YARN
In this unit we look at Hadoop 2.0, known as YARN.
Hadoop has undergone a major overhaul to address several inherent technical deficiencies, including the reliability and availability of the JobTracker (JT) and the static resource (map and reduce slots)10 allocation at TaskTrackers (TTs). The redesigned framework addresses such problems in the JT, Hadoop's primary node and, therefore, a single point of failure (SPOF). Another major objective for the new Hadoop is to support, in addition to MapReduce, other distributed analytics engines. This allows for increased utilization of Hadoop clusters and eliminates the need for a large cluster to be deployed for each framework. For Hadoop, the result is a new version named Yet Another Resource Negotiator (YARN). We next introduce YARN and point out how it differs from the previous version Hadoop MapReduce, which we call MapReduce 1.0.
YARN is the second generation of Hadoop (version 2.0 and higher). The main advantage of YARN from the previous generation of Hadoop is that the resource allocation is no longer fixed, and YARN is not bound to any single programming framework. This allows YARN to function as an independent cluster scheduler, which is capable of scheduling different workloads and applications. YARN is a two-level scheduler. The responsibility of the Job Tracker in Hadoop v1 in YARN is separated into resource allocation and task management, which enables YARN clusters to easily scale up.
Architecture and workflow
The fundamental change pursued in redesigning MapReduce 1.0 was segregating JT functionalities into multiple, independent daemons, illustrated in the following figure. YARN still employs a primary-subordinate topology, but adds these enhancements:
- To support other distributed analytics engines in addition to MapReduce, the resource management module has been entirely detached from the JT and defined as a separate entity, the Resource Manager (RM). The RM has been further sliced into two main components, the Scheduler (S) and the Applications Manager (ASM).
- Instead of using a single primary, JT, for all applications, YARN appoints one primary per application, an Application Master (AM). AMs can be distributed across cluster nodes to avoid application SPOFs and potential performance degradations.
- TTs have remained effectively unchanged but are now called Node Managers (NMs).
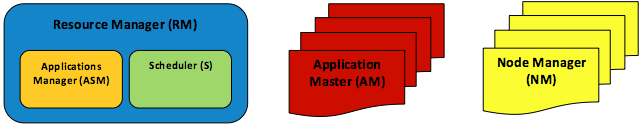
Figure 8: Elements of the YARN architecture: one RM, one ASM, one S, many AMs, and many NMs
Components of YARN
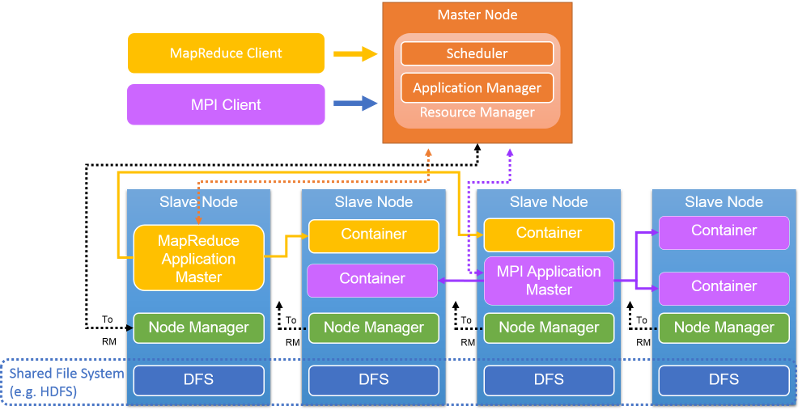
Figure 9: The architecture of a YARN cluster
A per-cluster Resource Manager resides in the primary node (Figure 9). The RM accepts application/job submissions by a client, allocates resources to jobs, monitors the cluster state, and manages the access to resources. The RM has two components: the Scheduler, which schedules job, and the Applications Manager, which creates, manages, monitors, restarts, and kills jobs.
The RM is the central authority; it arbitrates resource allocations among various competing applications/jobs. The RM dynamically allocates resources as leases to applications in the form of containers. Containers are a logical representation of resources in the form of amount of memory or number of CPUs. Currently, the RM handles memory capacities and CPU resources but does not yet support disk or network resources. The RM interacts with Node Managers to assemble a global view of the cluster and to enforce resource assignments. The RM tracks resource usage and node liveness through a heartbeat mechanism.
