変更データ キャプチャ (CDC) を使用して Azure SQL Managed Instance から Azure Storage へのデータの増分読み込みを行う
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
このチュートリアルでは、ソース Azure SQL Managed Instance データベースの変更データ キャプチャ (CDC) 情報に基づいて、差分データを Azure Blob Storage に読み込むパイプラインを使用して Azure データ ファクトリを作成します。
このチュートリアルでは、以下の手順を実行します。
- ソース データ ストアを準備します。
- データ ファクトリを作成します。
- リンクされたサービスを作成します。
- ソース データセットとシンク データセットを作成します。
- パイプラインを作成、デバッグ、実行して、変更されたデータを確認します
- ソース テーブルのデータを変更します
- 完全な増分コピー パイプラインを完成させ、実行して監視します
概要
Azure SQL Managed Instances (MI) や SQL Server などのデータ ストアでサポートされる変更データ キャプチャ テクノロジを使用して、変更されたデータを識別できます。 このチュートリアルでは、Azure Data Factory と SQL 変更データ キャプチャ テクノロジを使用して、Azure SQL Managed Instance から Azure Blob Storage に差分データの増分読み込みを行う方法について説明します。 SQL 変更データ キャプチャ テクノロジに関するより具体的な情報については、SQL Server での変更データ キャプチャに関するページを参照してください。
エンド ツー エンド ワークフロー
ここでは、変更データ キャプチャ テクノロジを使用してデータの増分読み込みを行う一般的なエンドツーエンドのワークフロー ステップを取り上げます。
Note
Azure SQL MI と SQL Server のどちらでも、変更データ キャプチャ テクノロジがサポートされています。 このチュートリアルでは、Azure SQL Managed Instance をソース データ ストアとして使用します。 オンプレミスの SQL Server を使用してもかまいません。
ソリューションの概略
このチュートリアルでは、次の操作を実行するパイプラインを作成します。
- SQL Database CDC テーブル内の変更されたレコードの数をカウントして IF 条件アクティビティに渡す検索アクティビティを作成します。
- 変更されたレコードがあるかどうかを調べて、ある場合はコピー アクティビティを呼び出す If 条件を作成します。
- 挿入、更新、削除されたデータを CDC テーブルから Azure Blob Storage にコピーするコピー アクティビティを作成します。
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
前提条件
- Azure SQL Managed Instance。 ソース データ ストアとして使うデータベースです。 Azure SQL Managed Instance がない場合は、Azure SQL Database Managed Instance の作成に関する記事に書かれている手順を参照して作成してください。
- Azure Storage アカウント。 シンク データ ストアとして使用する BLOB ストレージです。 Azure ストレージ アカウントがない場合、ストレージ アカウントの作成手順については、「ストレージ アカウントの作成」を参照してください。 raw という名前のコンテナーを作成します。
Azure SQL Database にデータ ソース テーブルを作成する
SQL Server Management Studio を起動し、Azure SQL Managed Instance サーバーに接続します。
サーバー エクスプローラーで目的のデータベースを右クリックして [新しいクエリ] を選択します。
Azure SQL Managed Instance データベースに対して次の SQL コマンドを実行し、ソース データ ストアとして
customersという名前のテーブルを作成します。create table customers ( customer_id int, first_name varchar(50), last_name varchar(50), email varchar(100), city varchar(50), CONSTRAINT "PK_Customers" PRIMARY KEY CLUSTERED ("customer_id") );次の SQL クエリを実行して、データベースとソース テーブル (customers) で変更データ キャプチャ機構を有効にします。
Note
- <your source schema name> は、customers テーブルが含まれる Azure SQL MI のスキーマに置き換えます。
- 変更データ キャプチャでは、追跡対象テーブルを変更するトランザクションの一部としては何も行われません。 代わりに、挿入、更新、削除の各操作がトランザクション ログに書き込まれます。 変更テーブルに格納されるデータは、定期的かつ体系的にクリーンアップしないと、増大して管理しきれなくなります。 詳細については、「データベースでの変更データ キャプチャの有効化」を参照してください
EXEC sys.sp_cdc_enable_db EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 1次のコマンドを実行して、customers テーブルにデータを挿入します。
insert into customers (customer_id, first_name, last_name, email, city) values (1, 'Chevy', 'Leward', 'cleward0@mapy.cz', 'Reading'), (2, 'Sayre', 'Ateggart', 'sateggart1@nih.gov', 'Portsmouth'), (3, 'Nathalia', 'Seckom', 'nseckom2@blogger.com', 'Portsmouth');Note
変更データ キャプチャを有効にする前のテーブルに対する履歴変更はキャプチャされません。
Data Factory の作成
使うデータ ファクトリがまだない場合は、記事「クイック スタート: Azure portal を使用してデータ ファクトリを作成する」の手順に従って作成します。
リンクされたサービスを作成します
データ ストアおよびコンピューティング サービスをデータ ファクトリにリンクするには、リンクされたサービスをデータ ファクトリに作成します。 このセクションでは、Azure ストレージ アカウントと Azure SQL MI に対するリンクされたサービスを作成します。
Azure Storage のリンクされたサービスを作成する
この手順では、Azure ストレージ アカウントをデータ ファクトリにリンクします。
[接続] をクリックし、 [+ 新規] をクリックします。

