Power Query-connectors (preview - buiten gebruik gesteld)
Belangrijk
Power Query connectorondersteuning is geïntroduceerd als een beperkte openbare preview onder aanvullende gebruiksvoorwaarden voor Microsoft Azure Previews, maar wordt nu stopgezet. Als u een zoekoplossing hebt die gebruikmaakt van een Power Query-connector, migreert u naar een alternatieve oplossing.
Migreren uiterlijk 28 november 2022
De preview-versie van de Power Query connector is aangekondigd in mei 2021 en wordt niet algemeen beschikbaar. De volgende migratierichtlijnen zijn beschikbaar voor Snowflake en PostgreSQL. Als u een andere connector gebruikt en migratie-instructies nodig hebt, gebruikt u de contactgegevens per e-mail in uw preview-registratie om hulp te vragen of een ticket te openen bij Azure-ondersteuning.
Vereisten
- Een Azure Storage-account. Als u nog geen opslagaccount hebt, maakt u een opslagaccount.
- Een Azure Data Factory. Als u nog geen data factory hebt, maakt u een data factory. Zie Prijzen voor Data Factory-pijplijnen vóór de implementatie voor meer informatie over de bijbehorende kosten. Controleer ook de prijzen van Data Factory via voorbeelden.
Een Snowflake-gegevenspijplijn migreren
In deze sectie wordt uitgelegd hoe u gegevens kopieert van een Snowflake-database naar een Azure Cognitive Search-index. Er is geen proces voor het rechtstreeks indexeren van Snowflake naar Azure Cognitive Search, dus deze sectie bevat een faseringsfase waarmee database-inhoud wordt gekopieerd naar een Azure Storage-blobcontainer. Vervolgens indexeert u vanuit die faseringscontainer met behulp van een Data Factory-pijplijn.
Stap 1: Snowflake-databasegegevens ophalen
Ga naar Snowflake en meld u aan bij uw Snowflake-account. Een Snowflake-account ziet eruit als https://< account_name.snowflakecomputing.com>.
Zodra u bent aangemeld, verzamelt u de volgende informatie in het linkerdeelvenster. U gebruikt deze informatie in de volgende stap:
- Selecteer bij Gegevensde optie Databases en kopieer de naam van de databasebron.
- Selecteer in BeheerGebruikers & rollen en kopieer de naam van de gebruiker. Zorg ervoor dat de gebruiker leesmachtigingen heeft.
- Selecteer in BeheerAccounts en kopieer de LOCATOR-waarde van het account.
- Vanuit de Url van Snowflake, vergelijkbaar met
https://app.snowflake.com/<region_name>/xy12345/organization). kopieer de regionaam. In issouth-central-us.azurede regionaam bijvoorbeeldhttps://app.snowflake.com/south-central-us.azure/xy12345/organization. - Selecteer in BeheerMagazijnen en kopieer de naam van het magazijn dat is gekoppeld aan de database die u als bron wilt gebruiken.
Stap 2: De gekoppelde Snowflake-service configureren
Meld u aan bij Azure Data Factory Studio met uw Azure-account.
Selecteer uw data factory en selecteer vervolgens Doorgaan.
Selecteer in het linkermenu het pictogram Beheren .
Selecteer onder Gekoppelde servicesde optie Nieuw.

Voer in het rechterdeelvenster in de zoekfunctie voor het gegevensarchief 'snowflake' in. Selecteer de tegel Snowflake en selecteer Doorgaan.
Vul in het formulier Nieuwe gekoppelde service de gegevens in die u in de vorige stap hebt verzameld. De accountnaam bevat een LOCATOR-waarde en de regio (bijvoorbeeld:
xy56789south-central-us.azure).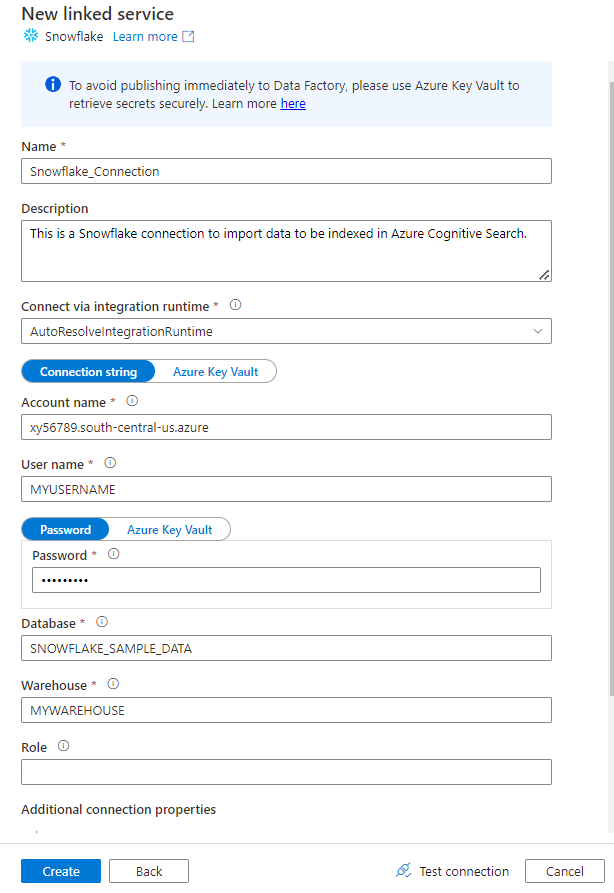
Nadat het formulier is ingevuld, selecteert u Verbinding testen.