The Scheduler is a part of the RM and builds a global plan for cluster resources, serves application resource needs, and schedules jobs using strategies such as Capacity or Fair scheduling. The Applications Manager, another part of RM, accepts submitted jobs, negotiates with the Scheduler to initialize resources (a container) to run a job's Application Master, and provides services for tolerating/restarting the AMs when failures occur.
The AM coordinates the application's (or job's) execution in a YARN cluster. Each job, be it a MapReduce job, MPI job, or Spark job, has a dedicated AM in the YARN cluster. The AM runs in a common container as other tasks do. The AM is responsible for getting containers and allocating its tasks on to them. It computes the set of resources that it needs based on the tasks it has to run and sends a request to the RM. Once the resources are allocated, the AM runs the tasks on those containers. Once the resources finish, the AM gives them back to the RM. Below we explain this process in more detail.
As the AM runs in a container, it sends periodic heartbeats to the RM to update its liveness and to update its resource demands. The AM calculates the resources demands of its job and makes a request for containers along with preferences and constraints within its periodic heartbeat message to the RM. In turn, the RM dynamically responds to the heartbeat in the form of container leases (provided as tokens). The AM uses the tokens when contacting the corresponding NMs to start a job's tasks. The AM keeps track of the status of its running tasks through an umbilical mechanism. During a job's execution, the RM is blind to the AM's scheduling. For a MapReduce job, the AM is like the JobTracker in Hadoop version 1.0.
The Node Manager resides on each node; there's a single NM per YARN cluster node. The NMs authenticate container leases and monitor resource utilization. NMs contact the RM through heartbeats and kill containers as directed by the RM or AM.
A container represents a lease for an allocated resource in the cluster. A lease is a logical bundle of resources bound to a node. The RM is the sole authority to allocate any container to jobs. Every allocated container has a unique ContainerID, which is globally unique. Each container has a number of non-static attributes: CPU, memory, disk BW, network BW. Containers can be compared to MapReduce slots in Hadoop version 1.0. A container is killed shortly after the task running in it finishes. The RM revokes the resources and makes use of it later.
When requiring compute resources, the AM presents to the RM Scheduler a series of container requests. The protocol understood by the Scheduler is <priority, (host, rack, *), resources, #containers>. The RM Scheduler assigns or allocates containers in the same format. A snapshot from the RM log shows how the RM allocates a container (Figure 10):

Figure 10: Log snapshot of a container assignment in YARN. The important information in this entry is: 1. ContainerID, 2. Computer resources in this ContainerID, 3. ID of the node where the ContainerID resides, and 4. Resource report of this node after allocation.
Job and task scheduling
YARN is a two-level scheduler. The RM schedules jobs, and the AM schedules its tasks on the containers that the RM allocates to it. The Scheduler, which is responsible for job scheduling in the RM, employs different scheduling strategies:
- FIFO Scheduler: This is a basic and simple scheduler that has a single first-in, first-out queue and schedules the container requests based on that. Typically, a job can exclusively occupy resources within the cluster while running. Though each job can be offered large resources, this creates problems such as starving other jobs or not sharing the available resources fairly. The FIFO scheduler allows job priorities to be set. Hence, the job with the highest priority is selected as the next job to run. However, since the FIFO scheduler does not support preemption, the problem of job starvation still exists. A high-priority job can be blocked by a long-running but low-priority job.
- Capacity Scheduler: This scheduler assumes that Hadoop jobs are running on a shared, multi-tenant cluster and maximizes the throughput and utilization of the cluster. The Capacity Scheduler gives capacity guarantees to users who are sharing a large cluster. The Capacity Scheduler organizes jobs in queues. Typically, the queues are set up by administrators based on how the YARN cluster will be partitioned and utilized by different groups of users (group 1, queue 1 gets 50% of the cluster). The Capacity Scheduler offers a set of limits to make sure a single job or queue cannot consume a disproportionate amount of resources in the cluster.
