この参照アーキテクチャは、Azure Databricks を使用してレコメンデーション モデルをトレーニングし、Azure Cosmos DB、Azure Machine Learning、および Azure Kubernetes Service (AKS) を使用して API としてこのモデルをデプロイする方法を示します。 このアーキテクチャのリファレンス実装については、GitHub での「リアルタイム レコメンデーション API の構築」を参照してください。
アーキテクチャ
このアーキテクチャの Visio ファイルをダウンロードします。
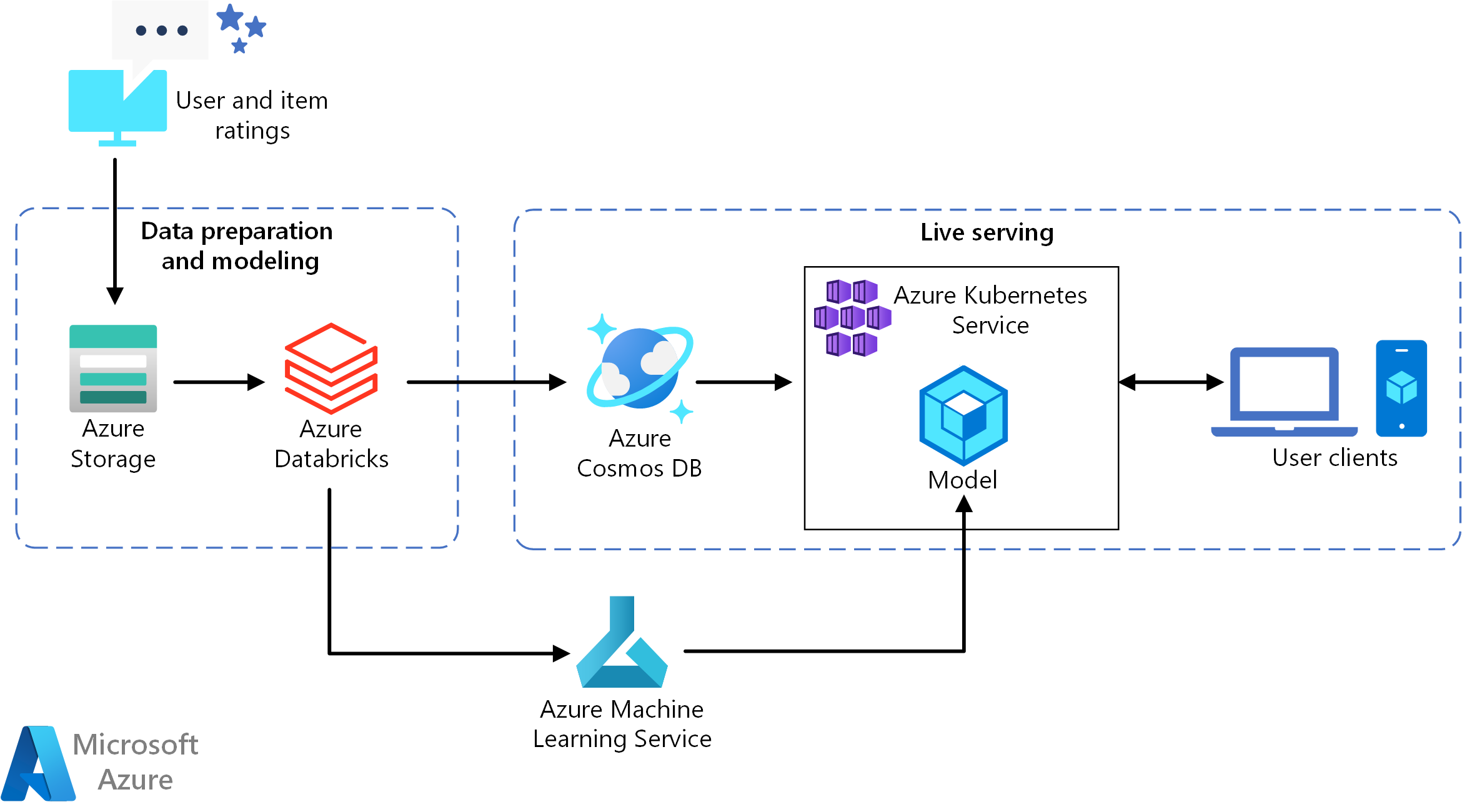
この参照アーキテクチャは、ユーザーに上位 10 個の映画のレコメンデーションを提供できるリアルタイム レコメンダー サービス API をトレーニングおよびデプロイするためのものです。
データフロー
- ユーザーの動作を追跡します。 たとえば、ユーザーが映画を評価したときや製品やニュースの記事をクリックしたときに、バックエンド サービスでログを記録することができます。
- このデータを、使用できるデータ ソースから Azure Databricks に読み込みます。
- データを準備し、それをトレーニング セットとテスト セットに分割してモデルをトレーニングします (このガイドでは、データを分割するための選択肢が説明されています)。
- データに合わせて Spark の Collaborative Filtering モデルを調整します。
- 評価とランク付けのメトリックを使用してモデルの品質を評価します (このガイドでは、レコメンダーの評価に使用できるメトリックについて詳しく説明されています)。
- ユーザーごとに上位 10 個のレコメンデーションを事前に計算し、Azure Cosmos DB にキャッシュとして保存します。
- Machine Learning API を使用して API サービスを AKS にデプロイし、API をコンテナー化してデプロイします。
- バックエンド サービスによってユーザーから要求が取得されたら、AKS 内でホストされているレコメンデーション API を呼び出して上位 10 個のレコメンデーションを取得し、それらをユーザーに表示します。
コンポーネント
- Azure Databricks。 Databricks は、入力データを準備し、Spark クラスター上でレコメンダー モデルをトレーニングするために使用される開発環境です。 また、Azure Databricks には、データ処理タスクや機械学習タスクのためにノートブック上で実行して共同作業することができる対話型ワークスペースも用意されています。
- Azure Kubernetes Service (AKS)。 AKS は、Kubernetes クラスターに機械学習モデル サービス API をデプロイして運用化するために使用されます。 AKS はコンテナー化されたモデルをホストし、スループット要件、ID とアクセス管理、ログ記録と正常性の監視を満たすスケーラビリティを実現しています。
