Azure Service Fabric でのディザスター リカバリー
高可用性を実現するうえで欠かせないのは、サービスがあらゆる種類の障害を切り抜けられるようにすることです。 これは、計画外の障害や、制御できない障害に関しては特に重要です。
この記事では、正しくモデル化および管理されていない場合に、災害につながる可能性がある一般的な障害モードをいくつか取り上げて説明します。 さらに、軽減策や災害発生時の対処方法についても解説します。 その目的は、計画的または計画外の障害時に、ダウンタイムやデータ損失のリスクを軽減または排除することです。
災害の回避
Azure Service Fabric の主な目的は、一般的な障害が災害につながらないように、環境とサービスの両方をモデル化できるよう支援することです。
一般的に、災害/障害のシナリオには 2 つの種類があります。
- ハードウェアおよびソフトウェアのエラー
- 操作上のエラー
ハードウェアおよびソフトウェアのエラー
ハードウェアとソフトウェアのエラーは予測できません。 障害を最も簡単に切り抜けるには、ハードウェアまたはソフトウェアのエラーの境界で、より多くのサービス コピーを実行します。
たとえば、サービスが 1 台のマシンでのみ実行されている場合、そのマシンで障害が発生するということは、サービスで災害が発生するということです。 この災害は、サービスを複数のマシンで実行することによって、簡単に回避できます。 1 台のマシンの障害によって実行中のサービスが中断しないように、テストを行う必要もあります。 容量計画によって置換インスタンスを他の場所に作成すれば、容量が減っても、残りのサービスが過負荷になりません。
このパターンは、回避しようとしている障害の種類にかかわらず有効です。 たとえば、SAN の障害が心配であれば、複数の SAN で実行します。 サーバー ラックの損失が心配であれば、複数のラックで実行します。 データセンターの損失が心配であれば、複数の Azure リージョン、複数の Azure Availability Zones、またはご自身のデータセンターでサービスを実行します。
サービスが複数の物理インスタンス (マシン、ラック、データセンター、リージョン) にまたがっていても、同時に発生する一部の障害の影響はまだ受けます。 ただし、1 つの障害と、種類によっては複数の障害 (1 つの仮想マシンまたはネットワーク リンクの障害など) については自動的に処理されるため、これはもはや "災害" ではありません。
Service Fabric には、クラスターを拡張するメカニズムが用意されており、障害が発生したノードとサービスを元に戻します。 また、計画外の障害が本当の意味での災害にならないように、Service Fabric では、サービスのインスタンスを多数実行できます。
障害に対応できる規模でのデプロイを実現できないのには理由があるのでしょう。 たとえば、ハードウェア リソースのコストが、障害が発生する可能性を考えたときに、惜しまずに支払える金額を超えているのかもしれません。 分散アプリケーションを扱う場合は、地理的に離れた場所における追加の通信ホップまたは状態レプリケーション コストにより、許容できない待機時間が発生することがあります。 この線引きはアプリケーションごとに異なります。
特にソフトウェア エラーについては、スケールしようとしているサービスでエラーが発生している可能性があります。 この場合、コピーを増やしても災害を防ぐことはできません。障害の状態が、すべてのインスタンス間で相互に関連付けられているためです。
操作上のエラー
サービスが世界規模で分散され、あらゆる冗長性が実現されていても、災害を引き起こすイベントは発生します。 たとえば、ユーザーは誤ってサービスの DNS 名を再構成したり、完全に削除したりすることがあります。
ステートフルな Service Fabric サービスがあり、誰かがそのサービスを誤って削除したとします。 軽減策がなければ、サービスとそのサービスの状態はすべて失われます。 こうした種類の操作上の災害 ("不測") には、通常の計画外の障害とは異なる復旧対策と手順が必要です。
このような操作上のエラーを回避する最善の方法を次に示します。
- 環境への作業のためのアクセスを制限する。
- 危険な操作を厳密に監査する。
- 自動化を実施し、手動または帯域外の変更を防止するほか、環境に対する特定の変更を適用前に検証する。