[New Linked Service](新しいリンクされたサービス) ウィンドウで [Azure Blob Storage] を選択し、 [続行] をクリックします。
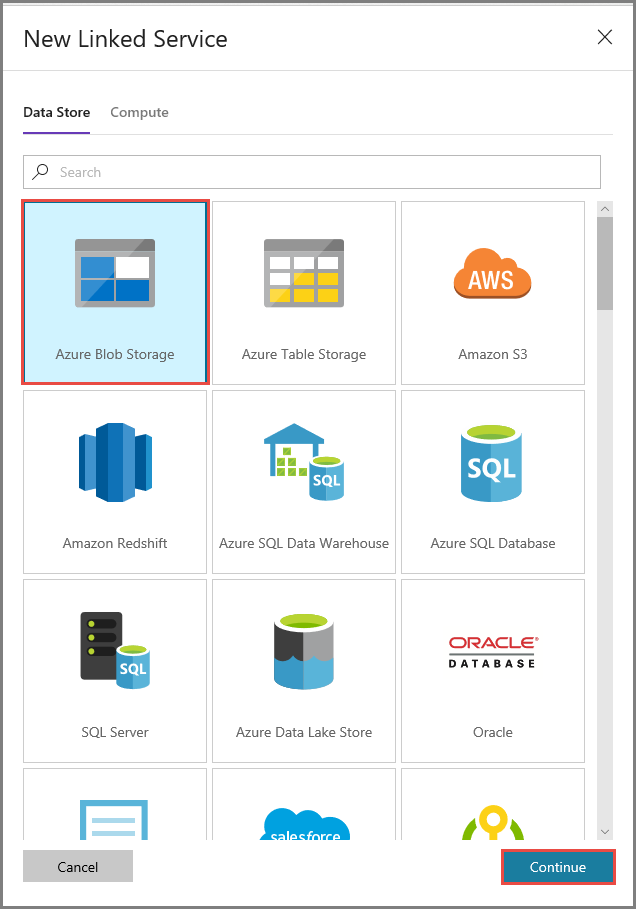
[New Linked Service](新しいリンクされたサービス) ウィンドウで、次の手順を行います。
- [名前] に「AzureStorageLinkedService」と入力します。
- [ストレージ アカウント名] で、使用する Azure ストレージ アカウントを選択します。
- [保存] をクリックします。
Azure SQL MI データベースのリンクされたサービスを作成する
この手順では、Azure SQL MI データベースをデータ ファクトリにリンクします。
Note
SQL MI を使用している場合、パブリック エンドポイントとプライベート エンドポイントを経由したアクセスの詳細については、こちらを参照してください。 プライベート エンドポイントを使用する場合は、セルフホステッド統合ランタイムを使用してこのパイプラインを実行する必要があります。 オンプレミス、VM、または VNet で SQL Server を実行するシナリオに対しても、同じことが当てはまります。
[接続] をクリックし、 [+ 新規] をクリックします。
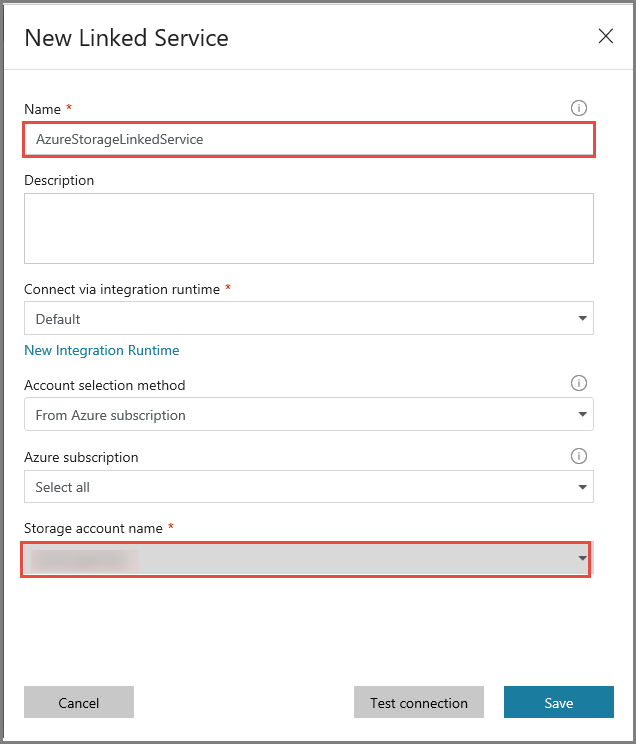
[New Linked Service](新しいリンクされたサービス) ウィンドウで [Azure SQL Database Managed Instance] を選択し、 [続行] をクリックします。
[New Linked Service](新しいリンクされたサービス) ウィンドウで、次の手順を行います。
- [名前] フィールドに「AzureSqlMI1」と入力します。
- [サーバー名] フィールドでお使いの SQL サーバーを選択します。
- [データベース名] フィールドでお使いの SQL データベースを選択します。
- [ユーザー名] フィールドにユーザーの名前を入力します。
- [パスワード] フィールドに、ユーザーのパスワードを入力します。
- [テスト接続] をクリックして接続をテストします。
- [保存] をクリックして、リンクされたサービスを保存します。

データセットを作成する
このステップでは、データのコピー元とコピー先を表すデータセットを作成します。
ソース データを表すデータセットを作成する
この手順では、ソース データを表すデータセットを作成します。
ツリー ビューで [+](プラス記号) をクリックし、 [データセット] をクリックします。

[Azure SQL Database Managed Instance] を選択し、 [続行] をクリックします。
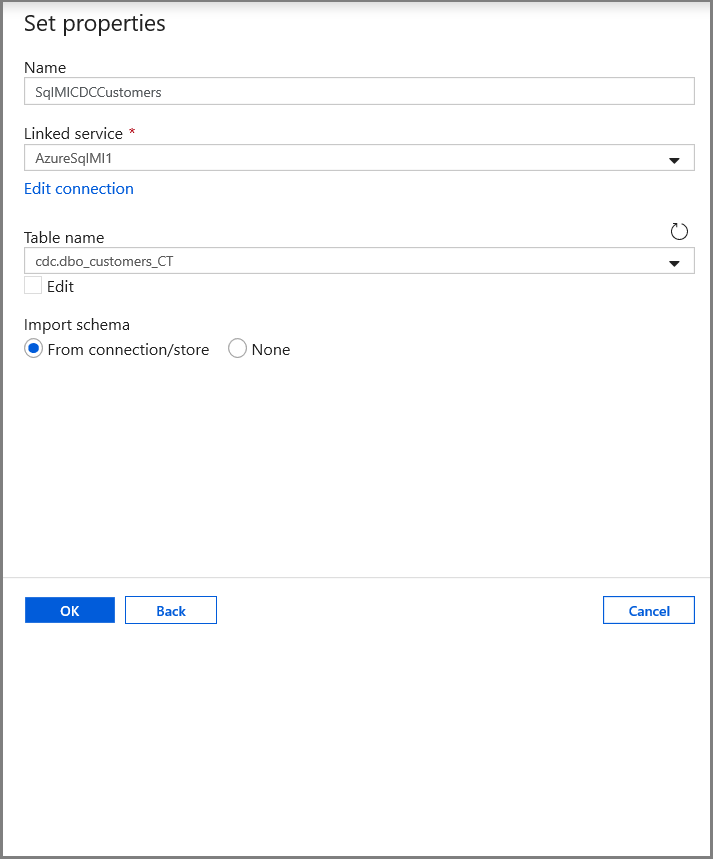
[プロパティの設定] タブで、データセット名と接続情報を設定します。
- [リンクされたサービス] で AzureSqlMI1 を選択します。
- [テーブル名] で [dbo].[dbo_customers_CT] を選択します。 注: このテーブルは、customers テーブルで CDC を有効にしたときに自動的に作成されたものです。 変更されたデータは、このテーブルから直接クエリされることはなく、代わりに CDC 関数を使用して抽出されます。
シンク データ ストアにコピーされるデータを表すデータセットを作成します。
この手順では、ソース データ ストアからコピーされたデータを表すデータセットを作成します。 前提条件の 1 つとして、データ レイク コンテナーを Azure Blob Storage に作成しました。 このコンテナーが存在しない場合は作成するか、または既存のコンテナーの名前に設定してください。 このチュートリアルでは、トリガー時刻を使用して出力ファイル名を動的に生成します。これは後で構成します。
ツリー ビューで [+](プラス記号) をクリックし、 [データセット] をクリックします。
[Azure Blob Storage] を選択し、 [続行] をクリックします。

