Panoramica di Archiviazione di Azure in HDInsight
Archiviazione di Azure è una soluzione di archiviazione affidabile di utilizzo generico che si integra perfettamente con HDInsight. HDInsight può usare un contenitore BLOB in Archiviazione di Azure come file system predefinito per il cluster. Grazie a un'interfaccia HDFS, tutti i componenti disponibili in HDInsight possono agire direttamente su dati strutturati o non strutturati archiviati come BLOB.
È consigliabile usare contenitori di archiviazione separati per l'archiviazione cluster predefinita e i dati aziendali. La separazione consiste nell'isolare i log di HDInsight e i file temporanei dai propri dati aziendali. È anche consigliabile eliminare il contenitore BLOB predefinito, che contiene i log dell'applicazione e del sistema, dopo ogni uso per ridurre i costi di archiviazione. Assicurarsi di recuperare i log prima di eliminare il contenitore.
Se si sceglie di proteggere l'account di archiviazione con le restrizioni firewall e reti virtuali nelle reti selezionate, assicurarsi di abilitare l'eccezione Consenti servizi Microsoft attendibile.... L'eccezione è in modo che HDInsight possa accedere all'account di archiviazione.
Architettura di archiviazione di HDInsight
Nel diagramma seguente viene sintetizzata l'architettura HDInsight di Archiviazione di Azure:
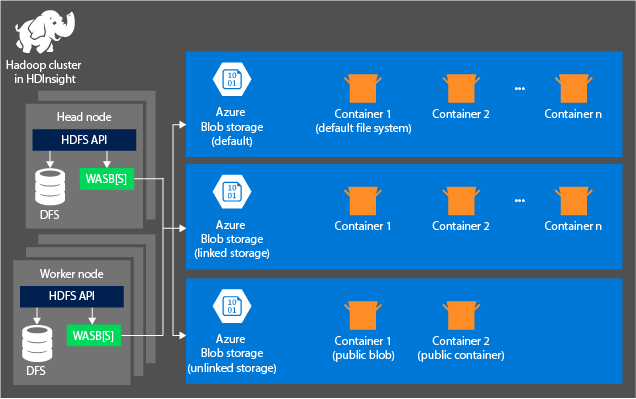
HDInsight offre accesso al file system distribuito collegato localmente ai nodi di calcolo. Il file system è accessibile tramite l'URI completo, ad esempio:
hdfs://<namenodehost>/<path>
Tramite HDInsight è anche possibile accedere ai dati in Archiviazione di Azure. La sintassi è la seguente:
wasb://<containername>@<accountname>.blob.core.windows.net/<path>
Per gli account con uno spazio dei nomi gerarchico (Azure Data Lake Archiviazione Gen2), la sintassi è la seguente:
abfs://<containername>@<accountname>.dfs.core.windows.net/<file.path>/
Tenere conto delle considerazioni seguenti quando si usa un account di Archiviazione di Azure con cluster HDInsight:
Contenitori negli account di archiviazione connessi a un cluster: poiché il nome e la chiave dell'account sono associati al cluster durante il processo di archiviazione, si disporrà di un accesso completo ai BLOB presenti in tali contenitori.
Contenitori pubblici o BLOB pubblici negli account di archiviazione che non sono connessi a un cluster: si dispone dell'autorizzazione di sola lettura per i BLOB nei contenitori.
Nota
Un contenitore pubblico consente di ottenere un elenco di tutti i BLOB in esso disponibili, nonché i metadati del contenitore stesso. È possibile accedere a un BLOB pubblico solo se ne conosce l'URL esatto. Per altre informazioni, vedere Gestire l'accesso in lettura anonimo a contenitori e BLOB.
Contenitori privati negli account di archiviazione che non sono connessi a un cluster: non è possibile accedere ai BLOB nei contenitori a meno che non si definiscano l'account di archiviazione quando si inviano i processi WebHCat.
