Dimensioni dell'indice vettoriale e permanenza ai limiti
Per ogni campo vettoriale, Ricerca di intelligenza artificiale di Azure costruisce un indice vettoriale interno usando i parametri dell'algoritmo specificati nel campo. Poiché Ricerca di intelligenza artificiale di Azure impone quote sulle dimensioni dell'indice vettoriale, è necessario sapere come stimare e monitorare le dimensioni dei vettori per assicurarsi di rimanere al di sotto dei limiti.
Nota
Nota sulla terminologia. Internamente, le strutture di dati fisici di un indice di ricerca includono contenuto non elaborato (usato per i modelli di recupero che richiedono contenuto non tokenizzato), indici invertiti (usati per i campi di testo ricercabili) e indici vettoriali (usati per i campi vettoriali ricercabili). Questo articolo illustra i limiti per gli indici vettoriali interni che riportano ognuno dei campi vettoriali.
Suggerimento
La quantizzazione vettoriale e la configurazione dell'archiviazione sono ora in anteprima. Usare funzionalità come tipi di dati ristretti, quantizzazione scalare ed eliminazione dell'archiviazione ridondante per rimanere sotto quota vettoriale e quota di archiviazione.
Punti chiave relativi alla quota e alle dimensioni dell'indice vettoriale
Le dimensioni dell'indice vettoriale vengono misurate in byte.
Le quote vettoriali sono basate sui vincoli di memoria. Tutti gli indici vettoriali ricercabili devono essere caricati in memoria. Allo stesso tempo, deve essere presente anche memoria sufficiente per altre operazioni di runtime. Esistono quote vettoriali per garantire che il sistema complessivo rimanga stabile e bilanciato per tutti i carichi di lavoro.
Gli indici vettoriali sono soggetti anche alla quota del disco, nel senso che tutti gli indici, i vettori e i nonvettori sono quota del disco soggetto. Non esiste alcuna quota disco separata per gli indici vettoriali.
Le quote vettoriali vengono applicate al servizio di ricerca nel suo complesso, per partizione, vale a dire che se si aggiungono partizioni, la quota vettoriale diventa in aumento. Le quote dei vettori per partizione sono maggiori nei servizi più recenti:
Come controllare le dimensioni e la quantità delle partizioni
Se non si è certi dei limiti del servizio di ricerca, ecco due modi per ottenere tali informazioni:
Nella pagina Panoramica del servizio di ricerca della portale di Azure, sia la scheda Proprietà che la scheda Utilizzo mostrano le dimensioni della partizione e l'archiviazione, nonché la quota vettoriale e le dimensioni dell'indice vettoriale.
Nella pagina Scala della portale di Azure è possibile esaminare il numero e le dimensioni delle partizioni.
Come controllare la data di creazione del servizio
I servizi più recenti creati dopo il 3 aprile 2024 offrono da cinque a dieci volte più spazio di archiviazione vettoriale come quelli meno recenti con la stessa tariffa di fatturazione del livello. Se il servizio è meno recente, è consigliabile creare un nuovo servizio e eseguire la migrazione del contenuto.
In portale di Azure aprire il gruppo di risorse che contiene il servizio di ricerca.
Nel riquadro all'estrema sinistra, in Impostazioni, selezionare Distribuzioni.
Individuare la distribuzione del servizio di ricerca. Se sono presenti molte distribuzioni, usare il filtro per cercare "search".
Selezionare la distribuzione. Se sono presenti più di una, fare clic per verificare se si risolve nel servizio di ricerca.
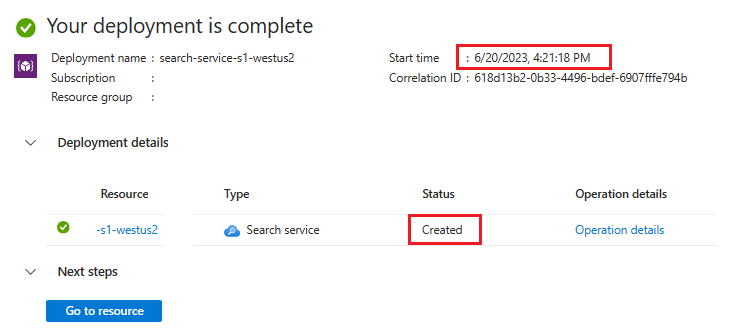
Espandere i dettagli della distribuzione. Verrà visualizzato Creato e la data di creazione.