[DelimitedText] を選択し、 [続行] をクリックします。

[プロパティの設定] タブで、データセット名と接続情報を設定します。
- [リンクされたサービス] で [AzureStorageLinkedService] を選択します。
- [ファイル パス] のコンテナー部分には「raw」と入力します。
- [First row as header](先頭の行を見出しとして使用する) を有効にします
- [OK] をクリックします。

変更されたデータをコピーするパイプラインを作成する
このステップで作成するパイプラインでは、最初に、検索アクティビティを使用して、変更テーブルに存在する変更されたレコードの数を調べます。 IF 条件アクティビティでは、変更されたレコードの数が 0 より大きいかどうかが確認され、コピー アクティビティが実行されて、挿入、更新、削除されたデータが Azure SQL Database から Azure Blob Storage にコピーされます。 最後に、タンブリング ウィンドウ トリガーが構成され、開始時刻と終了時刻がウィンドウの開始および終了パラメーターとしてアクティビティに渡されます。
Data Factory の UI で、 [編集] タブに切り替えます。左ウィンドウで [+](プラス記号) をクリックし、 [パイプライン] をクリックします。
パイプラインを構成するための新しいタブが表示されます。 ツリー ビューにもパイプラインが表示されます。 [プロパティ] ウィンドウで、パイプラインの名前を「IncrementalCopyPipeline」に変更します。
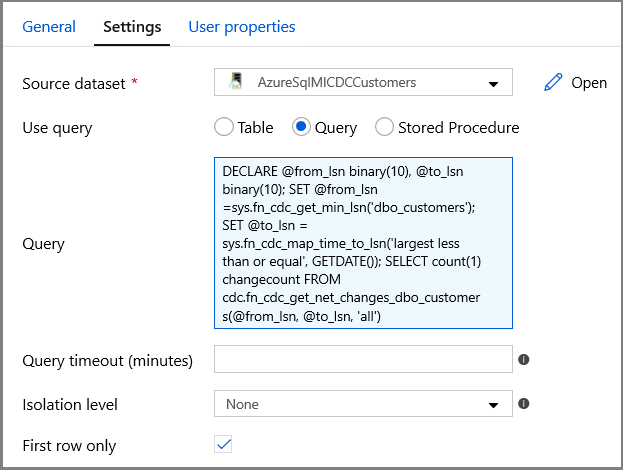
[アクティビティ] ツール ボックスの [General](一般) を展開し、 [検索] アクティビティをパイプライン デザイナー画面にドラッグ アンド ドロップします。 アクティビティの名前を GetChangeCount に設定します。 このアクティビティを使って、指定した期間における変更テーブル内のレコード数を取得します。

[プロパティ] ウィンドウで [設定] に切り替えます。
[Source Dataset](コピー元データセット) フィールドで SQL MI データセットの名前を指定します。
クエリ オプションを選択し、クエリ ボックスに次のように入力します。
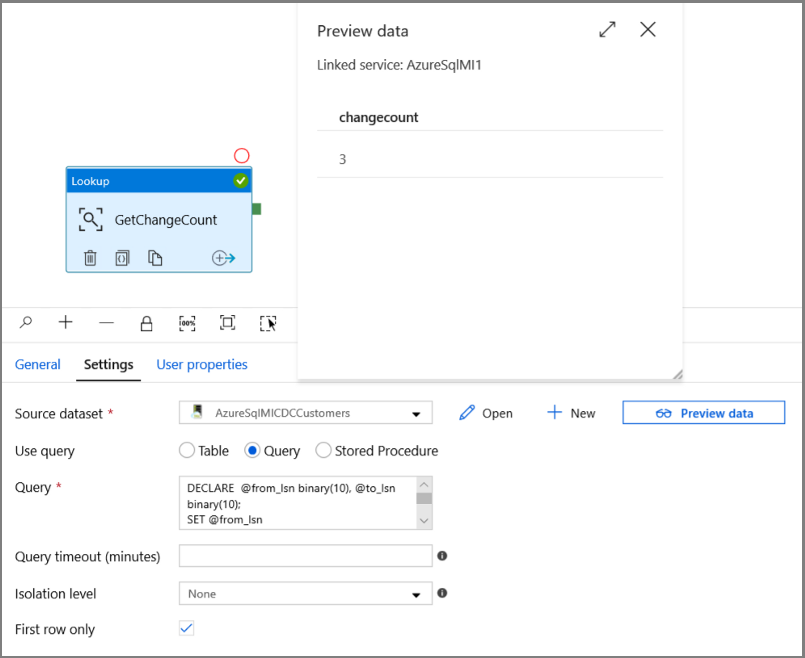
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')- [First row only](先頭行のみ) を有効にします
[データのプレビュー] ボタンをクリックし、検索アクティビティによって確実に有効な出力が取得されるようにします
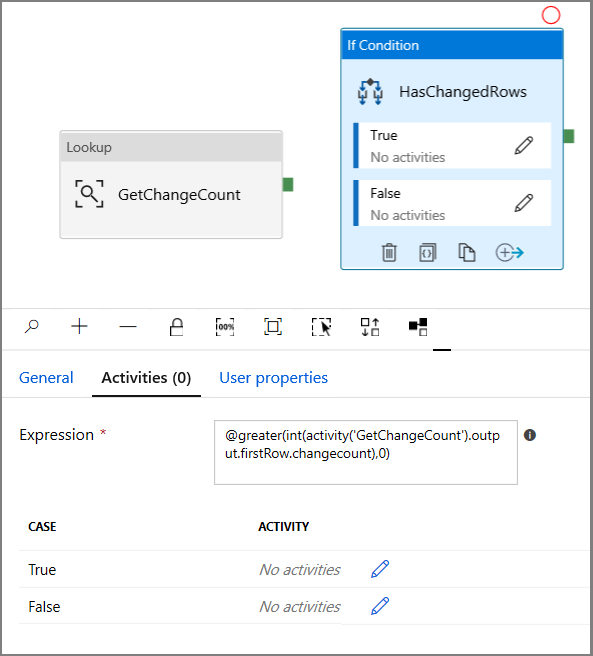
[アクティビティ] ツール ボックスで [Iteration & Conditionals]\(繰り返しと条件\) を展開し、パイプライン デザイナー画面に [If Condition]\(If 条件\) アクティビティをドラッグ アンド ドロップします。 アクティビティの名前を HasChangedRows に設定します。

[プロパティ] ウィンドウで [アクティビティ] に切り替えます。
- 次の式を入力します
@greater(int(activity('GetChangeCount').output.firstRow.changecount),0)- 鉛筆アイコンをクリックして、True 条件を編集します。
- [アクティビティ] ツール ボックスの [General](一般) を展開し、 [Wait](待機) アクティビティをパイプライン デザイナー画面にドラッグ アンド ドロップします。 これは、If 条件をデバッグするための一時的なアクティビティであり、チュートリアルの後半で変更します。