- Fair Scheduler: This scheduler focuses on running different YARN jobs fairly, providing jobs with an equal share of resources over time. By default, a scheduling decision made by the Fair Scheduler is based only on memory. However, the Fair Scheduler is configurable, and it can schedule with both memory and CPU. The Fair Scheduler ensures some short jobs to finish in a reasonable amount of time without starving large or time-consuming jobs. It is also a desirable scheduler for multiple users sharing the same cluster. Besides allocating resources equally, the Fair Scheduler can schedule jobs with different priorities. Priorities, set by users, can be used to determine how many resources each job should be assigned.
- Your Scheduler: Users can plug in their own job scheduler.
The strategies of scheduling can be configured in the file yarn-site.xml. There are also many properties that can be set in yarn-site.xml to tune the operational parameters of the schedulers mentioned above.
After a job is allocated resources (containers), the AM is in charge of scheduling a job's tasks on these containers. The AM schedules tasks in the same way the JobTracker does in Hadoop version 1.0. Moreover, the AM takes the responsibility of monitoring the status of tasks, which is done by TaskTracker in Hadoop version 1.0.
Fault tolerance in YARN
The Resource Manager is a single point of failure for a YARN cluster. The RM checkpoints its state to persistent storage periodically. If the RM fails, it can be restarted from one of the checkpoints. All running AMs are then killed and restarted, and the applications and tasks that are pending from the checkpoint state can be scheduled and executed.
Any AM may fail. The RM will notice an AM's failure to send a heartbeat, and will restart the AM. However, the AM has to resync with all running containers to ensure that the job finishes smoothly.
The NM failures can also be detected by the RM. When a NM fails, all containers on this node will be killed and the failure will be reported to all running AMs. The AMs are responsible for acquiring new resources in the form of containers from the RM to run the killed tasks. No more containers will be assigned on the failed node in the cluster until it recovers and reports back to the RM.
Job flow for MapReduce on YARN
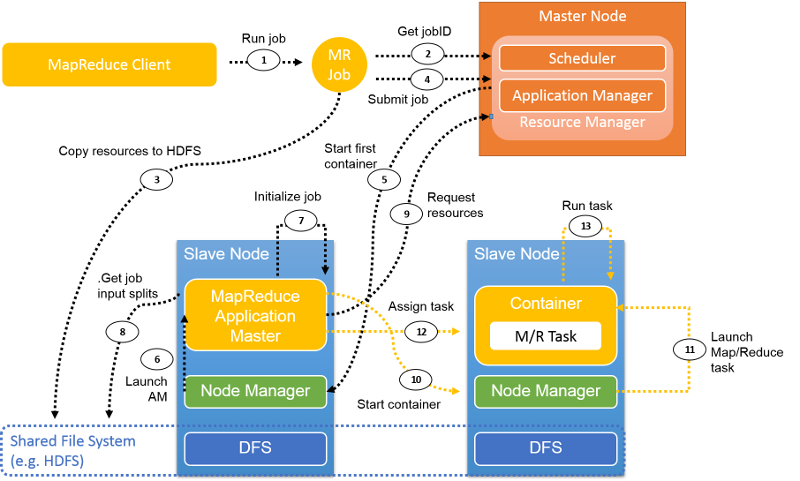
Figure 11: Job flow in YARN executing a MapReduce job
This figure illustrates a typical MapReduce job flow in YARN. The following sections describe the steps in this flow.
Job submission
Step 1. The MapReduce client uses the same API as Hadoop version 1.0 to submit a job to YARN. When mapreduce.framework.name is set to yarn in the job configuration, the ClientProtocol of YARN is activated. A job is referred to as an application in YARN.
Step 2. Unlike in Hadoop version 1.0 where the JobTracker manages all jobs in the cluster, in YARN, the new job ID is retrieved from the RM. However, sometimes a jobID in YARN is also called applicationID.
Step 3. Necessary job resources, such as the job JAR, configuration files, and split information, are copied to a shared file system in preparation to run the job.
Step 4. The job client calls submitApplication() on the RM to submit the job.
Job initialization
Step 5. The RM will pass the job request to its Scheduler after it receives the call of submitApplication(). The Scheduler allocates resources to run a container where the Application Master will reside. Then the RM sends the resource lease to some Node Manager.
