このリファレンス アーキテクチャは、可用性と堅牢な災害復旧インフラストラクチャを実現するために、複数の Azure リージョンで N 層アプリケーションを実行するための一連の実証済みのプラクティスを示しています。
Architecture
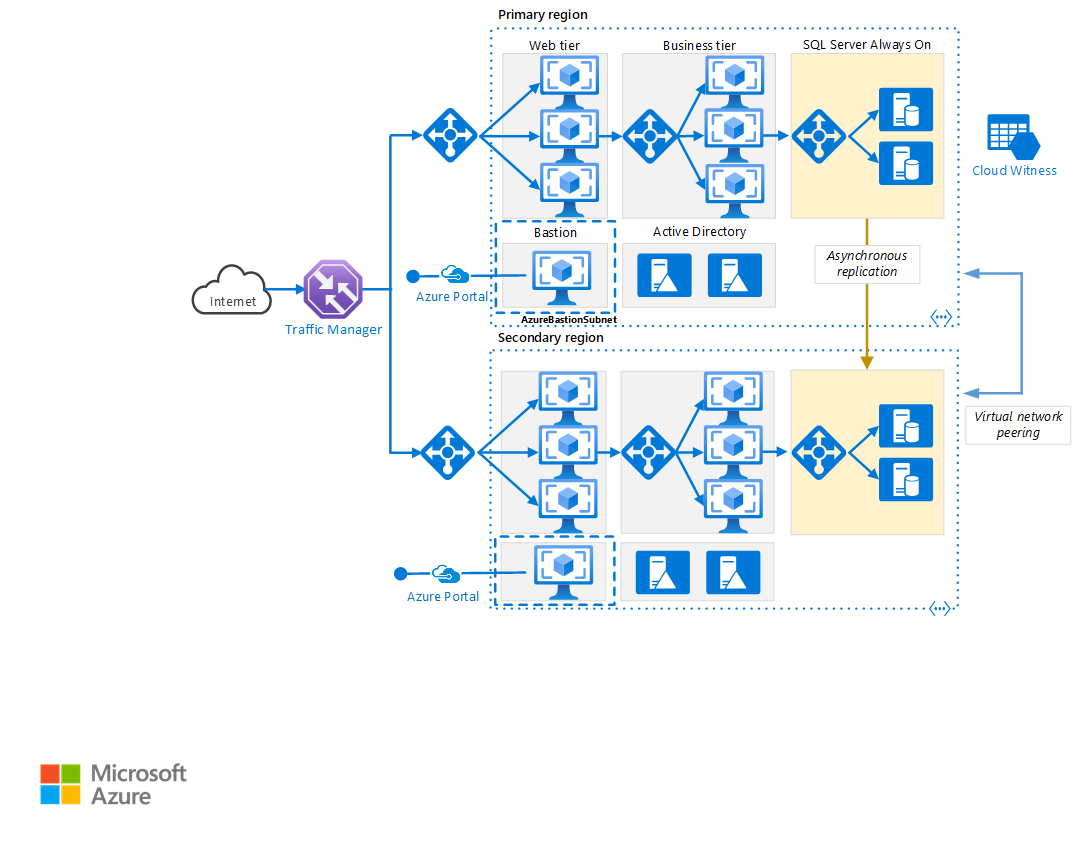
このアーキテクチャの Visio ファイルをダウンロードします。
ワークフロー
プライマリ リージョンとセカンダリ リージョン。 2 つのリージョンを使用して高可用性を実現します。 1 つはプライマリ リージョンであり、 他方のリージョンはフェールオーバー用です。
Azure Traffic Manager。 Traffic Manager では、着信要求がいずれかのリージョンにルーティングされます。 通常の運用中は、プライマリ リージョンに要求をルーティングします。 そのリージョンが使用できなくなった場合、Traffic Manager はセカンダリ リージョンへのフェールオーバーを実行します。 詳細については、「Traffic Manager の構成」を参照してください。
リソース グループ。 プライマリ リージョン、セカンダリ リージョン、Traffic Manager 用に個別のリソース グループを作成します。 この方法により、各リージョンをリソースの 1 つのコレクションとして柔軟に管理できます。 たとえば、片方のリージョンの再デプロイを、他方のリージョンをダウンさせずに実行できます。 リソース グループをリンクして、アプリケーション用のすべてのリソースを一覧表示するクエリを実行できるようにします。
仮想ネットワーク。 リージョンごとに個別の仮想ネットワークを作成します。 アドレス空間が重複していないことを確認してください。
SQL Server Always On 可用性グループ。 SQL Server を使用する場合は、SQL Always On 可用性グループを使用して高可用性を実現することをお勧めします。 両方のリージョンの SQL Server インスタンスを含む単一の可用性グループを作成します。
注意
Azure SQL Database の使用も検討してください。リレーショナル データベースがクラウドサービスとして提供されます。 SQL Database では、可用性グループの構成やフェールオーバーの管理は必要ありません。
仮想ネットワーク ピアリング。 2 つの仮想ネットワークをピアリングし、プライマリ リージョンからセカンダリ リージョンにデータをレプリケートできるようにします。 詳細については、「仮想ネットワーク ピアリング」をご覧ください。
Components
- 可用性セットを使うことで、Azure にデプロイする VM は、クラスター内で切り離された複数のハードウェア ノードに確実に分散されます。 Azure 内でハードウェアまたはソフトウェアの障害が発生した場合、影響を受けるのは VM のサブセットのみで、ソリューション全体は引き続き利用および運用可能です。
- 可用性ゾーンは、データセンターの障害からアプリケーションとデータを保護します。 可用性ゾーンは、Azure リージョン内の切り離された物理的な場所です。 それぞれのゾーンは、独立した電源、冷却手段、ネットワークを備えた 1 つまたは複数のデータセンターで構成されています。
- Azure Traffic Manager は、トラフィックを最適に分散させる DNS ベースのトラフィック ロード バランサーです。 これは世界中の Azure リージョンにまたがるサービスを高可用性と応答性と共に提供します。
- Azure Load Balancer は、定義された規則と正常性プローブに従って受信トラフィックを分散させます。 ロード バランサーは、低遅延と高スループットを実現し、あらゆる TCP アプリケーションと UDP アプリケーションの数百万ものフローにスケールアップします。 このシナリオでは、パブリック ロード バランサーを使って、着信クライアント トラフィックが Web 層に分散されます。 このシナリオでは、内部ロード バランサーを使って、ビジネス層からバックエンド SQL Server クラスターにトラフィックが分散されます。
- Azure Bastion は、プロビジョニングされる仮想ネットワーク内のすべての VM に対して安全な RDP および SSH 接続を提供します。 Azure Bastion を使用すると、RDP または SSH を使用した安全なアクセスを提供しながら、お使いの仮想マシンが RDP または SSH ポートを外部に公開しないように保護されます。
Recommendations
