Anbefalte fremgangsmåter for å opprette en dimensjonal modell ved hjelp av dataflyter
Utforming av en dimensjonal modell er en av de vanligste oppgavene du kan gjøre med en dataflyt. Denne artikkelen fremhever noen av de beste fremgangsmåtene for å opprette en dimensjonal modell ved hjelp av en dataflyt.
Sette opp dataflyter
Et av de viktigste punktene i ethvert dataintegreringssystem er å redusere antall lesinger fra kildeoperativsystemet. I den tradisjonelle arkitekturen for dataintegrasjon utføres denne reduksjonen ved å opprette en ny database som kalles en oppsamlingsdatabase. Formålet med oppsamlingsdatabasen er å laste inn data som de er, fra datakilden til oppsamlingsdatabasen etter en vanlig tidsplan.
Resten av dataintegreringen vil deretter bruke oppsamlingsdatabasen som kilde for videre transformasjon og konvertere den til den dimensjonale modellstrukturen.
Vi anbefaler at du følger samme fremgangsmåte ved hjelp av dataflyter. Opprett et sett med dataflyter som er ansvarlige for bare å laste inn data som de er fra kildesystemet (og bare for tabellene du trenger). Resultatet lagres deretter i lagringsstrukturen for dataflyten (enten Azure Data Lake Storage eller Dataverse). Denne endringen sikrer at leseoperasjonen fra kildesystemet er minimal.
Deretter kan du opprette andre dataflyter som henter dataene fra å sette opp dataflyter. Fordelene med denne tilnærmingen inkluderer:
