クイック スタート:Azure portal を使用して Azure HDInsight 内に Apache Spark クラスターを作成する
このクイックスタートでは、Azure portal を使用して Azure HDInsight に Apache Spark クラスターを作成します。 その後、Jupyter Notebook を作成し、それを使用して、Apache Hive のテーブルに対する Spark SQL クエリを実行します。 Azure HDInsight は、全範囲に対応した、オープンソースのエンタープライズ向けマネージド分析サービスです。 HDInsight の Apache Spark フレームワークにより、メモリ内処理を使用した、高速の Data Analytics とクラスター コンピューティングが可能になります。 Jupyter Notebook を使用すると、データを対話的に操作したり、コードと Markdown テキストとを結合したり、簡単な視覚化を行ったりすることができます。
使用できる構成の詳細については、HDInsight でクラスターを設定する方法に関するページを参照してください。 ポータルを使用したクラスター作成の詳細については、ポータルでクラスターを作成する方法に関するページを参照してください。
複数のクラスターを一緒に使用している場合は、仮想ネットワークを作成することが考えられます。Spark クラスターを使用している場合は、Hive Warehouse Connector を使用することもできます。 詳細については、「Azure HDInsight 用の仮想ネットワークを計画する」と「Hive Warehouse Connector を使用して Apache Spark と Apache Hive を統合する」を参照してください。
重要
HDInsight クラスターの料金は、そのクラスターを使用しているかどうかに関係なく、分単位で課金されます。 使用後は、クラスターを必ず削除してください。 詳しくは、この記事の「リソースのクリーンアップ」をご覧ください。
前提条件
アクティブなサブスクリプションが含まれる Azure アカウント。 無料でアカウントを作成できます。
HDInsight での Apache Spark クラスターの作成
Azure portal を使用して、クラスター ストレージとして Azure Storage BLOB を使用する HDInsight クラスターを作成します。 Data Lake Storage Gen2 の使用法の詳細については、「クイック スタート:HDInsight のクラスターを設定する」をご覧ください。
Azure portal にサインインします。
上部のメニューで、 [+ リソースの作成] を選択します。
[分析]>[Azure HDInsight] の順に選択して [HDInsight クラスターの作成] ページに移動します。
[基本] タブで次の情報を指定します。
プロパティ 説明 サブスクリプション ドロップダウン リストから、このクラスターに使用する Azure サブスクリプションを選択します。 Resource group ドロップダウン リストから既存のリソース グループを選択するか、 [新規作成] を選択します。 クラスター名 グローバルに一意の名前を入力します。 リージョン ドロップダウン リストから、クラスターの作成先となるリージョンを選択します。 可用性ゾーン オプション - クラスターをデプロイする可用性ゾーンを指定します クラスターの種類 クラスターの種類を選択して、一覧を開きます。 