Oracle 移行のためのデータ移行、ETL、読み込み
この記事は、Oracle から Azure Synapse Analytics に移行する方法に関するガイダンスを提供する 7 つのパートから成るシリーズのパート 2 です。 この記事で注目するのは、ETL と読み込みの移行に関するベスト プラクティスです。
データ移行に関する考慮事項
Oracle のレガシ データ ウェアハウスとデータ マートから Azure Synapse にデータの移行、ETL、および読み込みを行う場合は、考慮すべき多くの要因があります。
Oracle からのデータ移行に関する最初の決定
既存の Oracle 環境からの移行を計画する場合は、次のデータ関連の質問について検討してください。
未使用のテーブル構造を移行する必要がありますか?
リスクとユーザーへの影響を最小限に抑えるために最適な移行方法は何ですか?
データ マートを移行するとき: 物理を維持しますか、仮想に移行しますか?
以降のセクションでは、Oracle からの移行のコンテキスト内で、これらの点について説明します。
使用されていないテーブルを移行しますか?
使用されているテーブルのみを移行する方が合理的です。 アクティブでないテーブルは、移行するのではなく、アーカイブできます。これにより、将来必要な場合にデータを使用できます。 ドキュメントは最新ではない可能性があるため、使用中のテーブルを判別するには、ドキュメントではなくシステム メタデータとログ ファイルを使用することをお勧めします。
Oracle システム カタログ テーブルとログには、特定のテーブルが最後にアクセスされた時点を判別するために使用できる情報が含まれます。この情報を使用して、テーブルが移行の候補であるかどうかを判断できます。
Oracle Diagnostic Pack のライセンスがある場合は、アクティブ セッション履歴にアクセスできます。この履歴を使用して、テーブルが最後にアクセスされた時期を判別できます。
ヒント
レガシ システムでは、テーブルが時間の経過と共に冗長になることは珍しくありません。ほとんどの場合、これらを移行する必要はありません。
以下に、特定の時間枠内に特定のテーブルが使用された状況を調べるクエリの例を示します。
SELECT du.username,
s.sql_text,
MAX(ash.sample_time) AS last_access ,
sp.object_owner ,
sp.object_name ,
sp.object_alias as aliased_as ,
sp.object_type ,
COUNT(*) AS access_count
FROM v$active_session_history ash
JOIN v$sql s ON ash.force_matching_signature = s.force_matching_signature
LEFT JOIN v$sql_plan sp ON s.sql_id = sp.sql_id
JOIN DBA_USERS du ON ash.user_id = du.USER_ID
WHERE ash.session_type = 'FOREGROUND'
AND ash.SQL_ID IS NOT NULL
AND sp.object_name IS NOT NULL
AND ash.user_id <> 0
GROUP BY du.username,
s.sql_text,
sp.object_owner,
sp.object_name,
sp.object_alias,
sp.object_type
ORDER BY 3 DESC;
多数のクエリを実行している場合、このクエリの実行に時間がかかる場合があります。
リスクとユーザーへの影響を最小限に抑えるために最適な移行方法は何ですか?
企業でこの質問が頻繁に取り上げられるのは、企業は機敏性を向上させるため、データ ウェアハウス データ モデルへの変更の影響を軽減したいと考える場合があるためです。 多くの場合、企業は ETL の移行中にデータをさらに最新化または変換する機会を見つけます。 このアプローチでは、複数の要因が同時に変化し、古いシステムと新しいシステムの結果を比較することが困難になるため、リスクがいっそう高くなります。 ここでデータ モデルを変更すると、他のシステムへのアップストリームまたはダウンストリームの ETL ジョブにも影響する可能性があります。 そのリスクのため、この規模での再設計はデータ ウェアハウス移行後に行うことをお勧めします。
データ モデルが移行全体の一部として意図的に変更される場合であっても、新しいプラットフォームで再エンジニアリングを行うのではなく、既存のモデルをそのまま Azure Synapse に移行するのがよい方法です。 このようにすると、既存の運用システムへの影響が最小限になる一方で、1 回限りの再エンジニアリング タスクに対しては Azure プラットフォームのパフォーマンスと柔軟なスケーラビリティによる利点があります。
ヒント
データ モデルに対する変更が将来計画されている場合でも、最初は既存のモデルをそのまま移行します。
データ マートの移行: 物理的なままにするか、仮想に移行しますか?