- Redusere antall leseoperasjoner fra kildesystemet og redusere belastningen på kildesystemet som et resultat.
- Reduserer belastningen på datagatewayer hvis en lokal datakilde brukes.
- Hvis du har en mellomliggende kopi av dataene for avstemmingsformål, endres kildesystemdataene.
- Gjør transformasjonsdataflytkilden uavhengig.
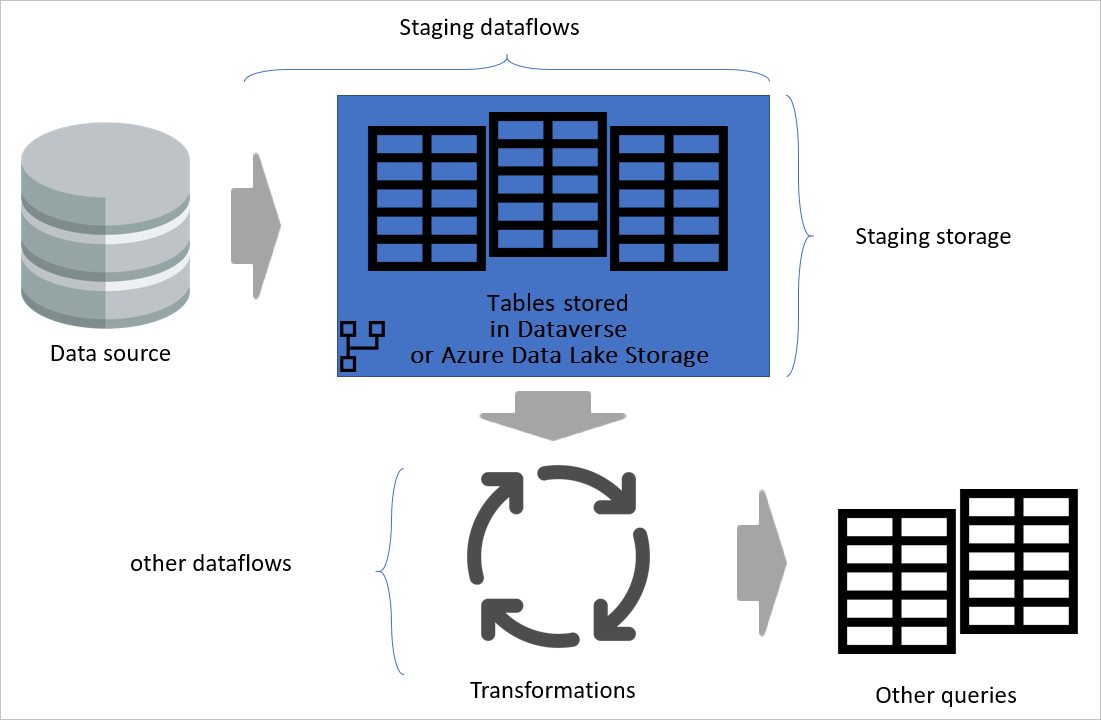
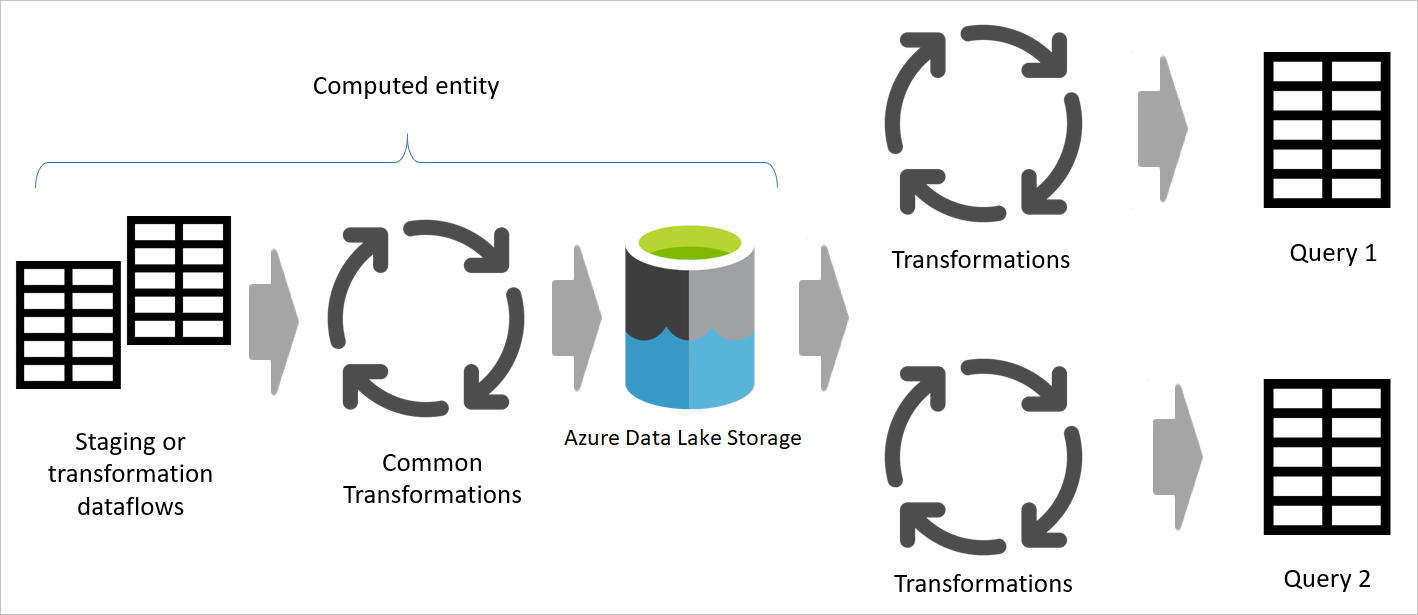
Bilde som fremhever oppsamling av dataflyter og oppsamlingslagring, og viser dataene som åpnes fra datakilden ved oppsamling av dataflyten, og tabeller som lagres i enten Cadavers eller Azure Data Lake Storage. Tabellene vises deretter transformert sammen med andre dataflyter, som deretter sendes ut som spørringer.
Transformasjonsdataflyter
Når du har skilt transformasjonsdataflytene fra de oppsamlingsdataflytene, vil transformasjonen være uavhengig av kilden. Denne separasjonen hjelper hvis du overfører kildesystemet til et nytt system. Alt du trenger å gjøre i så fall er å endre oppsamlingsdataflytene. Transformasjonsdataflytene vil sannsynligvis fungere uten problemer fordi de bare hentes fra de oppsamlingsdataflytene.
Denne separasjonen hjelper også i tilfelle tilkoblingen til kildesystemet går tregt. Transformasjonsdataflyten trenger ikke vente lenge for å få poster som kommer gjennom en treg tilkobling fra kildesystemet. Oppsamlingsdataflyten har allerede gjort den delen, og dataene vil være klare for transformasjonslaget.