- Azure Cosmos DB Azure Cosmos DB は、各ユーザーのおすすめ映画上位 10 個を保存するために使用されるグローバルに分散されたデータベース サービスです。 特定のユーザーの上位のおすすめ項目を読み取るためにかかる待機時間が短い (99 パーセンタイルで 10 ミリ秒) ので、Azure Cosmos DB はこのシナリオに適しています。
- 機械学習。 このサービスは、機械学習モデルを追跡および管理し、そのモデルをパッケージ化してスケーラブルな AKS 環境にデプロイするために使用されます。
- Microsoft Recommenders。 このオープンソース リポジトリには、レコメンダー システムの構築、評価、および運用化を始める際に役立つユーティリティ コードとサンプルが含まれています。
シナリオの詳細
このアーキテクチャは、製品、映画、およびニュースに関するレコメンデーションを含め、ほとんどのレコメンデーション エンジンのシナリオに一般化することができます。
考えられるユース ケース
シナリオ:あるメディア組織は、ユーザーに映画またはビデオのレコメンデーションを提供したいと考えています。 組織は、パーソナライズされたレコメンデーションを提供することで、クリックスルー率の向上、Web サイトのエンゲージメントの向上、ユーザー満足度の向上など、いくつかのビジネス目標を達成します。
このソリューションは、小売業界とメディアおよびエンターテイメント業界向けに最適化されています。
考慮事項
以降の考慮事項には、ワークロードの品質向上に使用できる一連の基本原則である Azure "Well-Architected Framework" の要素が組み込まれています。 詳細については、「Microsoft Azure Well-Architected Framework」を参照してください。
Azure Databricks での Spark モデルのバッチ スコアリングでは、Spark と Azure Databricks を使用して、スケジュールされたバッチ スコアリング プロセスを実行する参照アーキテクチャについて説明します。 新しいレコメンデーションを生成するには、このアプローチをお勧めします。
パフォーマンス効率
パフォーマンス効率とは、ユーザーによって行われた要求に合わせて効率的な方法でワークロードをスケーリングできることです。 詳細については、「パフォーマンス効率の柱の概要」を参照してください。
通常、レコメンデーションは、ユーザーが Web サイトに対して行う要求のクリティカル パスに含まれるため、パフォーマンスはリアルタイム レコメンデーションの主な考慮事項です。
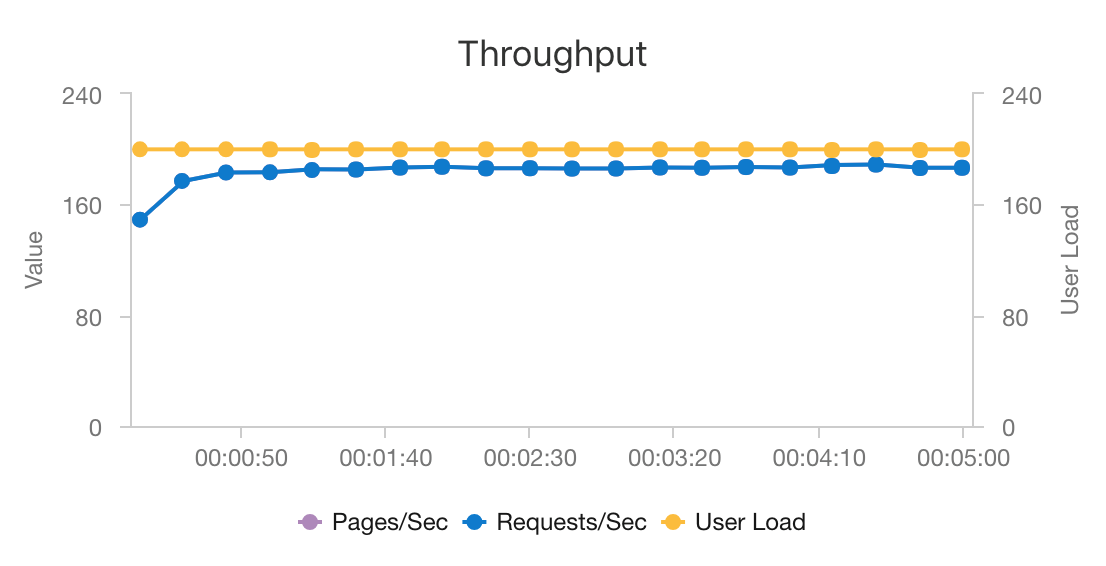
AKS と Azure Cosmos DB の組み合わせることで、このアーキテクチャは、最小限のオーバーヘッドで中規模のワークロード向けにレコメンデーションを提供するために適した出発点となります。 200 人の同時ユーザーによる負荷テストでは、このアーキテクチャは約 60 ミリ秒の中央値の待機時間でレコメンデーションを提供し、1 秒あたり 180 要求のスループットで実行されます。 この負荷テストは、既定のデプロイ構成 (Azure Cosmos DB 用にプロビジョニングされた 12 vCPU、42 GB のメモリ、および 11,000 要求ユニット (RU)/秒の 3x D3 v2 AKS クラスター) に対して実行されました。