Oracle のレガシ データ ウェアハウス環境では、組織内の特定の部門またはビジネス機能に対して、パフォーマンスの優れたアド ホック セルフサービス クエリとレポート機能を提供するために構成された多くのデータ マートを作成するのが一般的です。 データ マートは通常、データ ウェアハウスのサブセットで構成されており、ユーザーが短い応答時間でそれらのデータを簡単にクエリできる形式で、集計されたバージョンのデータが格納されています。 ユーザーは、データ マートとのビジネス ユーザーの対話をサポートする Microsoft Power BI などのユーザー フレンドリなクエリ ツールを使用できます。 データ マート内のデータの形式は、一般的にディメンション データ モデルです。 データ マートの使用方法の 1 つは、基になるウェアハウス データ モデルが異なる (データ コンテナーである、などの) 場合でも、使用可能な形式でデータを公開することです。
組織内の個々の事業単位に個別のデータ マートを使用して、堅牢なデータ セキュリティ体制を実装することができます。 ユーザーに関連する特定のデータ マートへのアクセスを制限し、機密データを除外、難読化、または匿名化します。
これらのデータ マートが物理テーブルとして実装されている場合は、それらを定期的にビルドおよび更新するための追加のストレージ リソースと処理が必要になります。 また、マート内のデータは、最後の更新操作の時点での最新状態を保っているだけなので、変動の激しいデータ ダッシュボードには適さない可能性があります。
ヒント
データ マートを仮想化すると、ストレージと処理のリソースを節約できます。
Azure Synapse などの低コストでスケーラブルな MPP アーキテクチャの出現と、それらの固有のパフォーマンス特性により、マートを物理テーブルのセットとしてインスタンス化しなくてもデータ マート機能を提供できます。 1 つの方法は、メイン データ ウェアハウスに SQL ビューを介してデータ マートを効果的に仮想化することです。 もう 1 つの方法は、Azure またはサード パーティ製の仮想化製品のビューなどの機能を使用して、仮想化レイヤーを介してデータ マートを仮想化することです。 この方法では、追加のストレージと集計処理の必要性が軽減されるか不要になるため、移行する必要のあるデータベース オブジェクトの総数が減少します。
このアプローチには、もう 1 つの潜在的な利点があります。 仮想化レイヤー内に集計および結合ロジックを実装し、仮想化されたビューで外部レポート ツールを提供すると、これらのビューを作成するために必要な処理がデータ ウェアハウスにプッシュされます。 データ ウェアハウスは通常、大規模なデータ ボリュームに対して結合、集計、およびその他の関連する操作を実行するのに最適な場所です。
物理データ マートよりも仮想データ マートを優先して実装する主な推進要因は、以下のとおりです。
機敏性の向上: 仮想データ マートの方が、物理テーブルとその関連 ETL プロセスよりも変更しやすい。
総保有コストの低下: 仮想化された実装では必要なデータ ストアとデータのコピー数が少なくなる。
移行のための ETL ジョブを排除でき、仮想化環境のデータ ウェアハウス アーキテクチャが簡素化される。
パフォーマンス: これまでのところ物理データ マートの方がパフォーマンスは優れているとはいえ、仮想化製品にはその差を軽減するためのインテリジェントなキャッシュ手法が実装されるようになっている。
ヒント
Azure Synapse のパフォーマンスとスケーラビリティにより、パフォーマンスを犠牲にすることなく仮想化が可能になります。
Oracle からのデータ移行
データを理解する
移行計画の一環として、移行する必要があるデータの量を詳細に理解する必要があります。これは、移行方法に関する決定に影響を与える可能性があるためです。 システム メタデータを使用して、移行するテーブル内の生データによって占有される物理スペースを判別します。 この文脈では、生データとは、インデックスや圧縮などのオーバーヘッドを除く、テーブル内でデータ行によって使用されている領域のサイズを意味します。 最大レベルのファクト テーブルでは、一般にデータの 95% 以上を構成します。
このクエリでは、Oracle のデータベースの合計サイズが表示されます。
SELECT
( SELECT SUM(bytes)/1024/1024/1024 data_size
FROM sys.dba_data_files ) +
( SELECT NVL(sum(bytes),0)/1024/1024/1024 temp_size
FROM sys.dba_temp_files ) +
( SELECT SUM(bytes)/1024/1024/1024 redo_size
FROM sys.v_$log ) +
( SELECT SUM(BLOCK_SIZE*FILE_SIZE_BLKS)/1024/1024/1024 controlfile_size
