この記事では、探索的データ分析 (EDA) と呼ばれるデータ ウェアハウス プロジェクトに対する代替アプローチについて説明します。 このアプローチにより、抽出、変換、読み込み (ETL) 操作の課題を軽減できます。 まず、ビジネス分析情報の生成に焦点を当て、次にモデリングタスクと ETL タスクを処理します。
Architecture

このアーキテクチャの Visio ファイルをダウンロードします。
EDA の場合は、図の右側のみが関係します。 Azure Synapse SQL サーバーレスは、データ レイク ファイルのコンピューティング エンジンとして使用されます。
EDA を達成するには、以下を行う必要があります。
- T-SQL クエリは、Azure Synapse SQL サーバーレスまたは Azure Synapse Spark で直接実行されます。
- クエリは、Power BI や Azure Data Studio などの、グラフィカル クエリ ツールから実行されます。
Parquet または Delta を使用して、すべてのレイクハウス データを保持することをお勧めします。
任意の抽出、読み込み、変換 (ELT) ツールを使用して、図の左側 (データ インジェスト) を実装できます。 EDA には影響しません。
Components
Azure Synapse Analytics は、データ統合、エンタープライズ データ ウェアハウジング、ビッグ データ分析をレイクハウス データと組み合わせます。 このソリューションの内容:
- Azure Synapse ワークスペースにより、データ エンジニア、データ サイエンティスト、データ アナリスト、ビジネス インテリジェンス (BI) の専門家間の EDA タスクでのコラボレーションが促進されます。
- Azure Synapse サーバーレス SQL プールでは、Azure Data Lake Storage の非構造化および半構造化データを標準の T-SQL を使用してオンデマンドで分析します。
- Azure Synapse サーバーレス Apache Spark プールでは、Spark SQL、PySpark、Scala などの Spark 言語を使用して Data Lake Storage でコードファースト探索を行います。
Azure Data Lake Storage は、データのストレージを提供し、このストレージは、Azure Synapse サーバーレス SQL プールで分析されます。
Azure Machine Learning は、Azure Synapse Spark にデータを提供します。
Power BI は、このソリューションで EDA を実現するためのデータのクエリに使用されます。
代替
Azure Databricks を使用して、Synapse SQL サーバーレス プールを置き換えるか補完することができます。
Synapse SQL サーバーレス プールでレイクハウス モデルを使用する代わりに、Azure Synapse 専用 SQL プールを使用してエンタープライズ データを保存できます。 使用するテクノロジを決定するには、この記事のユース ケースと考慮事項、および関連リソースを確認してください。
シナリオの詳細
このソリューションは、データ ウェアハウス プロジェクトに対する EDA アプローチの実装を示すものです。 このアプローチにより、ETL 操作の課題を軽減できます。 まず、ビジネス分析情報の生成に焦点を当て、次にモデリング タスクと ETL タスクを処理します。
考えられるユース ケース
この分析パターンからメリットを得ることができるその他のシナリオ:
規範的分析。 次の最適なアクション、次に何を行いますか、などデータについて質問します。データを使用し、直観型ではなく、データ駆動型を強化します。 データは非構造化され、品質の異なる多くの外部ソースから取得される可能性があります。 データ ウェアハウスにデータを実際に読み込まずに、可能な限り迅速にデータを使用してビジネス戦略を評価する必要があります。 疑問に対する答えを得た後は、データを破棄できます。
セルフサービス ETL。 データ サンドボックス (EDA) アクティビティを行う場合は、ETL/ELT を実行します。 データを変換し、価値を持たせます。 これにより、ETL 開発者のスケールが向上します。
探索的データ分析について
EDA のしくみを詳しく見る前に、データ ウェアハウス プロジェクトに対する従来のアプローチの概要を把握しておくと役に立ちます。 従来のアプローチは次のようなものです。
要件の収集。 データを使用して実行する処理の内容を文書化します。
データ モデリング 数値データと属性データをファクト テーブルとディメンション テーブルにモデル化する方法を決定します。 従来は、新しいデータを取得する前にこの手順を実行します。
ETL。 データを取得し、データ ウェアハウスのデータ モデルに取り込みます。
これらの手順には数週間または数か月かかる場合があります。 その後にのみ、データのクエリと、ビジネス上の問題の解決を開始できます。 ユーザーは、レポートの作成後にのみ値を見ることができます。 通常、ソリューション アーキテクチャは次のようになります。
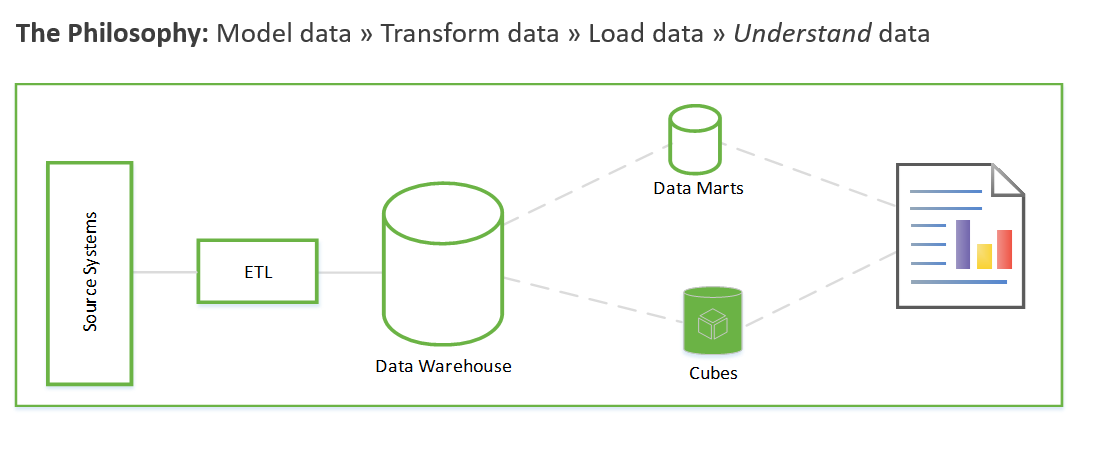
これは、まずビジネス分析情報の生成に焦点を当て、次にモデリング タスクと ETL タスクを処理する別の方法で行うことができます。 このプロセスは、データ サイエンス プロセスに似ています。 次のような画面が表示されます。
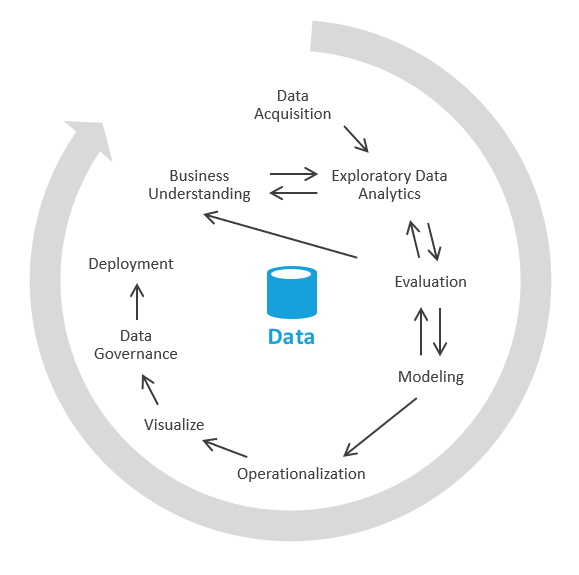
業界では、このプロセスは、EDA、または探索的データ分析と呼ばれます。
この手順を以下に示します。
データの取得 まず、データ レイク/サンドボックスに取り込む必要があるデータ ソースを決定する必要があります。 その後で、そのデータをレイクのランディング エリアに取り込む必要があります。 Azure は、Azure Data Factory や Azure Logic Apps などのデータを迅速に取り込むことができるツールを提供しています。
データ サンドボックス。 最初は、Azure Synapse Analytics サーバーレスまたは基本的な SQL を使用した探索的データ分析のスキルを持つエンジニアがビジネス アナリストと協力します。 このフェーズでは、新しいデータを使用してビジネス分析情報を明らかにしようとします。 EDA は反復的なプロセスです。 より多くのデータの取り込み、SME との話し合い、より多くの質問、視覚化の生成が必要になる場合があります。
評価。 ビジネス分析情報を見つけたら、データを使用して実行する処理の内容を評価する必要があります。 データ ウェアハウスにデータを保持する必要がある場合があります (そのため、モデリング フェーズに移行します)。 それ以外の場合は、データ レイク/レイクハウスにデータを保持し、予測分析 (機械学習アルゴリズム) に使用する場合があります。 さらにそれ以外に、新しい分析情報を使用してシステムのレコードをバックフィルする場合があります。 これらの決定に基づいて、次に何を行う必要があるのかをより正確に理解できます。 ETL を実行する必要がない場合もあります。
これらの手法は、真のセルフサービス分析の中核です。 データ レイクと、データ レイクのクエリ パターンを理解する Azure Synapse サーバーレスのようなクエリ ツールを使用すると、SQL をある程度理解しているビジネス ユーザーにデータ資産を渡すことができます。 この方法を使用すると、価値を得るまでの時間を大幅に短縮し、企業のデータ イニシアチブに関連するリスクの一部を解消することができます。
