Architetture di continuità aziendale di Azure HDInsight
Questo articolo offre alcuni esempi di architetture di continuità aziendale che è possibile prendere in considerazione per Azure HDInsight. La tolleranza per ridurre le funzionalità durante un'emergenza è una decisione aziendale che varia da un'applicazione all'altra. Potrebbe essere accettabile che alcune applicazioni non siano disponibili o siano parzialmente disponibili con funzionalità ridotte o elaborazione ritardata per un periodo. Per altre applicazioni, qualsiasi funzionalità ridotta potrebbe essere inaccettabile.
Nota
Le architetture presentate in questo articolo non sono in alcun modo esaustive. È consigliabile progettare architetture uniche dopo aver determinato in modo obiettivo la continuità aziendale prevista, la complessità operativa e il costo di proprietà.
Apache Hive e Interactive Query
La replica Hive V2 è consigliata per la continuità aziendale nei cluster Hive di HDInsight e Interactive Query. Le sezioni persistenti di un cluster Hive autonomo che devono essere replicate sono il Archiviazione Layer e il metastore Hive. I cluster Hive in uno scenario multiutente con Enterprise Security Package necessitano di Microsoft Entra Domain Services e Ranger Metastore.
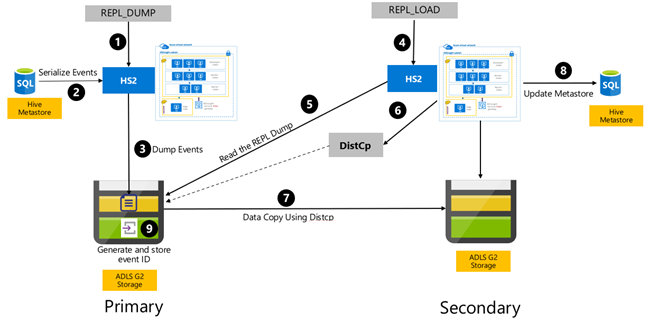
La replica basata su eventi Hive è configurata tra i cluster primari e secondari. Si tratta di due fasi distinte, il bootstrap e le esecuzioni incrementali:
Il bootstrap replica l'intero warehouse Hive, incluse le informazioni del metastore Hive dal database primario al secondario.
Le esecuzioni incrementali vengono automatizzate nel cluster primario e gli eventi generati durante le esecuzioni incrementali vengono riprodotti nel cluster secondario. Il cluster secondario recupera gli eventi generati dal cluster primario, assicurandosi che il cluster secondario sia coerente con gli eventi del cluster primario dopo l'esecuzione della replica.