FROM v$controlfile ) "Size in GB"
FROM dual
データベースのサイズは (data files + temp files + online/offline redo log files + control files) のサイズと等しくなります。 データベース全体のサイズには、使用済み領域と空き領域が含まれます。
次のクエリ例では、テーブル データとインデックスで使用されるディスク領域の内訳を示します。
SELECT
owner, "Type", table_name "Name", TRUNC(sum(bytes)/1024/1024) Meg
FROM
( SELECT segment_name table_name, owner, bytes, 'Table' as "Type"
FROM dba_segments
WHERE segment_type in ('TABLE','TABLE PARTITION','TABLE SUBPARTITION' )
UNION ALL
SELECT i.table_name, i.owner, s.bytes, 'Index' as "Type"
FROM dba_indexes i, dba_segments s
WHERE s.segment_name = i.index_name
AND s.owner = i.owner
AND s.segment_type in ('INDEX','INDEX PARTITION','INDEX SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.segment_name
AND s.owner = l.owner
AND s.segment_type IN ('LOBSEGMENT','LOB PARTITION','LOB SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB Index' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.index_name
AND s.owner = l.owner
AND s.segment_type = 'LOBINDEX')
WHERE owner in UPPER('&owner')
GROUP BY table_name, owner, "Type"
HAVING SUM(bytes)/1024/1024 > 10 /* Ignore really small tables */
ORDER BY SUM(bytes) desc;
さらに、Microsoft データベース移行チームは、Oracle Inventory Script Artifacts などの多くのリソースを提供します。 Oracle Inventory Script Artifacts ツールには、Oracle システム テーブルにアクセスとし、スキーマの種類、オブジェクトの種類、および状態別にオブジェクトの数を提示する PL/SQL クエリが含まれます。 このツールでは、各スキーマの生データの概算値と、各スキーマ内のテーブルのサイズ設定も提示されます。結果は CSV 形式で保存されます。 付属の電卓スプレッドシートは、CSV を入力として受け取り、サイズ設定データを提供します。
あらゆるテーブルについて、データの代表的なサンプル (100 万行など) を、非圧縮のフラットな ASCII 区切りデータ ファイルに抽出することにより、移行される必要があるデータの量を正確に見積もることができます。 次に、そのファイルのサイズを使用して、行あたりの平均生データ サイズを取得します。 最後に、その平均サイズに、テーブル全体に含まれる行の総数を掛けて、そのテーブルの生データ サイズを求めます。 その生データ サイズを計画で使用します。
SQL クエリを使用してデータ型を検索する
Oracle 静的データ ディクショナリの DBA_TAB_COLUMNS ビューに対してクエリを実行すると、スキーマで使用されているデータ型と、それらのデータ型を変更する必要があるかどうかを判断できます。 SQL クエリを使用して、Azure Synapse 内のデータ型に直接マップされないデータ型を持つ Oracle スキーマ内の列を検索します。 同様に、クエリを使用して、Azure Synapse に直接マップされない各 Oracle データ型の出現回数をカウントできます。 これらのクエリの結果をデータ型比較テーブルと組み合わせて使用することで、Azure Synapse 環境で変更する必要があるデータ型を決定できます。
Azure Synapse のデータ型にマップされないデータ型を含む列を見つけるには、次のクエリを実行します (<owner_name> をスキーマの関連する所有者に置き換えた後)。
