Case study dell'architettura della soluzione a disponibilità elevata di Azure HDInsight
I meccanismi di replica di Azure HDInsight possono essere integrati in un'architettura di soluzione a disponibilità elevata. In questo articolo viene usato un case study fittizio per Contoso Retail per spiegare i possibili approcci di ripristino di emergenza a disponibilità elevata, considerazioni sul costo e le progettazioni corrispondenti.
Le raccomandazioni per il ripristino di emergenza a disponibilità elevata possono avere molte permutazioni e combinazioni. Queste soluzioni devono essere arrivate dopo aver deliberato i vantaggi e i contro di ogni opzione. Questo articolo illustra solo una possibile soluzione.
Architettura del cliente
L'immagine seguente illustra l'architettura primaria di Contoso Retail. L'architettura è costituita da un carico di lavoro di streaming, un carico di lavoro batch, un livello di gestione, un livello di utilizzo, un livello di archiviazione e un controllo della versione.
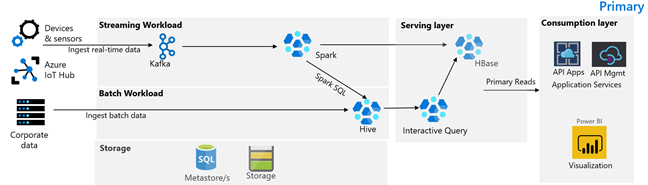
Carico di lavoro di streaming
I dispositivi e i sensori producono dati in HDInsight Kafka, che costituisce il framework di messaggistica. Un consumer HDInsight Spark legge gli argomenti di Kafka. Spark trasforma i messaggi in arrivo e lo scrive in un cluster HDInsight HBase nel livello di gestione.
Carico di lavoro batch
Un cluster Hadoop di HDInsight che esegue Hive e MapReduce inserisce i dati da sistemi transazionali locali. I dati non elaborati trasformati da Hive e MapReduce vengono archiviati in tabelle Hive in una partizione logica del data lake supportato da Azure Data Lake Archiviazione Gen2. I dati archiviati nelle tabelle Hive vengono resi disponibili anche per Spark SQL, che esegue trasformazioni batch prima di archiviare i dati curati in HBase per la gestione.
Livello di servizio
Un cluster HDInsight HBase con Apache Phoenix viene usato per gestire i dati alle applicazioni Web e ai dashboard di visualizzazione. Un cluster HDInsight LLAP viene usato per soddisfare i requisiti interni per la creazione di report.
Livello consumo
Un livello app per le API di Azure e Gestione API back a una pagina Web pubblica. I requisiti di creazione di report interni vengono soddisfatti da Power BI.
Livello di archiviazione
Azure Data Lake Archiviazione Gen2 partizionato logicamente viene usato come data lake aziendale. I metastore HDInsight sono supportati dal database SQL di Azure.
Sistema di controllo della versione
Un sistema di controllo della versione integrato in Azure Pipelines e ospitato all'esterno di Azure.
Requisiti di continuità aziendale dei clienti
È importante determinare la funzionalità aziendale minima necessaria in caso di emergenza.
Requisiti di continuità aziendale di Contoso Retail
- Dobbiamo essere protetti da un errore regionale o da un problema di salute dei servizi regionali.
- I miei clienti non devono mai visualizzare un errore 404. Il contenuto pubblico deve essere sempre servito. (RTO = 0)
- Per la maggior parte dell'anno, è possibile visualizzare contenuti pubblici non aggiornati di 5 ore. (RPO = 5 ore)
- Durante la stagione delle festività, il nostro contenuto pubblico deve essere sempre aggiornato. (RPO = 0)
- I requisiti interni per la creazione di report non sono considerati critici per la continuità aziendale.
- Ottimizzare i costi di continuità aziendale.
Soluzione proposta
L'immagine seguente mostra l'architettura di ripristino di emergenza a disponibilità elevata di Contoso Retail.
