Concepten voor hoge beschikbaarheid voor Azure Database for MySQL - Flexibele server
VAN TOEPASSING OP: Azure Database for MySQL - Flexibele server
Azure Database for MySQL - Flexibele server
Met flexibele Azure Database for MySQL-server kunt u hoge beschikbaarheid configureren met automatische failover. De oplossing met hoge beschikbaarheid is ontworpen om ervoor te zorgen dat vastgelegde gegevens nooit verloren gaan als gevolg van storingen en dat de database geen Single Point of Failure in uw softwarearchitectuur is. Wanneer hoge beschikbaarheid is geconfigureerd, richt flexibele server automatisch een stand-byreplica in en beheert deze. U wordt gefactureerd voor de ingerichte rekenkracht en opslag voor zowel de primaire als de secundaire replica. Er zijn twee architectuurmodellen voor hoge beschikbaarheid:
Zone-redundante hoge beschikbaarheid. Deze optie heeft de voorkeur voor volledige isolatie en redundantie van infrastructuur in meerdere beschikbaarheidszones. Het biedt het hoogste beschikbaarheidsniveau, maar hiervoor moet u toepassingsredundantie tussen zones configureren. Zone-redundante hoge beschikbaarheid heeft de voorkeur wanneer u het hoogste beschikbaarheidsniveau wilt bereiken op basis van infrastructuurfouten in de beschikbaarheidszone en wanneer latentie in de beschikbaarheidszone acceptabel is. Deze kan alleen worden ingeschakeld wanneer de server wordt gemaakt. Zone-redundante hoge beschikbaarheid is beschikbaar in een subset van Azure-regio's waar de regio ondersteuning biedt voor meerdere beschikbaarheidszones en zone-redundante Premium-bestandsshares beschikbaar zijn.
Dezelfde zone HA. Deze optie heeft de voorkeur voor infrastructuurredundantie met lagere netwerklatentie, omdat de primaire en stand-byservers zich in dezelfde beschikbaarheidszone bevinden. Het biedt hoge beschikbaarheid zonder dat u toepassingsredundantie tussen zones hoeft te configureren. Hoge beschikbaarheid van dezelfde zone heeft de voorkeur wanneer u het hoogste beschikbaarheidsniveau binnen één beschikbaarheidszone met de laagste netwerklatentie wilt bereiken. Hoge beschikbaarheid van dezelfde zone is beschikbaar in alle Azure-regio's waar u azure Database for MySQL flexibele server kunt gebruiken.
Zone-redundante HA-architectuur
Wanneer u een server met zone-redundante hoge beschikbaarheid implementeert, worden er twee servers gemaakt:
- Een primaire server in één beschikbaarheidszone.
- Een stand-byreplicaserver met dezelfde configuratie als de primaire server (rekenlaag, rekenkracht, opslaggrootte en netwerkconfiguratie) in een andere beschikbaarheidszone van dezelfde Azure-regio.
U kunt de beschikbaarheidszone voor de primaire en de stand-byreplica kiezen. Het plaatsen van de stand-bydatabaseservers en stand-bytoepassingen in dezelfde zone vermindert de latentie. Hiermee kunt u zich ook beter voorbereiden op situaties met herstel na noodgevallen en 'zone down'-scenario's.
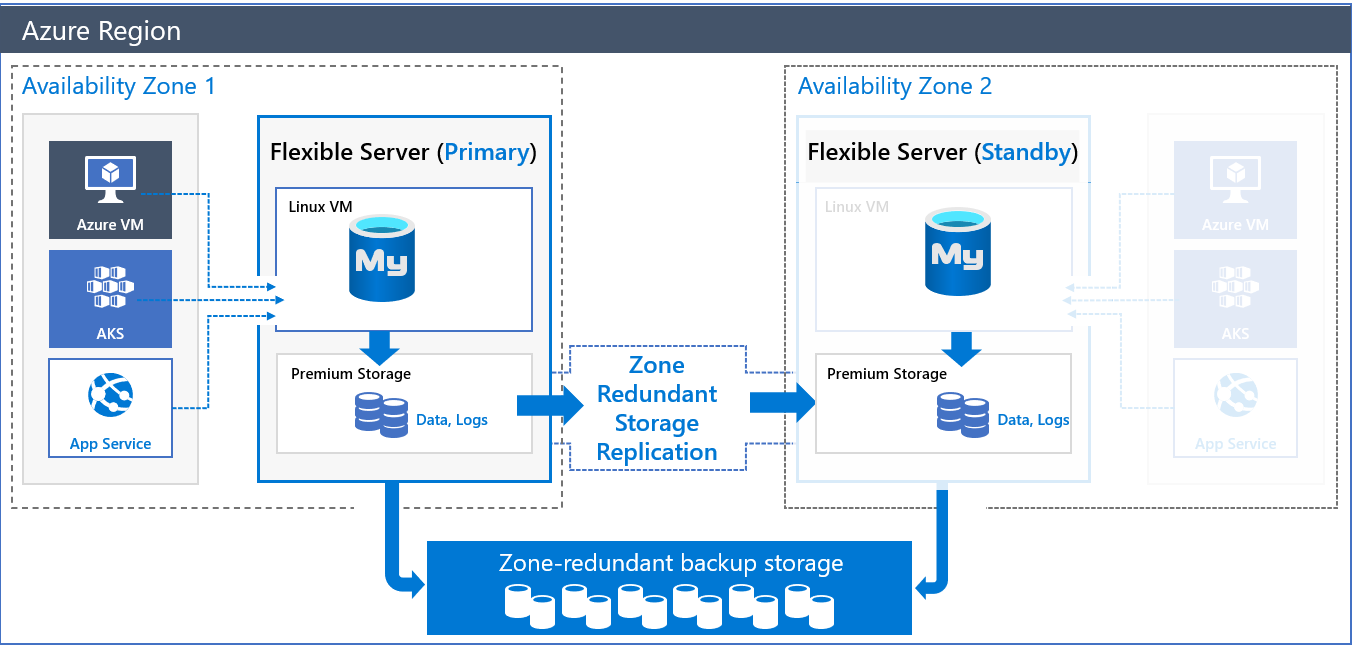
De gegevens en logboekbestanden worden gehost in zone-redundante opslag (ZRS). De stand-byserver leest en afspeelt de logboekbestanden continu vanuit het opslagaccount van de primaire server, dat wordt beveiligd door replicatie op opslagniveau.
Als er een failover is:
- De stand-byreplica is geactiveerd.
- De binaire logboekbestanden van de primaire server blijven van toepassing op de stand-byserver om deze online te brengen naar de laatste doorgevoerde transactie op de primaire server.
Logboeken in ZRS zijn toegankelijk, zelfs wanneer de primaire server niet beschikbaar is. Deze beschikbaarheid helpt ervoor te zorgen dat er geen gegevens verloren gaan. Nadat de stand-byreplica is geactiveerd en binaire logboeken zijn toegepast, neemt de huidige stand-byreplicaserver de rol van de primaire server. DNS wordt bijgewerkt zodat clientverbindingen worden omgeleid naar de nieuwe primaire server wanneer de client opnieuw verbinding maakt. De failover is volledig transparant vanuit de clienttoepassing en vereist geen actie van u. De ha-oplossing brengt vervolgens de oude primaire server indien mogelijk terug en plaatst deze als stand-by.
De naam van de databaseserver wordt gebruikt om toepassingen te verbinden met de primaire server. Informatie over stand-byreplica's wordt niet weergegeven voor directe toegang. Doorvoeringen en schrijfbewerkingen worden bevestigd nadat de logboekbestanden zijn leeggemaakt op de ZRS van de primaire server. Vanwege de synchronisatiereplicatietechnologie die wordt gebruikt in ZRS-opslag, kunt u 5-10 procent hogere latentie verwachten voor schrijf- en doorvoerbewerkingen van toepassingen.
Automatische back-ups, zowel momentopnamen als logboekback-ups, worden uitgevoerd op zone-redundante opslag vanaf de primaire databaseserver.
Architectuur voor hoge beschikbaarheid van dezelfde zone
Wanneer u een server met dezelfde zone-hoge beschikbaarheid implementeert, worden er twee servers gemaakt in dezelfde zone:
- Een primaire server
- Een stand-byreplicaserver met dezelfde configuratie als de primaire server (rekenlaag, rekenkracht, opslaggrootte en netwerkconfiguratie)
De stand-byserver biedt infrastructuurredundantie met een afzonderlijke virtuele machine (compute). Deze redundantie vermindert de failovertijd en netwerklatentie tussen de toepassing en de databaseserver vanwege colocatie.
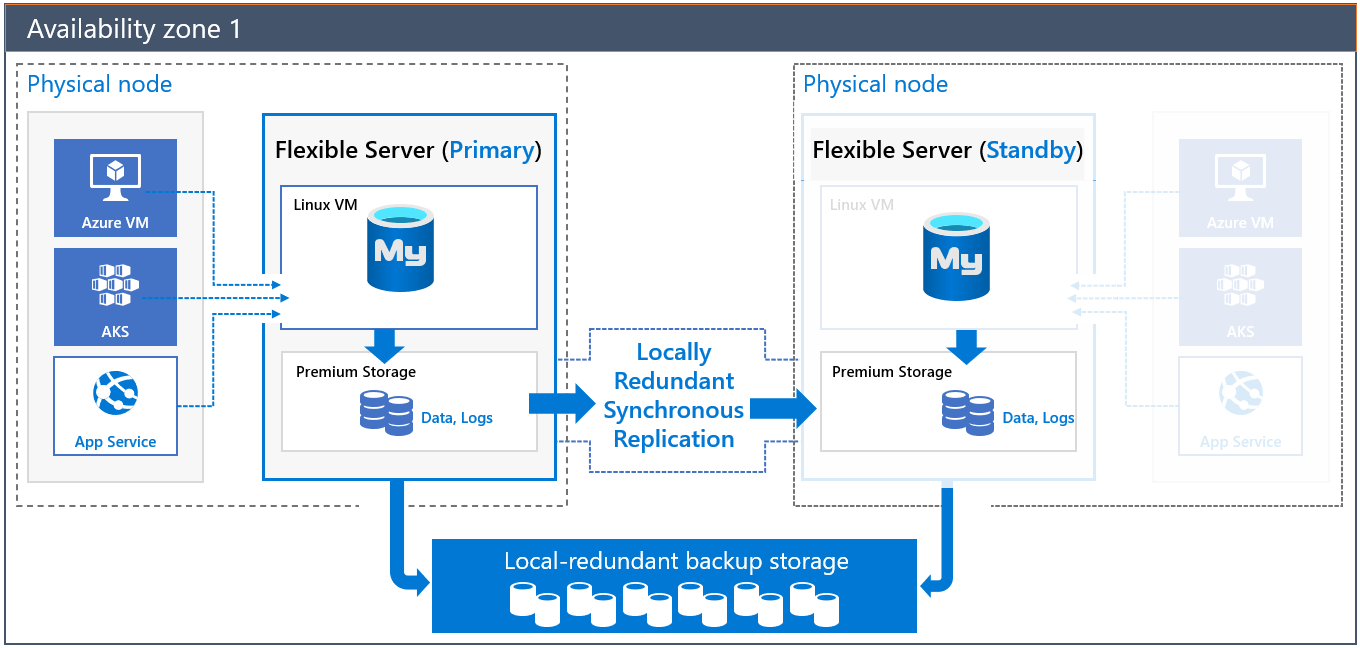
De gegevens en logboekbestanden worden gehost in lokaal redundante opslag (LRS). De stand-byserver leest en afspeelt de logboekbestanden continu vanuit het opslagaccount van de primaire server, dat wordt beveiligd door replicatie op opslagniveau.
Als er een failover is:
- De stand-byreplica is geactiveerd.
- De binaire logboekbestanden van de primaire server blijven van toepassing op de stand-byserver om deze online te brengen naar de laatste doorgevoerde transactie op de primaire server.
Logboeken in LRS zijn toegankelijk, zelfs wanneer de primaire server niet beschikbaar is. Deze beschikbaarheid helpt ervoor te zorgen dat er geen gegevens verloren gaan. Nadat de stand-byreplica is geactiveerd en binaire logboeken zijn toegepast, neemt de huidige stand-byreplica de rol van de primaire server. DNS wordt bijgewerkt om verbindingen om te leiden naar de nieuwe primaire server wanneer de client opnieuw verbinding maakt. De failover is volledig transparant vanuit de clienttoepassing en vereist geen actie van u. De ha-oplossing brengt vervolgens de oude primaire server indien mogelijk terug en plaatst deze als stand-by.
De naam van de databaseserver wordt gebruikt om toepassingen te verbinden met de primaire server. Informatie over stand-byreplica's wordt niet weergegeven voor directe toegang. Doorvoeringen en schrijfbewerkingen worden bevestigd nadat de logboekbestanden zijn leeggemaakt op de LRS van de primaire server. Omdat de primaire replica en de stand-byreplica zich in dezelfde zone bevinden, is er minder replicatievertraging en lagere latentie tussen de toepassingsserver en de databaseserver. De installatie van dezelfde zone biedt geen hoge beschikbaarheid wanneer afhankelijke infrastructuren uitvalt voor de specifieke beschikbaarheidszone. Er is downtime totdat alle afhankelijke services weer online zijn voor die beschikbaarheidszone.
Automatische back-ups, zowel momentopnamen als logboekback-ups, worden uitgevoerd op lokaal redundante opslag vanaf de primaire databaseserver.
Notitie
Voor zowel zone-redundante als dezelfde zone-HA:
- Als er een fout optreedt, is de tijd die nodig is om de rol van primaire replica over te nemen, afhankelijk van de tijd die nodig is om het binaire logboek van het primaire opslagaccount opnieuw af te spelen naar de stand-by. Daarom raden we u aan primaire sleutels in alle tabellen te gebruiken om de failovertijd te verminderen. Failovertijden liggen doorgaans tussen 60 en 120 seconden.
- De stand-byserver is niet beschikbaar voor lees- of schrijfbewerkingen. Het is een passieve stand-by om snelle failover mogelijk te maken.
- Gebruik altijd een FQDN (Fully Qualified Domain Name) om verbinding te maken met uw primaire server. Vermijd het gebruik van een IP-adres om verbinding te maken. Als er een failover is, kan een DNS A-record veranderen nadat de primaire en stand-byserverfuncties zijn gewijzigd. Deze wijziging voorkomt dat de toepassing verbinding maakt met de nieuwe primaire server als er een IP-adres wordt gebruikt in de verbindingsreeks.
Failoverproces
Gepland: geforceerde failover
Met geforceerde failover van azure Database for MySQL kunt u handmatig een failover afdwingen. Met deze mogelijkheid kunt u de functionaliteit testen met uw toepassingsscenario's en kunt u klaar zijn voor storingen.
Geforceerde failover activeert een failover die de stand-byreplica activeert om de primaire server met dezelfde databaseservernaam te worden door de DNS-record bij te werken. De oorspronkelijke primaire server wordt opnieuw opgestart en overgeschakeld naar de stand-byreplica. Clientverbindingen worden verbroken en moeten opnieuw worden verbonden om de bewerkingen te hervatten.
De totale failovertijd is afhankelijk van de huidige workload en het laatste controlepunt. Over het algemeen duurt dit naar verwachting tussen 60 en 120 seconden.
Notitie
De Azure Resource Health-gebeurtenis wordt gegenereerd in het geval van geplande failover, die de failovertijd vertegenwoordigt waarin de server niet beschikbaar was. De geactiveerde gebeurtenissen kunnen worden weergegeven wanneer u in het linkerdeelvenster op Resource Health klikt. Door de gebruiker geïnitieerde/handmatige failover wordt vertegenwoordigd door de status Niet beschikbaar en gemarkeerd als Gepland. Voorbeeld: 'Er is een failoverbewerking geactiveerd door een geautoriseerde gebruiker (gepland)'. Als uw resource gedurende langere tijd in deze status blijft staan, opent u een ondersteuningsticket en helpen wij u.
Niet-gepland: automatische failover
Niet-geplande service-downtime kan worden veroorzaakt door softwarefouten of infrastructuurfouten, zoals reken-, netwerk- of opslagfouten, of stroomstoringen die van invloed zijn op de beschikbaarheid van de database. Als de database onbeschikbaar wordt, wordt replicatie naar de stand-byreplica verbroken en wordt de stand-byreplica geactiveerd als de primaire databaseserver. DNS wordt bijgewerkt en clients maken opnieuw verbinding met de databaseserver en hervatten hun bewerkingen.
De totale failovertijd ligt naar verwachting tussen 60 en 120 seconden. Afhankelijk van de activiteit op de primaire databaseserver op het moment van de failover (zoals grote transacties en hersteltijd), kan de failover echter langer duren.
Notitie
Azure Resource Health-gebeurtenis wordt gegenereerd in het geval van niet-geplande failover, die de failovertijd vertegenwoordigt waarin de server niet beschikbaar was. De geactiveerde gebeurtenissen kunnen worden weergegeven wanneer u in het linkerdeelvenster op Resource Health klikt. Automatische failover wordt vertegenwoordigd door de status Niet beschikbaar en gelabeld als Niet-gepland. Voorbeeld: 'Niet beschikbaar: er is automatisch een failoverbewerking geactiveerd (niet-gepland)'. Als uw resource gedurende langere tijd in deze status blijft staan, opent u een ondersteuningsticket en helpen wij u.
Hoe automatische failoverdetectie werkt op servers met hoge beschikbaarheid
De primaire server en de secundaire server hebben twee netwerkeindpunten.
- Klanteindpunt: Klant maakt verbinding met en voert query's uit op het exemplaar met behulp van dit eindpunt.
- Beheereindpunt: intern gebruikt voor servicecommunicatie naar beheeronderdelen en om verbinding te maken met back-endopslag.
Het onderdeel statuscontrole voert continu de volgende controles uit
- De monitor pingt naar het eindpunt van het beheernetwerk van de knooppunten. Als deze controle twee keer continu mislukt, wordt automatische failover-bewerking geactiveerd. Het scenario zoals het knooppunt reageert niet of niet reageert vanwege een probleem met het besturingssysteem, het netwerkprobleem tussen beheeronderdelen en knooppunten, wordt opgelost door deze statuscontrole.
- De monitor voert ook een eenvoudige query uit op het exemplaar. Als de query's niet worden uitgevoerd, wordt automatische failover geactiveerd. De scenario's zoals MySQL-demon zijn vastgelopen/gestopt/vastgelopen, back-endopslagprobleem, enzovoort, worden opgelost door deze statuscontrole.
Notitie
Als er een netwerkprobleem is tussen de toepassing en het eindpunt voor het netwerk van de klant (privé-/openbare toegang), hetzij in het netwerkpad, op het eindpunt of dns-problemen aan de clientzijde, controleert de statuscontrole dit scenario niet. Als u privétoegang gebruikt, moet u ervoor zorgen dat de NSG-regels voor het VNet de communicatie met het eindpunt van het klantnetwerk van het exemplaar op poort 3306 niet blokkeert. Voor openbare toegang moet u ervoor zorgen dat de firewallregels zijn ingesteld en dat netwerkverkeer is toegestaan op poort 3306 (als het netwerkpad andere firewalls heeft). De DNS-omzetting van de clienttoepassingszijde moet ook worden uitgevoerd.
Bewaking voor hoge beschikbaarheid
De hoge beschikbaarheidsstatus in het deelvenster Hoge beschikbaarheid van de server in de portal kan worden gebruikt om de hoge beschikbaarheidsstatus van de server te bepalen.
| -Status | Beschrijving |
|---|---|
| NotEnabled | Hoge beschikbaarheid is niet ingeschakeld. |
| ReplicatingData | Stand-byserver wordt gesynchroniseerd met de primaire server op het moment van inrichting van ha-servers of wanneer de optie HA is ingeschakeld. |
| FailOver | De databaseserver is bezig met het uitvoeren van een failover van de primaire server naar de stand-by. |
| Gezonde | De optie HA is ingeschakeld. |
| Standby verwijderen | Wanneer de optie HA is uitgeschakeld en het verwijderingsproces wordt uitgevoerd. |
U kunt ook de onderstaande metrische gegevens gebruiken om de status van de HA-server te bewaken.
| Weergavenaam voor metrische gegevens | Metric | Eenheid | Beschrijving |
|---|---|---|---|
| I/O-status hoge beschikbaarheid | ha_io_running | Staat | HOGE IO-status geeft de status van ha-replicatie aan. De metrische waarde is 1 als de I/O-thread wordt uitgevoerd en 0 als dat niet het resultaat is. |
| HOGE SQL-status | ha_sql_running | Staat | HOGE SQL-status geeft de status van ha-replicatie aan. De metrische waarde is 1 als de SQL-thread wordt uitgevoerd en 0 als dat niet het resultaat is. |
| Ha-replicatievertraging | replication_lag | Seconden | Replicatievertraging is het aantal seconden dat de stand-by zich bevindt bij het opnieuw afspelen van de transacties die zijn ontvangen op de primaire server. |
Beperkingen
Hier volgen enkele overwegingen waarmee u rekening moet houden wanneer u hoge beschikbaarheid gebruikt:
- Zone-redundante hoge beschikbaarheid kan alleen worden ingesteld wanneer de flexibele server wordt gemaakt.
- Hoge beschikbaarheid wordt niet ondersteund in de burstable compute-laag.
- Als de primaire databaseserver opnieuw wordt opgestart om gewijzigde statische parameters op te halen, wordt ook de stand-byreplica opnieuw opgestart.
- DE GTID-modus wordt ingeschakeld omdat de HA-oplossing GTID gebruikt. Controleer of uw workload beperkingen heeft voor replicatie met GTID's.
Notitie
Als u dezelfde zone HA inschakelt na het maken van de server, moet u ervoor zorgen dat de serverparameters enforce_gtid_consistency' en 'gtid_mode' is ingesteld op AAN voordat u HA inschakelt.
Notitie
Automatische groei van opslag is standaard ingeschakeld voor een geconfigureerde server met hoge beschikbaarheid en kan niet worden uitgeschakeld.
Veelgestelde vragen
Wat zijn de SLA's voor dezelfde zone versus zone-redundante flexibele server met hoge beschikbaarheid?
SLA-informatie voor flexibele Azure Database for MySQL-server vindt u in sla voor Azure Database for MySQL.
Hoe wordt er gefactureerd voor hoge beschikbare (HA)-servers? Servers geschikt voor hoge beschikbaarheid hebben primaire en secundaire replica. Secundaire replica's kunnen zich in dezelfde zone bevinden of zoneredundant zijn. U wordt gefactureerd voor de ingerichte rekenkracht en opslag voor zowel de primaire als de secundaire replica. Als u bijvoorbeeld een primaire replica hebt met 4 vCores voor rekenkracht en 512 GB aan ingerichte opslag, heeft uw secundaire replica ook 4 vCores en 512 GB aan ingerichte opslag. Uw zone-redundante server met hoge beschikbaarheid wordt gefactureerd voor 8 vCores en 1024 GB aan opslag. Afhankelijk van het volume van uw back-upopslag, wordt u mogelijk ook gefactureerd voor back-upopslag.
Kan ik de stand-byreplica gebruiken voor lees- of schrijfbewerkingen? De stand-byserver is niet beschikbaar voor lees- of schrijfbewerkingen. Het is een passieve stand-by om snelle failover mogelijk te maken.
Zal ik gegevensverlies hebben wanneer er een failover plaatsvindt? Logboeken in ZRS zijn toegankelijk, zelfs wanneer de primaire server niet beschikbaar is. Deze beschikbaarheid helpt ervoor te zorgen dat er geen gegevens verloren gaan. Nadat de stand-byreplica is geactiveerd en binaire logboeken zijn toegepast, wordt de rol van de primaire server gebruikt.
Moet ik actie ondernemen na een failover? Failovers zijn volledig transparant vanuit de clienttoepassing. U hoeft geen actie te ondernemen. Toepassingen moeten alleen de logica voor opnieuw proberen gebruiken voor hun verbindingen.
Wat gebeurt er wanneer ik geen specifieke zone voor mijn stand-byreplica kies? Kan ik de zone later wijzigen? Als u geen zone kiest, wordt er een willekeurig geselecteerd. Dit wordt gebruikt voor de primaire server. Als u de zone later wilt wijzigen, kunt u hoge beschikbaarheid instellen op Uitgeschakeld in het deelvenster Hoge beschikbaarheid en deze vervolgens weer instellen op Zoneredundant en een zone kiezen.
Is replicatie tussen de primaire en stand-byreplica's synchroon? De replicatie tussen de primaire en de stand-by is vergelijkbaar met de semisynchrone modus in MySQL. Wanneer een transactie wordt doorgevoerd, wordt deze niet noodzakelijkerwijs doorgevoerd in de stand-by. Maar als de primaire niet beschikbaar is, repliceert de stand-by alle gegevenswijzigingen van de primaire machine om ervoor te zorgen dat er geen gegevensverlies is.
Is er een failover naar de stand-byreplica voor alle ongeplande fouten? Als er een databasecrash of knooppuntfout optreedt, wordt de vm met flexibele servers opnieuw opgestart op hetzelfde knooppunt. Tegelijkertijd wordt een automatische failover geactiveerd. Als het opnieuw opstarten van de vm met flexibele server is voltooid voordat de failover is voltooid, wordt de failoverbewerking geannuleerd. De bepaling van welke server moet worden gebruikt als de primaire replica, is afhankelijk van het proces dat het eerst wordt voltooid.
Is er een invloed op de prestaties wanneer ik hoge beschikbaarheid gebruik? Voor zone-redundante hoge beschikbaarheid, terwijl er geen grote invloed is op de prestaties van leesworkloads in beschikbaarheidszones, kan er tot 40 procent afnemen in de latentie van schrijfquery's. De toename van de schrijflatentie wordt veroorzaakt door synchrone replicatie in de beschikbaarheidszone. De impact van de schrijflatentie is over het algemeen twee keer in zone-redundante ha in vergelijking met dezelfde zone-HA. Voor hoge beschikbaarheid van dezelfde zone, omdat de primaire replica en de stand-byreplica zich in dezelfde zone bevinden, is de replicatielatentie en dus de synchrone schrijflatentie lager. Kortom, als schrijflatentie belangrijker is voor u in vergelijking met beschikbaarheid, kunt u dezelfde zone-HOGE beschikbaarheid kiezen, maar als beschikbaarheid en tolerantie van uw gegevens belangrijker zijn voor u ten koste van de daling van schrijflatentie, moet u zone-redundante hoge beschikbaarheid kiezen. Voor het meten van de nauwkeurige impact van de latentievermindering in de ha-installatie raden we u aan om prestatietests uit te voeren voor uw workload om een weloverwogen beslissing te nemen.
Hoe gebeurt het onderhoud van mijn HA-server? Geplande gebeurtenissen, zoals het schalen van reken- en secundaire versie-upgrades, vinden eerst plaats op het oorspronkelijke stand-byexemplaren, gevolgd door het activeren van een geplande failoverbewerking en werken vervolgens op het oorspronkelijke primaire exemplaar. U kunt het geplande onderhoudsvenster voor HA-servers instellen zoals u dat doet voor flexibele servers. De hoeveelheid downtime is hetzelfde als de downtime voor het flexibele serverexemplaren van Azure Database for MySQL wanneer hoge beschikbaarheid is uitgeschakeld.
Kan ik een herstel naar een bepaald tijdstip (PITR) van mijn HA-server uitvoeren? U kunt een PITR uitvoeren voor een azure Database for MySQL Flexible Server-exemplaar met hoge beschikbaarheid naar een nieuw exemplaar van een flexibele Azure Database for MySQL-server waarvoor hoge beschikbaarheid is uitgeschakeld. Als de bronserver is gemaakt met zone-redundante hoge beschikbaarheid, kunt u zone-redundante ha of dezelfde zone-ha later op de herstelde server inschakelen. Als de bronserver is gemaakt met dezelfde zone-HA, kunt u alleen dezelfde zone-HA inschakelen op de herstelde server.
Kan ik ha op een server inschakelen nadat ik de server heb gemaakt? Zone-redundante hoge beschikbaarheid moet worden ingeschakeld wanneer de server wordt gemaakt. U kunt dezelfde zone-HA inschakelen nadat u de server hebt gemaakt. Voordat u dezelfde zone-HA inschakelt, moet u ervoor zorgen dat de serverparameters enforce_gtid_consistency' en 'gtid_mode' zijn ingesteld op AAN
Kan ik HA uitschakelen voor een server nadat ik deze heb gemaakt? U kunt hoge beschikbaarheid op een server uitschakelen nadat u deze hebt gemaakt. Facturering stopt onmiddellijk.
Hoe kan ik downtime beperken? U moet downtime voor uw toepassing kunnen beperken, zelfs wanneer u geen hoge beschikbaarheid gebruikt. Service-downtime, zoals geplande patches, secundaire versie-upgrades of door de klant geïnitieerde bewerkingen, zoals het schalen van rekenkracht, kunnen worden uitgevoerd tijdens geplande onderhoudsvensters. Als u de impact van toepassingen voor door Azure geïnitieerde onderhoudstaken wilt beperken, kunt u deze plannen op een dag van de week en de tijd die de impact op de toepassing minimaliseert.
Kan ik een leesreplica gebruiken voor een server met hoge beschikbaarheid? Ja, leesreplica's worden ondersteund voor HA-servers.
Kan ik data-in-replicatie gebruiken voor HA-servers? Ondersteuning voor replicatie van inkomende gegevens voor server met hoge beschikbaarheid (HA) is alleen beschikbaar via replicatie op basis van GTID. De opgeslagen procedure voor replicatie met GTID is beschikbaar op alle servers met hoge beschikbaarheid op basis van de naam
mysql.az_replication_with_gtid.Om downtime te verminderen, kan ik tijdens het opnieuw opstarten van de server een failover naar de stand-byserver uitvoeren of omhoog of omlaag schalen? Op dit moment heeft azure Database for MySQL flexibele server geplande failover om de ha-bewerkingen te optmiseren, inclusief omhoog/omlaag schalen en gepland onderhoud om de downtime te verminderen. Wanneer dergelijke bewerkingen zijn gestart, wordt deze eerst uitgevoerd op het oorspronkelijke stand-by-exemplaar, gevolgd door een geplande failoverbewerking te activeren en vervolgens te werken op het oorspronkelijke primaire exemplaar.
Kunnen we de beschikbaarheidsmodus (zone-redundante HA/dezelfde zone) van de server wijzigen als u de server maakt waarvoor zone-redundante HA-modus is ingeschakeld, kunt u wijzigen van zone-redundante HA in dezelfde zone en omgekeerd. Als u de beschikbaarheidsmodus wilt wijzigen, kunt u hoge beschikbaarheidinstellen op Uitgeschakeld in het deelvenster Hoge beschikbaarheid en deze vervolgens weer instellen op Zoneredundant of dezelfde zone en de modus Hoge beschikbaarheid kiezen.
Volgende stappen
- Meer informatie over bedrijfscontinuïteit.
- Meer informatie over zone-redundante hoge beschikbaarheid.
- Meer informatie over back-up en herstel.