Step 6. The NM receives a message form RM and launches a container for the AM.
Step 7. The AM takes the responsibility of initializing the job. Several bookkeeping objects are created to monitor the job. Afterward, while the job is running, the AM will keep receiving updates with the progress of its tasks.
Step 8. The AM interacts with the shared file system (e.g., HDFS) to get its input splits and other information, which were copied to the shared file system in step 3.
Task assignment
Step 9. The AM computes the number of map tasks, which is decided by the number of input splits (similar to Hadoop version 1.0). The number of reduce tasks is a configurable parameter that is set in the configuration file. The AM requests resources for all the map and reduce tasks from the RM in the form of a request for containers. A request includes preferences in terms of data locality (for map tasks), the amount of memory, and the number of CPUs in each container.
ResourceRequest: <Priority: 20,
Resource: <vCores: 1, memory: 1024>,
Num Containers: 2,
Desired Host: 192.1.1.1,
Relax Locality: true>
In the above example, priority defines the priority of the container, which can be configured based on the type of task (e.g., mapper or reducer). The resources required for this task are designated as a sub-record called Resource. Here the number of vCores (CPUs) has been denoted as 1, while memory is an integer parameter that is defined in MB. Num containers denotes the number of such containers that is needed by YARN. Desired host denotes the locality requirement of the request. Relax locality denotes whether the defined locality requirement is stringent, or if any other allocation is also acceptable for this task.
Step 10 and Step 11. After the RM responds with container leases, the AM communicates with the NMs, and the NMs start the containers.
Step 12. The AM assigns a task to this container based on its knowledge of locality. The task will be executed by a Java application whose main class is YarnChild.
Status reports

Figure 12: Heartbeat and status reports in YARN
While the job is running, the tasks keep reporting their progress and status to the corresponding AM, which ensures that the AM has an aggregate view of the job (Figure 12). The Node Managers report liveness and resource utilization to the RM, which has a global view of the cluster.
Job completion
Every five seconds, the job client checks the job status to see if the job has finished. The function called is waitForCompletion(). Once the job finishes, the clean-up method is called. All containers and the working state of the AM will be cleaned up. The job history server keeps track of the information related to this job.
An example: WordCount
Here we present an example of running WordCount on a YARN cluster consisting of 1 primary node and 4 subordinate nodes. We employ the m1.large instance (2 vCPU, 6.5 ECU, 7.5 GB memory) offered by Amazon Web Services (AWS). The input data is partitioned as 39 plain text files on the distributed file system, which are 2.32 GB in total. The number of map tasks is computed to be 39, and we manually configure the number of reduce tasks in the job configuration file to be 7.
We use snapshots to detail the execution process of this job on YARN:
The client starts to run the WordCount job.
The RM assigns a
jobIDfor this WordCount job.Information for this WordCount job is saved or copied to HDFS.
The WordCount job is submitted to the RM (Figure 13).
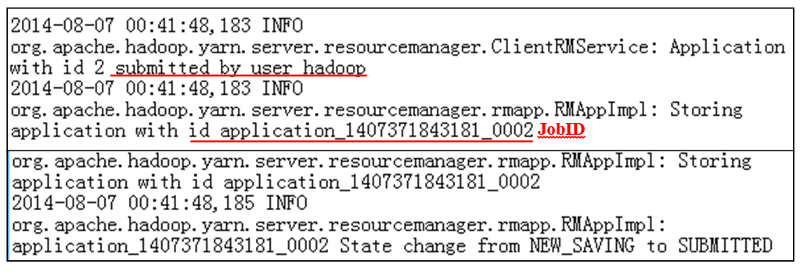
Figure 13: Job submission log
The RM communicates with the NM to allocate a container for the AM.
The NM authenticates the container lease from the RM.
The RM succeeds in launching the AM for the WordCount job (Figure 14).
Figure 14: Job allocation log
The AM starts running, and it computes resources it needs to finish the WordCount job: 39 map tasks and 7 reduce tasks.
The RM receives requests from the AM and allocates resources in the form of containers.
The AM sends the lease to NMs and a bunch of containers get running.