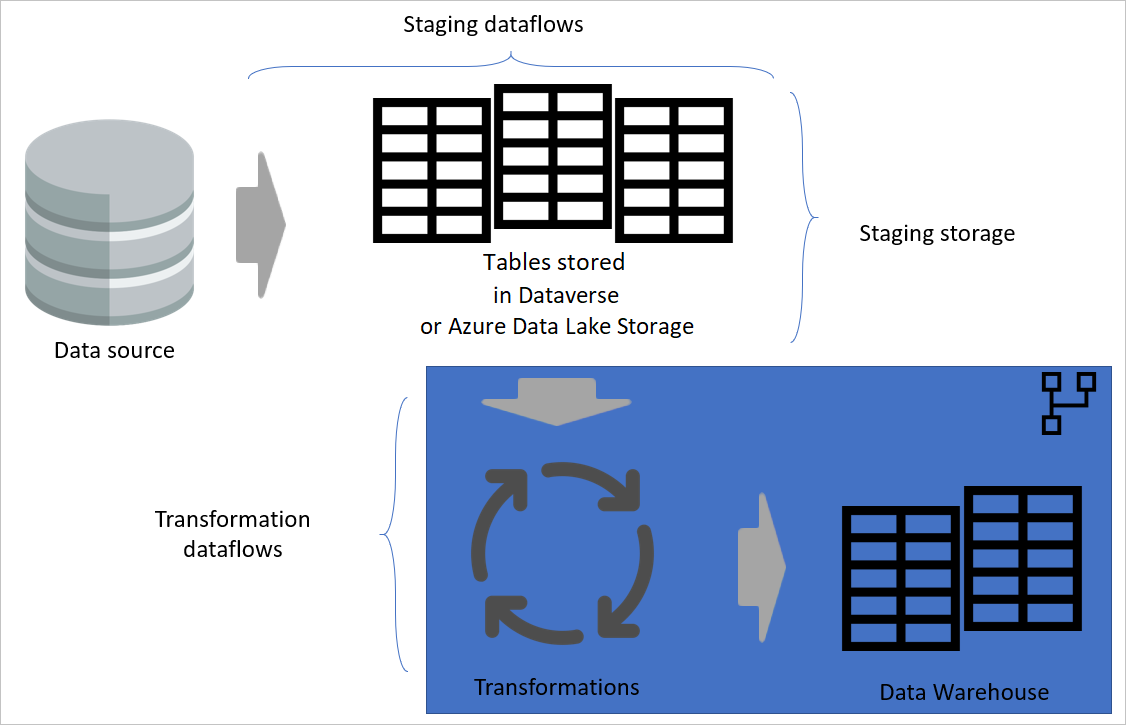
Lagdelt arkitektur
En lagdelt arkitektur er en arkitektur der du utfører handlinger i separate lag. Oppsamlings- og transformasjonsdataflytene kan være to lag med en flerlags dataflytarkitektur. Forsøk på å utføre handlinger i lag sikrer det minste vedlikeholdet som kreves. Når du vil endre noe, trenger du bare å endre det i laget der det er plassert. De andre lagene skal fortsette å fungere fint.
Bildet nedenfor viser en flerlags arkitektur for dataflyter der tabellene deres deretter brukes i semantiske modeller i Power BI.
