Azure Cosmos DB Python SDK のパフォーマンスに関するヒント
適用対象: ![]() NoSQL
NoSQL
重要
この記事のパフォーマンスに関するヒントは、Azure Cosmos DB Python SDK のみを対象としています。 詳細については、Azure Cosmos DB Python SDK の Readmeリリース ノート、パッケージ (PyPI)、パッケージ (Conda)、トラブルシューティング ガイドを参照してください。
Azure Cosmos DB は、高速で柔軟性に優れた分散データベースです。待機時間とスループットが保証されており、シームレスにスケーリングできます。 Azure Cosmos DB でデータベースをスケーリングするために、アーキテクチャを大きく変更したり、複雑なコードを記述したりする必要はありません。 スケールアップとスケールダウンは、API 呼び出しか SDK メソッド呼び出しを 1 回行うだけで簡単に実行できます。 ただし、Azure Cosmos DB にはネットワーク呼び出しによってアクセスするため、Azure Cosmos DB Python SDK を使用するときに最高のパフォーマンスを実現するために、クライアント側の最適化を行うことができます。
データベースのパフォーマンスを向上させる場合は、以下のオプションを検討してください。
ネットワーク
- パフォーマンスを確保するために同じ Azure リージョン内にクライアントを併置する
可能であれば、Azure Cosmos DB を呼び出すアプリケーションを Azure Cosmos DB データベースと同じリージョンに配置します。 おおよその比較では、Azure Cosmos DB の呼び出しは、同じリージョン内であれば 1 から 2 ミリ秒以内で完了するのに対し、米国西部と米国東部の間では待ち時間が 50 ミリ秒より長くなります。 要求がクライアントから Azure データセンターの境界まで流れるときに使用されるルートに応じて、この待機時間が要求ごとに異なる可能性があります。 最短の待機時間は、プロビジョニングされた Azure Cosmos DB エンドポイントと同じ Azure リージョン内に呼び出し元アプリケーションを配置することによって実現されます。 使用可能なリージョンの一覧については、「 Azure のリージョン」を参照してください。
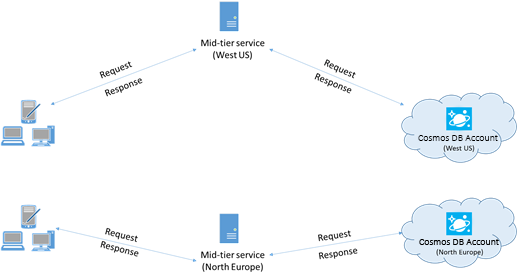
マルチリージョンの Azure Cosmos DB アカウントとやり取りするアプリでは、併置されたリージョンに要求が確実に送信されるように、優先される場所を構成する必要があります。
高速ネットワークを有効にして待機時間と CPU ジッターを削減する
パフォーマンスを最大限に高める(待機時間を短縮し、CPU ジッターを削減する) ために、手順に従って Windows (選んで手順を参照) または Linux (選んで手順を参照) の Azure VM で高速ネットワークを有効にすることをおすすめします。
高速ネットワークを使用しない場合、Azure VM と他の Azure リソース間を通過する IO は、VM とそのネットワーク カードの間にあるホストと仮想スイッチを介して不必要にルーティングされる可能性があります。 データパスにインラインでホストと仮想スイッチがあると、通信チャネルで待機時間とジッターが増加するだけでなく、VM から CPU サイクルが奪われます。 高速ネットワークを使用すると、VM は中継なしで NIC と直接やり取りします。ホストと仮想スイッチによって処理されていたネットワーク ポリシーの詳細は、NIC のハードウェアで処理されるようになり、ホストと仮想スイッチはバイパスされます。 通常、高速ネットワークを有効にすると、待機時間の短縮とスループットの向上だけでなく、より "一貫した" 待機時間と CPU 使用率の削減が期待できます。
制限事項: 高速ネットワークは、VM の OS でサポートされている必要があり、VM が停止され、割り当てが解除されている場合にのみ有効にすることができます。 Azure Resource Manager を使用して VM をデプロイすることはできません。 App Service では高速ネットワークが有効になっていません。
詳細については、Windows および Linux の手順を参照してください。
SDK の使用
- 最新の SDK をインストールする
Azure Cosmos DB SDK は、最適なパフォーマンスを提供するために頻繁に改善されています。 Azure Cosmos DB SDK リリース ノートを参照して、最新の SDK を判別し、改善点を確認してください。
- アプリケーションの有効期間中はシングルトン Azure Cosmos DB クライアントを使用します
各 Azure Cosmos DB クライアント インスタンスはスレッドセーフであり、効率的な接続管理とアドレスのキャッシュが実行されます。 Azure Cosmos DB クライアントによる効率的な接続管理とパフォーマンスの向上を実現するために、アプリケーションの有効期間中は、Azure Cosmos DB クライアントの単一のインスタンスを使用することをお勧めします。
