Durable Functions のパフォーマンスとスケーリング (Azure Functions)
パフォーマンスとスケーラビリティを最適化するには、Durable Functions 固有のスケーリング特性を理解しておくことが重要です。 この記事では、負荷に基づいてワーカーをスケーリングする方法と、さまざまなパラメーターを調整する方法について説明します。
ワーカーのスケーリング
タスク ハブの概念の基本的な利点は、タスク ハブの作業項目を処理するワーカーの数を継続的に調整できることです。 特に、作業をより迅速に処理する必要がある場合は、アプリケーションにより多くのワーカーを追加 ("スケールアウト") し、ワーカーをビジー状態に保つのに十分な作業がない場合は、ワーカーを削除 ("スケールイン") できます。 タスク ハブが完全にアイドル状態の場合は、"ゼロにスケーリング" することもできます。 ゼロにスケーリングすると、ワーカーはまったく存在しません。スケール コントローラーとストレージのみがアクティブな状態を維持する必要があります。
次の図にこの概念を示します。
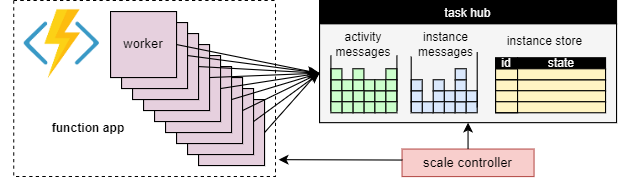
自動スケーリング
従量課金およびエラスティック Premium プランで実行されるすべての Azure Functions と同様に、Durable Functions では、Azure Functions のスケール コントローラーによる自動スケールがサポートされています。 スケール コントローラーは、メッセージとタスクが処理されるまでに待機する必要がある時間を監視します。 これらの待機時間に基づいて、ワーカーを追加または削除するかどうかを決定できます。
Note
Durable Functions 2.0 以降では、エラスティック Premium プランの VNET で保護されたサービス エンドポイント内で実行するように関数アプリを構成できます。 この構成では、Durable Functions のトリガーによってスケール コントローラーではなくスケール要求が開始されます。 詳細については、ランタイム スケールの監視に関する記事を参照してください。
Premium プランでは、自動スケーリングは、アプリケーションで発生している負荷にほぼ比例するワーカーの数 (したがって運用コスト) を維持するのに役立ちます。
CPU 使用率
オーケストレーター関数は、実行が多数の再生で決定論的であることを保証するために 1 つのスレッドで実行されます。 このシングル スレッド実行のため、オーケストレーター関数のスレッドでは、CPU 集約型タスクや I/O を実行したり、何らかの理由でブロックしたりしないことが重要です。 I/O、ブロック、または複数のスレッドが必要になる可能性がある作業は、アクティビティ関数に移動する必要があります。
アクティビティ関数は、通常のキューによってトリガーされる関数とまったく同じように動作します。 アクティビティ関数では、I/O を安全に実行し、CPU 集約型操作を実行できます。また、複数のスレッドを使用することもできます。 アクティビティ トリガーはステートレスであるため、無制限の VM に対して自由にスケールアウトできます。
エンティティ関数も 1 つのスレッドで実行され、操作は一度に 1 つずつ処理されます。 ただし、エンティティ関数には、実行可能なコードの種類に関する制限はありません。
関数のタイムアウト
アクティビティ、オーケストレーター、エンティティ関数は、すべての Azure Functions と同じ関数のタイムアウトの適用を受けます。 一般的な規則として、Durable Functions は、アプリケーション コードによってスローされるハンドルされない例外と同じ方法で関数のタイムアウトを処理します。
たとえば、アクティビティがタイムアウトになる場合、関数の実行はエラーとして記録され、オーケストレーターに通知され、他の例外と同様にタイムアウトが処理されます。つまり、呼び出しで指定されている場合は再試行が行われます。または、例外ハンドラーが実行される可能性があります。
エンティティ操作のバッチ処理
パフォーマンスを向上させ、コストを削減するために、1 つの作業項目でエンティティ操作のバッチ全体を実行できます。 従量課金プランでは、各バッチは 1 つの関数実行として課金されます。
既定では、最大バッチ サイズは従量課金プランの場合で 50、その他のすべてのプランの場合で 5000 です。 host.json ファイルでも最大バッチ サイズを構成できます。 最大バッチ サイズが 1 の場合、バッチ処理は実質的に無効になります。
Note
個別のエンティティ操作の実行に時間がかかる場合は、関数のタイムアウトのリスクを軽減するために最大バッチ サイズを制限すると便利な場合があります。これは特に従量課金プランに当てはまります。
インスタンスのキャッシュ
一般に、オーケストレーション作業項目を処理するには、ワーカーが次の両方を行う必要があります