Als de test is geslaagd, selecteert u Maken.
Stap 3: Snowflake-gegevensset configureren
Selecteer in het menu links het pictogram Auteur .
Selecteer Gegevenssets en selecteer vervolgens het menu Acties voor gegevenssets (
...).
Selecteer Nieuwe gegevensset.

Voer in het rechterdeelvenster in de zoekfunctie voor het gegevensarchief 'snowflake' in. Selecteer de tegel Snowflake en selecteer Doorgaan.

In Eigenschappen instellen:
- Selecteer de gekoppelde service die u in stap 2 hebt gemaakt.
- Selecteer de tabel die u wilt importeren en selecteer vervolgens OK.
Selecteer Opslaan.
Stap 4: een nieuwe index maken in Azure Cognitive Search
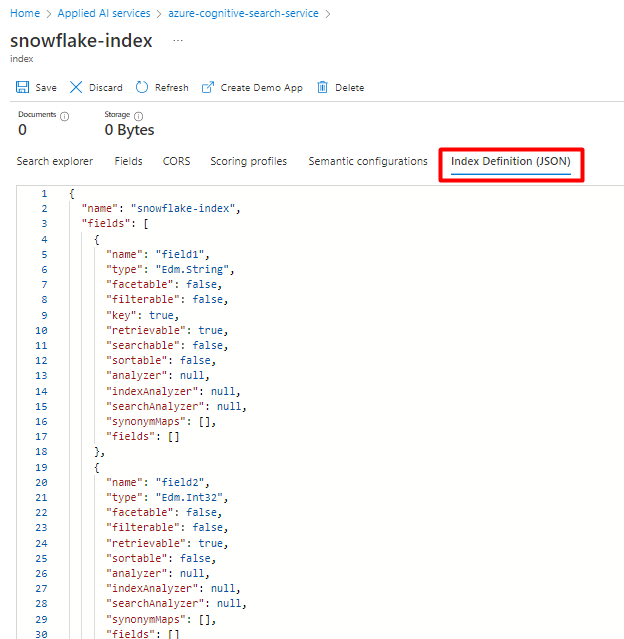
Maak een nieuwe index in uw Azure Cognitive Search-service met hetzelfde schema als het schema dat u momenteel hebt geconfigureerd voor uw Snowflake-gegevens.
U kunt het doel van de index die u momenteel gebruikt voor de Snowflake Power Connector wijzigen. Zoek in de Azure Portal de index en selecteer vervolgens Indexdefinitie (JSON). Selecteer de definitie en kopieer deze naar de hoofdtekst van uw nieuwe indexaanvraag.
Stap 5: Azure Cognitive Search gekoppelde service configureren
Selecteer in het linkermenu het pictogram Beheren .
Selecteer onder Gekoppelde servicesde optie Nieuw.
Voer in het rechterdeelvenster in de zoekopdracht voor het gegevensarchief 'zoeken' in. Selecteer de tegel Azure Search en selecteer Doorgaan.
Vul de waarden voor nieuwe gekoppelde service in:
- Kies het Azure-abonnement waarin uw Azure Cognitive Search service zich bevindt.
- Kies de Azure Cognitive Search-service met uw Power Query connectorindexeerfunctie.
- Selecteer Maken.
Stap 6: Azure Cognitive Search-gegevensset configureren
Selecteer in het menu links het pictogram Auteur .
Selecteer Gegevenssets en selecteer vervolgens het menu Acties voor gegevenssets (
...).
Selecteer Nieuwe gegevensset.
Voer in het rechterdeelvenster in de zoekopdracht voor het gegevensarchief 'zoeken' in. Selecteer de tegel Azure Search en selecteer Doorgaan.