- 破壊的な操作が "ソフト" であるようにする。ソフト操作はすぐには有効にならないか、一定の時間内に元に戻すことができます。
Service Fabric には、クラスター操作に対するロールベースのアクセス制御など、操作上のエラーを回避するためのメカニズムが用意されています。 ただし、このような操作上のエラーのほとんどでは、組織的な取り組みと他のシステムが必要です。 Service Fabric には、操作上のエラーを切り抜けるためのメカニズムが用意されています。中でもよく知られているのは、ステートフル サービスのバックアップと復元です。
障害の管理
Service Fabric では、障害を自動管理することを目標としています。 ただし、障害の中には、処理するために、追加コードがサービスに必要な場合があります。 また、安全性とビジネス継続性の理由により、自動的に対処するべき "ではない" 種類の障害もあります。
1 つの障害への対処
1 台のマシンで障害が発生する理由はさまざまです。 たとえば、電源やネットワーク ハードウェアの障害など、ハードウェアが原因の場合があります。 また、ソフトウェアが原因であることもあります。 これにはオペレーティング システムとサービス自体の障害が含まれます。 Service Fabric では、ネットワークの問題によりマシンが他のマシンから切り離されている、といった状況を含め、このような障害が自動的に検出されます。
サービスの種類に関係なく、実行されているインスタンスが 1 つだと、そのコードの 1 つのコピーが何らかの理由で失敗した場合に、そのサービスでダウンタイムが発生します。
すべての障害に対して最も簡単に対応するには、ご自身のサービスを、既定で、複数のノードで実行するようにします。 ステートレス サービスの場合は、InstanceCount が 1 よりも大きな値であることを確認します。 ステートフル サービスの場合、推奨最小値は、TargetReplicaSetSize と MinReplicaSetSize 両方が 3 に設定されています。 サービス コードのコピーを複数実行すると、サービスによって、すべての障害が確実に自動処理されます。
組織的障害への対処
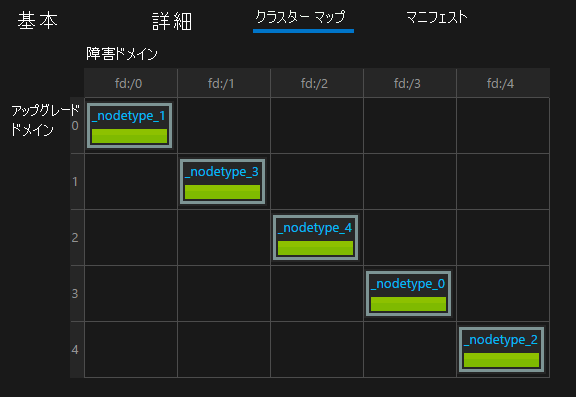
クラスター内での組織的障害の原因は、計画的または計画外インフラストラクチャ障害と変更、または計画的ソフトウェア変更のいずれかです。 Service Fabric は、組織的障害が発生しているインフラストラクチャ ゾーンを、"障害ドメイン" としてモデル化します。 組織的ソフトウェア変更が発生する領域は、"アップグレード ドメイン" としてモデル化されます。 障害ドメイン、アップグレード ドメイン、およびクラスター トポロジの詳細については、「クラスター リソース マネージャーを使用して Service Fabric クラスターを記述する」を参照してください。
既定では、Service Fabric は、障害ドメインとアップグレード ドメインを考慮して、サービスを実行する場所を計画します。 また、Service Fabric では、既定で複数の障害ドメインとアップグレード ドメインにわたってサービスを実行しようとするため、計画的または計画外変更が発生しても、サービスは使用可能な状態のままです。
たとえば、電源の障害により、ラック上のすべてのマシンで同時に障害が発生したとします。 サービスの複数のコピーが実行されているため、障害ドメインでの多数のマシンの喪失は、サービスに対する単一障害の別の一例に過ぎません。 障害およびアップグレード ドメインの管理が、サービスの高可用性の確保に欠かせないのはこのためです。
Azure で Service Fabric を実行している場合、障害ドメインおよびアップグレード ドメインは自動的に管理されます。 他の環境では、そうではない可能性があります。 オンプレミスで独自のクラスターを作成する場合は、障害ドメインのレイアウトを必ず正しく計画し、マップしてください。
アップグレード ドメインは、ソフトウェア アップグレードを同時に実行する領域をモデル化するときに役に立ちます。 このため、アップグレード ドメインは、多くの場合、計画的アップグレード中にソフトウェアが停止される境界も定義します。 Service Fabric とサービスの両方のアップグレードが同じモデルに従います。 ローリング アップグレード、アップグレード ドメイン、および予期しない変更による影響をクラスターとサービスが受けないようにするうえで役立つ Service Fabric 正常性モデルの詳細については、以下を参照してください。
Service Fabric Explorer で提供されるクラスター マップを使用して、クラスターのレイアウトを視覚化できます。
Note
障害領域のモデル化、ローリング アップグレード、サービス コードと状態の多くのインスタンスの実行、障害ドメインとアップグレード ドメインでサービスを確実に実行するための配置ルール、および組み込みの正常性の監視は、通常の操作上の問題や障害が災害につながるのを未然に防ぐために、Service Fabric に用意されている機能の "一部" にすぎません。
ハードウェアまたはソフトウェアの同時障害への対処
ここまでは 1 つの障害について説明しました。 おわかりのように、この障害は、障害ドメインとアップグレード ドメインで実行されているコード (および状態) のコピーを複数保持するだけで、ステートレス サービスとステートフル サービスの両方を簡単に処理できます。
複数の障害がランダムに同時発生することがあります。 こうした障害は、ダウンタイムまたは実際の災害につながる可能性が高くなります。
ステートレス サービス
ステートレス サービスの インスタンス数は、実行されている必要のある望ましいインスタンス数を示します。 いずれか (またはすべて) のインスタンスに障害が発生すると、その対応として、Service Fabric は自動的に置換インスタンスを他のノード上に作成します。 Service Fabric は、サービスのインスタンス数が望ましい数に戻るまで、置換インスタンスを作成し続けます。
たとえば、ステートレス サービスの InstanceCount が -1 だとします。 この値は、クラスター内の各ノード上で 1 つのインスタンスが実行されている必要があることを意味します。 そのいずれかのインスタンスに障害が発生した場合、Service Fabric はサービスが望ましい状態になっていないことを検出し、インスタンスが不足しているノード上にインスタンスを作成しようと試みます。
ステートフル サービス
ステートフル サービスには、次の 2 種類があります。
- 状態が永続化されるステートフル。
- 状態が永続化されないステートフル (状態はメモリに格納される)。
ステートフル サービスの障害復旧は、ステートフル サービスの種類、サービスに存在するレプリカの数、および障害の発生したレプリカの数によって異なります。
ステートフル サービスでは、レプリカ (プライマリと任意のアクティブ セカンダリ) 間で受信データがレプリケートされます。 レプリカの過半数がデータを受信した場合、データは "クォーラム" コミットされていると見なされます (5 つのレプリカなら 3 がクォーラム)。つまり、どの時点でも、少なくとも最新のデータを持つレプリカのクォーラムが存在することになります。 レプリカに障害が発生した場合は (たとえば 5 つのレプリカのうち 2 つに障害が発生した場合は)、クォーラム値を使用して、復旧できるかどうかを計算できます (5 つのレプリカのうち残り 3 つはまだ稼動状態であるため、少なくとも 1 つのレプリカに完全なデータが存在することが保証されます)。
レプリカのクォーラムで障害が発生すると、パーティションは、"クォーラム損失" 状態で宣言されます。 たとえば、パーティションに 5 つのレプリカがあるとします。つまり、少なくとも 3 つのレプリカに完全なデータがあることが保証されるということです。 レプリカのクォーラム (5 つのうち 3 つ) で障害が発生した場合、残りのレプリカ (5 つのうち 2 つ) にパーティションを復元できるだけのデータがあるかどうかは、Service Fabric には判断できません。 クォーラム損失を検出した Service Fabric は、既定では、パーティションへの追加の書き込みを防止し、クォーラム損失を宣言して、レプリカのクォーラムが復元されるのを待ちます。
ステートフル サービスについて災害が発生したかどうかを判断し、それを管理するプロセスは、3 つの段階に従って実行されます。
クォーラムの損失があるかどうかを確認する。
ステートフル サービスのレプリカの過半数が同時にダウンしているときは、クォーラム損失が宣言されます。
クォーラムの損失が永続的かどうかを確認する。
ほとんどの場合、障害は一時的なものです。 プロセス、ノード、仮想マシンが再起動され、ネットワーク パーティションは修復します。 ただし、障害が永続的である場合もあります。 障害が永続的かどうかは、ステートフル サービスによって、状態が維持されるかどうか、または状態がメモリ内にのみ保持されるかどうかによって異なります。
- 永続化状態でないサービスの場合、クォーラムまたはレプリカで障害が発生すると、"直ちに" 永続的なクォーラム損失が発生します。 Service Fabric は、非永続的なステートフル サービスでクォーラムの損失を検出すると、(潜在的な) データ損失を宣言することによって直ちに手順 3. に処理を進めます。 Service Fabric にとって、レプリカの復旧を待っても無駄であることは自明であるため、データ損失として処理を進めることは理にかなっています。 復旧されたとしても、非永続というサービスの性質上、データは失われます。
- 永続的なステートフル サービスの場合、クォーラム以上のレプリカで障害が発生すると、Service Fabric は、レプリカが復旧してクォーラムが復元するのを待ちます。 これにより、影響を受けるサービス パーティション ("レプリカ セット") に対するすべての "書き込み" でサービス停止が発生します。 ただし、一貫性の保証は少なくなりますが、読み取りはまだ可能です。 続行することは (潜在的な) データ損失イベントであり、他のリスクを伴うため、Service Fabric がクォーラムの復元を待つ既定の時間は "無制限" です。 つまり、管理者がデータ損失を宣言するアクションを実行しない限り、Service Fabric が次の手順に進むことはありません。
実際にデータが損失したかどうかを確認し、バックアップから復元する。
クォーラム損失が (自動的に、または管理アクションによって) 宣言された場合、Service Fabric とサービスは、データが実際に損失したかどうかの確認に進みます。 この時点で、Service Fabric は、他のレプリカが戻らないこともわかっています。 これは、クォーラム損失が解決されるのを待つことをやめたとき行われた決定です。 サービスに対する最善なアクションは、通常、アクションを凍結し、特定の管理介入を待つことです。
Service Fabric が
OnDataLossAsyncメソッドを呼び出す場合、それは常に、データ損失の "疑いがある" ためです。 Service Fabric により、この呼び出しは確実に "最適" な残りのレプリカに配信されます。 これは、最も進捗しているレプリカです。常に、データ損失の "疑いがある" のは、クォーラムが損失したときのプライマリの状態と、残りのレプリカがまったく同じ状態である可能性がある、ということが理由です。 しかし、比較対象となる状態がなければ、Service Fabric やオペレーターが適切な方法でそれを確信することはできません。
では、
OnDataLossAsyncメソッドの一般的な実装では何を行うのでしょう。実装は、
OnDataLossAsyncがトリガーされたことがログに記録し、必要な管理アラートを起動します。通常、実装は一時停止され、さらなる決定と、手動アクションが実行されるのを待ちます。 これは、バックアップを使用できる場合でも、準備が必要な可能性があるためです。
たとえば、2 つの異なるサービスで情報を調整する場合、復元後に、その 2 つのサービスに関連する情報の一貫性を確保するために、こうしたバックアップの変更が必要になることがあります。
多くの場合、サービスの他のテレメトリや消費データが存在します。 このメタデータは、他のサービスまたはログに含まれている可能性があります。 この情報を必要に応じて使用し、バックアップに存在しない呼び出し、またはこの特定のレプリカにレプリケートされなかった呼び出しが、プライマリで受信および処理されたかどうかを判断します。 復元を実現するには、これらの呼び出しを再生するか、バックアップに追加しなければならないことがあります。
