Azure Information Protection クラシック スキャナーの構成とインストール
Azure Information Protection スキャナーの構成とインストールを開始する前に、システムが必要な前提条件に準拠していることを確認します。
準備ができたら、次の手順に進みます。
システムに必要な次の追加構成手順を実行します。
| 手順 | 説明 |
|---|---|
| 保護するファイルの種類を変更する | 既定とは異なる種類のファイルをスキャン、分類、または保護することができます。 詳細については、「AIP スキャン プロセス」を参照してください。 |
| スキャナーをアップグレードする | スキャナーをアップグレードして、最新の機能と改善点を活用します。 |
| データ リポジトリ設定の一括編集 | インポートとエクスポートのオプションを使用して、複数のデータ リポジトリに対して一括変更を行います。 |
| 別の構成でスキャナーを使用する | 任意の条件でラベルを構成せずにスキャナーを使用します |
| パフォーマンスを最適化する | スキャナーのパフォーマンスを最適化するためのガイダンス |
詳細については、「スキャナーのコマンドレットの一覧」も参照してください。
Azure portal でスキャナーを構成する
スキャナーをインストールするか、以前の一般公開バージョンのスキャナーからアップグレードする前に、Azure portal でスキャナーのクラスターとコンテンツ スキャン ジョブを作成します。
次に、スキャナー設定とスキャンするデータ リポジトリを使用して、クラスターとコンテンツ スキャン ジョブを構成します。
スキャナーを構成するには:
Azure portal にサインインし、[Azure Information Protection] ウィンドウに移動します。
たとえば、リソース、サービス、ドキュメントの検索ボックスで次のようにします: 「Information」と入力し、 [Azure Information Protection] を選択します。
[スキャナー] メニュー オプションを見つけて、[クラスター] を選択します。
[Azure Information Protection] - [クラスター] ペインで、[追加] を選択します。
[新しいクラスターを追加] ペインで、次の操作を行います。
スキャナーに対してわかりやすい名前を指定します。 この名前は、スキャナーの構成設定とスキャンするデータ リポジトリを識別するために使用されます。
たとえば、スキャナーの対象となるデータ リポジトリの地理的な場所を識別するために、Europe を指定する場合があります。 後でスキャナーをインストールまたはアップグレードするときに、同じクラスター名を指定する必要があります。
スキャナーのクラスター名を識別するために、必要に応じて管理目的の説明を指定します。
[保存] を選択します。
[スキャナー] メニュー オプションを見つけて、[コンテンツ スキャン ジョブ] を選択します。
[Azure Information Protection - コンテンツ スキャン ジョブ] ペインで、[追加] を選択します。
この初期構成では、次の設定を構成して [保存] を選択しますが、ペインは閉じないでください。
セクション 設定 コンテンツ スキャン ジョブの設定 - [スケジュール]: 既定の [手動] のままにします
- [検出する情報の種類]: [ポリシーのみ] に変更します
- [リポジトリの構成]: 最初にコンテンツ スキャン ジョブを保存する必要があるため、現時点では構成しません。機密ポリシー - [強制]: [オフ] を選択します
- [コンテンツに基づいてファイルにラベルを付ける]: 既定の [オン] のままにします
- [既定のラベル]: 既定の [ポリシーの既定値] のままにします
- [ファイルのラベルを書き換える]: 既定の [オフ] のままにしますファイル設定を構成する - ["変更日"、"最終変更日時"、"変更者" を保持する]: 既定の [オン] のままにします
- [スキャンするファイルの種類]: 既定のファイルの種類を [除外] のままにします
- [既定の所有者]: 既定の [スキャナー アカウント] のままにしますこれでコンテンツ スキャン ジョブの作成と保存が完了したので、[リポジトリの構成] オプションに戻って、スキャンするデータ ストアを指定する準備が整いました。
SharePoint オンプレミス ドキュメント ライブラリおよびフォルダーの UNC パスと SharePoint Server URL を指定します。
注意
SharePoint としては SharePoint Server 2019、SharePoint Server 2016、および SharePoint Server 2013 がサポートされています。 また、SharePoint Server 2010 も、このバージョンの SharePoint の延長サポートを受けている場合はサポートされます。
最初のデータ ストアを追加するには、[新しいコンテンツ スキャン ジョブの追加] ペインで、[リポジトリの構成] を選択して [リポジトリ] ペインを開きます。

[リポジトリ] ペインで、 [追加] を選択します。

[リポジトリ] ペインで、次のようにデータ リポジトリのパスを指定して、[保存] を選択します。
たとえば、次のように入力します。
- ネットワーク共有の場合は、
\\Server\Folderを使用します。 - SharePoint ライブラリの場合は、