Azure Cosmos DB は、ターンキーのグローバル配布と、アプリが持っているデータベース要件を満たす上での有用性により推奨されています。 待機時間をやや短くするために、検索の処理には Azure Cosmos DB ではなく Azure Cache for Redis を使用することを検討してください。 Azure Cache for Redis で、バックエンド ストア内のデータへの依存度が高いシステムのパフォーマンスを向上することができます。
スケーラビリティ
Spark を使用する予定がない場合、またはワークロードが小規模で分散が不要な場合は、Azure Databricks ではなく Data Science Virtual Machine (DSVM) を使用することを検討してください。 DSVM は、機械学習とデータ サイエンス向けのディープ ラーニング フレームワークとツールを備えた Azure 仮想マシンです。 Azure Databricks と同様に、DSVM で作成したモデルは、Machine Learning を介して AKS 上のサービスとして運用化することができます。
トレーニング時は、より大きい固定サイズの Spark クラスターを Azure Databricks にプロビジョニングするか、自動スケーリングを構成します。 自動スケーリングが有効な場合、Databricks ではクラスターの負荷が監視され、必要に応じてスケールアップまたはスケールダウンされます。 大規模なデータ サイズで、データの準備またはモデリング タスクにかかる時間を短縮したい場合は、より大きなクラスターをプロビジョニングまたはスケールアウトします。
パフォーマンスとスループットの要件を満たすように AKS クラスターをスケールします。 クラスターを十分に活用するためにポッドの数をスケールアップし、サービスの要件を満たすようにクラスターのノードをスケールすることに留意します。 AKS クラスターに対して自動終了を設定することもできます。 詳しくは、「Azure Kubernetes Service クラスターにモデルをデプロイする」をご覧ください。
Azure Cosmos DB のパフォーマンスを管理するには、1 秒間に必要な読み取り数を見積もり、必要な秒あたりの RU (スループット) の数をプロビジョニングします。 パーティション分割と水平スケーリングのベスト プラクティスを使用してください。
コスト最適化
コストの最適化とは、不要な費用を削減し、運用効率を向上させる方法を検討することです。 詳しくは、コスト最適化の柱の概要に関する記事をご覧ください。
このシナリオにおけるコストの主な要因は次のとおりです。
- トレーニングに必要な Azure Databricks クラスターのサイズ。
- パフォーマンス要件を満たすために必要な AKS クラスターのサイズ。
- パフォーマンス要件を満たすためにプロビジョニングされる Azure Cosmos DB RU。
頻度が低い場合は再トレーニングを少なくし、使用していない場合は Spark クラスターをオフにすることで、Azure Databricks のコストを管理します。 AKS と Azure Cosmos DB のコストはサイトに必要なスループットとパフォーマンスに左右され、サイトへのトラフィック量に応じてスケールアップまたはスケールダウンします。
このシナリオのデプロイ