Il cluster secondario è necessario solo al momento della replica per eseguire la copia distribuita, DistCp, ma l'archiviazione e i metastore devono essere persistenti. È possibile scegliere di attivare un cluster secondario con script su richiesta prima della replica, eseguire lo script di replica su di esso e quindi eliminarlo dopo la corretta replica.
Il cluster secondario è in genere di sola lettura. È possibile eseguire la lettura/scrittura del cluster secondario, ma ciò comporta una maggiore complessità che comporta la replica delle modifiche dal cluster secondario al cluster primario.
RPO e RTO della replica basata su eventi Hive
RPO: la perdita di dati è limitata all'ultimo evento di replica incrementale riuscito da primario a secondario.
RTO: tempo tra l'errore e la ripresa delle transazioni upstream e downstream con il database secondario.
Architetture di Apache Hive e Interactive Query
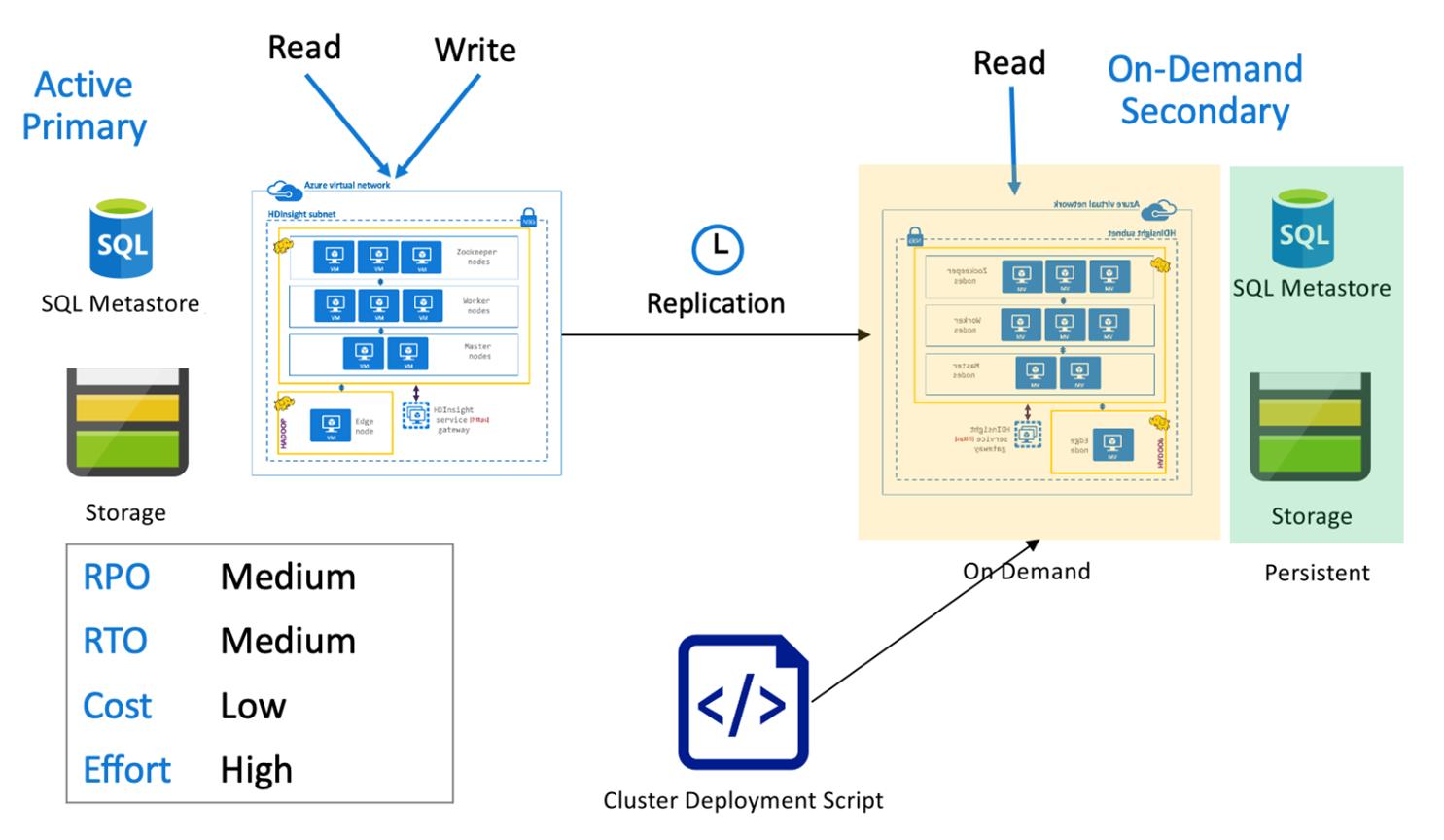
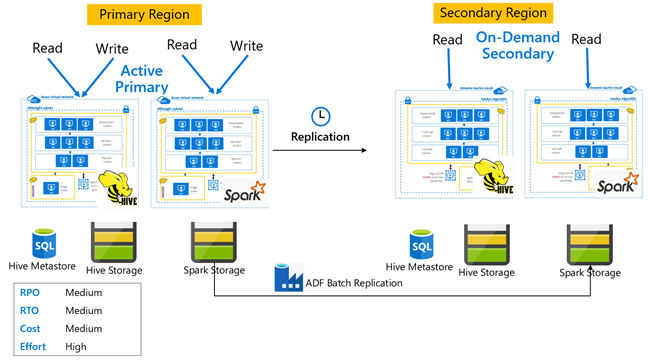
Database primario attivo Hive con secondario su richiesta
In un'architettura primaria attiva con architettura secondaria su richiesta, le applicazioni scrivono nell'area primaria attiva mentre non viene effettuato il provisioning del cluster nell'area secondaria durante le normali operazioni. Metastore SQL e Archiviazione nell'area secondaria sono persistenti, mentre il cluster HDInsight viene sottoposto a script e distribuito solo su richiesta prima dell'esecuzione della replica Hive pianificata.
Hive active primary with standby secondary (Primario attivo Hive con standby secondario)
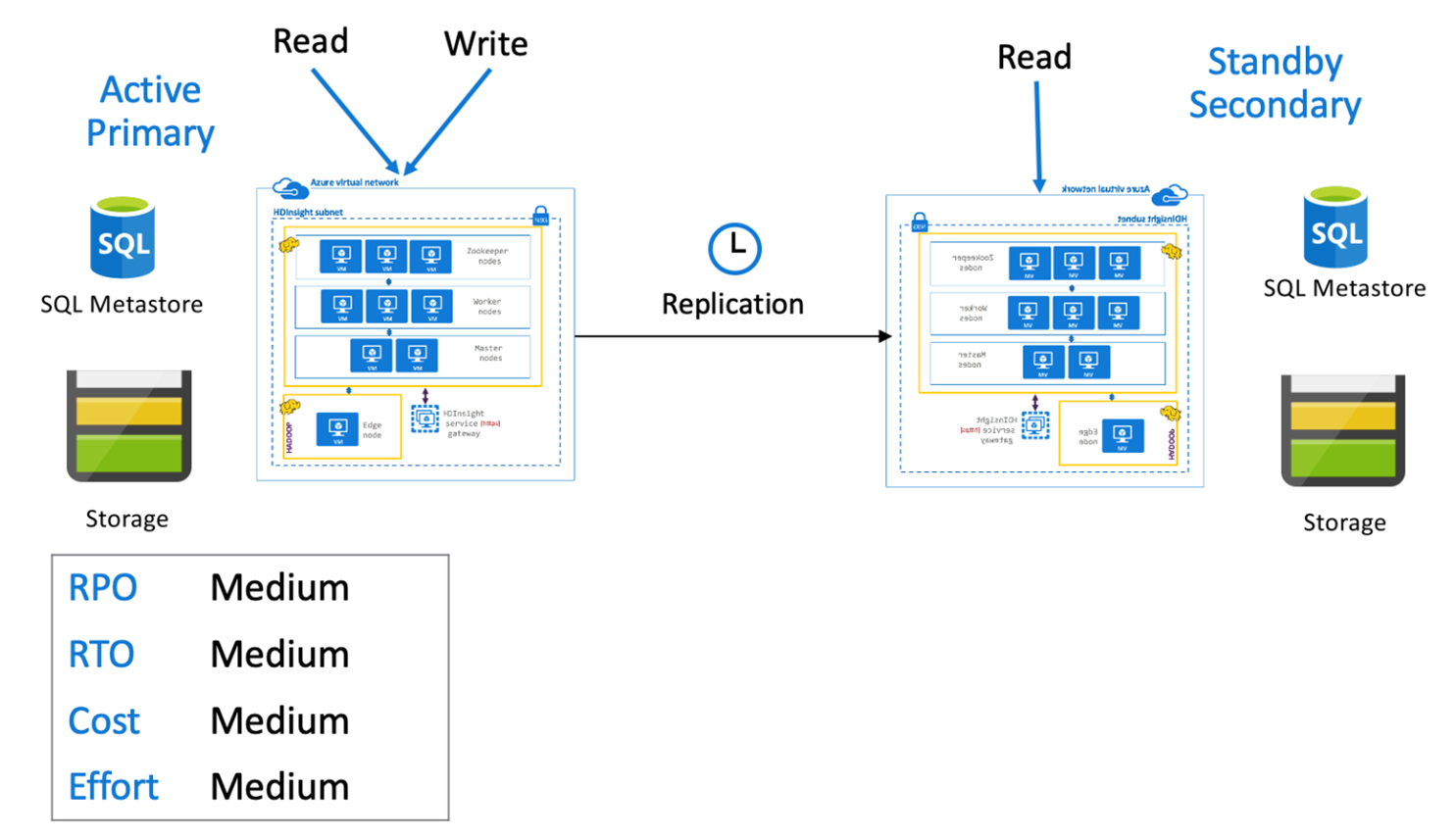
In un database primario attivo con secondario standby, le applicazioni scrivono nell'area primaria attiva mentre un cluster secondario in modalità di sola lettura viene eseguito in modalità di sola lettura durante le normali operazioni. Durante le normali operazioni, è possibile scegliere di eseguire l'offload delle operazioni di lettura specifiche dell'area nel database secondario.
