il traffico non viene gestito dall'applicazione. Frontdoor offre inoltre l'accelerazione dinamica del sito che consente di offrire un'esperienza utente migliore per l'app Web rispetto a quella disponibile solo con la memorizzazione nella cache del contenuto statico.
Nota
Frontdoor rete CDN non è progettato per gestire il contenuto che richiede l'autenticazione.
Database SQL
Usare la replica geografica attiva e i gruppi di failover automatico per rendere resilienti i database. La replica geografica attiva consente di replicare i database dall'area primaria in una o più (fino a quattro) altre aree. I gruppi di failover automatico si basano sulla replica geografica attiva consentendo di eseguire il failover in un database secondario senza apportare modifiche al codice alle app. I failover possono essere eseguiti manualmente o automaticamente, in base alle definizioni dei criteri create. Per usare i gruppi di failover automatico, è necessario configurare le stringhe di connessione con il failover stringa di connessione creato automaticamente per il gruppo di failover, anziché i stringa di connessione dei singoli database.
Azure Cosmos DB
Azure Cosmos DB supporta la replica geografica tra aree in un modello attivo-attivo con più aree di scrittura. In alternativa, è possibile designare un'area come scrivibile e le altre come repliche di sola lettura. Se si verifica un'interruzione a livello di area, è possibile eseguire il failover selezionando un'altra area come area di scrittura. L'SDK del client invia automaticamente richieste di scrittura all'area di scrittura corrente, in modo che non sia necessario aggiornare la configurazione del client dopo un failover. Per altre informazioni, vedere Distribuzione globale dei dati con Azure Cosmos DB.
Storage
Per l'Archiviazione di Azure, usare l'archiviazione con ridondanza geografica e accesso in lettura (RA-GRS). Con l'archiviazione RA-GRS, i dati vengono replicati in un'area secondaria. È possibile accedere in sola lettura ai dati nell'area secondaria attraverso un endpoint distinto. Il failover avviato dall'utente nell'area secondaria è supportato per gli account di archiviazione con replica geografica. L'avvio di un failover di un account di archiviazione aggiorna automaticamente i record DNS per rendere l'account di archiviazione secondario il nuovo account di archiviazione primario. I failover devono essere eseguiti solo quando si ritiene necessario. Questo requisito è definito dal piano di ripristino di emergenza dell'organizzazione ed è consigliabile prendere in considerazione le implicazioni descritte nella sezione Considerazioni di seguito.
In caso di interruzione o emergenza a livello di area, il team Archiviazione di Azure potrebbe decidere di eseguire un failover geografico nell'area secondaria. Per questi tipi di failover, non è necessaria alcuna azione da parte del cliente. Il failback nell'area primaria viene gestito anche dal team di archiviazione di Azure in questi casi.
In alcuni casi la replica di oggetti per i BLOB in blocchi sarà una soluzione di replica sufficiente per il carico di lavoro. Questa funzionalità di replica consente di copiare singoli BLOB in blocchi dall'account di archiviazione primario in un account di archiviazione nell'area secondaria. I vantaggi di questo approccio sono un controllo granulare sui dati replicati. È possibile definire criteri di replica per un controllo più granulare dei tipi di BLOB in blocchi replicati. Esempi di definizioni di criteri includono, ma non sono limitati a:
- Vengono replicati solo i BLOB in blocchi aggiunti successivamente alla creazione dei criteri
- Vengono replicati solo i BLOB in blocchi aggiunti dopo una data e un'ora specificati
- Vengono replicati solo i BLOB in blocchi corrispondenti a un prefisso specificato.
L'archiviazione code viene fatto riferimento come opzione di messaggistica alternativa per bus di servizio di Azure per questo scenario. Tuttavia, se si usa l'archiviazione code per la soluzione di messaggistica, le indicazioni fornite in precedenza relative alla replica geografica si applicano qui, perché l'archiviazione code risiede negli account di archiviazione. È importante comprendere, tuttavia, che i messaggi non vengono replicati nell'area secondaria e che il relativo stato sia inesttricabile dall'area.