実装は、残りのレプリカの状態と、使用できるバックアップに含まれるものを比較します。 Service Fabric の信頼できるコレクションを使用している場合、このためのツールやプロセスを入手できます。 その目的は、レプリカ内の状態が十分かどうか、およびバックアップで何が不足している可能性があるかを確認することです。
比較の完了後、(必要に応じて) 復元が行われ、その後に状態が変更されると、サービス コードは true を返します。 レプリカが使用可能な最善の状態のコピーであると判断された場合、変更は行われず、コードは false を返します。
true の値は、"他" の残りのレプリカが、このレプリカと整合性がとれていない可能性があることを示します。 残りのレプリカは削除され、このレプリカから再作成されます。 false は、状態の変更は行われていないため、他のレプリカをそのまま保持できることを意味します。
サービスが運用環境にデプロイされる前に、サービス作成者が潜在的なデータ損失と障害のシナリオを実施することが非常に重要です。 データ損失の可能性から保護するには、すべてのステートフル サービスの geo 冗長ストアへの状態のバックアップを定期的に行うことが重要です。
また、状態を復元する機能を確保する必要もあります。 さまざまなサービスのバックアップがそれぞれ異なるタイミングで行われるため、復元後、こうしたサービスのビューが相互に一貫性があることを確認する必要があります。
たとえば、あるサービスが数値を生成して格納し、その数値を他のサービスに送信したとします。送信先のサービスも、受け取った数値を格納します。 復元後、2 番目のサービスに数値があり、最初のサービスにはないことに気が付きました。これはバックアップに、この操作が含まれていなかったためです。
残りのレプリカがデータ損失のシナリオで続行するには不十分なことがわかり、サービスの状態をテレメトリまたは消費データから再構成できない場合は、バックアップの頻度によって、可能性のある最適な目標復旧時点 (RPO) が決定されます。 Service Fabric には、バックアップからの復元を必要とする永続的なクォーラムやデータ損失を含め、さまざまな障害のシナリオをテストするための多数のツールが用意されています。 こうしたシナリオは、Fault Analysis Service によって管理される、Service Fabric の Testability ツールに含まれています。 ツールとパターンの詳細については、「Fault Analysis Service の概要」を参照してください。
Note
システム サービスでもクォーラム損失が発生する可能性があり、 その影響は問題のあるサービスに固有です。 たとえば、ネーム サービスでのクォーラム損失は名前解決に影響があり、Failover Manager サービスでクォーラム損失が発生すると、新しいサービスの作成とフェールオーバーがブロックされます。
Service Fabric システム サービスは状態管理のためのサービスと同じパターンに従いますが、それらをクォーラム損失から潜在的なデータ損失に移動しようとすることはお勧めしません。 代わりに、サポートを利用して、個別の状況に合ったソリューションを見つけることをお勧めします。 通常は、ダウンしたレプリカが復旧するまで待つのがよいでしょう。
クォーラム損失のトラブルシューティング
一時的な障害によってレプリカが断続的にダウンすることがあります。 このような場合は、Service Fabric が復旧を試みるので、しばらくお待ちください。 レプリカがダウンしたまま所定の時間が経過した場合は、次のトラブルシューティング手順に従います。
- レプリカがクラッシュしている可能性があります。 レプリカ レベルの正常性レポートおよびアプリケーション ログをチェックしてください。 クラッシュ ダンプを収集し、復元のために必要な措置を講じます。
- レプリカのプロセスが無応答状態になっている可能性があります。 アプリケーション ログを見てそれを確認してください。 プロセス ダンプを収集し、応答しないプロセスを停止します。 Service Fabric は、代替プロセスを作成してレプリカの復旧を試みます。
- レプリカをホストしているノードがダウンしている可能性があります。 基になる仮想マシンを再起動して、ノードを稼動状態にしてください。
レプリカを復旧できない可能性があることもあります。 ドライブが故障している、マシンが物理的に応答していない、といった場合などです。 そのような場合は、レプリカの復旧を待たないよう Service Fabric に指示する必要があります。
