Gegevens kopiëren van Azure Data Lake Storage Gen1 naar Gen2 met Azure Data Factory
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Azure Data Lake Storage Gen2 is een set mogelijkheden die is toegewezen aan big data-analyses die zijn ingebouwd in Azure Blob Storage. U kunt het gebruiken om interactie met uw gegevens te maken met behulp van paradigma's voor zowel het bestandssysteem als de objectopslag.
Als u momenteel Azure Data Lake Storage Gen1 gebruikt, kunt u Azure Data Lake Storage Gen2 evalueren door gegevens van Data Lake Storage Gen1 naar Gen2 te kopiëren met behulp van Azure Data Factory.
Azure Data Factory is een volledig beheerde cloudservice voor gegevensintegratie. U kunt de service gebruiken om het meer te vullen met gegevens uit een uitgebreide set on-premises en cloudgegevensarchieven en om tijd te besparen wanneer u uw analyseoplossingen bouwt. Zie de tabel met ondersteunde gegevensarchieven voor een lijst met ondersteunde connectors.
Azure Data Factory biedt een oplossing voor het uitschalen van beheerde gegevensverplaatsing. Vanwege de uitschaalarchitectuur van Data Factory kan deze gegevens opnemen met een hoge doorvoer. Zie Copy-activiteit prestaties voor meer informatie.
In dit artikel leest u hoe u het hulpprogramma voor het kopiëren van gegevens van Data Factory gebruikt om gegevens uit Azure Data Lake Storage Gen1 te kopiëren naar Azure Data Lake Storage Gen2. U kunt vergelijkbare stappen volgen om gegevens te kopiëren vanuit andere typen gegevensarchieven.
Vereisten
- Een Azure-abonnement. Als u nog geen abonnement op Azure hebt, maak dan een gratis account aan voordat u begint.
- Azure Data Lake Storage Gen1-account met daarin gegevens.
- Azure Storage-account waarvoor Data Lake Storage Gen2 is ingeschakeld. Als u geen opslagaccount hebt, maakt u een account.
Een data factory maken
Als u uw data factory nog niet hebt gemaakt, volgt u de stappen in quickstart: Een gegevensfactory maken met behulp van Azure Portal en Azure Data Factory Studio om er een te maken. Nadat u deze hebt gemaakt, bladert u naar de data factory in Azure Portal.
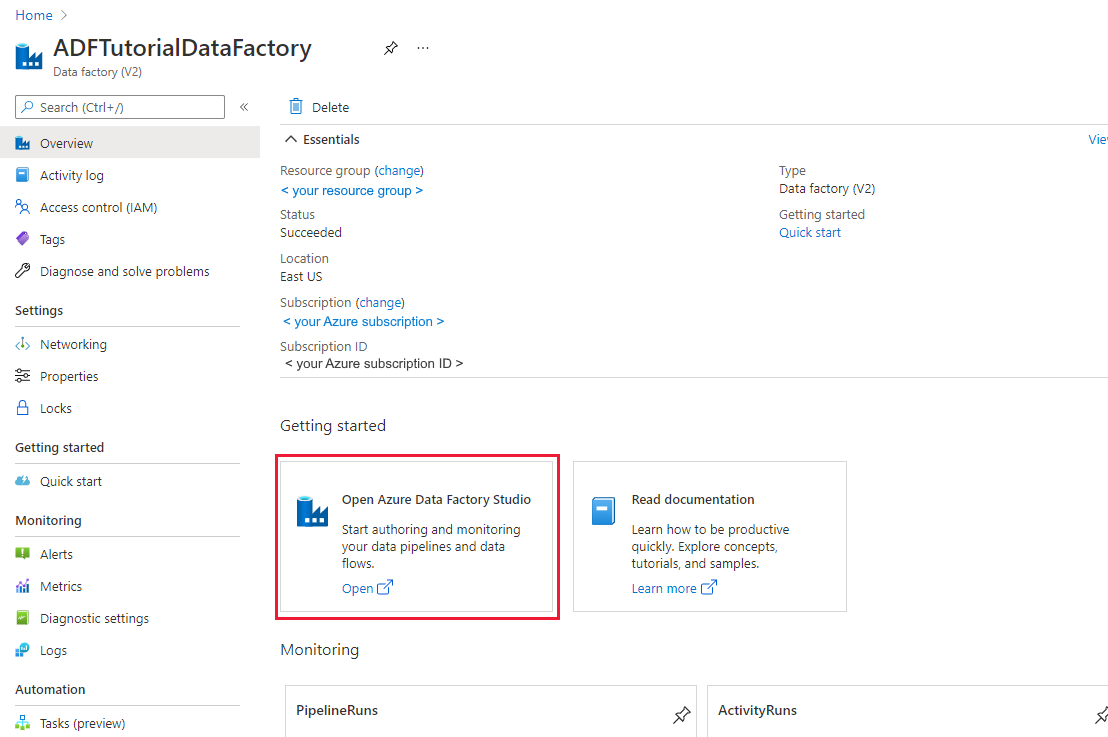
Selecteer Openen op de tegel Azure Data Factory Studio openen om de Data-Integratie toepassing op een afzonderlijk tabblad te starten.