Bus di servizio di Azure
Per trarre vantaggio dalla resilienza più elevata offerta per bus di servizio di Azure, usare il livello Premium per gli spazi dei nomi. Il livello Premium usa le zone di disponibilità, che rende gli spazi dei nomi resilienti alle interruzioni del data center. Se si verifica un'emergenza diffusa che interessa più data center, la funzionalità di ripristino di emergenza geografico inclusa nel livello Premium consente di eseguire il ripristino. La funzionalità di ripristino di emergenza geografico garantisce che l'intera configurazione di uno spazio dei nomi (code, argomenti, sottoscrizioni e filtri) venga replicata continuamente da uno spazio dei nomi primario a uno spazio dei nomi secondario quando abbinata. Consente di avviare un failover una sola volta dal database primario al secondario in qualsiasi momento. Lo spostamento del failover riporterà il nome alias scelto per lo spazio dei nomi allo spazio dei nomi secondario e quindi interromperà l'associazione. Una volta avviato, il failover è pressoché istantaneo.
Ricerca cognitiva di Azure
In Ricerca cognitiva, la disponibilità viene ottenuta tramite più repliche, mentre la continuità aziendale e il ripristino di emergenza (BCDR) vengono ottenuti tramite più servizi di ricerca.
In Ricerca cognitiva le repliche sono copie dell'indice. La presenza di più repliche consente Ricerca cognitiva di Azure di eseguire riavvii e manutenzione del computer su una replica, mentre l'esecuzione delle query continua su altre repliche. Per altre informazioni sull'aggiunta di repliche, vedere Aggiungere o ridurre repliche e partizioni.
È possibile usare zone di disponibilità con Ricerca cognitiva di Azure aggiungendo due o più repliche al servizio di ricerca. Ogni replica verrà inserita in un'altra zona di disponibilità all'interno dell'area.
Per considerazioni sulla continuità aziendale e ripristino di emergenza, vedere la documentazione Su più servizi in aree geografiche separate.
Cache Redis di Azure
Anche se tutti i livelli di cache di Azure per Redis offrono la replica Standard per la disponibilità elevata, il livello Premium o Enterprise è consigliato per offrire un livello superiore di resilienza e recuperabilità. Esaminare la disponibilità elevata e il ripristino di emergenza per un elenco completo delle funzionalità e delle opzioni di resilienza e recuperabilità per questi livelli. I requisiti aziendali determineranno il livello migliore per l'infrastruttura.
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di set di principi guida che possono essere usati per migliorare la qualità di un carico di lavoro. Per altre informazioni, vedere Framework ben progettato di Microsoft Azure.
Affidabilità
L'affidabilità garantisce che l'applicazione possa soddisfare gli impegni che l'utente ha preso con i clienti. Per altre informazioni, vedere Panoramica del pilastro dell'affidabilità. Prendere in considerazione questi punti durante la progettazione per la disponibilità elevata tra aree.
Frontdoor di Azure
Frontdoor di Azure esegue automaticamente il failover se l'area primaria non è più disponibile. Quando frontdoor esegue il failover, è presente un periodo di tempo (in genere circa 20-60 secondi) quando i client non riescono a raggiungere l'applicazione. La durata di questo periodo è influenzata dai fattori seguenti:
- Frequenza dei probe di integrità. Più frequenti vengono inviati i probe di integrità, il frontdoor più veloce può rilevare tempi di inattività o l'origine torna integra.
- Configurazione delle dimensioni di esempio. Questa configurazione controlla il numero di campioni necessari per il probe di integrità per rilevare che l'origine primaria non è raggiungibile. Se questo valore è troppo basso, è possibile ottenere falsi positivi da problemi intermittenti.
Frontdoor è un possibile punto di guasto nel sistema. Se il servizio non riesce, i client non possono accedere all'applicazione durante il tempo di inattività. Rivedere il contratto di servizio (SLA) di Frontdoor e determinare se l'uso di Frontdoor da solo soddisfa i requisiti aziendali per la disponibilità elevata. In caso contrario, provare ad aggiungere un'altra soluzione di gestione del traffico come fallback. In caso di errore del servizio Frontdoor, cambiare i record di nome canonico (CNAME) in DNS in modo che puntino all'altro servizio di gestione del traffico. Questo passaggio deve essere eseguito manualmente e l'applicazione non sarà disponibile finché non vengono propagate le modifiche al DNS.
Il livello Frontdoor di Azure Standard e Premium combina le funzionalità di Frontdoor di Azure (versione classica), Rete CDN di Azure Standard da Microsoft (versione classica) e Azure WAF in una singola piattaforma. L'uso di Frontdoor di Azure Standard o Premium riduce i punti di errore e abilita il controllo avanzato, il monitoraggio e la sicurezza. Per altre informazioni, vedere Panoramica del livello Frontdoor di Azure.
