Configurare le impostazioni di Apache Spark
Un cluster HDInsight Spark include un'installazione della libreria Apache Spark. Ogni cluster HDInsight include parametri di configurazione predefiniti per tutti i servizi installati, incluso Spark. Un aspetto chiave della gestione di un cluster Apache Hadoop di HDInsight è il monitoraggio del carico di lavoro, inclusi i processi Spark. Per eseguire al meglio i processi Spark, prendere in considerazione la configurazione del cluster fisico quando si determina la configurazione logica del cluster.
Il cluster HDInsight Apache Spark predefinito include i nodi seguenti: tre nodi Apache ZooKeeper, due nodi head e uno o più nodi del ruolo di lavoro:
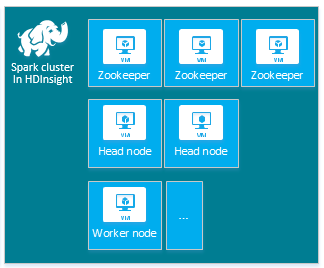
Il numero di macchine virtuali e le dimensioni delle macchine virtuali per i nodi nel cluster HDInsight può influire sulla configurazione di Spark. I valori di configurazione di HDInsight non predefiniti richiedono spesso valori di configurazione di Spark non predefiniti. Quando si crea un cluster HDInsight Spark, vengono visualizzate le dimensioni delle macchine virtuali suggerite per ognuno dei componenti. Attualmente le dimensioni delle macchine virtuali Linux ottimizzate per la memoria per Azure sono D12 v2 o maggiori.
Versioni di Apache Spark
Usare la versione di Spark più appropriata per il cluster. Il servizio HDInsight include diverse versioni di Spark e di HDInsight. Ogni versione di Spark include un set di impostazioni del cluster predefinite.
Quando si crea un nuovo cluster, è possibile scegliere tra più versioni di Spark. Per visualizzare l'elenco completo, Componenti e versioni di HDInsight.
Nota
La versione predefinita di Apache Spark nel servizio HDInsight può cambiare senza preavviso. In caso di dipendenza dalla versione, è consigliabile indicare la versione specifica quando si creano i cluster tramite .NET SDK, Azure PowerShell e l'interfaccia della riga di comando classica di Azure.
Apache Spark ha tre posizioni per le configurazioni di sistema:
- Le proprietà di Spark controllano la maggior parte dei parametri dell'applicazione e possono essere impostate usando un oggetto
SparkConfo tramite le proprietà di sistema Java. - Le variabili di ambiente possono essere usate per definire le impostazioni per computer, ad esempio l'indirizzo IP, tramite lo script
conf/spark-env.shin ogni nodo. - La registrazione può essere configurata tramite
log4j.properties.
Quando si seleziona una particolare versione di Spark, il cluster include le impostazioni di configurazione predefinite. È possibile modificare i valori di configurazione predefiniti di Spark usando un file di configurazione di Spark personalizzato. Di seguito è illustrato un esempio.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
L'esempio precedente esegue l'override di alcuni valori predefiniti per cinque parametri di configurazione di Spark. Questi valori sono il codec di compressione, apache Hadoop MapReduce split minimum size e le dimensioni dei blocchi parquet. Inoltre, la partizione SPARK SQL e le dimensioni dei file aperte sono valori predefiniti. Queste modifiche di configurazione vengono scelte perché i dati e i processi associati (in questo esempio, i dati genomici) hanno caratteristiche specifiche. Queste caratteristiche miglioreranno usando queste impostazioni di configurazione personalizzate.
Visualizzare le impostazioni di configurazione del cluster
Verificare le impostazioni di configurazione correnti del cluster HDInsight prima di eseguire l'ottimizzazione delle prestazioni nel cluster. Avviare il dashboard di HDInsight dal portale di Azure facendo clic sul collegamento Dashboard nel riquadro del cluster Spark. Accedere con il nome utente e la password dell'amministratore del cluster.