一覧から、 [Spark] を選択します。 クラスターのバージョン クラスターの種類が選択されると、このフィールドに既定のバージョンが自動的に入力されます。 クラスター ログイン ユーザー名 クラスターのログイン ユーザー名を入力します。 既定の名前は adminです。クイックスタートの後半で、このアカウントを使用して Jupyter Notebook にログインします。 クラスター ログイン パスワード クラスターのログイン パスワードを入力します。 Secure Shell (SSH) ユーザー名 SSH ユーザー名を入力します。 このクイック スタートで使う SSH ユーザー名は sshuser です。 既定では、このアカウントは "クラスター ログイン ユーザー名" アカウントと同じパスワードを共有します。 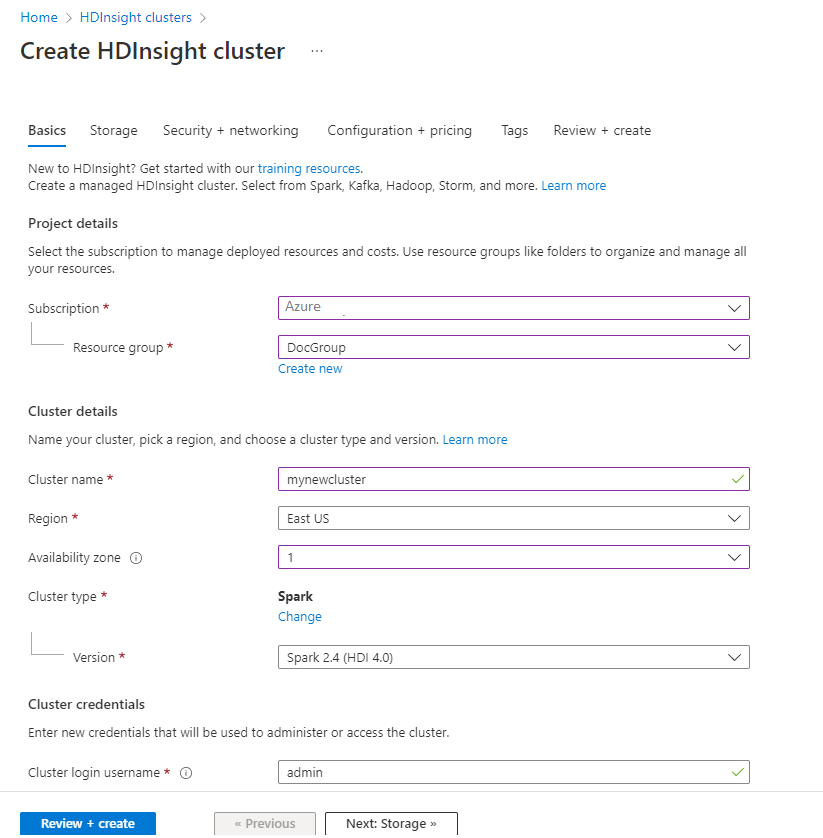
[次へ]>> を選んで、[ストレージ] ページに進みます。
[ストレージ] で次の値を指定します。
プロパティ 説明 プライマリ ストレージの種類 既定値の [Azure Storage] を使用します。 メソッドの選択 既定値の [一覧から選択する] を使用します。 プライマリ ストレージ アカウント 自動入力されている値を使用します。 コンテナー 自動入力されている値を使用します。 
[Review + create](確認と作成) を選択して続行します。
[Review + create](確認と作成) を選択し、 [作成] を選択します。 クラスターの作成には約 20 分かかります。 次のセッションに進む前に、クラスターを作成する必要があります。
HDInsight クラスターを作成する際に問題が発生した場合は、適切なアクセス許可がない可能性があります。 詳細については、「アクセス制御の要件」を参照してください。
Jupyter Notebook の作成
Jupyter Notebook は、さまざまなプログラミング言語をサポートする対話型のノートブック環境です。 ノートブックを使うと、データと対話し、Markdown テキストとコードを組み合わせて、簡単な視覚化を実行できます。
Web ブラウザーから、
https://CLUSTERNAME.azurehdinsight.net/jupyterに移動します。ここで、CLUSTERNAMEはクラスターの名前です。 入力を求められたら、クラスターのログイン資格情報を入力します。[新規]>[PySpark] を選んで、ノートブックを作成します。

Untitled(Untitled.pynb) という名前の新しい Notebook が作成されて開かれます。
Apache Spark SQL ステートメントを実行する
SQL (構造化照会言語) は、データ照会とデータ定義のための言語として最も一般的かつ広く使用されています。 Spark SQL を Apache Spark の拡張機能として導入することで、使い慣れた SQL 構文を使って構造化データを扱うことができます。
カーネルの準備ができていることを確認します。 Notebook のカーネル名の横に白丸が表示されたら、カーネルの準備ができています。 黒丸は、カーネルがビジー状態であることを示します。

Notebook を初めて起動すると、カーネルがバックグラウンドでいくつかのタスクを実行します。 カーネルの準備ができるまで待ちます。