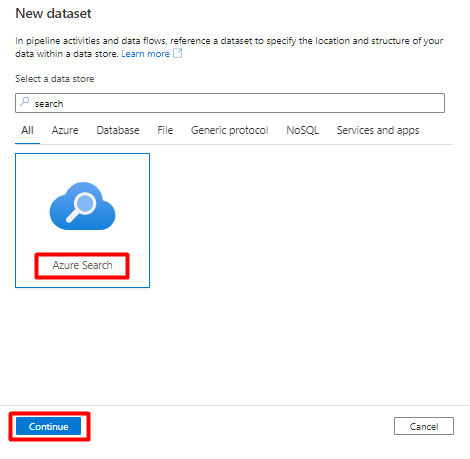
In Eigenschappen instellen:
Selecteer Opslaan.
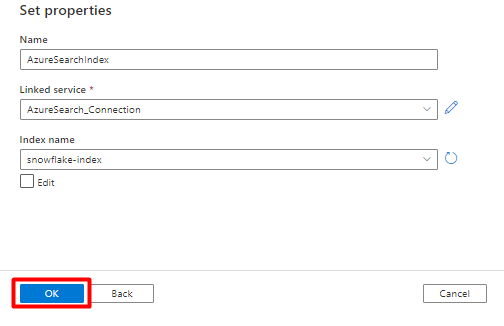
Stap 7: Azure Blob Storage gekoppelde service configureren
Selecteer in het linkermenu het pictogram Beheren .
Selecteer onder Gekoppelde servicesde optie Nieuw.
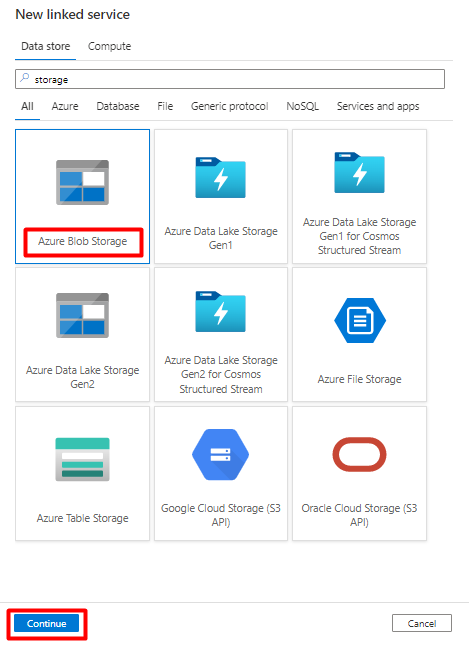
Voer in het rechterdeelvenster in de zoekopdracht voor het gegevensarchief 'opslag' in. Selecteer de tegel Azure Blob Storage en selecteer Doorgaan.
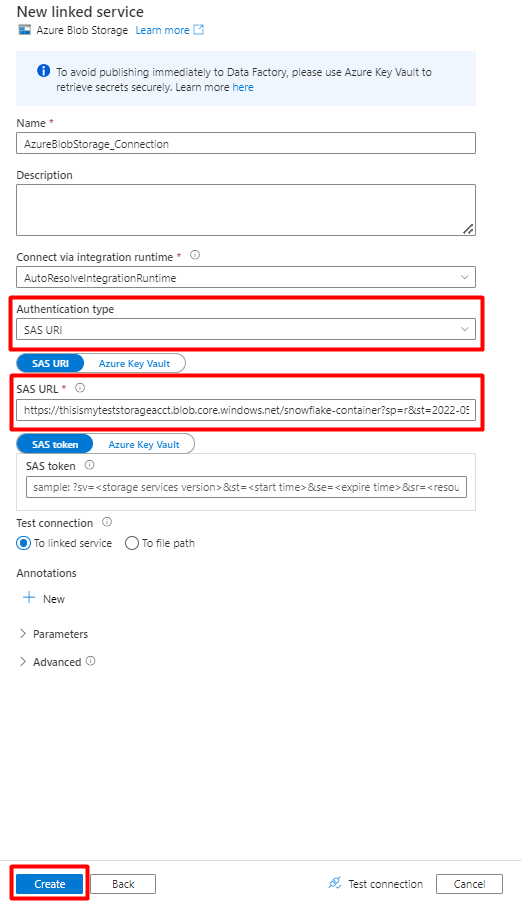
Vul de waarden voor nieuwe gekoppelde service in:
Kies het verificatietype: SAS-URI. Alleen dit verificatietype kan worden gebruikt om gegevens uit Snowflake te importeren in Azure Blob Storage.
Genereer een SAS-URL voor het opslagaccount dat u gaat gebruiken voor fasering. Plak de URL van de blob-SAS in het veld SAS-URL.
