このアーキテクチャ パターンでは、Azure データ サービスのエコシステムに MDM を組み込んで、分析と運用上の意思決定に使用されるデータの品質を向上させる方法を示します。 MDM によって、次のようないくつかの一般的な課題が解決します。
- 重複データの識別と管理 (照合とマージ)。
- データ品質の問題に対するフラグの設定と解決。
- データの標準化とエンリッチ。
- データ スチュワードがデータを積極的に管理および改善できるようにする。
このパターンは、MDM に対する最新手法を提示します。 Profisee を含め、すべてのテクノロジは Azure にネイティブにデプロイできます。Profisee はコンテナー経由でデプロイし、Azure Kubernetes Service で管理できます。
アーキテクチャ

"このアーキテクチャで使用される図の Visio ファイルをダウンロードしてください。"
データフロー
次のデータフローは、前の図に対応しています。
ソース データの読み込み: ビジネス アプリケーションからのソース データは、Azure Data Lake にコピーされ、下流の分析でのさらなる変換と使用のために格納されます。 ソース データは通常、次の 3 つのカテゴリのいずれかに分類されます。
- 構造化マスター データ – 顧客、製品、場所などが記述されている情報。 マスター データは量が少なく、複雑で、時間の経過と共にゆっくりと変化します。 これは、多くの場合、組織がデータ品質の面で最も苦労するデータです。
- 構造化トランザクション データ – 注文、請求、対話など、特定の時点で発生するビジネス イベント。 トランザクションには、そのトランザクションのメトリック (販売価格など) と、マスター データ (購入に関係する製品や顧客など) への参照が含まれます。 トランザクション データは通常、大量で、複雑度は低く、時間の経過と共に変化しません。
- 非構造化データ – ドキュメント、画像、動画、ソーシャル メディア コンテンツ、オーディオが含まれる可能性があるデータ。 最新の分析プラットフォームでは、ますます非構造化データを使用して新しい分析情報を得られるようになってきています。 非構造化データは、多くの場合、マスター データに関連付けられます (ソーシャル メディア アカウントに関連付けられた顧客や、画像に関連付けられた製品など)。
ソース マスター データの読み込み: ソース ビジネス アプリケーションのマスター データは、完全な系列情報と最小限の変換を使用して、MDM アプリケーションに "そのまま" 読み込まれます。
MDM の自動処理: MDM ソリューションでは、自動化されたプロセスを使用して、住所データなどのデータを標準化、検証、エンリッチします。 また、このソリューションでは、データ品質の問題を特定し、重複するレコード (重複する顧客など) をグループ化し、"ゴールデン レコード" とも呼ばれるマスター レコードを生成します。
データ スチュワードシップ: 必要に応じて、データ スチュワードは以下を実行できます。
- 一致したレコードのグループを確認および管理する
- データ リレーションシップの作成し、管理する
- 不足している情報を入力する
- データ品質の問題を解決する。
データ スチュワードは必要に応じて、製品階層など、複数の代替階層ロールアップを管理できます。
管理対象のマスター データの読み込み: 下流の分析ソリューションへの高品質のマスター データ フロー。 データ統合でのデータ品質の変換が不要になったため、このアクションによってプロセスはさらに簡略化されます。
トランザクション データと非構造化データの読み込み: トランザクション データと非構造化データが下流の分析ソリューションに読み込まれ、そこで高品質のマスター データと組み合わされます。
視覚化と分析: データはモデル化され、ビジネス ユーザーが分析のために使用できるようになります。 高品質のマスター データにより、データ品質の一般的な問題が解消され、より適切な分析情報が得られます。
Components
Azure Data Factory は、ETL と ELT ワークフローを作成、スケジュール設定、調整できるハイブリッド データ統合サービスです。
Azure Data Lake により、分析データのための無制限のストレージが提供されます。
Profisee は、Microsoft エコシステムと簡単に統合できるように設計されたスケーラブルな MDM プラットフォームです。