SELECT owner, table_name, column_name, data_type
FROM dba_tab_columns
WHERE owner in ('<owner_name>')
AND data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
ORDER BY 1,2,3;
マップできないデータ型の数をカウントするには、次のクエリを使用します。
SELECT data_type, count(*)
FROM dba_tab_columns
WHERE data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
GROUP BY data_type
ORDER BY data_type;
Microsoft では、データ型のマッピングなど、レガシの Oracle 環境からのデータ ウェアハウスの移行を自動化するために、SQL Server Migration Assistant (SSMA) for Oracle を提供しています。 また、Azure Database Migration Services を使用して、Oracle などの環境からの移行の計画と実行に役立てることもできます。 サードパーティベンダーも、移行を自動化するためのツールとサービスを提供しています。 サードパーティの ETL ツールが既に Oracle 環境で使用されている場合は、そのツールを使用して、必要なデータ変換を実装できます。 次のセクションでは、既存の ETL プロセスの移行について説明します。
ETL 移行に関する考慮事項
Oracle ETL 移行に関する最初の決定事項
ETL/ELT 処理の場合、Oracle のレガシ データ ウェアハウスでは、多くの場合、カスタムビルド スクリプト、 サードパーティの ETL ツール、または時間の経過とともに進化したアプローチの組み合わせを使用します。 Azure Synapse への移行を計画するときには、コストとリスクを最小限に抑えながら、必要な ETL/ELT 処理を新しい環境に実装するのに最適な方法を判断してください。
ヒント
前もって ETL 移行の方法を計画し、適切なところで Azure の機能を活用します。
次のフローチャートは、1 つの方法をまとめたものです。
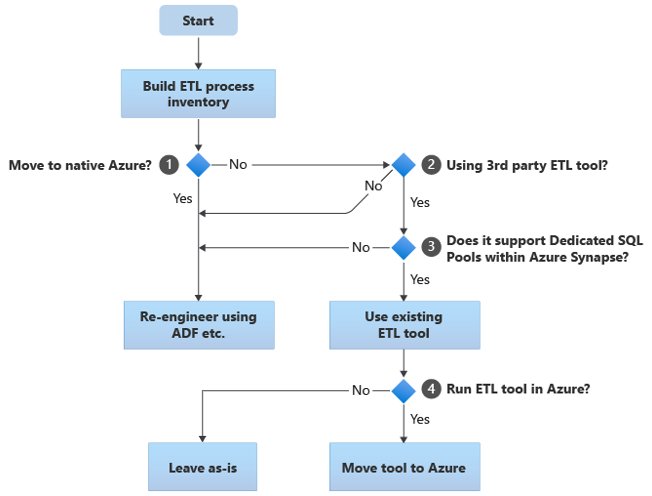
フローチャートに示すように、最初の手順は常に、移行する必要がある ETL/ELT プロセスのインベントリを作成します。 標準の組み込み Azure 機能では、一部の既存のプロセスを移動する必要がない場合があります。 計画目的では、移行の規模を理解することが重要です。 次に、フローチャート デシジョン ツリーの質問を検討します。
ネイティブ Azure に移行しますか? 答えは、完全に Azure ネイティブ環境に移行するかどうかによって異なります。 そうである場合は、Azure Data Factory のパイプラインとアクティビティまたは Azure Synapse パイプラインを使用して、ETL 処理を再エンジニアリングすることをお勧めします。
サードパーティの ETL ツールを使用していますか? 完全に Azure ネイティブの環境に移行しない場合は、既存のサードパーティの ETL ツールを既に使用中であるかどうかを確認します。 Oracle 環境では、ETL 処理の一部またはすべてが、Oracle SQL Developer、Oracle SQL*Loader、Oracle Data Pump などの Oracle 固有のユーティリティを使用して、カスタム スクリプトによって実行される場合があります。 この場合は、Azure Data Factory を使って再エンジニアリングする方法をとります。
サード パーティでは Azure Synapse 内の専用 SQL プールがサポートされていますか? サードパーティの ETL ツールのスキルに大きな投資を行っているか、または既存のワークフローとスケジュールでそのツールが使われているか検討します。 その場合は、そのツールで Azure Synapse をターゲット環境として効率的にサポートできるかどうかを判断します。 最も効率的なデータ読み込みのためには、PolyBase や COPY INTO などの Azure 機能を使用できるネイティブ コネクタがそのツールに含まれていれば理想的です。 ただし、ネイティブ コネクタがなくても、一般に PolyBase や
COPY INTOなどの外部プロセスを呼び出し、該当するパラメーターを渡す方法があります。 この場合は、Azure Synapse を新しいターゲット環境として、既存のスキルとワークフローを使用します。ELT 処理に Oracle Data Integrator (ODI) を使用している場合は、Azure Synapse 用の ODI ナレッジ モジュールが必要です。 組織でこれらのモジュールを使用できないが、ODI がある場合は、ODI を使用してフラット ファイルを生成できます。 その後、これらのフラット ファイルを Azure に移動し、Azure Synapse に読み込むために Azure Data Lake Storage に取り込むことができます。