- IncrementalCopyPipeline 階層リンクをクリックして、メイン パイプラインに戻ります。
パイプラインをデバッグ モードで実行し、パイプラインが正常に実行されることを確認します。

次に、True 条件のステップに戻り、待機アクティビティを削除します。 [アクティビティ] ツール ボックスで [Move & Transform]\(移動と変換\) を展開し、[コピー] アクティビティをパイプライン デザイナー画面にドラッグ アンド ドロップします。 アクティビティの名前を「IncrementalCopyActivity」に設定します。

[プロパティ] ウィンドウで [ソース] タブに切り替え、以下の手順を実行します。
[Source Dataset](コピー元データセット) フィールドで SQL MI データセットの名前を指定します。
[クエリの使用] で [クエリ] を選択します。
[クエリ] に次のように入力します。
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')
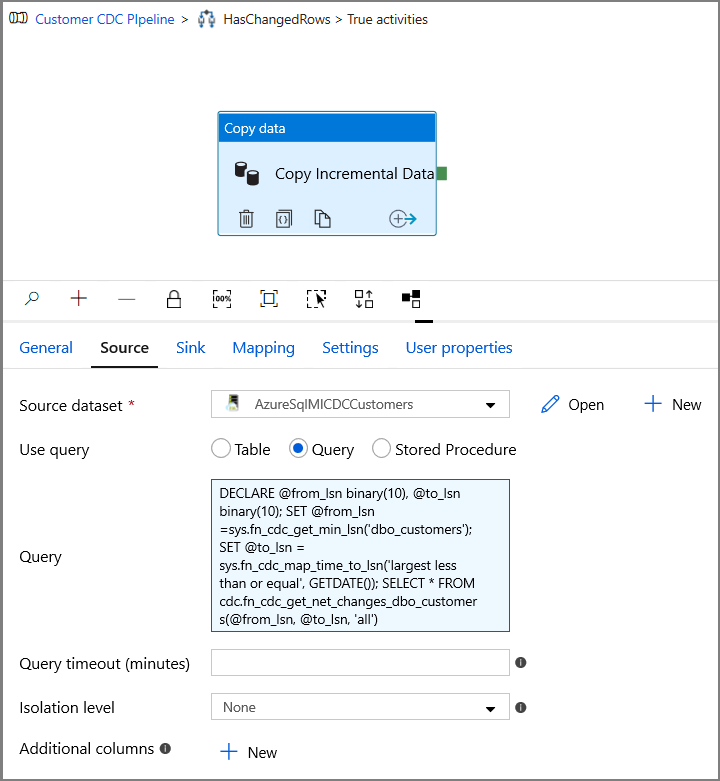
プレビューをクリックし、クエリから変更された行数が正しく返されることを確認します。

[Sink](コピー先) タブに切り替えて、 [Sink Dataset](コピー先データセット) フィールドで Azure Storage データセットを指定します。

クリックしてメイン パイプライン キャンバスに戻り、検索アクティビティを If 条件アクティビティに 1 つずつ接続します。 [検索] アクティビティに付いている緑のボタンを [If Condition](If 条件) アクティビティにドラッグします。
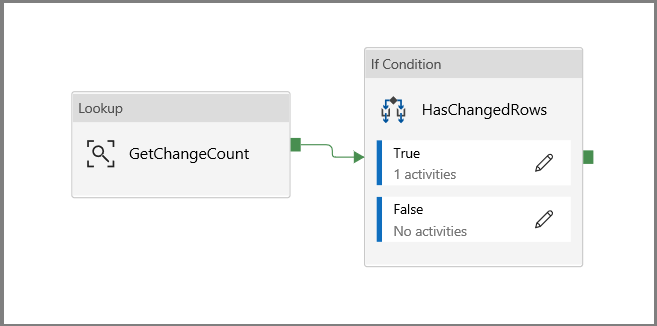
ツール バーの [検証] をクリックします。 検証エラーがないことを確認します。 [>>] をクリックして、[Pipeline Validation Report](パイプライン検証レポート) ウィンドウを閉じます。

[デバッグ] をクリックしてパイプラインをテストし、ファイルが保存場所に生成されることを確認します。
[すべて公開] ボタンをクリックして、エンティティ (リンクされたサービス、データセット、およびパイプライン) を Data Factory サービスに発行します。 [発行は成功しました] というメッセージが表示されるまで待機します。
タンブリング ウィンドウ トリガーと CDC ウィンドウ パラメーターを構成する
このステップでは、頻繁なスケジュールでジョブを実行するためのタンブリング ウィンドウ トリガーを作成します。 タンブリング ウィンドウ トリガーの WindowStart および WindowEnd システム変数を使用し、CDC クエリで使用するパラメーターとしてパイプラインに渡します。
IncrementalCopyPipeline パイプラインの [パラメーター] タブに移動し、 [+ 新規] ボタンを使用して、2 つのパラメーター (triggerStartTime と triggerEndTime) をパイプラインに追加します。これは、タンブリング ウィンドウの開始時刻と終了時刻を表します。 デバッグのため、YYYY-MM-DD HH24:MI:SS.FFF という形式で既定値を追加します。ただし、triggerStartTime がテーブルで CDC を有効にする時刻より前にならないようにします。そうしないと、エラーが発生します。