Per altre informazioni sulla replica Hive ed esempi di codice, vedere Replica Apache Hive nei cluster Azure HDInsight
Apache Spark
I carichi di lavoro Spark possono includere o meno un componente Hive. Per consentire ai carichi di lavoro Spark SQL di leggere e scrivere dati da Hive, i cluster HDInsight Spark condividono metastore hive personalizzati da cluster di query Hive/Interactive nella stessa area. In questi scenari, la replica tra aree dei carichi di lavoro Spark deve anche accompagnare la replica dei metastore Hive e dell'archiviazione. Gli scenari di failover in questa sezione si applicano a entrambi:
- Spark SQL nelle tabelle ACID usando l'installazione di Hive Warehouse Connessione or(HWC) usando un cluster HDInsight Interactive Query.
- Carico di lavoro Spark SQL in tabelle non ACID che usano un cluster Hadoop di HDInsight.
Per gli scenari in cui Spark funziona in modalità autonoma, è necessario replicare regolarmente i dati e i file JAR Spark archiviati (per i processi Livy) dall'area primaria all'area DistCPsecondaria usando Azure Data Factory.
È consigliabile usare sistemi di controllo della versione per archiviare notebook e librerie Spark in cui possono essere facilmente distribuiti in cluster primari o secondari. Assicurarsi che le soluzioni basate su notebook e non basate su notebook siano preparate per caricare i montaggi dati corretti nell'area di lavoro primaria o secondaria.
Se sono presenti librerie specifiche del cliente che esulano da ciò che HDInsight fornisce in modo nativo, devono essere rilevate e caricate periodicamente nel cluster secondario di standby.
RPO e RTO della replica apache Spark
RPO: la perdita di dati è limitata all'ultima replica incrementale riuscita (Spark e Hive) da primaria a secondaria.
RTO: tempo tra l'errore e la ripresa delle transazioni upstream e downstream con il database secondario.
Architetture di Apache Spark
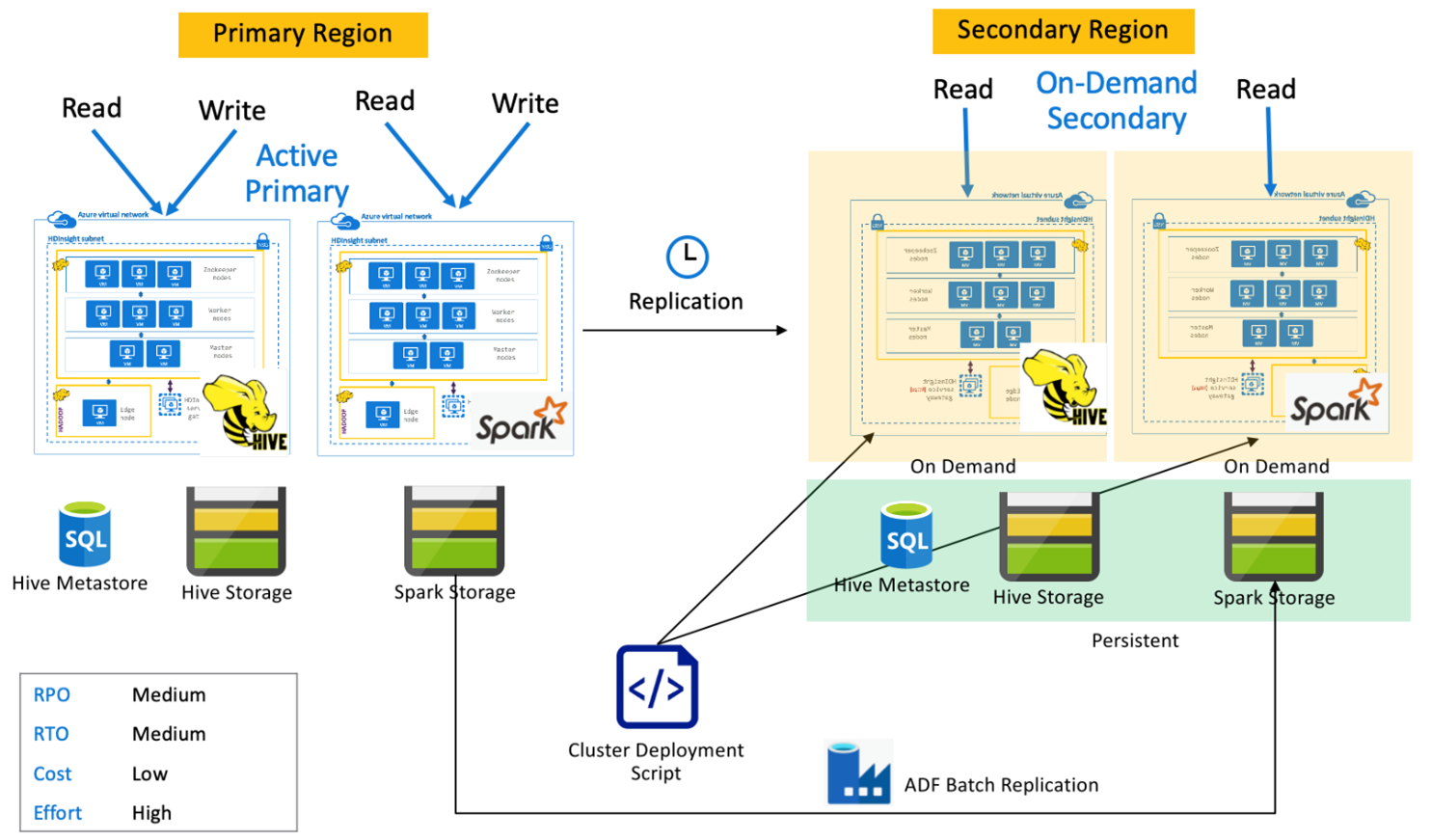
Spark active primary with on demand secondary (Spark active primary with on demand secondary) (Spark active primary with on demand secondary )Spark
Le applicazioni leggono e scrivono in cluster Spark e Hive nell'area primaria, mentre non viene effettuato il provisioning di cluster nell'area secondaria durante le normali operazioni. I metastore SQL, i Archiviazione Hive e i Archiviazione Spark sono persistenti nell'area secondaria. I cluster Spark e Hive vengono inseriti in script e distribuiti su richiesta. La replica Hive viene usata per replicare i metastore Hive Archiviazione e Hive, mentre Azure Data Factory può essere usato per copiare l'archiviazione DistCP Spark autonoma. I cluster Hive devono essere distribuiti prima dell'esecuzione di ogni replica Hive a causa del calcolo delle dipendenze DistCp .
Spark active primary with standby secondary (Spark active primary with standby secondary)
Le applicazioni leggono e scrivono in cluster Spark e Hive nell'area primaria mentre i cluster Hive e Spark in modalità di sola lettura vengono eseguiti in un'area secondaria durante le normali operazioni. Durante le normali operazioni, è possibile scegliere di eseguire l'offload di operazioni di lettura Hive e Spark specifiche nell'area secondaria.
Apache HBase
L'esportazione di HBase e la replica HBase sono modi comuni per abilitare la continuità aziendale tra cluster HDInsight HBase.
HBase Export è un processo di replica batch che usa l'utilità di esportazione HBase per esportare le tabelle dal cluster HBase primario all'archiviazione di Azure Data Lake Archiviazione Gen 2 sottostante. È quindi possibile accedere ai dati esportati dal cluster HBase secondario e importati in tabelle che devono essere preesistenti nel database secondario. Sebbene L'esportazione di HBase offra granularità a livello di tabella, in situazioni di aggiornamento incrementale, il motore di automazione di esportazione controlla l'intervallo di righe incrementali da includere in ogni esecuzione. Per altre informazioni, vedere Backup e replica di HBase di HDInsight.
La replica HBase usa la replica quasi in tempo reale tra cluster HBase in modo completamente automatizzato. La replica viene eseguita a livello di tabella. Tutte le tabelle o tabelle specifiche possono essere destinate alla replica. La replica HBase è infine coerente, ovvero le modifiche recenti a una tabella nell'area primaria potrebbero non essere immediatamente disponibili per tutti i database secondari. Le repliche secondarie alla fine diventano coerenti con il database primario. La replica HBase può essere configurata tra due o più cluster HDInsight HBase se:
- Primario e secondario si trovano nella stessa rete virtuale.
- Le reti virtuali primarie e secondarie si trovano in reti virtuali con peering diverse nella stessa area.
- Le reti virtuali primarie e secondarie si trovano in reti virtuali con peering diverse in aree diverse.
Per altre informazioni, vedere Configurare la replica del cluster Apache HBase nelle reti virtuali di Azure.
Esistono alcuni altri modi per eseguire backup di cluster HBase, ad esempio la copia della cartella hbase, la copia di tabelle e snapshot.
HBase RPO & RTO
Esportazione HBase
- RPO: la perdita di dati è limitata all'ultima importazione incrementale batch riuscita dal database secondario dal database primario.
- RTO: tempo tra l'errore del database primario e la ripresa delle operazioni di I/O sul database secondario.
Replica HBase
- RPO: la perdita di dati è limitata all'ultima spedizione WalEdit ricevuta nel database secondario.
- RTO: tempo tra l'errore del database primario e la ripresa delle operazioni di I/O sul database secondario.
Architetture HBase
La replica HBase può essere configurata in tre modalità: Leader-Follower, Leader-Leader e Ciclico.
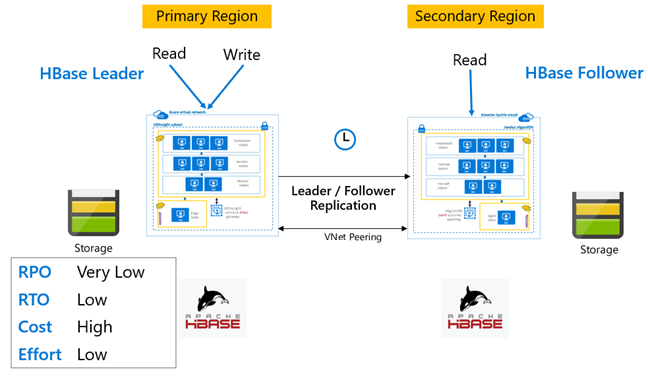
Replica HBase: Leader - Modello follower