このアーキテクチャをデプロイするには、セットアップのドキュメントにある Azure Databricks の手順に従ってください。 要約すると、その手順では次のことを行う必要があります。
- Azure Databricks ワークスペースを作成します。
- 次の構成を持つ新しいクラスターを Azure Databricks 上に作成します。
- クラスター モード:Standard
- Databricks Runtime のバージョン: 4.3 (Apache Spark 2.3.1、Scala 2.11 など)
- Python バージョン: 3
- ドライバーの種類: Standard_DS3_v2
- ワーカーの種類: Standard_DS3_v2 (必要に応じて最小値と最大値)
- 自動終了: (必要に応じて)
- Spark の構成: (必要に応じて)
- 環境変数: (必要に応じて)
- Azure Databricks ワークスペース内に個人用アクセス トークンを作成します。 詳細については、Azure Databricks 認証のドキュメントを参照してください。
- スクリプトを実行できる環境 (ご使用のローカル コンピューターなど) に Microsoft Recommenders リポジトリを複製します。
- クイック インストールのセットアップ手順に従って関連するライブラリを Azure Databricks にインストールします。
- クイック インストールのセットアップ手順に従って、Azure Databricks を運用化するために準備します。
- ワークスペースに ALS Movie Operationalization ノートブックをインポートします。 Azure Databricks ワークスペースへのサインイン後、次の手順を行います。
- ワークスペースの左側にある [ホーム] をクリックします。
- ホーム ディレクトリ内の空白を右クリックします。 [インポート] を選択します。
- [URL] を選択し、次のとおりテキスト フィールドに貼り付けます:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - [インポート] をクリックします。
- Azure Databricks 内でノートブックを開き、構成したクラスターをアタッチします。
- ノートブックを実行して、特定のユーザーに上位 10 個のおすすめ映画を提供するレコメンデーション API を作成するために必要な Azure リソースを作成します。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパルの作成者:
- Miguel Fierro | プリンシパル データ科学者マネージャー
- Nikhil Joglekar | プロダクト マネージャー、Azure アルゴリズムおよびデータ サイエンス
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次のステップ
- リアルタイム レコメンデーション API の構築
- Azure Databricks とは
- Azure Kubernetes Service
- Azure Cosmos DB へようこそ
- Azure Machine Learning とは