Azure で ETL ツールを実行しますか? 既存のサードパーティの ETL ツールを持ち続ける場合は、(既存のオンプレミス ETL サーバーに対してではなく) Azure 環境内でそのツールを実行し、既存のワークフローの全体的オーケストレーションを Data Factory に処理させることができます。 そのため、既存のツールをそのまま実行するか、Azure 環境に移行してコスト、パフォーマンス、スケーラビリティの利点を実現するかを決定します。
ヒント
パフォーマンス、スケーラビリティ、コストのメリットを活用するために、Azure で ETL ツールを実行することを検討してください。
既存の Oracle 固有のスクリプトを再エンジニアリングする
既存の Oracle ウェアハウス ETL/ELT 処理の一部またはすべてが、Oracle SQL*Plus、Oracle SQL Developer、Oracle SQL*Loader、Oracle Data Pump などの Oracle 固有のユーティリティを使用するカスタム スクリプトによって処理される場合は、これらのスクリプトを Azure Synapse 環境用に再コーディングする必要があります。 同様に、Oracle でストアド プロシージャを使用して ETL プロセスが実装されている場合は、それらのプロセスを再コーディングする必要があります。
ETL プロセスの一部の要素は、たとえば、外部ファイルからステージング テーブルへの単純な一括データ読み込みにより、簡単に移行できます。 たとえば、SQL*Loader ではなく Azure Synapse COPY INTO や PolyBase を使用して、プロセスのそれらの部分を自動化することもできます。 任意の複雑な SQL やストアド プロシージャが含まれるプロセスの他の部分については、再エンジニアリングにかかる時間が長くなります。
ヒント
移行する ETL タスクのインベントリには、スクリプトとストアド プロシージャが含まれている必要があります。
Oracle SQL の Azure Synapse との互換性をテストする 1 つの方法は、Oracle v$active_session_history と v$sql の結合からいくつかの代表的な SQL ステートメントをキャプチャして sql_text を取得し、それらのクエリの先頭に.EXPLAIN を付けることです。 Azure Synapse 内で同一条件で移行されたデータ モデルを想定して、Azure Synapse でこれらの EXPLAIN ステートメントを実行します。 互換性のない SQL ではエラーが発生します。 この情報を使用して、再コーディング タスクのスケールを決定できます。
ヒント
SQL の非互換性を見つけるには、EXPLAIN を使用します。
最悪の場合、手動での再コーディングが必要な場合があります。 ただし、Oracle 固有のコードの再エンジニアリングを支援する製品およびサービスを Microsoft パートナーから入手できます。
ヒント
パートナーは、Oracle 固有のコードの再エンジニアリングを支援する製品とスキルを提供しています。
既存のサードパーティの ETL ツールを使用する
多くの場合、既存のレガシ データ ウェアハウス システムには、サードパーティの ETL 製品によって事前にデータが取り込まれ、保守されます。 Azure Synapse の現在の Microsoft データ統合パートナーの一覧については、「Azure Synapse Analytics データ統合パートナー」を参照してください。
Oracle コミュニティでは、いくつかの一般的な ETL 製品が頻繁に使用されています。 以下の段落では、Oracle ウェアハウスで最も一般的な ETL ツールについて説明します。 Azure の VM 内でこれらの製品をすべて実行し、それらを使用して Azure データベースとファイルの読み取りと書き込みを行うことができます。
ヒント
既存のサードパーティ ツールへの投資を活用して、コストとリスクを軽減します。
Oracle からのデータの読み込み
Oracle からデータを読み込むときに使用できる選択肢
Oracle データ ウェアハウスからのデータ移行を準備するときは、既存のオンプレミス Oracle 環境からクラウドの Azure Synapse にデータを物理的に移動する方法のほか、転送と読み込みを実行するために使用するツールを決定する必要があります。 以降のセクションで説明する次の質問を検討してください。
データをファイルに抽出しますか、ネットワーク接続を介して直接移動しますか?