マルチリージョン アーキテクチャは、単一のリージョンにデプロイするよりも高い可用性を提供できます。 地域的な停止がプライマリ リージョンに影響する場合は、Traffic Manager を使用して、セカンダリ リージョンにフェールオーバーできます。 このアーキテクチャは、アプリケーションの個々のサブシステムが失敗した場合にも役立ちます。
リージョン間で高可用性を実現する一般的な方法はいくつかあります。
- アクティブ/パッシブ (ホット スタンバイ)。 トラフィックが片方のリージョンにルーティングされている間、他方のリージョンは、ホット スタンバイ状態で待機します。 ホット スタンバイとは、セカンダリ リージョン内の VM が割り当て済みであり、常に実行されていることを意味します。
- アクティブ/パッシブ (コールド スタンバイ)。 トラフィックが片方のリージョンにルーティングされている間、他方のリージョンは、コールド スタンバイ状態で待機します。 コールド スタンバイとは、セカンダリ リージョン内の VM がフェールオーバーが必要になるまで割り当てられないことを意味します。 この方法のほうが実行コストは低くなりますが、ほとんどの場合、障害発生時にオンラインになるまでの時間が長くなります。
- アクティブ/アクティブ。 両方のリージョンがアクティブであり、要求はそれらの間で負荷分散されます。 片方のリージョンが使用できなくなった場合は、ローテーションから外されます。
この参照アーキテクチャでは、Traffic Manager を使用してフェールオーバーを行うアクティブ/パッシブ (ホット スタンバイ) に焦点を当てています。 ホット スタンバイ用の少数の VM をデプロイした後、必要に応じてスケール アウトできます。
リージョンのペアリング
各 Azure リージョンは、同じ地区内の別のリージョンとペアリングされます。 通常は、同じリージョン ペアからリージョンを選択します (たとえば、米国東部 2 と米国中部)。 これには、次のような利点があります。
- 広範囲にわたる停止が発生した場合は、すべてのペアで、少なくとも 1 つのリージョンの復旧が優先的に実行されます。
- Azure システムの計画的更新は、起こり得るダウンタイムを最小限に抑えるために、ペアになっているリージョンに対して順にロールアウトされます。
- ペアは、データの所在地要件を満たすために同じ地区内に所在します。
ただし、両方のリージョンでアプリケーションに必要なすべての Azure サービスがサポートされていることを確認してください (リージョン別サービスに関する記事を参照してください)。 リージョン ペアの詳細については、「ビジネス継続性とディザスター リカバリー (BCDR):Azure のペアになっているリージョン」をご覧ください。
Traffic Manager の構成
Traffic Manager を構成するときは、次の点を検討してください。
- ルーティング。 Traffic Manager では、複数のルーティング アルゴリズムがサポートされています。 この記事で説明するシナリオでは、"優先度による" ルーティング (旧称 "フェールオーバー" ルーティング) を使用します。 この設定では、プライマリ リージョンが到達不能にならない限り、Traffic Manager はプライマリ リージョンにすべての要求を送信します。 到達不能になった時点で、セカンダリ リージョンに自動的にフェールオーバーします。 フェールオーバーのルーティング方法の構成に関する記事を参照してください。
- 正常性プローブ。 Traffic Manager では、HTTP (または HTTPS) プローブを使用して、各リージョンが使用可能かどうかが監視されます。 プローブは、特定の URL パスの HTTP 200 応答をチェックします。 ベスト プラクティスとして、アプリケーションの全体的な正常性を報告するエンドポイントを作成し、そのエンドポイントを正常性プローブ用に使用します。 これを行わなかった場合、プローブは、アプリケーションの重要な部分で実際には障害が発生しているにもかかわらず、エンドポイントが正常であると報告する可能性があります。 詳細については、「正常性エンドポイントの監視パターン」を参照してください。
Traffic Manager がフェールオーバーを実行すると、クライアントがアプリケーションに到達できない時間が発生します。 この持続時間は、次の要因に影響されます。
- 正常性プローブが、プライマリ リージョンが到達不能になっていることを検出する必要があります。
- DNS サーバーが、IP アドレスのキャッシュされた DNS レコードを更新する必要があります。これは DNS 有効期限 (TTL) に依存します。 TTL の既定値は 300 秒 (5 分) ですが、この値は、Traffic Manager プロファイルを作成するときに構成できます。
詳細については、Traffic Manager の監視に関する記事を参照してください。
