Azure AI Search 内のナレッジ ストア
ナレッジ ストアは、Azure AI 検索のスキルセットによって作成された AI でエンリッチされたコンテンツのセカンダリ ストレージです。 Azure AI 検索では、インデックス作成ジョブは常に出力を検索インデックスに送信しますが、インデクサーにスキルセットをアタッチする場合は、必要に応じて、Azure Storage のコンテナーまたはテーブルに AI でエンリッチされた出力を送信することもできます。 ナレッジ ストアは、ナレッジ マイニングなど、検索以外のシナリオでの独立した分析とダウンストリーム処理に使用できます。
インデックス作成の 2 つの出力 (検索インデックスとナレッジ ストア) は、同じパイプラインの相互に排他的な製品です。 これらは同じ入力から派生し、同じデータを含んでいますが、そのコンテンツは構造化され、保存され、さまざまなアプリケーションで使用されます。

物理的には、ナレッジ ストアは Azure Storage です。つまり Azure Table Storage か Azure Blob Storage、またはその両方になります。 Azure Storage に接続できるすべてのツールまたはプロセスは、ナレッジ ストアのコンテンツを使用できます。 Azure AI 検索では、ナレッジ ストアからコンテンツを取得するためのクエリのサポートはありません。
Azure portal から表示すると、ナレッジ ストアは他のテーブル、オブジェクト、またはファイルのコレクションと同じように見えます。 次のスクリーンショットは、3 つのテーブルで構成されるナレッジ ストアを示しています。 kstore プレフィックスなどの名前付け規則を採用して、コンテンツをまとめておくことができます。
ナレッジ ストアのメリット
ナレッジ ストアの主な利点は、コンテンツに柔軟にアクセスできることと、データを形成する機能という 2 つの点にあります。
Azure AI 検索のクエリを介してアクセスする必要がある検索インデックスとは異なり、ナレッジ ストアには、Azure Storage への接続をサポートする任意のツール、アプリ、プロセスからアクセスできます。 この柔軟性によって、エンリッチメント パイプラインによって生成された、分析およびエンリッチメントされたコンテンツを消費するための新しいシナリオが開きます。
データをエンリッチする同じスキルセットを、データの形成にも使用できます。 Power BI のようなツールは、テーブルの方が適していますが、データ サイエンス ワークロードには BLOB 形式の複雑なデータ構造が必要になる場合があります。 スキルセットに Shaper スキルを追加すると、データのシェイプを制御できるようになります。 そして、このシェイプをテーブルや BLOB などのプロジェクションに渡すことで、データの使用目的に沿った物理的なデータ構造を作成することができます。
次のビデオでは、これらの利点の両方について説明します。
ナレッジ ストアの定義
ナレッジ ストアは、スキルセット定義内で定義されており、2 つのコンポーネントがあります。
Azure ストレージの接続文字列
ナレッジ ストアがテーブル、オブジェクト、ファイルのいずれで構成されているかを決定するプロジェクション。 プロジェクション要素は配列です。 1 つのナレッジ ストア内に、テーブル、オブジェクト、ファイルの組み合わせを複数セット作成することができます。
"knowledgeStore": { "storageConnectionString":"<YOUR-AZURE-STORAGE-ACCOUNT-CONNECTION-STRING>", "projections":[ { "tables":[ ], "objects":[ ], "files":[ ] } ] }
この構造体で指定するプロジェクションの種類は、ナレッジ ストアが使用するストレージの種類を決定しますが、その構造体は決定しません。 テーブル、オブジェクト、およびファイルのフィールドは、ナレッジ ストアをプログラムで作成する場合は Shaper スキルの出力によって決定され、ポータルを使用している場合はデータのインポート ウィザードによって決定されます。
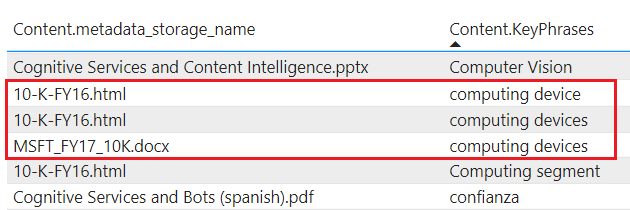
tablesは、エンリッチメントされたコンテンツを Table Storage に投影します。 分析ツールへの入力のために表形式のレポート構造が必要な場合や、データ フレームとして他のデータ ストアにエクスポートする場合は、テーブル プロジェクションを定義します。 同じプロジェクション グループ内の複数のtablesを指定して、エンリッチメントされたドキュメントのサブセットまたは断面を取得することができます。 同じプロジェクション グループ内では、テーブルのリレーションシップが保持されるため、すべてのテーブルを操作できます。プロジェクションされたコンテンツは集計または正規化されません。 次のスクリーンショットは、キー フレーズで並べ替えられたテーブルを示しており、隣接する列に親ドキュメントが示されています。 インデックス作成中のデータ インジェストとは対照的に、言語分析やコンテンツの集計はありません。 複数形と大文字と小文字の違いは、一意のインスタンスと見なされます。