In questa configurazione tra aree, la replica è unidirezionale dall'area primaria all'area secondaria. È possibile identificare tutte le tabelle o tabelle specifiche nel database primario per la replica unidirezionale. Durante le normali operazioni, il cluster secondario può essere usato per gestire le richieste di lettura nella propria area.
Il cluster secondario opera come un normale cluster HBase che può ospitare le proprie tabelle e può gestire letture e scritture dalle applicazioni a livello di area. Tuttavia, le scritture nelle tabelle o nelle tabelle replicate native in secondarie non vengono replicate nuovamente nel database primario.
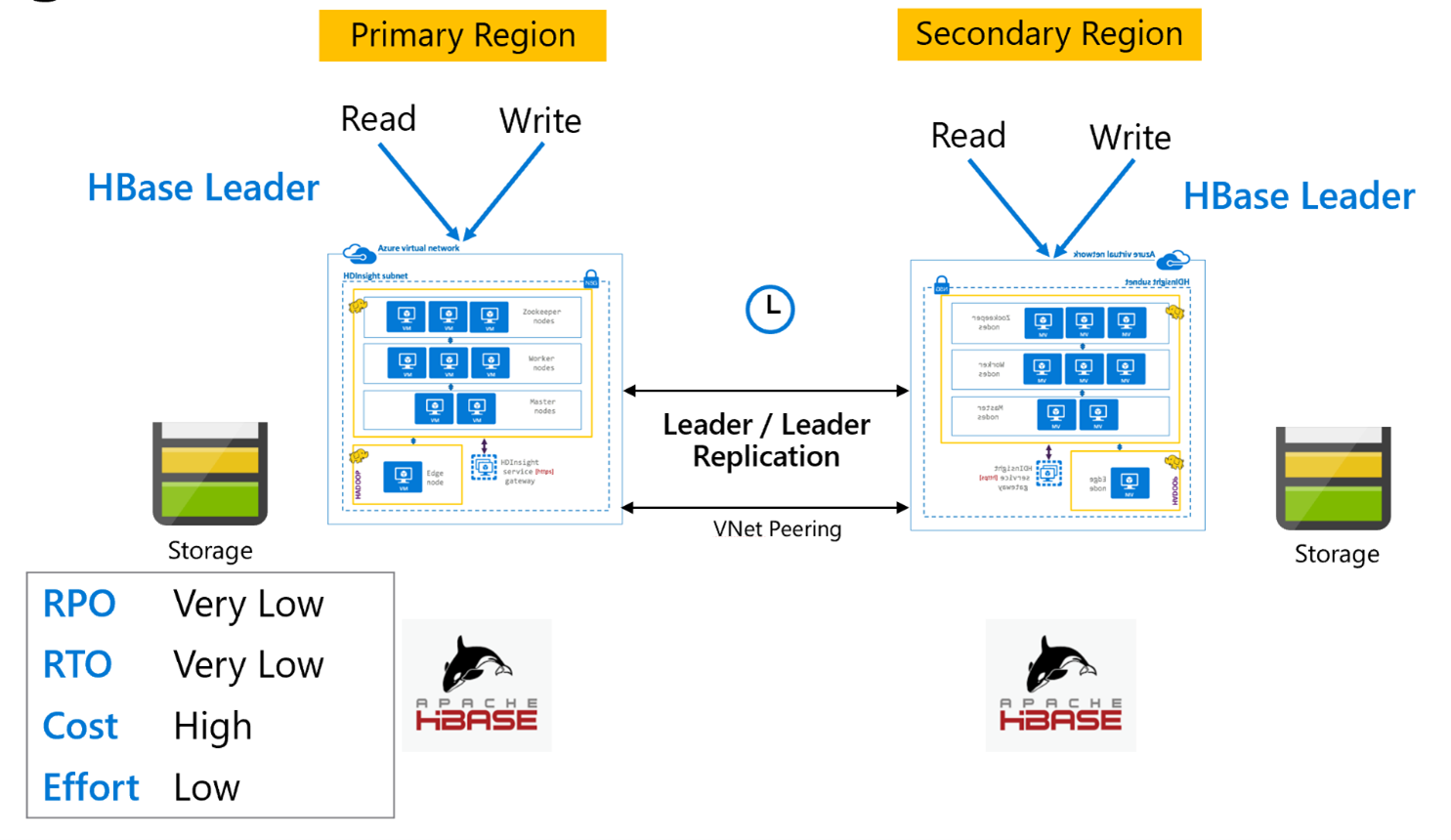
Replica HBase: Leader - Modello leader
Questa configurazione tra aree è molto simile alla configurazione unidirezionale, ad eccezione del fatto che la replica avviene in modo bidirezionale tra l'area primaria e l'area secondaria. Le applicazioni possono usare entrambi i cluster in modalità di lettura/scrittura e gli aggiornamenti sono scambi in modo asincrono tra di essi.
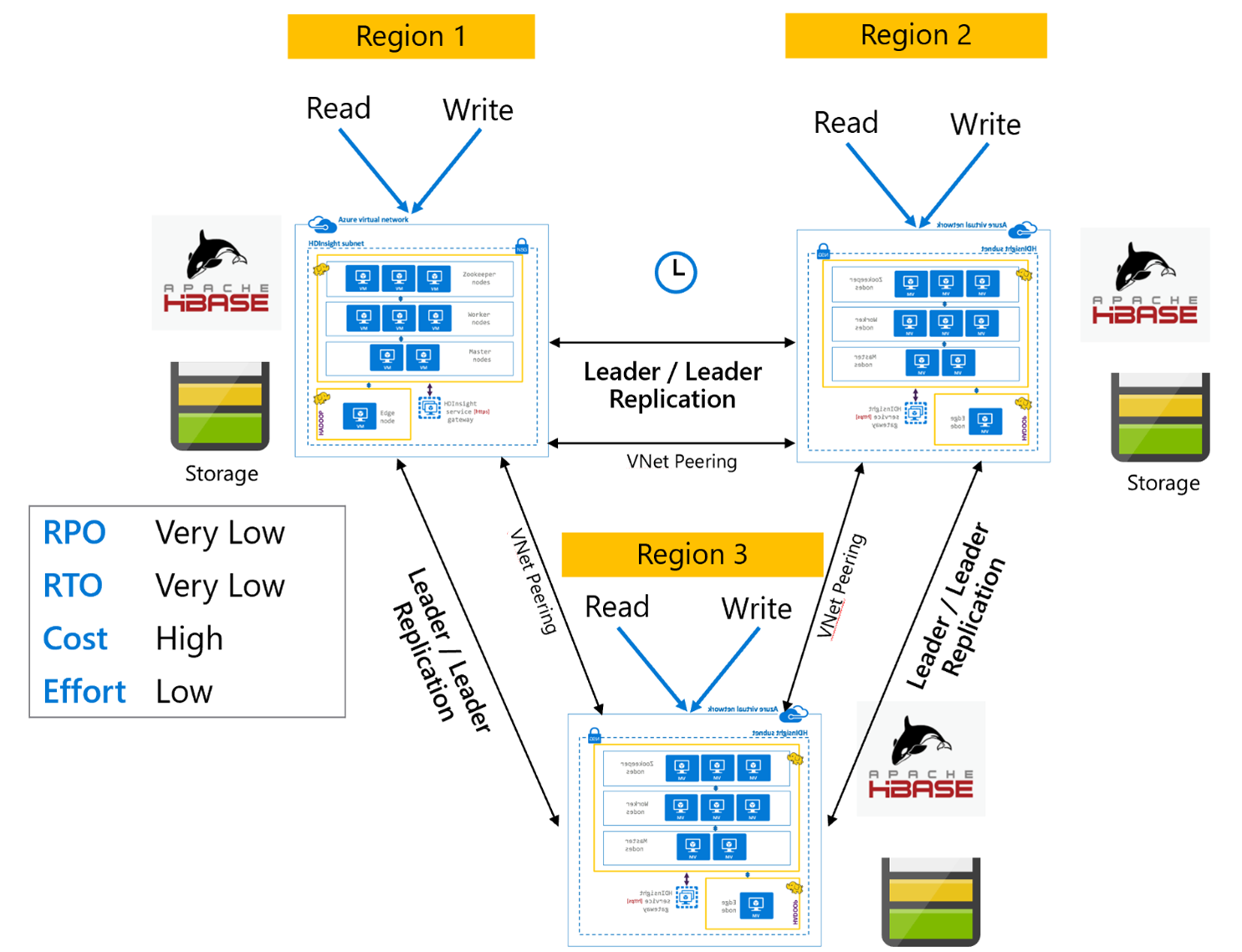
Replica HBase: multi-area o ciclico
Il modello di replica multiarea/ciclico è un'estensione della replica HBase e può essere usato per creare un'architettura HBase con ridondanza globale con più applicazioni che leggono e scrivono in cluster HBase specifici dell'area. I cluster possono essere configurati in varie combinazioni di Leader/Leader o Leader/Follower a seconda dei requisiti aziendali.