次のコードを空のセルに貼り付け、Shift + Enter キーを押してコードを実行します。 コマンドを実行すると、クラスター上の Hive テーブルが一覧表示されます。
%%sql SHOW TABLESHDInsight クラスターで Jupyter Notebook を使用すると、Spark SQL を使用して Hive クエリを実行するために使用できるプリセット
sqlContextが手に入ります。%%sqlにより、プリセットsqlContextを使用して Hive クエリを実行するよう Jupyter Notebook に指示します。 クエリは、すべての HDInsight クラスターに既定で付属する Hive テーブル (hivesampletable) から先頭の 10 行を取得します。 結果が得られるまで約 30 秒かかります。 出力は次のようになります。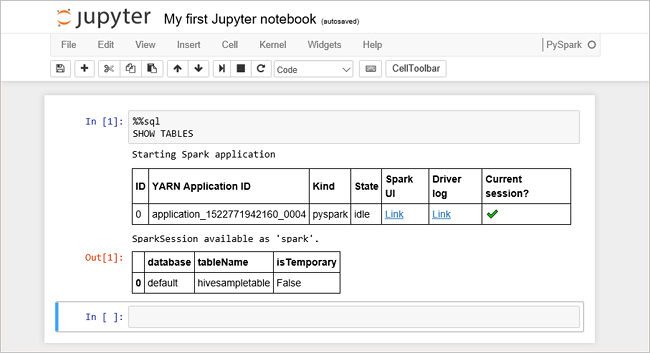 is quickstart." border="true":::
is quickstart." border="true":::Jupyter でクエリを実行するたびに、Web ブラウザー ウィンドウのタイトルに [(ビジー)] ステータスと Notebook のタイトルが表示されます。 また、右上隅にある PySpark というテキストの横に塗りつぶされた円も表示されます。
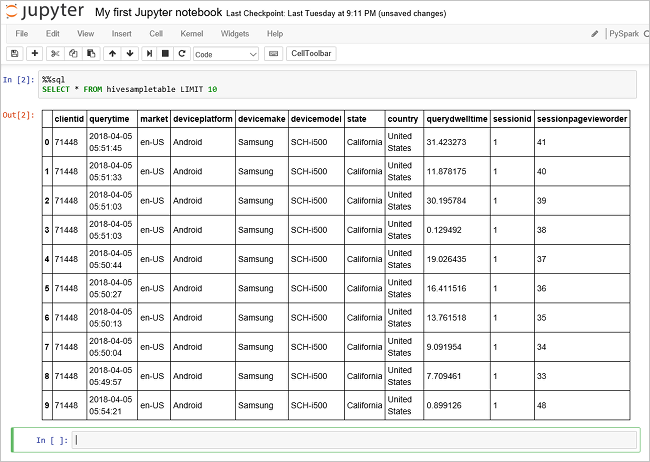
別のクエリを実行して、
hivesampletableのデータを確認します。%%sql SELECT * FROM hivesampletable LIMIT 10画面が更新され、クエリ出力が表示されます。
 Insight" border="true":::
Insight" border="true":::ノートブックの [File](ファイル) メニューの [Close and Halt](閉じて停止) を選びます。 Notebook をシャットダウンすると、クラスターのリソースが解放されます。
リソースをクリーンアップする
HDInsight はデータを Azure Storage または Azure Data Lake Storage に格納するので、クラスターが使われていないときは、クラスターを安全に削除できます。 また、HDInsight クラスターは、使用していない場合でも課金されます。 クラスターの料金は Storage の料金の何倍にもなるため、クラスターを使用しない場合は削除するのが経済的にも合理的です。 「次のステップ」で示されているチュートリアルにすぐに取り掛かる場合は、クラスターをそのままにしてもかまいません。
Azure portal に戻り、 [削除] を選びます。
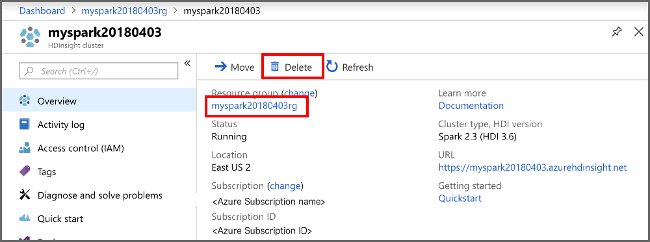 sight cluster" border="true":::
sight cluster" border="true":::
リソース グループ名を選び、リソース グループ ページを開いて、 [リソース グループの削除] を選ぶこともできます。 リソース グループを削除すると、HDInsight クラスターと既定のストレージ アカウントの両方が削除されます。
次のステップ
このクイックスタートでは、HDInsight に Apache Spark クラスターを作成し、基本的な Spark SQL クエリを実行する方法を学習しました。 HDInsight クラスターを使用してサンプル データに対話型のクエリを実行する方法については、次のチュートリアルに進みます。