Azure Synapse Analytics は、高速で柔軟性のある、信頼性の高いクラウド データ ウェアハウスです。これにより、超並列処理アーキテクチャを使用して、データを弾力的かつ個別にスケーリング、計算、格納できます。
Power BI は、組織全体に分析情報を配信できるビジネス分析ツール スイートです。 数百のデータ ソースに接続でき、データの準備が簡素化され、即席の分析が促進されます。 優れたレポートを生成し、組織に公開して、Web やモバイル デバイスで使用できます。
代替
専用の MDM アプリケーションがない場合、Azure エコシステム内に MDM ソリューションを構築するために必要な技術的機能がいくつかあります。
- データ品質 - 分析プラットフォームに読み込むときに、データ品質を統合プロセスに組み込むことができます。 たとえば、ハードコーディングされたスクリプトを使用して、Azure Data Factory パイプラインにデータ品質の変換を適用します。
- データの標準化とエンリッチメント - 住所データのデータ検証および標準化に、Azure Maps を利用できます。これは、Azure Functions と Azure Data Factory で使用できます。 他のデータの標準化には、ハード コーディングされたスクリプトの開発が必要になる場合があります。
- 重複データの管理 - 完全一致のために十分な識別子を使用できる場合は、Azure Data Factory を使用して行の重複を除去できます。 この場合、一致するものを適切なサバイバーシップでマージするロジックには、ハード コーディングされたカスタム スクリプトが必要になる場合があります。
- データ スチュワードシップ - Power Apps を使用して、レビュー、ワークフロー、アラート、検証のための適切なユーザー インターフェイスを備えた、簡単なデータ スチュワードシップ ソリューションを迅速に開発して、Azure 内のデータを管理します。
シナリオの詳細
多くのデジタル変換プログラムでは、コアとして Azure を使用します。 ただし、これは、ビジネス アプリケーション、データベース、データ フィードなど、複数のソースからのデータの品質と一貫性に依存しています。 また、ビジネス インテリジェンス、分析、機械学習などを通じて価値を提供します。 Profisee のマスター データ管理 (MDM) ソリューションを使用すると、複数のソースからのデータを "整合させて結合する" ための実用的な方法で Azure データ資産が完全になります。 これは、照合、マージ、標準化、検証、修正など、ソース データに対して一貫したデータ標準を適用して行われます。 Azure Data Factory および他の Azure Data Services とのネイティブ統合により、このプロセスはさらに合理化されて、Azure のビジネス ベネフィットの提供が促進されます。
MDM ソリューションの機能の中核となるのは、複数のソースからのデータが結合されて、各レコードの最もよく知られた信頼できるデータが含まれる "ゴールデン レコード マスター" が作成されることです。 この構造は要件に従ってドメインごとに構築されますが、ほとんどの場合、複数のドメインが必要です。 一般的なドメインは、顧客、製品、場所です。 しかし、参照データから契約や薬品名まで、あらゆるものをドメインで表すことができます。 一般に、広範な Azure のデータ要件に関連してドメイン カバレッジをより適切に作成できるほど、望ましくなります。
MDM 統合パイプライン

このアーキテクチャの Visio ファイルをダウンロードします。
上の図は、Profisee MDM ソリューションとの統合の詳細を示したものです。 Azure Data Factory と Profisee にはネイティブの REST 統合サポートが含まれており、軽量で最新の統合が提供されることに留意してください。
ソース データを MDM に読み込む: Azure Data Factory によってデータがデータ レイクから抽出され、マスター データ モデルと一致するように変換されて、REST シンク経由で MDM リポジトリにストリーミングされます。
MDM の処理: MDM プラットフォームにより、一連のアクティビティを通じてソース マスター データが処理され、データの検証、標準化、エンリッチが行われて、データ品質プロセスが実行されます。 最後に、MDM によって照合とサバイバーシップが実行されて、重複するレコードの識別およびグループ化が行われ、マスター レコードが作成されます。 必要に応じて、データ スチュワードはタスクを実行して、下流の分析で使用するマスター データのセットを得ることができます。