Viene visualizzata l'interfaccia utente Web di Apache Ambari, con un dashboard delle metriche di utilizzo delle risorse del cluster chiave. Il dashboard di Ambari mostra la configurazione di Apache Spark e altri servizi installati. Il dashboard include una scheda Cronologia configurazione, in cui è possibile visualizzare le informazioni per i servizi installati, incluso Spark.
Per visualizzare i valori di configurazione per Apache Spark, selezionare Config History (Cronologia configurazione) e quindi selezionare Spark2. Selezionare la scheda Configs (Configurazioni) e quindi fare clic sul collegamento Spark (o Spark2, a seconda della versione) nell'elenco di servizi. Verrà visualizzato un elenco di valori di configurazione per il cluster:
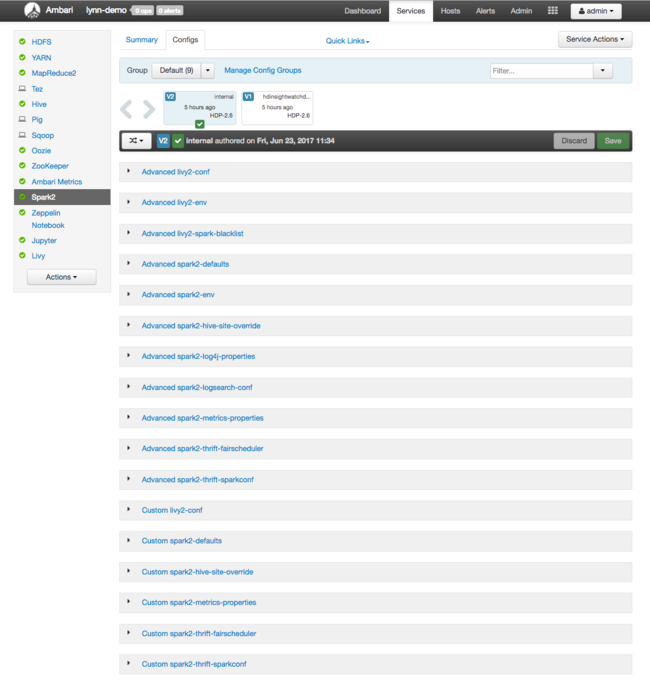
Per visualizzare e modificare i singoli valori di configurazione di Spark, selezionare qualsiasi collegamento con "spark" nel titolo. Le configurazioni per Spark includono sia i valori di configurazione personalizzati che quelli avanzati nelle categorie seguenti:
- Custom Spark2-defaults (Impostazioni predefinite Spark2 personalizzate)
- Custom Spark2-metrics-properties (Proprietà metriche Spark2 personalizzate)
- Advanced Spark2-defaults (Impostazioni predefinite Spark2 avanzate)
- Advanced Spark2-env (Impostazioni ambiente Spark2 avanzate)
- Advanced spark2-hive-site-override (Impostazioni override sito hive Spark2 avanzate)
Se si crea un set non predefinito di valori di configurazione, la cronologia degli aggiornamenti è visibile. Questa cronologia di configurazione può essere utile per capire quale configurazione non predefinita offre prestazioni ottimali.
Nota
Per visualizzare, ma senza modificare, le impostazioni di configurazione del cluster Spark comuni, selezionare la scheda Environment (Ambiente) al livello superiore dell'interfaccia utente del processo Spark.
Configurazione degli executor Spark
Il diagramma seguente mostra gli oggetti Spark principali: il programma driver e il contesto Spark associato, oltre che lo strumento di gestione di cluster e i relativi n nodi del ruolo di lavoro. Ogni nodo del ruolo di lavoro include un executor, una cache e n istanze di attività.
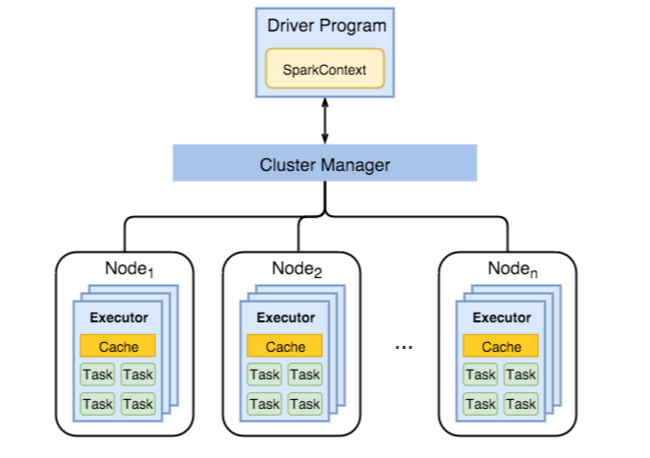
I processi Spark usano risorse del ruolo di lavoro, in particolare la memoria, quindi è prassi comune modificare i valori di configurazione di Spark per gli executor del nodo del ruolo di lavoro.
I tre parametri principali che vengono spesso modificati per ottimizzare le configurazioni di Spark per migliorare i requisiti dell'applicazione sono spark.executor.instances, spark.executor.cores e spark.executor.memory. Un Executor è un processo avviato per un'applicazione Spark. Viene eseguito nel nodo del ruolo di lavoro ed è responsabile delle attività per l'applicazione. Il numero di nodi di lavoro e dimensioni del nodo di lavoro determina il numero di executor e le dimensioni dell'executor. Questi valori vengono archiviati nei spark-defaults.conf nodi head del cluster. È possibile modificare questi valori in un cluster in esecuzione selezionando Custom spark-defaults nell'interfaccia utente Web di Ambari. Dopo avere apportato le modifiche, nell'interfaccia utente viene chiesto diriavviare tutti i servizi interessati.
Nota
Questi tre parametri di configurazione possono essere configurati a livello di cluster, per tutte le applicazioni in esecuzione nel cluster, oppure specificati per ogni singola applicazione.
Un'altra origine di informazioni sulle risorse usate dagli executor Spark è l'interfaccia utente dell'applicazione Spark. Nell'interfaccia utente gli executor visualizzano le visualizzazioni Riepilogo e Dettaglio della configurazione e delle risorse utilizzate. Determinare se modificare i valori degli executor per l'intero cluster o un determinato set di esecuzioni di processi.
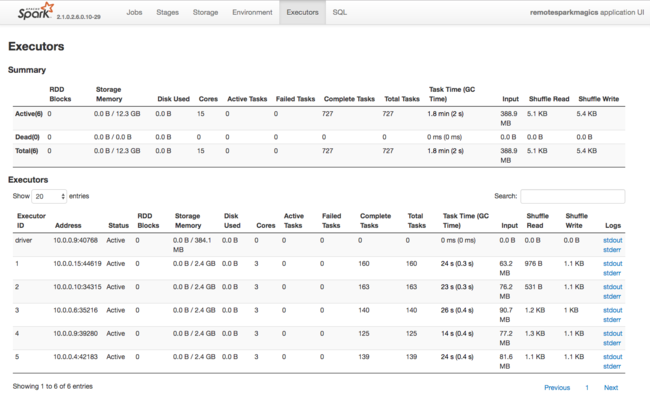
In alternativa, è possibile usare l'API REST Ambari per verificare a livello di codice le impostazioni di configurazione del cluster HDInsight e Spark. Per altre informazioni, vedere le informazioni di riferimento dell'API Apache Ambari in GitHub.
A seconda del carico di lavoro di Spark, è possibile determinare che una configurazione non predefinita per Spark può consentire esecuzioni più ottimizzate dei processi Spark. Eseguire test di benchmark con carichi di lavoro di esempio per convalidare tutte le configurazioni cluster non predefinite. Alcuni dei parametri comuni che è possibile provare a modificare sono:
| Parametro | Descrizione |
|---|---|
| --num-executors | Imposta il numero di executor. |
| --executor-cores | Imposta il numero di core per ogni executor. È consigliabile usare executor di dimensioni medie, in quanto parte della memoria disponibile è già usata da altri processi. |
| --executor-memory | Controlla le dimensioni della memoria (dimensioni heap) di ogni executor in Apache Hadoop YARN ed è necessario lasciare memoria per il sovraccarico di esecuzione. |
Ecco un esempio di due nodi del ruolo di lavoro con valori di configurazione diversi:

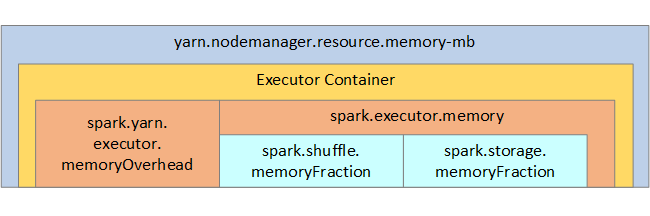
L'elenco seguente illustra i principali parametri di memoria degli executor Spark.