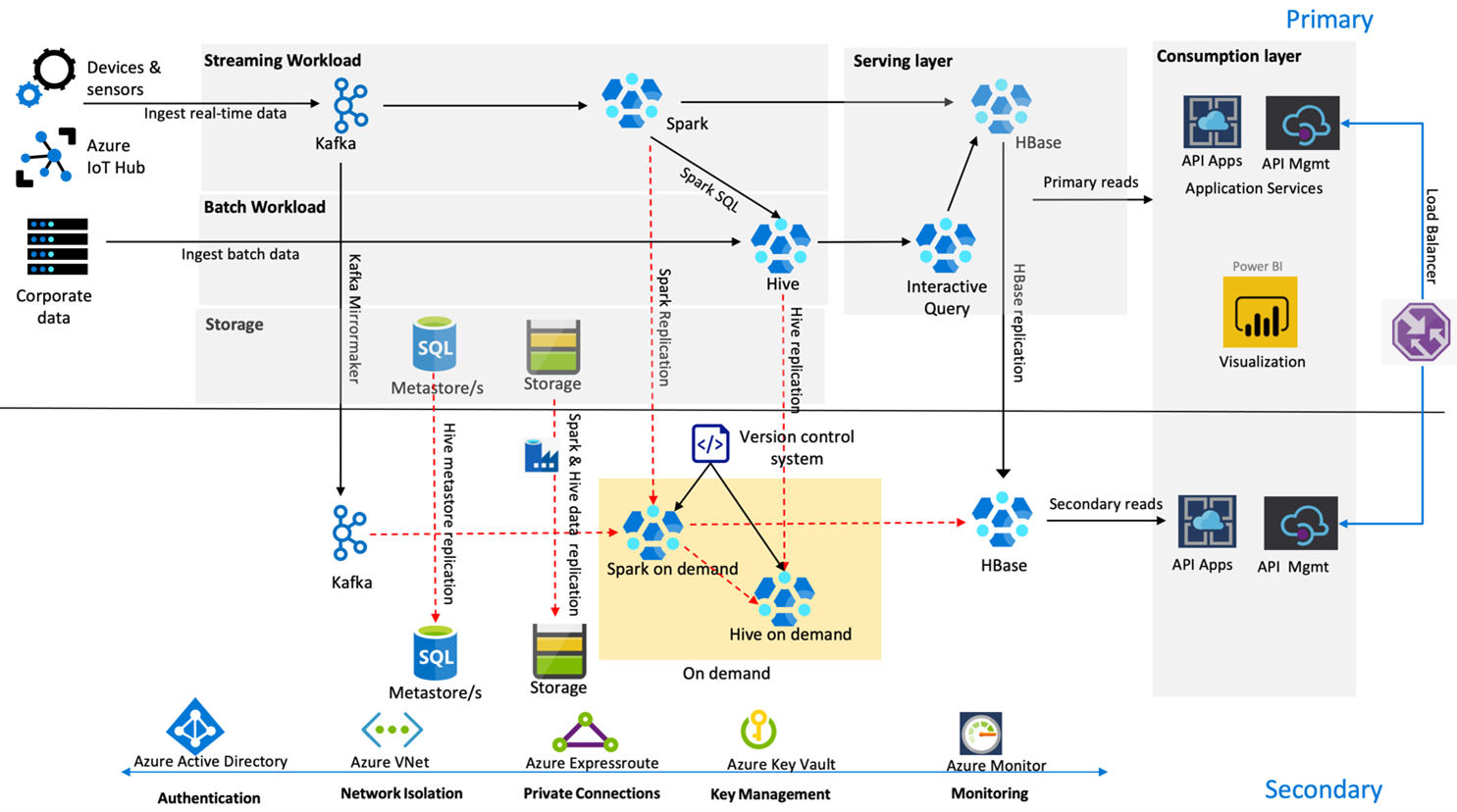
Kafka usa la replica attiva- Passiva per eseguire il mirroring degli argomenti Kafka dall'area primaria all'area secondaria. Un'alternativa alla replica Kafka può essere quella di produrre in Kafka in entrambe le aree.
Hive e Spark usano modelli di replica primaria attiva - secondario su richiesta durante i normali tempi. Il processo di replica Hive viene eseguito periodicamente e accompagna la replica del metastore SQL di Hive e dell'account di archiviazione Hive. L'account di archiviazione Spark viene replicato periodicamente tramite ADF DistCP. La natura temporanea di questi cluster consente di ottimizzare i costi. Le repliche vengono pianificate ogni 4 ore per arrivare a un RPO che rientra nel requisito di cinque ore.
La replica HBase usa il modello Leader - Follower durante i tempi normali per garantire che i dati vengano sempre serviti indipendentemente dall'area e che l'RPO sia molto basso.
Se si verifica un errore a livello di area nell'area primaria, la pagina Web e il contenuto back-end vengono serviti dall'area secondaria per 5 ore con un certo grado di decadimento. Se il dashboard di integrità dei servizi di Azure non indica un ETA di ripristino nella finestra di cinque ore, Contoso Retail creerà il livello di trasformazione Hive e Spark nell'area secondaria e quindi punterà tutte le origini dati upstream all'area secondaria. Rendere scrivibile l'area secondaria causerebbe un processo di failback che comporta la replica nel database primario.
Durante una stagione di punta dello shopping, l'intera pipeline secondaria è sempre attiva e in esecuzione. I produttori Kafka producono in entrambe le aree e la replica HBase vengono modificati da Leader-Follower a Leader-Leader per garantire che il contenuto pubblico sia sempre aggiornato.
Non è necessario progettare alcuna soluzione di failover per la creazione di report interni perché non è fondamentale per la continuità aziendale.
Passaggi successivi
Per altre informazioni sugli elementi descritti in questo articolo, vedere: