Correggere un errore Apache Hive di memoria insufficiente in Azure HDInsight
Informazioni su come risolvere un errore Apache Hive di memoria insufficiente durante l'elaborazione di tabelle di grandi dimensioni configurando le impostazioni di memoria Hive.
Eseguire una query Apache Hive su tabelle di grandi dimensioni
Un cliente ha eseguito una query Hive:
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
Dettagli della query:
- T1 è un alias di una tabella di grandi dimensioni, TABLE1, che include molti tipi di colonna STRING.
- Altre tabelle non sono di grandi dimensioni, ma hanno molte colonne.
- Tutte le tabelle sono unite tra loro, in alcuni casi con più colonne in TABLE1 e altre.
La query Hive ha richiesto 26 minuti in un nodo del cluster HDInsight A3 24. Il cliente ha notato i messaggi di avviso seguenti:
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
Tramite il motore di esecuzione di Apache Tez. La stessa query ha richiesto 15 minuti e quindi ha generato l'errore seguente:
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
L'errore persiste quando si usa una macchina virtuale più grande (ad esempio, D12).
Debug dell'errore di memoria insufficiente
Il supporto Microsoft insieme al team di progettazione ha rilevato che uno dei problemi che provocava l'errore di memoria insufficiente era un problema noto descritto in Apache JIRA:
"Quando hive.auto.convert.join.noconditionaltask = true controlliamo noconditionaltask.size e se la somma delle dimensioni delle tabelle nel join della mappa è minore di noconditionaltask.size il piano genera un join mappa, il problema è che il calcolo non tiene conto del sovraccarico introdotto da un'implementazione HashTable diversa come risultato se la somma delle dimensioni di input è inferiore alla dimensione noconditionaltask di una piccola query di margine raggiungerà OOM".
hive.auto.convert.join.noconditionaltask nel file hive-site.xml file è stato impostato su true:
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
È probabile che il mapping join sia la causa dell'errore di memoria insufficiente dello spazio heap Java. Come illustrato nel post di blog sulle impostazioni della memoria Yarn di Hadoop in HDInsight, quando si usa il motore di esecuzione Tez lo spazio dell'heap effettivamente usato appartiene al contenitore Tez. Vedere l'immagine seguente che descrive la memoria del contenitore Tez.
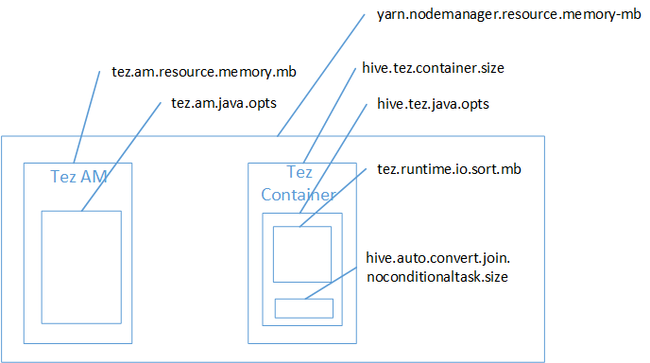
Come suggerisce il post di blog, le due impostazioni di memoria seguenti definiscono la memoria del contenitore per l'heap: hive.tez.container.size e hive.tez.java.opts. Dalla nostra esperienza, l'eccezione di memoria insufficiente non significa che le dimensioni del contenitore sono troppo piccole. Ossia, ad essere ridotte solo le dimensioni dell'heap di Java (hive.tez.java.opts). Pertanto ogni volta che viene visualizzato un errore di memoria insufficiente, è possibile provare ad aumentare hive.tez.java.opts. Se necessario, può essere necessario aumentare hive.tez.container.size. L'impostazione java.opts deve essere circa l'80% di container.size.
Nota
L'impostazione hive.tez.java.opts deve sempre essere inferiore a hive.tez.container.size.
Poiché un computer D12 ha 28 GB di memoria, si è deciso di usare una dimensione del contenitore di 10 GB (10240 MB) e assegnare l'80% a java.opts:
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
Con le nuove impostazioni, la query è stata eseguita in meno di dieci minuti.
Passaggi successivi
Un errore di memoria insufficiente non indica necessariamente che le dimensioni del contenitore sono troppo piccole. Al contrario, è necessario configurare le impostazioni della memoria in modo che le dimensioni dell'heap aumentino e raggiungano almeno l'80% delle dimensioni della memoria del contenitore. Per l'ottimizzazione delle query Hive, vedere Ottimizzare le query Apache Hive per Apache Hadoop in HDInsight.