| Parametro | Descrizione |
|---|---|
| spark.executor.memory | Definisce la quantità totale di memoria disponibile per un executor. |
| spark.storage.memoryFraction | (valore predefinito ~60%) definisce la quantità di memoria disponibile per l'archiviazione di RDD persistenti. |
| spark.shuffle.memoryFraction | (valore predefinito ~20%) definisce la quantità di memoria riservata per lo shuffle. |
| spark.storage.unrollFraction e spark.storage.safetyFraction | (totale circa il 30% della memoria totale): questi valori vengono usati internamente da Spark e non devono essere modificati. |
YARN controlla la quantità complessiva massima di memoria usata dai contenitori in ogni nodo Spark. Il diagramma seguente mostra le relazioni per nodo tra gli oggetti di configurazione YARN e gli oggetti Spark.
Modificare i parametri per un'applicazione in esecuzione in Jupyter Notebook
I cluster Spark in HDInsight includono per impostazione predefinita diversi componenti. Ognuno di questi componenti include valori di configurazione predefiniti, di cui è possibile eseguire l'override se necessario.
| Componente | Descrizione |
|---|---|
| Spark Core | Spark Core, Spark SQL, API di streaming Spark, GraphX e Apache Spark MLlib. |
| Anaconda | Gestione pacchetti Python. |
| Apache Livy | L'API REST apache Spark, usata per inviare processi remoti a un cluster HDInsight Spark. |
| Notebook di Jupyter e notebook Apache Zeppelin | Interfaccia utente interattiva basata su browser per interagire con il cluster Spark. |
| Driver ODBC | Connessione cluster Spark in HDInsight a strumenti di business intelligence (BI), ad esempio Microsoft Power BI e Tableau. |
Per le applicazioni in esecuzione in Jupyter Notebook, usare il %%configure comando per apportare modifiche di configurazione dall'interno del notebook stesso. Queste modifiche alla configurazione verranno applicate ai processi di Spark eseguiti dall'istanza del notebook. Apportare tali modifiche all'inizio dell'applicazione, prima di eseguire la prima cella di codice. La configurazione modificata viene applicata alla sessione di Livy al momento della creazione.
Nota
Per modificare la configurazione in una fase successiva nell'applicazione, usare il parametro -f (force). Tuttavia, in questo modo tutte le operazioni eseguite nell'applicazione andranno perse.
Il codice seguente illustra come modificare la configurazione per un'applicazione in esecuzione in un notebook di Jupyter.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Conclusione
Monitorare le impostazioni di configurazione di base per garantire che i processi Spark vengano eseguiti in modo prevedibile e efficiente. Queste impostazioni aiutano a determinare la migliore configurazione del cluster Spark per i carichi di lavoro specifici. È anche necessario monitorare l'esecuzione di esecuzioni di processi Spark a esecuzione prolungata e che utilizzano risorse. Le sfide più comuni centrata sulla pressione della memoria da configurazioni non corrette, ad esempio executor con dimensioni non corrette. Inoltre, operazioni a esecuzione prolungata e attività, che comportano operazioni cartesiane.
Passaggi successivi
- Componenti e versioni di Apache Hadoop disponibili in HDInsight
- Gestire le risorse di un cluster Apache Spark in HDInsight
- Configurazione di Apache Spark
- Running Apache Spark on Apache Hadoop YARN (Esecuzione di Apache Spark in Apache Hadoop YARN)