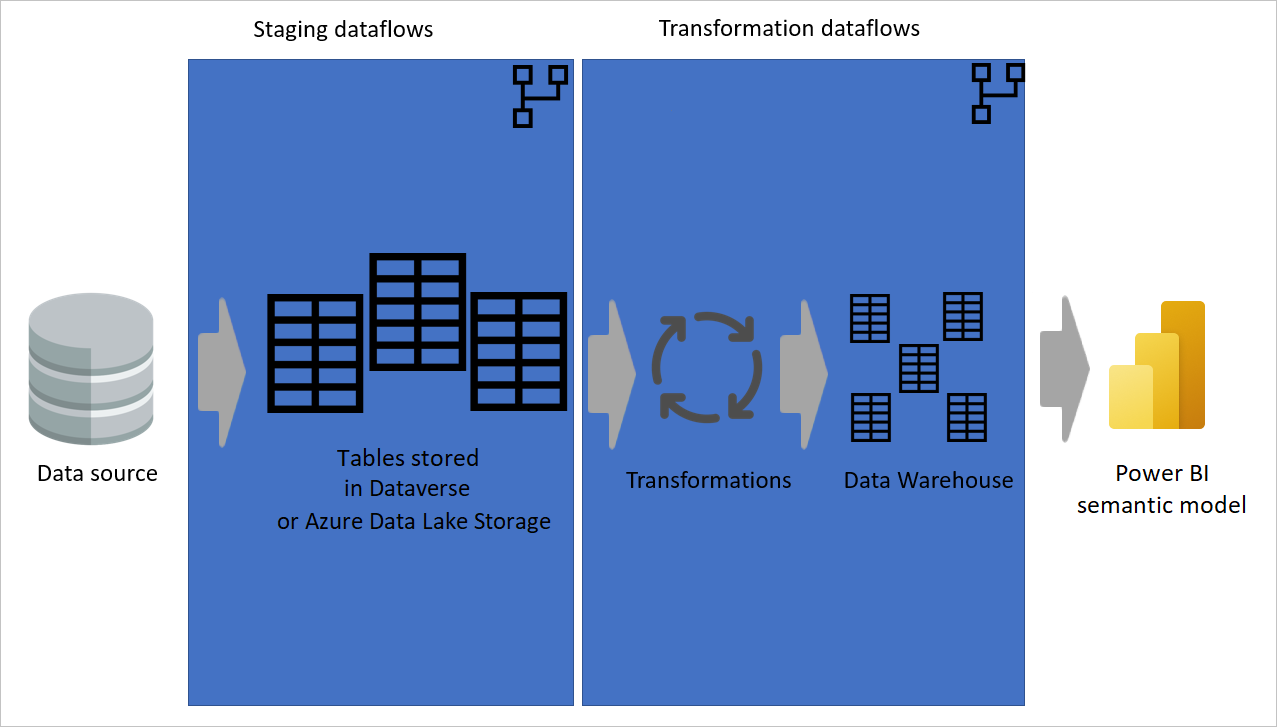
Bruke en beregnet tabell så mye som mulig
Når du bruker resultatet av en dataflyt i en annen dataflyt, bruker du konseptet med den beregnede tabellen, noe som betyr å hente data fra en «allerede behandlet og lagret» tabell. Det samme kan skje i en dataflyt. Når du refererer til en tabell fra en annen tabell, kan du bruke den beregnede tabellen. Dette er nyttig når du har et sett med transformasjoner som må gjøres i flere tabeller, som kalles vanlige transformasjoner.
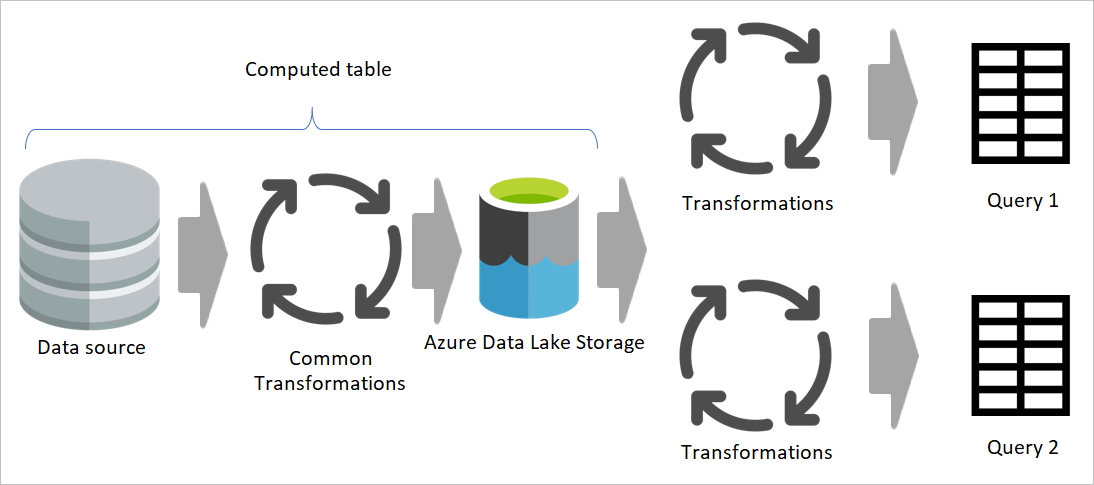
I det forrige bildet henter den beregnede tabellen dataene direkte fra kilden. Men i arkitekturen for oppsamlings- og transformasjonsdataflyter er det sannsynlig at de beregnede tabellene er hentet fra de oppsamlingsdataflytene.