Ora che si conosce l'età del servizio di ricerca, esaminare i limiti di quota vettoriale in base alla creazione del servizio:
Come ottenere le dimensioni dell'indice vettoriale
Una richiesta per le metriche vettoriali è un'operazione del piano dati. È possibile usare l'portale di Azure, le API REST o gli SDK di Azure per ottenere l'utilizzo del vettore a livello di servizio tramite statistiche del servizio e per singoli indici.
Le informazioni sull'utilizzo sono disponibili nella scheda Utilizzo della pagina Panoramica . Le pagine del portale vengono aggiornate ogni pochi minuti, quindi se un indice è stato aggiornato di recente, attendere un po' prima di controllare i risultati.
Lo screenshot seguente è relativo a un servizio di ricerca Standard 1 (S1) precedente, configurato per una partizione e una replica.
- Archiviazione quota è un vincolo su disco ed è inclusivo di tutti gli indici (vettore e non operatore) in un servizio di ricerca.
- La quota di dimensioni dell'indice vettoriale è un vincolo di memoria. È la quantità di memoria necessaria per caricare tutti gli indici vettoriali interni creati per ogni campo vettoriale in un servizio di ricerca.
Lo screenshot indica che gli indici (vector e nonvector) utilizzano quasi 460 megabyte di spazio di archiviazione su disco disponibile. Gli indici vettoriali utilizzano quasi 93 megabyte di memoria a livello di servizio.

Le quote per le dimensioni dell'indice di archiviazione e vettoriale aumentano o diminuiscono man mano che si aggiungono o rimuovono partizioni. Se si modifica il numero di partizioni, il riquadro mostra una modifica corrispondente nella quota di archiviazione e vettore.
Nota
Su disco, gli indici vettoriali non sono di 93 megabyte. Gli indici vettoriali su disco occupano circa tre volte più spazio rispetto agli indici vettoriali in memoria. Per informazioni dettagliate, vedere Come i campi vettoriali influiscono sull'archiviazione su disco.
Fattori che influiscono sulle dimensioni dell'indice vettoriale
Esistono tre componenti principali che influiscono sulle dimensioni dell'indice vettoriale interno:
- Dimensioni non elaborate dei dati
- Overhead dall'algoritmo selezionato
- Sovraccarico dovuto all'eliminazione o all'aggiornamento di documenti all'interno dell'indice
Dimensioni non elaborate dei dati
Ogni vettore è in genere una matrice di numeri a virgola mobile a precisione singola, in un campo di tipo Collection(Edm.Single).
Le strutture di dati vettoriali richiedono l'archiviazione, rappresentata nel calcolo seguente come "dimensione non elaborata" dei dati. Usare questa dimensione non elaborata per stimare i requisiti di dimensione dell'indice vettoriale dei campi vettoriali.
Le dimensioni di archiviazione di un vettore sono determinate dalla sua dimensionalità. Moltiplicare le dimensioni di un vettore in base al numero di documenti contenenti il campo vettore per ottenere le dimensioni non elaborate:
raw size = (number of documents) * (dimensions of vector field) * (size of data type)
| Tipo di dati EDM | Dimensioni del tipo di dati |
|---|---|
Collection(Edm.Single) |
4 byte |
Collection(Edm.Half) |
2 byte |
Collection(Edm.Int16) |
2 byte |
Collection(Edm.SByte) |
1 byte |
Overhead di memoria dall'algoritmo selezionato
Ogni algoritmo ANN (Near NearEst Neighbor) approssimativo genera strutture di dati aggiuntive in memoria per consentire una ricerca efficiente. Queste strutture utilizzano spazio aggiuntivo all'interno della memoria.
Per l'algoritmo HNSW, l'overhead di memoria varia tra l'1% e il 20%.
L'overhead di memoria è inferiore per le dimensioni superiori perché le dimensioni non elaborate dei vettori aumentano, mentre le strutture di dati aggiuntive rimangono di dimensioni fisse poiché archiviano informazioni sulla connettività all'interno del grafico. Di conseguenza, il contributo delle strutture di dati aggiuntive costituisce una parte inferiore delle dimensioni complessive.