http://sharepoint.contoso.com/Shared%20Documents/Folderを使用します。
注意
ワイルドカードはサポートされていません。また、WebDav の場所はサポートされていません。
SharePoint パスを追加するときに、次の構文を使用します。
パス 構文 ルート パス http://<SharePoint server name>
スキャナー ユーザーに許可されているサイト コレクションを含め、すべてのサイトをスキャンします。
ルート コンテンツを自動的に検出するには、追加のアクセス許可が必要です特定の SharePoint サブサイトまたはコレクション 次のいずれかです。
-http://<SharePoint server name>/<subsite name>
-http://SharePoint server name>/<site collection name>/<site name>
サイト コンテンツを自動的に検出するには、追加のアクセス許可が必要です特定の SharePoint ライブラリ 次のいずれかです。
-http://<SharePoint server name>/<library name>
-http://SharePoint server name>/.../<library name>特定の SharePoint フォルダー http://<SharePoint server name>/.../<folder name>このペインの残りの設定に関しては、この初期構成では変更せず、コンテンツ スキャン ジョブの既定値のままにしておきます。 既定の設定は、データ リポジトリがコンテンツ スキャン ジョブから設定を継承することです。
- ネットワーク共有の場合は、
別のデータ リポジトリを追加する場合は、手順 8 と 9 を繰り返します。
[リポジトリ] ペインと [コンテンツ スキャン ジョブ] ペインを閉じます。
[Azure Information Protection - コンテンツ スキャン ジョブ] ペインに戻ると、コンテンツ スキャン名が表示されるとともに、[スケジュール] 列には [手動] が表示され、[適用] 列は空白になります。
これで、作成したコンテンツ スキャン ジョブを使ってスキャナーをインストールする準備ができました。 引き続きスキャナーのインストールを行います。
スキャナーのインストール
Azure portal で Azure Information Protection スキャナーの構成を完了したら、次の手順を実行してスキャナーをインストールします。
スキャナーを実行する Windows Server コンピューターにサインインします。 ローカル管理者権限と SQL Server マスター データベースに書き込むためのアクセス許可を持つアカウントを使用します。
重要
詳細については、「Azure Information Protection スキャナーをインストールおよびデプロイするための前提条件」を参照してください。
[管理者として実行] オプションを使用して Windows PowerShell セッションを開きます。
Azure Information Protection スキャナー用のデータベースを作成する SQL Server のインスタンスと、前のセクションで指定したスキャナーのクラスター名を指定して、Install-AIPScanner コマンドレットを実行します。
Install-AIPScanner -SqlServerInstance <name> -Profile <cluster name>プロファイル名 Europe を使った例:
既定のインスタンスの場合:
Install-AIPScanner -SqlServerInstance SQLSERVER1 -Profile Europe名前付きインスタンスの場合:
Install-AIPScanner -SqlServerInstance SQLSERVER1\AIPSCANNER -Profile EuropeSQL Server Express の場合:
Install-AIPScanner -SqlServerInstance SQLSERVER1\SQLEXPRESS -Profile Europe
求められたら、スキャナー サービス アカウントの資格情報 (
\<domain\user name>) とパスワードを指定します。[管理ツール]>[サービス] を使用して、サービスがインストールされたことを確認します。
インストールされているサービスの名前は Azure Information Protection スキャナーで、作成したスキャナー サービス アカウントを使用して実行するように構成されます。
スキャナーをインストールしたら、スキャナーを無人で実行できるように、スキャナー サービス アカウントを認証するための Azure AD トークンを取得する必要があります。
スキャナー用の Azure AD トークンを取得する
Azure AD トークンを使用すると、スキャナーで Azure Information Protection サービスを認証できます。
Azure AD トークンを取得するには:
Azure portal に戻り、認証のためのアクセス トークンを指定するための 2 つの Azure AD アプリケーションを作成します。 このトークンを使用すると、スキャナーを非対話形式で実行できます。