- タイムアウトと再試行の構成を調整する
タイムアウト構成と再試行ポリシーは、アプリケーションのニーズに基づいてカスタマイズできます。 カスタマイズ可能な構成の完全な一覧を取得するには、タイムアウトと再試行の構成に関するドキュメントを参照してください。
- アプリケーションに必要な最低の整合性レベルを使用する
CosmosClient を作成するときに、クライアントの作成時に何も指定されていない場合は、アカウント レベルの整合性が使用されます。 整合性レベルの詳細については、整合性レベルに関するドキュメントを参照してください。
- クライアント ワークロードをスケールアウトする
高いスループット レベルでテストを行っている場合、コンピューターが CPU 使用率またはネットワーク使用率の上限に達したことでクライアント アプリケーションがボトルネックになることがあります。 この状態に達しても、クライアント アプリケーションを複数のサーバーにスケールアウトすることで引き続き同じ Azure Cosmos DB アカウントで対応できます。
低待機時間を維持するには、経験則として、特定のサーバーで CPU 使用率が 50% を超えないようにします。
- OS の開かれるファイルのリソース制限
Red Hat などの一部の Linux システムには、開かれるファイルの数、したがって合計接続数に上限があります。 現在の制限を確認するには、次のコマンドを実行します。
ulimit -a
構成されている接続プール サイズおよび OS によって開かれる他のファイルのために十分なスペースがあるよう、開かれるファイル (nofile) の値は十分な大きさである必要があります。 大きい接続プール サイズに対応できるように変更できます。
limits.conf ファイルを開きます。
vim /etc/security/limits.conf
次の行を追加または変更します。
* - nofile 100000
クエリ操作
クエリ操作については、クエリ パフォーマンスのヒントに関するページを参照してください。
インデックス作成ポリシー
- インデックス作成から未使用のパスを除外して書き込みを高速化する
Azure Cosmos DB のインデックス作成ポリシーでは、パスのインデックス作成 (setIncludedPaths および setExcludedPaths) を使って、インデックス作成に含める/除外するドキュメント パスを指定できます。 インデックス作成コストはインデックス付きの一意のパスの数に直接関係するため、パスのインデックス作成を使用すると、クエリ パターンが事前にわかっているシナリオで書き込みパフォーマンスが向上し、インデックス ストレージを削減できます。 たとえば、次のコードは、ワイルドカード "*" を使用して、ドキュメントのセクション全体 (サブツリーとも呼ばれる) をインデックス作成から追加および除外する方法を示しています。
container_id = "excluded_path_container"
indexing_policy = {
"includedPaths" : [ {'path' : "/*"} ],
"excludedPaths" : [ {'path' : "/non_indexed_content/*"} ]
}
db.create_container(
id=container_id,
indexing_policy=indexing_policy,
partition_key=PartitionKey(path="/pk"))
詳細については、Azure Cosmos DB インデックス作成ポリシーに関するページをご覧ください。
スループット
- 測定と調整によって 1 秒あたりの要求ユニットの使用量を削減する
Azure Cosmos DB には、UDF、ストアド プロシージャ、トリガーを使ったリレーショナル クエリや階層クエリなど、さまざまなデータベース操作が用意されています。これらの操作はすべて、データベース コレクション内のドキュメントに対して実行できます。 これらの操作のそれぞれに関連付けられたコストは、操作を完了するために必要な CPU、IO、およびメモリに応じて異なります。 ハードウェア リソースの管理について考える代わりに、各種のデータベース操作を実行しアプリケーション要求を処理するのに必要なリソースに関する単一の測定単位として要求単位 (RU) を考えることができます。
コンテナーごとに設定された要求ユニットの数に基づいて、スループットをプロビジョニングします。 要求単位の消費は、1 秒あたりのレートとして評価されます。 コンテナーのプロビジョニング済み要求ユニット レートを超過したアプリケーションは、レートがそのコンテナーにプロビジョニングされているレベルを下回るまで制限されます。 アプリケーションでより高いスループットが必要になった場合は、追加の要求ユニットをプロビジョニングしてスループットを増やすことができます。