Gegevens laden in Azure Data Lake Storage Gen2
Selecteer op de startpagina de tegel Opnemen om het hulpprogramma voor het kopiëren van gegevens te starten.
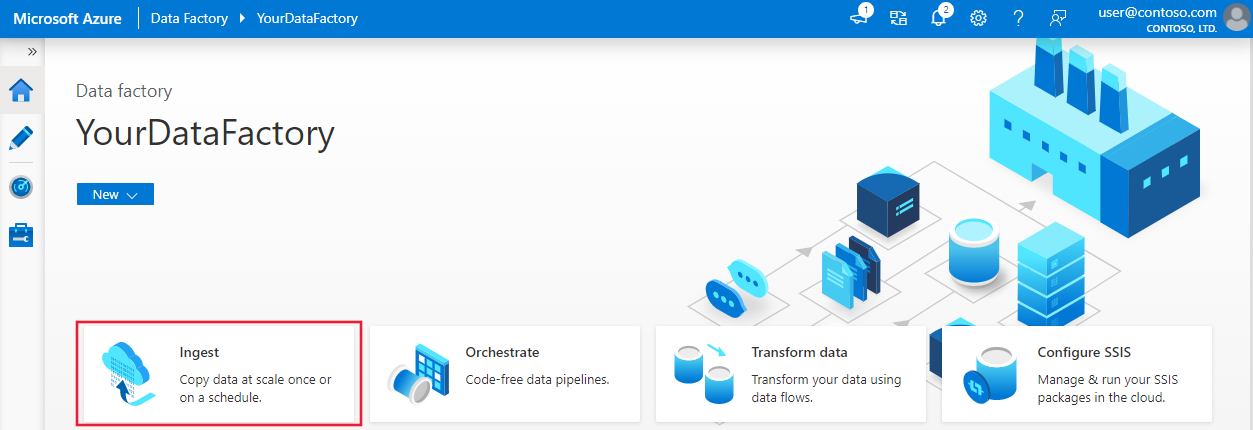
Kies op de pagina Eigenschappen de optie Ingebouwde kopieertaak onder Taaktype en kies Eenmaal uitvoeren onder Taakfrequentie of taakschema en selecteer Vervolgens Volgende.
Selecteer + Nieuwe verbinding op de pagina Brongegevensarchief.
Selecteer Azure Data Lake Storage Gen1 in de connectorgalerie en selecteer Doorgaan.
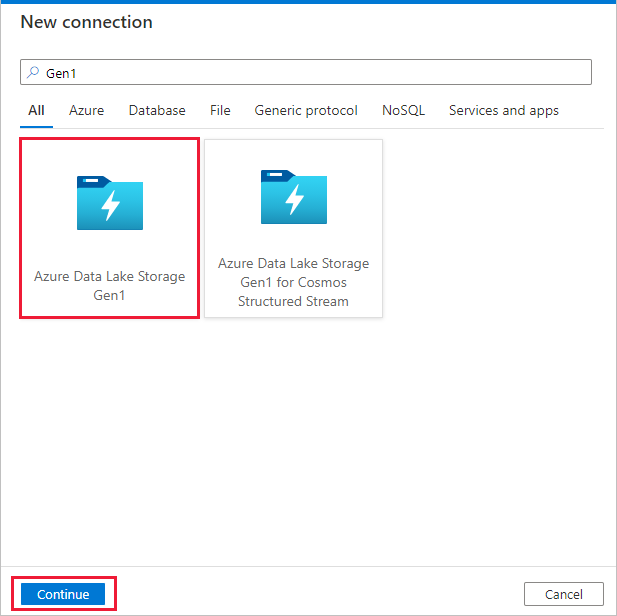
Voer op de pagina Nieuwe verbinding (Azure Data Lake Storage Gen1) de volgende stappen uit:
- Selecteer uw Data Lake Storage Gen1 voor de accountnaam en geef de tenant op of valideer deze.
- Selecteer Verbinding testen om de instellingen te valideren. Selecteer vervolgens Maken.