Apache Kafka
Per abilitare la disponibilità tra aree HDInsight 4.0 supporta Kafka MirrorMaker, che può essere usato per gestire una replica secondaria del cluster Kafka primario in un'area diversa. MirrorMaker funge da coppia consumer-producer di alto livello, utilizza da un argomento specifico nel cluster primario e produce in un argomento con lo stesso nome nel database secondario. La replica tra cluster per il ripristino di emergenza a disponibilità elevata tramite MirrorMaker presuppone che i producer e i consumer debbano eseguire il failover nel cluster di replica. Per altre informazioni, vedere Usare MirrorMaker per replicare gli argomenti di Apache Kafka con Kafka in HDInsight
A seconda della durata dell'argomento all'avvio della replica, la replica degli argomenti di MirrorMaker può comportare offset diversi tra gli argomenti di origine e di replica. I cluster Kafka di HDInsight supportano anche la replica di partizioni degli argomenti, una funzionalità a disponibilità elevata a livello di singolo cluster.
Architetture Apache Kafka
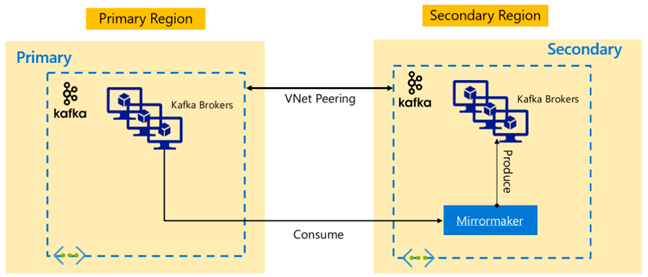
Replica Kafka: Attivo - Passivo
L'installazione attiva-passiva abilita il mirroring unidirezionale asincrono da Attivo a Passivo. I produttori e i consumer devono essere consapevoli dell'esistenza di un cluster attivo e passivo e devono essere pronti per eseguire il failover al passivo nel caso in cui l'attività non riesca. Di seguito sono riportati alcuni vantaggi e svantaggi della configurazione attivo-passivo.
Vantaggi:
- La latenza di rete tra cluster non influisce sulle prestazioni del cluster attivo.
- Semplicità della replica unidirezionale.
Svantaggi:
- Il cluster Passivo può rimanere sottoutilizzato.
- Progettare complessità nell'incorporare la consapevolezza del failover nei produttori di applicazioni e nei consumer.
- Possibile perdita di dati durante l'errore del cluster attivo.
- Coerenza finale tra argomenti tra cluster attivi e passivi.
- I failback nel database primario possono causare incoerenze nei messaggi negli argomenti.
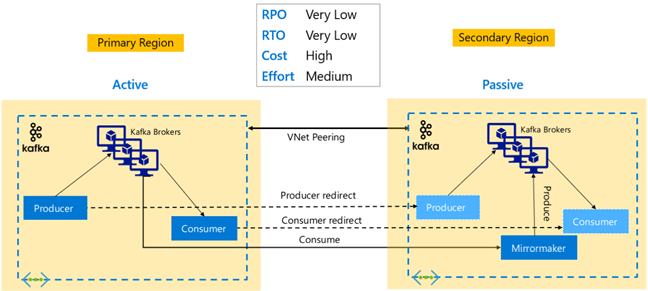
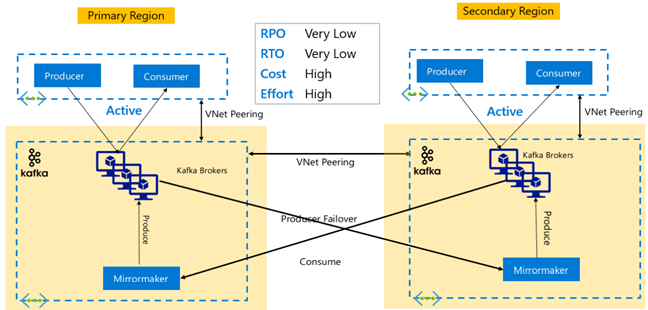
Replica Kafka: Attiva - Attiva
La configurazione attiva-attiva prevede due cluster HDInsight Kafka con peering a livello di area con due cluster HDInsight con replica asincrona bidirezionale con MirrorMaker. In questa progettazione, i messaggi utilizzati dai consumer nel database primario vengono resi disponibili anche ai consumer in secondario e viceversa. Di seguito sono riportati alcuni vantaggi e svantaggi della configurazione di Active-Active.
Vantaggi:
- A causa dello stato duplicato, i failover e i failback sono più facili da eseguire.
Svantaggi:
- La configurazione, la gestione e il monitoraggio sono più complessi rispetto a Active-Passive.
- Il problema della replica circolare deve essere risolto.