検索アクティビティの設定タブをクリックし、開始パラメーターと終了パラメーターを使用するようにクエリを構成します。 以下をクエリにコピーします。
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')If 条件アクティビティの True の場合のコピー アクティビティに移動し、 [ソース] タブをクリックします。以下をクエリにコピーします。
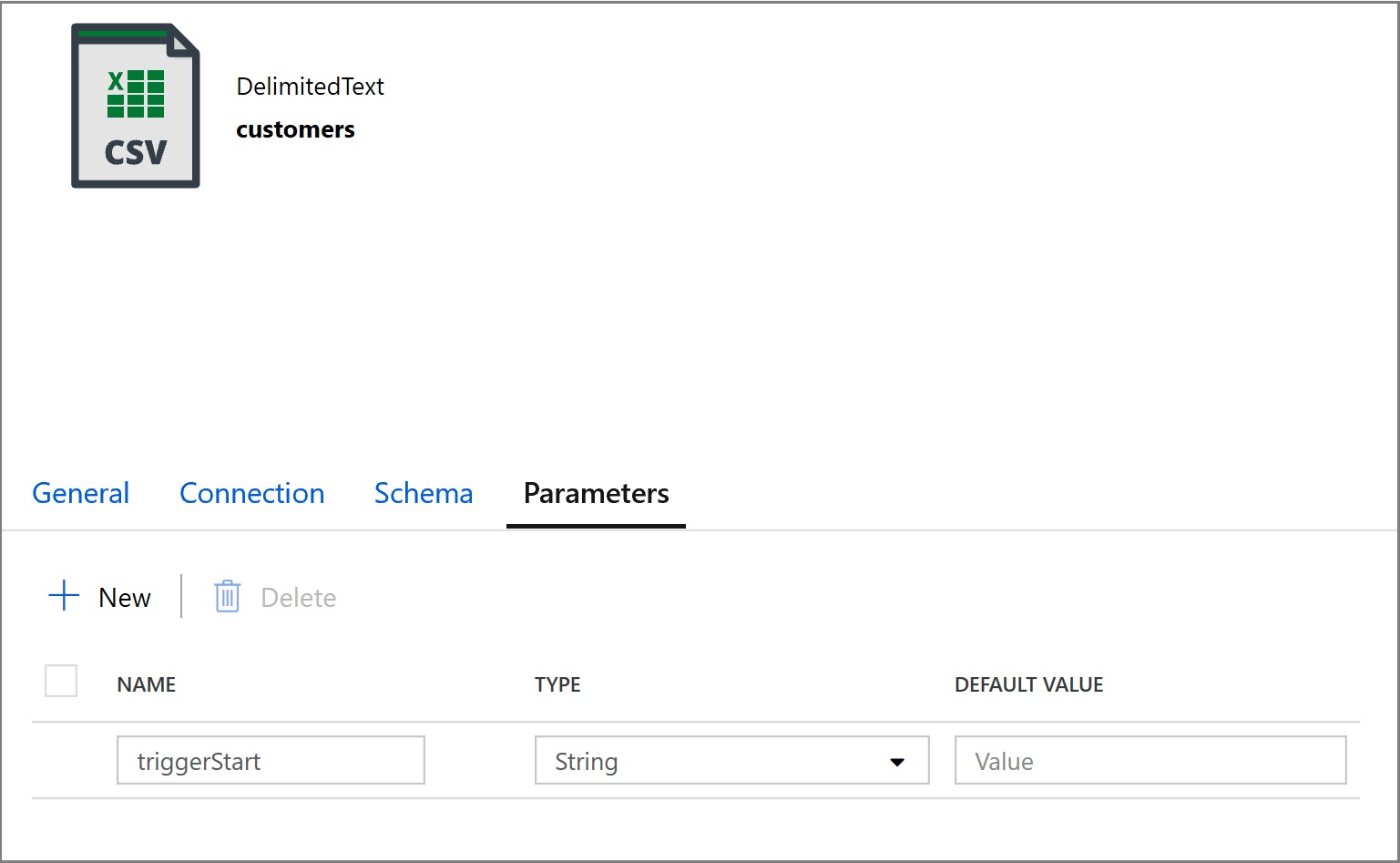
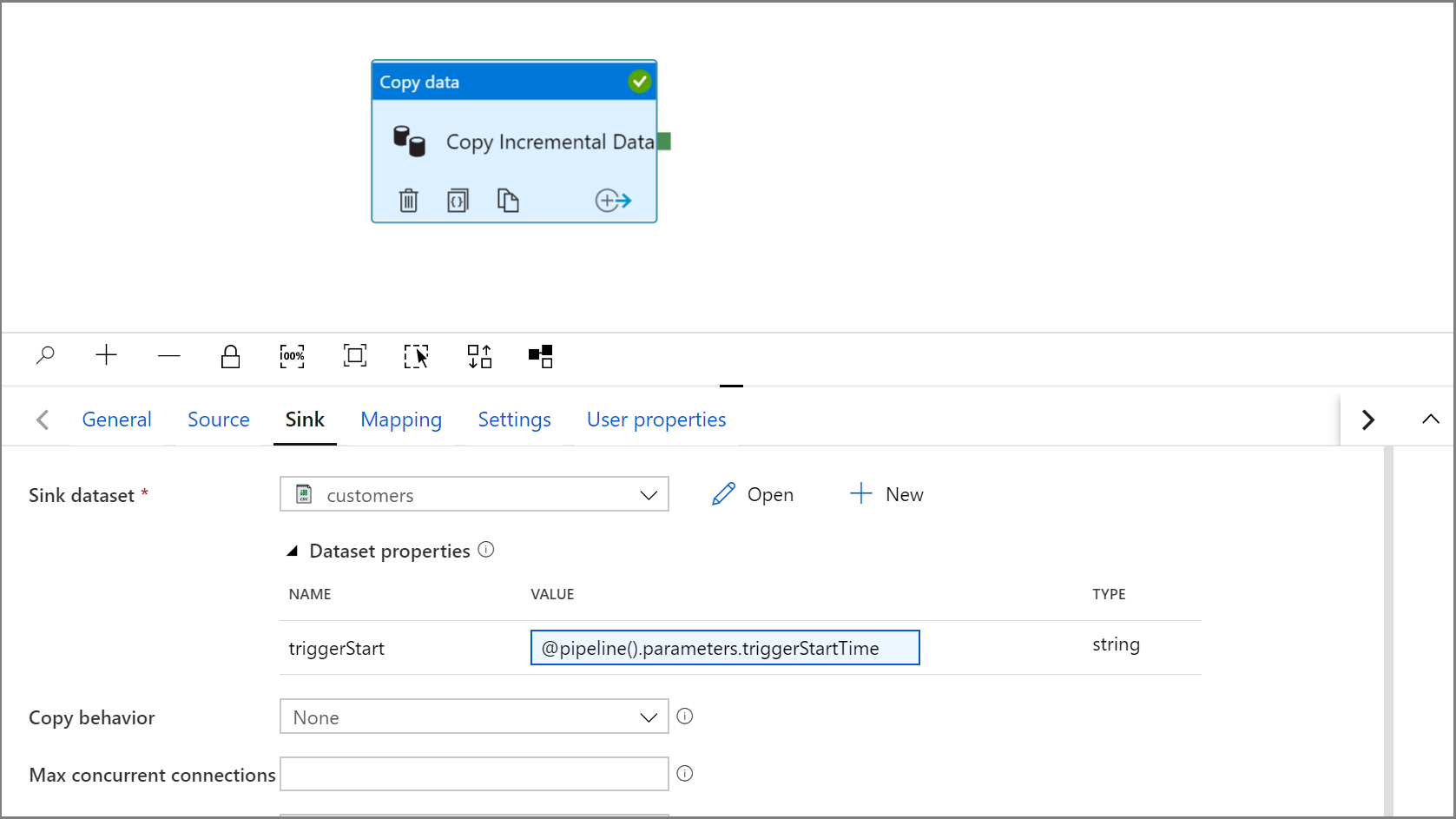
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')コピー アクティビティの [Sink](コピー先) タブをクリックし、 [開く] をクリックして、データセットのプロパティを編集します。 [パラメーター] タブをクリックし、triggerStart という名前の新しいパラメーターを追加します
次に、日付ベースのパーティションで customers/incremental サブディレクトリにデータを格納するように、データセットのプロパティを構成します。
データセットのプロパティの [接続] タブをクリックし、 [ディレクトリ] と [ファイル] の両方のセクションに動的なコンテンツを追加します。
テキスト ボックスの下にある動的コンテンツ リンクをクリックして、 [ディレクトリ] セクションに次の式を入力します。
@concat('customers/incremental/',formatDateTime(dataset().triggerStart,'yyyy/MM/dd'))[ファイル] セクションに次の式を入力します。 これにより、トリガーの開始日時を基にしてファイル名が作成され、csv 拡張子がサフィックスとして付けられます。
@concat(formatDateTime(dataset().triggerStart,'yyyyMMddHHmmssfff'),'.csv')
IncrementalCopyPipeline タブをクリックしてコピー アクティビティの [Sink](コピー先) 設定に戻ります。
データセットのプロパティを展開し、次の式を使用して、triggerStart パラメーター値に動的コンテンツを入力します。
@pipeline().parameters.triggerStartTime
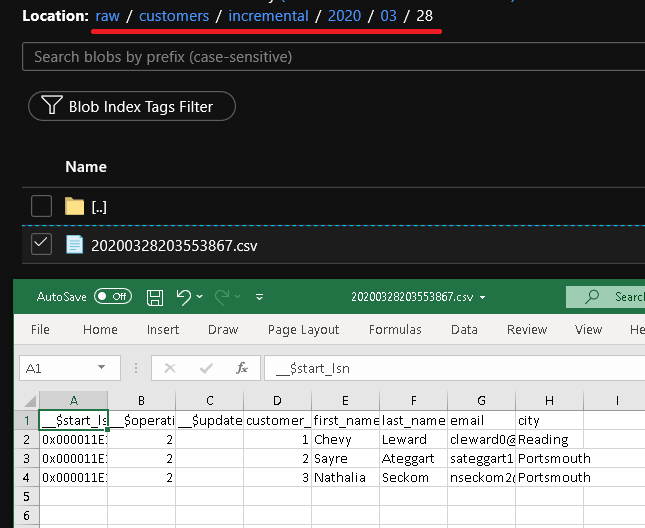
[デバッグ] をクリックしてパイプラインをテストし、確実にフォルダー構造と出力ファイルが想定どおりに生成されるようにします。 ファイルをダウンロードして開き、内容を確認します。
パイプライン実行の入力パラメーターを調べて、パラメーターがクエリに確実に挿入されているようにします。
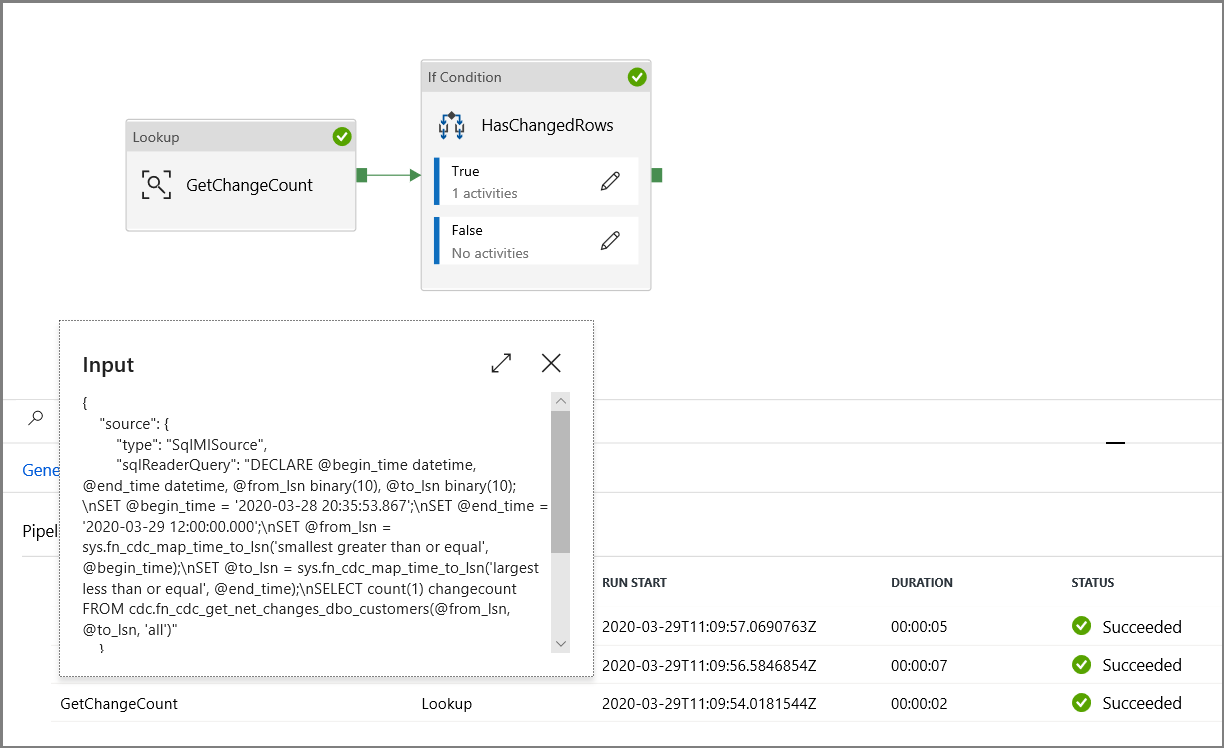
[すべて公開] ボタンをクリックして、エンティティ (リンクされたサービス、データセット、およびパイプライン) を Data Factory サービスに発行します。 [発行は成功しました] というメッセージが表示されるまで待機します。
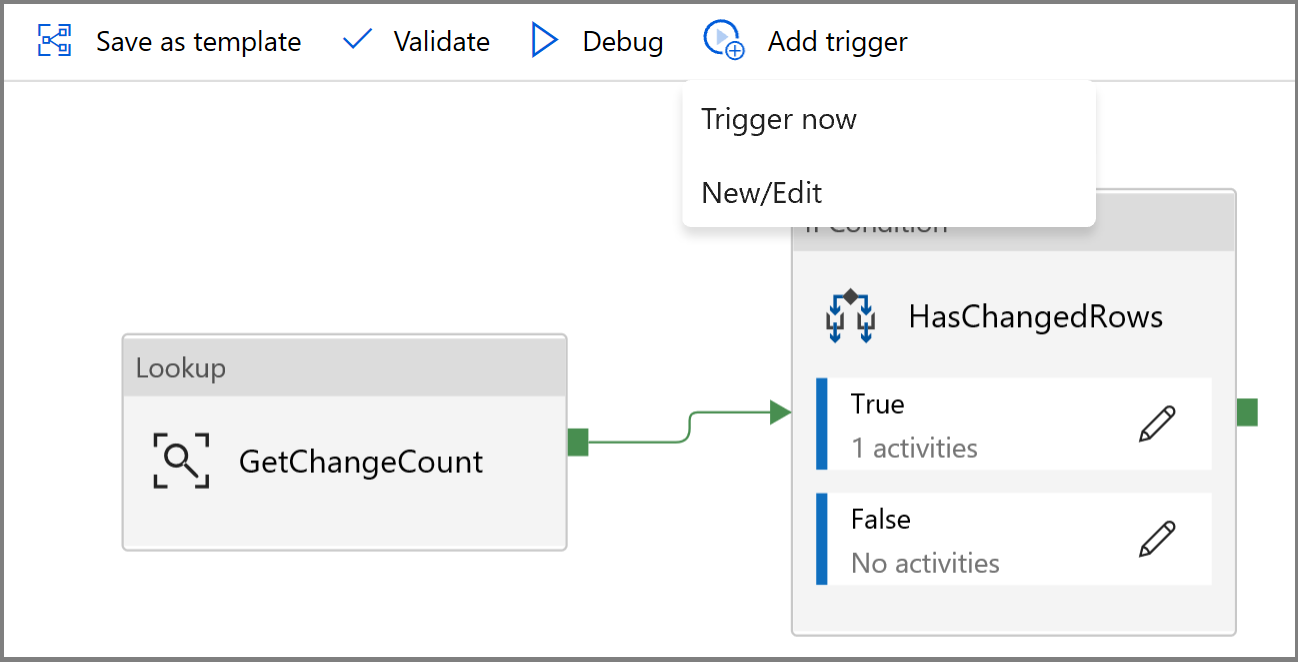
最後に、一定の間隔でパイプラインが実行されるようにタンブリング ウィンドウ トリガーを構成し、開始時刻と終了時刻のパラメーターを設定します。
- [トリガーの追加] ボタンをクリックし、 [New/Edit](新規作成/編集) を選択します
- トリガー名を入力し、上のデバッグ ウィンドウの終了時刻と同じ時刻に開始時刻を指定します。
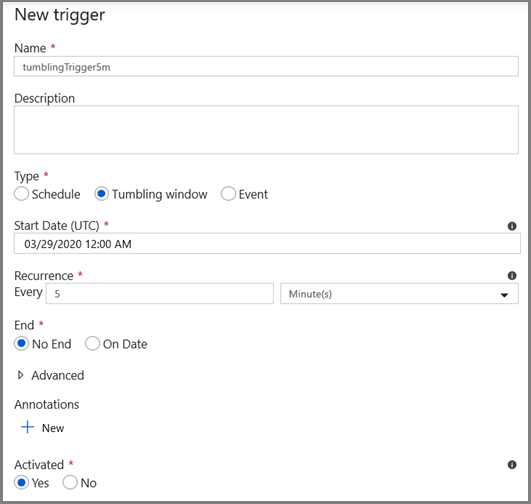