Selecteer Maken.
Stap 8: Opslaggegevensset configureren
Selecteer in het menu links het pictogram Auteur .
Selecteer Gegevenssets en selecteer vervolgens het menu Acties voor gegevenssets (
...).
Selecteer Nieuwe gegevensset.
Voer in het rechterdeelvenster in de zoekopdracht voor het gegevensarchief 'opslag' in. Selecteer de tegel Azure Blob Storage en selecteer Doorgaan.

Selecteer DelimitedText-indeling en selecteer Doorgaan.
In Eigenschappen instellen:
Selecteer onder Gekoppelde service de gekoppelde service die in stap 7 is gemaakt.
Kies onder Bestandspad de container die de sink voor het faseringsproces wordt en selecteer OK.
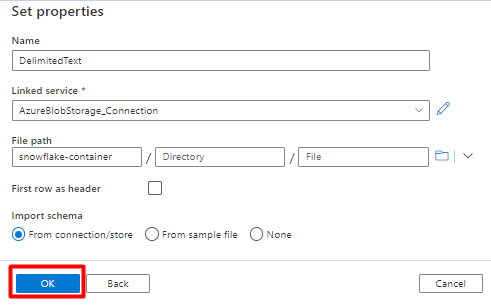
Selecteer regelinvoer (\n) in rijscheidingsteken.
Schakel het selectievakje Eerste rij als koptekst in.
Selecteer Opslaan.
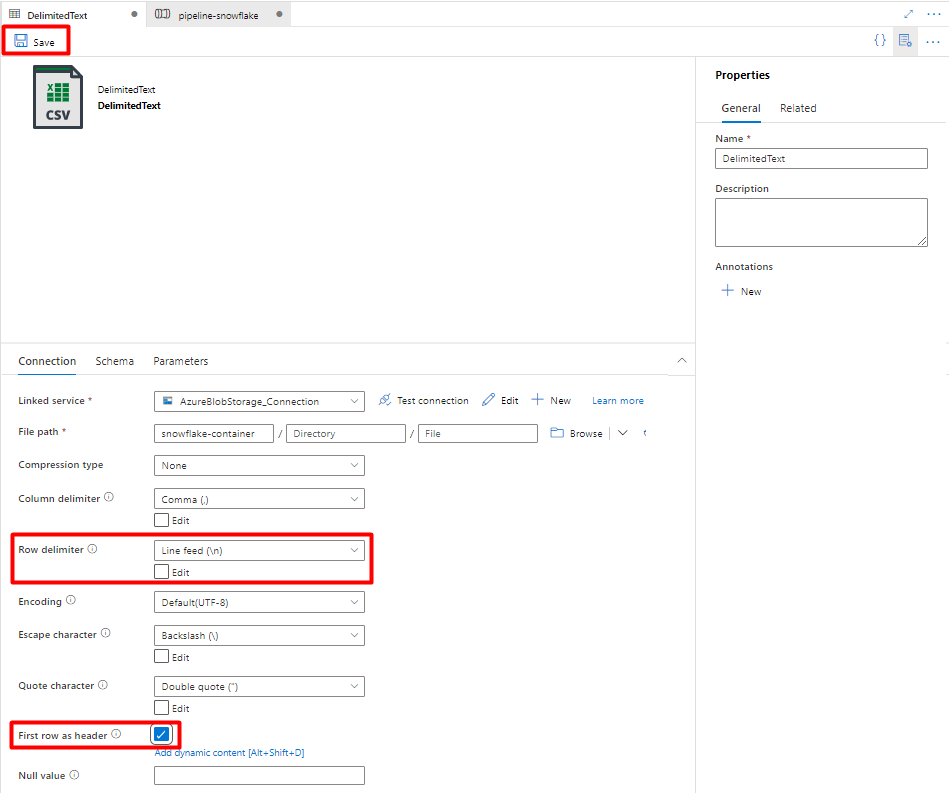
Stap 9: Pijplijn configureren
Selecteer in het menu links het pictogram Auteur .
Selecteer Pijplijnen en selecteer vervolgens het beletselteken voor pijplijnenacties (
...).
Selecteer Nieuwe pijplijn.
Maak en configureer de Data Factory-activiteiten die kopiëren van Snowflake naar Azure Storage-container:
Vouw de sectie Verplaatsen & transformatie uit en sleep de activiteit Kopieergegevens naar het lege canvas van de pijplijneditor.