Il sovraccarico di memoria è maggiore per valori maggiori del parametro mHNSW , che determina il numero di collegamenti bidirezionali creati per ogni nuovo vettore durante la costruzione dell'indice. Ciò è dovuto al fatto che m contribuisce a circa 8 byte a 10 byte per documento moltiplicato per m.
La tabella seguente riepiloga le percentuali di overhead osservate nei test interni:
| Dimensioni | Parametro HNSW (m) | Percentuale overhead |
|---|---|---|
| 96 | 4 | 20% |
| 200 | 4 | %8 |
| 768 | 4 | 2% |
| 1536 | 4 | %1 |
Questi risultati illustrano la relazione tra dimensioni, parametro mHNSW e overhead di memoria per l'algoritmo HNSW.
Sovraccarico dovuto all'eliminazione o all'aggiornamento di documenti all'interno dell'indice
Quando un documento con un campo vettoriale viene eliminato o aggiornato (gli aggiornamenti vengono rappresentati internamente come operazione di eliminazione e inserimento), il documento sottostante viene contrassegnato come eliminato e ignorato durante le query successive. Man mano che i nuovi documenti vengono indicizzati e l'indice vettoriale interno aumenta, il sistema pulisce questi documenti eliminati e recupera le risorse. Ciò significa che è probabile che si osservi un ritardo tra l'eliminazione di documenti e le risorse sottostanti liberate.
Si fa riferimento a questo come rapporto documenti eliminati. Poiché il rapporto tra documenti eliminati dipende dalle caratteristiche di indicizzazione del servizio, non esiste un'euristica universale per stimare questo parametro e non esiste alcuna API o script che restituisca il rapporto effettivo per il servizio. Si osserva che la metà dei clienti ha un rapporto di documenti eliminati inferiore al 10%. Se si tende a eseguire eliminazioni o aggiornamenti ad alta frequenza, è possibile osservare un rapporto documenti eliminati più elevato.
Si tratta di un altro fattore che influisce sulle dimensioni dell'indice vettoriale. Sfortunatamente, non è disponibile un meccanismo per visualizzare il rapporto dei documenti eliminati corrente.
Stima delle dimensioni totali dei dati in memoria
Tenendo conto dei fattori descritti in precedenza, per stimare le dimensioni totali dell'indice vettoriale, usare il calcolo seguente:
(raw_size) * (1 + algorithm_overhead (in percent)) * (1 + deleted_docs_ratio (in percent))
Ad esempio, per calcolare il raw_size, si supponga di usare un modello OpenAI di Azure popolare, text-embedding-ada-002 con 1.536 dimensioni. Ciò significa che un documento utilizzerà 1.536 Edm.Single (float) o 6.144 byte, perché ognuno Edm.Single è di 4 byte. 1.000 documenti con un singolo campo vettore dimensionale 1.536 utilizzerebbe in totale 1000 documenti x 1536 floats/doc = 1.536.000 floats o 6.144.000 byte.
Se sono presenti più campi vettoriali, è necessario eseguire questo calcolo per ogni campo vettore all'interno dell'indice e aggiungerli tutti insieme. Ad esempio, 1.000 documenti con due campi vettoriali 1.536 dimensionali, utilizzare 1000 documenti x 2 campi x 1536 floats/doc x 4 byte/float = 12.288.000 byte.
Per ottenere le dimensioni dell'indice vettoriale, moltiplicare questa raw_size in base al sovraccarico dell'algoritmo e al rapporto del documento eliminato. Se il sovraccarico dell'algoritmo per i parametri HNSW scelti è pari al 10% e il rapporto tra documenti eliminati è 10%, si ottiene: 6.144 MB * (1 + 0.10) * (1 + 0.10) = 7.434 MB.
Impatto dei campi vettoriali sull'archiviazione su disco
La maggior parte di questo articolo fornisce informazioni sulle dimensioni dei vettori in memoria. Se si desidera conoscere le dimensioni del vettore su disco, il consumo del disco per i dati vettoriali è circa tre volte la dimensione dell'indice vettoriale in memoria. Ad esempio, se l'utilizzo vectorIndexSize è pari a 100 megabyte (10 milioni di byte), è stato usato almeno 300 megabyte di storageSize quota per contenere gli indici vettoriali