「非対話形式でファイルに Azure Information Protection のラベル付けをする方法」を参照してください。
スキャナーのサービス アカウントにインストール用にローカルでログオン権限が付与されている場合、Windows Server コンピューターから、このアカウントを使用してサインインし、PowerShell セッションを開始します。
前の手順でコピーした値を指定して Set-AIPAuthentication を実行します。
Set-AIPAuthentication -webAppId <ID of the "Web app / API" application> -webAppKey <key value generated in the "Web app / API" application> -nativeAppId <ID of the "Native" application>求められたら、Azure AD のサービス アカウントの資格情報のパスワードを指定し、[同意する] をクリックします。
次に例を示します。
Set-AIPAuthentication -WebAppId "57c3c1c3-abf9-404e-8b2b-4652836c8c66" -WebAppKey "+LBkMvddz?WrlNCK5v0e6_=meM59sSAn" -NativeAppId "8ef1c873-9869-4bb1-9c11-8313f9d7f76f").token | clip Acquired application access token on behalf of the user
ヒント
スキャナーのサービス アカウントにローカルでログオンの権限が付与されない場合、Set-AIPAuthentication の Token パラメーターを指定し、使用します。
これでスキャナーに Azure AD を認証するためのトークンが取得されました。トークンの有効期間は、Azure AD での Web アプリ/API の構成に従って、1 年間、2 年間、または無期限のいずれかになります。
トークンが期限切れになったら、手順 1 と 2 を繰り返す必要があります。
これで、最初のスキャンを検索モードで実行する準備ができました。 詳細については、「探索サイクルの実行とスキャナーのレポートの表示」を参照してください。
最初の検出スキャンを実行済みの場合は、引き続きスキャナーを構成して分類と保護を適用します。
スキャナーを構成して分類と保護を適用する
既定の設定では、スキャナーが 1 回だけ、レポート専用モードで実行されるように構成されています。
これらの設定を変更するには、コンテンツ スキャン ジョブを編集します。
Azure portal の [Azure Information Protection - コンテンツ スキャン ジョブ] ペインで、クラスターとコンテンツ スキャン ジョブを選択して編集します。
[コンテンツ スキャン ジョブ] ペインで、次のように変更し、[保存] を選択します。
- [コンテンツ スキャン ジョブ] セクション: [スケジュール] を [常時] に変更します
- [機密ポリシー] セクション: [適用] を [オン] に変更します
ヒント
ファイルの属性を変更するかどうかや、スキャナーがファイルのラベルを変更できるかどうかなど、このペインで他の設定を変更することもできます。 情報のポップアップ ヘルプを使って、各構成設定について詳しく学習してください。
現在の時刻をメモして、[Azure Information Protection - コンテンツ スキャン ジョブ] ペインからもう一度スキャナーを起動します。

または、PowerShell セッションで次のコマンドを実行します。
Start-AIPScanラベルが付けられたファイル、適用された分類、保護が適用されたかどうかを含むレポートを表示するには、イベント ログで情報の種類 911 と最新のタイム スタンプを監視します。
詳細についてはレポートを確認するか、Azure portal を使用してこの情報を検索してください。
これで、スキャナーが継続的に実行されるようにスケジュールされました。 スキャナーは、構成されたすべてのファイルを介して動作するときに、新しいファイルと変更されたファイルが検出されるように、新しいサイクルを自動的に開始します。
保護するファイルの種類を変更する
既定では、AIP スキャナーは Office ファイルの種類と PDF ファイルのみを保護します。 この動作を変更する、たとえば、クライアントと同様にすべてのファイルの種類を保護したり、特定の付加的なファイルの種類を保護したりするようにスキャナーを構成するには、レジストリを次のように編集します。
- 保護する追加のファイルの種類を指定します
- 適用する保護の種類を指定します (ネイティブまたは汎用)
この開発者向けドキュメントでは、汎用的な保護は "PFile" と呼ばれています。
サポートされているファイルの種類をクライアントと合わせ、すべてのファイルがネイティブまたは汎用保護で自動的に保護されるようにするには:
指定:
- レジストリ キーとして
*ワイルドカード - 値として
Encryption(REG_SZ) - 値のデータとして
Default
- レジストリ キーとして
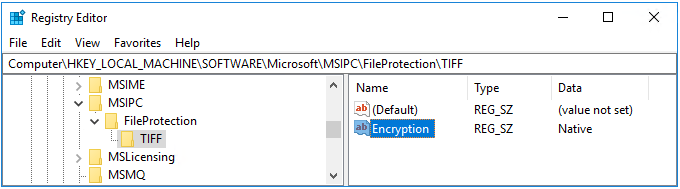
MSIPC および FileProtection キーが存在するかどうかを確認します。 存在しない場合は手動で作成し、ファイル名拡張子ごとにサブキーを作成します。