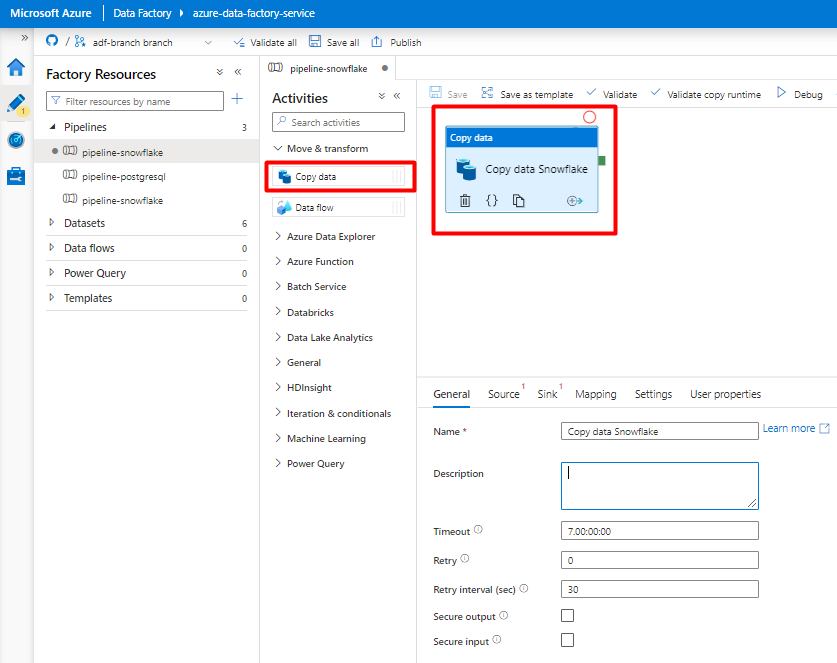
Open het tabblad Algemeen . Accepteer de standaardwaarden, tenzij u de uitvoering moet aanpassen.
Selecteer op het tabblad Bron de tabel Snowflake. Laat de overige opties staan met de standaardwaarden.
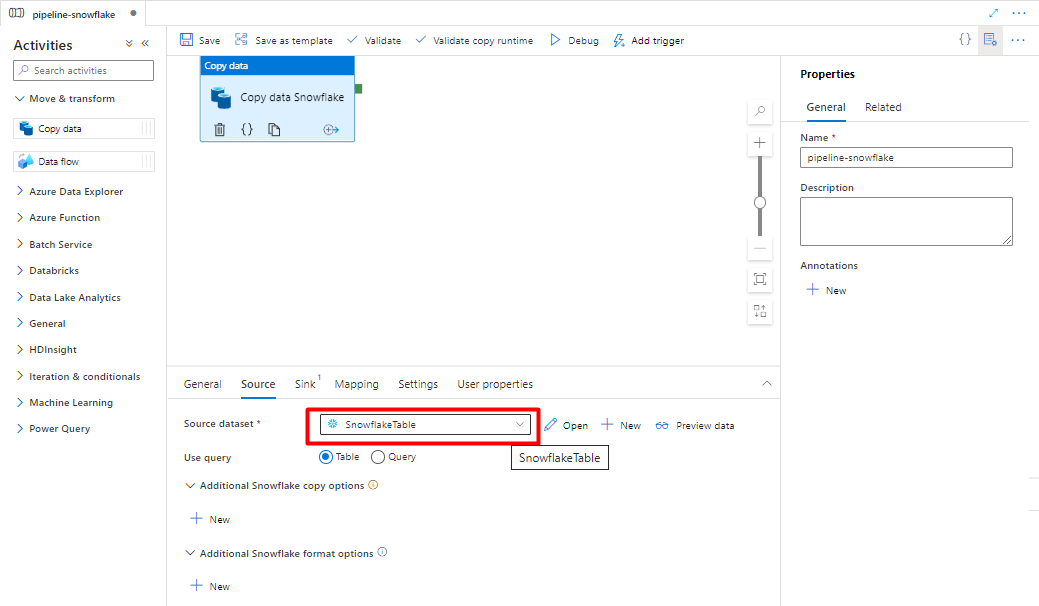
Op het tabblad Sink :
Selecteer Storage DelimitedText-gegevensset die is gemaakt in stap 8.
Voeg in Bestandsextensie.csvtoe.
Laat de overige opties staan met de standaardwaarden.
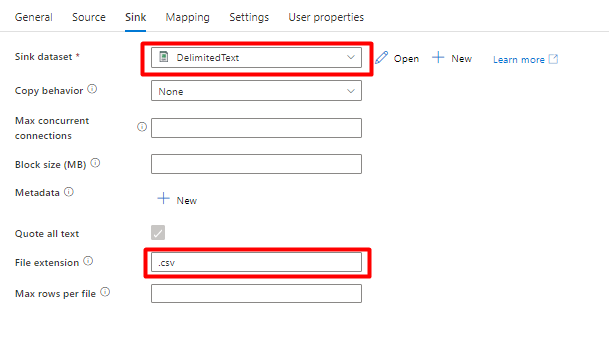
Selecteer Opslaan.