- オーケストレーション履歴をフェッチする。
- 履歴を使用してオーケストレーター コードを再生する。
同じワーカーが同じオーケストレーションに対して複数の作業項目を処理している場合、ストレージ プロバイダーはワーカーのメモリに履歴をキャッシュすることでこのプロセスを最適化できます。これにより、最初の手順は不要になります。 さらに、実行途中のオーケストレーターをキャッシュできるため、2 番目のステップである履歴の再生も不要になります。
キャッシュの一般的な効果は、基になるストレージ サービスに対する I/O の削減と、スループットと待機時間の全体的な向上です。 一方、キャッシュを使用すると、ワーカーのメモリ消費量が増加します。
インスタンス キャッシュは現在、Azure Storage プロバイダーと Netherite ストレージ プロバイダーによってサポートされています。 次の表で比較を示します。
| Azure Storage プロバイダー | Netherite ストレージ プロバイダー | MSSQL ストレージ プロバイダー | |
|---|---|---|---|
| インスタンスのキャッシュ | サポートされています (.NET インプロセス ワーカーのみ) |
サポートされています | サポートされていません |
| 既定の設定 | 無効 | Enabled | 該当なし |
| メカニズム | 延長セッション | インスタンス キャッシュ | 該当なし |
| ドキュメント | 「延長セッション」を参照してください | 「インスタンス キャッシュ」を参照してください | 該当なし |
ヒント
キャッシュを使用すると、履歴を再生する頻度を減らすことができますが、再生を完全に排除することはできません。 オーケストレーターを開発するときは、キャッシュを無効にする構成でテストすることを強くお勧めします。 強制再生動作は、開発時にオーケストレーター関数コードの制約違反を検出する場合に役立つ可能性があります。
キャッシュ メカニズムの比較
プロバイダーは、キャッシュを実装するためにさまざまなメカニズムを使用し、キャッシュ動作を構成するためのさまざまなパラメーターを提供します。
- Azure Storage プロバイダーによって使用される拡張セッションは、実行途中のオーケストレーターをしばらくアイドル状態になるまでメモリに保持します。 このメカニズムを制御するパラメーターは
extendedSessionsEnabledとextendedSessionIdleTimeoutInSecondsです。 詳細については、Azure Storage プロバイダーのドキュメントの「拡張セッション」セクションを参照してください。
注意
拡張セッションは、.NET インプロセス ワーカーでのみサポートされます。
- Netherite ストレージ プロバイダーによって使用されるインスタンス キャッシュは、使用されたメモリの合計を追跡しながら、履歴を含むすべてのインスタンスの状態をワーカーのメモリに保持します。 キャッシュ サイズが
InstanceCacheSizeMBによって構成された制限を超えた場合は、最近使用したインスタンス データが削除されます。CacheOrchestrationCursorsが true に設定されている場合、キャッシュには実行中のオーケストレーターとインスタンスの状態も格納されます。 詳細については、Netherite ストレージ プロバイダーのドキュメントの「インスタンス キャッシュ」を参照してください。
注意
インスタンス キャッシュはすべての言語 SDK で機能しますが、CacheOrchestrationCursors オプションは .NET インプロセス ワーカーでのみ使用できます。
コンカレンシーのスロットル
1 つのワーカー インスタンスで複数の作業項目を同時に実行できます。 これにより、並列処理が向上し、ワーカーをより効率的に利用できるようになります。 ただし、ワーカーが同時に処理しようとする作業項目が多すぎると、CPU 負荷、ネットワーク接続の数、使用可能なメモリなど、使用可能なリソースが使い果たされる可能性があります。
個々のワーカーがオーバーコミットしないようにするには、インスタンスごとのコンカレンシーを抑えることが必要な場合があります。 各ワーカーで同時に実行される関数の数を制限することで、そのワーカーのリソース制限を使い果たすことを回避できます。
注意
コンカレンシーのスロットルはローカルでのみ適用され、ワーカーごとに現在処理されている内容が制限されます。 したがって、これらのスロットルによってシステムのスループットの合計は制限されません。
ヒント
場合によっては、ワーカーごとのコンカレンシーを抑えると、システムの合計スループットが実際に "向上" する可能性があります。 これは、各ワーカーが受け取る作業が少なくなり、キューに追いつくためにスケール コントローラーによってワーカーが追加され、合計スループットが向上する場合に発生する可能性があります。
スロットルの構成