サービスをオンライン状態にするためのデータ損失を許容できない場合、これらの方法は "使用しない" でください。 この場合は、物理マシン復旧のために、できることをすべて行う必要があります。
次のアクションは、データ損失につながる可能性があります。 その点を理解したうえで実行してください。
Note
対象の方法以外で特定のパーティションに対してこれらの方法を使用するのは、"決して" 安全ではありません。
Repair-ServiceFabricPartition -PartitionIdまたはSystem.Fabric.FabricClient.ClusterManagementClient.RecoverPartitionAsync(Guid partitionId)API を使用します。 この API により、クォーラム損失から潜在的なデータ損失に移行するために、パーティションの ID を指定できます。- クォーラム損失の状態をサービスに引き起こすような障害がクラスターで頻繁に発生する場合で、かつ潜在的な "データ損失が許容できる" 場合は、適切な QuorumLossWaitDuration 値を指定することが、サービスの自動復旧に役立つことがあります。 Service Fabric は、指定された
QuorumLossWaitDuration値 (既定では無期限) 待機した後、復旧を実行します。 この方法は予期しないデータ損失につながるおそれがあるため "お勧めしません"。
Service Fabric クラスターの可用性
一般的に、Service Fabric クラスターは高度な分散環境で、単一障害点がありません。 どのノードで障害が発生しても、クラスターの可用性または信頼性で問題が発生することはありません。これは主に Service Fabric システム サービスが、前に説明したものと同じガイドラインに従っているためです。 つまり、既定で常に 3 つ以上のレプリカで実行され、ステートレスのシステム サービスはすべてのノードで実行されています。
基になる Service Fabric ネットワークとエラー検出レイヤーは完全に分散されています。 システム サービスは総じてメタデータから再構築できるか、他の場所から状態を再同期する方法を認識しています。 クラスターの可用性が低下する可能性があるのは、前述したようなクォーラム損失状態がシステム サービスで発生した場合です。 このような場合、アップグレードの開始、一部の操作 (新しいサービスのデプロイなど) をクラスターで実行できないことがありますが、クラスター自体はまだ起動しています。
実行中のクラスター上のサービスについては、システム サービスに書き込まなくても継続して動作できるのであれば、こうした状況でも引き続き実行されます。 たとえば、Failover Manager でクォーラム損失が発生しても、すべてのサービスが継続して実行されます。 ただし、障害が発生しているサービスについては、Failover Manager の関与が必要であるため、自動的に再起動することはできません。
データセンターまたはAzure リージョンの障害
まれに、停電やネットワーク切断のために、物理的なデータセンターが一時的に使用できなくなることがあります。 このような場合、そのデータセンターまたは Azure リージョンの Service Fabric クラスターとサービスは使用できなくなります。 ただし、"データは保存されます"。
Azure で実行されているクラスターの場合、「Azure の状態」ページで停止に関する更新情報を確認できます。 極めてまれなことですが、データ センターが物理的に一部または全体が破壊された場合、そこでホストされている Service Fabric クラスター、またはその中のサービスが失われる可能性があります。 この損失には、そのデータセンターやリージョン外でバックアップされていない状態も含まれます。
1 つのデータセンターやリージョンにおける永続的または持続的な障害を切り抜けるための戦略はいくつかあります。
このような複数のリージョンで Service Fabric クラスターをそれぞれ実行し、こうした環境間でのフェールオーバーとフェールバックのメカニズムをいくつか使用します。 このような複数クラスターのアクティブ/アクティブまたはアクティブ/パッシブ モデルには、追加の管理および操作コードが必要です。 また、このモデルには、あるデータセンターやリージョンで障害が発生したときに、その中のサービスを他のデータセンターやリージョンで使用できるように、サービスのバックアップの調整も必要です。