Database SQL
L'obiettivo del punto di ripristino (RPO) e l'obiettivo del tempo di ripristino stimato (RTO) per database SQL sono documentati in Panoramica della continuità aziendale con database SQL di Azure.
Tenere presente che la replica geografica attiva raddoppia in modo efficace il costo di ogni database replicato. I database sandbox, di test e di sviluppo non sono in genere consigliati per la replica.
Azure Cosmos DB
L'obiettivo del tempo di ripristino e l'obiettivo del tempo di ripristino per Azure Cosmos DB sono configurabili tramite i livelli di coerenza usati, che offrono compromessi tra disponibilità, durabilità dei dati e velocità effettiva. Azure Cosmos DB offre un RTO minimo pari a 0 per un livello di coerenza rilassato con multimaster o RPO pari a 0 per una coerenza assoluta con un singolo master. Per altre informazioni sui livelli di coerenza di Azure Cosmos DB, vedere Livelli di coerenza e durabilità dei dati in Azure Cosmos DB.
Storage
L'archiviazione con ridondanza geografica e accesso in lettura fornisce un'archiviazione durevole, ma è importante considerare i fattori seguenti quando si prevede di eseguire un failover:
Prevedere la perdita di dati: la replica dei dati nell'area secondaria viene eseguita in modo asincrono. Pertanto, se viene eseguito un failover geografico, è necessario prevedere una perdita di dati se le modifiche all'account primario non sono state completamente sincronizzate con l'account secondario. È possibile controllare la proprietà Ora ultima sincronizzazione dell'account di archiviazione secondario per visualizzare l'ultima volta in cui i dati dell'area primaria sono stati scritti correttamente nell'area secondaria.
Pianificare di conseguenza l'obiettivo del tempo di ripristino: il failover nell'area secondaria richiede in genere circa un'ora, quindi il piano di ripristino di emergenza deve tenere conto di queste informazioni durante il calcolo dei parametri RTO.
Pianificare attentamente il failback: è importante comprendere che quando viene eseguito il failover di un account di archiviazione, i dati nell'account primario originale andranno persi. Il tentativo di eseguire un failback nell'area primaria senza un'attenta pianificazione è rischioso. Al termine del failover, il nuovo database primario, nell'area di failover, verrà configurato per l'archiviazione con ridondanza locale. È necessario riconfigurarla manualmente come risorsa di archiviazione con replica geografica per avviare la replica nell'area primaria e quindi concedere tempo sufficiente per consentire la sincronizzazione degli account.
Gli errori temporanei, ad esempio un'interruzione della rete, non attiveranno un failover di archiviazione. Progettare l'applicazione in modo che sia resiliente agli errori temporanei. Le opzioni di mitigazione includono:
- Leggere dall'area secondaria.
- Passare temporaneamente a un altro account di archiviazione per le nuove operazioni di scrittura (ad esempio, ai messaggi di coda).
- Copiare i dati dall'area secondaria a un altro account di archiviazione.
- Fornire funzionalità ridotte fino al failback del sistema.
Per altre informazioni, vedere Cosa fare se si verifica un'interruzione di Archiviazione di Azure.
Per considerazioni sull'uso della replica di oggetti per i BLOB in blocchi, vedere i prerequisiti e le avvertenze per la documentazione sulla replica di oggetti.
Bus di servizio di Azure
È importante comprendere che la funzionalità di ripristino di emergenza geografico inclusa nel livello premium bus di servizio di Azure consente la continuità immediata delle operazioni con la stessa configurazione. Tuttavia, non replica i messaggi contenuti in code o sottoscrizioni di argomenti o code di messaggi non recapitabili. Di conseguenza, è necessaria una strategia di mitigazione per garantire un failover uniforme nell'area secondaria. Per una descrizione dettagliata di altre considerazioni e strategie di mitigazione, vedere i punti importanti da considerare e la documentazione sulle considerazioni sul ripristino di emergenza.
Sicurezza
La sicurezza offre garanzie contro attacchi intenzionali e l'abuso di dati e sistemi preziosi. Per altre informazioni, vedere Panoramica del pilastro della sicurezza.
Limitare il traffico in ingresso Configurare l'applicazione per accettare il traffico solo da Frontdoor. In questo modo tutto il traffico passa attraverso il WAF prima di raggiungere l'app. Per altre informazioni, vedere Ricerca per categorie bloccare l'accesso al back-end solo in Frontdoor di Azure?