Configureer de activiteiten die van Azure Storage Blob naar een zoekindex kopiëren:
Vouw de sectie Verplaatsen & transformatie uit en sleep de activiteit Kopieergegevens naar het lege canvas van de pijplijneditor.
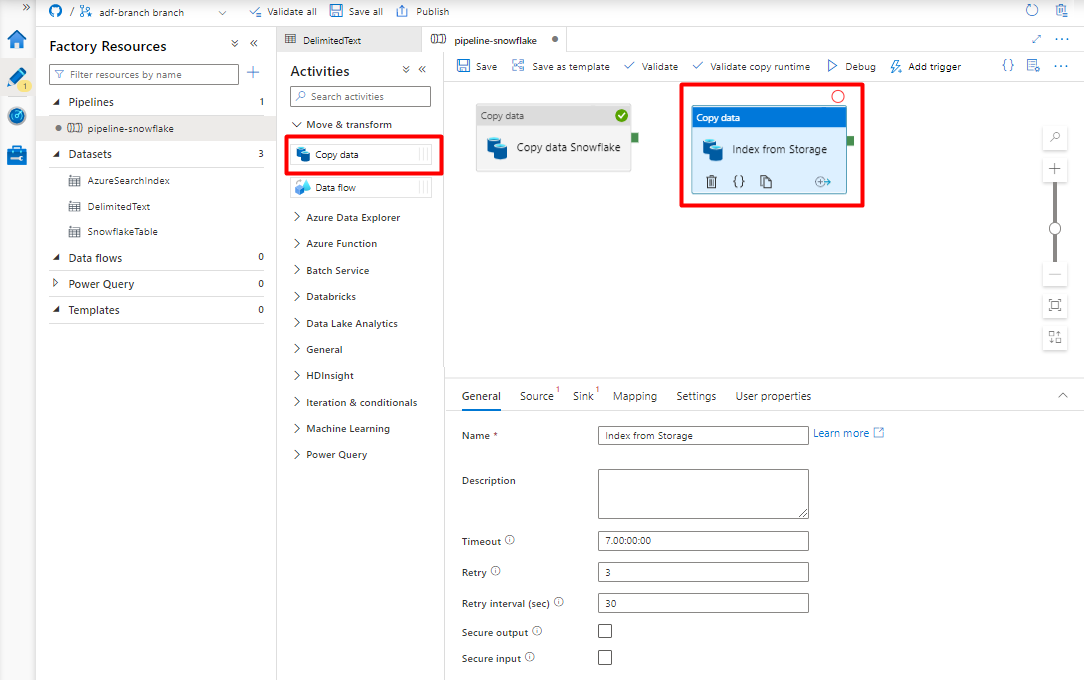
Accepteer op het tabblad Algemeen de standaardwaarden, tenzij u de uitvoering moet aanpassen.
Op het tabblad Bron :
- Selecteer Storage DelimitedText-gegevensset die is gemaakt in stap 8.
- Selecteer bij Bestandstype de optie Jokertekenbestandspad.
- Laat alle resterende velden met standaardwaarden staan.
Selecteer op het tabblad Sink uw Azure Cognitive Search index. Laat de overige opties staan met de standaardwaarden.
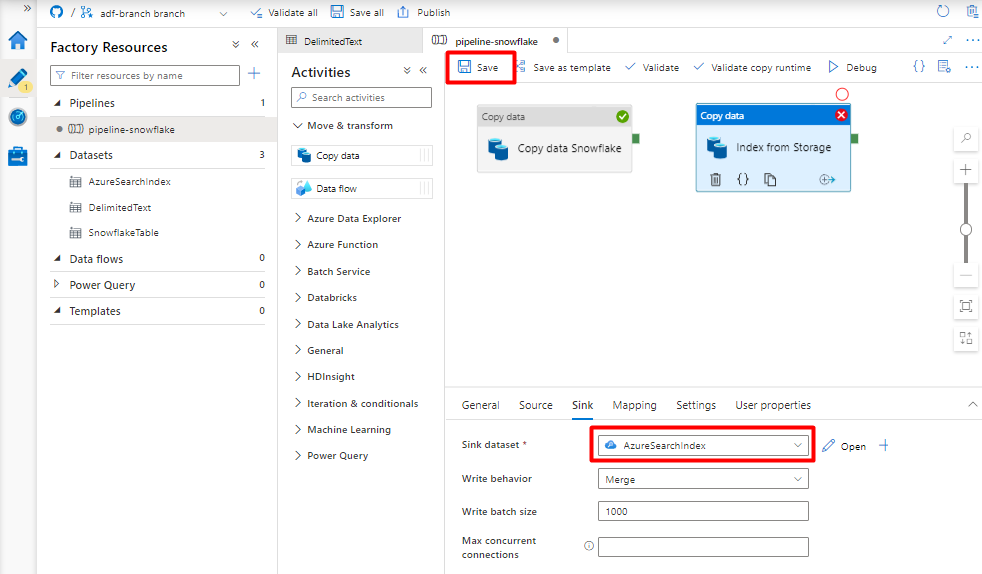
Selecteer Opslaan.