複数のデータセンターにまたがる 1 つの Service Fabric クラスターを実行します。 この戦略がサポートされる最小構成は 3 つのデータ センターです。 詳細については、「Deploy a Service Fabric cluster across Availability Zones (Availability Zones をまたがる Service Fabric マネージド クラスターのデプロイ)」を参照してください。
このモデルでは、追加の設定が必要です。 ただし、利点は、1 つのデータセンターの障害が、災害から通常の障害に変換される点です。 こうした障害は、1 つのリージョン内のクラスターに対して有効なメカニズムで処理できます。 障害ドメイン、アップグレード ドメイン、および Service Fabric の配置ルールにより、通常の障害が許容されるようにワークロードが分散されます。
この種類のクラスターにおけるサービス操作に役立つポリシーの詳細については、「Service Fabric サービスの配置ポリシー」を参照してください。
スタンドアロン モデルを使用して、複数のリージョンにまたがる単一の Service Fabric クラスターを実行します。 推奨されるリージョン数は 3 つです。 スタンドアロン Service Fabric セットアップの詳細については、「Create a standalone cluster (スタンドアロンクラスターの作成)」を参照してください。
クラスター障害につながるランダムに発生する障害
Service Fabric には "シード ノード" の概念があります。 これは基になるクラスターの可用性を維持するノードです。
特定の種類の障害が発生しているときに、他のノードとのリースを確立し、タイブレーカーとして機能することで、クラスターが確実に稼働し続けるうえで、シード ノードが役立ちます。 ランダムに発生する障害によりクラスターのシード ノードの大部分が削除され、すぐには元に戻らない場合、お使いのクラスターは自動的にシャット ダウンします。 その後、クラスターは失敗します。
Azure では、Service Fabric リソース プロバイダーによって、Service Fabric クラスターの構成が管理され、 既定では、"プライマリ ノード タイプ" のフォールト ドメインとアップグレード ドメインに、シード ノードが分散されます。 プライマリ ノード タイプが Silver または Gold の持続性とマークされている場合、(プライマリ ノード タイプをスケーリングするか、手動で) シード ノードを削除するときに、クラスターによって、プライマリ ノード タイプの空き領域から別の非シード ノードへの昇格が試みられます。 空き容量が、プライマリ ノード タイプに必要なクラスターの信頼性レベルよりも少ない場合、この試みは失敗します。
スタンドアロンの Service Fabric クラスターと Azure の両方について、シードを実行するのは "プライマリ ノード タイプ" です。 プライマリ ノード タイプを定義するとき、Service Fabric では、システム サービスごとに最大 9 個のシード ノードと 7 個のレプリカを作成することで、提供されるノード数が自動的に使用されます。 ランダムに発生する障害によって、こうしたレプリカの大部分が同時に削除されると、システム サービスはクォーラム損失に移行します。 シード ノードの大部分が失われた場合、クラスターは直ちにシャット ダウンします。
次のステップ
- Testability フレームワークを使用して、さまざまな障害をシミュレートする方法を確認します。
- ディザスター リカバリーと高可用性に関する他のリソースを読みます。 Microsoft は、これらのトピックに関して多数のガイダンスを公開しています。 これらのリソースの一部は他の製品で使用するための具体的な方法に関するものですが、Service Fabric に適用できる一般的なベスト プラクティスが多数含まれます。
- Service Fabric のサポート オプションについて学びます。