Condivisione di risorse tra le origini (CORS) Se si crea un sito Web e un'API Web come app separate, il sito Web non può effettuare chiamate AJAX sul lato client all'API a meno che non si abiliti CORS.
Nota
La sicurezza del browser impedisce a una pagina Web di creare richieste AJAX per un altro dominio. Questa restrizione è nota come criteri di corrispondenza dell'origine e impedisce a un sito dannoso di leggere dati sensibili da un altro sito. CORS è uno standard W3C che consente a un server di ridurre i criteri di corrispondenza dell'origine, oltre che di accettare alcune richieste multiorigine e rifiutarne altre.
Il supporto per CORS è incorporato in Servizi app, quindi non è necessario scrivere alcun codice applicazione. Vedere Utilizzare un'app per le API da JavaScript tramite CORS. Aggiungere il sito Web all'elenco delle origini consentite per l'API.
crittografia database SQL Usare Transparent Data Encryption se è necessario crittografare i dati inattivi nel database. Questa funzionalità esegue in tempo reale la crittografia e la decrittografia di un intero database, inclusi i backup e i file di log delle transazioni, senza dover apportare modifiche all'applicazione. La crittografia aggiunge un certo livello di latenza, quindi è consigliabile separare i dati che devono essere protetti nel relativo database e abilitare la crittografia solo per quel database.
Identità Quando si definiscono le identità per i componenti di questa architettura, usare le identità gestite dal sistema, laddove possibile, per ridurre la necessità di gestire le credenziali e i rischi intrinseci alla gestione delle credenziali. Quando non è possibile usare le identità gestite dal sistema, assicurarsi che ogni identità gestita dall'utente esista in una sola area e non sia mai condivisa tra i limiti dell'area.
Firewall del servizio Quando si configurano i firewall del servizio per i componenti, assicurarsi che solo i servizi locali dell'area abbiano accesso ai servizi e che i servizi consentano solo connessioni in uscita, richieste in modo esplicito per la funzionalità di replica e applicazione. È consigliabile usare collegamento privato di Azure per migliorare ulteriormente il controllo e la segmentazione. Per altre informazioni sulla protezione delle applicazioni Web, vedere Applicazione Web con ridondanza della zona a disponibilità elevata.
Ottimizzazione dei costi
L'ottimizzazione dei costi riguarda l'analisi dei modi per ridurre le spese non necessarie e migliorare l'efficienza operativa. Per altre informazioni, vedere Panoramica del pilastro di ottimizzazione dei costi.
Memorizzazione nella cache Usare la memorizzazione nella cache per ridurre il carico nei server che gestiscono contenuto che non cambia di frequente. Ogni ciclo di rendering di una pagina può influire sui costi perché utilizza risorse di calcolo, memoria e larghezza di banda. Questi costi possono essere ridotti in modo significativo usando la memorizzazione nella cache, in particolare per i servizi di contenuto statico, ad esempio le app a pagina singola JavaScript e il contenuto di streaming multimediale.
Se l'app include contenuto statico, usare rete CDN per ridurre il carico nei server front-end. Per i dati che non cambiano di frequente, usare cache di Azure per Redis.
Le app senza stato configurate per la scalabilità automatica sono più convenienti rispetto alle app con stato. Per un'applicazione ASP.NET che usa lo stato della sessione, archiviarla in memoria con cache di Azure per Redis. Per altre informazioni, vedere ASP.NET Provider di stato sessione per cache di Azure per Redis. Un'altra opzione consiste nell'usare Azure Cosmos DB come archivio stati back-end tramite un provider di stato della sessione. Vedere Usare Azure Cosmos DB come provider di cache e stato della sessione ASP.NET.
Le funzioni considerano l'inserimento di un'app per le funzioni in un piano di servizio app dedicato in modo che le attività in background non vengano eseguite nelle stesse istanze che gestiscono le richieste HTTP. Se le attività in background vengono eseguite in modo intermittente, prendere in considerazione l'uso di un piano a consumo, che viene fatturato in base al numero di esecuzioni e risorse usate, anziché ogni ora.
Per altre informazioni, vedere la sezione relativa ai costi in Microsoft Azure Well-Architected Framework.
Usare il calcolatore prezzi per stimare i costi. Queste raccomandazioni in questa sezione possono essere utili per ridurre i costi.