分析用にマスター データを読み込む: Azure Data Factory により、その REST ソースを使用して、Profisee から Azure Synapse Analytics にマスター データがストリーミングされます。
Profisee 用の Azure Data Factory テンプレート
Microsoft との共同作業により、Profisee は、Azure Data Services エコシステムに Profisee をすばやく簡単に統合できるようにする一連の Azure Data Factory テンプレートを開発しました。 これらのテンプレートでは、Azure Data Factory の REST データ ソースとデータ シンクを使用して、Profisee の REST Gateway API のデータの読み取りと書き込みが行われます。 Profisee に対する読み取りと書き込みの両方のテンプレートが用意されています。
Data Factory テンプレートの例: REST で JSON から Profisee に
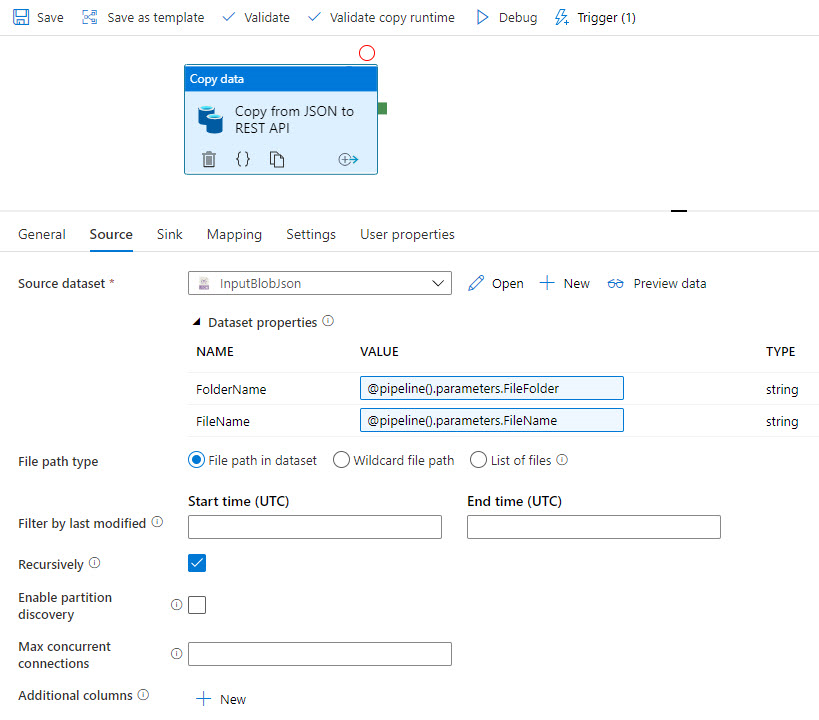
次のスクリーンショットは、REST を使用して Azure Data Lake 内の JSON ファイルから Profisee にデータをコピーする Azure Data Factory テンプレートを示しています。
このテンプレートは、ソースの JSON データをコピーします。
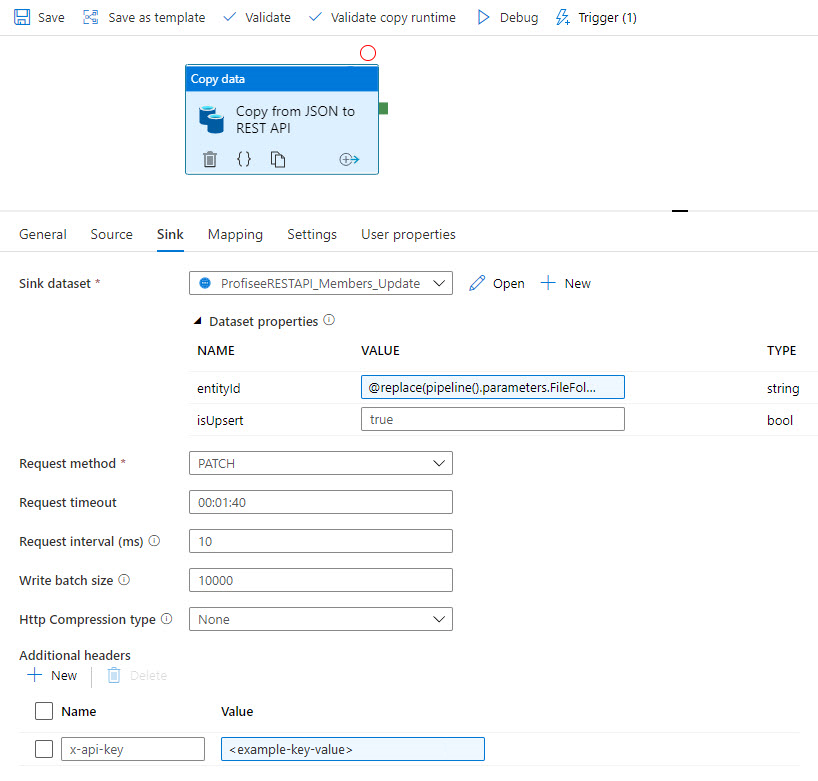
その後、データは REST を使用して Profisee に同期されます。
詳細については、Profisee 用の Azure Data Factory テンプレートに関するページを参照してください。
MDM の処理
MDM の分析ユース ケースでは、データは多くの場合、分析用のデータを読み込むために、MDM ソリューションを介して自動的に処理されます。 以降のセクションでは、このコンテキストでの顧客データの一般的なプロセスを示します。
1. ソース データの読み込み
系列情報などのソース データが、ソース システムから MDM ソリューションに読み込まれます。 この例では、CRM からのものと ERP アプリケーションからのものの 2 つのソース レコードがあります。 目視検査では、2 つのレコードは両方とも同じ人物を表しているように見えます。
| ソース名 | ソースの住所 | ソースの州 | ソースの電話番号 | ソース ID | 標準の住所 | 標準の州 | 標準の名前 | 標準の電話番号 | Similarity |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | GA | 7708434125 | CRM-100 | |||||
| Bosch, Alana | 123 Main St. | ジョージア | 404-854-7736 | CRM-121 | |||||
| Alana Bosch | (404) 854-7736 | ERP-988 |
2. データの検証と標準化
検証と標準化の規則やサービスを使用すると、住所、名前、電話番号の情報の標準化および検証ができます。
| ソース名 | ソースの住所 | ソースの州 | ソースの電話番号 | ソース ID | 標準の住所 | 標準の州 | 標準の名前 | 標準の電話番号 | Similarity |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | GA | 7708434125 | CRM-100 | 123 Main St. | GA | Alana Bosh | 770 843 4125 | |
| Bosch, Alana | 123 Main St. | ジョージア | 404-854-7736 | CRM-121 | 123 Main St. | GA | Alana Bosch | 404 854 7736 | |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 |
3. [照合]
データが標準化されたら、照合が実行されて、グループ内のレコード間の類似性が識別されます。 このシナリオでは、2 つのレコードの名前と電話番号が正確に一致し、それ以外は名前と住所があいまいに一致します。