プロセスのオーケストレーションは、ソース システムから行いますか、ターゲットの Azure 環境から行いますか?
移行プロセスの自動化と管理にはどのツールを使用しますか?
ファイルとネットワーク接続のどちらを介してデータを転送するか
移行するデータベース テーブルが Azure Synapse 内に作成されたら、データを移動して、Oracle のレガシ システムからそれらのテーブルにデータを取り込み、新しい環境に入れることができます。 基本的な方法は 2 つあります。
ファイル抽出: Oracle テーブルから、区切り文字で区切られたフラット ファイル (通常は CSV 形式) にデータを抽出します。 テーブル データは、いくつかの方法で抽出できます。
- SQL*Plus、SQL Developer、SQLcl などの標準の Oracle ツールを使用する。
- Oracle Data Integrator (ODI) を使用してフラット ファイルを生成する。
- Data Factory の Oracle コネクタを使用して Oracle テーブルを並列でアンロードし、パーティションごとのデータ読み込みを実現する。
- サードパーティの ETL ツールを使用する。
Oracle テーブル データを抽出する方法の例については、この記事の付録を参照してください。
この方法では、抽出されたデータ ファイルの到着場所となる領域が必要です。 この領域は、ローカルの Oracle ソース データベース (十分なストレージが使用可能である場合) でも、リモートの Azure Blob Storage でもかまいません。 ファイルがローカルに書き込まれる場合はネットワークのオーバーヘッドが回避されるため、最適なパフォーマンスが実現します。
ストレージとネットワーク転送の要件を最小限に抑えるには、gzip などのユーティリティを使用して、抽出されたデータ ファイルを圧縮します。
抽出後、フラット ファイルを Azure Blob Storage に移動します。 Microsoft では、大量のデータを移動するための、次のようなさまざまなオプションを提供しています。
- ネットワーク経由で Azure Storage にファイルを移動するための AzCopy。
- プライベート ネットワーク接続経由で一括データを移動するための Azure ExpressRoute。
- 読み込みのために Azure データ センターに送付する物理ストレージ デバイスにファイルを移動するための Azure Data Box。
詳細については、「Azure との間でのデータの転送」を参照してください。
ネットワーク経由での直接抽出と読み込み: データ抽出要求が、ターゲットの Azure 環境から、通常は SQL コマンドを介して Oracle のレガシ システムに送信され、データを抽出します。 結果は、ネットワーク経由で送信され、Azure Synapse に直接読み込まれます。データの到着場所を中間ファイルにする必要はありません。 このシナリオの制限要因は、通常、Oracle データベースと Azure 環境の間の、ネットワーク接続の帯域幅です。 データ量が非常に多い場合、この方法は実用的でないことがあります。
ヒント
移行するデータの量と使用可能なネットワーク帯域幅を把握します。これらの要因が移行方法の決定に影響を与えるためです。
両方の方法を使用するハイブリッドな方法もあります。 たとえば、小さなディメンション テーブルと大きなファクト テーブルのサンプルであれば、ネットワーク直接抽出の方法を使用して、Azure Synapse にテスト環境をすばやく用意できます。 以前からのデータ量が多いファクト テーブルの場合は、Azure Data Box を使用して、ファイルの抽出と転送の方法を使用できます。
オーケストレーションは Oracle と Azure のどちらから行うか?