Traffic Manager でフェールオーバーを実行する場合は、自動フェールバックを実装するのではなく、手動でフェールバックを実行することをお勧めします。 これを行わなかった場合、リージョン間でアプリケーションが切り替わる状況が発生する可能性があります。 フェールバックする前に、すべてのアプリケーション サブシステムが正常であることを確認します。
Traffic Manager は、既定では自動的にフェールバックします。 この問題が起こらないようにするには、フェールオーバー イベントの後、手動でプライマリ リージョンの優先度を下げます。 たとえば、プライマリ リージョンの優先度は 1、セカンダリ リージョンの優先度は 2 であるとします。 フェールオーバーした後、プライマリ リージョンの優先度を 3 に設定して、自動フェールバックが起こらないにします。 元に戻す準備ができたら、優先度を 1 に更新します。
次の Azure CLI コマンドでは、優先度が更新されます。
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --priority 3
別の方法は、フェールバックの準備ができるまで、エンドポイントを一時的に無効にすることです。
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type azureEndpoints --endpoint-status Disabled
フェールオーバーの原因によっては、リソースをリージョン内に再デプロイする必要があります。 フェールバックする前に、運用準備テストを実行します。 このテストでは、以下のような点を検証する必要があります。
- VM が正しく構成されている (すべての必要なソフトウェアがインストールされていること、IIS が実行されていることなど)。
- アプリケーションのサブシステムが正常である。
- 機能テスト (たとえば、Web 層からデータベース層に到達可能である)。
SQL Server Always On 可用性グループを構成する
Windows Server 2016 より前に、SQL Server Always On 可用性グループではドメイン コントローラーを必要とし、可用性グループ内のすべてのノードが同じ Active Directory (AD) ドメイン内にある必要があります。
可用性グループを構成するには:
各リージョンに少なくとも 2 つのドメイン コントローラーを配置します。
各ドメイン コントローラーに静的 IP アドレスを指定します。
2 つの仮想ネットワークをピアリングし、それらの間で通信できるようにします。
各仮想ネットワークで、DNS サーバーのリストに (両方のリージョンの) ドメイン コントローラーの IP アドレスを追加します。 次の CLI コマンドを使用できます。 詳細については、「DNS サーバーの変更」を参照してください。
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"両方のリージョンの SQL Server インスタンスを含む Windows Server フェールオーバー クラスタリング (WSFC) クラスターを作成します。
プライマリ リージョンとセカンダリ リージョンの SQL Server インスタンスを含む SQL Server Always On 可用性グループを作成します。 手順については、Always On 可用性グループのリモート Azure データセンターへの拡張 (PowerShell)に関する記事を参照してください。
プライマリ レプリカをプライマリ リージョンに配置します。
1 つ以上のセカンダリ レプリカをプライマリ リージョンに配置します。 これらのレプリカを自動フェールオーバーを伴う同期コミット モードを使用するように構成します。
1 つ以上のセカンダリ レプリカをセカンダリ リージョンに配置します。 パフォーマンス上の理由で、"非同期" コミットを使用するようにこれらのレプリカを構成します。 (これを行わなかった場合、すべての T-SQL トランザクションがセカンダリ リージョンへのネットワーク上にラウンド トリップで待機する必要があります)。
注意
非同期コミット レプリカでは、自動フェールオーバーはサポートされていません。
考慮事項
以降の考慮事項には、ワークロードの品質向上に使用できる一連の基本原則である Azure "Well-Architected Framework" の要素が組み込まれています。 詳細については、「Microsoft Azure Well-Architected Framework」を参照してください。
可用性