Belangrijk
In dit overzicht gebruikt u een beheerde identiteit voor Azure-resources om uw Azure Data Lake Storage Gen1 te verifiëren. Volg deze instructies om de beheerde identiteit de juiste machtigingen te verlenen in Azure Data Lake Storage Gen1.
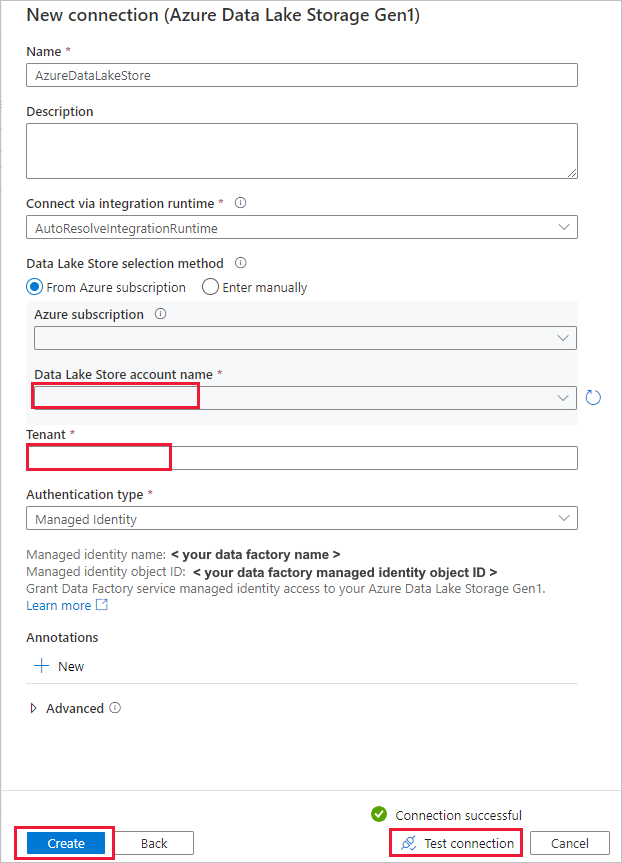
Voer op de pagina Brongegevensarchief de volgende stappen uit.
- Selecteer de zojuist gemaakte verbinding in de sectie Verbinding maken ion.
- Blader onder Bestand of map naar de map en het bestand dat u wilt kopiëren. Selecteer de map of het bestand en selecteer OK.
- Geef het kopieergedrag op door de opties Recursief en Binair kopiëren te selecteren. Selecteer Volgende.
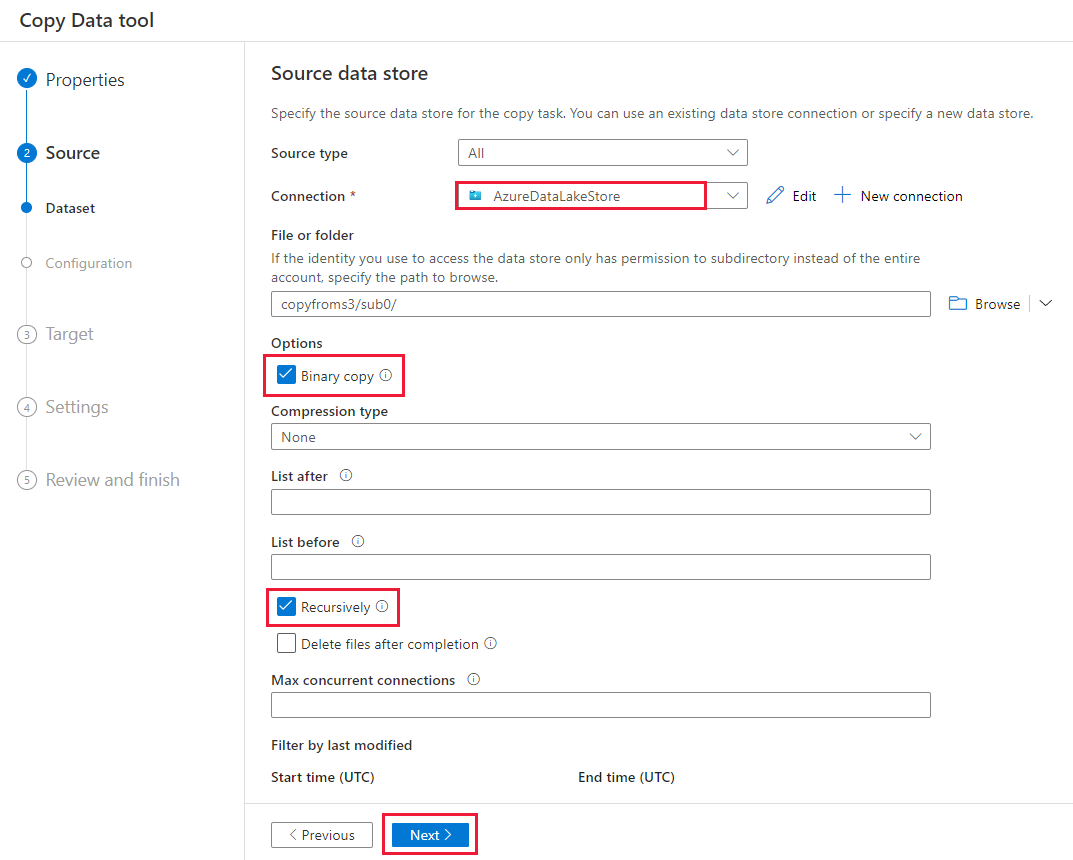
Selecteer + Nieuwe verbinding>in Azure Data Lake Storage Gen2>op de pagina Doelgegevensarchief.

Voer op de pagina Nieuwe verbinding (Azure Data Lake Storage Gen2) de volgende stappen uit:
- Selecteer uw Data Lake Storage Gen2-account dat geschikt is in de vervolgkeuzelijst Opslagaccountnaam .
- Selecteer Maken om de verbinding te maken.

Voer op de pagina Doelgegevensarchief de volgende stappen uit.
- Selecteer de zojuist gemaakte verbinding in het Verbinding maken ionblok.
- Voer onder Mappad copyfromadlsgen1 in als de naam van de uitvoermap en selecteer Volgende. Data Factory maakt het bijbehorende Azure Data Lake Storage Gen2-bestandssysteem en submappen tijdens het kopiëren als deze niet bestaan.
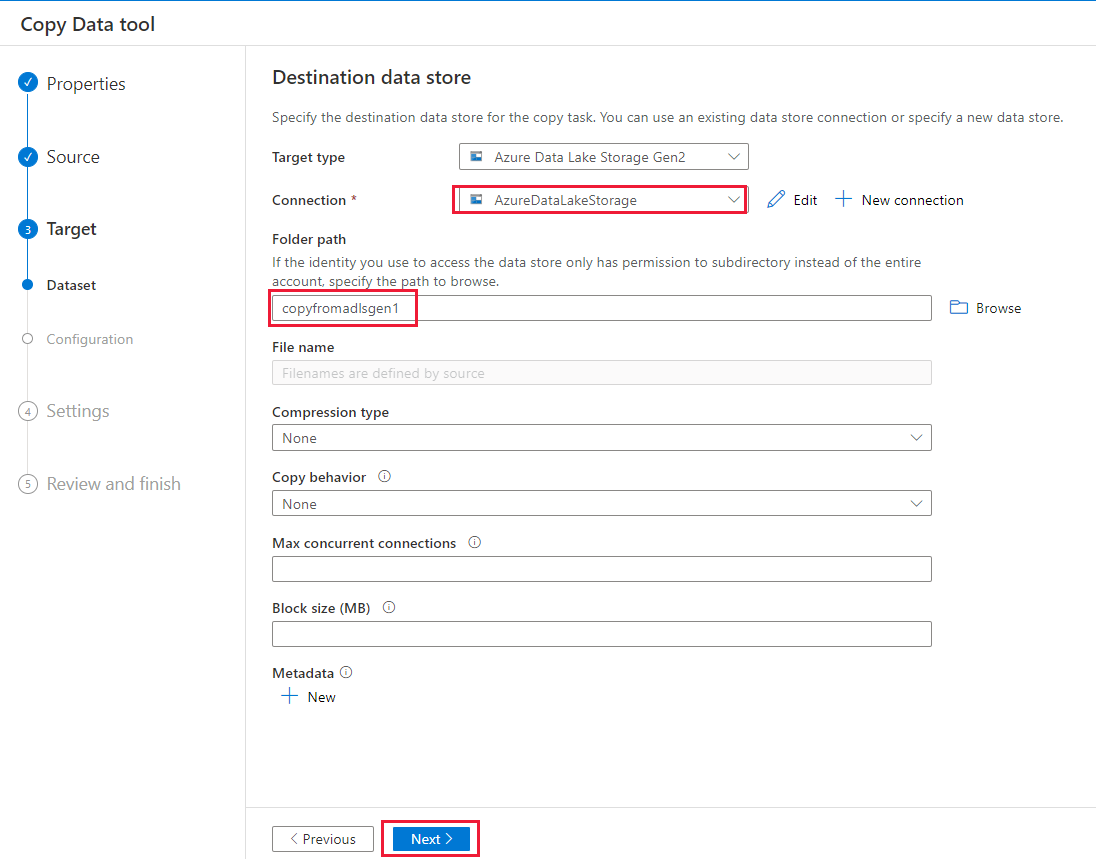
Geef op de pagina Instellingen CopyFromADLSGen1ToGen2 op voor het veld Taaknaam en selecteer vervolgens Volgende om de standaardinstellingen te gebruiken.
Controleer de instellingen op de pagina Samenvatting en selecteer Volgende.

Selecteer Controleren op de pagina Implementatie om de pijplijn te bewaken.
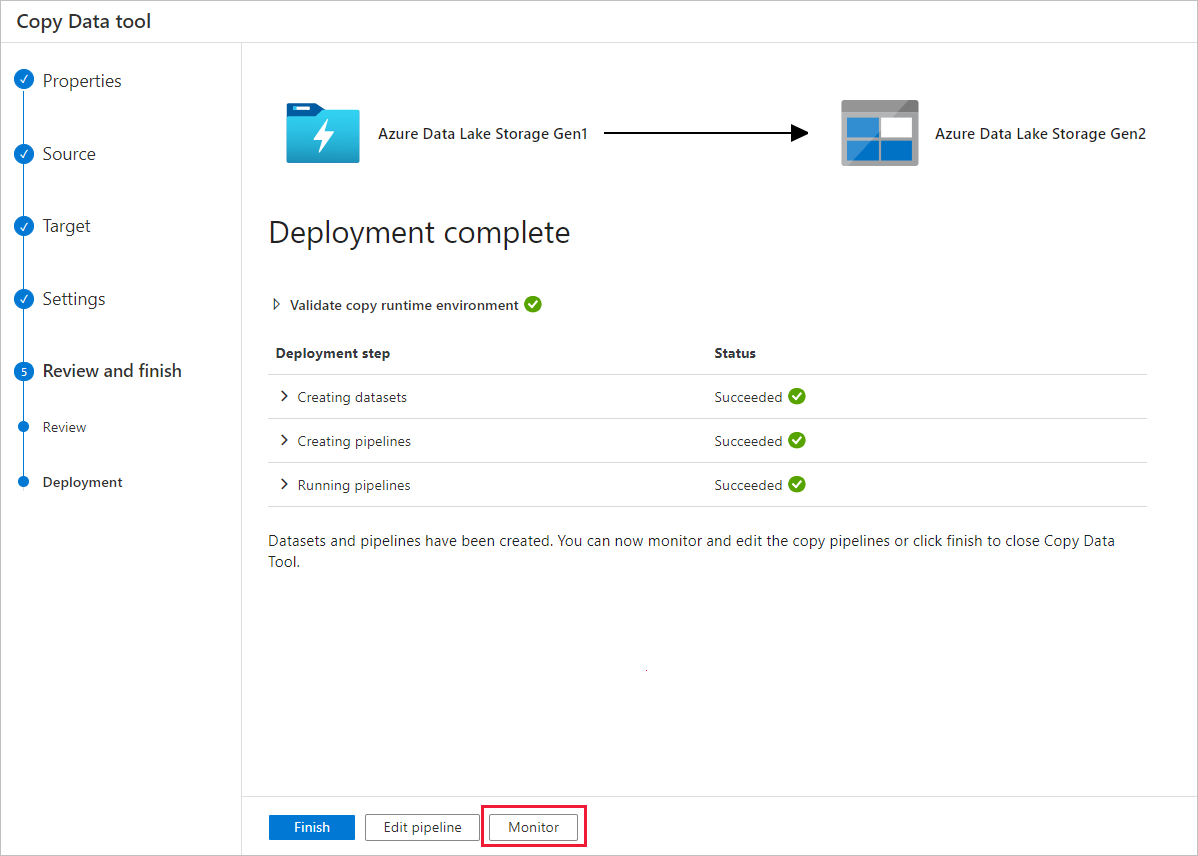
U ziet dat het tabblad Controleren aan de linkerkant automatisch wordt geselecteerd. De kolom Pijplijnnaam bevat koppelingen om details van de activiteitsuitvoering weer te geven en de pijplijn opnieuw uit te voeren.

Als u activiteitsuitvoeringen wilt weergeven die zijn gekoppeld aan de pijplijnuitvoering, selecteert u de koppeling in de kolom Pijplijnnaam . Omdat er slechts één activiteit (kopieeractiviteit) in de pijplijn is, ziet u slechts één vermelding in de lijst. Als u wilt teruggaan naar de weergave pijplijnuitvoeringen, selecteert u de koppeling Alle pijplijnuitvoeringen in het breadcrumb-menu bovenaan. Selecteer Vernieuwen om de lijst te vernieuwen.
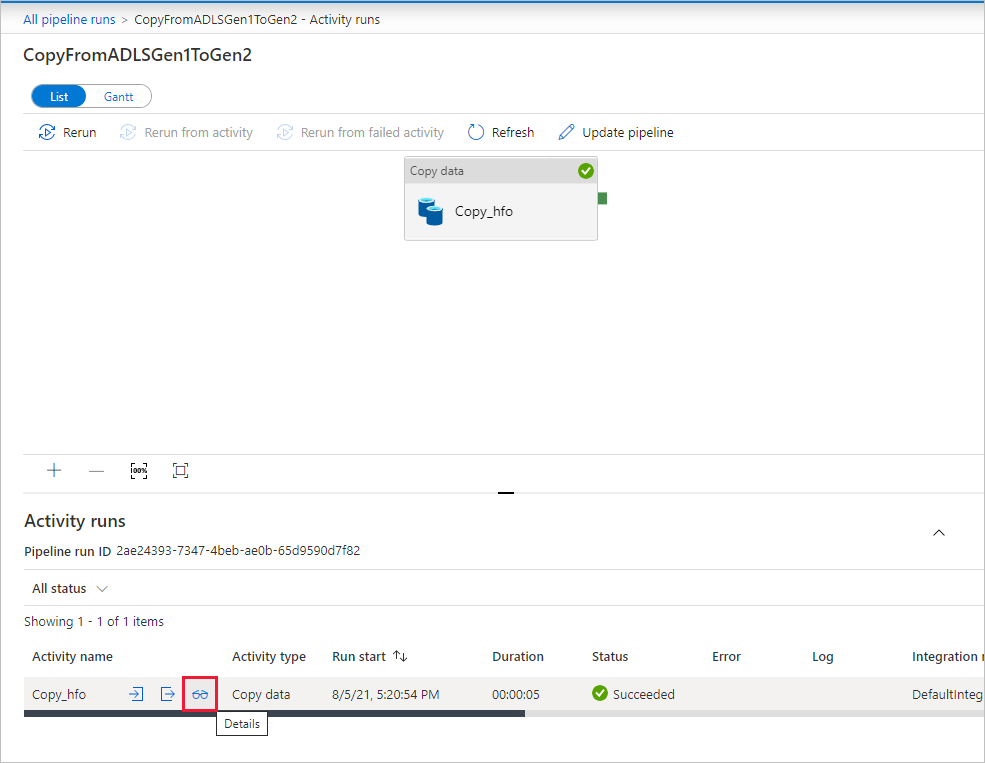
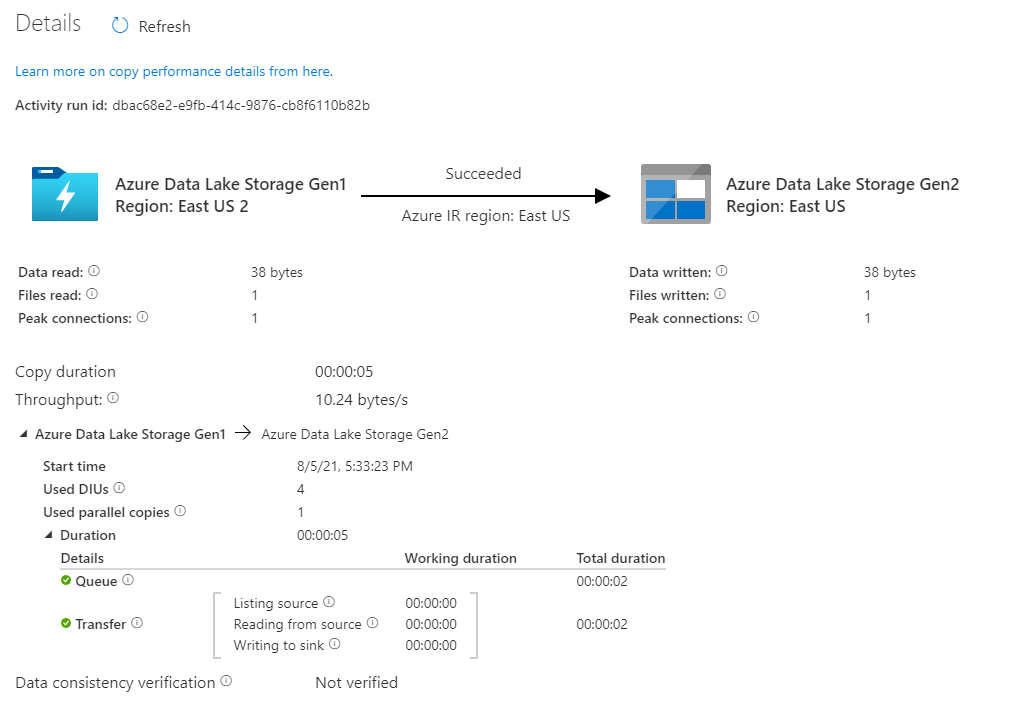
Als u de uitvoeringsdetails voor elke kopieeractiviteit wilt controleren, selecteert u de koppeling Details (afbeelding van een bril) onder de kolom Activiteitsnaam in de weergave Activiteitscontrole. U kunt details bekijken, zoals het volume van de gegevens die uit de bron zijn gekopieerd naar de sink, de gegevensdoorvoer, de uitvoeringsstappen met de overeenkomstige duur en de gebruikte configuraties.
Controleer of de gegevens worden gekopieerd naar uw Azure Data Lake Storage Gen2-account.
Aanbevolen procedures
Als u de upgrade van Azure Data Lake Storage Gen1 naar Azure Data Lake Storage Gen2 in het algemeen wilt evalueren, raadpleegt u Uw big data analytics-oplossingen upgraden van Azure Data Lake Storage Gen1 naar Azure Data Lake Storage Gen2. In de volgende secties worden aanbevolen procedures geïntroduceerd voor het gebruik van Data Factory voor een gegevensupgrade van Data Lake Storage Gen1 naar Data Lake Storage Gen2.
Eerste momentopnamegegevensmigratie
Prestaties
ADF biedt een serverloze architectuur waarmee parallelle uitvoering op verschillende niveaus mogelijk is, waardoor ontwikkelaars pijplijnen kunnen bouwen om volledig gebruik te maken van uw netwerkbandbreedte en opslag-IOPS en bandbreedte om de doorvoer van gegevensverplaatsing voor uw omgeving te maximaliseren.
Klanten hebben petabytes aan gegevens gemigreerd die bestaan uit honderden miljoenen bestanden van Data Lake Storage Gen1 naar Gen2, met een duurzame doorvoer van 2 GBps en hoger.
U kunt grotere snelheden voor gegevensverplaatsing bereiken door verschillende niveaus van parallelle uitvoering toe te passen:
- Eén kopieeractiviteit kan profiteren van schaalbare rekenresources: wanneer u Azure Integration Runtime gebruikt, kunt u maximaal 256 gegevensintegratie-eenheden (DIU's) opgeven voor elke kopieeractiviteit op een serverloze manier. Wanneer u zelf-hostende Integration Runtime gebruikt, kunt u de machine handmatig omhoog schalen of uitschalen naar meerdere computers (maximaal 4 knooppunten), en één kopieeractiviteit zal de bestandsset partitioneren op alle knooppunten.
- Eén kopieeractiviteit leest van en schrijft naar het gegevensarchief met behulp van meerdere threads.
- ADF-controlestroom kan meerdere kopieeractiviteiten parallel starten, bijvoorbeeld met behulp van voor elke lus.
Gegevenspartities
Als de totale gegevensgrootte in Data Lake Storage Gen1 kleiner is dan 10 TB en het aantal bestanden kleiner is dan 1 miljoen, kunt u alle gegevens kopiëren in één uitvoering van een kopieeractiviteit. Als u een grotere hoeveelheid gegevens wilt kopiëren of als u de flexibiliteit wilt hebben om de gegevensmigratie in batches te beheren en ze allemaal binnen een bepaald tijdsbestek te voltooien, partitioneert u de gegevens. Partitionering vermindert ook het risico op onverwacht probleem.
De manier om de bestanden te partitioneren, is het gebruik van naambereik- listAfter/listBefore in de eigenschap kopieeractiviteit. Elke kopieeractiviteit kan worden geconfigureerd om één partitie tegelijk te kopiëren, zodat meerdere kopieeractiviteiten gegevens van één Data Lake Storage Gen1-account kunnen kopiëren.
Snelheidsbeperking
Als best practice voert u een prestatie-POC uit met een representatieve voorbeeldgegevensset, zodat u de juiste partitiegrootte kunt bepalen.
Begin met één partitie en één kopieeractiviteit met standaard-DIU-instelling. De parallelle kopie wordt altijd voorgesteld om als leeg (standaard) in te stellen. Als de kopieerdoorvoer niet geschikt is voor u, identificeert en lost u de prestatieknelpunten op door de stappen voor het afstemmen van de prestaties te volgen.
Verhoog geleidelijk de DIU-instelling totdat u de bandbreedtelimiet van uw netwerk of IOPS/bandbreedtelimiet van de gegevensarchieven bereikt, of u hebt de maximaal 256 DIU bereikt die is toegestaan voor één kopieeractiviteit.
Als u de prestaties van één kopieeractiviteit hebt gemaximaliseerd, maar nog niet de bovenlimieten voor doorvoer van uw omgeving hebt bereikt, kunt u meerdere kopieeractiviteiten parallel uitvoeren.
Wanneer u een aanzienlijk aantal beperkingsfouten ziet bij het bewaken van kopieeractiviteiten, wordt aangegeven dat u de capaciteitslimiet van uw opslagaccount hebt bereikt. ADF probeert elke beperkingsfout automatisch te verhelpen om ervoor te zorgen dat er geen gegevens verloren gaan, maar er kunnen ook te veel nieuwe pogingen de kopieerdoorvoer verminderen. In dat geval wordt u aangeraden het aantal kopieeractiviteiten dat gelijktijdig wordt uitgevoerd te verminderen om aanzienlijke hoeveelheden beperkingsfouten te voorkomen. Als u één kopieeractiviteit hebt gebruikt om gegevens te kopiëren, wordt u aangeraden de DIU te verminderen.
Delta-gegevensmigratie
U kunt verschillende methoden gebruiken om alleen de nieuwe of bijgewerkte bestanden van Data Lake Storage Gen1 te laden:
- Laad nieuwe of bijgewerkte bestanden op tijd gepartitioneerde map of bestandsnaam. Een voorbeeld is /2019/05/13/*.
- Laad nieuwe of bijgewerkte bestanden door LastModifiedDate. Als u grote hoeveelheden bestanden kopieert, moet u eerst partities uitvoeren om te voorkomen dat een lage kopieerdoorvoer het resultaat is van het scannen van uw hele Data Lake Storage Gen1-account om nieuwe bestanden te identificeren.
- Identificeer nieuwe of bijgewerkte bestanden door een hulpprogramma of oplossing van derden. Geef vervolgens de naam van het bestand of de map door aan de Data Factory-pijplijn via een parameter of een tabel of bestand.
De juiste frequentie voor het uitvoeren van incrementele belasting is afhankelijk van het totale aantal bestanden in Azure Data Lake Storage Gen1 en het volume van nieuwe of bijgewerkte bestanden die telkens moeten worden geladen.
Netwerkbeveiliging
ADF draagt standaard gegevens over van Azure Data Lake Storage Gen1 naar Gen2 met behulp van een versleutelde verbinding via het HTTPS-protocol. HTTPS biedt gegevensversleuteling tijdens overdracht en voorkomt afluisteren en man-in-the-middle-aanvallen.
Als u niet wilt dat gegevens via openbaar internet worden overgedragen, kunt u ook een hogere beveiliging bereiken door gegevens over te dragen via een particulier netwerk.
ACL's behouden
Als u de ACL's samen met gegevensbestanden wilt repliceren wanneer u een upgrade uitvoert van Data Lake Storage Gen1 naar Data Lake Storage Gen2, raadpleegt u ACL's van Data Lake Storage Gen1 behouden.
Flexibiliteit
Binnen één uitvoering van een kopieeractiviteit heeft ADF een ingebouwd mechanisme voor opnieuw proberen, zodat het een bepaald niveau van tijdelijke fouten in de gegevensarchieven of in het onderliggende netwerk kan verwerken. Als u meer dan 10 TB-gegevens migreert, wordt u aangeraden de gegevens te partitioneren om het risico op onverwachte problemen te verminderen.
U kunt fouttolerantie in de kopieeractiviteit ook inschakelen om de vooraf gedefinieerde fouten over te slaan. De verificatie van gegevensconsistentie in kopieeractiviteit kan ook worden ingeschakeld om extra verificatie uit te voeren om ervoor te zorgen dat de gegevens niet alleen van bron naar doelarchief worden gekopieerd, maar ook om consistent te zijn tussen bron- en doelopslag.
Bevoegdheden
In Data Factory ondersteunt de Data Lake Storage Gen1-connector service-principal en beheerde identiteit voor Azure-resourceverificaties. De Data Lake Storage Gen2-connector ondersteunt accountsleutel, service-principal en beheerde identiteit voor Azure-resourceverificaties. Als u wilt dat Data Factory in staat is om door alle bestanden of toegangsbeheerlijsten (ACL's) te navigeren en te kopiëren, moet u voldoende machtigingen verlenen aan het account om alle bestanden te kunnen openen, lezen of schrijven en ACL's instellen als u dat wilt. U moet het account een rol van supergebruiker of eigenaar verlenen tijdens de migratieperiode en de verhoogde machtigingen verwijderen zodra de migratie is voltooid.