考慮事項
以降の考慮事項には、ワークロードの品質向上に使用できる一連の基本原則である Azure "Well-Architected Framework" の要素が組み込まれています。 詳細については、「Microsoft Azure Well-Architected Framework」を参照してください。
可用性
Azure Synapse SQL サーバーレス プールは、高可用性 (HA) とディザスター リカバリー (DR) の要件を満たすことができるサービスとしてのプラットフォーム (PaaS) 機能です。
サーバーレス プールはオンデマンドで使用できます。 スケールアップ、スケールダウン、スケールイン、スケールアウトや、どのような管理も必要ありません。 クエリごとの支払いモデルを使用するので、未使用の容量は常にありません。 サーバーレス プールは、次の場合に最適です。
- T-SQL でのアドホック データ サイエンス探索。
- データ ウェアハウス エンティティの初期プロトタイピング。
- パフォーマンスの遅れを許容できるシナリオで、たとえば Power BI でコンシューマーが使用できるビューの定義。
- 探索的データ分析
Operations
Synapse SQL サーバーレスでは、クエリと操作に標準の T SQLを使用します。 Synapse ワークスペース UI、Azure Data Studio、または T-SQL Server Management Studio を T-SQL ツールとして使用できます。
コスト最適化
コストの最適化とは、不要な費用を削減し、運用効率を向上させる方法を検討することです。 詳しくは、コスト最適化の柱の概要に関する記事をご覧ください。
Data Lake Storage の価格は、格納するデータの量とデータの使用頻度によって異なります。 サンプル価格には、1 TB の格納データが含まれており、さらに別のトランザクションの前提条件があります。 1 TB は、元のレガシ データベースのサイズではなく、データ レイクのサイズを意味します。
Azure Synapse Spark プールの料金は、ノード サイズ、インスタンス数、稼働時間に基づきます。 例では、使用率が 1 週間に 5 時間から 1 か月に 40 時間までの 1 つの小さな計算ノードを前提としています。
Azure Synapse サーバーレス SQL プールの価格は、処理済みデータの TB 数に基づきます。 サンプルでは、1 か月に 50 TB が処理されることを前提としています。 この数字は、元のレガシ データベースのサイズではなく、データ レイクのサイズを意味しています。
共同作成者
この記事は、Microsoft によって更新および保守されています。 当初の寄稿者は以下のとおりです。
プリンシパルの作成者:
- デイブ・ウェンツェル | プリンシパル MTC テクニカル アーキテクト
次のステップ
- データ エンジニアのラーニング パス
- チュートリアル:Azure Synapse Analytics の使用を開始する
- 単一データベースの作成 - Azure SQL Database
- Azure Synapse SQL アーキテクチャ
- Azure Data Lake Storage のストレージ アカウントの作成
- Azure Event Hubs クイック スタート - Azure portal を使用したイベント ハブの作成
- クイックスタート: Azure portal を使用して Stream Analytics ジョブを作成する
- クイックスタート: Azure Machine Learning の利用を開始する