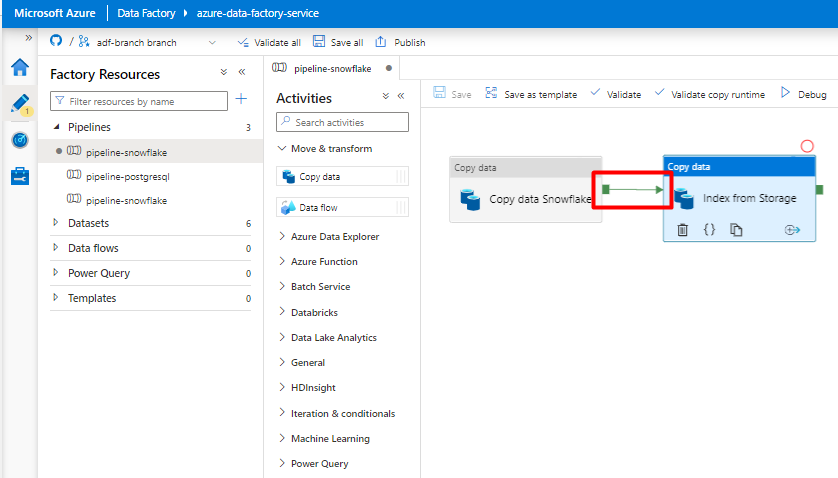
Stap 10: Activiteitsvolgorde configureren
Selecteer in de editor van het pijplijncanvas het kleine groene vierkantje aan de rand van de tegel pijplijnactiviteit. Sleep deze naar de activiteit Indexen van opslagaccount naar Azure Cognitive Search om de uitvoeringsvolgorde in te stellen.
Selecteer Opslaan.
Stap 11: Een pijplijntrigger toevoegen
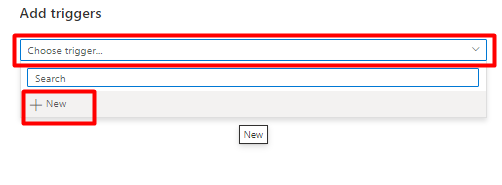
Selecteer Trigger toevoegen om de pijplijnuitvoering te plannen en selecteer Nieuw/Bewerken.

Selecteer in de vervolgkeuzelijst Trigger kiezende optie Nieuw.
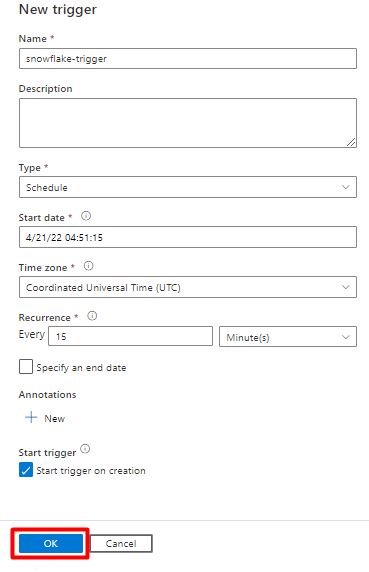
Bekijk de triggeropties om de pijplijn uit te voeren en selecteer OK.