たとえば、Office ファイルと PDF だけでなく、TIFF イメージも保護するスキャナーの場合、レジストリの編集後は、次の図のようになります。
注意
イメージ ファイルなので、TIFF ファイルではネイティブ保護がサポートされ、結果としてファイル名拡張子は .ptiff になります。
ネイティブ保護がサポートされていないファイルの場合は、新しいキーとしてファイル名拡張子を指定し、汎用的な保護のために PFile を指定します。 結果として、保護されるファイルのファイル名拡張子は .pfile になります。
同様に、ネイティブ保護はサポートされていても、レジストリで指定する必要があるテキスト ファイルとイメージ ファイルの種類の一覧については、「分類と保護がサポートされているファイルの種類」をご覧ください。
スキャナーのアップグレード
スキャナーを以前にインストールしていてアップグレードする場合は、「Azure Information Protection スキャナーのアップグレード」を参照してください。
その後は、通常どおりにスキャナーを構成して使用します。スキャナーをインストールする手順はスキップします。
注意
1.48.204.0 よりも前のバージョンのスキャナーを使用していて、アップグレードする準備ができていない場合は、「ファイルを自動的に分類して保護するために以前のバージョンの Azure Information Protection スキャナーを展開する」を参照してください。
データ リポジトリ設定の一括編集
複数のリポジトリでスキャナーを変更するには、[エクスポート] ボタンと [インポート] ボタンを使用します。
このように、Azure portal で同じ変更を何度も手動で行う必要はありません。
たとえば、複数の SharePoint データ リポジトリに新しいファイルの種類がある場合は、それらのリポジトリの設定を一括で更新できます。
リポジトリ間で一括で変更を行うには:
Azure portal の [リポジトリ] ペインで、[エクスポート] オプションを選択します。 次に例を示します。

エクスポートしたファイルを手動で編集して変更します。
同じページの [インポート] オプションを使用して、リポジトリ全体に更新をインポートします。
代替構成でのスキャナーの使用
通常、Azure Information Protection スキャナーは、必要に応じてコンテンツを分類および保護するために、ラベルに指定された条件を検索します。
次のシナリオでは、Azure Information Protection スキャナーは、条件を構成せずにコンテンツをスキャンし、ラベルを管理することもできます。
データ リポジトリ内のすべてのファイルに既定のラベルを適用する
この構成では、リポジトリ内のすべてのラベル付けされていないファイルに、リポジトリまたはコンテンツ スキャン ジョブに指定された既定のラベルが付けられます。 ファイルは検査なしでラベル付けされます。
次の設定を構成します。
- [コンテンツに基づいてファイルにラベルを付ける]: [オフ] に設定します
- [既定のラベル]: [カスタム] に設定し、使用するラベルを選択します
すべてのカスタム条件と既知の機密情報の種類を特定する
この構成により気付かない可能性がある機密情報を発見できますが、スキャナーのスキャン速度が犠牲になります。
[検出する情報の種類] を [すべて] に設定します。
ラベル付けの条件と情報の種類を識別するために、スキャナーでは、ラベルに指定されたカスタム条件と、Azure Information Protection ポリシーに示されている、ラベルに指定できる情報の種類の一覧を使用します。
詳細については、「クイック スタート: オンプレミスに格納しているファイル内の機密情報を検索する」を参照してください。
スキャナーのパフォーマンスの最適化
注意
スキャナーのパフォーマンスではなくスキャナー コンピューターの応答性を向上させる場合は、クライアントの詳細設定を使用してスキャナーで使用されるスレッドの数を制限します。
スキャナーのパフォーマンスを最適化するには、次のオプションとガイダンスを使用します。
| オプション | 説明 |
|---|---|
| スキャナー コンピューターとスキャンされたデータ ストア間のネットワーク接続を高速かつ信頼性の高い接続にする | たとえば、スキャンされたデータ ストアと同じ LAN 内または同じネットワーク セグメント内 (推奨) にスキャナー コンピューターを配置します。 ネットワーク接続の品質は、スキャナーがスキャナー サービスを実行しているコンピューターにファイルのコンテンツを転送してファイルを検査するため、スキャナーのパフォーマンスに影響します。 データの移動に必要なネットワーク ホップを減らすか、削除することによっても、ネットワークの負荷が軽減されます。 |
| スキャナー コンピューターに利用可能なプロセッサ リソースがあることを確認する | ファイル コンテンツの検査およびファイルの暗号化と復号化は、プロセッサ負荷の高いアクションです。 プロセッサ リソースの不足がスキャナー パフォーマンスを低下させているかどうかを識別するには、指定したデータ ストアの標準のスキャン サイクルを監視します。 |
| スキャナーの複数のインスタンスをインストールする | Azure Information Protection スキャナーでは、スキャナーのカスタム クラスター (プロファイル) 名を指定するときに同じ SQL Server インスタンス上の複数の構成データベースがサポートされます。 |