複雑な N 層アプリケーションでは、アプリケーション全体をセカンダリ リージョンにレプリケートする必要はない場合があります。 代わりに、ビジネス継続性をサポートするために必要な重要なサブシステムのみをレプリケートできます。
Traffic Manager は、システムの障害ポイントになる可能性があります。 Traffic Manager サービスが失敗すると、クライアントは、ダウンタイム中はアプリケーションにアクセスできなくなります。 「Traffic Manager の SLA」を確認して、Traffic Manager の使用だけで高可用性のビジネス要件が満たされるかどうかを確かめてください。 満たされない場合は、フェールバックとして別のトラフィック管理ソリューションを追加することを検討してください。 Azure Traffic Manager サービスで障害が発生した場合は、他のトラフィック管理サービスを参照するように、DNS の CNAME レコードを変更します (この手順は手動で実行する必要があり、DNS の変更が反映されるまでアプリケーションを使用することはできません)。
SQL Server クラスターでは、2 つのフェールオーバー シナリオを考慮する必要があります。
プライマリ リージョン内のすべての SQL Server データベースのレプリカが失敗する。 この失敗は、たとえば地域的な停止中に発生することがあります。 この場合は、Traffic Manager がフロント エンドで自動的にフェールオーバーを実行する場合でも、可用性グループを手動でフェールオーバーする必要があります。 「Perform a Forced Manual Failover of a SQL Server Availability Group」(SQL Server 可用性グループの強制手動フェールオーバーを実行する) の手順に従います。この記事では、SQL Server 2016 で SQL Server Management Studio、Transact-SQL、または PowerShell を使用して強制フェールオーバーを実行する方法が説明されています。
警告
強制フェールオーバーには、データ損失のリスクがあります。 プライマリ リージョンがオンラインに戻ったら、データベースのスナップショットを取得し、tablediff を使用して差異を検出してください。
Traffic Manager がセカンダリ リージョンへのフェールオーバーを実行するが、SQL Server データベースのプライマリ レプリカが引き続き使用可能である。 たとえば SQL Server VM に影響しない障害がフロント エンド層で発生することがあります。 この場合、インターネット トラフィックはセカンダリ リージョンにルーティングされますが、セカンダリ リージョンは引き続きプライマリ レプリカに接続できます。 ただし、SQL Server の接続がリージョンにまたがるため、待機時間が長くなります。 この状況では、次のように手動フェールオーバーを実行する必要があります。
- セカンダリ リージョンの SQL Server データベースのレプリカを一時的に同期コミットに切り替えます。 この手順により、フェールオーバー中にデータの損失が発生しないことが保証されます。
- そのレプリカにフェールオーバーします。
- プライマリ リージョンにフェールバックするときに、設定を非同期コミットに戻します。
管理の容易性
デプロイを更新するときは、一度に 1 つのリージョンを更新することで、アプリケーションの不適切な構成やエラーによってグローバル エラーが発生する機会を減らします。
システムのエラーに対する回復性をテストします。 テストされる一般的な障害シナリオを次に示します。
- VM インスタンスのシャットダウン。
- CPU やメモリなどのリソースへの負荷。
- ネットワークの切断/遅延。
- プロセスのクラッシュ。
- 証明書の期限切れ。
- ハードウェア障害のシミュレート。
- ドメイン コントローラー上の DNS サービスのシャットダウン。
回復時間を測定し、ビジネス要件を満たしていることを確認します。 障害モードの組み合わせもテストします。
コストの最適化
コストの最適化とは、不要な費用を削減し、運用効率を向上させる方法を検討することです。 詳しくは、コスト最適化の柱の概要に関する記事をご覧ください。
コストを見積もるには、Azure 料金計算ツールを使用します。 その他の考慮事項のいくつかを次に示します。
Virtual Machine Scale Sets
Virtual Machine Scale Sets は、Windows VM のすべてのサイズで使用できます。 課金されるのは、デプロイする Azure VM と、使用したその他の基になるインフラストラクチャ リソース (ストレージやネットワークなど) のみです。 Virtual Machine Scale Sets サービスに対する増分料金は発生しません。