Frontdoor di Azure
La fatturazione di Frontdoor di Azure prevede tre piani tariffari: trasferimenti di dati in uscita, trasferimenti di dati in ingresso e regole di routing. Per altre informazioni, vedere Prezzi di Frontdoor di Azure. Il grafico dei prezzi non include il costo dell'accesso ai dati dai servizi di origine e il trasferimento a Frontdoor. Questi costi vengono fatturati in base agli addebiti per il trasferimento dei dati, descritti in Dettagli dei prezzi della larghezza di banda.
Azure Cosmos DB
Esistono due fattori che determinano i prezzi di Azure Cosmos DB:
Velocità effettiva con provisioning o unità richiesta al secondo (UR/sec).
Esistono due tipi di velocità effettiva di cui è possibile effettuare il provisioning in Azure Cosmos DB, standard e scalabilità automatica. La velocità effettiva standard alloca le risorse necessarie per garantire le UR/s specificate. Per la scalabilità automatica, si effettua il provisioning della velocità effettiva massima e Azure Cosmos DB aumenta o riduce immediatamente le prestazioni a seconda del carico, con un minimo del 10% della velocità effettiva massima di scalabilità automatica. La velocità effettiva standard viene fatturata per la velocità effettiva di cui è stato effettuato il provisioning orario. La velocità effettiva con scalabilità automatica viene fatturata per la velocità effettiva massima utilizzata ogni ora.
Spazio di archiviazione utilizzato. Viene addebitata una tariffa fissa per la quantità totale di spazio di archiviazione (GB) utilizzata per i dati e gli indici per un'ora specifica.
Per altre informazioni, vedere la sezione sui costi in Microsoft Azure Well-Architected Framework.
Efficienza prestazionale
Uno dei vantaggi principali del servizio app di Azure è la possibilità di scalare l'applicazione in base al carico. Ecco alcune considerazioni da tenere presenti quando si pianifica la scalabilità dell'applicazione.
app del servizio app
Se la propria soluzione include diverse app del servizio app, è consigliabile distribuirle in piani di servizio app distinti. Questo approccio consente di scalare le app in modo indipendente, poiché vengono eseguite in istanze separate.
Database SQL
Aumentare la scalabilità di un database SQL eseguendo il partizionamento orizzontale del database. Il database viene così partizionato in senso orizzontale. Il partizionamento orizzontale consente di aumentare il numero di istanze per il database mediante strumenti di database elastico. I possibili vantaggi del partizionamento orizzontale includono:
- Maggiore velocità effettiva delle transazioni.
- Esecuzione più rapida delle query su un subset dei dati.
Frontdoor di Azure
Frontdoor può eseguire l'offload SSL e riduce anche il numero totale di connessioni TCP con l'app Web back-end. Ciò migliora la scalabilità perché l'app Web gestisce un volume inferiore di handshake SSL e connessioni TCP. Questi miglioramenti delle prestazioni si applicano anche se si inoltrano le richieste all'app Web come HTTPS, a causa dell'elevato livello di riutilizzo della connessione.
Ricerca di Azure
Il servizio Ricerca di Azure evita di dover eseguire ricerche di dati complesse dall'archivio dati primario e può essere scalato per la gestione del carico. Vedere Ridimensionare i livelli di risorse per i carichi di lavoro di indicizzazione e query in Ricerca di Azure.
Eccellenza operativa
L'eccellenza operativa si riferisce ai processi operativi che distribuiscono un'applicazione e la mantengono in esecuzione nell'ambiente di produzione ed è un'estensione delle linee guida sull'affidabilità del framework ben progettato. Queste linee guida forniscono una panoramica dettagliata della resilienza di progettazione nel framework dell'applicazione per garantire che i carichi di lavoro siano disponibili e possano eseguire il ripristino da errori su qualsiasi scala. Un principio fondamentale di questo approccio consiste nel progettare l'infrastruttura dell'applicazione in modo che sia a disponibilità elevata, in modo ottimale in più aree geografiche, come illustrato in questa progettazione.
Collaboratori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Arvind Boggaram Pandurangsight Setty | Consulente senior
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Passaggi successivi
Approfondimento su Frontdoor di Azure - Metodi di routing del traffico
Creare probe di integrità che segnalano l'integrità complessiva dell'applicazione in base ai modelli di monitoraggio degli endpoint
Abilitare i gruppi di failover automatico di AZURE SQL
Garantire la continuità aziendale e il ripristino di emergenza usando aree abbinate di Azure
Risorse correlate
Un'applicazione multi-area a più livelli è uno scenario simile. Mostra un'applicazione a più livelli in esecuzione in più aree di Azure