アクティビティ、オーケストレーター、およびエンティティ関数のコンカレンシーの制限は、host.json ファイルで構成できます。 関連する設定は、アクティビティ関数の場合は durableTask/maxConcurrentActivityFunctions、オーケストレーターおよびエンティティ関数の場合は durableTask/maxConcurrentOrchestratorFunctions です。 これらの設定は、単一のワーカーのメモリに同時に読み込むことができるオーケストレーター、エンティティ、またはアクティビティの関数の最大数を制御します。
注意
オーケストレーションとエンティティは、イベントまたは操作をアクティブに処理しているとき、またはインスタンス キャッシュが有効になっている場合にのみ、メモリに読み込まれます。 これらは、ロジックを実行して待機 (すなわち、オーケストレーター関数コードで await (C#) または yield (JavaScript、Python) ステートメントを実行) した後、メモリからアンロードできます。 メモリからアンロードされたオーケストレーションとエンティティは、maxConcurrentOrchestratorFunctions スロットルにカウントされません。 無数のオーケストレーションまたはエンティティが "実行中" 状態にある場合でも、アクティブ メモリに読み込まれるとき、スロットルの上限までしかカウントされません。 アクティビティ関数をスケジュールするオーケストレーションも同様に、そのオーケストレーションがアクティビティの実行が完了するのを待機している場合はスロットルにカウントされません。
Functions 2.0
{
"extensions": {
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
}
Functions 1.x
{
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
言語ランタイムに関する考慮事項
選択する言語ランタイムによって、関数に対して厳格なコンカレンシー制限が課される場合があります。 たとえば、Python または PowerShell で記述された Durable Function アプリでは、1 つの VM 上で一度に 1 つの関数の実行のみがサポートされるといったことが考えられます。 慎重に検討しないと、これによって重大なパフォーマンスの問題が生じるおそれがあります。 たとえば、オーケストレーターが 10 のアクティビティにファンアウトしていても、言語ランタイムでコンカレンシーが 1 つの関数だけに制限されている場合、10 のアクティビティ関数のうち 9 つは実行の機会を待って停止することになります。 さらに、これら 9 つの停止状態のアクティビティは、Durable Functions ランタイムによって既にメモリに読み込まれているため、他のワーカーに負荷分散することができません。 これは、アクティビティ関数の実行時間が長い場合は特に問題になります。
使用している言語ランタイムでコンカレンシーに制限が課されている場合は、言語ランタイムのコンカレンシー設定と一致するように Durable Functions のコンカレンシー設定を更新する必要があります。 これにより、Durable Functions ランタイムでは、言語ランタイムで許可されている数より多くの関数を同時に実行しようとしないため、保留中のアクティビティを他の VM に負荷分散することができます。 たとえば、コンカレンシーを 4 つの関数に制限する Python アプリがある場合 (1 つの言語ワーカー プロセスで 4 つのスレッド、または 4 つの言語ワーカー プロセスで 1 つのスレッドのみを使用して構成されているなどの場合)、maxConcurrentOrchestratorFunctions と maxConcurrentActivityFunctions の両方を 4 に構成する必要があります。
Python の詳細とパフォーマンスに関する推奨事項については、「Azure Functions で Python アプリのスループット パフォーマンスを向上させる」を参照してください。 この Python 開発者向けリファレンス ドキュメントに記載されている手法は、Durable Functions のパフォーマンスとスケーラビリティに大きな影響を与える場合があります。
[パーティション数]
一部のストレージ プロバイダーでは、"パーティション分割" メカニズムを使用し、partitionCount パラメーターを指定できます。
パーティション分割を使用する場合、ワーカーは個々の作業項目に対して直接競合することはありません。 代わりに、作業項目は最初に partitionCount パーティションにグループ化されます。 これらのパーティションはワーカーに割り当てられます。 このパーティション分割された負荷分散アプローチは、必要なストレージ アクセスの合計数を減らすのに役立ちます。 また、インスタンス キャッシュを有効にすることもできます。さらに、同じインスタンスのすべての作業項目が同じワーカーによって処理される "アフィニティ" が作成されるため、ローカリティが向上します。