Bygge et stjerneskjema
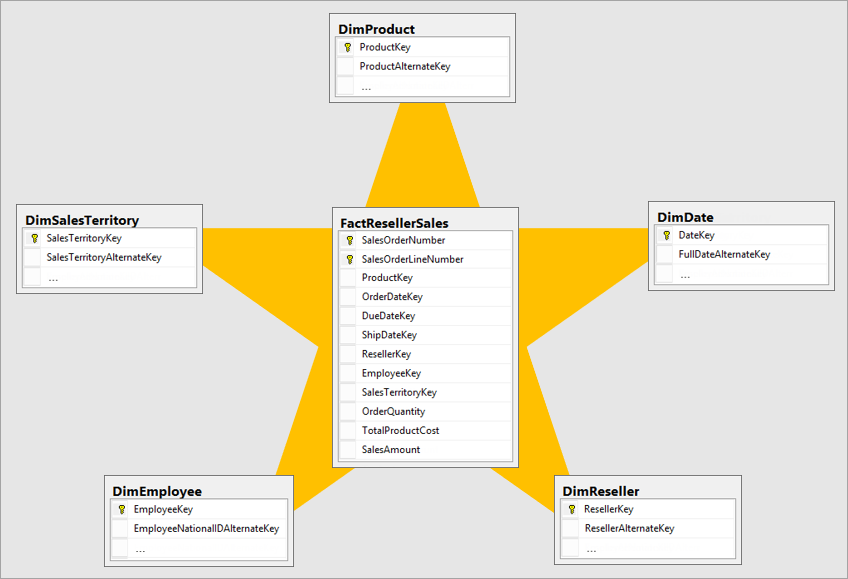
Den beste dimensjonsmodellen er en stjerneskjemamodell som har dimensjoner og faktatabeller utformet på en måte som minimerer tiden det tar å spørre etter dataene fra modellen, og gjør det også enkelt å forstå for datavisualisereren.
Det er ikke ideelt å hente data i samme oppsett av operativsystemet til et BI-system. Datatabellene skal være ombygd. Noen av tabellene bør ta form av en dimensjonstabell, som beholder den beskrivende informasjonen. Noen av tabellene bør ta form av en faktatabell for å beholde de smidige dataene. Det beste oppsettet for faktatabeller og dimensjonstabeller som skal dannes, er et stjerneskjema. Mer informasjon: Forstå stjerneskjema og viktigheten for Power BI
Bruk en unik nøkkelverdi for dimensjoner
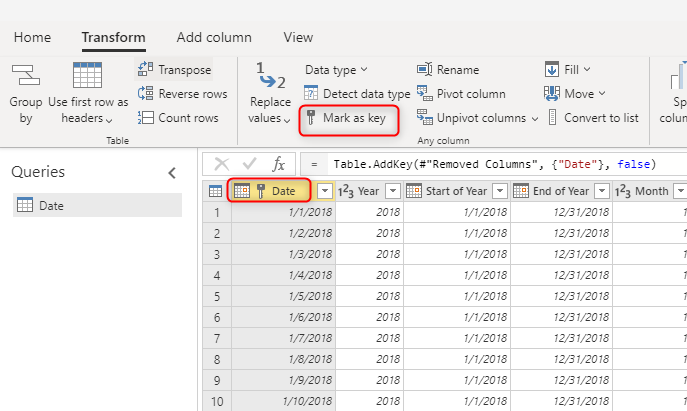
Når du bygger dimensjonstabeller, må du kontrollere at du har en nøkkel for hver av dem. Denne nøkkelen sikrer at det ikke finnes mange-til-mange (eller med andre ord "svake") relasjoner mellom dimensjoner. Du kan opprette nøkkelen ved å bruke litt transformasjon for å sikre at en kolonne eller en kombinasjon av kolonner returnerer unike rader i dimensjonen. Deretter kan denne kombinasjonen av kolonner merkes som en nøkkel i tabellen i dataflyten.