Gli account di archiviazione definiti durante il processo di creazione, con le rispettive chiavi, sono archiviati in %HADOOP_HOME%/conf/core-site.xml nei nodi del cluster. Per impostazione predefinita, HDInsight usa gli account di archiviazione definiti nel file core-site.xml. È possibile modificare questa impostazione usando Apache Ambari. Per altre informazioni sulle impostazioni dell'account di archiviazione che possono essere modificate o inserite nel file di core-site.xml, vedere gli articoli seguenti:
- Supporto di Hadoop per Azure: Archiviazione BLOB di Azure
- Supporto di Azure Hadoop: ABFS - Azure Data Lake Archiviazione Gen2
Più processi WebHCat, tra cui Apache Hive. E MapReduce, apache Hadoop streaming e Apache Pig, contengono una descrizione degli account di archiviazione e dei metadati. Questo aspetto è attualmente vero per Pig con account di archiviazione, ma non per i metadati. Per altre informazioni, vedere Uso di un cluster HDInsight con account di archiviazione e metastore alternativi.
I BLOB possono essere usati per i dati strutturati e non strutturati. I contenitori BLOB archiviano i dati come coppie chiave/valore e non dispongono di una gerarchia di directory. Il nome della chiave tuttavia può includere una barra (/) per far sembrare che un file sia archiviato in una struttura di directory. Ad esempio, la chiave di un BLOB può essere input/log1.txt. Non esiste una directory input, ma a causa della barra nel nome, la chiave è simile a un percorso file.
Vantaggi di Archiviazione di Azure
I cluster di elaborazione e le risorse di archiviazione senza percorso condiviso hanno costi di prestazioni impliciti. Questi costi vengono ridotti creando i cluster di elaborazione in prossimità delle risorse di account di archiviazione all'interno dell'area di Azure. In quest'area i nodi di calcolo possono accedere in modo efficiente ai dati attraverso la rete ad alta velocità all'interno di Archiviazione di Azure.
Se si archiviano i dati in Archiviazione di Azure anziché in HDFS, si ottengono diversi vantaggi:
Riuso e condivisione dei dati: i dati in HDFS sono situati all'interno del cluster di calcolo. Solo le applicazioni che hanno accesso al cluster di calcolo, quindi, possono usare i dati tramite le API HDFS. È possibile accedere ai dati in Archiviazione di Azure invece tramite le API HDFS o tramite le API REST dell'archiviazione BLOB. Con questa soluzione, è possibile usare una più ampia gamma di strumenti e applicazioni, compresi altri cluster HDInsight, per produrre e usare i dati.
Archiviazione dei dati: quando i dati vengono archiviati in Archiviazione di Azure, i cluster HDInsight usati per il calcolo possono essere eliminati in modo sicuro senza perdere i dati utente.
Costo di archiviazione dei dati: l'archiviazione dei dati in DFS a lungo termine è più costosa rispetto all'archiviazione dei dati in Archiviazione di Azure. Poiché il costo di un cluster di calcolo è superiore al costo di Archiviazione di Azure. Poiché inoltre non è necessario ricaricare i dati ogni volta che si genera un cluster di elaborazione, si risparmiano anche i costi di caricamento dei dati.
Scalabilità orizzontale elastica: anche se HDFS offre scalabilità orizzontale del file system, la scala è determinata dal numero di nodi di cui si effettua la creazione per il cluster. La modifica della scalabilità può essere più complessa rispetto alle funzionalità di scalabilità elastica che si ottengono automaticamente in Archiviazione di Azure.
Replica geografica: i Archiviazione di Azure possono essere replicati geograficamente. Sebbene la replica geografica offra ripristino geografico e ridondanza dei dati, un failover nella posizione sottoposta a replica geografica incide negativamente sulle prestazioni e può comportare costi aggiuntivi. Scegliere pertanto la replica geografica con cautela e solo se il valore dei dati giustifica i costi aggiuntivi.
Alcuni pacchetti e processi MapReduce possono creare risultati intermedi che non si vuole archiviare in Archiviazione di Azure. In questo caso, è possibile scegliere di archiviare i dati nel file system HDFS locale. HDInsight usa DFS per molti di questi risultati intermedi nei processi Hive e in altri processi.
Nota
La maggior parte dei comandi HDFS, ad esempio ls, copyFromLocal e mkdir, funziona come previsto in Archiviazione di Azure. Solo i comandi specifici dell'implementazione HDFS nativa (denominata DFS), ad esempio fschk e dfsadmin, hanno un comportamento diverso in Archiviazione di Azure.