Azure Synapse に移行するときの推奨される方法は、SSMA または Data Factory を使用して Azure 環境からのデータの抽出と読み込みのオーケストレーションを行うことです。 最も効率的なデータ読み込みとなるように、PolyBase や COPY INTO などの関連付けられているユーティリティを使用します。 この方法では、組み込みの Azure 機能の利点を活用し、再利用可能なデータ読み込みパイプラインを構築する作業が削減されます。 メタデータ駆動型のデータ読み込みパイプラインを使用して、移行プロセスを自動化できます。
推奨される方法では、管理と読み込みプロセスが Azure で実行されるため、データ読み込みプロセス中の既存の Oracle 環境でのパフォーマンスの影響も最小限に抑えられます。
既存のデータ移行ツール
データの変換と移動は、どの ETL 製品にもある基本的な機能です。 データ移行ツールが既に既存の Oracle 環境で使用されており、ターゲット環境として Azure Synapse をサポートしている場合は、そのツールを使用してデータ移行を簡略化することを検討してください。
既存の ETL ツールが配備されていない場合でも、Azure Synapse Analytics データ統合パートナーでは、データ移行のタスクを簡略化するための ETL ツールを提供しています。
最後に、ETL ツールを使用する場合は、Azure 環境内でそのツールを実行して、Azure クラウドのパフォーマンス、スケーラビリティ、コストを活用することを検討してください。 この方法により、Oracle データ センターのリソースも解放されます。
まとめ
まとめると、Oracle から Azure Synapse にデータと関連 ETL プロセスを移行する場合の推奨事項は、以下のとおりです。
移行作業が確実に成功するように事前に計画します。
できるだけ早期に、移行するデータとプロセスの詳細なインベントリを作成します。
システム メタデータとログ ファイルを使用して、データとプロセスの使用状況を正確に理解します。 ドキュメントは最新ではない可能性があるため、頼らないでください。
移行するデータの量と、オンプレミス データ センターと Azure クラウド環境の間のネットワーク帯域幅について把握します。
レガシの Oracle 環境からのオフロード移行の足掛かりとして、Azure VM で Oracle インスタンスを使用することを検討してください。
標準の組み込み Azure 機能を使用して、移行ワークロードを最小限に抑えます。
Oracle 環境と Azure 環境の両方でのデータ抽出と読み込みのために最も効率的なツールを特定して理解します。 プロセスの各フェーズで適切なツールを使用します。
Data Factory などの Azure 機能を使用して、Oracle システムへの影響を最小限に抑えながら、移行プロセスのオーケストレーションと自動化を行います。
付録: Oracle データを抽出する手法の例
Oracle から Azure Synapse に移行するときに、いくつかの手法を使用して Oracle データを抽出できます。 次のセクションでは、Oracle SQL Developer と Data Factory の Oracle コネクタを使用して Oracle データを抽出する方法を示します。
データ抽出に Oracle SQL Developer を使用する
Oracle SQL Developer UI を使用して、次のスクリーンショットに示すように、テーブル データを CSV などの多くの形式にエクスポートできます。

その他のエクスポート オプションには、JSON と XML があります。 UI を使用してテーブル名のセットを "cart" に追加し、cart 内のセット全体にエクスポートを適用できます。

Oracle SQL Developer コマンド ライン (SQLcl) を使用して Oracle データをエクスポートすることもできます。 このオプションは、シェル スクリプトを使用した自動化をサポートします。
比較的小さいテーブルでは、直接接続を介してデータを抽出する際に問題が発生した場合に、この手法が役立つ場合があります。
Azure Data Factory で Oracle コネクタを使用して並列コピーを行う
Data Factory の Oracle コネクタを使用して、大規模な Oracle テーブルを並列でアンロードできます。 Oracle コネクタでは、Oracle からデータを並列コピーするために、組み込みのデータ パーティション分割を提供します。 データ パーティション分割オプションは、コピー アクティビティの [ソース] タブにあります。
![[ソース] タブの Azure Data Factory Oracle パーティション オプションのスクリーンショット。](../media/2-etl-load-migration-considerations/azure-data-factory-source-tab.png)
並列コピーのために Oracle コネクタを構成する方法については、「Oracle からの並列コピー」を参照してください。
Data Factory のコピー アクティビティのパフォーマンスとスケーラビリティの詳細については、「コピー アクティビティのパフォーマンスとスケーラビリティに関するガイド」を参照してください。
次のステップ
セキュリティ アクセス操作の詳細については、このシリーズの次の記事「Oracle 移行のセキュリティ、アクセス、操作」を参照してください。