Gjør en trinnvis oppdatering for store faktatabeller
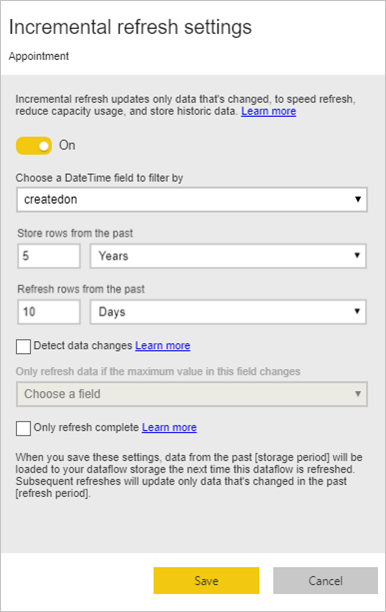
Faktatabeller er alltid de største tabellene i den dimensjonale modellen. Vi anbefaler at du reduserer antall rader som overføres for disse tabellene. Hvis du har en veldig stor faktatabell, må du kontrollere at du bruker trinnvis oppdatering for tabellen. En trinnvis oppdatering kan gjøres i semantisk Power BI-modell, og også dataflyttabellene.
Du kan bruke trinnvis oppdatering til å oppdatere bare en del av dataene, delen som er endret. Det finnes flere alternativer for å velge hvilken del av dataene som skal oppdateres, og hvilken del som skal beholdes. Mer informasjon: Bruke trinnvis oppdatering med Power BI-dataflyter
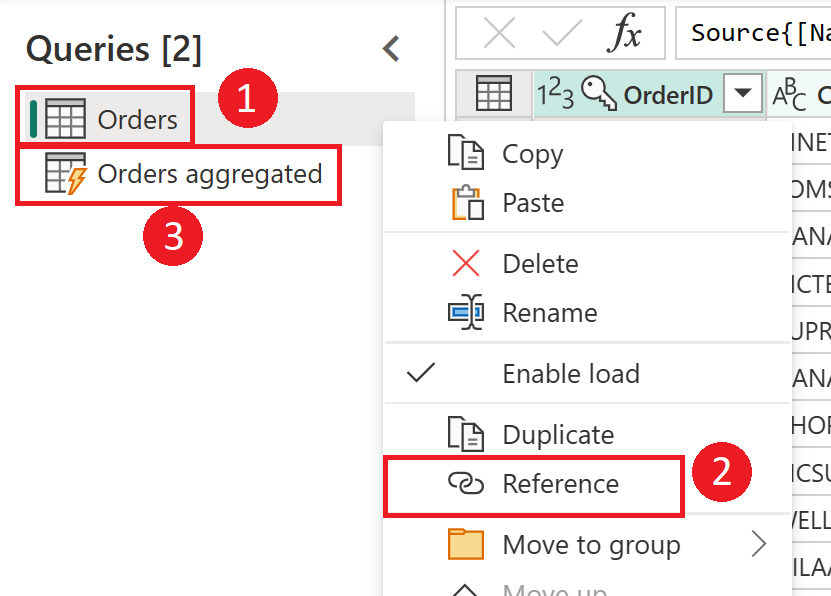
Refererer til å opprette dimensjoner og faktatabeller
I kildesystemet har du ofte en tabell som du bruker til å generere både fakta- og dimensjonstabeller i datalageret. Disse tabellene er gode kandidater for beregnede tabeller og også mellomliggende dataflyter. Den vanlige delen av prosessen, for eksempel datarengjøring og fjerning av ekstra rader og kolonner, kan gjøres én gang. Ved å bruke en referanse fra utdataene for disse handlingene, kan du produsere dimensjons- og faktatabellene. Denne fremgangsmåten bruker den beregnede tabellen for de vanlige transformasjonene.
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for