- La replica bidirezionale comporta costi di uscita dei dati a livello di area più elevati.
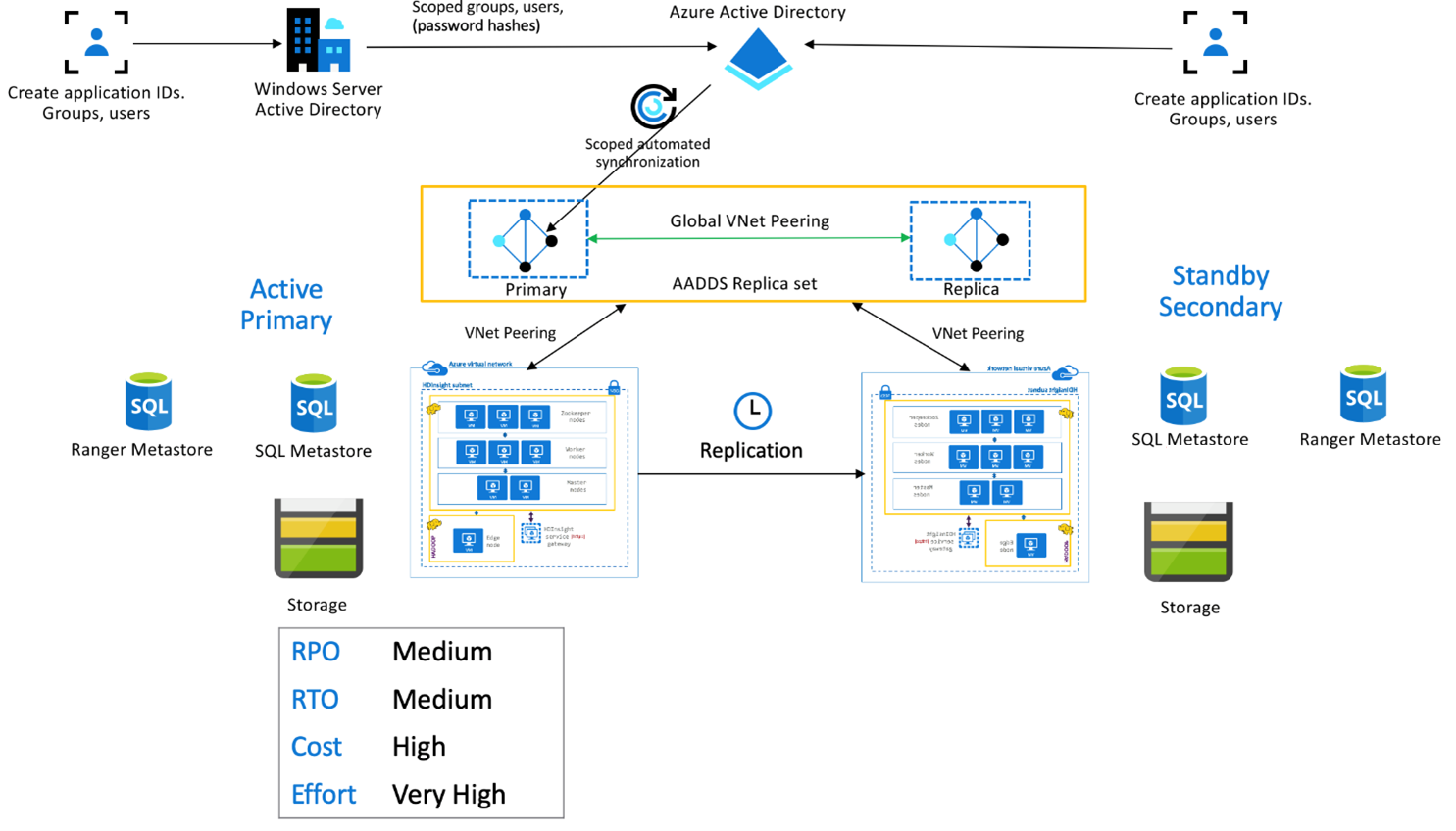
Pacchetto di sicurezza di HDInsight Enterprise
Questa configurazione viene usata per abilitare le funzionalità multiutente sia nel database primario che in quello secondario, nonché nei set di repliche di Microsoft Entra Domain Services per garantire che gli utenti possano eseguire l'autenticazione in entrambi i cluster. Durante le normali operazioni, i criteri ranger devono essere configurati nel database secondario per garantire che gli utenti siano limitati alle operazioni di lettura. L'architettura seguente spiega come potrebbe essere visualizzata una configurazione hive attiva hive attiva - secondaria standby.
Replica metastore ranger:
Ranger Metastore viene usato per archiviare e gestire in modo permanente i criteri ranger per controllare l'autorizzazione dei dati. È consigliabile mantenere criteri ranger indipendenti in primario e secondario e mantenere il database secondario come replica di lettura.
Se il requisito consiste nel mantenere sincronizzati i criteri ranger tra primario e secondario, usare Ranger Importazione/Esportazione per eseguire periodicamente il backup e l'importazione dei criteri ranger da primario a secondario.
La replica dei criteri Ranger tra primario e secondario può causare l'abilitazione della scrittura da parte del database secondario, che può portare a scritture accidentali sul database secondario che causano incoerenze dei dati.
Passaggi successivi
Per altre informazioni sugli elementi descritti in questo articolo, vedere: