Gearchiveerde releaseopmerkingen
Samenvatting
Azure HDInsight is een van de populairste services van zakelijke klanten voor opensource-analyses in Azure. Abonneer u op de releaseopmerkingen voor HDInsight voor actuele informatie in HDInsight en alle HDInsight-versies.
Als u zich wilt abonneren, klikt u op de knop 'watch' in de banner en kijkt u uit voor HDInsight-releases.
Release-informatie
Releasedatum: 15 februari 2024
Deze release is van toepassing op HDInsight 4.x- en 5.x-versies. HDInsight-release is gedurende meerdere dagen beschikbaar voor alle regio's. Deze release is van toepassing op afbeeldingsnummer 2401250802. Het installatiekopienummer controleren
HDInsight maakt gebruik van veilige implementatieprocedures, waarbij geleidelijke implementatie van regio's is betrokken. Het kan maximaal 10 werkdagen duren voordat een nieuwe release of een nieuwe versie beschikbaar is in alle regio's.
Besturingssysteemversies
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Notitie
Ubuntu 18.04 wordt ondersteund onder Extended Security Maintenance (ESM) door het Azure Linux-team voor Azure HDInsight juli 2023, release en hoger.
Zie Voor workloadspecifieke versies
Nieuwe functies
- Apache Ranger-ondersteuning voor Spark SQL in Spark 3.3.0 (HDInsight versie 5.1) met enterprise-beveiligingspakket. Hier vindt u meer informatie.
Problemen opgelost
- Beveiligingsoplossingen van Ambari- en Oozie-onderdelen
 Binnenkort beschikbaar
Binnenkort beschikbaar
- Vm's uit de Basic- en Standard A-serie buiten gebruik gesteld.
- Op 31 augustus 2024 gaan we vm's uit de Basic- en Standard A-serie buiten gebruik stellen. Vóór die datum moet u uw workloads migreren naar AV2-serie-VM's, die meer geheugen per vCPU bieden en snellere opslag op SSD's (Solid-State Drives).
- Als u serviceonderbrekingen wilt voorkomen, migreert u uw workloads van vm's uit de Basic- en Standard A-serie naar av2-serie-VM's vóór 31 augustus 2024.
Neem contact op met de ondersteuning van Azure als u nog vragen hebt.
U kunt ons altijd vragen over HDInsight in Azure HDInsight - Microsoft Q&A
We luisteren: u bent welkom om hier meer ideeën en andere onderwerpen toe te voegen en erop te stemmen - HDInsight Ideas en volg ons voor meer updates op de AzureHDInsight-community
Notitie
We adviseren klanten om te gebruiken voor de nieuwste versies van HDInsight-installatiekopieën wanneer ze het beste van opensource-updates, Azure-updates en beveiligingsoplossingen bieden. Zie Best practices voor meer informatie.
Volgende stappen
- Azure HDInsight: veelgestelde vragen
- Het patchschema voor het besturingssysteem configureren voor HDInsight-clusters op basis van Linux
- Vorige releasenotitie
Azure HDInsight is een van de populairste services van zakelijke klanten voor opensource-analyses in Azure. Als u zich wilt abonneren op releaseopmerkingen, bekijkt u releases in deze GitHub-opslagplaats.
Releasedatum: 10 januari 2024
Deze hotfixrelease is van toepassing op HDInsight 4.x- en 5.x-versies. HDInsight-release is gedurende meerdere dagen beschikbaar voor alle regio's. Deze release is van toepassing op afbeeldingsnummer 2401030422. Het installatiekopienummer controleren
HDInsight maakt gebruik van veilige implementatieprocedures, waarbij geleidelijke implementatie van regio's is betrokken. Het kan maximaal 10 werkdagen duren voordat een nieuwe release of een nieuwe versie beschikbaar is in alle regio's.
Besturingssysteemversies
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Notitie
Ubuntu 18.04 wordt ondersteund onder Extended Security Maintenance (ESM) door het Azure Linux-team voor Azure HDInsight juli 2023, release en hoger.
Zie Voor workloadspecifieke versies
Problemen opgelost
- Beveiligingsoplossingen van Ambari- en Oozie-onderdelen
Binnenkort beschikbaar
- Vm's uit de Basic- en Standard A-serie buiten gebruik gesteld.
- Op 31 augustus 2024 gaan we vm's uit de Basic- en Standard A-serie buiten gebruik stellen. Vóór die datum moet u uw workloads migreren naar AV2-serie-VM's, die meer geheugen per vCPU bieden en snellere opslag op SSD's (Solid-State Drives).
- Als u serviceonderbrekingen wilt voorkomen, migreert u uw workloads van vm's uit de Basic- en Standard A-serie naar av2-serie-VM's vóór 31 augustus 2024.
Neem contact op met de ondersteuning van Azure als u nog vragen hebt.
U kunt ons altijd vragen over HDInsight in Azure HDInsight - Microsoft Q&A
We luisteren: u bent welkom om hier meer ideeën en andere onderwerpen toe te voegen en erop te stemmen - HDInsight Ideas en volg ons voor meer updates op de AzureHDInsight-community
Notitie
We adviseren klanten om te gebruiken voor de nieuwste versies van HDInsight-installatiekopieën wanneer ze het beste van opensource-updates, Azure-updates en beveiligingsoplossingen bieden. Zie Best practices voor meer informatie.
Releasedatum: 26 oktober 2023
Deze release is van toepassing op HDInsight 4.x en 5.x HDInsight-release is beschikbaar voor alle regio's gedurende meerdere dagen. Deze release is van toepassing op afbeeldingsnummer 2310140056. Het installatiekopienummer controleren
HDInsight maakt gebruik van veilige implementatieprocedures, waarbij geleidelijke implementatie van regio's is betrokken. Het kan maximaal 10 werkdagen duren voordat een nieuwe release of een nieuwe versie beschikbaar is in alle regio's.
Besturingssysteemversies
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Zie Voor workloadspecifieke versies
Nieuwe functies
HDInsight kondigt de algemene beschikbaarheid van HDInsight 5.1 aan vanaf 1 november 2023. Deze release brengt een volledige stackvernieuwing naar de opensource-onderdelen en de integraties van Microsoft.
- Nieuwste opensourceversies : HDInsight 5.1 wordt geleverd met de nieuwste stabiele opensource-versie . Klanten kunnen profiteren van alle nieuwste opensource-functies, prestatieverbeteringen van Microsoft en oplossingen voor fouten.
- Beveiligd: de nieuwste versies worden geleverd met de meest recente beveiligingsoplossingen, zowel opensource-beveiligingsoplossingen als beveiligingsverbeteringen van Microsoft.
- Lagere TCO: met prestatieverbeteringen kunnen klanten de operationele kosten verlagen, samen met verbeterde automatische schaalaanpassing.
Clustermachtigingen voor beveiligde opslag
- Klanten kunnen opgeven (tijdens het maken van clusters) of een beveiligd kanaal moet worden gebruikt voor HDInsight-clusterknooppunten om het opslagaccount te verbinden.
HDInsight-cluster maken met aangepaste VNets.
- Om de algehele beveiligingspostuur van de HDInsight-clusters te verbeteren, moeten HDInsight-clusters met behulp van aangepaste VNET's ervoor zorgen dat de gebruiker gemachtigd moet zijn om
Microsoft Network/virtualNetworks/subnets/join/actionbewerkingen te kunnen maken. De klant kan fouten ondervinden bij het maken als deze controle niet is ingeschakeld.
- Om de algehele beveiligingspostuur van de HDInsight-clusters te verbeteren, moeten HDInsight-clusters met behulp van aangepaste VNET's ervoor zorgen dat de gebruiker gemachtigd moet zijn om
Niet-ESP ABFS-clusters [Clustermachtigingen voor Word leesbaar]
- Niet-ESP ABFS-clusters beperken niet-Hadoop-groepsgebruikers van het uitvoeren van Hadoop-opdrachten voor opslagbewerkingen. Deze wijziging verbetert de beveiligingspostuur van het cluster.
Update van inlinequotum.
- Nu kunt u de quotumverhoging rechtstreeks aanvragen via de pagina Mijn quotum, met de directe API-aanroep is dit veel sneller. Als de API-aanroep mislukt, kunt u een nieuwe ondersteuningsaanvraag voor quotumverhoging maken.
Binnenkort beschikbaar
De maximale lengte van de clusternaam wordt gewijzigd van 45 naar 59 tekens om de beveiligingspostuur van clusters te verbeteren. Deze wijziging wordt geïmplementeerd in alle regio's die beginnen met de aanstaande release.
Vm's uit de Basic- en Standard A-serie buiten gebruik gesteld.
- Op 31 augustus 2024 gaan we vm's uit de Basic- en Standard A-serie buiten gebruik stellen. Vóór die datum moet u uw workloads migreren naar AV2-serie-VM's, die meer geheugen per vCPU bieden en snellere opslag op SSD's (Solid-State Drives).
- Als u serviceonderbrekingen wilt voorkomen, migreert u uw workloads van vm's uit de Basic- en Standard A-serie naar av2-serie-VM's vóór 31 augustus 2024.
Neem contact op met de ondersteuning van Azure als u nog vragen hebt.
U kunt ons altijd vragen over HDInsight in Azure HDInsight - Microsoft Q&A
We luisteren: u bent welkom om hier meer ideeën en andere onderwerpen toe te voegen en erop te stemmen - HDInsight Ideas en volg ons voor meer updates op de AzureHDInsight-community
Notitie
Deze release heeft betrekking op de volgende CV's die op 12 september 2023 door MSRC zijn uitgebracht. De actie is om bij te werken naar de meest recente installatiekopieën 2308221128 of 2310140056. Klanten worden geadviseerd om dienovereenkomstig te plannen.
| CVE | Ernst | CVE-titel | Opmerking |
|---|---|---|---|
| CVE-2023-38156 | Belangrijk | Azure HDInsight Apache Ambari-uitbreiding van beveiligingsproblemen met bevoegdheden | Opgenomen in installatiekopie 2308221128 of 2310140056 |
| CVE-2023-36419 | Belangrijk | Azure HDInsight Apache Oozie Workflow Scheduler-uitbreiding van beveiligingsprobleem met bevoegdheden | Pas scriptactie toe op uw clusters of werk bij naar installatiekopie 2310140056 |
Notitie
We adviseren klanten om te gebruiken voor de nieuwste versies van HDInsight-installatiekopieën wanneer ze het beste van opensource-updates, Azure-updates en beveiligingsoplossingen bieden. Zie Best practices voor meer informatie.
Releasedatum: 7 september 2023
Deze release is van toepassing op HDInsight 4.x en 5.x HDInsight-release is beschikbaar voor alle regio's gedurende meerdere dagen. Deze release is van toepassing op afbeeldingsnummer 2308221128. Het installatiekopienummer controleren
HDInsight maakt gebruik van veilige implementatieprocedures, waarbij geleidelijke implementatie van regio's is betrokken. Het kan maximaal 10 werkdagen duren voordat een nieuwe release of een nieuwe versie beschikbaar is in alle regio's.
Besturingssysteemversies
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Zie Voor workloadspecifieke versies
Belangrijk
Deze release heeft betrekking op de volgende CV's die op 12 september 2023 door MSRC zijn uitgebracht. De actie is om bij te werken naar de meest recente installatiekopieën 2308221128. Klanten worden geadviseerd om dienovereenkomstig te plannen.
| CVE | Ernst | CVE-titel | Opmerking |
|---|---|---|---|
| CVE-2023-38156 | Belangrijk | Azure HDInsight Apache Ambari-uitbreiding van beveiligingsproblemen met bevoegdheden | Opgenomen in 2308221128 afbeelding |
| CVE-2023-36419 | Belangrijk | Azure HDInsight Apache Oozie Workflow Scheduler-uitbreiding van beveiligingsprobleem met bevoegdheden | Scriptactie toepassen op uw clusters |
Binnenkort beschikbaar
- De maximale lengte van de clusternaam wordt gewijzigd van 45 naar 59 tekens om de beveiligingspostuur van clusters te verbeteren. Deze wijziging wordt geïmplementeerd op 30 september 2023.
- Clustermachtigingen voor beveiligde opslag
- Klanten kunnen opgeven (tijdens het maken van clusters) of een beveiligd kanaal moet worden gebruikt voor HDInsight-clusterknooppunten om contact op te maken met het opslagaccount.
- Update van inlinequotum.
- Aanvraagquota verhogen rechtstreeks vanaf de pagina Mijn quotum. Dit is een directe API-aanroep. Dit is sneller. Als de APdI-aanroep mislukt, moeten klanten een nieuwe ondersteuningsaanvraag voor quotumverhoging maken.
- HDInsight-cluster maken met aangepaste VNets.
- Om de algehele beveiligingspostuur van de HDInsight-clusters te verbeteren, moeten HDInsight-clusters met behulp van aangepaste VNET's ervoor zorgen dat de gebruiker gemachtigd moet zijn om
Microsoft Network/virtualNetworks/subnets/join/actionbewerkingen te kunnen maken. Klanten moeten dienovereenkomstig plannen omdat deze wijziging een verplichte controle zou zijn om fouten bij het maken van clusters vóór 30 september 2023 te voorkomen.
- Om de algehele beveiligingspostuur van de HDInsight-clusters te verbeteren, moeten HDInsight-clusters met behulp van aangepaste VNET's ervoor zorgen dat de gebruiker gemachtigd moet zijn om
- Vm's uit de Basic- en Standard A-serie buiten gebruik gesteld.
- Op 31 augustus 2024 gaan we vm's uit de Basic- en Standard A-serie buiten gebruik stellen. Vóór die datum moet u uw workloads migreren naar AV2-serie-VM's, die meer geheugen per vCPU bieden en snellere opslag op SSD's (Solid-State Drives). Als u serviceonderbrekingen wilt voorkomen, migreert u uw workloads van vm's uit de Basic- en Standard A-serie naar av2-serie-VM's vóór 31 augustus 2024.
- Niet-ESP ABFS-clusters [Clustermachtigingen voor Word leesbaar]
- Plan om een wijziging in niet-ESP ABFS-clusters te introduceren, waardoor gebruikers die geen Hadoop-groep zijn, geen Hadoop-opdrachten kunnen uitvoeren voor opslagbewerkingen. Deze wijziging om het beveiligingspostuur van het cluster te verbeteren. Klanten moeten de updates plannen vóór 30 september 2023.
Neem contact op met de ondersteuning van Azure als u nog vragen hebt.
U kunt ons altijd vragen over HDInsight in Azure HDInsight - Microsoft Q&A
U bent van harte welkom om hier meer voorstellen en ideeën en andere onderwerpen toe te voegen en voor hen te stemmen - HDInsight Community (azure.com).
Notitie
We adviseren klanten om te gebruiken voor de nieuwste versies van HDInsight-installatiekopieën wanneer ze het beste van opensource-updates, Azure-updates en beveiligingsoplossingen bieden. Zie Best practices voor meer informatie.
Releasedatum: 25 juli 2023
Deze release is van toepassing op HDInsight 4.x en 5.x HDInsight-release is beschikbaar voor alle regio's gedurende meerdere dagen. Deze release is van toepassing op afbeeldingsnummer 2307201242. Het installatiekopienummer controleren
HDInsight maakt gebruik van veilige implementatieprocedures, waarbij geleidelijke implementatie van regio's is betrokken. Het kan maximaal 10 werkdagen duren voordat een nieuwe release of een nieuwe versie beschikbaar is in alle regio's.
Besturingssysteemversies
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Zie Voor workloadspecifieke versies
 Wat is er nieuw
Wat is er nieuw
- HDInsight 5.1 wordt nu ondersteund met het ESP-cluster.
- Bijgewerkte versie van Ranger 2.3.0 en Oozie 5.2.1 maken nu deel uit van HDInsight 5.1
- Het Spark 3.3.1-cluster (HDInsight 5.1) wordt geleverd met Hive Warehouse Verbinding maken or (HWC) 2.1, dat samen met het HDInsight 5.1-cluster (Interactive Query) werkt.
- Ubuntu 18.04 wordt ondersteund onder ESM (Uitgebreid beveiligingsonderhoud) door het Azure Linux-team voor Azure HDInsight juli 2023, release en hoger.
Belangrijk
Deze release heeft betrekking op de volgende CV's die op 8 augustus 2023 door MSRC zijn uitgebracht. De actie is om bij te werken naar de meest recente installatiekopieën 2307201242. Klanten worden geadviseerd om dienovereenkomstig te plannen.
| CVE | Ernst | CVE-titel |
|---|---|---|
| CVE-2023-35393 | Belangrijk | Beveiligingsprobleem met Azure Apache Hive-adresvervalsing |
| CVE-2023-35394 | Belangrijk | Beveiligingsprobleem met Spoofing van Azure HDInsight Jupyter Notebook |
| CVE-2023-36877 | Belangrijk | Beveiligingsprobleem met Azure Apache Oozie-adresvervalsing |
| CVE-2023-36881 | Belangrijk | Beveiligingsprobleem met Azure Apache Ambari-adresvervalsing |
| CVE-2023-38188 | Belangrijk | Beveiligingsprobleem met Azure Apache Hadoop-adresvervalsing |
Binnenkort beschikbaar
- De maximale lengte van de clusternaam wordt gewijzigd van 45 naar 59 tekens om de beveiligingspostuur van clusters te verbeteren. Klanten moeten de updates plannen vóór 30 september 2023.
- Clustermachtigingen voor beveiligde opslag
- Klanten kunnen opgeven (tijdens het maken van clusters) of een beveiligd kanaal moet worden gebruikt voor HDInsight-clusterknooppunten om contact op te maken met het opslagaccount.
- Update van inlinequotum.
- Aanvraagquota verhogen rechtstreeks vanaf de pagina Mijn quotum. Dit is een directe API-aanroep. Dit is sneller. Als de API-aanroep mislukt, moeten klanten een nieuwe ondersteuningsaanvraag voor quotumverhoging maken.
- HDInsight-cluster maken met aangepaste VNets.
- Om de algehele beveiligingspostuur van de HDInsight-clusters te verbeteren, moeten HDInsight-clusters met behulp van aangepaste VNET's ervoor zorgen dat de gebruiker gemachtigd moet zijn om
Microsoft Network/virtualNetworks/subnets/join/actionbewerkingen te kunnen maken. Klanten moeten dienovereenkomstig plannen omdat deze wijziging een verplichte controle zou zijn om fouten bij het maken van clusters vóór 30 september 2023 te voorkomen.
- Om de algehele beveiligingspostuur van de HDInsight-clusters te verbeteren, moeten HDInsight-clusters met behulp van aangepaste VNET's ervoor zorgen dat de gebruiker gemachtigd moet zijn om
- Vm's uit de Basic- en Standard A-serie buiten gebruik gesteld.
- Op 31 augustus 2024 gaan we vm's uit de Basic- en Standard A-serie buiten gebruik stellen. Vóór die datum moet u uw workloads migreren naar AV2-serie-VM's, die meer geheugen per vCPU bieden en snellere opslag op SSD's (Solid-State Drives). Als u serviceonderbrekingen wilt voorkomen, migreert u uw workloads van vm's uit de Basic- en Standard A-serie naar av2-serie-VM's vóór 31 augustus 2024.
- Niet-ESP ABFS-clusters [Clustermachtigingen voor Word leesbaar]
- Plan om een wijziging in niet-ESP ABFS-clusters te introduceren, waardoor gebruikers die geen Hadoop-groep zijn, geen Hadoop-opdrachten kunnen uitvoeren voor opslagbewerkingen. Deze wijziging om het beveiligingspostuur van het cluster te verbeteren. Klanten moeten de updates plannen vóór 30 september 2023.
Neem contact op met de ondersteuning van Azure als u nog vragen hebt.
U kunt ons altijd vragen over HDInsight in Azure HDInsight - Microsoft Q&A
U kunt hier meer voorstellen en ideeën en andere onderwerpen toevoegen en stemmen voor hen - HDInsight Community (azure.com) en volg ons voor meer updates op Twitter
Notitie
We adviseren klanten om te gebruiken voor de nieuwste versies van HDInsight-installatiekopieën wanneer ze het beste van opensource-updates, Azure-updates en beveiligingsoplossingen bieden. Zie Best practices voor meer informatie.
Releasedatum: 08 mei 2023
Deze release is van toepassing op HDInsight 4.x en 5.x HDInsight-release is beschikbaar voor alle regio's gedurende meerdere dagen. Deze release is van toepassing op afbeeldingsnummer 2304280205. Het installatiekopienummer controleren
HDInsight maakt gebruik van veilige implementatieprocedures, waarbij geleidelijke implementatie van regio's is betrokken. Het kan maximaal 10 werkdagen duren voordat een nieuwe release of een nieuwe versie beschikbaar is in alle regio's.
Besturingssysteemversies
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Zie Voor workloadspecifieke versies
![]()
Azure HDInsight 5.1 bijgewerkt met
- Apache HBase 2.4.11
- Apache Phoenix 5.1.2
- Apache Hive 3.1.2
- Apache Spark 3.3.1
- Apache Tez 0.9.1
- Apache Zeppelin 0.10.1
- Apache Livy 0.5
- Apache Kafka 3.2.0
Notitie
- Alle onderdelen zijn geïntegreerd met Hadoop 3.3.4 & ZK 3.6.3
- Alle bovenstaande bijgewerkte onderdelen zijn nu beschikbaar in niet-ESP-clusters voor openbare preview.
![]()
Verbeterde automatische schaalaanpassing voor HDInsight
Azure HDInsight heeft aanzienlijke verbeteringen aangebracht in stabiliteit en latentie op automatische schaalaanpassing. De essentiële wijzigingen omvatten verbeterde feedbacklus voor beslissingen over schaalaanpassing, aanzienlijke verbetering van de latentie voor schalen en ondersteuning voor het opnieuw toewijzen van de buiten gebruik gestelde knooppunten, meer informatie over de verbeteringen, het aanpassen en migreren van uw cluster naar verbeterde automatische schaalaanpassing. De verbeterde automatische schaalaanpassing is beschikbaar vanaf 17 mei 2023 in alle ondersteunde regio's.
Azure HDInsight ESP voor Apache Kafka 2.4.1 is nu algemeen beschikbaar.
Azure HDInsight ESP voor Apache Kafka 2.4.1 is sinds april 2022 in openbare preview. Nadat belangrijke verbeteringen in CVE-oplossingen en -stabiliteit zijn aangebracht, wordt Azure HDInsight ESP Kafka 2.4.1 nu algemeen beschikbaar en klaar voor productieworkloads. Lees hier meer informatie over het configureren en migreren van workloads.
Quotumbeheer voor HDInsight
HDInsight wijst momenteel quota toe aan klantabonnementen op regionaal niveau. De kernen die aan klanten zijn toegewezen, zijn algemeen en niet geclassificeerd op vm-familieniveau (bijvoorbeeld
Dv2Ev3,Eav4, enzovoort).HDInsight heeft een verbeterde weergave geïntroduceerd, die een gedetailleerde en classificatie van quota biedt voor VM's op familieniveau. Met deze functie kunnen klanten de huidige en resterende quota voor een regio op het niveau van de VM-familie bekijken. Met de verbeterde weergave hebben klanten uitgebreidere zichtbaarheid, voor het plannen van quota en een betere gebruikerservaring. Deze functie is momenteel beschikbaar in HDInsight 4.x en 5.x voor de regio VS - oost EUAP. Andere regio's die u later kunt volgen.
Zie Clustercapaciteitsplanning in Azure HDInsight | Microsoft Learn
![]()
- Polen - centraal
- De maximale lengte van de clusternaam wordt gewijzigd in 45 van 59 tekens om de beveiligingspostuur van clusters te verbeteren.
- Clustermachtigingen voor beveiligde opslag
- Klanten kunnen opgeven (tijdens het maken van clusters) of een beveiligd kanaal moet worden gebruikt voor HDInsight-clusterknooppunten om contact op te maken met het opslagaccount.
- Update van inlinequotum.
- Aanvraagquota verhogen rechtstreeks vanaf de pagina Mijn quotum. Dit is een directe API-aanroep. Dit is sneller. Als de API-aanroep mislukt, moeten klanten een nieuwe ondersteuningsaanvraag voor quotumverhoging maken.
- HDInsight-cluster maken met aangepaste VNets.
- Om de algehele beveiligingspostuur van de HDInsight-clusters te verbeteren, moeten HDInsight-clusters met behulp van aangepaste VNET's ervoor zorgen dat de gebruiker gemachtigd moet zijn om
Microsoft Network/virtualNetworks/subnets/join/actionbewerkingen te kunnen maken. Klanten moeten dienovereenkomstig plannen, omdat dit een verplichte controle zou zijn om fouten bij het maken van clusters te voorkomen.
- Om de algehele beveiligingspostuur van de HDInsight-clusters te verbeteren, moeten HDInsight-clusters met behulp van aangepaste VNET's ervoor zorgen dat de gebruiker gemachtigd moet zijn om
- Vm's uit de Basic- en Standard A-serie buiten gebruik gesteld.
- Op 31 augustus 2024 gaan we vm's uit de Basic- en Standard A-serie buiten gebruik stellen. Vóór die datum moet u uw workloads migreren naar AV2-serie-VM's, die meer geheugen per vCPU bieden en snellere opslag op SSD's (Solid-State Drives). Om serviceonderbrekingen te voorkomen, migreert u uw workloads vóór 31 augustus 2024 van vm's uit de Basic- en Standard A-serie naar av2-serie-VM's.
- Niet-ESP ABFS-clusters [Clustermachtigingen voor wereld leesbaar]
- Plan om een wijziging in niet-ESP ABFS-clusters te introduceren, waardoor gebruikers die geen Hadoop-groep zijn, geen Hadoop-opdrachten kunnen uitvoeren voor opslagbewerkingen. Deze wijziging om het beveiligingspostuur van het cluster te verbeteren. Klanten moeten plannen voor de updates.
Releasedatum: 28 februari 2023
Deze release is van toepassing op HDInsight 4.0. en 5.0, 5.1. HDInsight-release is beschikbaar voor alle regio's gedurende meerdere dagen. Deze release is van toepassing op afbeeldingsnummer 2302250400. Het installatiekopienummer controleren
HDInsight maakt gebruik van veilige implementatieprocedures, waarbij geleidelijke implementatie van regio's is betrokken. Het kan maximaal 10 werkdagen duren voordat een nieuwe release of een nieuwe versie beschikbaar is in alle regio's.
Besturingssysteemversies
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Zie Voor workloadspecifieke versies
Belangrijk
Microsoft heeft CVE-2023-23408 uitgegeven, wat is opgelost in de huidige release en klanten wordt aangeraden hun clusters te upgraden naar de nieuwste installatiekopie.
![]()
HDInsight 5.1
We zijn begonnen met het implementeren van een nieuwe versie van HDInsight 5.1. Alle nieuwe opensource-releases zijn toegevoegd als incrementele releases in HDInsight 5.1.
Zie HDInsight 5.1.0-versie voor meer informatie
![]()
Kafka 3.2.0-upgrade (preview)
- Kafka 3.2.0 bevat verschillende belangrijke nieuwe functies/verbeteringen.
- Zookeeper bijgewerkt naar 3.6.3
- Ondersteuning voor Kafka Streams
- Sterkere leveringsgaranties voor de Kafka-producent die standaard is ingeschakeld.
log4j1.x vervangen doorreload4j.- Stuur een hint naar de partitieleider om de partitie te herstellen.
JoinGroupRequestenLeaveGroupRequesthebben een reden bijgevoegd.- Broker count metrics8 toegevoegd.
- Mirror-verbeteringen
Maker2.
HBase 2.4.11 Upgrade (preview)
- Deze versie heeft nieuwe functies, zoals het toevoegen van nieuwe cachemechanismetypen voor blokcache, de mogelijkheid om de
hbase:metatabel te wijzigenhbase:meta tableen weer te geven vanuit de HBase WEB UI.
Phoenix 5.1.2 Upgrade (preview)
- Phoenix-versie is bijgewerkt naar 5.1.2 in deze release. Deze upgrade omvat de Phoenix Query Server. De Phoenix Query Server proxyt het standaard Phoenix JDBC-stuurprogramma en biedt een achterwaarts compatibel wire-protocol om dat JDBC-stuurprogramma aan te roepen.
Ambari-CV's
- Er zijn meerdere Ambari-CV's opgelost.
Notitie
ESP wordt niet ondersteund voor Kafka en HBase in deze release.
![]()
Einde van de ondersteuning voor Azure HDInsight-clusters op Spark 2.4 februari 10, 2024. Zie Spark-versies die worden ondersteund in Azure HDInsight voor meer informatie
De volgende stap
- Automatisch schalen
- Automatisch schalen met verbeterde latentie en verschillende verbeteringen
- Beperking van wijziging van clusternaam
- De maximale lengte van de clusternaam wordt gewijzigd in 45 van 59 in Public, Azure China en Azure Government.
- Clustermachtigingen voor beveiligde opslag
- Klanten kunnen opgeven (tijdens het maken van clusters) of een beveiligd kanaal moet worden gebruikt voor HDInsight-clusterknooppunten om contact op te maken met het opslagaccount.
- Niet-ESP ABFS-clusters [Clustermachtigingen voor wereld leesbaar]
- Plan om een wijziging in niet-ESP ABFS-clusters te introduceren, waardoor gebruikers die geen Hadoop-groep zijn, geen Hadoop-opdrachten kunnen uitvoeren voor opslagbewerkingen. Deze wijziging om het beveiligingspostuur van het cluster te verbeteren. Klanten moeten plannen voor de updates.
- Opensource-upgrades
- Apache Spark 3.3.0 en Hadoop 3.3.4 zijn in ontwikkeling in HDInsight 5.1 en bevatten verschillende belangrijke nieuwe functies, prestaties en andere verbeteringen.
Notitie
We adviseren klanten om te gebruiken voor de nieuwste versies van HDInsight-installatiekopieën wanneer ze het beste van opensource-updates, Azure-updates en beveiligingsoplossingen bieden. Zie Best practices voor meer informatie.
Releasedatum: 12 december 2022
Deze release is van toepassing op HDInsight 4.0. en 5.0 HDInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's.
HDInsight maakt gebruik van veilige implementatieprocedures, waarbij geleidelijke implementatie van regio's is betrokken. Het kan maximaal 10 werkdagen duren voordat een nieuwe release of een nieuwe versie beschikbaar is in alle regio's.
Besturingssysteemversies
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Zie hier voor specifieke versies van workloads.
![]()
- Log Analytics : klanten kunnen klassieke bewaking inschakelen om de nieuwste OMS-versie 14.19 te verkrijgen. Als u oude versies wilt verwijderen, schakelt u klassieke bewaking uit en schakelt u deze in.
- Automatisch afmelden voor ambari-gebruikersinterface vanwege inactiviteit. Zie voor meer informatie hier
- Spark : een nieuwe en geoptimaliseerde versie van Spark 3.1.3 is opgenomen in deze release. We hebben Apache Spark 3.1.2 (vorige versie) en Apache Spark 3.1.3 (huidige versie) getest met behulp van de TPC-DS-benchmark. De test is uitgevoerd met behulp van de E8 V3-SKU voor Apache Spark op een workload van 1 TB. Apache Spark 3.1.3 (huidige versie) presteerde beter dan Apache Spark 3.1.2 (vorige versie) met meer dan 40% in de totale queryruntime voor TPC-DS-query's met dezelfde hardwarespecificaties. Het Microsoft Spark-team heeft optimalisaties toegevoegd die beschikbaar zijn in Azure Synapse met Azure HDInsight. Raadpleeg voor meer informatie uw gegevensworkloads versnellen met prestatie-updates voor Apache Spark 3.1.2 in Azure Synapse
![]()
- Qatar - centraal
- Duitsland - noord
![]()
HDInsight is verwijderd van Azul Zulu Java JDK 8 naar
Adoptium Temurin JDK 8, dat ondersteuning biedt voor hoogwaardige TCK-gecertificeerde runtimes en bijbehorende technologie voor gebruik in het Java-ecosysteem.HDInsight is gemigreerd naar
reload4j. Delog4jwijzigingen zijn van toepassing op- Apache Hadoop
- Apache Zookeeper
- Apache Oozie
- Apache Ranger
- Apache Sqoop
- Apache Pig
- Apache Ambari
- Apache Kafka
- Apache Spark
- Apache Zeppelin
- Apache Livy
- Apache Rubix
- Apache Hive
- Apache Tez
- Apache HBase
- OMI
- Apache Pheonix
![]()
HDInsight voor het implementeren van TLS1.2 in de toekomst en eerdere versies worden bijgewerkt op het platform. Als u toepassingen boven op HDInsight uitvoert en ze TLS 1.0 en 1.1 gebruiken, voert u een upgrade uit naar TLS 1.2 om onderbrekingen in services te voorkomen.
Zie Transport Layer Security (TLS) inschakelen voor meer informatie
![]()
Einde van de ondersteuning voor Azure HDInsight-clusters op Ubuntu 16.04 LTS vanaf 30 november 2022. HDInsight begint met het vrijgeven van clusterinstallatiekopieën met Ubuntu 18.04 vanaf 27 juni 2021. We raden onze klanten aan om clusters uit te voeren met Ubuntu 16.04 door hun clusters met de nieuwste HDInsight-installatiekopieën op 30 november 2022 opnieuw te bouwen.
Zie hier voor meer informatie over het controleren van de Ubuntu-versie van het cluster
Voer de opdracht 'lsb_release -a' uit in de terminal.
Als de waarde voor de eigenschap Beschrijving in de uitvoer 'Ubuntu 16.04 LTS' is, is deze update van toepassing op het cluster.
![]()
- Ondersteuning voor Beschikbaarheidszones selectie voor Kafka- en HBase-clusters (schrijftoegang).
Oplossingen voor opensource-fouten
Oplossingen voor Hive-fouten
| Bugfixes | Apache JIRA |
|---|---|
| HIVE-26127 | INSERT OVERWRITE-fout - Bestand niet gevonden |
| HIVE-24957 | Verkeerde resultaten wanneer subquery COALESCE heeft in correlatiepredicaat |
| HIVE-24999 | HiveSubQueryRemoveRule genereert een ongeldig plan voor IN-subquery met meerdere correlaties |
| HIVE-24322 | Als er direct invoegen is, moet de pogings-id worden gecontroleerd bij het lezen van het manifest mislukt |
| HIVE-23363 | DataNucleus-afhankelijkheid upgraden naar 5.2 |
| HIVE-26412 | Interface maken om beschikbare sites op te halen en de standaardwaarde toe te voegen |
| HIVE-26173 | Upgrade derby naar 10.14.2.0 |
| HIVE-25920 | Hobbel Xerce2 naar 2.12.2. |
| HIVE-26300 | Upgrade Jackson-gegevensbindingsversie naar 2.12.6.1+ om CVE-2020-36518 te voorkomen |
Releasedatum: 10-08-2022
Deze release is van toepassing op HDInsight 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's.
HDInsight maakt gebruik van veilige implementatieprocedures, waarbij geleidelijke implementatie van regio's is betrokken. Het kan maximaal 10 werkdagen duren voordat een nieuwe release of een nieuwe versie beschikbaar is in alle regio's.
![]()
Nieuwe functie
1. Externe schijven koppelen in HDI Hadoop-/Spark-clusters
HDInsight-cluster wordt geleverd met vooraf gedefinieerde schijfruimte op basis van SKU. Deze ruimte is mogelijk niet voldoende in scenario's voor grote taken.
Met deze nieuwe functie kunt u meer schijven toevoegen in het cluster, die worden gebruikt als lokale map van knooppuntbeheer. Voeg het aantal schijven toe aan werkknooppunten tijdens het maken van hive- en Spark-clusters, terwijl de geselecteerde schijven deel uitmaken van de lokale mappen van knooppuntbeheer.
Notitie
De toegevoegde schijven zijn alleen geconfigureerd voor lokale mappen van knooppuntbeheer.
Zie voor meer informatie hier
2. Selectieve logboekregistratieanalyse
Selectieve logboekregistratieanalyse is nu beschikbaar voor alle regio's voor openbare preview. U kunt uw cluster verbinden met een Log Analytics-werkruimte. Zodra deze functie is ingeschakeld, kunt u de logboeken en metrische gegevens zien, zoals HDInsight-beveiligingslogboeken, Yarn Resource Manager, metrische systeemgegevens, enzovoort. U kunt workloads bewaken en zien hoe deze van invloed zijn op clusterstabiliteit. Met selectief logboekregistratie kunt u alle tabellen in- of uitschakelen of selectief tabellen inschakelen in log analytics-werkruimte. U kunt het brontype voor elke tabel aanpassen, omdat in een nieuwe versie van Genève één tabel meerdere bronnen heeft.
- Het bewakingssysteem van Genève maakt gebruik van mdsd(MDS-daemon), een bewakingsagent en vloeiend voor het verzamelen van logboeken met behulp van geïntegreerde logboekregistratielaag.
- Selectief logboekregistratie maakt gebruik van scriptacties om tabellen en hun logboektypen uit te schakelen/in te schakelen. Omdat er geen nieuwe poorten worden geopend of een bestaande beveiligingsinstelling wordt gewijzigd, zijn er geen beveiligingswijzigingen.
- Scriptactie wordt parallel uitgevoerd op alle opgegeven knooppunten en wijzigt de configuratiebestanden voor het uitschakelen/inschakelen van tabellen en de bijbehorende logboektypen.
Zie voor meer informatie hier
![]()
Vast
Logboekanalyses
Log Analytics die is geïntegreerd met Azure HDInsight met OMS versie 13, vereist een upgrade naar OMS versie 14 om de meest recente beveiligingsupdates toe te passen. Klanten die een oudere versie van het cluster gebruiken met OMS versie 13, moeten OMS versie 14 installeren om te voldoen aan de beveiligingsvereisten. (Huidige versie controleren en 14 installeren)
Uw huidige OMS-versie controleren
- Meld u aan bij het cluster met behulp van SSH.
- Voer de volgende opdracht uit in uw SSH-client.
sudo /opt/omi/bin/ominiserver/ --version

Uw OMS-versie upgraden van 13 naar 14
- Meld u aan bij Azure Portal
- Selecteer in de resourcegroep de HDInsight-clusterresource
- Scriptacties selecteren
- Kies in het deelvenster Scriptactie verzenden het scripttype als aangepast
- Plak de volgende koppeling in het vak URL van het Bash-script https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Knooppunttype(en) selecteren
- Selecteer Maken.
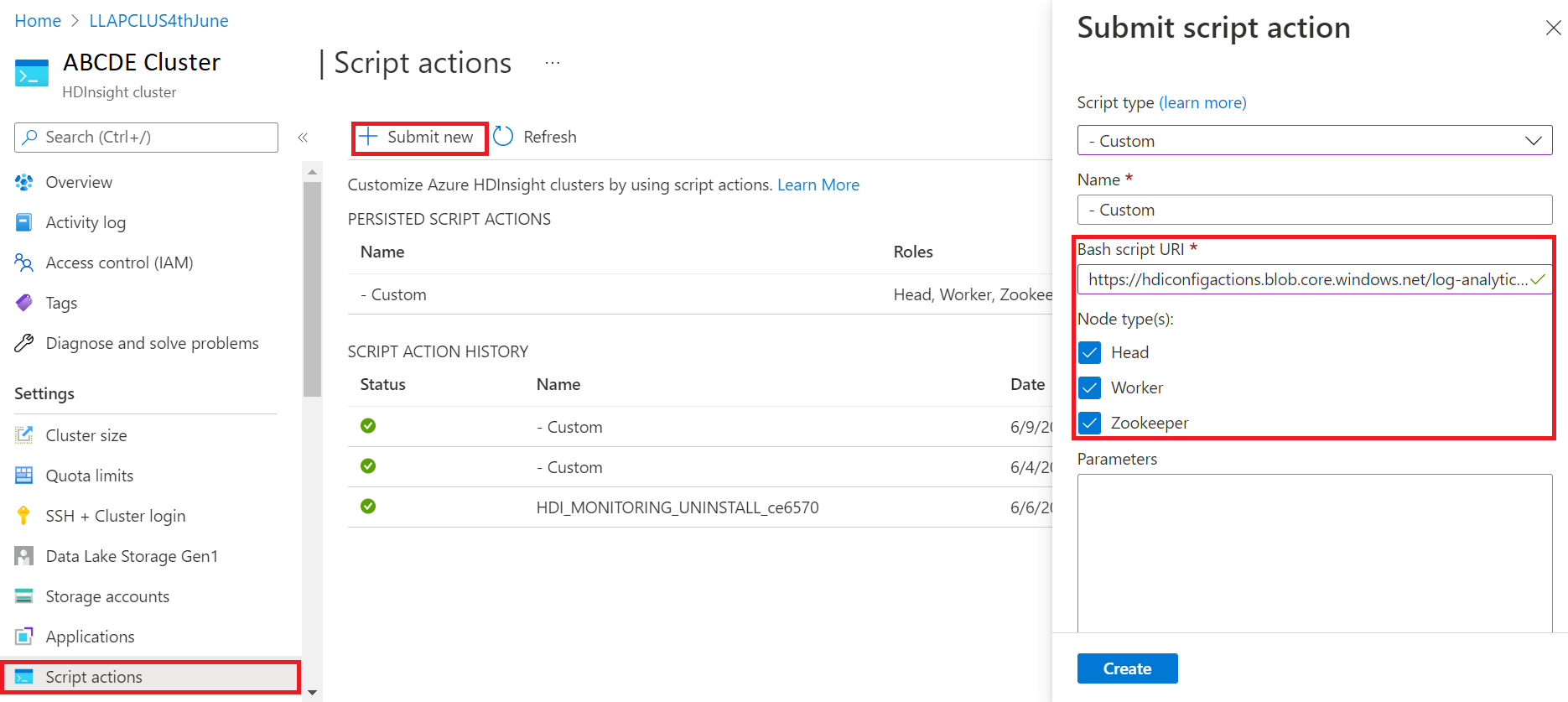
Controleer de geslaagde installatie van de patch met behulp van de volgende stappen:
Meld u aan bij het cluster met behulp van SSH.
Voer de volgende opdracht uit in uw SSH-client.
sudo /opt/omi/bin/ominiserver/ --version
Andere oplossingen voor fouten
- De CLI van het Yarn-logboek kan de logboeken niet ophalen als deze
TFilebeschadigd of leeg zijn. - Er is een fout met ongeldige details van de service-principal opgelost tijdens het ophalen van het OAuth-token uit Azure Active Directory.
- Verbeterde betrouwbaarheid van het maken van clusters wanneer 100+ gewerkte knooppunten zijn geconfigureerd.
Oplossingen voor opensource-fouten
OPLOSSINGEN voor TEZ-fouten
| Bugfixes | Apache JIRA |
|---|---|
| Tez-buildfout: FileSaver.js niet gevonden | TEZ-4411 |
Verkeerde FS-uitzondering wanneer magazijn en scratchdir zich op verschillende FS bevinden |
TEZ-4406 |
| TezUtils.createConfFromByteString on Configuration groter dan 32 MB genereert com.google.protobuf.CodedInputStream-uitzondering | TEZ-4142 |
| TezUtils::createByteStringFromConf moet snappy gebruiken in plaats van DeflaterOutputStream | TEZ-4113 |
| Protobuf-afhankelijkheid bijwerken naar 3.x | TEZ-4363 |
Oplossingen voor Hive-fouten
| Bugfixes | Apache JIRA |
|---|---|
| Optimalisaties perf in ORC-splitsingsgeneratie | HIVE-21457 |
| Leestabel niet als ACID wanneer de tabelnaam begint met 'delta', maar tabel niet transactioneel is en BI Split Strategy wordt gebruikt | HIVE-22582 |
| Een FS#-aanroep verwijderen uit AcidUtils#getLogicalLength | HIVE-23533 |
| Vectorized OrcAcidRowBatchReader.computeOffset en bucketoptimalisatie | HIVE-17917 |
Bekende problemen
HDInsight is compatibel met Apache HIVE 3.1.2. Vanwege een fout in deze release wordt de Hive-versie weergegeven als 3.1.0 in Hive-interfaces. Er is echter geen invloed op de functionaliteit.
Releasedatum: 10-08-2022
Deze release is van toepassing op HDInsight 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's.
HDInsight maakt gebruik van veilige implementatieprocedures, waarbij geleidelijke implementatie van regio's is betrokken. Het kan maximaal 10 werkdagen duren voordat een nieuwe release of een nieuwe versie beschikbaar is in alle regio's.
![]()
Nieuwe functie
1. Externe schijven koppelen in HDI Hadoop-/Spark-clusters
HDInsight-cluster wordt geleverd met vooraf gedefinieerde schijfruimte op basis van SKU. Deze ruimte is mogelijk niet voldoende in scenario's voor grote taken.
Met deze nieuwe functie kunt u meer schijven toevoegen in het cluster, die worden gebruikt als lokale map van knooppuntbeheer. Voeg het aantal schijven toe aan werkknooppunten tijdens het maken van hive- en Spark-clusters, terwijl de geselecteerde schijven deel uitmaken van de lokale mappen van knooppuntbeheer.
Notitie
De toegevoegde schijven zijn alleen geconfigureerd voor lokale mappen van knooppuntbeheer.
Zie voor meer informatie hier
2. Selectieve logboekregistratieanalyse
Selectieve logboekregistratieanalyse is nu beschikbaar voor alle regio's voor openbare preview. U kunt uw cluster verbinden met een Log Analytics-werkruimte. Zodra deze functie is ingeschakeld, kunt u de logboeken en metrische gegevens zien, zoals HDInsight-beveiligingslogboeken, Yarn Resource Manager, metrische systeemgegevens, enzovoort. U kunt workloads bewaken en zien hoe deze van invloed zijn op clusterstabiliteit. Met selectief logboekregistratie kunt u alle tabellen in- of uitschakelen of selectief tabellen inschakelen in log analytics-werkruimte. U kunt het brontype voor elke tabel aanpassen, omdat in een nieuwe versie van Genève één tabel meerdere bronnen heeft.
- Het bewakingssysteem van Genève maakt gebruik van mdsd(MDS-daemon), een bewakingsagent en vloeiend voor het verzamelen van logboeken met behulp van geïntegreerde logboekregistratielaag.
- Selectief logboekregistratie maakt gebruik van scriptacties om tabellen en hun logboektypen uit te schakelen/in te schakelen. Omdat er geen nieuwe poorten worden geopend of een bestaande beveiligingsinstelling wordt gewijzigd, zijn er geen beveiligingswijzigingen.
- Scriptactie wordt parallel uitgevoerd op alle opgegeven knooppunten en wijzigt de configuratiebestanden voor het uitschakelen/inschakelen van tabellen en de bijbehorende logboektypen.
Zie voor meer informatie hier
![]()
Vast
Logboekanalyses
Log Analytics die is geïntegreerd met Azure HDInsight met OMS versie 13, vereist een upgrade naar OMS versie 14 om de meest recente beveiligingsupdates toe te passen. Klanten die een oudere versie van het cluster gebruiken met OMS versie 13, moeten OMS versie 14 installeren om te voldoen aan de beveiligingsvereisten. (Huidige versie controleren en 14 installeren)
Uw huidige OMS-versie controleren
- Meld u aan bij het cluster met behulp van SSH.
- Voer de volgende opdracht uit in uw SSH-client.
sudo /opt/omi/bin/ominiserver/ --version
Uw OMS-versie upgraden van 13 naar 14
- Meld u aan bij Azure Portal
- Selecteer in de resourcegroep de HDInsight-clusterresource
- Scriptacties selecteren
- Kies in het deelvenster Scriptactie verzenden het scripttype als aangepast
- Plak de volgende koppeling in het vak URL van het Bash-script https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- Knooppunttype(en) selecteren
- Selecteer Maken.
Controleer de geslaagde installatie van de patch met behulp van de volgende stappen:
Meld u aan bij het cluster met behulp van SSH.
Voer de volgende opdracht uit in uw SSH-client.
sudo /opt/omi/bin/ominiserver/ --version
Andere oplossingen voor fouten
- De CLI van het Yarn-logboek kan de logboeken niet ophalen als deze
TFilebeschadigd of leeg zijn. - Er is een fout met ongeldige details van de service-principal opgelost tijdens het ophalen van het OAuth-token uit Azure Active Directory.
- Verbeterde betrouwbaarheid van het maken van clusters wanneer 100+ gewerkte knooppunten zijn geconfigureerd.
Oplossingen voor opensource-fouten
OPLOSSINGEN voor TEZ-fouten
| Bugfixes | Apache JIRA |
|---|---|
| Tez-buildfout: FileSaver.js niet gevonden | TEZ-4411 |
Verkeerde FS-uitzondering wanneer magazijn en scratchdir zich op verschillende FS bevinden |
TEZ-4406 |
| TezUtils.createConfFromByteString on Configuration groter dan 32 MB genereert com.google.protobuf.CodedInputStream-uitzondering | TEZ-4142 |
| TezUtils::createByteStringFromConf moet snappy gebruiken in plaats van DeflaterOutputStream | TEZ-4113 |
| Protobuf-afhankelijkheid bijwerken naar 3.x | TEZ-4363 |
Oplossingen voor Hive-fouten
| Bugfixes | Apache JIRA |
|---|---|
| Optimalisaties perf in ORC-splitsingsgeneratie | HIVE-21457 |
| Leestabel niet als ACID wanneer de tabelnaam begint met 'delta', maar tabel niet transactioneel is en BI Split Strategy wordt gebruikt | HIVE-22582 |
| Een FS#-aanroep verwijderen uit AcidUtils#getLogicalLength | HIVE-23533 |
| Vectorized OrcAcidRowBatchReader.computeOffset en bucketoptimalisatie | HIVE-17917 |
Bekende problemen
HDInsight is compatibel met Apache HIVE 3.1.2. Vanwege een fout in deze release wordt de Hive-versie weergegeven als 3.1.0 in Hive-interfaces. Er is echter geen invloed op de functionaliteit.
Releasedatum: 06-03-2022
Deze release is van toepassing op HDInsight 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release gedurende enkele dagen in uw regio live is.
Release-hoogtepunten
De Hive Warehouse Verbinding maken or (HWC) op Spark v3.1.2
Met het Hive Warehouse Verbinding maken or (HWC) kunt u profiteren van de unieke functies van Hive en Spark om krachtige big data-toepassingen te bouwen. HWC wordt momenteel alleen ondersteund voor Spark v2.4. Met deze functie wordt bedrijfswaarde toegevoegd door ACID-transacties in Hive-tabellen toe te staan met behulp van Spark. Deze functie is handig voor klanten die zowel Hive als Spark gebruiken in hun gegevensomgeving. Zie Apache Spark & Hive - Hive Warehouse Verbinding maken or - Azure HDInsight | Microsoft Docs
Ambari
- Wijzigingen in het schalen en inrichten van wijzigingen
- HDI hive is nu compatibel met OSS versie 3.1.2
HDI Hive 3.1-versie wordt bijgewerkt naar OSS Hive 3.1.2. Deze versie bevat alle fixes en functies die beschikbaar zijn in open source Hive 3.1.2-versie.
Notitie
Spark
- Als u Azure User Interface gebruikt om een Spark-cluster voor HDInsight te maken, ziet u in de vervolgkeuzelijst een andere versie van Spark 3.1. (HDI 5.0) samen met de oudere versies. Deze versie is een hernoemde versie van Spark 3.1. (HDI 4.0). Dit is alleen een wijziging op gebruikersinterfaceniveau. Dit heeft geen invloed op de bestaande gebruikers en gebruikers die al gebruikmaken van de ARM-sjabloon.
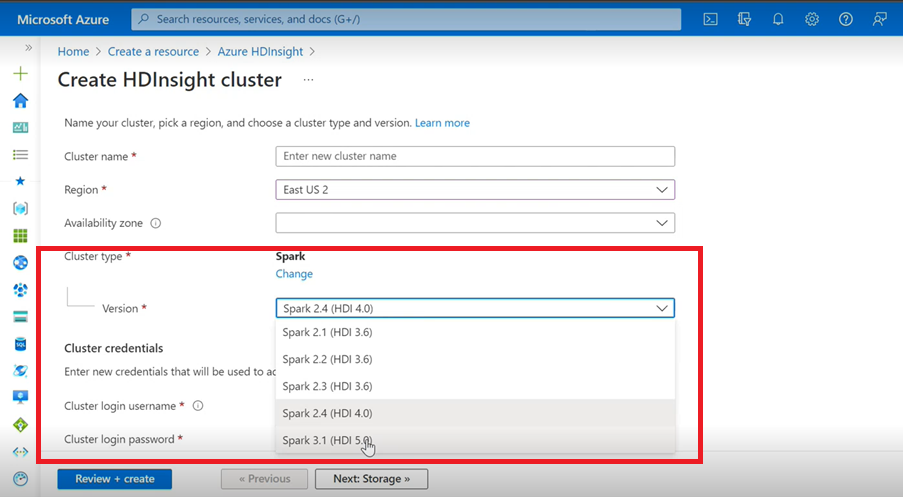
Notitie
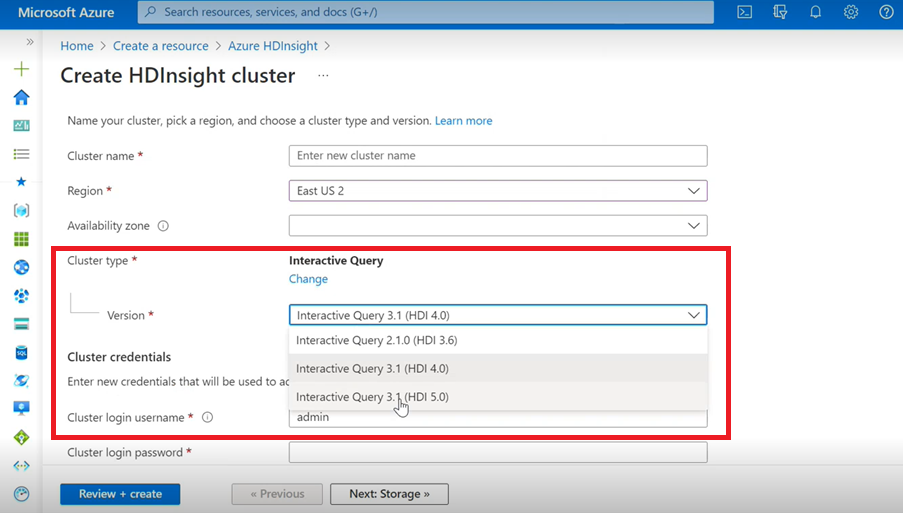
Interactieve query
- Als u een Interactive Query-cluster maakt, ziet u in de vervolgkeuzelijst een andere versie als Interactive Query 3.1 (HDI 5.0).
- Als u de Spark 3.1-versie samen met Hive gebruikt waarvoor ACID-ondersteuning is vereist, moet u deze versie Interactive Query 3.1 (HDI 5.0) selecteren.
OPLOSSINGEN voor TEZ-fouten
| Bugfixes | Apache JIRA |
|---|---|
| TezUtils.createConfFromByteString on Configuration groter dan 32 MB genereert com.google.protobuf.CodedInputStream-uitzondering | TEZ-4142 |
| TezUtils createByteStringFromConf moet snappy gebruiken in plaats van DeflaterOutputStream | TEZ-4113 |
Oplossingen voor HBase-fouten
| Bugfixes | Apache JIRA |
|---|---|
TableSnapshotInputFormat moet ReadType.STREAM gebruiken om te scannen HFiles |
HBASE-26273 |
| Optie toevoegen om scanMetrics uit te schakelen in TableSnapshotInputFormat | HBASE-26330 |
| Oplossing voor ArrayIndexOutOfBoundsException wanneer balancer wordt uitgevoerd | HBASE-22739 |
Oplossingen voor Hive-fouten
| Bugfixes | Apache JIRA |
|---|---|
| NPE bij het invoegen van gegevens met de component 'distribute by' met dynpart sort optimization | HIVE-18284 |
| MSCK REPAIR-opdracht met partitiefiltering mislukt tijdens het verwijderen van partities | HIVE-23851 |
| Er is een verkeerde uitzondering opgetreden als capaciteit<=0 | HIVE-25446 |
| Ondersteuning voor parallelle belasting voor HastTables - Interfaces | HIVE-25583 |
| MultiDelimitSerDe opnemen in HiveServer2 standaard | HIVE-20619 |
| Verwijder glassfish.jersey en mssql-jdbc-klassen uit jdbc-standalone jar | HIVE-22134 |
| Null-aanwijzer-uitzondering bij het uitvoeren van compressie op basis van een MM-tabel. | HIVE-21280 |
Hive-query met grote grootte mislukt knox met verbroken pijp schrijven is mislukt |
HIVE-22231 |
| Mogelijkheid toevoegen voor gebruiker om bindingsgebruiker in te stellen | HIVE-21009 |
| UDF implementeren om datum/tijdstempel te interpreteren met behulp van de interne weergave en de hybride kalender Gregoriaanse-Juliaanse | HIVE-22241 |
| Beeline-optie om het uitvoeringsrapport weer te geven/niet weer te geven | HIVE-22204 |
| Tez: SplitGenerator probeert te zoeken naar planbestanden, die niet bestaan voor Tez | HIVE-22169 |
Dure logboekregistratie verwijderen uit de LLAP-cache hotpath |
HIVE-22168 |
| UDF: FunctionRegistry synchroniseert op org.apache.hadoop.hive.ql.udf.UDFType-klasse | HIVE-22161 |
| Voorkomen dat de toevoegfunctie voor queryroutering wordt gemaakt als de eigenschap is ingesteld op false | HIVE-22115 |
| Kruisquerysynchronisatie verwijderen voor de partitie-eval | HIVE-22106 |
| Het instellen van hive scratch dir overslaan tijdens de planning | HIVE-21182 |
| Sla het maken van scratch-dirs voor tez over als RPC is ingeschakeld | HIVE-21171 |
Hive UDF's overschakelen om regex-engine te gebruiken Re2J |
HIVE-19661 |
| Gemigreerde geclusterde tabellen met bucketing_version 1 op hive 3 gebruikt bucketing_version 2 voor invoegingen | HIVE-22429 |
| Bucketing: Bucketing versie 1 is onjuist partitioneren van gegevens | HIVE-21167 |
| ASF-licentieheader toevoegen aan het zojuist toegevoegde bestand | HIVE-22498 |
| Verbeteringen van het schemahulpprogramma ter ondersteuning van mergeCatalog | HIVE-22498 |
| Hive met TEZ UNION ALL en UDTF resulteert in gegevensverlies | HIVE-21915 |
| Tekstbestanden splitsen, zelfs als koptekst/voettekst bestaat | HIVE-21924 |
| MultiDelimitSerDe retourneert verkeerde resultaten in de laatste kolom wanneer het geladen bestand meer kolommen heeft dan het bestand aanwezig is in het tabelschema | HIVE-22360 |
| Externe LLAP-client - LlapBaseInputFormat#getSplits() footprint verminderen | HIVE-22221 |
| Kolomnaam met gereserveerd trefwoord is ongezichtig wanneer query's toevoegen aan tabel met maskerkolom opnieuw worden geschreven (Zoltan Matyus via Zoltan Haindrich) | HIVE-22208 |
Afsluiten van LLAP op AMReporter gerelateerde RuntimeException voorkomen |
HIVE-22113 |
| LlAP-statusservicestuurprogramma kan vastlopen met de verkeerde Yarn-app-id | HIVE-21866 |
| OperationManager.queryIdOperation schoont meerdere queryIds niet goed op | HIVE-22275 |
| Het omlaag brengen van een knooppuntbeheerder blokkeert het opnieuw opstarten van de LLAP-service | HIVE-22219 |
| StackOverflowError bij het neerzetten van veel partities | HIVE-15956 |
| Toegangscontrole is mislukt wanneer een tijdelijke map wordt verwijderd | HIVE-22273 |
| Onjuiste resultaten/MatrixOutOfBound-uitzondering in left outer map joins in specifieke grensvoorwaarden oplossen | HIVE-22120 |
| Distributiebeheertag verwijderen uit pom.xml | HIVE-19667 |
| Parseringstijd kan hoog zijn als er diep geneste subquery's zijn | HIVE-21980 |
Voor ALTER TABLE t SET TBLPROPERTIES ('EXTERNAL'='TRUE'); TBL_TYPE kenmerkwijzigingen worden niet weerspiegeld voor niet-CAPS |
HIVE-20057 |
JDBC: Hive Verbinding maken ion-interfaces log4j |
HIVE-18874 |
URL's voor opslagplaatsen bijwerken in poms vertakking 3.1-versie |
HIVE-21786 |
DBInstall tests die zijn verbroken op master en branch-3.1 |
HIVE-21758 |
| Gegevens laden in een bucketed tabel negeert partitiespecificaties en laadt gegevens in standaardpartitie | HIVE-21564 |
| Query's met joinvoorwaarde met tijdstempel of tijdstempel met letterlijke SemanticException in de lokale tijdzone | HIVE-21613 |
| Rekenstatistieken analyseren voor kolom laat faserings-dir achter in HDFS | HIVE-21342 |
| Incompatibele wijziging in hive-bucketberekening | HIVE-21376 |
| Geef een terugval autor op wanneer er geen andere autor wordt gebruikt | HIVE-20420 |
| Sommige alterPartitions-aanroepen gooien NumberFormatException: null | HIVE-18767 |
| HiveServer2: Vooraf geverifieerd onderwerp voor http-transport wordt in sommige gevallen niet bewaard gedurende de gehele duur van http-communicatie | HIVE-20555 |
Releasedatum: 10-03-2022
Deze release is van toepassing op HDInsight 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release gedurende enkele dagen in uw regio live is.
De versies van het besturingssysteem voor deze release zijn:
- HDInsight 4.0: Ubuntu 18.04.5
Spark 3.1 is nu algemeen beschikbaar
Spark 3.1 is nu algemeen beschikbaar in HDInsight 4.0. Deze release bevat
- Uitvoering van adaptieve query's,
- Samenvoegen sorteren converteren naar Broadcast Hash Join,
- Spark Catalyst Optimizer,
- Dynamische partitie snoeien,
- Klanten kunnen nieuwe Spark 3.1-clusters maken en geen Spark 3.0-clusters (preview).
Zie de Apache Spark 3.1 nu algemeen beschikbaar in HDInsight - Microsoft Tech Community voor meer informatie.
Zie de releaseopmerkingen voor Apache Spark 3.1 voor een volledige lijst met verbeteringen.
Zie de migratiehandleiding voor meer informatie over migratie.
Kafka 2.4 is nu algemeen beschikbaar
Kafka 2.4.1 is nu algemeen beschikbaar. Zie de releaseopmerkingen van Kafka 2.4.1 voor meer informatie . Andere functies zijn de beschikbaarheid van MirrorMaker 2, de nieuwe metrische categorie AtMinIsr-onderwerppartitie, verbeterde opstarttijd van broker door lui op aanvraag mmap van indexbestanden, Meer metrische gegevens van consumenten om het gedrag van gebruikerspeilingen te observeren.
Toewijzingsgegevenstype in HWC wordt nu ondersteund in HDInsight 4.0
Deze release bevat Ondersteuning voor Map Datatype voor HWC 1.0 (Spark 2.4) via de spark-shell-toepassing en alle andere spark-clients die HWC ondersteunt. De volgende verbeteringen zijn opgenomen, net als andere gegevenstypen:
Een gebruiker kan
- Maak een Hive-tabel met een of meer kolommen met toewijzingsgegevenstype, voeg er gegevens in en lees de resultaten ervan.
- Maak een Apache Spark-gegevensframe met toewijzingstype en voer batch-/stream-lees- en schrijfbewerkingen uit.
Nieuwe regio’s
HDInsight heeft nu zijn geografische aanwezigheid uitgebreid naar twee nieuwe regio's: China - oost 3 en China - noord 3.
OSS-backportwijzigingen
OSS-backports die zijn opgenomen in Hive, waaronder HWC 1.0 (Spark 2.4) die ondersteuning biedt voor het gegevenstype Kaart.
Dit zijn de OSS-backported Apache JIRAs voor deze release:
| Beïnvloede functie | Apache JIRA |
|---|---|
| Metastore directe SQL-query's met IN/(NOT IN) moeten worden gesplitst op basis van de maximale parameters die zijn toegestaan door SQL DB | HIVE-25659 |
Upgrade log4j van 2.16.0 naar 2.17.0 |
HIVE-25825 |
Updateversie Flatbuffer |
HIVE-22827 |
| Systeemeigen ondersteuning voor kaartgegevenstype in pijlindeling | HIVE-25553 |
| EXTERNE LLAP-client: geneste waarden verwerken wanneer de bovenliggende struct null is | HIVE-25243 |
| Upgradepijlversie naar 0.11.0 | HIVE-23987 |
Kennisgevingen over afschaffing
Virtuele-machineschaalsets van Azure in HDInsight
HDInsight maakt geen gebruik meer van Virtuele-machineschaalsets van Azure om de clusters in te richten. Er wordt geen belangrijke wijziging verwacht. Bestaande HDInsight-clusters op virtuele-machineschaalsets hebben geen invloed, nieuwe clusters op de nieuwste installatiekopieën gebruiken geen virtuele-machineschaalsets meer.
Schalen van Azure HDInsight HBase-workloads wordt nu alleen ondersteund met handmatig schalen
Vanaf 01 maart 2022 biedt HDInsight alleen ondersteuning voor handmatige schaalaanpassing voor HBase. Dit heeft geen invloed op het uitvoeren van clusters. Nieuwe HBase-clusters kunnen geen automatische schaalaanpassing op basis van planning inschakelen. Raadpleeg onze documentatie over het handmatig schalen van Azure HDInsight-clusters voor meer informatie over het handmatig schalen van uw HBase-cluster
Releasedatum: 27-12-2021
Deze release is van toepassing op HDInsight 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release gedurende enkele dagen in uw regio live is.
De versies van het besturingssysteem voor deze release zijn:
- HDInsight 4.0: Ubuntu 18.04.5 LTS
HdInsight 4.0-installatiekopie is bijgewerkt om het beveiligingsprobleem te beperken Log4j , zoals beschreven in het antwoord van Microsoft op CVE-2021-44228 Apache Log4j 2.
Notitie
- HDI 4.0-clusters die na 27 december 2021 00:00 UTC zijn gemaakt, worden gemaakt met een bijgewerkte versie van de installatiekopie, waardoor de
log4jbeveiligingsproblemen worden beperkt. Daarom hoeven klanten deze clusters niet te patchen/opnieuw op te starten. - Voor nieuwe HDInsight 4.0-clusters die zijn gemaakt tussen 16 december 2021 om 01:15 UTC en 27 december 2021 00:00 UTC, HDInsight 3.6 of in vastgemaakte abonnementen na 16 december 2021 wordt de patch automatisch toegepast binnen het uur waarin het cluster wordt gemaakt, maar klanten moeten hun knooppunten opnieuw opstarten om de patch te voltooien (met uitzondering van Kafka-beheerknooppunten, die automatisch opnieuw worden opgestart).
Releasedatum: 27-07-2021
Deze release is van toepassing op zowel HDInsight 3.6 als HDInsight 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release binnen enkele dagen live is in uw regio.
De versies van het besturingssysteem voor deze release zijn:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Nieuwe functies
Azure HDInsight-ondersteuning voor beperkte openbare Verbinding maken iviteit is algemeen beschikbaar op 15 oktober 2021
Azure HDInsight ondersteunt nu beperkte openbare connectiviteit in alle regio's. Hieronder ziet u enkele van de belangrijkste hoogtepunten van deze mogelijkheid:
- Mogelijkheid om resourceprovider om te keren naar clustercommunicatie, zodat deze uitgaand is van het cluster naar de resourceprovider
- Ondersteuning voor het alleen gebruiken van uw eigen private link-resources (bijvoorbeeld opslag, SQL, sleutelkluis) voor HDInsight-cluster voor toegang tot de resources via een particulier netwerk
- Er zijn geen openbare IP-adressen ingericht
Met deze nieuwe mogelijkheid kunt u ook de regels voor binnenkomende netwerkbeveiligingsgroepen (NSG)-servicetags voor HDInsight-beheer-IP's overslaan. Meer informatie over het beperken van openbare connectiviteit
Ondersteuning voor Azure HDInsight voor Azure Private Link is algemeen beschikbaar op 15 oktober 2021
U kunt nu privé-eindpunten gebruiken om via private link verbinding te maken met uw HDInsight-clusters. Private Link kan worden gebruikt in scenario's voor meerdere VNET's waarbij VNET-peering niet beschikbaar of ingeschakeld is.
Met Azure Private Link hebt u via een privé-eindpunt in uw virtuele netwerk toegang tot Azure PaaS-services (bijvoorbeeld Azure Storage en SQL Database) en in Azure gehoste services van klanten of partners.
Verkeer tussen uw virtuele netwerk en de service wordt via het Microsoft-backbonenetwerk verplaatst. U hoeft uw service niet langer bloot te stellen aan het openbare internet.
Laten we meer doen bij het inschakelen van een privékoppeling.
Nieuwe Integratie-ervaring van Azure Monitor (preview)
De nieuwe integratie-ervaring van Azure Monitor is preview in VS - oost en Europa - west met deze release. Meer informatie over de nieuwe Azure Monitor-ervaring vindt u hier.
Afschaffing
HDInsight 3.6-versie is afgeschaft vanaf 01 oktober 2022.
Gedragswijzigingen
HDInsight Interactive Query biedt alleen ondersteuning voor automatisch schalen op basis van schema's
Naarmate klantscenario's volwassener en diverser worden, hebben we enkele beperkingen geïdentificeerd met op load gebaseerde automatische schaalaanpassing op basis van Interactive Query (LLAP). Deze beperkingen worden veroorzaakt door de aard van LLAP-querydynamiek, toekomstige problemen met de nauwkeurigheid van de belastingvoorspelling en problemen in de herdistributie van de taak van de LLAP-planner. Vanwege deze beperkingen kunnen gebruikers zien dat hun query's langzamer worden uitgevoerd op LLAP-clusters wanneer automatische schaalaanpassing is ingeschakeld. Het effect op prestaties kan opwegen tegen de kostenvoordelen van automatische schaalaanpassing.
Vanaf juli 2021 biedt de workload Interactive Query in HDInsight alleen ondersteuning voor automatisch schalen op basis van een planning. U kunt automatisch schalen op basis van belasting niet meer inschakelen op nieuwe Interactive Query-clusters. Bestaande actieve clusters kunnen blijven worden uitgevoerd met de bekende beperkingen die hierboven worden beschreven.
Microsoft raadt u aan over te stappen op een op planning gebaseerde automatische schaalaanpassing voor LLAP. U kunt het huidige gebruikspatroon van uw cluster analyseren via het Grafana Hive-dashboard. Zie Azure HDInsight-clusters automatisch schalen voor meer informatie.
Toekomstige wijzigingen
De volgende wijzigingen vinden plaats in toekomstige releases.
Het ingebouwde LLAP-onderdeel in het ESP Spark-cluster wordt verwijderd
HDInsight 4.0 ESP Spark-cluster bevat ingebouwde LLAP-onderdelen die op beide hoofdknooppunten worden uitgevoerd. De LLAP-onderdelen in het ESP Spark-cluster zijn oorspronkelijk toegevoegd voor HDInsight 3.6 ESP Spark, maar heeft geen echte gebruikerscase voor HDInsight 4.0 ESP Spark. In de volgende release die is gepland in sep 2021, wordt in HDInsight het ingebouwde LLAP-onderdeel verwijderd uit het HDInsight 4.0 ESP Spark-cluster. Deze wijziging helpt bij het offloaden van de workload van het hoofdknooppunt en om verwarring te voorkomen tussen het clustertype ESP Spark en ESP Interactive Hive.
Nieuwe regio
- US - west 3
JioIndia West- Australië - centraal
Wijziging van onderdeelversie
De volgende onderdeelversie is gewijzigd met deze release:
- ORC-versie van 1.5.1 tot 1.5.9
In dit document vindt u de huidige onderdeelversies voor HDInsight 4.0 en HDInsight 3.6.
Gepoorte JIRA's terug
Dit zijn de back-overgezet Apache JIRA's voor deze release:
| Beïnvloede functie | Apache JIRA |
|---|---|
| Datum/tijdstempel | HIVE-25104 |
| HIVE-24074 | |
| HIVE-22840 | |
| HIVE-22589 | |
| HIVE-22405 | |
| HIVE-21729 | |
| HIVE-21291 | |
| HIVE-21290 | |
| UDF | HIVE-25268 |
| HIVE-25093 | |
| HIVE-22099 | |
| HIVE-24113 | |
| HIVE-22170 | |
| HIVE-22331 | |
| ORC | HIVE-21991 |
| HIVE-21815 | |
| HIVE-21862 | |
| Tabelschema | HIVE-20437 |
| HIVE-22941 | |
| HIVE-21784 | |
| HIVE-21714 | |
| HIVE-18702 | |
| HIVE-21799 | |
| HIVE-21296 | |
| Workloadbeheer | HIVE-24201 |
| Compressie | HIVE-24882 |
| HIVE-23058 | |
| HIVE-23046 | |
| Gerealiseerde weergave | HIVE-22566 |
Prijscorrectie voor virtuele HDInsight-machines Dv2
Er is een prijsfout gecorrigeerd op 25 april 2021 voor de Dv2 VM-serie in HDInsight. De prijsfout heeft geresulteerd in een verlaagde kosten voor de facturen van een aantal klanten vóór 25 april en met de correctie komen de prijzen nu overeen met wat er is geadverteerd op de pagina met HDInsight-prijzen en de HDInsight-prijscalculator. De prijsfout heeft klanten in de volgende regio's beïnvloed die VM's hebben gebruikt Dv2 :
- Canada - midden
- Canada - oost
- Azië - oost
- Zuid-Afrika - noord
- Azië - zuidoost
- UAE - centraal
Vanaf 25 april 2021 wordt het gecorrigeerde bedrag voor de Dv2 VM's op uw account weergegeven. Klantmeldingen zijn verzonden naar abonnementseigenaren vóór de wijziging. U kunt de pagina Prijscalculator, hdInsight-prijzen of de blade HDInsight-cluster maken in Azure Portal gebruiken om de gecorrigeerde kosten voor Dv2 VM's in uw regio te bekijken.
Er is geen andere actie van u nodig. De prijscorrectie is alleen van toepassing op of na 25 april 2021 in de opgegeven regio's en niet op enig gebruik vóór deze datum. Om ervoor te zorgen dat u de meest presterende en rendabele oplossing hebt, raden we u aan de prijzen, VCPU en RAM voor uw Dv2 clusters te bekijken en de Dv2 specificaties te vergelijken met de Ev3 VM's om te zien of uw oplossing zou profiteren van een van de nieuwere VM-serie.
Releasedatum: 06-02-2021
Deze release is van toepassing op zowel HDInsight 3.6 als HDInsight 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release binnen enkele dagen live is in uw regio.
De versies van het besturingssysteem voor deze release zijn:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Nieuwe functies
Upgrade van besturingssysteemversie
Zoals wordt verwezen in de releasecyclus van Ubuntu, bereikt de Ubuntu 16.04-kernel het einde van de levensduur (EOL) in april 2021. We zijn begonnen met het implementeren van de nieuwe HDInsight 4.0-clusterinstallatiekopie die wordt uitgevoerd op Ubuntu 18.04 met deze release. Nieuw gemaakte HDInsight 4.0-clusters worden standaard uitgevoerd op Ubuntu 18.04 zodra deze beschikbaar zijn. Bestaande clusters op Ubuntu 16.04 worden uitgevoerd, net als bij volledige ondersteuning.
HDInsight 3.6 blijft actief op Ubuntu 16.04. Het wordt vanaf 1 juli 2021 gewijzigd in Basic-ondersteuning (vanaf Standard-ondersteuning). Zie Azure HDInsight-versies voor meer informatie over datums en ondersteuningsopties. Ubuntu 18.04 wordt niet ondersteund voor HDInsight 3.6. Als u Ubuntu 18.04 wilt gebruiken, moet u uw clusters migreren naar HDInsight 4.0.
U moet uw clusters verwijderen en opnieuw maken als u bestaande HDInsight 4.0-clusters wilt verplaatsen naar Ubuntu 18.04. Plan om uw clusters te maken of opnieuw te maken nadat de ondersteuning voor Ubuntu 18.04 beschikbaar is.
Nadat u het nieuwe cluster hebt gemaakt, kunt u SSH naar uw cluster uitvoeren om te controleren of het wordt uitgevoerd sudo lsb_release -a op Ubuntu 18.04. U wordt aangeraden uw toepassingen eerst in uw testabonnementen te testen voordat u naar productie gaat.
Optimalisaties schalen op versnelde HBase-schrijfclusters
HDInsight heeft enkele verbeteringen en optimalisaties aangebracht bij het schalen van clusters met versnelde schrijfbewerkingen voor HBase. Meer informatie over versneld schrijven via HBase.
Afschaffing
Geen afschaffing in deze release.
Gedragswijzigingen
Stardard_A5 VM-grootte uitschakelen als hoofdknooppunt voor HDInsight 4.0
HdInsight-clusterhoofdknooppunt is verantwoordelijk voor het initialiseren en beheren van het cluster. Standard_A5 VM-grootte betrouwbaarheidsproblemen heeft als hoofdknooppunt voor HDInsight 4.0. Vanaf deze release kunnen klanten geen nieuwe clusters maken met Standard_A5 VM-grootte als hoofdknooppunt. U kunt andere vm's met twee kernen gebruiken, zoals E2_v3 of E2s_v3. Bestaande clusters worden als zodanig uitgevoerd. Een VM met vier kernen wordt ten zeerste aanbevolen voor Head Node om de hoge beschikbaarheid en betrouwbaarheid van uw HDInsight-productieclusters te garanderen.
Netwerkinterfaceresource is niet zichtbaar voor clusters die worden uitgevoerd op virtuele-machineschaalsets van Azure
HDInsight migreert geleidelijk naar virtuele-machineschaalsets van Azure. Netwerkinterfaces voor virtuele machines zijn niet meer zichtbaar voor klanten voor clusters die gebruikmaken van virtuele-machineschaalsets van Azure.
Toekomstige wijzigingen
De volgende wijzigingen worden doorgevoerd in toekomstige releases.
HDInsight Interactive Query biedt alleen ondersteuning voor automatisch schalen op basis van schema's
Naarmate klantscenario's volwassener en diverser worden, hebben we enkele beperkingen geïdentificeerd met op load gebaseerde automatische schaalaanpassing op basis van Interactive Query (LLAP). Deze beperkingen worden veroorzaakt door de aard van LLAP-querydynamiek, toekomstige problemen met de nauwkeurigheid van de belastingvoorspelling en problemen in de herdistributie van de taak van de LLAP-planner. Vanwege deze beperkingen kunnen gebruikers zien dat hun query's langzamer worden uitgevoerd op LLAP-clusters wanneer automatische schaalaanpassing is ingeschakeld. Het effect op prestaties kan opwegen tegen de kostenvoordelen van automatische schaalaanpassing.
Vanaf juli 2021 biedt de workload Interactive Query in HDInsight alleen ondersteuning voor automatisch schalen op basis van een planning. U kunt automatische schaalaanpassing niet meer inschakelen voor nieuwe Interactive Query-clusters. Bestaande actieve clusters kunnen blijven worden uitgevoerd met de bekende beperkingen die hierboven worden beschreven.
Microsoft raadt u aan over te stappen op een op planning gebaseerde automatische schaalaanpassing voor LLAP. U kunt het huidige gebruikspatroon van uw cluster analyseren via het Grafana Hive-dashboard. Zie Azure HDInsight-clusters automatisch schalen voor meer informatie.
Naamgeving van VM-host wordt gewijzigd op 1 juli 2021
HDInsight maakt nu gebruik van virtuele Azure-machines om het cluster in te richten. De service migreert geleidelijk naar virtuele-machineschaalsets van Azure. Met deze migratie wordt de FQDN-naamindeling van de clusterhostnaam gewijzigd en worden de getallen in de hostnaam niet op volgorde gegarandeerd. Als u de FQDN-namen voor elk knooppunt wilt ophalen, raadpleegt u De hostnamen van clusterknooppunten zoeken.
Verplaatsen naar virtuele-machineschaalsets van Azure
HDInsight maakt nu gebruik van virtuele Azure-machines om het cluster in te richten. De service wordt geleidelijk gemigreerd naar virtuele-machineschaalsets van Azure. Het hele proces kan maanden duren. Nadat uw regio's en abonnementen zijn gemigreerd, worden nieuw gemaakte HDInsight-clusters uitgevoerd op virtuele-machineschaalsets zonder klantacties. Er wordt geen wijziging verwacht die fouten veroorzaken.
Releasedatum: 24-03-2021
Nieuwe functies
Preview van Spark 3.0
HDInsight heeft Spark 3.0.0-ondersteuning toegevoegd aan HDInsight 4.0 als preview-functie.
Kafka 2.4 preview
HDInsight heeft Kafka 2.4.1-ondersteuning toegevoegd aan HDInsight 4.0 als preview-functie.
Eav4-serieondersteuning
HDInsight heeft ondersteuning voor -series toegevoegd Eav4in deze release.
Overstappen op virtuele-machineschaalsets van Azure
HDInsight maakt nu gebruik van virtuele Azure-machines om het cluster in te richten. De service migreert geleidelijk naar virtuele-machineschaalsets van Azure. Het hele proces kan maanden duren. Nadat uw regio's en abonnementen zijn gemigreerd, worden nieuw gemaakte HDInsight-clusters uitgevoerd op virtuele-machineschaalsets zonder klantacties. Er wordt geen wijziging verwacht die fouten veroorzaken.
Afschaffing
Geen afschaffing in deze release.
Gedragswijzigingen
De standaardclusterversie wordt gewijzigd in 4.0
De standaardversie van het HDInsight-cluster wordt gewijzigd van 3.6 in 4.0. Zie de beschikbare versies voor meer informatie over beschikbare versies. Meer informatie over wat er nieuw is in HDInsight 4.0.
Standaardgrootten van cluster-VM's worden gewijzigd in Ev3-series
Standaardgrootten van cluster-VM's worden gewijzigd van D-serie in Ev3-series. Deze wijziging is van toepassing op hoofdknooppunten en werkknooppunten. Als u deze wijziging wilt voorkomen die van invloed zijn op uw geteste werkstromen, geeft u de VM-grootten op die u wilt gebruiken in de ARM-sjabloon.
Netwerkinterfaceresource is niet zichtbaar voor clusters die worden uitgevoerd op virtuele-machineschaalsets van Azure
HDInsight migreert geleidelijk naar virtuele-machineschaalsets van Azure. Netwerkinterfaces voor virtuele machines zijn niet meer zichtbaar voor klanten voor clusters die gebruikmaken van virtuele-machineschaalsets van Azure.
Toekomstige wijzigingen
De volgende wijzigingen worden doorgevoerd in toekomstige releases.
HDInsight Interactive Query biedt alleen ondersteuning voor automatisch schalen op basis van schema's
Naarmate klantscenario's volwassener en diverser worden, hebben we enkele beperkingen geïdentificeerd met op load gebaseerde automatische schaalaanpassing op basis van Interactive Query (LLAP). Deze beperkingen worden veroorzaakt door de aard van LLAP-querydynamiek, toekomstige problemen met de nauwkeurigheid van de belastingvoorspelling en problemen in de herdistributie van de taak van de LLAP-planner. Vanwege deze beperkingen kunnen gebruikers zien dat hun query's langzamer worden uitgevoerd op LLAP-clusters wanneer automatische schaalaanpassing is ingeschakeld. De invloed op prestaties kan opwegen tegen de kostenvoordelen van automatische schaalaanpassing.
Vanaf juli 2021 biedt de workload Interactive Query in HDInsight alleen ondersteuning voor automatisch schalen op basis van een planning. U kunt automatische schaalaanpassing niet meer inschakelen voor nieuwe Interactive Query-clusters. Bestaande actieve clusters kunnen blijven worden uitgevoerd met de bekende beperkingen die hierboven worden beschreven.
Microsoft raadt u aan over te stappen op een op planning gebaseerde automatische schaalaanpassing voor LLAP. U kunt het huidige gebruikspatroon van uw cluster analyseren via het Grafana Hive-dashboard. Zie Azure HDInsight-clusters automatisch schalen voor meer informatie.
Upgrade van besturingssysteemversie
HDInsight-clusters worden momenteel uitgevoerd op Ubuntu 16.04 LTS. Zoals wordt verwezen in de releasecyclus van Ubuntu, bereikt de Ubuntu 16.04-kernel het einde van de levensduur (EOL) in april 2021. We gaan de nieuwe HDInsight 4.0-clusterinstallatiekopie implementeren die in mei 2021 wordt uitgevoerd op Ubuntu 18.04. Nieuw gemaakte HDInsight 4.0-clusters worden standaard uitgevoerd op Ubuntu 18.04 zodra ze beschikbaar zijn. Bestaande clusters in Ubuntu 16.04 worden uitgevoerd zoals die met volledige ondersteuning.
HDInsight 3.6 blijft actief op Ubuntu 16.04. Vanaf 1 juli 2021 wordt de standaardondersteuning beëindigd en wordt vanaf 1 juli 2021 de basisondersteuning gewijzigd. Zie Azure HDInsight-versies voor meer informatie over datums en ondersteuningsopties. Ubuntu 18.04 wordt niet ondersteund voor HDInsight 3.6. Als u Ubuntu 18.04 wilt gebruiken, moet u uw clusters migreren naar HDInsight 4.0.
U moet uw clusters verwijderen en opnieuw maken als u bestaande clusters wilt verplaatsen naar Ubuntu 18.04. Plan om uw cluster te maken of opnieuw te maken nadat ubuntu 18.04-ondersteuning beschikbaar is. Er wordt een andere melding verzonden nadat de nieuwe installatiekopie beschikbaar is in alle regio's.
Het wordt ten zeerste aanbevolen om vooraf uw scriptacties en aangepaste toepassingen te testen die zijn geïmplementeerd op edge-knooppunten op een virtuele Ubuntu 18.04-machine (VM). U kunt een Ubuntu Linux-VM maken op 18.04-LTS en vervolgens een SSH-sleutelpaar (Secure Shell) maken en gebruiken op uw VM om uw scriptacties en aangepaste toepassingen uit te voeren en te testen die zijn geïmplementeerd op edge-knooppunten.
Stardard_A5 VM-grootte uitschakelen als hoofdknooppunt voor HDInsight 4.0
HdInsight-clusterhoofdknooppunt is verantwoordelijk voor het initialiseren en beheren van het cluster. Standard_A5 VM-grootte betrouwbaarheidsproblemen heeft als hoofdknooppunt voor HDInsight 4.0. Vanaf de volgende release in mei 2021 kunnen klanten geen nieuwe clusters maken met Standard_A5 VM-grootte als hoofdknooppunt. U kunt andere vm's met twee kernen gebruiken, zoals E2_v3 of E2s_v3. Bestaande clusters worden als zodanig uitgevoerd. Een VM met vier kernen wordt ten zeerste aanbevolen voor hoofdknooppunten om de hoge beschikbaarheid en betrouwbaarheid van uw HDInsight-productieclusters te garanderen.
Bugfixes
HDInsight blijft de betrouwbaarheid en prestaties van clusters verbeteren.
Wijziging van onderdeelversie
Ondersteuning toegevoegd voor Spark 3.0.0 en Kafka 2.4.1 als preview. In dit document vindt u de huidige onderdeelversies voor HDInsight 4.0 en HDInsight 3.6.
Releasedatum: 02-05-2021
Deze release is van toepassing op zowel HDInsight 3.6 als HDInsight 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release binnen enkele dagen live is in uw regio.
Nieuwe functies
Ondersteuning voor Dav4-serie
HDInsight heeft ondersteuning voor de Dav4-serie toegevoegd in deze release. Meer informatie over Dav4-serie vindt u hier.
GA van Kafka REST-proxy
Met de Kafka REST-proxy kunt u communiceren met uw Kafka-cluster via een REST API via HTTPS. Kafka REST Proxy is algemeen beschikbaar vanaf deze release. Meer informatie over Kafka REST Proxy vindt u hier.
Overstappen op virtuele-machineschaalsets van Azure
HDInsight maakt nu gebruik van virtuele Azure-machines om het cluster in te richten. De service migreert geleidelijk naar virtuele-machineschaalsets van Azure. Het hele proces kan maanden duren. Nadat uw regio's en abonnementen zijn gemigreerd, worden nieuw gemaakte HDInsight-clusters uitgevoerd op virtuele-machineschaalsets zonder klantacties. Er wordt geen wijziging verwacht die fouten veroorzaken.
Afschaffing
Uitgeschakelde VM-grootten
Vanaf 9 januari 2021 blokkeert HDInsight alle klanten die clusters maken met behulp van standand_A8, standand_A9, standand_A10 en standand_A11 VM-grootten. Bestaande clusters worden als zodanig uitgevoerd. Overweeg om over te stappen op HDInsight 4.0 om mogelijke systeem-/ondersteuningsonderbrekingen te voorkomen.
Gedragswijzigingen
De grootte van de standaardcluster-VM wordt gewijzigd in Ev3-series
Standaardgrootten van cluster-VM's worden gewijzigd van D-serie in Ev3-series. Deze wijziging is van toepassing op hoofdknooppunten en werkknooppunten. Als u deze wijziging wilt voorkomen die van invloed zijn op uw geteste werkstromen, geeft u de VM-grootten op die u wilt gebruiken in de ARM-sjabloon.
Netwerkinterfaceresource is niet zichtbaar voor clusters die worden uitgevoerd op virtuele-machineschaalsets van Azure
HDInsight migreert geleidelijk naar virtuele-machineschaalsets van Azure. Netwerkinterfaces voor virtuele machines zijn niet meer zichtbaar voor klanten voor clusters die gebruikmaken van virtuele-machineschaalsets van Azure.
Toekomstige wijzigingen
De volgende wijzigingen worden doorgevoerd in toekomstige releases.
De standaardclusterversie wordt gewijzigd in 4.0
Vanaf februari 2021 wordt de standaardversie van het HDInsight-cluster gewijzigd van 3.6 in 4.0. Zie de beschikbare versies voor meer informatie over beschikbare versies. Meer informatie over wat er nieuw is in HDInsight 4.0.
Upgrade van besturingssysteemversie
HDInsight voert een upgrade uit van de versie van het besturingssysteem van Ubuntu 16.04 naar 18.04. De upgrade wordt vóór april 2021 voltooid.
HdInsight 3.6 einde van de ondersteuning op 30 juni 2021
HDInsight 3.6 wordt beëindigd. Vanaf 30 juni 2021 kunnen klanten geen nieuwe HDInsight 3.6-clusters maken. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Overweeg om over te stappen op HDInsight 4.0 om mogelijke systeem-/ondersteuningsonderbrekingen te voorkomen.
Wijziging van onderdeelversie
Er is geen wijziging in de onderdeelversie voor deze release. In dit document vindt u de huidige onderdeelversies voor HDInsight 4.0 en HDInsight 3.6.
Releasedatum: 11-18-2020
Deze release is van toepassing op zowel HDInsight 3.6 als HDInsight 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release binnen enkele dagen live is in uw regio.
Nieuwe functies
Automatische sleutelrotatie voor door de klant beheerde sleutelversleuteling at rest
Vanaf deze release kunnen klanten azure KeyValut-versieloze versleutelingssleutel-URL's gebruiken voor door de klant beheerde sleutelversleuteling in rust. HDInsight draait de sleutels automatisch wanneer ze verlopen of vervangen worden door nieuwe versies. Meer informatie hier.
Mogelijkheid om verschillende Grootten van virtuele Zookeeper-machines te selecteren voor Spark, Hadoop en ML Services
HDInsight biedt eerder geen ondersteuning voor het aanpassen van zookeeper-knooppuntgrootte voor Spark-, Hadoop- en ML Services-clustertypen. Het is standaard ingesteld op A2_v2/A2 grootten van virtuele machines, die gratis worden aangeboden. In deze release kunt u een Grootte van de virtuele Zookeeper-machine selecteren die het meest geschikt is voor uw scenario. Zookeeper-knooppunten met een andere grootte dan A2_v2/A2 worden in rekening gebracht. A2_v2 en A2 virtuele machines worden nog steeds gratis aangeboden.
Overstappen op virtuele-machineschaalsets van Azure
HDInsight maakt nu gebruik van virtuele Azure-machines om het cluster in te richten. Vanaf deze release wordt de service geleidelijk gemigreerd naar virtuele-machineschaalsets van Azure. Het hele proces kan maanden duren. Nadat uw regio's en abonnementen zijn gemigreerd, worden nieuw gemaakte HDInsight-clusters uitgevoerd op virtuele-machineschaalsets zonder klantacties. Er wordt geen wijziging verwacht die fouten veroorzaken.
Afschaffing
Afschaffing van HDInsight 3.6 ML Services-cluster
Het clustertype HDInsight 3.6 ML Services wordt tegen 31 december 2020 beëindigd. Klanten kunnen na 31 december 2020 geen nieuwe 3.6 ML Services-clusters maken. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Controleer hier de vervaldatum van de ondersteuning voor HDInsight-versies en clustertypen.
Uitgeschakelde VM-grootten
Vanaf 16 november 2020 blokkeren HDInsight nieuwe klanten die clusters maken met behulp van standand_A8, standand_A9, standand_A10 en standand_A11 VM-grootten. Bestaande klanten die deze VM-grootten in de afgelopen drie maanden hebben gebruikt, worden niet beïnvloed. Vanaf 9 januari 2021 blokkeert HDInsight alle klanten die clusters maken met behulp van standand_A8, standand_A9, standand_A10 en standand_A11 VM-grootten. Bestaande clusters worden als zodanig uitgevoerd. Overweeg om over te stappen op HDInsight 4.0 om mogelijke systeem-/ondersteuningsonderbrekingen te voorkomen.
Gedragswijzigingen
NSG-regelcontrole toevoegen voordat de schaalbewerking wordt uitgevoerd
HDInsight heeft netwerkbeveiligingsgroepen (NSG's) en door de gebruiker gedefinieerde routes (UDR's) toegevoegd die controleren op schaalbewerkingen. Dezelfde validatie wordt uitgevoerd voor het schalen van clusters, naast het maken van clusters. Deze validatie helpt onvoorspelbare fouten te voorkomen. Als de validatie niet is geslaagd, mislukt het schalen. Raadpleeg IP-adressen voor HDInsight-beheer voor meer informatie over het correct configureren van NSG's en UDR's.
Wijziging van onderdeelversie
Er is geen wijziging in de onderdeelversie voor deze release. In dit document vindt u de huidige onderdeelversies voor HDInsight 4.0 en HDInsight 3.6.
Releasedatum: 11-09-2020
Deze release is van toepassing op zowel HDInsight 3.6 als HDInsight 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release binnen enkele dagen live is in uw regio.
Nieuwe functies
HDInsight Identity Broker (HIB) is nu algemeen beschikbaar
HDInsight Identity Broker (HIB) waarmee OAuth-verificatie voor ESP-clusters wordt ingeschakeld, is nu algemeen beschikbaar met deze release. HIB-clusters die na deze release zijn gemaakt, hebben de nieuwste HIB-functies:
- Hoge beschikbaarheid (HA)
- Ondersteuning voor meervoudige verificatie (MFA)
- Federatieve gebruikers melden zich aan zonder wachtwoord-hashsynchronisatie met AAD-DS Voor meer informatie raadpleegt u de HIB-documentatie.
Overstappen op virtuele-machineschaalsets van Azure
HDInsight maakt nu gebruik van virtuele Azure-machines om het cluster in te richten. Vanaf deze release wordt de service geleidelijk gemigreerd naar virtuele-machineschaalsets van Azure. Het hele proces kan maanden duren. Nadat uw regio's en abonnementen zijn gemigreerd, worden nieuw gemaakte HDInsight-clusters uitgevoerd op virtuele-machineschaalsets zonder klantacties. Er wordt geen wijziging verwacht die fouten veroorzaken.
Afschaffing
Afschaffing van HDInsight 3.6 ML Services-cluster
Het clustertype HDInsight 3.6 ML Services wordt tegen 31 december 2020 beëindigd. Klanten maken na 31 december 2020 geen nieuwe 3.6 ML Services-clusters. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Controleer hier de vervaldatum van de ondersteuning voor HDInsight-versies en clustertypen.
Uitgeschakelde VM-grootten
Vanaf 16 november 2020 blokkeren HDInsight nieuwe klanten die clusters maken met behulp van standand_A8, standand_A9, standand_A10 en standand_A11 VM-grootten. Bestaande klanten die deze VM-grootten in de afgelopen drie maanden hebben gebruikt, worden niet beïnvloed. Vanaf 9 januari 2021 blokkeert HDInsight alle klanten die clusters maken met behulp van standand_A8, standand_A9, standand_A10 en standand_A11 VM-grootten. Bestaande clusters worden als zodanig uitgevoerd. Overweeg om over te stappen op HDInsight 4.0 om mogelijke systeem-/ondersteuningsonderbrekingen te voorkomen.
Gedragswijzigingen
Geen gedragswijziging voor deze release.
Toekomstige wijzigingen
De volgende wijzigingen worden doorgevoerd in toekomstige releases.
Mogelijkheid om verschillende Grootten van virtuele Zookeeper-machines te selecteren voor Spark, Hadoop en ML Services
HDInsight biedt momenteel geen ondersteuning voor het aanpassen van zookeeper-knooppuntgrootte voor Spark-, Hadoop- en ML Services-clustertypen. Het is standaard ingesteld op A2_v2/A2 grootten van virtuele machines, die gratis worden aangeboden. In de komende release kunt u een Grootte van de virtuele Zookeeper-machine selecteren die het meest geschikt is voor uw scenario. Zookeeper-knooppunten met een andere grootte dan A2_v2/A2 worden in rekening gebracht. A2_v2 en A2 virtuele machines worden nog steeds gratis aangeboden.
De standaardclusterversie wordt gewijzigd in 4.0
Vanaf februari 2021 wordt de standaardversie van het HDInsight-cluster gewijzigd van 3.6 in 4.0. Zie ondersteunde versies voor meer informatie over beschikbare versies. Meer informatie over wat er nieuw is in HDInsight 4.0
HdInsight 3.6 einde van de ondersteuning op 30 juni 2021
HDInsight 3.6 wordt beëindigd. Vanaf 30 juni 2021 kunnen klanten geen nieuwe HDInsight 3.6-clusters maken. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Overweeg om over te stappen op HDInsight 4.0 om mogelijke systeem-/ondersteuningsonderbrekingen te voorkomen.
Bugfixes
HDInsight blijft de betrouwbaarheid en prestaties van clusters verbeteren.
Probleem opgelost voor het opnieuw opstarten van VM's in cluster
Het probleem voor het opnieuw opstarten van VM's in het cluster is opgelost. U kunt PowerShell of REST API gebruiken om knooppunten in het cluster opnieuw op te starten.
Wijziging van onderdeelversie
Er is geen wijziging in de onderdeelversie voor deze release. In dit document vindt u de huidige onderdeelversies voor HDInsight 4.0 en HDInsight 3.6.
Releasedatum: 10-08-2020
Deze release is van toepassing op zowel HDInsight 3.6 als HDInsight 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release binnen enkele dagen live is in uw regio.
Nieuwe functies
Privéclusters in HDInsight zonder openbare IP- en privékoppeling (preview)
HDInsight biedt nu ondersteuning voor het maken van clusters zonder openbare IP- en privékoppelingstoegang tot de clusters in preview. Klanten kunnen de nieuwe geavanceerde netwerkinstellingen gebruiken om een volledig geïsoleerd cluster te maken zonder openbaar IP-adres en hun eigen privé-eindpunten te gebruiken voor toegang tot het cluster.
Overstappen op virtuele-machineschaalsets van Azure
HDInsight maakt nu gebruik van virtuele Azure-machines om het cluster in te richten. Vanaf deze release wordt de service geleidelijk gemigreerd naar virtuele-machineschaalsets van Azure. Het hele proces kan maanden duren. Nadat uw regio's en abonnementen zijn gemigreerd, worden nieuw gemaakte HDInsight-clusters uitgevoerd op virtuele-machineschaalsets zonder klantacties. Er wordt geen wijziging verwacht die fouten veroorzaken.
Afschaffing
Afschaffing van HDInsight 3.6 ML Services-cluster
HdInsight 3.6 ML Services-clustertype wordt tegen 31 december 2020 beëindigd. Klanten maken daarna geen nieuwe 3.6 ML Services-clusters. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Controleer hier de vervaldatum van de ondersteuning voor HDInsight-versies en clustertypen.
Gedragswijzigingen
Geen gedragswijziging voor deze release.
Toekomstige wijzigingen
De volgende wijzigingen worden doorgevoerd in toekomstige releases.
Mogelijkheid om verschillende Grootten van virtuele Zookeeper-machines te selecteren voor Spark, Hadoop en ML Services
HDInsight biedt momenteel geen ondersteuning voor het aanpassen van zookeeper-knooppuntgrootte voor Spark-, Hadoop- en ML Services-clustertypen. Het is standaard ingesteld op A2_v2/A2 grootten van virtuele machines, die gratis worden aangeboden. In de komende release kunt u een Grootte van de virtuele Zookeeper-machine selecteren die het meest geschikt is voor uw scenario. Zookeeper-knooppunten met een andere grootte dan A2_v2/A2 worden in rekening gebracht. A2_v2 en A2 virtuele machines worden nog steeds gratis aangeboden.
Bugfixes
HDInsight blijft de betrouwbaarheid en prestaties van clusters verbeteren.
Wijziging van onderdeelversie
Er is geen wijziging in de onderdeelversie voor deze release. In dit document vindt u de huidige onderdeelversies voor HDInsight 4.0 en HDInsight 3.6.
Releasedatum: 28-09-2020
Deze release is van toepassing op zowel HDInsight 3.6 als HDInsight 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release binnen enkele dagen live is in uw regio.
Nieuwe functies
Automatisch schalen voor Interactive Query met HDInsight 4.0 is nu algemeen beschikbaar
Automatisch schalen voor het type Interactive Query-cluster is nu algemeen beschikbaar (GA) voor HDInsight 4.0. Alle Interactive Query 4.0-clusters die na 27 augustus 2020 zijn gemaakt, bieden ALGEMENE ondersteuning voor automatische schaalaanpassing.
HBase-cluster ondersteunt Premium ADLS Gen2
HDInsight ondersteunt nu Premium ADLS Gen2 als primair opslagaccount voor HDInsight HBase 3.6- en 4.0-clusters. Samen met versnelde schrijfbewerkingen kunt u betere prestaties krijgen voor uw HBase-clusters.
Kafka-partitiedistributie in Azure-foutdomeinen
Een foutdomein is een logische groepering van de onderliggende hardware in een Azure-datacenter. Elk foutdomein deelt een algemene voedingsbron en netwerkswitch. Voordat HDInsight Kafka alle partitiereplica's in hetzelfde foutdomein kan opslaan. Vanaf deze release ondersteunt HDInsight nu automatisch distributie van Kafka-partities op basis van Azure-foutdomeinen.
Versleuteling 'in transit'
Klanten kunnen versleuteling inschakelen tussen clusterknooppunten met behulp van IPSec-versleuteling met door het platform beheerde sleutels. Deze optie kan worden ingeschakeld tijdens het maken van het cluster. Zie meer informatie over het inschakelen van versleuteling tijdens overdracht.
Versleuteling op de host
Wanneer u versleuteling op de host inschakelt, worden gegevens die zijn opgeslagen op de VM-host versleuteld in rust en stromen versleuteld naar de opslagservice. In deze release kunt u versleuteling op host op tijdelijke gegevensschijf inschakelen bij het maken van het cluster. Versleuteling op de host wordt alleen ondersteund op bepaalde VM-SKU's in beperkte regio's. HDInsight ondersteunt de volgende knooppuntconfiguratie en SKU's. Zie meer informatie over het inschakelen van versleuteling op de host.
Overstappen op virtuele-machineschaalsets van Azure
HDInsight maakt nu gebruik van virtuele Azure-machines om het cluster in te richten. Vanaf deze release wordt de service geleidelijk gemigreerd naar virtuele-machineschaalsets van Azure. Het hele proces kan maanden duren. Nadat uw regio's en abonnementen zijn gemigreerd, worden nieuw gemaakte HDInsight-clusters uitgevoerd op virtuele-machineschaalsets zonder klantacties. Er wordt geen wijziging verwacht die fouten veroorzaken.
Afschaffing
Geen afschaffing voor deze release.
Gedragswijzigingen
Geen gedragswijziging voor deze release.
Toekomstige wijzigingen
De volgende wijzigingen worden doorgevoerd in toekomstige releases.
Mogelijkheid om verschillende Zookeeper-SKU te selecteren voor Spark, Hadoop en ML Services
HDInsight biedt momenteel geen ondersteuning voor het wijzigen van Zookeeper-SKU voor Spark-, Hadoop- en ML Services-clustertypen. Het maakt gebruik van A2_v2/A2-SKU voor Zookeeper-knooppunten en klanten worden hiervoor niet in rekening gebracht. In de komende release kunnen klanten De Zookeeper-SKU voor Spark, Hadoop en ML Services zo nodig wijzigen. Zookeeper-knooppunten met andere SKU's dan A2_v2/A2 worden in rekening gebracht. De standaard-SKU wordt nog steeds A2_V2/A2 en gratis.
Bugfixes
HDInsight blijft de betrouwbaarheid en prestaties van clusters verbeteren.
Wijziging van onderdeelversie
Er is geen wijziging in de onderdeelversie voor deze release. In dit document vindt u de huidige onderdeelversies voor HDInsight 4.0 en HDInsight 3.6.
Releasedatum: 08-09-2020
Deze release is alleen van toepassing op HDInsight 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release binnen enkele dagen live is in uw regio.
Nieuwe functies
Ondersteuning voor SparkCruise
SparkCruise is een systeem voor automatisch hergebruik van berekeningen voor Spark. Het selecteert algemene subexpressies om te materialiseren op basis van de eerdere queryworkload. SparkCruise materialiseert deze subexpressies als onderdeel van queryverwerking en hergebruik van berekeningen wordt automatisch op de achtergrond toegepast. U kunt gebruikmaken van SparkCruise zonder dat u de Spark-code hoeft aan te passen.
Ondersteuning voor Hive-weergave voor HDInsight 4.0
De Apache Ambari Hive-weergave is ontworpen om u te helpen Hive-query's te ontwerpen, te optimaliseren en uit te voeren vanuit uw webbrowser. Hive-weergave wordt systeemeigen ondersteund voor HDInsight 4.0-clusters vanaf deze release. Deze is niet van toepassing op bestaande clusters. U moet het cluster verwijderen en opnieuw maken om de ingebouwde Hive-weergave op te halen.
Ondersteuning voor Tez View voor HDInsight 4.0
Apache Tez View wordt gebruikt om de uitvoering van de Hive Tez-taak bij te houden en fouten op te sporen. Tez View wordt systeemeigen ondersteund voor HDInsight 4.0 vanaf deze release. Deze is niet van toepassing op bestaande clusters. U moet het cluster verwijderen en opnieuw maken om de ingebouwde Tez-weergave op te halen.
Afschaffing
Afschaffing van Apache Spark 2.1 en 2.2 in HDInsight 3.6 Spark-cluster
Vanaf 1 juli 2020 kunnen klanten geen nieuwe Spark-clusters maken met Spark 2.1 en 2.2 in HDInsight 3.6. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Overweeg om tegen 30 juni 2020 over te stappen naar Spark 2.3.3 op HDInsight 3.6 om mogelijke systeem-/ondersteuningsonderbrekingen te voorkomen.
Afschaffing van Apache Spark 2.3 in HDInsight 4.0 Spark-cluster
Vanaf 1 juli 2020 kunnen klanten geen nieuwe Spark-clusters maken met Spark 2.3 in HDInsight 4.0. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Overweeg om de overstap naar Apache Spark 2.4 op HDInsight 4.0 voor 30 juni 2020 te maken om potentiële systeem- en ondersteuningsonderbrekingen te voorkomen.
Afschaffing van Kafka 1.1 in HDInsight 4.0 Kafka-cluster
Vanaf 1 juli 2020 kunnen klanten geen nieuwe Kafka-clusters maken met Kafka 1.1 op HDInsight 4.0. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Overweeg om de overstap naar Kafka 2.1 op HDInsight 4.0 voor 30 juni 2020 te maken om potentiële systeem- en ondersteuningsonderbrekingen te voorkomen.
Gedragswijzigingen
Wijziging van Ambari-stackversie
In deze release verandert de Ambari-versie van 2.x.x.x in 4.1. U kunt de stackversie (HDInsight 4.1) controleren in Ambari: Ambari-gebruikersversies >> .
Toekomstige wijzigingen
Geen aanstaande wijzigingen die fouten veroorzaken waarvoor u aandacht moet besteden.
Bugfixes
HDInsight blijft de betrouwbaarheid en prestaties van clusters verbeteren.
Onderstaande JIRA's worden teruggezet voor Hive:
Onderstaande JIRA's worden weer overgezet voor HBase:
Wijziging van onderdeelversie
Er is geen wijziging in de onderdeelversie voor deze release. In dit document vindt u de huidige onderdeelversies voor HDInsight 4.0 en HDInsight 3.6.
Bekende problemen
Er is een probleem opgelost in Azure Portal, waarbij gebruikers een fout ondervonden bij het maken van een Azure HDInsight-cluster met behulp van een SSH-verificatietype van een openbare sleutel. Wanneer gebruikers op Review + Create hebben geklikt, krijgen ze de foutmelding 'Mag geen drie opeenvolgende tekens van de SSH-gebruikersnaam bevatten'. Dit probleem is opgelost, maar mogelijk moet u de browsercache vernieuwen door op Ctrl+F5 te drukken om de gecorrigeerde weergave te laden. De tijdelijke oplossing voor dit probleem was het maken van een cluster met een ARM-sjabloon.
Releasedatum: 13-07-2020
Deze release is zowel van toepassing op HDInsight 3.6 als 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release binnen enkele dagen live is in uw regio.
Nieuwe functies
Ondersteuning voor Customer Lockbox voor Microsoft Azure
Azure HDInsight ondersteunt nu Azure Customer Lockbox. Het biedt een interface voor klanten om aanvragen voor klantgegevenstoegang te beoordelen en goed te keuren of af te wijzen. Deze wordt gebruikt wanneer microsoft-technicus tijdens een ondersteuningsaanvraag toegang nodig heeft tot klantgegevens. Zie Customer Lockbox voor Microsoft Azure voor meer informatie.
Beleid voor service-eindpunten voor opslag
Klanten kunnen nu SEP (Service Endpoint Policies) gebruiken in het HDInsight-clustersubnet. Meer informatie over azure-service-eindpuntbeleid.
Afschaffing
Afschaffing van Apache Spark 2.1 en 2.2 in HDInsight 3.6 Spark-cluster
Vanaf 1 juli 2020 kunnen klanten geen nieuwe Spark-clusters maken met Spark 2.1 en 2.2 in HDInsight 3.6. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Overweeg om tegen 30 juni 2020 over te stappen naar Spark 2.3.3 op HDInsight 3.6 om mogelijke systeem-/ondersteuningsonderbrekingen te voorkomen.
Afschaffing van Apache Spark 2.3 in HDInsight 4.0 Spark-cluster
Vanaf 1 juli 2020 kunnen klanten geen nieuwe Spark-clusters maken met Spark 2.3 in HDInsight 4.0. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Overweeg om de overstap naar Apache Spark 2.4 op HDInsight 4.0 voor 30 juni 2020 te maken om potentiële systeem- en ondersteuningsonderbrekingen te voorkomen.
Afschaffing van Kafka 1.1 in HDInsight 4.0 Kafka-cluster
Vanaf 1 juli 2020 kunnen klanten geen nieuwe Kafka-clusters maken met Kafka 1.1 op HDInsight 4.0. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Overweeg om de overstap naar Kafka 2.1 op HDInsight 4.0 voor 30 juni 2020 te maken om potentiële systeem- en ondersteuningsonderbrekingen te voorkomen.
Gedragswijzigingen
Geen gedragswijzigingen waarop u moet letten.
Toekomstige wijzigingen
De volgende wijzigingen worden doorgevoerd in toekomstige releases.
Mogelijkheid om verschillende Zookeeper-SKU te selecteren voor Spark, Hadoop en ML Services
HDInsight biedt momenteel geen ondersteuning voor het wijzigen van Zookeeper-SKU voor Spark-, Hadoop- en ML Services-clustertypen. Het maakt gebruik van A2_v2/A2-SKU voor Zookeeper-knooppunten en klanten worden hiervoor niet in rekening gebracht. In de komende release kunnen klanten De Zookeeper-SKU voor Spark, Hadoop en ML Services zo nodig wijzigen. Zookeeper-knooppunten met andere SKU's dan A2_v2/A2 worden in rekening gebracht. De standaard-SKU wordt nog steeds A2_V2/A2 en gratis.
Bugfixes
HDInsight blijft de betrouwbaarheid en prestaties van clusters verbeteren.
Probleem met Hive Warehouse Verbinding maken or opgelost
Er is een probleem opgetreden bij de bruikbaarheid van de Hive Warehouse-connector in de vorige release. Het probleem is opgelost.
Probleem met voorloopnullen afgekapt met Zeppelin-notebook opgelost
Zeppelin was onjuist afgekapt voorloopnullen in de tabeluitvoer voor tekenreeksindeling. Dit probleem is opgelost in deze release.
Wijziging van onderdeelversie
Er is geen wijziging in de onderdeelversie voor deze release. In dit document vindt u de huidige onderdeelversies voor HDInsight 4.0 en HDInsight 3.6.
Releasedatum: 11-06-2020
Deze release is zowel van toepassing op HDInsight 3.6 als 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release binnen enkele dagen live is in uw regio.
Nieuwe functies
Overstappen op virtuele-machineschaalsets van Azure
HDInsight maakt gebruik van virtuele Azure-machines om het cluster nu in te richten. In deze release maken nieuwe HDInsight-clusters gebruik van een virtuele-machineschaalset van Azure. De wijziging wordt geleidelijk uitgerold. U zou geen belangrijke wijziging moeten verwachten. Meer informatie over virtuele-machineschaalsets van Azure.
VM's opnieuw opstarten in HDInsight-cluster
In deze release ondersteunen we het opnieuw opstarten van VM's in het HDInsight-cluster om niet-reagerende knooppunten opnieuw op te starten. Momenteel kunt u dit alleen doen via API, PowerShell en CLI-ondersteuning. Zie dit document voor meer informatie over de API.
Afschaffing
Afschaffing van Apache Spark 2.1 en 2.2 in HDInsight 3.6 Spark-cluster
Vanaf 1 juli 2020 kunnen klanten geen nieuwe Spark-clusters maken met Spark 2.1 en 2.2 in HDInsight 3.6. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Overweeg om tegen 30 juni 2020 over te stappen naar Spark 2.3.3 op HDInsight 3.6 om mogelijke systeem-/ondersteuningsonderbrekingen te voorkomen.
Afschaffing van Apache Spark 2.3 in HDInsight 4.0 Spark-cluster
Vanaf 1 juli 2020 kunnen klanten geen nieuwe Spark-clusters maken met Spark 2.3 in HDInsight 4.0. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Overweeg om de overstap naar Apache Spark 2.4 op HDInsight 4.0 voor 30 juni 2020 te maken om potentiële systeem- en ondersteuningsonderbrekingen te voorkomen.
Afschaffing van Kafka 1.1 in HDInsight 4.0 Kafka-cluster
Vanaf 1 juli 2020 kunnen klanten geen nieuwe Kafka-clusters maken met Kafka 1.1 op HDInsight 4.0. Bestaande clusters worden uitgevoerd zoals dit is zonder de ondersteuning van Microsoft. Overweeg om de overstap naar Kafka 2.1 op HDInsight 4.0 voor 30 juni 2020 te maken om potentiële systeem- en ondersteuningsonderbrekingen te voorkomen.
Gedragswijzigingen
Wijziging van de grootte van het HOOFDknooppunt van ESP Spark-cluster
De minimaal toegestane hoofdknooppuntgrootte voor ESP Spark-cluster wordt gewijzigd in Standard_D13_V2. VM's met lage kernen en geheugen als hoofdknooppunt kunnen problemen met het ESP-cluster veroorzaken vanwege relatief lage CPU- en geheugencapaciteit. Gebruik vanaf de release SKU's die hoger zijn dan Standard_D13_V2 en Standard_E16_V3 als hoofdknooppunt voor ESP Spark-clusters.
Er is minimaal een VM met 4 kernen vereist voor hoofdknooppunt
Er is minimaal 4 kern-VM's vereist voor hoofdknooppunten om de hoge beschikbaarheid en betrouwbaarheid van HDInsight-clusters te garanderen. Vanaf 6 april 2020 kunnen klanten alleen kiezen voor een vm met vier kernen of hoger als hoofdknooppunt voor de nieuwe HDInsight-clusters. Bestaande clusters blijven op de verwachte manier werken.
Inrichtingswijziging voor clusterwerkknooppunten
Wanneer 80% van de werkknooppunten gereed zijn, wordt het cluster in de operationele fase gezet. In deze fase kunnen klanten alle gegevensvlakbewerkingen uitvoeren, zoals het uitvoeren van scripts en taken. Maar klanten kunnen geen besturingsvlakbewerkingen uitvoeren, zoals omhoog/omlaag schalen. Alleen verwijdering wordt ondersteund.
Na de operationele fase wacht het cluster nog eens 60 minuten voor de resterende 20% werkknooppunten. Aan het einde van deze periode van 60 minuten wordt het cluster verplaatst naar de actieve fase, zelfs als alle werkknooppunten nog steeds niet beschikbaar zijn. Zodra een cluster de actieve fase binnenkomt, kunt u het als normaal gebruiken. Zowel beheerplanbewerkingen als omhoog/omlaag schalen en bewerkingen voor gegevensplannen, zoals het uitvoeren van scripts en taken, worden geaccepteerd. Als sommige aangevraagde werkknooppunten niet beschikbaar zijn, wordt het cluster gemarkeerd als gedeeltelijk geslaagd. Er worden kosten in rekening gebracht voor de knooppunten die zijn geïmplementeerd.
Nieuwe service-principal maken via HDInsight
Voorheen kunnen klanten met het maken van een cluster een nieuwe service-principal maken voor toegang tot het verbonden ADLS Gen 1-account in Azure Portal. Vanaf 15 juni 2020 is het maken van een nieuwe service-principal niet mogelijk in de werkstroom voor het maken van HDInsight. Alleen bestaande service-principals worden ondersteund. Zie Service-principal en certificaten maken met behulp van Azure Active Directory.
Time-out voor scriptacties bij het maken van een cluster
HDInsight ondersteunt het uitvoeren van scriptacties bij het maken van clusters. Vanuit deze release moeten alle scriptacties met het maken van een cluster binnen 60 minuten worden voltooid, of er is een time-out opgetreden. Scriptacties die worden verzonden naar actieve clusters, worden niet beïnvloed. Meer informatie hier.
Toekomstige wijzigingen
Geen aanstaande wijzigingen die fouten veroorzaken waarvoor u aandacht moet besteden.
Bugfixes
HDInsight blijft de betrouwbaarheid en prestaties van clusters verbeteren.
Wijziging van onderdeelversie
HBase 2.0 tot 2.1.6
HBase-versie wordt bijgewerkt van versie 2.0 naar 2.1.6.
Spark 2.4.0 tot 2.4.4
Spark-versie wordt bijgewerkt van versie 2.4.0 naar 2.4.4.
Kafka 2.1.0 tot 2.1.1
Kafka-versie wordt bijgewerkt van versie 2.1.0 naar 2.1.1.
In dit document vindt u de huidige onderdeelversies voor HDInsight 4.0 ad HDInsight 3.6
Bekende problemen
Probleem met Hive Warehouse Verbinding maken or
Er is een probleem met Hive Warehouse Verbinding maken or in deze release. De fix wordt opgenomen in de volgende release. Bestaande clusters die vóór deze release worden gemaakt, worden niet beïnvloed. Vermijd indien mogelijk het cluster te verwijderen en opnieuw te maken. Open het ondersteuningsticket als u meer hulp nodig hebt.
Releasedatum: 01-09-2020
Deze release is zowel van toepassing op HDInsight 3.6 als 4.0. HdInsight-release wordt gedurende meerdere dagen beschikbaar gesteld voor alle regio's. De releasedatum hier geeft de eerste releasedatum van de regio aan. Als u de volgende wijzigingen niet ziet, wacht u tot de release binnen enkele dagen live is in uw regio.
Nieuwe functies
TLS 1.2 afdwingen
Transport Layer Security (TLS) en Secure Sockets Layer (SSL) zijn cryptografische protocollen die communicatiebeveiliging bieden via een computernetwerk. Meer informatie over TLS. HDInsight maakt gebruik van TLS 1.2 op openbare HTTP-eindpunten, maar TLS 1.1 wordt nog steeds ondersteund voor achterwaartse compatibiliteit.
Met deze release kunnen klanten alleen kiezen voor TLS 1.2 voor alle verbindingen via het eindpunt van het openbare cluster. Ter ondersteuning hiervan wordt de nieuwe eigenschap minSupportedTlsVersion geïntroduceerd en kan worden opgegeven tijdens het maken van het cluster. Als de eigenschap niet is ingesteld, ondersteunt het cluster nog steeds TLS 1.0, 1.1 en 1.2, wat hetzelfde is als het gedrag van vandaag. Klanten kunnen de waarde voor deze eigenschap instellen op '1.2', wat betekent dat het cluster alleen TLS 1.2 en hoger ondersteunt. Zie Transport Layer Security voor meer informatie.
Bring Your Own Key voor schijfversleuteling
Alle beheerde schijven in HDInsight worden beveiligd met Azure Storage Service Encryption (SSE). Gegevens op deze schijven worden standaard versleuteld door door Microsoft beheerde sleutels. Vanaf deze release kunt u BYOK (Bring Your Own Key) gebruiken voor schijfversleuteling en deze beheren met behulp van Azure Key Vault. BYOK-versleuteling is een configuratie in één stap tijdens het maken van het cluster zonder andere kosten. Registreer HDInsight als een beheerde identiteit bij Azure Key Vault en voeg de versleutelingssleutel toe wanneer u uw cluster maakt. Zie Schijfversleuteling die door de klant wordt beheerd voor meer informatie.
Afschaffing
Geen afschaffingen voor deze release. Zie Toekomstige wijzigingen om u voor te bereiden op geplande afschaffingen.
Gedragswijzigingen
Er zijn geen gedragswijzigingen voor deze release. Zie Geplande wijzigingen om u voor te bereiden op toekomstige wijzigingen.
Toekomstige wijzigingen
De volgende wijzigingen worden doorgevoerd in toekomstige releases.
Afschaffing van Apache Spark 2.1 en 2.2 in HDInsight 3.6 Spark-cluster
Vanaf 1 juli 2020 kunnen klanten geen nieuwe Spark-clusters maken met Spark 2.1 en 2.2 op HDInsight 3.6. Bestaande clusters worden zonder ondersteuning van Microsoft uitgevoerd zoals ze zijn. Overweeg om de overstap naar Apache Spark 2.3 op HDInsight 3.6 voor 30 juni 2020 te maken om potentiële systeem- en ondersteuningsonderbrekingen te voorkomen.
Afschaffing van Apache Spark 2.3 in HDInsight 4.0 Spark-cluster
Vanaf 1 juli 2020 kunnen klanten geen nieuwe Spark-clusters maken met Spark 2.3 in HDInsight 4.0. Bestaande clusters worden zonder ondersteuning van Microsoft uitgevoerd zoals ze zijn. Overweeg om de overstap naar Apache Spark 2.4 op HDInsight 4.0 voor 30 juni 2020 te maken om potentiële systeem- en ondersteuningsonderbrekingen te voorkomen.
Afschaffing van Kafka 1.1 in HDInsight 4.0 Kafka-cluster
Vanaf 1 juli 2020 kunnen klanten geen nieuwe Kafka-clusters maken met Kafka 1.1 op HDInsight 4.0. Bestaande clusters worden zonder ondersteuning van Microsoft uitgevoerd zoals ze zijn. Overweeg om de overstap naar Kafka 2.1 op HDInsight 4.0 voor 30 juni 2020 te maken om potentiële systeem- en ondersteuningsonderbrekingen te voorkomen. Zie Workloads van Apache Kafka migreren naar Azure HDInsight 4.0 voor meer informatie.
HBase 2.0 tot 2.1.6
In de komende HDInsight 4.0-release wordt de HBase-versie bijgewerkt van versie 2.0 naar 2.1.6
Spark 2.4.0 tot 2.4.4
In de komende HDInsight 4.0-release wordt de Spark-versie bijgewerkt van versie 2.4.0 naar 2.4.4
Kafka 2.1.0 tot 2.1.1
In de komende HDInsight 4.0-release wordt de Kafka-versie bijgewerkt van versie 2.1.0 naar 2.1.1.
Er is minimaal een VM met 4 kernen vereist voor hoofdknooppunt
Er is minimaal 4 kern-VM's vereist voor hoofdknooppunten om de hoge beschikbaarheid en betrouwbaarheid van HDInsight-clusters te garanderen. Vanaf 6 april 2020 kunnen klanten alleen kiezen voor een vm met vier kernen of hoger als hoofdknooppunt voor de nieuwe HDInsight-clusters. Bestaande clusters blijven op de verwachte manier werken.
Grootte van ESP Spark-clusterknooppunt wijzigen
In de volgende release wordt de minimaal toegestane knooppuntgrootte voor ESP Spark-cluster gewijzigd in Standard_D13_V2. VM's uit de A-serie kunnen problemen met het ESP-cluster veroorzaken vanwege relatief lage CPU- en geheugencapaciteit. Vm's uit de A-serie worden afgeschaft voor het maken van nieuwe ESP-clusters.
Overstappen op virtuele-machineschaalsets van Azure
HDInsight maakt nu gebruik van virtuele Azure-machines om het cluster in te richten. In de komende release gebruikt HDInsight in plaats daarvan virtuele-machineschaalsets van Azure. Meer informatie over virtuele-machineschaalsets van Azure.
Bugfixes
HDInsight blijft de betrouwbaarheid en prestaties van clusters verbeteren.
Wijziging van onderdeelversie
Er is geen wijziging in de onderdeelversie voor deze release. Hier vindt u de huidige onderdeelversies voor HDInsight 4.0 ad HDInsight 3.6.
Releasedatum: 12-17-2019
Deze release is zowel van toepassing op HDInsight 3.6 als 4.0.
Nieuwe functies
Servicetags
Servicetags vereenvoudigen de beveiliging voor virtuele Azure-machines en virtuele Azure-netwerken door u in staat te stellen de netwerktoegang tot de Azure-services eenvoudig te beperken. U kunt servicetags in uw NSG-regels (netwerkbeveiligingsgroep) gebruiken om verkeer naar een specifieke Azure-service wereldwijd of per Azure-regio toe te staan of te weigeren. Azure biedt het onderhoud van IP-adressen die onder elke tag staan. HDInsight-servicetags voor netwerkbeveiligingsgroepen (NSG's) zijn groepen IP-adressen voor status- en beheerservices. Deze groepen helpen de complexiteit voor het maken van beveiligingsregels te minimaliseren. HDInsight-klanten kunnen servicetags inschakelen via Azure Portal, PowerShell en REST API. Zie servicetags voor netwerkbeveiligingsgroepen (NSG) voor Azure HDInsight voor meer informatie.
Aangepaste Ambari-database
Met HDInsight kunt u nu uw eigen SQL DB voor Apache Ambari gebruiken. U kunt deze aangepaste Ambari-database configureren vanuit Azure Portal of via een Resource Manager-sjabloon. Met deze functie kunt u de juiste SQL-database kiezen voor uw verwerkings- en capaciteitsbehoeften. U kunt ook eenvoudig upgraden om te voldoen aan de bedrijfsgroeivereisten. Zie HDInsight-clusters instellen met een aangepaste Ambari-database voor meer informatie.

Afschaffing
Geen afschaffingen voor deze release. Zie Toekomstige wijzigingen om u voor te bereiden op geplande afschaffingen.
Gedragswijzigingen
Er zijn geen gedragswijzigingen voor deze release. Als u zich wilt voorbereiden op toekomstige gedragswijzigingen, raadpleegt u Toekomstige wijzigingen.
Toekomstige wijzigingen
De volgende wijzigingen worden doorgevoerd in toekomstige releases.
Transport Layer Security (TLS) 1.2 afdwingen
Transport Layer Security (TLS) en Secure Sockets Layer (SSL) zijn cryptografische protocollen die communicatiebeveiliging bieden via een computernetwerk. Zie Transport Layer Security voor meer informatie. Hoewel Azure HDInsight-clusters TLS 1.2-verbindingen op openbare HTTPS-eindpunten accepteren, wordt TLS 1.1 nog steeds ondersteund voor achterwaartse compatibiliteit met oudere clients.
Vanaf de volgende release kunt u zich aanmelden en uw nieuwe HDInsight-clusters configureren om alleen TLS 1.2-verbindingen te accepteren.
Later in het jaar, vanaf 30-6-2020, dwingt Azure HDInsight TLS 1.2 of latere versies af voor alle HTTPS-verbindingen. We raden u aan om ervoor te zorgen dat al uw clients klaar zijn voor het verwerken van TLS 1.2 of nieuwere versies.
Overstappen op virtuele-machineschaalsets van Azure
HDInsight maakt nu gebruik van virtuele Azure-machines om het cluster in te richten. Vanaf februari 2020 (exacte datum wordt later gecommuniceerd), gebruikt HDInsight in plaats daarvan virtuele-machineschaalsets van Azure. Meer informatie over virtuele-machineschaalsets van Azure.
Grootte van ESP Spark-clusterknooppunt wijzigen
In de volgende release:
- De minimaal toegestane knooppuntgrootte voor ESP Spark-cluster wordt gewijzigd in Standard_D13_V2.
- VM's uit de A-serie worden afgeschaft voor het maken van nieuwe ESP-clusters, omdat VM's uit de A-serie problemen met het ESP-cluster kunnen veroorzaken vanwege relatief lage CPU- en geheugencapaciteit.
HBase 2.0 tot 2.1
In de komende HDInsight 4.0-release wordt de HBase-versie bijgewerkt van versie 2.0 naar 2.1.
Bugfixes
HDInsight blijft de betrouwbaarheid en prestaties van clusters verbeteren.
Wijziging van onderdeelversie
We hebben HDInsight 3.6-ondersteuning verlengd tot 31 december 2020. Meer informatie vindt u in ondersteunde HDInsight-versies.
Er is geen onderdeelversiewijziging voor HDInsight 4.0.
Apache Zeppelin in HDInsight 3.6: 0.7.0-->0.7.3.
U vindt de meest recente onderdeelversies uit dit document.
Nieuwe regio's
VAE - noord
De beheer-IP's van UAE - noord zijn: 65.52.252.96 en 65.52.252.97.
Releasedatum: 11-07-2019
Deze release is zowel van toepassing op HDInsight 3.6 als 4.0.
Nieuwe functies
HDInsight Identity Broker (HIB) (preview)
Met HDInsight Identity Broker (HIB) kunnen gebruikers zich aanmelden bij Apache Ambari met behulp van meervoudige verificatie (MFA) en de vereiste Kerberos-tickets ophalen zonder wachtwoordhashes te hoeven hebben in Azure Active Directory-domein Services (AAD-DS). Momenteel is HIB alleen beschikbaar voor clusters die zijn geïmplementeerd via een ARM-sjabloon (Azure Resource Management).
Kafka REST API-proxy (preview)
Kafka REST API-proxy biedt een implementatie met één klik van maximaal beschikbare REST-proxy met Kafka-cluster via beveiligde Azure AD-autorisatie en OAuth-protocol.
Automatisch schalen
Automatische schaalaanpassing voor Azure HDInsight is nu algemeen beschikbaar in alle regio's voor Apache Spark- en Hadoop-clustertypen. Met deze functie kunt u workloads voor big data-analyses op een rendabelere en productievere manier beheren. U kunt nu het gebruik van uw HDInsight-clusters optimaliseren en alleen betalen voor wat u nodig hebt.
Afhankelijk van uw vereisten kunt u kiezen tussen automatische schaalaanpassing op basis van belasting of op basis van planning. Automatisch schalen op basis van belasting kan de clustergrootte omhoog en omlaag schalen op basis van de huidige resourcebehoeften, terwijl automatisch schalen op basis van een planning de clustergrootte kan wijzigen op basis van een vooraf gedefinieerd schema.
Ondersteuning voor automatische schaalaanpassing voor HBase- en LLAP-werkbelasting is ook een openbare preview. Zie Azure HDInsight-clusters automatisch schalen voor meer informatie.
Versnelde schrijfbewerkingen voor HDInsight voor Apache HBase
Voor verbeterde schrijfbewerkingen worden beheerde Azure Premium SSD-schijven gebruikt om de prestaties van het Apache HBase Write Ahead Log (WAL) te verbeteren. Zie Verbeterde schrijfbewerkingen van Azure HDInsight voor Apache HBase voor meer informatie.
Aangepaste Ambari-database
HDInsight biedt nu een nieuwe capaciteit waarmee klanten hun eigen SQL DB voor Ambari kunnen gebruiken. Klanten kunnen nu de juiste SQL DB voor Ambari kiezen en deze eenvoudig upgraden op basis van hun eigen bedrijfsgroeivereiste. De implementatie wordt uitgevoerd met een Azure Resource Manager-sjabloon. Zie HDInsight-clusters instellen met een aangepaste Ambari-database voor meer informatie.
Virtuele machines uit de F-serie zijn nu beschikbaar met HDInsight
Virtuele machines uit de F-serie (VM's) is een goede keuze om aan de slag te gaan met HDInsight met vereisten voor lichte verwerking. Tegen een lagere prijs per uur zijn de F-serie de beste prijs-prestaties in de Azure-portfolio op basis van de ACU (Azure Compute Unit) per vCPU. Zie De juiste VM-grootte voor uw Azure HDInsight-cluster selecteren voor meer informatie.
Afschaffing
Afschaffing van virtuele machines uit de G-serie
Vanaf deze release worden VM's uit de G-serie niet meer aangeboden in HDInsight.
Dv1 afschaffing van virtuele machines
Vanaf deze release wordt het gebruik van Dv1 VM's met HDInsight afgeschaft. Elke klantaanvraag Dv1 wordt automatisch verwerkt Dv2 . Er is geen prijsverschil tussen Dv1 en Dv2 VM's.
Gedragswijzigingen
Grootte van beheerde clusterschijf wijzigen
HDInsight biedt beheerde schijfruimte met het cluster. Vanaf deze release wordt de grootte van elke beheerde schijf van elk knooppunt in het nieuwe gemaakte cluster gewijzigd in 128 GB.
Toekomstige wijzigingen
De volgende wijzigingen worden doorgevoerd in de komende releases.
Overstappen op virtuele-machineschaalsets van Azure
HDInsight maakt nu gebruik van virtuele Azure-machines om het cluster in te richten. Vanaf december gebruikt HDInsight in plaats daarvan virtuele-machineschaalsets van Azure. Meer informatie over virtuele-machineschaalsets van Azure.
HBase 2.0 tot 2.1
In de komende HDInsight 4.0-release wordt de HBase-versie bijgewerkt van versie 2.0 naar 2.1.
Afschaffing van virtuele machines uit de A-serie voor ESP-cluster
VM's uit de A-serie kunnen problemen met het ESP-cluster veroorzaken vanwege relatief lage CPU- en geheugencapaciteit. In de volgende release worden VM's uit de A-serie afgeschaft voor het maken van nieuwe ESP-clusters.
Bugfixes
HDInsight blijft de betrouwbaarheid en prestaties van clusters verbeteren.
Wijziging van onderdeelversie
Er is geen wijziging in de onderdeelversie voor deze release. Hier vindt u de huidige onderdeelversies voor HDInsight 4.0 en HDInsight 3.6.
Releasedatum: 08-07-2019
Onderdeelversies
Hieronder ziet u de officiële Apache-versies van alle HDInsight 4.0-onderdelen. De vermelde onderdelen zijn releases van de meest recente stabiele versies die beschikbaar zijn.
- Apache Ambari 2.7.1
- Apache Hadoop 3.1.1
- Apache HBase 2.0.0
- Apache Hive 3.1.0
- Apache Kafka 1.1.1, 2.1.0
- Apache Mahout 0.9.0+
- Apache Oozie 4.2.0
- Apache Phoenix 4.7.0
- Apache Pig 0.16.0
- Apache Ranger 0.7.0
- Apache Slider 0.92.0
- Apache Spark 2.3.1, 2.4.0
- Apache Sqoop 1.4.7
- Apache TEZ 0.9.1
- Apache Zeppelin 0.8.0
- Apache ZooKeeper 3.4.6
Latere versies van Apache-onderdelen worden soms gebundeld in de HDP-distributie, naast de bovenstaande versies. In dit geval worden deze latere versies vermeld in de tabel Technical Previews en moeten ze niet worden vervangen door de versies van het Apache-onderdeel van de bovenstaande lijst in een productieomgeving.
Informatie over Apache-patches
Zie de patchvermelding voor elk product in de onderstaande tabel voor meer informatie over patches die beschikbaar zijn in HDInsight 4.0.
| Productnaam | Patchinformatie |
|---|---|
| Ambari | Informatie over Ambari-patches |
| Hadoop | Informatie over Hadoop-patch |
| HBase | Informatie over HBase-patch |
| Hive | Deze release biedt Hive 3.1.0 zonder Apache-patches. |
| Kafka | Deze release biedt Kafka 1.1.1 zonder Apache-patches meer. |
| Oozie | Informatie over Oozie-patches |
| Phoenix | Informatie over Phoenix-patch |
| Pig | Informatie over varkenspatch |
| Ranger | Informatie over ranger-patches |
| Spark | Informatie over Spark-patch |
| Sqoop | Deze release biedt Sqoop 1.4.7 zonder Apache-patches meer. |
| Tez | Deze release biedt Tez 0.9.1 zonder Apache-patches meer. |
| Zeppelin | Deze release biedt Zeppelin 0.8.0 zonder Apache-patches meer. |
| Zookeeper | Informatie over Zookeeper-patch |
Veelvoorkomende beveiligingsproblemen en blootstellingen opgelost
Zie Hortonworks's Fixed Common Vulnerabilities and Exposures for HDP 3.0.1 (Veelvoorkomende beveiligingsproblemen en blootstellingen voor HDP 3.0.1) voor meer informatie over beveiligingsproblemen die in deze release zijn opgelost.
Bekende problemen
Replicatie is verbroken voor Secure HBase met standaardinstallatie
Voor HDInsight 4.0 voert u de volgende stappen uit:
Schakel communicatie tussen clusters in.
Meld u aan bij het actieve hoofdknooppunt.
Download een script om replicatie in te schakelen met de volgende opdracht:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shTyp de opdracht
sudo kinit <domainuser>.Typ de volgende opdracht om het script uit te voeren:
sudo bash hdi_enable_replication.sh -m <hn*> -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
Voor HDInsight 3.6
Meld u aan bij actieve HMaster ZK.
Download een script om replicatie in te schakelen met de volgende opdracht:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shTyp de opdracht
sudo kinit -k -t /etc/security/keytabs/hbase.service.keytab hbase/<FQDN>@<DOMAIN>.Typ de volgende opdracht:
sudo bash hdi_enable_replication.sh -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
Phoenix Sqlline werkt niet meer nadat het HBase-cluster is gemigreerd naar HDInsight 4.0
Voer de volgende stappen uit:
- Verwijder de volgende Phoenix-tabellen:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.MUTEXSYSTEM.CATALOG
- Als u een van de tabellen niet kunt verwijderen, start u HBase opnieuw om verbindingen met de tabellen te wissen.
- Voer
sqlline.pyopnieuw uit. Phoenix maakt alle tabellen die zijn verwijderd in stap 1 opnieuw. - Genereer Phoenix-tabellen en -weergaven opnieuw voor uw HBase-gegevens.
Phoenix Sqlline werkt niet meer na het repliceren van HBase Phoenix-metagegevens van HDInsight 3.6 naar 4.0
Voer de volgende stappen uit:
- Voordat u de replicatie uitvoert, gaat u naar het doel 4.0-cluster en voert u deze uit
sqlline.py. Met deze opdracht worden Phoenix-tabellen gegenereerd zoalsSYSTEM.MUTEXenSYSTEM.LOGdie alleen bestaan in 4.0. - Verwijder de volgende tabellen:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.CATALOG
- De HBase-replicatie starten
Afschaffing
Apache Storm- en ML-services zijn niet beschikbaar in HDInsight 4.0.
Releasedatum: 14-04-2019
Nieuwe functies
De nieuwe updates en mogelijkheden vallen in de volgende categorieën:
Hadoop en andere opensource-projecten bijwerken: naast 1000+ bugfixes voor meer dan 20 opensource-projecten bevat deze update een nieuwe versie van Spark (2.3) en Kafka (1.0).
R Server 9.1 bijwerken naar Machine Learning Services 9.3 : met deze release bieden we gegevenswetenschappers en technici het beste van open source dat is verbeterd met algoritme-innovaties en het gemak van operationalisatie, die allemaal beschikbaar zijn in hun voorkeurstaal met de snelheid van Apache Spark. Deze release breidt uit op de mogelijkheden die worden aangeboden in R Server met toegevoegde ondersteuning voor Python, wat leidt tot de wijziging van de clusternaam van R Server naar ML Services.
Ondersteuning voor Azure Data Lake Storage Gen2 – HDInsight biedt ondersteuning voor de preview-versie van Azure Data Lake Storage Gen2. In de beschikbare regio's kunnen klanten een ADLS Gen2-account kiezen als primair of secundair archief voor hun HDInsight-clusters.
HdInsight Enterprise Security Package Updates (preview) – (preview) Ondersteuning voor service-eindpunten voor virtuele netwerken voor Azure Blob Storage, ADLS Gen1, Azure Cosmos DB en Azure DB.
Onderdeelversies
Hieronder vindt u de officiële Apache-versies van alle HDInsight 3.6-onderdelen. Alle hier vermelde onderdelen zijn officiële Apache-releases van de meest recente stabiele versies die beschikbaar zijn.
Apache Hadoop 2.7.3
Apache HBase 1.1.2
Apache Hive 1.2.1
Apache Hive 2.1.0
Apache Kafka 1.0.0
Apache Mahout 0.9.0+
Apache Oozie 4.2.0
Apache Phoenix 4.7.0
Apache Pig 0.16.0
Apache Ranger 0.7.0
Apache Slider 0.92.0
Apache Spark 2.2.0/2.3.0
Apache Sqoop 1.4.6
Apache Storm 1.1.0
Apache TEZ 0.7.0
Apache Zeppelin 0.7.3
Apache ZooKeeper 3.4.6
Latere versies van een paar Apache-onderdelen worden soms gebundeld in de HDP-distributie, naast de bovenstaande versies. In dit geval worden deze latere versies vermeld in de tabel Technical Previews en moeten ze niet worden vervangen door de versies van het Apache-onderdeel van de bovenstaande lijst in een productieomgeving.
Informatie over Apache-patches
Hadoop
Deze release biedt Hadoop Common 2.7.3 en de volgende Apache-patches:
HADOOP-13190: Vermeld LoadBalancingKMSClientProvider in de KMS HA-documentatie.
HADOOP-13227: AsyncCallHandler moet een gebeurtenisgestuurde architectuur gebruiken om asynchrone aanroepen af te handelen.
HADOOP-14104: Client moet altijd een naamknooppunt vragen voor het kms-providerpad.
HADOOP-14799: Werk nimbus-jose-jwt bij naar 4.41.1.
HADOOP-14814: Een incompatibele API-wijziging in FsServerDefaults in HADOOP-14104 oplossen.
HADOOP-14903: voeg json-smart expliciet toe aan pom.xml.
HADOOP-15042: Azure PageBlobInputStream.skip() kan een negatieve waarde retourneren wanneer numberOfPagesRemaining 0 is.
HADOOP-15255: ondersteuning voor conversie van hoofdletters/kleine letters voor groepsnamen in LdapGroupsMapping.
HADOOP-15265: sluit json-smart expliciet uit van hadoop-auth pom.xml.
HDFS-7922: ShortCircuitCache#close brengt ScheduledThreadPoolExecutors niet uit.
HDFS-8496: Aanroepen van stopWriter() met FSDatasetImpl-vergrendeling kan andere threads (cmccabe) blokkeren.
HDFS-10267: Extra "gesynchroniseerd" op FsDatasetImpl#recoverAppend en FsDatasetImpl#recoverClose.
HDFS-10489: afgeschaft dfs.encryption.key.provider.uri voor HDFS-versleutelingszones.
HDFS-11384: Voeg de optie voor balancer toe om getBlocks-aanroepen te verspreiden om de rpc van NameNode te voorkomen. CallQueueLength-piek.
HDFS-11689: Nieuwe uitzondering die wordt gegenereerd door
DFSClient%isHDFSEncryptionEnabledde hive-code die is verbrokenhacky.HDFS-11711: DN mag het blok niet verwijderen op 'Te veel geopende bestanden' Uitzondering.
HDFS-12347: TestBalancerRPCDelay#testBalancerRPCDelay mislukt regelmatig.
HDFS-12781: Na
DatanodedownNamenode, genereert het tabblad UiDatanodeeen waarschuwingsbericht.HDFS-13054: PathIsNotEmptyDirectoryException verwerken in
DFSClientverwijderaanroep.HDFS-13120: Diff van momentopnamen kan na samenvoegen beschadigd raken.
YARN-3742: YARN RM wordt afgesloten als
ZKClienter een time-out optreedt bij het maken.YARN-6061: Voeg een UncaughtExceptionHandler toe voor kritieke threads in RM.
YARN-7558: de opdracht yarn-logboeken kan geen logboeken ophalen voor actieve containers als UI-verificatie is ingeschakeld.
YARN-7697: Logboeken ophalen voor voltooide toepassing mislukt, ook al is logboekaggregatie voltooid.
HDP 2.6.4 biedt Hadoop Common 2.7.3 en de volgende Apache-patches:
HADOOP-13700: Verwijder onthrown
IOExceptionuit TrashPolicy#initialiseer en #getInstance handtekeningen.HADOOP-13709: Mogelijkheid om subprocessen op te schonen die door Shell zijn voortgekomen wanneer het proces wordt afgesloten.
HADOOP-14059: typfout in
s3ahet foutbericht rename(self, subdir).HADOOP-14542: VOEG IOUtils.cleanupWithLogger toe die slf4j logger-API accepteert.
HDFS-9887: Time-outs voor webhdfs-sockets moeten kunnen worden geconfigureerd.
HDFS-9914: Configureerbare time-out voor webhDFS-verbinding/leesbewerking opgelost.
MAPREDUCE-6698: Time-out verhogen op TestUnnecessaryBlockingOnHist oryFileInfo.testTwoThreadsQueryingDifferentJobOfSameUser.
YARN-4550: Sommige tests in TestContainerLanch mislukken in een niet-Engelse landinstellingsomgeving.
YARN-4717: TestResourceLocalizationService.testPublicResourceInitializesLocalDir mislukt af en toe vanwege IllegalArgumentException van opschoning.
YARN-5042: Koppel /sys/fs/cgroup aan Docker-containers als alleen-lezenkoppeling.
YARN-5318: Er is een onregelmatige testfout opgelost van TestRM Beheer Service#te stRefreshNodesResourceWithFileSystemBasedConfigurationProvider.
YARN-5641: Localizer laat tarballen achter nadat de container is voltooid.
YARN-6004: Herstructureer TestResourceLocalizationService#testDownloadingResourcesOnContainer zodat deze minder dan 150 regels is.
YARN-6078: Containers die vastzitten in de lokalisatiestatus.
YARN-6805: NPE in LinuxContainerExecutor vanwege null PrivilegedOperationException-afsluitcode.
HBase
Deze release biedt HBase 1.1.2 en de volgende Apache-patches.
HBASE-13376: Verbeteringen aan Stochastic load balancer.
HBASE-13716: Stop met het gebruik van FSConstants van Hadoop.
HBASE-13848: Toegang tot SSL-wachtwoorden voor InfoServer via referentieprovider-API.
HBASE-13947: Gebruik MasterServices in plaats van Server in AssignmentManager.
HBASE-14135: HBase-back-up/herstelfase 3: Back-upinstallatiekopieën samenvoegen.
HBASE-14473: De landinstelling van de rekenregio wordt parallel berekend.
HBASE-14517: Versie weergeven
regionserver'sop basisstatuspagina.HBASE-14606: TestSecureLoadIncrementalHFiles test heeft een time-out opgetreden in trunk-build op Apache.
HBASE-15210: Maak agressieve load balancer-logboekregistratie ongedaan op tientallen regels per milliseconde.
HBASE-15515: LocalityBasedCandidateGenerator verbeteren in Balancer.
HBASE-15615: Verkeerde slaaptijd wanneer
RegionServerCallableu het opnieuw moet proberen.HBASE-16135: PeerClusterZnode onder rs van verwijderde peer kan nooit worden verwijderd.
HBASE-16570: Locality van de rekenregio parallel bij het opstarten.
HBASE-16810: HBase Balancer genereert ArrayIndexOutOfBoundsException wanneer
regionserverszich in /hbase/draining znode bevindt en wordt verwijderd.HBASE-16852: TestDefaultCompactSelection is mislukt op branch-1.3.
HBASE-17387: Verminder de overhead van uitzonderingsrapport in RegionActionResult voor multi().
HBASE-17850: Hulpprogramma voor systeemherstel van back-up.
HBASE-17931: Systeemtabellen toewijzen aan servers met de hoogste versie.
HBASE-18083: Maak een groot/klein threadnummer dat kan worden geconfigureerd in HFileCleaner.
HBASE-18084: Improve CleanerChore to clean from directory, which consumes more disk space.
HBASE-18164: Veel snellere kostenfunctie voor lokaliteit en kandidaatgenerator.
HBASE-18212: In zelfstandige modus met lokaal bestandssysteem HBase-logboeken Waarschuwingsbericht: Kan methode unbuffer niet aanroepen in klasse org.apache.hadoop.fs.FSDataInputStream.
HBASE-18808: Ineffectieve configuratiecontrole in BackupLogCleaner#getDeletableFiles().
HBASE-19052: FixedFileTrailer moet de klasse CellComparatorImpl herkennen in branch-1.x.
HBASE-19065: HRegion#bulkLoadHFiles() moet wachten tot gelijktijdige Region#flush() is voltooid.
HBASE-19285: Histogrammen per tabel toevoegen.
HBASE-19393: HTTP 413 FULL head tijdens het openen van de HBase-gebruikersinterface met SSL.
HBASE-19395: [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting mislukt met NPE.
HBASE-19421: branch-1 compileert niet met Hadoop 3.0.0.
HBASE-19934: HBaseSnapshotException wanneer leesreplica's zijn ingeschakeld en er wordt een onlinemomentopname gemaakt na het splitsen van de regio.
HBASE-20008: [backport] NullPointerException bij het herstellen van een momentopname na het splitsen van een regio.
Hive
Deze release biedt Naast de volgende patches ook Hive 1.2.1 en Hive 2.1.0:
Apache-patches voor Hive 1.2.1:
HIVE-10697: ObjectInspectorConvertors#UnionConvertor voert een foutieve conversie uit.
HIVE-11266: het verkeerde resultaat tellen(*) op basis van tabelstatistieken voor externe tabellen.
HIVE-12245: ondersteuning voor kolomopmerkingen voor een tabel met HBase-ondersteuning.
HIVE-12315: Fix Vectorized double divide by zero.
HIVE-12360: Slecht zoeken in ongecomprimeerde ORC met predicaat pushdown.
HIVE-12378: Uitzondering op HBaseSerDe.serialiseer binair veld.
HIVE-12785: Weergave met samenvoegtype en UDF aan de struct is verbroken.
HIVE-14013: De tabel beschrijven geeft unicode niet goed weer.
HIVE-14205: Hive biedt geen ondersteuning voor samenvoegingstype met AVRO-bestandsindeling.
HIVE-14421: FS.deleteOnExit bevat verwijzingen naar _tmp_space.db bestanden.
HIVE-15563: Uitzondering voor overgang van status ongeldige bewerking negeren in SQLOperation.runQuery om echte uitzonderingen weer te geven.
HIVE-15680: Onjuiste resultaten wanneer hive.optimize.index.filter=true en dezelfde ORC-tabel twee keer wordt verwezen in de query, in de MR-modus.
HIVE-15883: HBase toegewezen tabel in Hive invoegen mislukt voor decimalen.
HIVE-16232: Ondersteuning voor statistiekenberekening voor kolommen in QuotedIdentifier.
HIVE-16828: Als CBO is ingeschakeld, genereert Query op gepartitioneerde weergaven IndexOutOfBoundException.
HIVE-17013: Aanvraag verwijderen met een subquery op basis van selectie over een weergave.
HIVE-17063: overschrijfpartitie invoegen in een externe tabel mislukt wanneer de partitie eerst wordt verwijderd.
HIVE-17259: Hive JDBC herkent geen UNIONTYPE-kolommen.
HIVE-17419: TABEL ANALYSEREN... De opdracht COMPUTE STATISTICS FOR COLUMNS toont berekende statistieken voor gemaskeerde tabellen.
HIVE-17530: ClassCastException bij het
uniontypeconverteren.HIVE-17621: Hive-site-instellingen worden genegeerd tijdens de split-calculation van HCatInputFormat.
HIVE-17636: Voeg multiple_agg.q-test toe voor
blobstores.HIVE-17729: Database toevoegen en gerelateerde blobstore-tests uitleggen.
HIVE-17731: voeg een achterwaartse
compatoptie toe voor externe gebruikers aan HIVE-11985.HIVE-17803: Met Pig multiquery zullen 2 HCatStorers die naar dezelfde tabel schrijven elkaars uitvoer vertrappen.
HIVE-17829: ArrayIndexOutOfBoundsException - HBASE-ondersteunde tabellen met Avro-schema in
Hive2.HIVE-17845: invoegen mislukt als doeltabelkolommen niet kleine letters bevatten.
HIVE-17900: analyseer statistieken over kolommen die door Compactor worden geactiveerd, genereert ongeldige SQL met > één partitiekolom.
HIVE-18026: Configuratieoptimalisatie van Hive-webhcat-principal.
HIVE-18031: ondersteuning voor replicatie voor de bewerking Alter Database.
HIVE-18090: acid heartbeat mislukt wanneer metastore is verbonden via hadoop-referentie.
HIVE-18189: Hive-query retourneert verkeerde resultaten bij het instellen van hive.groupby.position.alias op true.
HIVE-18258: Vectorization: Reduce-Side GROUP BY MERGEPARTIAL with duplicate columns is broken.
HIVE-18293: Hive kan geen tabellen comprimeren die zijn opgenomen in een map die niet eigendom is van de identiteit waarop HiveMetaStore wordt uitgevoerd.
HIVE-18327: Verwijder de onnodige HiveConf-afhankelijkheid voor MiniHiveKdc.
HIVE-18341: voeg ondersteuning voor repl-belasting toe voor het toevoegen van 'onbewerkte' naamruimte voor TDE met dezelfde versleutelingssleutels.
HIVE-18352: introduceer een METADATAONLY-optie tijdens het uitvoeren van REPL DUMP om integraties van andere hulpprogramma's toe te staan.
HIVE-18353: CompactorMR moet jobclient.close() aanroepen om opschoning te activeren.
HIVE-18390: IndexOutOfBoundsException bij het uitvoeren van een query op een gepartitioneerde weergave in ColumnPruner.
HIVE-18429: Compressie moet een case verwerken wanneer deze geen uitvoer produceert.
HIVE-18447: JDBC: Een manier bieden voor JDBC-gebruikers om cookiegegevens door te geven via verbindingsreeks.
HIVE-18460: De compressiefunctie geeft geen tabeleigenschappen door aan de Orc-schrijver.
HIVE-18467: ondersteuning voor hele magazijndump / load + create/drop database-gebeurtenissen (Anishek Agarwal, beoordeeld door Sankar Hariappan).
HIVE-18551: VectorIzation: VectorMapOperator probeert te veel vectorkolommen te schrijven voor Hybrid Grace.
HIVE-18587: het invoegen van een DML-gebeurtenis kan proberen om een controlesom in mappen te berekenen.
HIVE-18613: JsonSerDe uitbreiden ter ondersteuning van binair type.
HIVE-18626: Herpl load "with" component geeft geen configuratie door aan taken.
HIVE-18660: PCR maakt geen onderscheid tussen partitie- en virtuele kolommen.
HIVE-18754: REPL STATUS moet ondersteuning bieden voor de component 'with'.
HIVE-18754: REPL STATUS moet ondersteuning bieden voor de component 'with'.
HIVE-18788: Invoer opschonen in JDBC PreparedStatement.
HIVE-18794: Herpl load "with" component geeft geen configuratie door aan taken voor niet-partitietabellen.
HIVE-18808: compressie krachtiger maken wanneer de update van statistieken mislukt.
HIVE-18817: ArrayIndexOutOfBounds-uitzondering tijdens het lezen van de ACID-tabel.
HIVE-18833: Automatisch samenvoegen mislukt wanneer 'invoegen in map als orcfile'.
HIVE-18879: Ingesloten element in UDFXPathUtil niet inschakelen, moet werken als xercesImpl.jar in het klaspad.
HIVE-18907: Maak een hulpprogramma voor het oplossen van probleem met de acid-sleutelindex van HIVE-18817.
Hive 2.1.0 Apache Patches:
HIVE-14013: De tabel beschrijven geeft unicode niet goed weer.
HIVE-14205: Hive biedt geen ondersteuning voor samenvoegingstype met AVRO-bestandsindeling.
HIVE-15563: Uitzondering voor overgang van status ongeldige bewerking negeren in SQLOperation.runQuery om echte uitzonderingen weer te geven.
HIVE-15680: Onjuiste resultaten wanneer hive.optimize.index.filter=true en dezelfde ORC-tabel twee keer wordt verwezen in de query, in de MR-modus.
HIVE-15883: HBase toegewezen tabel in Hive invoegen mislukt voor decimalen.
HIVE-16757: Verwijder aanroepen naar afgeschafte AbstractRelNode.getRows.
HIVE-16828: Als CBO is ingeschakeld, genereert Query op gepartitioneerde weergaven IndexOutOfBoundException.
HIVE-17063: overschrijfpartitie invoegen in een externe tabel mislukt wanneer de partitie eerst wordt verwijderd.
HIVE-17259: Hive JDBC herkent geen UNIONTYPE-kolommen.
HIVE-17530: ClassCastException bij het
uniontypeconverteren.HIVE-17600: Maak de enforceBufferSize user-settable van OrcFile.
HIVE-17601: foutafhandeling verbeteren in LlapServiceDriver.
HIVE-17613: verwijder objectgroepen voor korte toewijzingen van dezelfde threads.
HIVE-17617: Rollup van een lege resultatenset moet de groepering van de lege groeperingsset bevatten.
HIVE-17621: Hive-site-instellingen worden genegeerd tijdens de split-calculation van HCatInputFormat.
HIVE-17629: CachedStore: een goedgekeurde/niet-goedgekeurde configuratie hebben om selectieve caching van tabellen/partities toe te staan en lezen toe te staan tijdens het voorwarmen.
HIVE-17636: Voeg multiple_agg.q-test toe voor
blobstores.HIVE-17702: onjuiste verwerking van verwerking in decimale lezer in ORC.
HIVE-17729: Database toevoegen en gerelateerde blobstore-tests uitleggen.
HIVE-17731: voeg een achterwaartse
compatoptie toe voor externe gebruikers aan HIVE-11985.HIVE-17803: Met Pig multiquery zullen 2 HCatStorers die naar dezelfde tabel schrijven elkaars uitvoer vertrappen.
HIVE-17845: invoegen mislukt als doeltabelkolommen niet kleine letters bevatten.
HIVE-17900: analyseer statistieken over kolommen die door Compactor worden geactiveerd, genereert ongeldige SQL met > één partitiekolom.
HIVE-18006: Geheugenvoetafdruk van HLLDenseRegister optimaliseren.
HIVE-18026: Configuratieoptimalisatie van Hive-webhcat-principal.
HIVE-18031: ondersteuning voor replicatie voor de bewerking Alter Database.
HIVE-18090: acid heartbeat mislukt wanneer metastore is verbonden via hadoop-referentie.
HIVE-18189: Volgorde op positie werkt niet wanneer
cbodeze is uitgeschakeld.HIVE-18258: Vectorization: Reduce-Side GROUP BY MERGEPARTIAL with duplicate columns is broken.
HIVE-18269: LLAP: Snelle
llapio met pijplijn voor trage verwerking kan leiden tot OOM.HIVE-18293: Hive kan geen tabellen comprimeren die zijn opgenomen in een map die niet eigendom is van de identiteit waarop HiveMetaStore wordt uitgevoerd.
HIVE-18318: LLAP-recordlezer moet de interrupt controleren, zelfs wanneer deze niet wordt geblokkeerd.
HIVE-18326: LLAP Tez scheduler - alleen taken voorbereiden als er een afhankelijkheid tussen deze taken is.
HIVE-18327: Verwijder de onnodige HiveConf-afhankelijkheid voor MiniHiveKdc.
HIVE-18331: Voeg opnieuw aanmelden toe wanneer TGT verloopt en een aantal logboekregistratie/lambda.
HIVE-18341: voeg ondersteuning voor repl-belasting toe voor het toevoegen van 'onbewerkte' naamruimte voor TDE met dezelfde versleutelingssleutels.
HIVE-18352: introduceer een METADATAONLY-optie tijdens het uitvoeren van REPL DUMP om integraties van andere hulpprogramma's toe te staan.
HIVE-18353: CompactorMR moet jobclient.close() aanroepen om opschoning te activeren.
HIVE-18384: ConcurrentModificationException in
log4j2.xbibliotheek.HIVE-18390: IndexOutOfBoundsException bij het uitvoeren van een query op een gepartitioneerde weergave in ColumnPruner.
HIVE-18447: JDBC: Een manier bieden voor JDBC-gebruikers om cookiegegevens door te geven via verbindingsreeks.
HIVE-18460: De compressiefunctie geeft geen tabeleigenschappen door aan de Orc-schrijver.
HIVE-18462: (Uitleg die is opgemaakt voor query's met toewijzingsdeelname heeft columnExprMap met niet-opgemaakte kolomnaam).
HIVE-18467: ondersteuning voor hele magazijndump /load + databasegebeurtenissen maken/neerzetten.
HIVE-18488: LLAP ORC-lezers missen enkele null-controles.
HIVE-18490: Query met EXISTS en NOT EXISTS met niet-equi predicaat kan een onjuist resultaat opleveren.
HIVE-18506: LlapBaseInputFormat - negatieve matrixindex.
HIVE-18517: Vectorization: Fix VectorMapOperator to accept VRBs and check vectorized flag correct to support LLAP Caching).
HIVE-18523: Samenvattingsrij herstellen voor het geval er geen invoer is.
HIVE-18528: Statistische statistieken in ObjectStore krijgen het verkeerde resultaat.
HIVE-18530: Replicatie moet mm-tabel overslaan (voorlopig).
HIVE-18548: Import herstellen
log4j.HIVE-18551: VectorIzation: VectorMapOperator probeert te veel vectorkolommen te schrijven voor Hybrid Grace.
HIVE-18577: SemanticAnalyzer.validate heeft enkele pointless metastore-aanroepen.
HIVE-18587: het invoegen van een DML-gebeurtenis kan proberen om een controlesom in mappen te berekenen.
HIVE-18597: LLAP: Pak altijd het
log4j2API-JAR-bestand voororg.apache.log4j.HIVE-18613: JsonSerDe uitbreiden ter ondersteuning van binair type.
HIVE-18626: Herpl load "with" component geeft geen configuratie door aan taken.
HIVE-18643: controleer niet op gearchiveerde partities voor ACID-ops.
HIVE-18660: PCR maakt geen onderscheid tussen partitie- en virtuele kolommen.
HIVE-18754: REPL STATUS moet ondersteuning bieden voor de component 'with'.
HIVE-18788: Invoer opschonen in JDBC PreparedStatement.
HIVE-18794: Herpl load "with" component geeft geen configuratie door aan taken voor niet-partitietabellen.
HIVE-18808: compressie krachtiger maken wanneer de update van statistieken mislukt.
HIVE-18815: Verwijder ongebruikte functie in HPL/SQL.
HIVE-18817: ArrayIndexOutOfBounds-uitzondering tijdens het lezen van de ACID-tabel.
HIVE-18833: Automatisch samenvoegen mislukt wanneer 'invoegen in map als orcfile'.
HIVE-18879: Ingesloten element in UDFXPathUtil niet inschakelen, moet werken als xercesImpl.jar in het klaspad.
HIVE-18944: De positie van groeperingssets wordt onjuist ingesteld tijdens DPP.
Kafka
Deze release biedt Kafka 1.0.0 en de volgende Apache-patches.
KAFKA-4827: Kafka connect: error with special characters in connector name.
KAFKA-6118: Tijdelijke fout in kafka.api.SaslScramSslEndToEndAuthorizationTest.testTwoConsumersWithDifferentSaslCredentials.
KAFKA-6156: JmxReporter kan mappaden in Windows-stijl niet verwerken.
KAFKA-6164: ClientQuotaManager-threads voorkomen afsluiten wanneer er een fout optreedt bij het laden van logboeken.
KAFKA-6167: Timestamp op streams-map bevat een dubbele punt, een ongeldig teken.
KAFKA-6179: RecordQueue.clear() wist de onderhouden lijst van MinTimestampTracker niet.
KAFKA-6185: Selector geheugenlek met een hoge kans op OOM als er een downconversie is.
KAFKA-6190: GlobalKTable voltooit het herstellen nooit wanneer transactionele berichten worden gebruikt.
KAFKA-6210: IllegalArgumentException als 1.0.0 wordt gebruikt voor inter.broker.protocol.version of log.message.format.version. version.
KAFKA-6214: Het gebruik van stand-byreplica's met een opslag in de geheugenstatus zorgt ervoor dat Streams vastlopen.
KAFKA-6215: KafkaStreamsTest mislukt in trunk.
KAFKA-6238: problemen met protocolversie bij het toepassen van een rolling upgrade op 1.0.0.
KAFKA-6260: AbstractCoordinator verwerkt null-uitzondering niet duidelijk.
KAFKA-6261: Logboekregistratie aanvragen genereert uitzondering als acks=0.
KAFKA-6274: De namen van het bronstatusarchief verbeteren
KTable.
Mahout
In HDP-2.3.x en 2.4.x, in plaats van een specifieke Apache-versie van Mahout te verzenden, hebben we gesynchroniseerd met een bepaald revisiepunt op Apache Mahout trunk. Dit revisiepunt is na de release 0.9.0, maar vóór de release 0.10.0. Dit biedt een groot aantal bugfixes en functionele verbeteringen ten opzichte van de release 0.9.0, maar biedt een stabiele release van de Mahout-functionaliteit voordat de volledige conversie naar nieuwe Spark-gebaseerde Mahout in 0.10.0.
Het revisiepunt dat is gekozen voor Mahout in HDP 2.3.x en 2.4.x is afkomstig van de vertakking 'mahout-0.10.x' van Apache Mahout, vanaf 19 december 2014, revisie 0f037cb03e77c096 in GitHub.
In HDP-2.5.x en 2.6.x hebben we de bibliotheek commons-httpclient verwijderd uit Mahout omdat we deze als een verouderde bibliotheek met mogelijke beveiligingsproblemen bekijken en de Hadoop-Client in Mahout upgraden naar versie 2.7.3, dezelfde versie die wordt gebruikt in HDP-2.5. Als gevolg hiervan:
Eerder gecompileerde Mahout-taken moeten opnieuw worden gecompileerd in de HDP-2.5- of 2.6-omgeving.
Er is een kleine mogelijkheid dat sommige Mahout-taken fouten 'ClassNotFoundException' of 'kan klasse niet laden' optreden met betrekking tot org.apache.commons.httpclient, 'net.java.dev.jets3t' of gerelateerde klassenaamvoorvoegsels. Als deze fouten optreden, kunt u overwegen of u de benodigde JAR's handmatig wilt installeren in uw klaspad voor de taak, als het risico op beveiligingsproblemen in de verouderde bibliotheek acceptabel is in uw omgeving.
Er is een nog kleinere mogelijkheid dat sommige Mahout-taken crashes kunnen tegenkomen in de hbase-clientcodeaanroepen van Mahout naar de hadoop-common bibliotheken, vanwege binaire compatibiliteitsproblemen. Helaas is er geen manier om dit probleem op te lossen, behalve teruggaan naar de HDP-2.4.2-versie van Mahout, die mogelijk beveiligingsproblemen heeft. Nogmaals, dit moet ongebruikelijk zijn en zal waarschijnlijk niet voorkomen in een bepaalde Mahout-jobsuite.
Oozie
Deze release biedt Oozie 4.2.0 met de volgende Apache-patches.
OOZIE-2571: Voeg de maven-eigenschap spark.scala.binary.version toe, zodat Scala 2.11 kan worden gebruikt.
OOZIE-2606: Stel spark.yarn.jars in om Spark 2.0 te herstellen met Oozie.
OOZIE-2658: --driver-class-path kan het klassepad in SparkMain overschrijven.
OOZIE-2787: Oozie distribueert toepassings jar tweemaal, waardoor de spark-taak mislukt.
OOZIE-2792:
Hive2de actie parseert de Spark-toepassings-id niet correct uit het logboekbestand wanneer Hive zich in Spark bevindt.OOZIE-2799: Logboeklocatie instellen voor spark sql op hive.
OOZIE-2802: Spark-actiefout op Spark 2.1.0 vanwege duplicaat
sharelibs.OOZIE-2923: Spark-opties parseren verbeteren.
OOZIE-3109: SCA: Cross-Site Scripting: Reflected.
OOZIE-3139: Oozie valideert werkstroom onjuist.
OOZIE-3167: Upgrade tomcat versie op Oozie 4.3 branch.
Phoenix
Deze release biedt Phoenix 4.7.0 en de volgende Apache-patches:
PHOENIX-1751: Aggregaties, sortering, enzovoort uitvoeren in de preScannerNext in plaats van postScannerOpen.
PHOENIX-2714: Juiste byteraming in BaseResultIterators en beschikbaar maken als interface.
PHOENIX-2724: Query met een groot aantal geleideposten is langzamer vergeleken met geen statistieken.
PHOENIX-2855: Tijdelijke oplossing Increment TimeRange wordt niet geserialiseerd voor HBase 1.2.
PHOENIX-3023: Trage prestaties wanneer limietquery's standaard parallel worden uitgevoerd.
PHOENIX-3040: Gebruik geen guideposts voor het uitvoeren van query's serieel.
PHOENIX-3112: Gedeeltelijke rijscan is niet correct verwerkt.
PHOENIX-3240: ClassCastException van Pig loader.
PHOENIX-3452: NULLS FIRST/NULL LAST mag geen invloed hebben op of GROUP BY ordebehoud is.
PHOENIX-3469: Onjuiste sorteervolgorde voor DESC primaire sleutel voor NULLS LAST/NULLS FIRST.
PHOENIX-3789: Voer onderhoudsaanroepen voor meerdere regio's uit in postBatchMutateIndispensably.
PHOENIX-3865: IS NULL retourneert geen juiste resultaten wanneer de eerste kolomfamilie niet is gefilterd op.
PHOENIX-4290: Volledige tabelscan uitgevoerd voor DELETE met tabel met onveranderbare indexen.
PHOENIX-4373: De sleutel voor de lengte van de lokale indexvariabele kan volg null-waarden hebben tijdens upserting.
PHOENIX-4466: java.lang.RuntimeException: antwoordcode 500 - Een Spark-taak uitvoeren om verbinding te maken met phoenix-queryserver en gegevens laden.
PHOENIX-4489: HBase Verbinding maken ion-lek in Phoenix MR Jobs.
PHOENIX-4525: Overloop van gehele getallen in GroupBy-uitvoering.
PHOENIX-4560: ORDER BY met GROUP BY werkt niet als er WHERE in
pkde kolom staat.PHOENIX-4586: UPSERT SELECT houdt geen rekening met vergelijkingsoperators voor subquery's.
PHOENIX-4588: Kloonexpressie ook als de onderliggende elementen Determinism.PER_INVOCATION hebben.
Pig
Deze release biedt Pig 0.16.0 met de volgende Apache-patches.
Ranger
Deze release biedt Ranger 0.7.0 en de volgende Apache-patches:
RANGER-1805: Codeverbetering om de best practices in js te volgen.
RANGER-1960: Neem de tabelnaam van de momentopname in overweging voor verwijdering.
RANGER-1982: Foutverbetering voor metrische analysegegevens van Ranger Beheer en Ranger KMS.
RANGER-1984: HBase-auditlogboekrecords bevatten mogelijk niet alle tags die zijn gekoppeld aan de geopende kolom.
RANGER-1988: Onveilige willekeurigheid oplossen.
RANGER-1990: One-way SSL MySQL-ondersteuning toevoegen in Ranger Beheer.
RANGER-2006: Los problemen op die zijn gedetecteerd door statische codeanalyse in ranger
usersyncvoorldapsynchronisatiebron.RANGER-2008: Beleidsevaluatie mislukt voor beleidsvoorwaarden met meerdere regels.
Schuifregelaar
Deze release biedt Slider 0.92.0 zonder Apache-patches meer.
Spark
Deze release biedt Spark 2.3.0 en de volgende Apache-patches:
SPARK-13587: Ondersteuning voor virtualenv in pyspark.
SPARK-19964: Vermijd het lezen van externe opslagplaatsen in SparkSubmitSuite.
SPARK-22882: ML-test voor gestructureerd streamen: ml.classification.
SPARK-22915: Streamingtests voor spark.ml.feature, van N tot Z.
SPARK-23020: Herstel een andere race in de processtartertest.
SPARK-23040: retourneert interruptible iterator voor shuffle reader.
SPARK-23173: Vermijd het maken van beschadigde Parquet-bestanden bij het laden van gegevens uit JSON.
SPARK-23264: Scala herstellen. MatchError in literals.sql.out.
SPARK-23288: Corrigeer metrische uitvoergegevens met parquet sink.
SPARK-23329: Documentatie van trigonometrische functies herstellen.
SPARK-23406: schakel stream-stream-self-joins in voor branch-2.3.
SPARK-23434: Spark mag de map met metagegevens niet waarschuwen voor een HDFS-bestandspad.
SPARK-23436: de partitie afleiden als alleen datum als deze kan worden gecast naar Datum.
SPARK-23457: Registreer eerst listeners voor taakvoltooiing in ParquetFileFormat.
SPARK-23462: verbeter het foutbericht over ontbrekende velden in 'StructType'.
SPARK-23490: Controleer storage.locationUri met bestaande tabel in CreateTable.
SPARK-23524: Grote lokale willekeurige blokken mogen niet worden gecontroleerd op beschadiging.
SPARK-23525: ondersteuning voor ALTER TABLE CHANGE COLUMN COMMENT voor externe hive-tabel.
SPARK-23553: Tests mogen niet uitgaan van de standaardwaarde 'spark.sql.sources.default'.
SPARK-23569: pandas_udf toestaan om te werken met type-aantekeningenfuncties in python3.
SPARK-23570: Spark 2.3.0 toevoegen in HiveExternalCatalogVersionsSuite.
SPARK-23598: Maak methoden in BufferedRowIterator openbaar om runtimefouten voor een grote query te voorkomen.
SPARK-23599: Voeg een UUID-generator toe van pseudo-willekeurige getallen.
SPARK-23599: Gebruik RandomUUIDGenerator in Uuid-expressie.
SPARK-23601: Bestanden verwijderen
.md5uit de release.SPARK-23608: Voeg synchronisatie toe in SHS tussen attachSparkUI- en ontkoppelingSparkUI-functies om gelijktijdige wijzigingsproblemen met Jetty Handlers te voorkomen.
SPARK-23614: Corrigeer onjuiste exchange voor hergebruik wanneer caching wordt gebruikt.
SPARK-23623: Vermijd gelijktijdig gebruik van consumenten in cache in CachedKafkaConsumer (branch-2.3).
SPARK-23624: Document van methode pushFilters herzien in Datasource V2.
SPARK-23628: calculateParamLength mag niet 1 + aantal expressies retourneren.
SPARK-23630: Hiermee staat u toe dat de hadoop-conf-aanpassingen van de gebruiker van kracht worden.
SPARK-23635: Spark executor env-variabele wordt overschreven met dezelfde naam AM env-variabele.
SPARK-23637: Yarn kan meer resources toewijzen als een zelfde uitvoerder meerdere keren wordt gedood.
SPARK-23639: het token verkrijgen vóór init-metastore-client in SparkSQL CLI.
SPARK-23642: AccumulatorV2 subklasse isZero
scaladocfix.SPARK-23644: Gebruik absoluut pad voor REST-aanroep in SHS.
SPARK-23645: Docs RE 'pandas_udf' toevoegen met trefwoordargumenten.
SPARK-23649: tekens overslaan die niet zijn toegestaan in UTF-8.
SPARK-23658: InProcessAppHandle gebruikt de verkeerde klasse in getLogger.
SPARK-23660: Oplossing voor uitzondering in yarn-clustermodus wanneer de toepassing snel is beëindigd.
SPARK-23670: Geheugenlek oplossen op SparkPlanGraphWrapper.
SPARK-23671: Oplossingsvoorwaarde om de SHS-threadgroep in te schakelen.
SPARK-23691: Gebruik waar mogelijk sql_conf hulpprogramma in PySpark-tests.
SPARK-23695: Corrigeer het foutbericht voor Kinesis-streamingtests.
SPARK-23706: spark.conf.get(value, default=None) moet Geen produceren in PySpark.
SPARK-23728: ML-tests oplossen met verwachte uitzonderingen die streamingtests uitvoeren.
SPARK-23729: Respecteer URI-fragment bij het omzetten van globs.
SPARK-23759: Kan de Spark-gebruikersinterface niet binden aan specifieke hostnaam/IP.
SPARK-23760: CodegenContext.withSubExprEliminationExprs moet de CSE-status correct opslaan/herstellen.
SPARK-23769: Verwijder opmerkingen die de controle onnodig uitschakelen
Scalastyle.SPARK-23788: Race herstellen in StreamingQuerySuite.
SPARK-23802: PropagateEmptyRelation kan het queryplan ongewijzigd laten.
SPARK-23806: Broadcast.unpersist kan een fatale uitzondering veroorzaken bij gebruik met dynamische toewijzing.
SPARK-23808: Standaard Spark-sessie instellen in spark-sessies die alleen worden getest.
SPARK-23809: Actieve SparkSession moet worden ingesteld door getOrCreate.
SPARK-23816: Gedoode taken moeten FetchFailures negeren.
SPARK-23822: Het foutbericht voor parquet-schema komt niet overeen.
SPARK-23823: Oorsprong behouden in transformExpression.
SPARK-23827: StreamingJoinExec moet ervoor zorgen dat invoergegevens worden gepartitioneerd in een specifiek aantal partities.
SPARK-23838: Het uitvoeren van EEN SQL-query wordt weergegeven als 'voltooid' op het tabblad SQL.
SPARK-23881: Fix flaky test JobCancellationSuite." interruptible iterator of shuffle reader".
Sqoop
Deze release biedt Sqoop 1.4.6 zonder Apache-patches meer.
Storm
Deze release biedt Storm 1.1.1 en de volgende Apache-patches:
STORM-2652: Er is een uitzondering opgetreden in de open methode JmsSpout.
STORM-2841: testNoAcksIfFlushFails UT mislukt met NullPointerException.
STORM-2854: IEventLogger beschikbaar maken om event log pluggable te maken.
STORM-2870: FileBasedEventLogger lekt niet-daemon ExecutorService, waardoor het proces niet kan worden voltooid.
STORM-2960: Beter om het belang van het instellen van het juiste besturingssysteemaccount voor Storm-processen te benadrukken.
Tez
Deze release biedt Tez 0.7.0 en de volgende Apache-patches:
- TEZ-1526: LoadingCache voor TezTaskID traag voor grote taken.
Zeppelin
Deze release biedt Zeppelin 0.7.3 zonder Apache-patches meer.
ZEPPELIN-3072: De gebruikersinterface van Zeppelin wordt traag/reageert niet als er te veel notitieblokken zijn.
ZEPPELIN-3129: De gebruikersinterface van Zeppelin meldt zich niet af bij IE.
ZEPPELIN-903: Vervang CXF door
Jersey2.
ZooKeeper
Deze release biedt ZooKeeper 3.4.6 en de volgende Apache-patches:
ZOOKEEPER-1256: ClientPortBindTest mislukt op macOS X.
ZOOKEEPER-1901: [JDK8] Sorteer kinderen ter vergelijking in AsyncOps-tests.
ZOOKEEPER-2423: Upgrade Netty-versie vanwege beveiligingsprobleem (CVE-2014-3488).
ZOOKEEPER-2693: DOS-aanval op wchp/wchc vier letterwoorden (4lw).
ZOOKEEPER-2726: Patch introduceert een potentiële racevoorwaarde.
Veelvoorkomende beveiligingsproblemen en blootstellingen opgelost
In deze sectie worden alle Common Vulnerabilities and Exposures (CVE) behandeld die in deze release worden behandeld.
CVE-2017-7676
| Samenvatting: De beleidsevaluatie van Apache Ranger negeert tekens na het jokerteken * |
|---|
| Ernst: Kritiek |
| Leverancier: Hortonworks |
| Betrokken versies: HDInsight 3.6-versies, waaronder Apache Ranger-versies 0.5.x/0.6.x/0.7.0 |
| Betrokken gebruikers: omgevingen die gebruikmaken van Ranger-beleid met tekens na '*' jokerteken, zoals mijn*test, test*.txt |
| Impact: De matcher voor beleidsresources negeert tekens na het jokerteken *, wat kan leiden tot onbedoeld gedrag. |
| Oplossingsdetails: Ranger-beleidsresourcematcher is bijgewerkt om jokertekenovereenkomsten correct te verwerken. |
| Aanbevolen actie: upgraden naar HDI 3.6 (met Apache Ranger 0.7.1+). |
CVE-2017-7677
| Samenvatting: Apache Ranger Hive Authorizer moet controleren op RWX-machtiging wanneer externe locatie is opgegeven |
|---|
| Ernst: Kritiek |
| Leverancier: Hortonworks |
| Betrokken versies: HDInsight 3.6-versies, waaronder Apache Ranger-versies 0.5.x/0.6.x/0.7.0 |
| Betrokken gebruikers: omgevingen die gebruikmaken van externe locatie voor hive-tabellen |
| Impact: In omgevingen die gebruikmaken van externe locatie voor hive-tabellen, moet Apache Ranger Hive Authorizer controleren op RWX-machtigingen voor de externe locatie die is opgegeven voor de create-tabel. |
| Oplossingsdetails: Ranger Hive Authorizer is bijgewerkt om de machtigingscontrole correct af te handelen met externe locatie. |
| Aanbevolen actie: gebruikers moeten upgraden naar HDI 3.6 (met Apache Ranger 0.7.1+). |
CVE-2017-9799
| Samenvatting: Mogelijke uitvoering van code als de verkeerde gebruiker in Apache Storm |
|---|
| Ernst: Belangrijk |
| Leverancier: Hortonworks |
| Betrokken versies: HDP 2.4.0, HDP-2.5.0, HDP-2.6.0 |
| Getroffen gebruikers: gebruikers die Storm in de beveiligde modus gebruiken en blobstore gebruiken om topologieartefacten te distribueren of de blobstore te gebruiken om topologieresources te distribueren. |
| Impact: In sommige situaties en configuraties van storm is het theoretisch mogelijk voor de eigenaar van een topologie om de supervisor te misleiden om een werkrol te starten als een andere, niet-hoofdgebruiker. In het ergste geval kan dit ertoe leiden dat de referenties van de andere gebruiker worden beveiligd. Dit beveiligingsprobleem is alleen van toepassing op Apache Storm-installaties waarvoor beveiliging is ingeschakeld. |
| Risicobeperking: Upgrade uitvoeren naar HDP-2.6.2.1 omdat er momenteel geen tijdelijke oplossingen zijn. |
CVE-2016-4970
| Samenvatting: handler/ssl/OpenSslEngine.java in Netty 4.0.x vóór 4.0.37. Definitief en 4.1.x vóór 4.1.1. Ten slotte kunnen externe aanvallers een Denial of Service veroorzaken (oneindige lus) |
|---|
| Ernst: Gemiddeld |
| Leverancier: Hortonworks |
| Versies beïnvloed: HDP 2.x.x sinds 2.3.x |
| Betrokken gebruikers: alle gebruikers die HDFS gebruiken. |
| Impact: Impact is laag omdat Hortonworks niet rechtstreeks in Hadoop-codebase OpenSslEngine.java gebruikt. |
| Aanbevolen actie: upgraden naar HDP 2.6.3. |
CVE-2016-8746
| Samenvatting: het overeenkomende probleem met het Apache Ranger-pad in beleidsevaluatie |
|---|
| Ernst: Normaal |
| Leverancier: Hortonworks |
| Betrokken versies: Alle HDP 2.5-versies, waaronder Apache Ranger-versies 0.6.0/0.6.1/0.6.2 |
| Betrokken gebruikers: Alle gebruikers van het beleidsbeheerprogramma ranger. |
| Impact: ranger-beleidsengine komt onjuist overeen met paden in bepaalde voorwaarden wanneer een beleid jokertekens en recursieve vlaggen bevat. |
| Oplossingsdetails: Vaste logica voor beleidsevaluatie |
| Aanbevolen actie: gebruikers moeten upgraden naar HDP 2.5.4+ (met Apache Ranger 0.6.3+) of HDP 2.6+ (met Apache Ranger 0.7.0+) |
CVE-2016-8751
| Samenvatting: Probleem met het uitvoeren van scripts opgeslagen op meerdere sites in Apache Ranger |
|---|
| Ernst: Normaal |
| Leverancier: Hortonworks |
| Betrokken versies: Alle HDP 2.3/2.4/2.5-versies, waaronder Apache Ranger-versies 0.5.x/0.6.0/0.6.1/0.6.2 |
| Betrokken gebruikers: Alle gebruikers van het beleidsbeheerprogramma ranger. |
| Impact: Apache Ranger is kwetsbaar voor een opgeslagen cross-site scripting bij het invoeren van aangepaste beleidsvoorwaarden. Beheer gebruikers willekeurige JavaScript-code kunnen opslaan wanneer normale gebruikers zich aanmelden en toegangsbeleid. |
| Oplossingsdetails: Logica toegevoegd voor het opschonen van de gebruikersinvoer. |
| Aanbevolen actie: gebruikers moeten upgraden naar HDP 2.5.4+ (met Apache Ranger 0.6.3+) of HDP 2.6+ (met Apache Ranger 0.7.0+) |
Problemen opgelost voor ondersteuning
Opgeloste problemen vertegenwoordigen geselecteerde problemen die eerder zijn vastgelegd via Hortonworks Support, maar die nu worden opgelost in de huidige release. Deze problemen zijn mogelijk gerapporteerd in eerdere versies in de sectie Bekende problemen; wat betekent dat ze zijn gerapporteerd door klanten of geïdentificeerd door het Hortonworks Quality Engineering-team.
Onjuiste resultaten
| Fout-id | Apache JIRA | Samenvatting |
|---|---|---|
| BUG-100019 | YARN-8145 | yarn rmadmin -getGroups retourneert geen bijgewerkte groepen voor de gebruiker |
| BUG-100058 | PHOENIX-2645 | Jokertekens komen niet overeen met nieuweregeltekens |
| BUG-100266 | PHOENIX-3521, PHOENIX-4190 | Resultaten onjuist met lokale indexen |
| BUG-88774 | HIVE-17617, HIVE-18413, HIVE-18523 | query36 mislukt, aantal rijen komt niet overeen |
| BUG-89765 | HIVE-17702 | onjuiste verwerking in decimale lezer in ORC |
| BUG-92293 | HADOOP-15042 | Azure PageBlobInputStream.skip() kan een negatieve waarde retourneren wanneer numberOfPagesRemaining 0 is |
| BUG-92345 | ATLAS-2285 | Gebruikersinterface: De naam van opgeslagen zoekopdracht is gewijzigd met het datumkenmerk. |
| BUG-92563 | HIVE-17495, HIVE-18528 | Statistische statistieken in ObjectStore krijgen het verkeerde resultaat |
| BUG-92957 | HIVE-11266 | onjuist resultaat count(*) op basis van tabelstatistieken voor externe tabellen |
| BUG-93097 | RANGER-1944 | Actiefilter voor Beheer Audit werkt niet |
| BUG-93335 | HIVE-12315 | vectorization_short_regress.q heeft een verkeerd resultaatprobleem voor een dubbele berekening |
| BUG-93415 | HIVE-18258, HIVE-18310 | Vectorisatie: Reduce-Side GROUP BY MERGEPARTIAL met dubbele kolommen is verbroken |
| BUG-93939 | ATLAS-2294 | Extra parameter 'description' toegevoegd bij het maken van een type |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | Phoenix-query's retourneert null-waarden vanwege gedeeltelijke HBase-rijen |
| BUG-94266 | HIVE-12505 | Overschrijven invoegen in dezelfde versleutelde zone op de achtergrond kan sommige bestaande bestanden niet verwijderen |
| BUG-94414 | HIVE-15680 | Onjuiste resultaten wanneer hive.optimize.index.filter=true en dezelfde ORC-tabel twee keer wordt verwezen in de query |
| BUG-95048 | HIVE-18490 | Query's met EXISTS en NOT EXISTS met niet-equi predicaat kunnen een onjuist resultaat opleveren |
| BUG-95053 | PHOENIX-3865 | IS NULL retourneert geen juiste resultaten wanneer de eerste kolomfamilie niet is gefilterd op |
| BUG-95476 | RANGER-1966 | Initialisatie van beleidsengine maakt in sommige gevallen geen contextverrijkers |
| BUG-95566 | SPARK-23281 | Query produceert resultaten in onjuiste volgorde wanneer een samengestelde volgorde per component verwijst naar zowel oorspronkelijke kolommen als aliassen |
| BUG-95907 | PHOENIX-3451, PHOENIX-3452, PHOENIX-3469, PHOENIX-4560 | Problemen met ORDER BY ASC oplossen wanneer query aggregatie heeft |
| BUG-96389 | PHOENIX-4586 | UPSERT SELECT houdt geen rekening met vergelijkingsoperators voor subquery's. |
| BUG-96602 | HIVE-18660 | PCR maakt geen onderscheid tussen partitie- en virtuele kolommen |
| BUG-97686 | ATLAS-2468 | [Basiszoekopdrachten] Probleem met OF-gevallen wanneer NEQ wordt gebruikt met numerieke typen |
| BUG-97708 | HIVE-18817 | MatrixIndexOutOfBounds-uitzondering tijdens het lezen van de ACID-tabel. |
| BUG-97864 | HIVE-18833 | Automatisch samenvoegen mislukt wanneer 'invoegen in map als orcfile' |
| BUG-97889 | RANGER-2008 | Beleidsevaluatie mislukt voor beleidsvoorwaarden met meerdere regels. |
| BUG-98655 | RANGER-2066 | Toegang tot de HBase-kolomfamilie is geautoriseerd door een gelabelde kolom in de kolomfamilie |
| BUG-99883 | HIVE-19073, HIVE-19145 | StatsOptimizer kan constante kolommen beheren |
Overig
| Fout-id | Apache JIRA | Samenvatting |
|---|---|---|
| BUG-100267 | HBASE-17170 | HBase probeert ook DoNotRetryIOException opnieuw vanwege verschillen in klasselaadprogramma's. |
| BUG-92367 | YARN-7558 | De opdracht yarn logs kan geen logboeken ophalen voor actieve containers als UI-verificatie is ingeschakeld. |
| BUG-93159 | OOZIE-3139 | Oozie valideert werkstroom onjuist |
| BUG-93936 | ATLAS-2289 | Ingesloten kafka/zookeeper-server start-/stopcode die moet worden verplaatst uit de KafkaNotification-implementatie |
| BUG-93942 | ATLAS-2312 | ThreadLocal DateFormat-objecten gebruiken om gelijktijdig gebruik van meerdere threads te voorkomen |
| BUG-93946 | ATLAS-2319 | Gebruikersinterface: Het verwijderen van een tag, die op 25+ positie in de taglijst in zowel platte structuur als structuur moet worden vernieuwd om de tag uit de lijst te verwijderen. |
| BUG-94618 | YARN-5037, YARN-7274 | Mogelijkheid om elasticiteit uit te schakelen op bladwachtrijniveau |
| BUG-94901 | HBASE-19285 | Histogrammen voor latentie per tabel toevoegen |
| BUG-95259 | HADOOP-15185, HADOOP-15186 | Connector adls bijwerken om de huidige versie van ADLS SDK te gebruiken |
| BUG-95619 | HIVE-18551 | Vectorisatie: VectorMapOperator probeert te veel vectorkolommen te schrijven voor Hybrid Grace |
| BUG-97223 | SPARK-23434 | Spark mag 'metagegevensmap' niet waarschuwen voor een HDFS-bestandspad |
Prestaties
| Fout-id | Apache JIRA | Samenvatting |
|---|---|---|
| BUG-83282 | HBASE-13376, HBASE-14473, HBASE-15210, HBASE-15515, HBASE-16570, HBASE-16810, HBASE-18164 | Snelle lokalisatieberekening in balancer |
| BUG-91300 | HBASE-17387 | Verminder de overhead van uitzonderingsrapport in RegionActionResult voor multi() |
| BUG-91804 | TEZ-1526 | LoadingCache voor TezTaskID traag voor grote taken |
| BUG-92760 | ACCUMULO-4578 | De compressie-LOT-bewerking annuleert geen vergrendeling van naamruimte |
| BUG-93577 | RANGER-1938 | Solr for Audit Setup maakt niet effectief gebruik van DocValues |
| BUG-93910 | HIVE-18293 | Hive kan geen tabellen comprimeren die zijn opgenomen in een map die geen eigendom is van de identiteit waarop HiveMetaStore wordt uitgevoerd |
| BUG-94345 | HIVE-18429 | Compressie moet een case verwerken wanneer er geen uitvoer wordt geproduceerd |
| BUG-94381 | HADOOP-13227, HDFS-13054 | RequestHedgingProxyProvider RetryAction-order verwerken: FAIL < RETRY < FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | CompactorMR moet jobclient.close() aanroepen om opschoning te activeren |
| BUG-94869 | PHOENIX-4290, PHOENIX-4373 | Aangevraagde rij buiten bereik voor Get on HRegion voor lokale geïndexeerde gezouten phoenix tabel. |
| BUG-94928 | HDFS-11078 | NPE in LazyPersistFileScrubber herstellen |
| BUG-94964 | HIVE-18269, HIVE-18318, HIVE-18326 | Meerdere LLAP-oplossingen |
| BUG-95669 | HIVE-18577, HIVE-18643 | Bij het uitvoeren van een bijwerk-/verwijderquery op een gepartitioneerde ACID-tabel leest HS2 alle partities. |
| BUG-96390 | HDFS-10453 | ReplicationMonitor-thread kan lange tijd vastlopen vanwege de race tussen replicatie en het verwijderen van hetzelfde bestand in een groot cluster. |
| BUG-96625 | HIVE-16110 | Terugdraaien van "Vectorization: Support 2 Value CASE WHEN in plaats van terugval naar VectorUDFAdaptor" |
| BUG-97109 | HIVE-16757 | Het gebruik van afgeschafte getRows() in plaats van nieuwe schattingRowCount(RelMetadataQuery...) heeft ernstige gevolgen voor de prestaties |
| BUG-97110 | PHOENIX-3789 | Onderhoudsaanroepen voor meerdere regio's uitvoeren in postBatchMutateIndispensably |
| BUG-98833 | YARN-6797 | TimelineWriter verbruikt het POST-antwoord niet volledig |
| BUG-98931 | ATLAS-2491 | Hive-hook bijwerken om Atlas v2-meldingen te gebruiken |
Potentieel gegevensverlies
| Fout-id | Apache JIRA | Samenvatting |
|---|---|---|
| BUG-95613 | HBASE-18808 | Ineffectieve configuratiecontrole backupLogCleaner#getDeletableFiles() |
| BUG-97051 | HIVE-17403 | Samenvoeging mislukt voor niet-beheerde en transactionele tabellen |
| BUG-97787 | HIVE-18460 | Tabeleigenschappen worden niet doorgegeven aan de Orc Writer |
| BUG-97788 | HIVE-18613 | JsonSerDe uitbreiden ter ondersteuning van binair type |
Queryfout
| Fout-id | Apache JIRA | Samenvatting |
|---|---|---|
| BUG-100180 | CALCITE-2232 | Assertion error on AggregatePullUpConstantsRule while adjusting Aggregate indices |
| BUG-100422 | HIVE-19085 | FastHiveDecimal abs(0) stelt het teken in op +ve |
| BUG-100834 | PHOENIX-4658 | IllegalStateException: requestSeek kan niet worden aangeroepen op ReversedKeyValueHeap |
| BUG-102078 | HIVE-17978 | TPCDS query's 58 en 83 genereren uitzonderingen in vectorisatie. |
| BUG-92483 | HIVE-17900 | analyseert statistieken over kolommen die door Compactor worden geactiveerd, genereert ongeldige SQL met > één partitiekolom |
| BUG-93135 | HIVE-15874, HIVE-18189 | Hive-query retourneert verkeerde resultaten bij het instellen van hive.groupby.orderby.position.alias op true |
| BUG-93136 | HIVE-18189 | Volgorde op positie werkt niet wanneer cbo deze is uitgeschakeld |
| BUG-93595 | HIVE-12378, HIVE-15883 | HBase toegewezen tabel in Hive invoegen mislukt voor decimale en binaire kolommen |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | Phoenix-query's retourneert null-waarden vanwege gedeeltelijke HBase-rijen |
| BUG-94144 | HIVE-17063 | overschrijven van partitie invoegen in een externe tabel mislukt wanneer de partitie eerst wordt verwijderd |
| BUG-94280 | HIVE-12785 | Weergeven met samenvoegtype en UDF om de struct te 'casten' is verbroken |
| BUG-94505 | PHOENIX-4525 | Overloop van gehele getallen in GroupBy-uitvoering |
| BUG-95618 | HIVE-18506 | LlapBaseInputFormat - negatieve matrixindex |
| BUG-95644 | HIVE-9152 | CombineHiveInputFormat: Hive-query mislukt in Tez met uitzondering java.lang.IllegalArgumentException |
| BUG-96762 | PHOENIX-4588 | Kloonexpressie ook als de onderliggende items Determinism.PER_INVOCATION |
| BUG-97145 | HIVE-12245, HIVE-17829 | Ondersteuning voor kolomopmerkingen voor een tabel met HBase-ondersteuning |
| BUG-97741 | HIVE-18944 | De positie van groeperingssets is onjuist ingesteld tijdens DPP |
| BUG-98082 | HIVE-18597 | LLAP: Pak altijd het log4j2 API-JAR-bestand voor org.apache.log4j |
| BUG-99849 | N.v.t. | Een nieuwe tabel maken vanuit een wizard Bestand probeert de standaarddatabase te gebruiken |
Beveiliging
| Fout-id | Apache JIRA | Samenvatting |
|---|---|---|
| BUG-100436 | RANGER-2060 | Knox proxy met knox-sso werkt niet voor ranger |
| BUG-101038 | SPARK-24062 | Fout 'Verbinding maken ion geweigerd' van Zeppelin %Spark-interpreter, 'Er moet een geheime sleutel worden opgegeven...' fout in HiveThriftServer |
| BUG-101359 | ACCUMULO-4056 | Updateversie van commons-collection naar 3.2.2 wanneer deze wordt uitgebracht |
| BUG-54240 | HIVE-18879 | Het ingesloten element in UDFXPathUtil moet niet werken als xercesImpl.jar in classpath |
| BUG-79059 | OOZIE-3109 | HTML-specifieke tekens van escapelogboekstreaming |
| BUG-90041 | OOZIE-2723 | JSON.org licentie is nu CatX |
| BUG-93754 | RANGER-1943 | Ranger Solr-autorisatie wordt overgeslagen wanneer de verzameling leeg of null is |
| BUG-93804 | HIVE-17419 | TABEL ANALYSEREN... De opdracht COMPUTE STATISTICS FOR COLUMNS toont berekende statistieken voor gemaskeerde tabellen |
| BUG-94276 | ZEPPELIN-3129 | De gebruikersinterface van Zeppelin meldt zich niet af bij IE |
| BUG-95349 | ZOOKEEPER-1256, ZOOKEEPER-1901 | Netty upgraden |
| BUG-95483 | N.v.t. | Oplossing voor CVE-2017-15713 |
| BUG-95646 | OOZIE-3167 | Tomcat-versie upgraden op Oozie 4.3-vertakking |
| BUG-95823 | N.v.t. | Knox:Upgrade Beanutils |
| BUG-95908 | RANGER-1960 | HBase-verificatie neemt geen rekening met tabelnaamruimte voor het verwijderen van momentopnamen |
| BUG-96191 | FALCON-2322, FALCON-2323 | Jackson- en Spring-versies upgraden om beveiligingsproblemen te voorkomen |
| BUG-96502 | RANGER-1990 | One-way SSL MySQL-ondersteuning toevoegen in Ranger Beheer |
| BUG-96712 | FLUME-3194 | upgrade derby naar de nieuwste versie (1.14.1.0) |
| BUG-96713 | FLUME-2678 | Upgrade xalan naar 2.7.2 om het beveiligingsprobleem CVE-2014-0107 op te lossen |
| BUG-96714 | FLUME-2050 | Upgraden naar log4j2 (wanneer GA) |
| BUG-96737 | N.v.t. | Java Io-bestandssysteemmethoden gebruiken voor toegang tot lokale bestanden |
| BUG-96925 | N.v.t. | Tomcat upgraden van 6.0.48 naar 6.0.53 in Hadoop |
| BUG-96977 | FLUME-3132 | Tomcat-bibliotheekafhankelijkheden jasper upgraden |
| BUG-97022 | HADOOP-14799, HADOOP-14903, HADOOP-15265 | Nimbus-JOSE-JWT-bibliotheek upgraden met versie hoger dan 4.39 |
| BUG-97101 | RANGER-1988 | Onveilige willekeurigheid herstellen |
| BUG-97178 | ATLAS-2467 | Upgrade van afhankelijkheden voor Spring en nimbus-jose-jwt |
| BUG-97180 | N.v.t. | Nimbus-jose-jwt upgraden |
| BUG-98038 | HIVE-18788 | Invoer opschonen in JDBC PreparedStatement |
| BUG-98353 | HADOOP-13707 | Terugkeren van 'Als Kerberos is ingeschakeld terwijl HTTP SPNEGO niet is geconfigureerd, kunnen sommige koppelingen niet worden geopend' |
| BUG-98372 | HBASE-13848 | Toegang tot InfoServer SSL-wachtwoorden via referentieprovider-API |
| BUG-98385 | ATLAS-2500 | Voeg meer headers toe aan het Atlas-antwoord. |
| BUG-98564 | HADOOP-14651 | Okhttp-versie bijwerken naar 2.7.5 |
| BUG-99440 | RANGER-2045 | Hive-tabelkolommen zonder expliciet beleid voor toestaan worden weergegeven met de opdracht 'desc table' |
| BUG-99803 | N.v.t. | Oozie moet dynamische HBase-klasse laden uitschakelen |
Stabiliteit
| Fout-id | Apache JIRA | Samenvatting |
|---|---|---|
| BUG-100040 | ATLAS-2536 | NPE in Atlas Hive Hook |
| BUG-100057 | HIVE-19251 | ObjectStore.getNextNotification met LIMIT moet minder geheugen gebruiken |
| BUG-100072 | HIVE-19130 | NPE wordt gegenereerd wanneer REPL LOAD de partitiegebeurtenis toepast. |
| BUG-100073 | N.v.t. | te veel close_wait verbindingen van hiveserver het gegevensknooppunt |
| BUG-100319 | HIVE-19248 | REPL LOAD genereert geen fout als het kopiëren van bestanden mislukt. |
| BUG-100352 | N.v.t. | CLONE - RM purging logic scans /registry znode te vaak |
| BUG-100427 | HIVE-19249 | Replicatie: WITH-component geeft de configuratie niet correct door aan taak in alle gevallen |
| BUG-100430 | HIVE-14483 | java.lang.ArrayIndexOutOfBoundsException org.apache.orc.impl.TreeReaderFactory$BytesColumnVectorUtil.commonReadByteArrays |
| BUG-100432 | HIVE-19219 | Incrementele REPL DUMP moet een fout veroorzaken als aangevraagde gebeurtenissen worden opgeschoond. |
| BUG-100448 | SPARK-23637, SPARK-23802, SPARK-23809, SPARK-23816, SPARK-23822, SPARK-23823, SPARK-23838, SPARK-23881 | Bijwerken Spark2 naar 2.3.0+ (4/11) |
| BUG-100740 | HIVE-16107 | JDBC: HttpClient moet het opnieuw proberen op NoHttpResponseException |
| BUG-100810 | HIVE-19054 | Hive Functions-replicatie mislukt |
| BUG-100937 | MAPREDUCE-6889 | Voeg job#close-API toe om MR-clientservices af te sluiten. |
| BUG-101065 | ATLAS-2587 | Stel de lees-ACL in voor /apache_atlas/active_server_info znode in hoge beschikbaarheid, zodat Knox de proxy kan worden gelezen. |
| BUG-101093 | STORM-2993 | Storm HDFS bolt genereert ClosedChannelException wanneer beleid voor tijdrotatie wordt gebruikt |
| BUG-101181 | N.v.t. | PhoenixStorageHandler verwerkt AND niet correct in predicaat |
| BUG-101266 | PHOENIX-4635 | HBase Verbinding maken ionlek in org.apache.phoenix.hive.mapreduce.PhoenixInputFormat |
| BUG-101458 | HIVE-11464 | herkomstgegevens ontbreken als er meerdere uitvoerwaarden zijn |
| BUG-101485 | N.v.t. | hive metastore thrift-API is traag en veroorzaakt een time-out van de client |
| BUG-101628 | HIVE-19331 | Incrementele Hive-replicatie naar de cloud is mislukt. |
| BUG-102048 | HIVE-19381 | Hive-functiereplicatie naar de cloud mislukt met FunctionTask |
| BUG-102064 | N.v.t. | Hive-replicatietests \[ onprem to onprem \] zijn mislukt in ReplCopyTask |
| BUG-102137 | HIVE-19423 | Hive-replicatietests \[ Onprem to Cloud \] zijn mislukt in ReplCopyTask |
| BUG-102305 | HIVE-19430 | HS2- en hive-metastore-OOM-dumps |
| BUG-102361 | N.v.t. | meerdere invoegresultaten in één invoeging gerepliceerd naar het hive-doelcluster ( onprem - s3 ) |
| BUG-87624 | N.v.t. | Het inschakelen van storm gebeurtenislogboeken zorgt ervoor dat werknemers continu sterven |
| BUG-88929 | HBASE-15615 | Verkeerde slaaptijd wanneer RegionServerCallable opnieuw moet proberen |
| BUG-89628 | HIVE-17613 | objectgroepen verwijderen voor korte, zelfde thread-toewijzingen |
| BUG-89813 | N.v.t. | SCA: Code correctheid: Niet-gesynchroniseerde methode overschrijft gesynchroniseerde methode |
| BUG-90437 | ZEPPELIN-3072 | De gebruikersinterface van Zeppelin reageert traag/reageert niet als er te veel notebooks zijn |
| BUG-90640 | HBASE-19065 | HRegion#bulkLoadHFiles() moet wachten tot gelijktijdige Region#flush() is voltooid |
| BUG-91202 | HIVE-17013 | Aanvraag verwijderen met een subquery op basis van selecteren in een weergave |
| BUG-91350 | KNOX-1108 | NiFiHaDispatch mislukte failover |
| BUG-92054 | HIVE-13120 | doA's doorgeven bij het genereren van ORC-splitsingen |
| BUG-92373 | FALCON-2314 | Bump TestNG-versie naar 6.13.1 om BeanShell-afhankelijkheid te voorkomen |
| BUG-92381 | N.v.t. | testContainerLogsWithNewAPI en testContainerLogsWithOldAPI UT mislukt |
| BUG-92389 | STORM-2841 | testNoAcksIfFlushFails UT mislukt met NullPointerException |
| BUG-92586 | SPARK-17920, SPARK-20694, SPARK-21642, SPARK-22162, SPARK-22289, SPARK-22373, SPARK-22495, SPARK-22574, SPARK-22591, SPARK-22595, SPARK-22601, SPARK-22603, SPARK-22607, SPARK-22635, SPARK-22637, SPARK-22653, SPARK-22654, SPARK-22686, SPARK-22688, SPARK-22817, SPARK-22862, SPARK-22889, SPARK-22972, SPARK-22975, SPARK-22982, SPARK-22983, SPARK-22984, SPARK-23001, SPARK-23038, SPARK-23095 | Up-to-date Spark2 bijwerken naar 2.2.1 (16 januari) |
| BUG-92680 | ATLAS-2288 | NoClassDefFoundError-uitzondering tijdens het uitvoeren van import-hive-script wanneer de hbase-tabel wordt gemaakt via Hive |
| BUG-92760 | ACCUMULO-4578 | De compressie-LOT-bewerking annuleert geen vergrendeling van naamruimte |
| BUG-92797 | HDFS-10267, HDFS-8496 | Het verminderen van de datanodevergrendelingsconflicten voor bepaalde gebruiksvoorbeelden |
| BUG-92813 | FLUME-2973 | Impasse in hdfs sink |
| BUG-92957 | HIVE-11266 | onjuist resultaat count(*) op basis van tabelstatistieken voor externe tabellen |
| BUG-93018 | ATLAS-2310 | In hoge beschikbaarheid leidt het passieve knooppunt de aanvraag om met verkeerde URL-codering |
| BUG-93116 | RANGER-1957 | Ranger Usersync synchroniseert gebruikers of groepen niet periodiek wanneer incrementele synchronisatie is ingeschakeld. |
| BUG-93361 | HIVE-12360 | Slecht zoeken in ongecomprimeerde ORC met predicaat pushdown |
| BUG-93426 | CALCITE-2086 | HTTP/413 in bepaalde omstandigheden vanwege grote autorisatieheaders |
| BUG-93429 | PHOENIX-3240 | ClassCastException van Pig-laadprogramma |
| BUG-93485 | N.v.t. | kan tabel mytestorg.apache.hadoop.hive.ql.metadata.InvalidTableException niet ophalen: Tabel niet gevonden bij het uitvoeren van een analysetabel in kolommen in LLAP |
| BUG-93512 | PHOENIX-4466 | java.lang.RuntimeException: antwoordcode 500 - Een Spark-taak uitvoeren om verbinding te maken met phoenix-queryserver en gegevens laden |
| BUG-93550 | N.v.t. | Zeppelin %spark.r werkt niet met spark1 omdat de scala-versie niet overeenkomt |
| BUG-93910 | HIVE-18293 | Hive kan geen tabellen comprimeren die zijn opgenomen in een map die geen eigendom is van de identiteit waarop HiveMetaStore wordt uitgevoerd |
| BUG-93926 | ZEPPELIN-3114 | Notebooks en interpreters worden niet opgeslagen in zeppelin na >1d stresstests |
| BUG-93932 | ATLAS-2320 | classificatie '*' met query genereert 500 interne server-uitzondering. |
| BUG-93948 | YARN-7697 | NM gaat omlaag met OOM vanwege lek in logboekaggregatie (deel#1) |
| BUG-93965 | ATLAS-2229 | DSL-zoekopdracht: orderby kenmerk niet-tekenreeks genereert uitzondering |
| BUG-93986 | YARN-7697 | NM gaat omlaag met OOM vanwege lek in logboekaggregatie (deel#2) |
| BUG-94030 | ATLAS-2332 | Het maken van het type met kenmerken met geneste verzamelingsgegevenstype mislukt |
| BUG-94080 | YARN-3742, YARN-6061 | Beide RM zijn in stand-by in beveiligd cluster |
| BUG-94081 | HIVE-18384 | ConcurrentModificationException in log4j2.x bibliotheek |
| BUG-94168 | N.v.t. | Yarn RM gaat uit met serviceregister heeft de verkeerde status ERROR |
| BUG-94330 | HADOOP-13190, HADOOP-14104, HADOOP-14814, HDFS-10489, HDFS-11689 | HDFS moet ondersteuning bieden voor meerdere KMS Uris |
| BUG-94345 | HIVE-18429 | Compressie moet een case verwerken wanneer er geen uitvoer wordt geproduceerd |
| BUG-94372 | ATLAS-2229 | DSL-query: hive_table naam = ["t1","t2"] genereert ongeldige DSL-query-uitzondering |
| BUG-94381 | HADOOP-13227, HDFS-13054 | RequestHedgingProxyProvider RetryAction-order verwerken: FAIL < RETRY < FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | CompactorMR moet jobclient.close() aanroepen om opschoning te activeren |
| BUG-94575 | SPARK-22587 | Spark-taak mislukt als fs.defaultFS en toepassings-JAR verschillende URL's zijn |
| BUG-94791 | SPARK-22793 | Geheugenlek in Spark Thrift Server |
| BUG-94928 | HDFS-11078 | NPE in LazyPersistFileScrubber herstellen |
| BUG-95013 | HIVE-18488 | LLAP ORC-lezers missen enkele null-controles |
| BUG-95077 | HIVE-14205 | Hive biedt geen ondersteuning voor samenvoegingstype met AVRO-bestandsindeling |
| BUG-95200 | HDFS-13061 | SaslDataTransferClient#checkTrustAndSend mag geen gedeeltelijk vertrouwd kanaal vertrouwen |
| BUG-95201 | HDFS-13060 | Een BlacklistBasedTrustedChannelResolver toevoegen voor TrustedChannelResolver |
| BUG-95284 | HBASE-19395 | [vertakking-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting mislukt met NPE |
| BUG-95301 | HIVE-18517 | Vectorization: Fix VectorMapOperator to accept VRBs and check vectorized flag correct to support LLAP Caching |
| BUG-95542 | HBASE-16135 | PeerClusterZnode onder rs van verwijderde peer kan nooit worden verwijderd |
| BUG-95595 | HIVE-15563 | Negeer de overgangsondering voor de status van de ongeldige bewerking in SQLOperation.runQuery om echte uitzonderingen weer te geven. |
| BUG-95596 | YARN-4126, YARN-5750 | TestClientRMService mislukt |
| BUG-96019 | HIVE-18548 | Import herstellen log4j |
| BUG-96196 | HDFS-13120 | Diff van momentopnamen kan beschadigd zijn na samenvoegen |
| BUG-96289 | HDFS-11701 | NPE van niet-opgeloste host veroorzaakt permanente DFSInputStream-fouten |
| BUG-96291 | STORM-2652 | Uitzondering die is opgetreden in de open methode JmsSpout |
| BUG-96363 | HIVE-18959 | Vermijd het maken van extra threads in LLAP |
| BUG-96390 | HDFS-10453 | ReplicationMonitor-thread kan lange tijd vastlopen vanwege de race tussen replicatie en het verwijderen van hetzelfde bestand in een groot cluster. |
| BUG-96454 | YARN-4593 | Impasse in AbstractService.getConfig() |
| BUG-96704 | FALCON-2322 | ClassCastException tijdens verzendenAndSchedule-feed |
| BUG-96720 | SLIDER-1262 | Functests voor schuifregelaars mislukken in Kerberized de omgeving |
| BUG-96931 | SPARK-23053, SPARK-23186, SPARK-23230, SPARK-23358, SPARK-23376, SPARK-23391 | Bijgewerkt Spark2 (19 februari) |
| BUG-97067 | HIVE-10697 | ObjectInspectorConvertors#UnionConvertor voert een foutieve conversie uit |
| BUG-97244 | KNOX-1083 | De standaardtime-out van HttpClient moet een verstandige waarde zijn |
| BUG-97459 | ZEPPELIN-3271 | Optie voor het uitschakelen van scheduler |
| BUG-97511 | KNOX-1197 | AnonymousAuthFilter wordt niet toegevoegd wanneer verificatie=Anoniem in de service |
| BUG-97601 | HIVE-17479 | Faseringsmappen worden niet opgeschoond voor bijwerk-/verwijderquery's |
| BUG-97605 | HIVE-18858 | Systeemeigenschappen in taakconfiguratie niet opgelost bij het verzenden van een MR-taak |
| BUG-97674 | OOZIE-3186 | Oozie kan geen configuratie gebruiken die is gekoppeld met jceks://file/... |
| BUG-97743 | N.v.t. | java.lang.NoClassDefFoundError-uitzondering tijdens het implementeren van stormtopologie |
| BUG-97756 | PHOENIX-4576 | LocalIndexSplitMergeIT-tests zijn mislukt |
| BUG-97771 | HDFS-11711 | DN mag het blok niet verwijderen bij 'Te veel geopende bestanden' Uitzondering |
| BUG-97869 | KNOX-1190 | Knox Ondersteuning voor eenmalige aanmelding voor Google OIDC is verbroken. |
| BUG-97879 | PHOENIX-4489 | HBase Verbinding maken ionlek in Phoenix MR Jobs |
| BUG-98392 | RANGER-2007 | Kerberos-ticket van ranger-tagsync kan niet worden vernieuwd |
| BUG-98484 | N.v.t. | Incrementele hive-replicatie naar cloud werkt niet |
| BUG-98533 | HBASE-19934, HBASE-20008 | Herstellen van HBase-momentopname mislukt vanwege een null-aanwijzer-uitzondering |
| BUG-98555 | PHOENIX-4662 | NullPointerException in TableResultIterator.java op cache opnieuw verzenden |
| BUG-98579 | HBASE-13716 | Stoppen met het gebruik van Hadoop FSConstants |
| BUG-98705 | KNOX-1230 | Veel gelijktijdige aanvragen veroorzaken Knox URL-mangling |
| BUG-98983 | KNOX-1108 | NiFiHaDispatch mislukte failover |
| BUG-99107 | HIVE-19054 | Functiereplicatie gebruikt 'hive.repl.replica.functions.root.dir' als root |
| BUG-99145 | RANGER-2035 | Fouten bij het openen van servicedefs met lege implClass met Oracle-back-end |
| BUG-99160 | SLIDER-1259 | Schuifregelaar werkt niet in omgevingen met meerdere locaties |
| BUG-99239 | ATLAS-2462 | Sqoop-import voor alle tabellen genereert NPE voor geen tabel opgegeven in de opdracht |
| BUG-99301 | ATLAS-2530 | Newline aan het begin van het naamkenmerk van een hive_process en hive_column_lineage |
| BUG-99453 | HIVE-19065 | De compatibiliteitscontrole van de Metastore-client moet syncMetaStoreClient bevatten |
| BUG-99521 | N.v.t. | ServerCache voor HashJoin wordt niet opnieuw gemaakt wanneer iterators opnieuw worden geïnantieerd |
| BUG-99590 | PHOENIX-3518 | Geheugenlek in RenewLeaseTask |
| BUG-99618 | SPARK-23599, SPARK-23806 | Bijwerken Spark2 naar 2.3.0+ (3/28) |
| BUG-99672 | ATLAS-2524 | Hive-hook met V2-meldingen - onjuiste verwerking van bewerking 'alter view as' |
| BUG-99809 | HBASE-20375 | Het gebruik van getCurrentUserCredentials verwijderen in de hbase-spark-module |
Ondersteuning
| Fout-id | Apache JIRA | Samenvatting |
|---|---|---|
| BUG-87343 | HIVE-18031 | Ondersteuning voor replicatie voor alter database-bewerking. |
| BUG-91293 | RANGER-2060 | Knox proxy met knox-sso werkt niet voor ranger |
| BUG-93116 | RANGER-1957 | Ranger Usersync synchroniseert gebruikers of groepen niet periodiek wanneer incrementele synchronisatie is ingeschakeld. |
| BUG-93577 | RANGER-1938 | Solr for Audit Setup maakt niet effectief gebruik van DocValues |
| BUG-96082 | RANGER-1982 | Foutverbetering voor metrische analysegegevens van Ranger Beheer en RangerKms |
| BUG-96479 | HDFS-12781 | Nadat Datanode de gebruikersinterface is uitgeschakeld, Namenode wordt er een waarschuwingsbericht weergegeven op het tabblad Ui Datanode . |
| BUG-97864 | HIVE-18833 | Automatisch samenvoegen mislukt wanneer 'invoegen in map als orcfile' |
| BUG-98814 | HDFS-13314 | NameNode moet optioneel afsluiten als fsImage-beschadiging wordt gedetecteerd |
Upgraden
| Fout-id | Apache JIRA | Samenvatting |
|---|---|---|
| BUG-100134 | SPARK-22919 | Herstellen van 'Bump Apache httpclient-versies' |
| BUG-95823 | N.v.t. | Knox:Upgrade Beanutils |
| BUG-96751 | KNOX-1076 | Nimbus-jose-jwt bijwerken naar 4.41.2 |
| BUG-97864 | HIVE-18833 | Automatisch samenvoegen mislukt wanneer 'invoegen in map als orcfile' |
| BUG-99056 | HADOOP-13556 | Configuration.getPropsWithPrefix wijzigen om getProps te gebruiken in plaats van iterator |
| BUG-99378 | ATLAS-2461, ATLAS-2554 | Migratiehulpprogramma voor het exporteren van Atlas-gegevens in Titan graph DB |
Bruikbaarheid
| Fout-id | Apache JIRA | Samenvatting |
|---|---|---|
| BUG-100045 | HIVE-19056 | IllegalArgumentException in FixAcidKeyIndex wanneer HET ORC-bestand 0 rijen heeft |
| BUG-100139 | KNOX-1243 | De vereiste DN's normaliseren die zijn geconfigureerd in KnoxToken de service |
| BUG-100570 | ATLAS-2557 | Oplossing om hadoop-groepen ldap toe te lookup staan wanneer groepen van UGI onjuist zijn ingesteld of niet leeg zijn |
| BUG-100646 | ATLAS-2102 | Verbeteringen in de Atlas-gebruikersinterface: pagina met zoekresultaten |
| BUG-100737 | HIVE-19049 | Ondersteuning toevoegen voor Alter table add columns for Druid |
| BUG-100750 | KNOX-1246 | Werk de serviceconfiguratie bij Knox om de nieuwste configuraties voor Ranger te ondersteunen. |
| BUG-100965 | ATLAS-2581 | Regressie met V2 Hive-hookmeldingen: Tabel verplaatsen naar een andere database |
| BUG-84413 | ATLAS-1964 | Gebruikersinterface: Ondersteuning voor het orden van kolommen in de zoektabel |
| BUG-90570 | HDFS-11384, HDFS-12347 | Voeg de optie voor balancer toe om getBlocks-aanroepen te verspreiden om de rpc van NameNode te voorkomen. CallQueueLength-piek |
| BUG-90584 | HBASE-19052 | FixedFileTrailer moet de klasse CellComparatorImpl herkennen in branch-1.x |
| BUG-90979 | KNOX-1224 | Knox Proxy HADispatcher voor ondersteuning van Atlas in HOGE beschikbaarheid. |
| BUG-91293 | RANGER-2060 | Knox proxy met knox-sso werkt niet voor ranger |
| BUG-92236 | ATLAS-2281 | Query's voor tag-/typekenmerkfilters opslaan met null-/niet-null-filters. |
| BUG-92238 | ATLAS-2282 | Opgeslagen favoriete zoekopdrachten worden alleen weergegeven bij vernieuwen na het maken wanneer er meer dan 25 favoriete zoekopdrachten zijn. |
| BUG-92333 | ATLAS-2286 | Vooraf gebouwd type 'kafka_topic' mag het kenmerk 'onderwerp' niet als uniek declareren |
| BUG-92678 | ATLAS-2276 | De padwaarde voor de entiteit hdfs_path type is ingesteld op kleine letters van hive-bridge. |
| BUG-93097 | RANGER-1944 | Actiefilter voor Beheer Audit werkt niet |
| BUG-93135 | HIVE-15874, HIVE-18189 | Hive-query retourneert verkeerde resultaten bij het instellen van hive.groupby.orderby.position.alias op true |
| BUG-93136 | HIVE-18189 | Volgorde op positie werkt niet wanneer cbo deze is uitgeschakeld |
| BUG-93387 | HIVE-17600 | Maak de user-settable van OrcFile 'enforceBufferSize'. |
| BUG-93495 | RANGER-1937 | Ranger tagsync moet ENTITY_CREATE melding verwerken om de Atlas-importfunctie te ondersteunen |
| BUG-93512 | PHOENIX-4466 | java.lang.RuntimeException: antwoordcode 500 - Een Spark-taak uitvoeren om verbinding te maken met phoenix-queryserver en gegevens laden |
| BUG-93801 | HBASE-19393 | HTTP 413 FULL head tijdens het openen van de HBase-gebruikersinterface met BEHULP van SSL. |
| BUG-93804 | HIVE-17419 | TABEL ANALYSEREN... De opdracht COMPUTE STATISTICS FOR COLUMNS toont berekende statistieken voor gemaskeerde tabellen |
| BUG-93932 | ATLAS-2320 | classificatie '*' met query genereert 500 interne server-uitzondering. |
| BUG-93933 | ATLAS-2286 | Vooraf gebouwd type 'kafka_topic' mag het kenmerk 'onderwerp' niet als uniek declareren |
| BUG-93938 | ATLAS-2283, ATLAS-2295 | UI-updates voor classificaties |
| BUG-93941 | ATLAS-2296, ATLAS-2307 | Uitbreiding van basiszoekopdrachten om optioneel subtypeentiteiten en subclassificatietypen uit te sluiten |
| BUG-93944 | ATLAS-2318 | Gebruikersinterface: Wanneer u tweemaal op onderliggende tag klikt, wordt bovenliggende tag geselecteerd |
| BUG-93946 | ATLAS-2319 | Gebruikersinterface: Het verwijderen van een tag, die op 25+ positie in de taglijst in zowel platte structuur als structuur moet worden vernieuwd om de tag uit de lijst te verwijderen. |
| BUG-93977 | HIVE-16232 | Berekening van statistieken voor kolom in QuotedIdentifier ondersteunen |
| BUG-94030 | ATLAS-2332 | Het maken van het type met kenmerken met geneste verzamelingsgegevenstype mislukt |
| BUG-94099 | ATLAS-2352 | Atlas-server moet een configuratie opgeven om de geldigheid op te geven voor Kerberos DelegationToken |
| BUG-94280 | HIVE-12785 | Weergeven met samenvoegtype en UDF om de struct te 'casten' is verbroken |
| BUG-94332 | SQOOP-2930 | Sqoop-taak die de algemene eigenschappen van de opgeslagen taak niet overschrijft |
| BUG-94428 | N.v.t. | DataplaneRest API-ondersteuning voor Profiler-agent Knox |
| BUG-94514 | ATLAS-2339 | UI: Wijzigingen in 'kolommen' in de weergave Basiszoekresultaat zijn ook van invloed op DSL. |
| BUG-94515 | ATLAS-2169 | Verwijderen mislukt wanneer hard verwijderen is geconfigureerd |
| BUG-94518 | ATLAS-2329 | Atlas UI Multiple Hovers wordt weergegeven als de gebruiker op een andere tag klikt die onjuist is |
| BUG-94519 | ATLAS-2272 | Sla de status van gesleepte kolommen op met behulp van de zoek-API opslaan. |
| BUG-94627 | HIVE-17731 | een achterwaartse compat optie voor externe gebruikers toevoegen aan HIVE-11985 |
| BUG-94786 | HIVE-6091 | Lege pipeout bestanden worden gemaakt voor het maken/sluiten van de verbinding |
| BUG-94793 | HIVE-14013 | De tabel beschrijven geeft unicode niet correct weer |
| BUG-94900 | OOZIE-2606, OOZIE-2658, OOZIE-2787, OOZIE-2802 | Spark.yarn.jars instellen om Spark 2.0 te herstellen met Oozie |
| BUG-94901 | HBASE-19285 | Histogrammen voor latentie per tabel toevoegen |
| BUG-94908 | ATLAS-1921 | UI: Zoeken met entiteits- en kenmerkkenmerken: de gebruikersinterface voert geen bereikcontrole uit en maakt het mogelijk om buiten de grenzen waarden op te geven voor integrale en zwevende gegevenstypen. |
| BUG-95086 | RANGER-1953 | verbetering van de lijst met pagina's van gebruikersgroepen |
| BUG-95193 | SLIDER-1252 | Schuifregelaaragent mislukt met SSL-validatiefouten met Python 2.7.5-58 |
| BUG-95314 | YARN-7699 | queueUsagePercentage komt als INF voor getApp REST API-aanroep |
| BUG-95315 | HBASE-13947, HBASE-14517, HBASE-17931 | Systeemtabellen toewijzen aan servers met de hoogste versie |
| BUG-95392 | ATLAS-2421 | Meldingsupdates ter ondersteuning van V2-gegevensstructuren |
| BUG-95476 | RANGER-1966 | Initialisatie van beleidsengine maakt in sommige gevallen geen contextverrijkers |
| BUG-95512 | HIVE-18467 | ondersteuning voor hele magazijndump /load + database-gebeurtenissen maken/neerzetten |
| BUG-95593 | N.v.t. | Oozie DB-hulpprogramma's uitbreiden ter ondersteuning van Spark2sharelib het maken |
| BUG-95595 | HIVE-15563 | Negeer de overgangsondering voor de status van de ongeldige bewerking in SQLOperation.runQuery om echte uitzonderingen weer te geven. |
| BUG-95685 | ATLAS-2422 | Exporteren: Ondersteuning voor op type gebaseerde export |
| BUG-95798 | PHOENIX-2714, PHOENIX-2724, PHOENIX-3023, PHOENIX-3040 | Gebruik geen hulplijnposts voor het uitvoeren van query's serieel |
| BUG-95969 | HIVE-16828, HIVE-17063, HIVE-18390 | Gepartitioneerde weergave mislukt met FAILED: IndexOutOfBoundsException Index: 1, Grootte: 1 |
| BUG-96019 | HIVE-18548 | Import herstellen log4j |
| BUG-96288 | HBASE-14123, HBASE-14135, HBASE-17850 | Backport HBase Backup/Restore 2.0 |
| BUG-96313 | KNOX-1119 | Pac4J OAuth/OpenID Principal moet kunnen worden geconfigureerd |
| BUG-96365 | ATLAS-2442 | Gebruiker met alleen-lezenmachtiging voor entiteitsresource kan geen eenvoudige zoekopdracht uitvoeren |
| BUG-96479 | HDFS-12781 | Nadat Datanode de gebruikersinterface is uitgeschakeld, Namenode wordt er een waarschuwingsbericht weergegeven op het tabblad Ui Datanode . |
| BUG-96502 | RANGER-1990 | One-way SSL MySQL-ondersteuning toevoegen in Ranger Beheer |
| BUG-96718 | ATLAS-2439 | Sqoop-hook bijwerken om V2-meldingen te gebruiken |
| BUG-96748 | HIVE-18587 | DML-gebeurtenis invoegen kan proberen een controlesom te berekenen in mappen |
| BUG-96821 | HBASE-18212 | In de zelfstandige modus met lokaal bestandssysteem HBase-logboeken Waarschuwingsbericht: Kan methode unbuffer niet aanroepen in klasse org.apache.hadoop.fs.FSDataInputStream |
| BUG-96847 | HIVE-18754 | REPL STATUS moet ondersteuning bieden voor de component 'with' |
| BUG-96873 | ATLAS-2443 | Vereiste entiteitskenmerken vastleggen in uitgaande DELETE-berichten |
| BUG-96880 | SPARK-23230 | Wanneer hive.default.fileformat andere bestandstypen is, veroorzaakt het maken textfile van een tabel een serde fout |
| BUG-96911 | OOZIE-2571, OOZIE-2792, OOZIE-2799, OOZIE-2923 | Spark-opties parseren verbeteren |
| BUG-97100 | RANGER-1984 | HBase-auditlogboekrecords bevatten mogelijk niet alle tags die zijn gekoppeld aan de geopende kolom |
| BUG-97110 | PHOENIX-3789 | Onderhoudsaanroepen voor meerdere regio's uitvoeren in postBatchMutateIndispensably |
| BUG-97145 | HIVE-12245, HIVE-17829 | Ondersteuning voor kolomopmerkingen voor een tabel met HBase-ondersteuning |
| BUG-97409 | HADOOP-15255 | Ondersteuning voor conversie van hoofdletters/kleine letters voor groepsnamen in LdapGroupsMapping |
| BUG-97535 | HIVE-18710 | inheritPerms uitbreiden naar ACID in Hive 2.X |
| BUG-97742 | OOZIE-1624 | Uitsluitingspatroon voor sharelib JAR's |
| BUG-97744 | PHOENIX-3994 | De prioriteit index RPC is nog steeds afhankelijk van de eigenschap controllerfactory in hbase-site.xml |
| BUG-97787 | HIVE-18460 | Tabeleigenschappen worden niet doorgegeven aan de Orc Writer |
| BUG-97788 | HIVE-18613 | JsonSerDe uitbreiden ter ondersteuning van binair type |
| BUG-97899 | HIVE-18808 | Compressie robuuster maken wanneer het bijwerken van statistieken mislukt |
| BUG-98038 | HIVE-18788 | Invoer opschonen in JDBC PreparedStatement |
| BUG-98383 | HIVE-18907 | Hulpprogramma maken voor het oplossen van probleem met de acid key-index van HIVE-18817 |
| BUG-98388 | RANGER-1828 | Goede codering om meer headers toe te voegen in ranger |
| BUG-98392 | RANGER-2007 | Kerberos-ticket van ranger-tagsync kan niet worden vernieuwd |
| BUG-98533 | HBASE-19934, HBASE-20008 | Herstellen van HBase-momentopname mislukt vanwege een null-aanwijzer-uitzondering |
| BUG-98552 | HBASE-18083, HBASE-18084 | Groot/klein bestand schoon threadnummer configureerbaar maken in HFileCleaner |
| BUG-98705 | KNOX-1230 | Veel gelijktijdige aanvragen veroorzaken Knox URL-mangling |
| BUG-98711 | N.v.t. | NiFi-verzending kan geen tweerichtings-SSL gebruiken zonder service.xml wijzigingen |
| BUG-98880 | OOZIE-3199 | Systeemeigenschapsbeperking configureren |
| BUG-98931 | ATLAS-2491 | Hive-hook bijwerken om Atlas v2-meldingen te gebruiken |
| BUG-98983 | KNOX-1108 | NiFiHaDispatch mislukte failover |
| BUG-99088 | ATLAS-2511 | Opties opgeven voor het selectief importeren van database/tabellen uit Hive in Atlas |
| BUG-99154 | OOZIE-2844, OOZIE-2845, OOZIE-2858, OOZIE-2885 | Spark-query is mislukt met de uitzondering 'java.io.FileNotFoundException: hive-site.xml (machtiging geweigerd)' |
| BUG-99239 | ATLAS-2462 | Sqoop-import voor alle tabellen genereert NPE voor geen tabel opgegeven in de opdracht |
| BUG-99636 | KNOX-1238 | Aangepaste Truststore-Instellingen voor gateway herstellen |
| BUG-99650 | KNOX-1223 | De proxy van Knox Zeppelin leidt /api/ticket niet om zoals verwacht |
| BUG-99804 | OOZIE-2858 | HiveMain, ShellMain en SparkMain mogen de eigenschappen en configuratiebestanden niet lokaal overschrijven |
| BUG-99805 | OOZIE-2885 | Voor het uitvoeren van Spark-acties is Hive niet nodig in het klassepad |
| BUG-99806 | OOZIE-2845 | Code op basis van weerspiegeling vervangen, waarmee een variabele in HiveConf wordt ingesteld |
| BUG-99807 | OOZIE-2844 | De stabiliteit van Oozie-acties vergroten wanneer log4j.properties ontbreekt of niet leesbaar is |
| RMP-9995 | AMBARI-22222 | Switch druid to use /var/druid directory in plaats van /apps/druid on local disk |
Gedragswijzigingen
| Apache-onderdeel | Apache JIRA | Samenvatting | DETAILS |
|---|---|---|---|
| Spark 2.3 | N.v.t. | Wijzigingen zoals beschreven in de opmerkingen bij de Apache Spark-release | - Er is een document 'Afschaffing' en een handleiding 'Gedrag wijzigen', https://spark.apache.org/releases/spark-release-2-3-0.html#deprecations - Voor SQL-gedeelte is er nog een gedetailleerde handleiding voor migratie (van 2.2 tot 2.3), https://spark.apache.org/docs/latest/sql-programming-guide.html#upgrading-from-spark-sql-22-to-23| |
| Spark | HIVE-12505 | Spark-taak is voltooid, maar er is een volledige fout met het HDFS-schijfquotum | Scenario: het uitvoeren van insert overschrijven wanneer een quotum is ingesteld op de prullenbak van de gebruiker die de opdracht uitvoert. Vorig gedrag: de taak slaagt, ook al worden de gegevens niet verplaatst naar de Prullenbak. Het resultaat kan ten onrechte enkele gegevens bevatten die eerder in de tabel aanwezig waren. Nieuw gedrag: wanneer de verplaatsing naar de prullenbak mislukt, worden de bestanden definitief verwijderd. |
| Kafka 1.0 | N.v.t. | Wijzigingen zoals beschreven in de opmerkingen bij de Apache Spark-release | https://kafka.apache.org/10/documentation.html#upgrade_100_notable |
| Hive/Ranger | Ander hive-beleid voor ranger dat is vereist voor INSERT OVERWRITE | Scenario: Een ander bereik hive-beleid vereist voor INSERT OVERWRITE Vorig gedrag: Hive INSERT OVERWRITE-query's slagen zoals gebruikelijk. Nieuw gedrag: Hive INSERT OVERWRITE-query's mislukken onverwacht na een upgrade naar HDP-2.6.x met de volgende fout: Fout bij het compileren van de instructie: FAILED: HiveAccessControlException Permission denied: user jdoe heeft geen schrijfbevoegdheden op /tmp/*(state=42000,code=40000) Vanaf HDP-2.6.0 vereisen Hive INSERT OVERWRITE-query's een Ranger-URI-beleid om schrijfbewerkingen toe te staan, zelfs als de gebruiker schrijfbevoegdheden heeft verleend via HDFS-beleid. Tijdelijke oplossing/verwachte klantactie: 1. Maak een nieuw beleid onder de Hive-opslagplaats. 2. Selecteer URI in de vervolgkeuzelijst waar u Database ziet. 3. Werk het pad bij (voorbeeld: /tmp/*) 4. Voeg de gebruikers en groep toe en sla deze op. 5. Voer de invoegquery opnieuw uit. |
|
| HDFS | N.v.t. | HDFS moet ondersteuning bieden voor meerdere KMS Uris |
Vorig gedrag: dfs.encryption.key.provider.uri-eigenschap is gebruikt voor het configureren van het KMS-providerpad. Nieuw gedrag: dfs.encryption.key.provider.uri is nu afgeschaft ten gunste van hadoop.security.key.provider.path om het KMS-providerpad te configureren. |
| Zeppelin | ZEPPELIN-3271 | Optie voor het uitschakelen van scheduler | Beïnvloed onderdeel: Zeppelin-Server Vorig gedrag: In eerdere versies van Zeppelin was er geen optie voor het uitschakelen van scheduler. Nieuw gedrag: standaard zien gebruikers scheduler niet meer, omdat deze standaard is uitgeschakeld. Tijdelijke oplossing/Verwachte klantactie: als u scheduler wilt inschakelen, moet u azeppelin.notebook.cron.enable met de waarde true toevoegen onder aangepaste zeppelin-site in Zeppelin-instellingen vanuit Ambari. |
Bekende problemen
HDInsight-integratie met ADLS Gen 2 : er zijn twee problemen met HDInsight ESP-clusters met behulp van Azure Data Lake Storage Gen 2 met gebruikersmappen en -machtigingen:
Startmappen voor gebruikers worden niet gemaakt op Hoofdknooppunt 1. Als tijdelijke oplossing maakt u de directory's handmatig en wijzigt u het eigendom van de upn van de desbetreffende gebruiker.
Machtigingen voor /hdp-directory zijn momenteel niet ingesteld op 751. Dit moet worden ingesteld op
chmod 751 /hdp chmod –R 755 /hdp/apps
Spark 2.3
[SPARK-23523][SQL] Onjuist resultaat veroorzaakt door de regel OptimizeMetadataOnlyQuery
[SPARK-23406] Bugs in stream-stream self-joins
Spark-voorbeeldnotebooks zijn niet beschikbaar wanneer Azure Data Lake Storage (Gen2) standaardopslag van het cluster is.
Enterprise Security Package
- Spark Thrift Server accepteert geen verbindingen van ODBC-clients.
Tijdelijke stappen:
- Wacht ongeveer 15 minuten nadat het cluster is gemaakt.
- Controleer de gebruikersinterface van ranger op het bestaan van hivesampletable_policy.
- Start de Spark-service opnieuw. STS-verbinding moet nu werken.
- Spark Thrift Server accepteert geen verbindingen van ODBC-clients.
Tijdelijke stappen:
Tijdelijke oplossing voor fout bij het controleren van de Ranger-service
RANGER-1607: Tijdelijke oplossing voor ranger-servicecontrolefouten tijdens een upgrade naar HDP 2.6.2 van eerdere HDP-versies.
Notitie
Alleen wanneer Ranger SSL is ingeschakeld.
Dit probleem doet zich voor wanneer u probeert een upgrade uit te voeren naar HDP-2.6.1 van eerdere HDP-versies via Ambari. Ambari gebruikt een curl-aanroep om een servicecontrole uit te voeren naar de Ranger-service in Ambari. Als de JDK-versie die wordt gebruikt door Ambari JDK-1.7 is, mislukt de curl-aanroep met de onderstaande fout:
curl: (35) error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failureDe reden voor deze fout is de tomcat-versie die wordt gebruikt in Ranger is Tomcat-7.0.7*. Het gebruik van JDK-1.7 conflicteert met standaardcoderingen in Tomcat-7.0.7*.
U kunt dit probleem op twee manieren oplossen:
Werk de JDK in Ambari bij van JDK-1.7 naar JDK-1.8 (zie de sectie JDK-versie wijzigen in de Ambari-referentiehandleiding).
Als u een JDK-1.7-omgeving wilt blijven ondersteunen:
Voeg de eigenschap ranger.tomcat.ciphers toe in de sectie ranger-admin-site in uw Ambari Ranger-configuratie met de onderstaande waarde:
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Als uw omgeving is geconfigureerd voor Ranger-KMS, voegt u de eigenschap ranger.tomcat.ciphers toe in de sectie theranger-kms-site in uw Ambari Ranger-configuratie met de onderstaande waarde:
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Notitie
De genoteerde waarden zijn werkende voorbeelden en zijn mogelijk niet indicatief voor uw omgeving. Zorg ervoor dat de manier waarop u deze eigenschappen instelt overeenkomt met de manier waarop uw omgeving is geconfigureerd.
RangerUI: Escape of policy condition text in the policy form
Beïnvloed onderdeel: Ranger
Beschrijving van het probleem
Als een gebruiker beleid wil maken met aangepaste beleidsvoorwaarden en de expressie of tekst speciale tekens bevat, werkt het afdwingen van beleid niet. Speciale tekens worden geconverteerd naar ASCII voordat u het beleid opslaat in de database.
Speciale tekens: & <> " ' '
De voorwaardetags.attributes['type']='abc' wordt bijvoorbeeld geconverteerd naar het volgende zodra het beleid is opgeslagen.
tags.attds[' dsds'] =' cssdfs'
U kunt de beleidsvoorwaarde met deze tekens zien door het beleid te openen in de bewerkingsmodus.
Tijdelijke oplossing
Optie 1: Beleid maken/bijwerken via Ranger REST API
REST-URL: http://< host>:6080/service/plugins/policies
Beleid maken met beleidsvoorwaarde:
In het volgende voorbeeld wordt beleid gemaakt met tags als tags-test en toegewezen aan een openbare groep met beleidsvoorwaarde astags.attr['type']=='abc' door alle hive-onderdeelmachtigingen te selecteren, zoals selecteren, bijwerken, maken, neerzetten, wijzigen, indexeren, vergrendelen, allemaal.
Voorbeeld:
curl -H "Content-Type: application/json" -X POST http://localhost:6080/service/plugins/policies -u admin:admin -d '{"policyType":"0","name":"P100","isEnabled":true,"isAuditEnabled":true,"description":"","resources":{"tag":{"values":["tags-test"],"isRecursive":"","isExcludes":false}},"policyItems":[{"groups":["public"],"conditions":[{"type":"accessed-after-expiry","values":[]},{"type":"tag-expression","values":["tags.attr['type']=='abc'"]}],"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}]}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"service":"tagdev"}'Bestaand beleid bijwerken met beleidsvoorwaarde:
In het volgende voorbeeld wordt het beleid bijgewerkt met tags als tags-test en wordt het toegewezen aan de groep 'public' met beleidsvoorwaarde astags.attr['type']=='abc' door alle machtigingen voor hive-onderdelen te selecteren, zoals selecteren, bijwerken, maken, neerzetten, wijzigen, indexeren, vergrendelen, allemaal.
REST-URL: http://< host-name>:6080/service/plugins/policies/<policy-id>
Voorbeeld:
curl -H "Content-Type: application/json" -X PUT http://localhost:6080/service/plugins/policies/18 -u admin:admin -d '{"id":18,"guid":"ea78a5ed-07a5-447a-978d-e636b0490a54","isEnabled":true,"createdBy":"Admin","updatedBy":"Admin","createTime":1490802077000,"updateTime":1490802077000,"version":1,"service":"tagdev","name":"P0101","policyType":0,"description":"","resourceSignature":"e5fdb911a25aa7f77af5a9546938d9ed","isAuditEnabled":true,"resources":{"tag":{"values":["tags"],"isExcludes":false,"isRecursive":false}},"policyItems":[{"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}],"users":[],"groups":["public"],"conditions":[{"type":"ip-range","values":["tags.attributes['type']=abc"]}],"delegateAdmin":false}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"dataMaskPolicyItems":[],"rowFilterPolicyItems":[]}'Optie 2: JavaScript-wijzigingen toepassen
Stappen voor het bijwerken van JS-bestand:
Ontdek PermissionList.js bestand onder /usr/hdp/current/ranger-admin
Ontdek de definitie van de functie renderPolicyCondtion (regel nr: 404).
Verwijder de volgende regel uit die functie, bijvoorbeeld onder weergavefunctie (regel nr: 434)
val = _.escape(val);//Regel nr:460
Nadat u de bovenstaande regel hebt verwijderd, kunt u met de ranger-gebruikersinterface beleidsregels maken met een beleidsvoorwaarde die speciale tekens kan bevatten en de beleidsevaluatie voor hetzelfde beleid is geslaagd.
HDInsight-integratie met ADLS Gen 2: probleem met gebruikersmappen en machtigingen met ESP-clusters 1. Startmappen voor gebruikers worden niet gemaakt op Hoofdknooppunt 1. Tijdelijke oplossing is om deze handmatig te maken en het eigendom te wijzigen van de UPN van de desbetreffende gebruiker. 2. Machtigingen voor /hdp zijn momenteel niet ingesteld op 751. Dit moet worden ingesteld op a. chmod 751 /hdp b. chmod –R 755 /hdp/apps
Afschaffing
OMS-portal: de koppeling is verwijderd van de RESOURCEpagina van HDInsight die verwijst naar de OMS-portal. Azure Monitor-logboeken gebruikten aanvankelijk een eigen portal, de OMS-portal genoemd, om de configuratie te beheren en verzamelde gegevens te analyseren. Alle functionaliteit van deze portal is verplaatst naar De Azure-portal waar deze verder wordt ontwikkeld. HDInsight heeft de ondersteuning voor de OMS-portal afgeschaft. Klanten gebruiken de integratie van HDInsight Azure Monitor-logboeken in Azure Portal.
Spark 2.3:Spark Release 2.3.0-afschaffingen
Upgraden
Al deze functies zijn beschikbaar in HDInsight 3.6. Als u de nieuwste versie van Spark, Kafka en R Server (Machine Learning Services) wilt ophalen, kiest u de Spark-, Kafka-, ML Services-versie wanneer u een HDInsight 3.6-cluster maakt. Als u ondersteuning voor ADLS wilt krijgen, kunt u het ADLS-opslagtype als optie kiezen. Bestaande clusters worden niet automatisch bijgewerkt naar deze versies.
Alle nieuwe clusters die na juni 2018 zijn gemaakt, krijgen automatisch de oplossingen voor 1000+ fouten in alle opensource-projecten. Volg deze handleiding voor aanbevolen procedures voor het upgraden naar een nieuwere HDInsight-versie.