| ソース名 | ソースの住所 | ソースの州 | ソースの電話番号 | ソース ID | 標準の住所 | 標準の州 | 標準の名前 | 標準の電話番号 | Similarity |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | GA | 7708434125 | CRM-100 | 123 Main St. | GA | Alana Bosh | 770 843 4125 | 0.9 |
| Bosch, Alana | 123 Main St. | ジョージア | 404-854-7736 | CRM-121 | 123 Main St. | GA | Alana Bosch | 404 854 7736 | 1.0 |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 | 1.0 |
4.サバイバーシップ
グループが形成されたら、サバイバーシップによりグループを表すためのマスター レコード ("ゴールデン レコード" とも呼ばれます) が作成されて設定されます。
| ソース名 | ソースの住所 | ソースの州 | ソースの電話番号 | ソース ID | 標準の住所 | 標準の州 | 標準の名前 | 標準の電話番号 | Similarity |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | GA | 7708434125 | CRM-100 | 123 Main St. | GA | Alana Bosh | 770 843 4125 | 0.9 |
| Bosch, Alana | 123 Main St. | ジョージア | 404-854-7736 | CRM-121 | 123 Main St. | GA | Alana Bosch | 404 854 7736 | 1.0 |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 | 1.0 | ||||
| マスター レコード: | 123 Main St. | GA | Alana Bosch | 404 854 7736 |
このマスター レコードは、改善されたソース データおよび系列情報と共に、下流の分析ソリューションに読み込まれ、そこでトランザクション データに関連付けられます。
この例では、MDM の基本的な自動処理を示します。 データ品質ルールを使用して、値を自動的に計算および更新し、データ スチュワードが解決できるように欠損値や無効な値にフラグを設定することもできます。 データ スチュワードは、データの階層的なロールアップの管理など、データの管理を支援します。
統合の複雑さに対する MDM の影響
前に示したように、MDM により、分析ソリューションにデータを統合するときに発生するいくつかの一般的な課題が対処されます。 これには、データ品質の問題の修正、データの標準化とエンリッチ、重複データの合理化が含まれます。 MDM を分析アーキテクチャに組み込むと、統合プロセスのハード コーディングされたロジックが除去され、MDM ソリューションにオフロードされて、データ フローが根本的に変更されます。これにより、統合が大幅に簡素化されます。 次の表は、MDM がある場合とない場合での、統合プロセスの一般的な相違点をまとめたものです。
| 機能 | MDM なし | MDM あり |
|---|---|---|
| データ品質 | 統合プロセスには、データが移動したときにその修正と訂正に役立つ品質ルールと変換が含まれます。 これらのルールの初期の実装と継続的なメンテナンスの両方のために技術リソースが必要になるため、データ統合プロセスの開発と保守が複雑かつ高コストになります。 | MDM ソリューションでは、データ品質のロジックとルールを構成し、適用します。 統合プロセスによってデータ品質の変換が行われることはなく、データは "そのまま" MDM ソリューションに移動されます。 データ統合プロセスの開発と保守は簡単で低コストです。 |
| データの標準化とエンリッチメント | 統合プロセスには、参照とマスターのデータを標準化して整合させるロジックが含まれます。 住所、名前、メール、電話のデータの標準化を実行するために、サードパーティのサービスを使用して統合を開発します。 | 組み込みのルールと、サードパーティのデータ サービスとのすぐに使用できる統合を使用すると、MDM ソリューション内のデータを標準化できるため、統合が簡素化されます。 |