単一の VM の価格オプションについては、Windows VM の料金に関するページを参照してください。
[データベースのインポート]
Azure SQL DBaas を選択した場合は、Always On 可用性グループやドメイン コントローラー マシンを構成する必要がないため、コストを節約できます。 単一データベースからマネージド インスタンスまたはエラスティック プールまで、いくつかのデプロイ オプションがあります。 詳細については、Azure SQL の価格に関するページをご覧ください。
SQL Server VM の価格オプションについては、SQL VM の料金に関するページを参照してください。
ロード バランサー
構成された負荷分散およびアウトバウンド規則の数に対してのみ課金されます。 インバウンド NAT 規則は無料です。 規則が構成されていない場合、Standard Load Balancer に対する時間あたりの料金は発生しません。
Traffic Manager の料金
Traffic Manager の課金は、受信された DNS クエリの数に基づいており、1 月あたり 10 億を超えるクエリを受信するサービスには割引が適用されます。 また、監視対象のエンドポイントごとにも課金されます。
詳細については、「Microsoft Azure Well-Architected Framework」のコストのセクションを参照してください。
VNET ピアリングの価格
複数の Azure リージョンを使用する高可用性のデプロイでは、VNET ピアリングが活用されます。 同じリージョン内での VNET ピアリングとグローバル VNET ピアリングでは料金が異なります。
詳細については、「Virtual Network の価格」を参照してください。
DevOps
1 つの Azure Resource Manager テンプレートを使用して、Azure リソースとその依存関係をプロビジョニングします。 同じテンプレートを使用して、プライマリ リージョンとセカンダ リリージョンの両方にリソースをデプロイします。 同じ仮想ネットワーク内のすべてのリソースを含めて、同じ基本ワークロードで分離されるようにします。 すべてのリソースを含むことで、ワークロード固有のリソースを DevOps チームに容易に関連付けられるので、チームはこれらのリソースのあらゆる側面を個別に管理できます。 この分離により、DevOps チームと DevOps Services は、継続的インテグレーションと継続的デリバリー (CI/CD) を実行できます。
また、各種 Azure Resource Manager テンプレートを使用して、それを Azure DevOps Services と統合することで、さまざまな環境を数分でプロビジョニングし、必要なときにのみ、たとえば疑似運用シナリオをレプリケートしたりテスト環境を読み込んだりできるため、コストを節約できます。
Azure Monitor を使用して、インフラストラクチャのパフォーマンスを分析および最適化することを検討してください。仮想マシンにログインせずに、ネットワークの問題を監視および診断できます。 Application Insights は、実際には Azure Monitor のコンポーネントの 1 つであり、ご利用の Azure 環境全体の状態を検証するためのメトリックとログを豊富に提供します。 Azure Monitor は、インフラストラクチャの状態を追跡するのに役立ちます。
アプリケーション コードを支えるコンピューター要素だけでなく、ご自身の特定のデータベースで、データ プラットフォームも監視するようにしてください。アプリケーションのデータ層のパフォーマンスが低いと、深刻な結果を招く可能性があるからです。
アプリケーションが実行されている Azure 環境は、テストの目的で、アプリケーション コードと同じメカニズムを使用してバージョン管理およびデプロイされている必要があるため、DevOps テストパラダイムを使用してテストおよび検証することもできます。
詳細については、Microsoft Azure Well-Architected Framework に関するページのオペレーショナル エクセレンスのセクションを参照してください。
共同作成者
この記事は、Microsoft によって保守されています。 当初の寄稿者は以下のとおりです。
プリンシパル作成者:
- Donnie Trumpower | シニア クラウド ソリューション アーキテクト
パブリックでない LinkedIn プロファイルを表示するには、LinkedIn にサインインします。
次の手順
関連リソース
次のアーキテクチャでは、同じテクノロジのいくつかを使用しています。