| 特定の権限を付与し、低い整合性レベルを無効にする | スキャナーを実行するサービス アカウントに、「サービス アカウントの要件」に記載されている権限のみが付与されていることを確認します。 次に、高度なクライアント設定を構成して、スキャナーの低整合性レベルを無効にします。 |
| 代替構成の使用状況を確認する | 代替構成を使ってすべてのファイルに既定のラベルを適用すると、ファイル内容の検査がスキップされるため、スキャナーの実行速度が速くなります。 代替構成を使ってすべてのカスタム条件と既知の機密情報の種類を特定すると、スキャナーの実行速度が遅くなりなります。 |
| スキャナーのタイムアウトを減らす | クライアントの詳細設定を使用して、スキャナーのタイムアウトを減らします。スキャナーのタイムアウトを小さくすると、スキャン速度が向上し、メモリ使用量が少なくなります。 注: スキャナーのタイムアウトを減らすと、一部のファイルがスキップされる可能性があります。 |
パフォーマンスに影響を与えるその他の要因
スキャナーのパフォーマンスに影響を与えるその他の要因は次のとおりです。
| 要素 | 説明 |
|---|---|
| 読み込み/応答時間 | スキャンするファイルを含むデータ ストアの現在の読み込みおよび応答時間もスキャナーのパフォーマンスに影響します。 |
| スキャナー モード (検出/適用) | 検出モードは通常、適用モードよりもスキャン速度が高くなります。 検出には 1 つのファイル読み取りアクションが必要ですが、適用モードでは読み取りおよび書き込みアクションが必要です。 |
| ポリシーの変更 | Azure Information Protection ポリシーの条件を変更した場合、スキャナーのパフォーマンスが影響を受ける可能性があります。 スキャナーがすべてのファイルを検査する必要がある場合、最初のスキャン サイクルには、既定では新規および変更されたファイルのみを検査する後続のスキャン サイクルよりも、長い時間がかかります。 条件を変更すると、すべてのファイルが再度スキャンされます。 詳細については、「ファイルを再スキャンする」を参照してください。 |
| 正規表現の構築 | スキャナーのパフォーマンスは、カスタム条件の正規表現の構築方法によって影響を受けます。 メモリの大量消費とタイムアウト (1 ファイルあたり 15 分) のリスクを回避するには、ご利用の正規表現式を確認して効率的なパターン マッチングが行われているかを確認してください。 例: - 最長一致の量指定子を避けます - (expression) ではなく、(?:expression) などの非キャプチャ グループを使用します |
| ログ レベル | スキャナー レポートに対するログ レベルのオプションには、[デバッグ]、[情報]、[エラー]、[オフ] があります。 - [オフ] を選択すると、最適なパフォーマンスになります。 - [デバッグ] は大幅にスキャナーのスピードを低下させるので、トラブルシューティング時にのみ使用してください。 詳細については、Set-AIPScannerConfiguration コマンドレットの ReportLevel パラメーターを参照してください。 |
| スキャンされるファイル | - Excel ファイルを除き、Office ファイルは PDF ファイルよりも短時間でスキャンされます。 保護されていないファイルは、保護されたファイルよりもすばやくスキャンされます。 大きいファイルは明らかに小さいファイルよりも時間がかかります。 |
スキャナーのコマンドレットの一覧
このセクションでは、Azure Information Protection スキャナーでサポートされている PowerShell コマンドレットの一覧を示します。
注意
Azure Information Protection スキャナーは、Azure portal から構成されます。 このため、以前のバージョンで使用されていた、データリポジトリとスキャンされるファイルの種類の一覧を構成するコマンドレットは非推奨となりました。
スキャナーでサポートされているコマンドレットは次のとおりです。
次の手順
スキャナーのインストールと構成が完了したら、ファイルのスキャンを開始します。
「Azure Information Protection スキャナーをデプロイして、ファイルを自動的に分類して保護する」も参照してください。
詳細情報:
Microsoft の Core Services Engineering と Operations チームがどのようにこのスキャナーを実装したかについて関心をお持ちですか。 テクニカル ケース スタディ「Automating data protection with Azure Information Protection scanner」(Azure Information Protection スキャナーを使用したデータ保護の自動化) をご覧ください。
Windows Server FCI と Azure Information Protection スキャナーの違いについてご説明します。
また、PowerShell を使用して、デスクトップ コンピューターからファイルを対話的に分類し、保護することができます。 これに関する詳細および PowerShell を使用するその他のシナリオについては、「Azure Information Protection クライアントでの PowerShell の使用」をご覧ください。