| 重複データの管理 | 統合プロセスでは、既存の一意の識別子に基づいて、アプリケーション内およびアプリケーション間に存在する重複レコードを識別し、グループ化します。 このプロセスでは、システム (SSN やメールなど) 間で識別子を共有し、同一の場合にのみ照合してグループ化します。 さらに高度な方法を使用するには、統合エンジニアリングに多大な投資を行う必要があります。 | 組み込みの機械学習の照合機能によって、システム内およびシステム間で重複するレコードが識別され、グループを表すゴールデン レコードが生成されます。 このプロセスにより、説明可能な結果でのレコードの "あいまい一致" (類似したレコードのグループ化) が可能になります。 ML エンジンが信頼度の高いグループを形成できないシナリオでも、グループが管理されます。 |
| データ スチュワードシップ | データ スチュワードシップのアクティビティは、ERP や CRM などのソース アプリケーションのデータのみを更新します。 通常、分析の実行時に、データの欠落、不備、誤りなどの問題を検出します。 ソース アプリケーションで問題を修正し、その後、次の更新時に分析ソリューションで更新します。 管理する新しい情報があれば、ソース アプリケーションに追加されます。これには、時間とコストがかかります。 | MDM ソリューションにデータ スチュワードシップ機能が組み込まれており、ユーザーがデータにアクセスおよび管理できます。 問題にフラグが設定され、修正するようにデータ スチュワードにプロンプト表示するのが理想的です。 ソリューション内の新しい情報や階層を迅速に構成して、データ スチュワードが管理できるようにします。 |
MDM のユース ケース
MDM には多くのユース ケースがありますが、現実の世界の MDM 実装をほとんどカバーしているユース ケースは少数です。 これらのユース ケースでは 1 つのドメインに重点を置いていますが、そのドメインだけで構築される可能性はありません。 つまり、ここで注目しているユース ケースでも、ほとんどの場合に複数のマスター データ ドメインが含まれます。
Customer 360
分析のための顧客データの統合は、MDM の最も一般的なユース ケースです。 組織では、増加するアプリケーションから顧客データがキャプチャされ、一貫性がなく一致しない重複する顧客データが、アプリケーション内およびアプリケーション間に作成されます。 このような質の低い顧客データを使用すると、最新の分析ソリューションの価値を実現することが難しくなります。 次のような現象が発生します。
- "上得意の顧客はだれか"、"獲得した新規顧客の数" といった基本的なビジネス上の疑問に対する回答を得ることが難しいため、大幅な手作業が必要になります。
- 顧客情報が不足したり不正確になったりするため、データのロールアップやドリルダウンが困難になります。
- 組織やシステムの境界を越えて顧客を一意に識別できないため、システムまたは事業単位をまたがって顧客データを分析できません。
- 入力データの品質が低いため、AI や機械学習からの分析情報の品質が低下します。
Product 360
多くの場合、製品データは、ERP、PLM、eコマースなどの複数のエンタープライズ アプリケーションに分散しています。 結果として、製品の名前、説明、特性などのプロパティの定義に一貫性がない総合的な製品カタログができあがり、理解するのが困難になります。 また、参照データの定義が異なると、この状況がさらに複雑になります。 次のような現象が発生します。
- 製品分析での階層のロールアップやドリルダウンで、代わりのパスをサポートできません。
- 完成品または材料のどちらの在庫でも、手持ちの製品、製品を購入しているベンダー、重複する製品の正確な把握が困難になり、過剰な在庫が発生します。
- 定義が矛盾しているために製品を理論的に説明するのが難しく、分析で情報が欠落したり不正確になったりします。
Reference Data 360
分析のコンテキストでは、参照データは、他のマスター データのセットをさらに説明するのに役立つデータの多数のリストとして存在します。 参照データには、国と地域、通貨、色、サイズ、測定単位のリストを含めることができます。 参照データに一貫性がないと、下流の分析で明らかなエラーにつながります。 次のような現象が発生します。
- 同じ事柄に複数の表現があります。 たとえば、ジョージア州が "GA" および "Georgia" と表されていると、データの一貫した集約やドリルダウンが困難になります。
- システム間で横断的にデータ値を参照できないため、異なるアプリケーション間でデータを集計するのが困難です。 たとえば、赤い色が、ERP システムでは "R" と表され、PLM システムでは "Red" と表されているような場合です。
- データ分類用に決められた参照データ値の違いにより、組織間での数値の照合が困難です。