注意
ほとんどの partitionCount ワーカーがパーティション分割されたキューから作業項目を処理できるため、パーティション分割ではスケールアウトが制限されます。
次の表は、各ストレージ プロバイダーについて、パーティション分割されているキュー、および partitionCount パラメーターの許容範囲と既定値を示しています。
| Azure Storage プロバイダー | Netherite ストレージ プロバイダー | MSSQL ストレージ プロバイダー | |
|---|---|---|---|
| インスタンス メッセージ | Partitioned | Partitioned | パーティション分割されていません |
| アクティビティ メッセージ | パーティション分割されていません | Partitioned | パーティション分割されていません |
既定値 partitionCount |
4 | 12 | 該当なし |
最大値 partitionCount |
16 | 32 | 該当なし |
| ドキュメント | 「オーケストレーターのスケールアウト」を参照してください | 「パーティション数に関する考慮事項」を参照してください | 該当なし |
警告
タスク ハブが作成された後、パーティション数を変更できなくなる可能性があります。 したがって、タスク ハブ インスタンスの将来のスケールアウト要件に対応するために十分に大きい値に設定することをお勧めします。
パーティション数の構成
partitionCount パラメーターは host.json ファイルで指定できます。 次の例の host.json スニペットを使うと、durableTask/storageProvider/partitionCount プロパティ (または Durable Functions 1.x の durableTask/partitionCount) は 3 に設定されます。
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
呼び出しの待機時間を最小限に抑えるための考慮事項
通常の状況では、(アクティビティ、オーケストレーター、エンティティなどへの) 呼び出し要求は迅速に処理する必要があります。 ただし、呼び出し要求の最長待機時間は、App Service プランのスケール動作の種類、コンカレンシー設定、アプリケーションのバックログのサイズなどの要因によって変わるため、保証はありません。 そのため、アプリケーションのテール待機時間を測定して最適化するために、ストレス テストに投資することをお勧めします。
パフォーマンスの目標
運用アプリケーションに Durable Functions を使用する場合は、計画プロセスの早期にパフォーマンス要件を検討することが重要です。 基本的な使用シナリオには、次のものがあります。
- アクティビティの順次実行: このシナリオでは、一連のアクティビティ関数を順次実行するオーケストレーター関数を記述します。 これは、関数チェーンのサンプルに最も似ています。
- アクティビティの並列実行: このシナリオでは、ファンアウト/ファンイン パターンを使用して多数のアクティビティ関数を並列実行するオーケストレーター関数を記述します。
- 並列応答処理: このシナリオは、ファンアウト/ファンイン パターンの後半部分です。 ファンインのパフォーマンスが重視されます。 ファンアウトとは異なり、ファンインは 1 つのオーケストレーター関数インスタンスによって実行されるため、ファンインを実行できる VM は 1 台だけであることに注意してください。
- 外部イベント処理: このシナリオは、一度に 1 つの外部イベントを待機する単一のオーケストレーター関数インスタンスを表します。
- エンティティ操作の処理: このシナリオでは、"単一" のカウンター エンティティで操作の一定のストリームを処理する速度をテストします。
これらのシナリオのスループットの数値は、ストレージ プロバイダーのそれぞれのドキュメントで提供します。 特に次の点に違いがあります。
- Azure Storage プロバイダーについては、「パフォーマンスの目標」を参照してください。
- Netherite ストレージ プロバイダーについては、「基本的なシナリオ」を参照してください。
- MSSQL ストレージ プロバイダーについては、「オーケストレーション スループット ベンチマーク」を参照してください。
ヒント
ファンアウトとは異なり、ファンイン操作は 1 台の VM に制限されます。 アプリケーションでファンアウト/ファンイン パターンを使用しており、ファンインのパフォーマンスを懸念している場合は、アクティビティ関数のファンアウトを複数のサブオーケストレーションに分けることを検討してください。