次の画面で、開始および終了パラメーターにそれぞれ次の値を指定します。
@formatDateTime(trigger().outputs.windowStartTime,'yyyy-MM-dd HH:mm:ss.fff') @formatDateTime(trigger().outputs.windowEndTime,'yyyy-MM-dd HH:mm:ss.fff')
Note
トリガーは、公開された後でのみ実行されます。 さらに、タンブリング ウィンドウの予想される動作では、開始日から現在までのすべての履歴間隔が実行されます。 タンブリング ウィンドウ トリガーに関する詳細については、こちらを参照してください。
SQL Server Management Studio を使用し、次の SQL を実行して、customer テーブルにいくつかの追加の変更を行います。
insert into customers (customer_id, first_name, last_name, email, city) values (4, 'Farlie', 'Hadigate', 'fhadigate3@zdnet.com', 'Reading'); insert into customers (customer_id, first_name, last_name, email, city) values (5, 'Anet', 'MacColm', 'amaccolm4@yellowbook.com', 'Portsmouth'); insert into customers (customer_id, first_name, last_name, email, city) values (6, 'Elonore', 'Bearham', 'ebearham5@ebay.co.uk', 'Portsmouth'); update customers set first_name='Elon' where customer_id=6; delete from customers where customer_id=5;[すべて公開] ボタンをクリックします。 [発行は成功しました] というメッセージが表示されるまで待機します。
数分後にパイプラインがトリガーされ、新しいファイルが Azure Storage に読み込まれます
増分コピー パイプラインを監視する
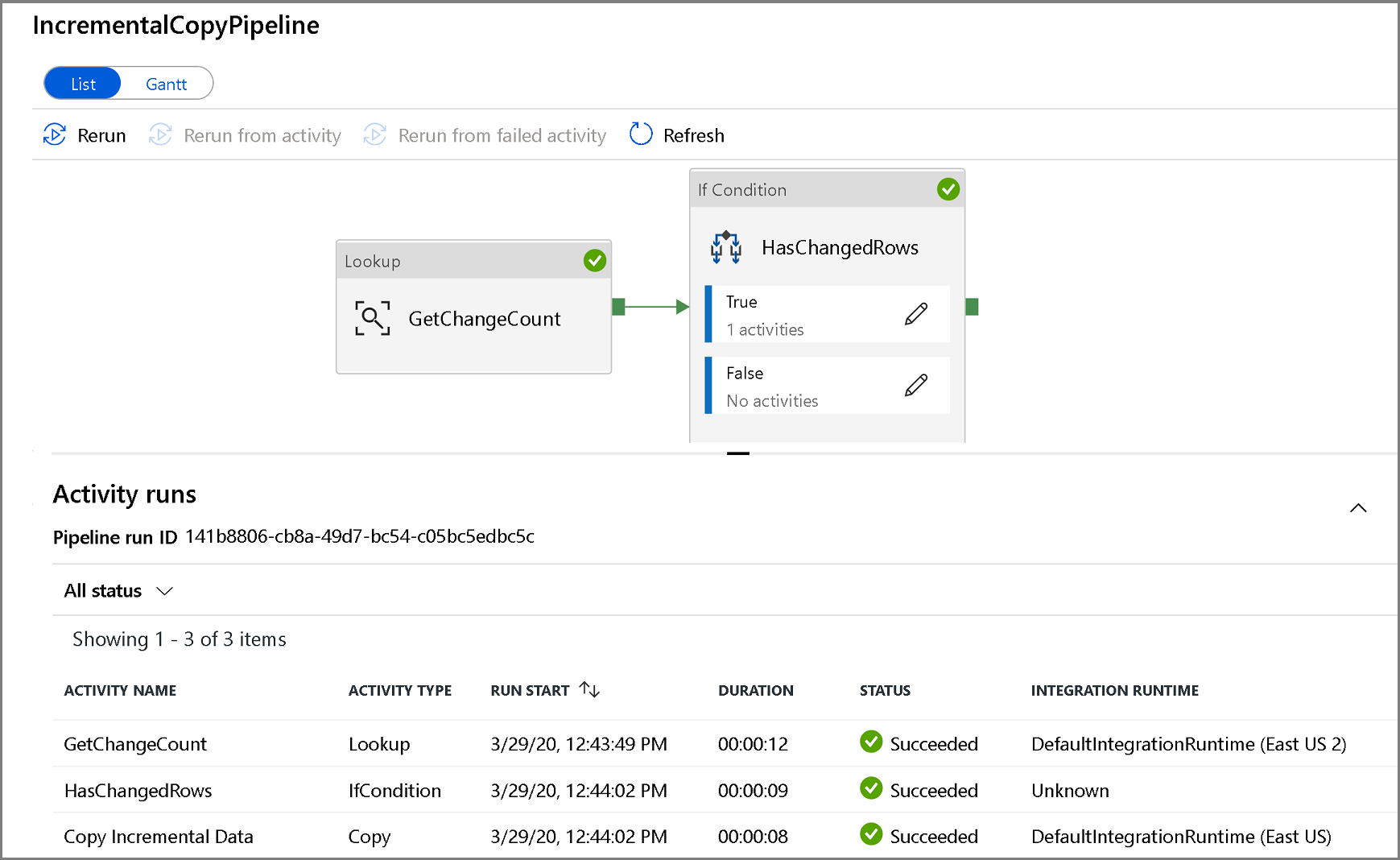
左側の [監視] タブをクリックします。 一覧にパイプラインの実行とその状態が表示されます。 一覧を更新するには、 [最新の情報に更新] をクリックします。 再実行アクションと消費量レポートにアクセスするには、パイプラインの名前の近くをポイントします。
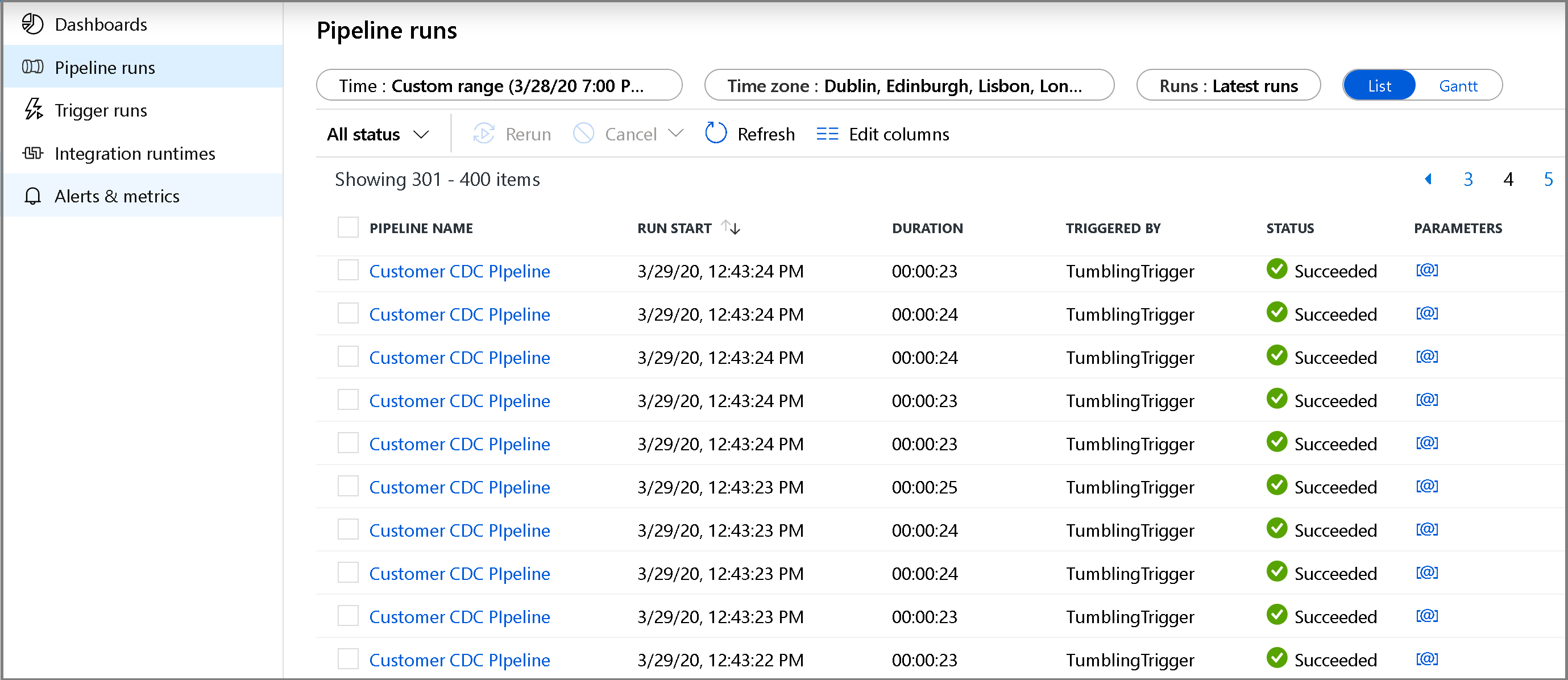
パイプラインの実行に関連付けられたアクティビティの実行を表示するには、パイプラインの名前をクリックします。 変更されたデータが検出された場合は、コピー アクティビティを含む 3 つのアクティビティがリストに存在し、それ以外の場合は 2 つのエントリしか存在しません。 パイプライン実行ビューに戻るには、上部の [すべてのパイプライン] リンクをクリックします。
結果の確認
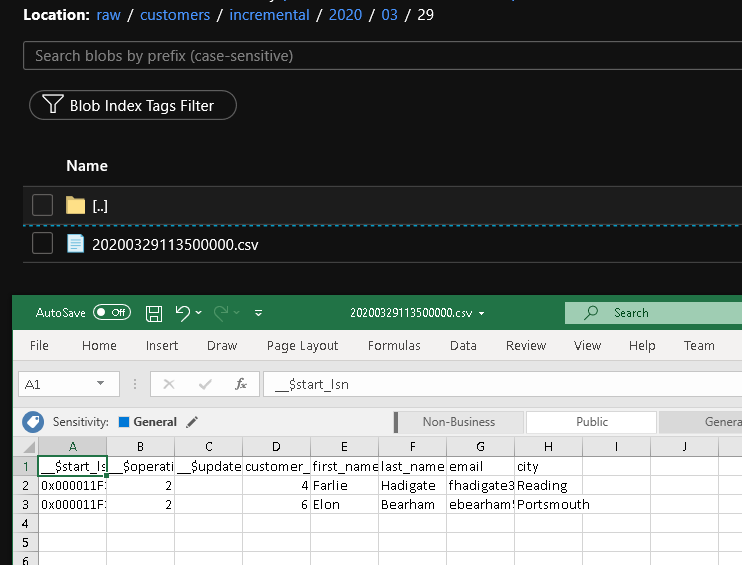
raw コンテナーの customers/incremental/YYYY/MM/DD フォルダーにもう 1 つファイルが確認できます。
関連するコンテンツ
次のチュートリアルに進んで、LastModifiedDate に基づいて新規ファイルおよび変更されたファイルのみをコピーする方法について学習してください。