Finance 360
財務組織は、月単位、四半期単位、年単位の報告書などの重要なアクティビティについて、データに大きく依存しています。 複数の財務と会計のシステムを使用する組織は、多くの場合、複数の総勘定元帳にまたがって財務データを保持しており、これらを統合して財務レポートを作成します。 MDM は、勘定科目、コスト センター、ビジネス エンティティ、その他の財務データ セットを統合ビューにマップして管理するための一元的な場所を提供できます。 次のような現象が発生します。
- 複数のシステムにわたる財務データを統合ビューに集約するのが困難です。
- 財務システムに新しいデータ要素を追加してマッピングするためのプロセスがありません。
- 期末の会計報告の作成が遅れます。
考慮事項
以降の考慮事項には、ワークロードの品質向上に使用できる一連の基本原則である Azure "Well-Architected Framework" の要素が組み込まれています。 詳細については、「Microsoft Azure Well-Architected Framework」を参照してください。
[信頼性]
信頼性により、顧客に確約したことをアプリケーションで確実に満たせるようにします。 詳細については、「信頼性の重要な要素の概要」を参照してください。
Profisee は、Azure Kubernetes Service と Azure SQL Database でネイティブに実行されます。 どちらのサービスにも、高可用性をサポートするためのすぐに使用できる機能が用意されています。
パフォーマンス効率
パフォーマンス効率とは、ユーザーによって行われた要求に合わせて効率的な方法でワークロードをスケーリングできることです。 詳細については、「パフォーマンス効率の柱の概要」を参照してください。
Profisee は、Azure Kubernetes Service と Azure SQL Database でネイティブに実行されます。 必要に応じて、Profisee をスケールアップおよびスケールアウトするように Azure Kubernetes Service を構成できます。 パフォーマンス、スケーラビリティ、コストのバランスを取るために、Azure SQL Database をさまざまな構成にデプロイできます。
セキュリティ
セキュリティは、重要なデータやシステムの意図的な攻撃や悪用に対する保証を提供します。 詳細については、「セキュリティの重要な要素の概要」を参照してください。
Profisee によるユーザーの認証は、OAuth 2.0 認証フローが実装された OpenID Connect を使用して行われます。 ほとんどの組織では、Microsoft Entra ID に対してユーザーを認証するように Profisee を構成します。 このプロセスにより、認証用のエンタープライズ ポリシーが確実に適用および強制されます。
コストの最適化
コストの最適化とは、不要な費用を削減し、運用効率を向上させる方法を検討することです。 詳しくは、コスト最適化の柱の概要に関する記事をご覧ください。
実行コストは、ソフトウェアのライセンスと Azure の使用量で構成されます。 詳細については、Profisee にお問い合わせください。
このシナリオのデプロイ
このシナリオをデプロイするには:
- ARM テンプレートを使用して、Azure に Profisee をデプロイします。
- Azure データ ファクトリを作成します。
- Git リポジトリに接続するように、Azure データ ファクトリを構成します。
- Azure Data Factory Git リポジトリに Profisee のAzure Data Factory テンプレートを追加します。
- テンプレートを使用して新しい Azure Data Factory パイプラインを作成します。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- スニル サバート | プリンシパル プログラム マネージャー
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次のステップ
- Azure Data Factory での REST コピー コネクタの機能について理解します。
- Azureでの Profisee のネイティブな実行の詳細を確認します。
- ARM テンプレートを使用して Azure に Profisee をデプロイする方法を確認します。
- Profisee の Azure Data Factory テンプレートを確認します。