objectsでは、JSON ドキュメントを BLOB ストレージに投影します。objectの物理的表現は、エンリッチメントされたドキュメントを表す階層型の JSON 構造体です。filesでは、イメージ ファイルを BLOB ストレージに投影します。fileは、ドキュメントから抽出され、BLOB ストレージにそのまま転送されるイメージです。 "ファイル" という名前ですが、ファイル ストレージではなく Blob Storage に表示されます。
ナレッジ ストアの作成
ナレッジ ストアを作成するには、ポータルまたは API を使用します。
Azure Storage、スキルセット、インデクサーが必要になります。 インデクサーには検索インデックスが必要なので、インデックス定義も指定する必要があります。
完成したナレッジ ストアへの最短ルートとしては、ポータル アプローチを採用してください。 または、オブジェクトがどのように定義され、関連しているかをより深く理解するには、REST API を選択します。
データのインポート ウィザードを使用して、4 つの手順で最初のナレッジ ストアを作成します。
エンリッチするデータを含むデータ ソースを定義します。
スキルセットを定義します。 スキルセットにより、エンリッチメント ステップとナレッジ ストアが指定されます。
インデックス スキーマを定義します。 これは必要ない場合もありますが、インデクサーでは必要です。 このウィザードではインデックスを推測できます。
ウィザードの完了。 この最後のステップで、抽出、エンリッチメント、ナレッジ ストアの作成が行われます。
このウィザードを使用すると、いくつかのタスクを自動化できます。 具体的には、整形とプロジェクションの両方 (Azure Storage 内の物理データ構造の定義) が作成されます。
アプリに接続する
エンリッチされたコンテンツがストレージに存在するようになると、Azure Blob に接続する任意のツールまたはテクノロジを使用して、コンテンツを探索、分析、または使用できます。 次の一覧が開始点です。
エンリッチされたドキュメント構造とコンテンツを表示するための Azure portal の Storage Explorer またはストレージブラウザー (プレビュー)。 これは、ナレッジ ストアのコンテンツを表示するためのベースライン ツールと考えてください。
レポートと分析のための Power BI。
さらに操作するための Azure Data Factory。
コンテンツのライフサイクル
インデクサーとスキルセットを実行するたび、スキルセットまたは基になるソース データが変更された場合、ナレッジ ストアが更新されます。 インデクサーによって取得された変更は、エンリッチメント プロセスを通じてナレッジ ストア内のプロジェクションに反映され、投影されたデータが元のデータ ソース内のコンテンツの現在の表現になります。
Note
プロジェクション内のデータを編集することができますが、ソース データ内のドキュメントが更新された場合、次のパイプライン呼び出しですべての編集が上書きされます。
ソース データの変更
変更の追跡をサポートするデータ ソースの場合、インデクサーは新規および変更されたドキュメントを処理し、既に処理されている既存のドキュメントをバイパスします。 タイムスタンプ情報はデータ ソースによって異なりますが、BLOB コンテナーでは、インデクサーによって lastmodified の日付が確認され、取り込む必要がある BLOB が特定されます。
スキルセットの変更
スキルセットに変更を加える場合は、エンリッチされたドキュメントのキャッシュを有効にして、可能な限り既存のエンリッチメントを再利用する必要があります。
増分キャッシュを使用しない場合、インデクサーは常に高いウォーター マークの順に逆戻りせずドキュメントを処理します。 BLOB の場合、インデクサーは、インデクサーの設定やスキルセットに対する変更に関係なく、lastModified で並べ替えた BLOB を処理します。 スキルセットを変更した場合、以前に処理されたドキュメントは、新しいスキルセットを反映するように更新されません。 スキルセットの変更後に処理されたドキュメントでは新しいスキルセットが使用され、その結果、インデックス ドキュメントには古いスキルセットと新しいスキルセットが混在します。
増分キャッシュを使用する場合、スキルセットの更新後に、インデクサーはスキルセットの変更の影響を受けないエンリッチメントを再利用します。 アップストリーム エンリッチメントは、変更されたスキルから独立して分離されたエンリッチメントと同様に、キャッシュからプルされます。
削除
インデクサーは、Azure Storage 内の構造とコンテンツを作成および更新しますが、それらを削除しません。 インデクサーまたはスキルセットが削除された場合でも、プロジェクションは引き続き存在します。 ストレージ アカウントの所有者は、不要になったプロジェクションを削除する必要があります。
次のステップ
ナレッジ ストアは、エンリッチメントされたドキュメントを永続化する手段として、スキルセットを設計する際に役立つほか、Azure Storage アカウントにアクセスする機能を備えた、あらゆるクライアント アプリケーションから利用する新しい構造やコンテンツを作成する際にも役立てることができます。
エンリッチされたドキュメントを作成する最も簡単なアプローチは、ポータルを使用することですが、REST クライアントと REST API の方が、オブジェクトがプログラムでどのように作成され、参照されるのかについて深く理解することができます。