クエリの複雑さは、操作で消費される要求ユニット数に影響します。 述語の数、述語の特性、UDF 数、ソース データ セットのサイズのすべてがクエリ操作のコストに影響します。
操作 (作成、更新、または削除) のオーバーヘッドを測定するには、x-ms-request-charge ヘッダーを調べて、これらの操作で使われる要求ユニット数を測定します。
document_definition = {
'id': 'document',
'key': 'value',
'pk': 'pk'
}
document = container.create_item(
body=document_definition,
)
print("Request charge is : ", container.client_connection.last_response_headers['x-ms-request-charge'])
このヘッダーで返される要求の使用量は、プロビジョニングしたスループットの一部です。 たとえば、2000 RU/秒がプロビジョニングされていて、上記のクエリが 1 KB のドキュメントを 1000 個返した場合、この操作のコストは 1000 になります。 そのため、後続の要求をレート制限する前に、サーバーは 1 秒以内にこのような要求を 2 つだけ受け付けます。 詳細については、要求ユニットに関する記事および要求ユニット計算ツールのページを参照してください。
- レート制限と大きすぎる要求レートに対処する
クライアントがアカウントの予約済みスループットを超えようとしても、サーバーでパフォーマンスの低下が発生することはなく、予約済みのレベルを超えてスループット容量が使用されることもありません。 サーバーはいち早く RequestRateTooLarge (HTTP 状態コード 429) で要求を終了させ、要求を再試行するまでにユーザーが待機しなければならない時間 (ミリ秒) を示す x-ms-retry-after-ms ヘッダーを返します。
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK はすべてこの応答を暗黙的にキャッチし、サーバーが指定した retry-after ヘッダーを優先して要求を再試行します。 アカウントに複数のクライアントが同時アクセスしている状況でなければ、次回の再試行は成功します。
複数のクライアントが常に要求レートを上回った状態で累積的に動作している場合、現在クライアントによって内部的に 9 に設定されている既定の再試行回数では不十分な可能性があります。この場合、クライアントでは状態コード 429 を含む CosmosHttpResponseError をアプリケーションにスローします。 既定の再試行回数は、retry_total 構成をクライアントに渡すと変更できます。 既定では、要求レートを超えて要求が続行されている場合に、30 秒の累積待ち時間を過ぎると、状態コードが 429 の CosmosHttpResponseError が返されます。 これは、現在の再試行回数が最大再試行回数 (既定値の 9 またはユーザー定義の値) より少ない場合でも発生します。
自動再試行動作により、ほとんどのアプリケーションの回復性とユーザービリティが向上しますが、パフォーマンス ベンチマークの実行時 (特に待機時間の測定時) に問題が生じることがあります。 実験でサーバー スロットルが発生し、クライアント SDK によって警告なしに再試行が行われると、クライアントが監視する待機時間が急増します。 パフォーマンスの実験中に待機時間が急増するのを回避するには、各操作で返される使用量を測定し、予約済みの要求レートを下回った状態で要求が行われていることを確認します。 詳細については、 要求ユニットに関する記事を参照してください。
- スループットを向上させるためにサイズの小さいドキュメントに合わせて設計する
特定の操作の要求の使用量 (要求処理コスト) は、ドキュメントのサイズに直接関係します。 サイズの大きいドキュメントの操作は、サイズの小さいドキュメントの操作よりもコストがかかります。 項目のサイズを最大 1 KB 程度にするようにアプリケーションとワークフローを設計するのが理想的です。 待機時間の影響を受けやすいアプリケーションでは、サイズの大きい項目は避ける必要があります。数 MB のドキュメントはアプリケーションの速度を低下させます。
次のステップ
スケーリングと高パフォーマンスのためのアプリケーションの設計について詳しくは、「Azure Cosmos DB でのパーティション分割とスケーリング」をご覧ください。
Azure Cosmos DB への移行のための容量計画を実行しようとしていますか? 容量計画のために、既存のデータベース クラスターに関する情報を使用できます。
- 既存のデータベース クラスター内の仮想コアとサーバーの数のみがわかっている場合は、仮想コアまたは vCPU を使用した要求ユニットの見積もりに関するページを参照してください
- 現在のデータベース ワークロードに対する通常の要求レートがわかっている場合は、Azure Cosmos DB Capacity Planner を使用した要求ユニットの見積もりに関するページを参照してください