The AM starts map task attempts, ready to run in containers. In our case, the AM, in the first place, starts 12 map task attempts because there aren't enough resources for other container on our 4-node cluster.
The AM then assigns containers to map task attempts based on its knowledge of data locality (Figure 15).

Figure 15: Job assignment log
The map tasks start running. The AM keeps track of the status of each task attempt through a heartbeat mechanism.
At some point, a map task finishes executing in a container and the AM is informed.
This container is then cleaned by the AM. Compute resources are retrieved and a new container will be started by the NM through the same process mentioned above. The AM will assign new map or reduce task attempt to the new container. Only one task can be run in one container.
Because of the early shuffle, when several map tasks finish (at least 5% by default), the AM will assign a reduce task attempt to an available container. A reduce phase consists of the shuffle, the merge and sort, and the execution of the reduce function. Only after the output bytes of the reduce task are written to HDFS can a reduce task finish.
The AM manages all the map and reduce tasks, and it waits for their completion. Once the last reduce task finishes, the whole job will be marked FINISHED.
The AM communicates with the NMs to clean up all remaining containers.
The AM will notify the RM that the job is completed.
The RM cleans up the AM. The whole WordCount job ends (Figure 16).

Figure 16: Job cleanup log
Timeline of tasks for example WordCount job
Shortly after the job starts, 12 map tasks (blue bars) start running (Figure 17). No more map task can be run because no more resources (containers) are available in the cluster to start another map task. We refer to several map tasks running in parallel as a wave, so we have 12 map tasks in the first wave. After a period of time, some of the map tasks finish. Due to the early shuffle mechanism, when some of the map tasks finish (5% by default), reduce tasks are scheduled and then begin to shuffle. In this example, there are enough resources for 4 reduce tasks to start. Each reduce task has 3 sequential subphases: shuffle (red), merge&sort (yellow), and reduce function (pink). While the 4 reduce tasks are performing an early shuffle, the second wave of map tasks begins to run. When the last map task finishes, the whole map phase ends. The merge&sort and reduce functions can then run. Afterward, there are enough containers to run 3 more reduce tasks. The job finishes shortly after the last reduce task ends.
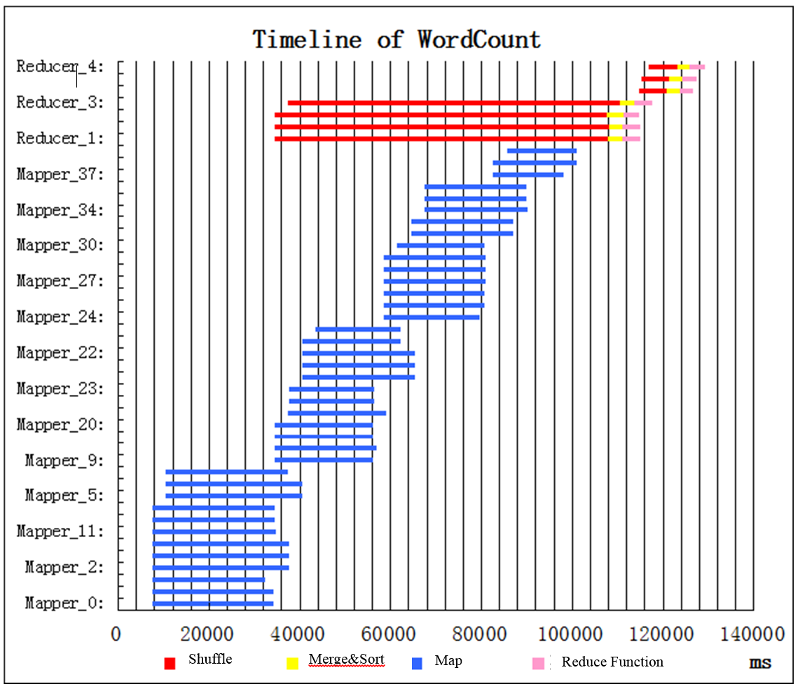
Figure 17: Job execution timeline for WordCount
10 The number of map slots and the number of reduce slots are configurable parameters, which users can set before submitting jobs to Hadoop MapReduce.