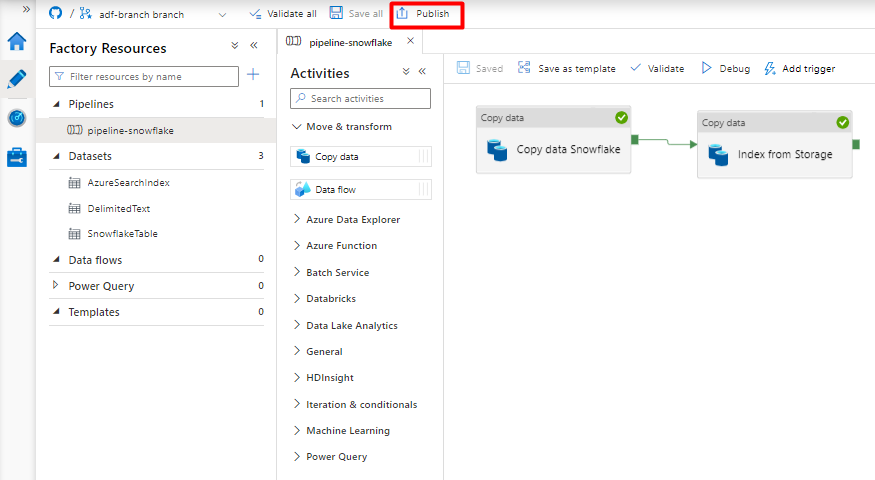
Selecteer Opslaan.
Selecteer Publiceren.
Een PostgreSQL-gegevenspijplijn migreren
In deze sectie wordt uitgelegd hoe u gegevens kopieert van een PostgreSQL-database naar een Azure Cognitive Search-index. Er is geen proces voor het rechtstreeks indexeren van PostgreSQL naar Azure Cognitive Search, dus deze sectie bevat een faseringsfase waarmee database-inhoud wordt gekopieerd naar een Azure Storage-blobcontainer. Vervolgens indexeert u vanuit die faseringscontainer met behulp van een Data Factory-pijplijn.
Stap 1: Gekoppelde PostgreSQL-service configureren
Meld u aan bij Azure Data Factory Studio met uw Azure-account.
Kies uw Data Factory en selecteer Doorgaan.
Selecteer in het linkermenu het pictogram Beheren .
Selecteer onder Gekoppelde servicesde optie Nieuw.
Voer in het rechterdeelvenster in de zoekfunctie voor het gegevensarchief 'postgresql' in. Selecteer de postgreSQL-tegel die aangeeft waar uw PostgreSQL-database zich bevindt (Azure of een andere) en selecteer Doorgaan. In dit voorbeeld bevindt de PostgreSQL-database zich in Azure.

Vul de waarden voor nieuwe gekoppelde service in:
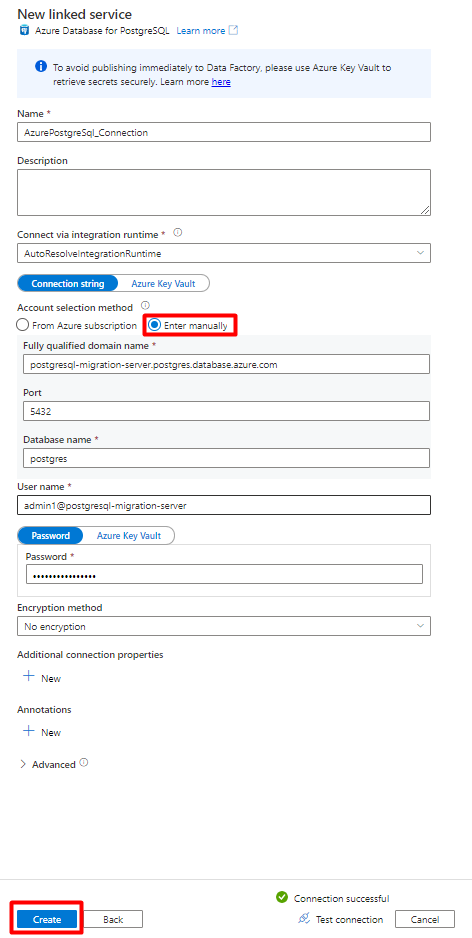
Selecteer handmatig invoeren in Accountselectiemethode.
Plak op de Azure Database for PostgreSQL overzichtspagina in de Azure Portal de volgende waarden in het desbetreffende veld:
- Voeg Servernaam toe aan Volledig gekwalificeerde domeinnaam.
- Voeg Beheer gebruikersnaam toe aan Gebruikersnaam.
- Voeg Database toe aan Databasenaam.
- Voer het Beheer gebruikersnaamwachtwoord in op Gebruikersnaamwachtwoord.
- Selecteer Maken.
Stap 2: PostgreSQL-gegevensset configureren
Selecteer in het linkermenu Het pictogram Auteur .
Selecteer Gegevenssets en selecteer vervolgens het beletseltekenmenu Acties voor gegevenssets (
...).
Selecteer Nieuwe gegevensset.
Voer in het rechterdeelvenster in het gegevensarchief zoeken 'postgresql' in. Selecteer de tegel Azure PostgreSQL . Selecteer Doorgaan.
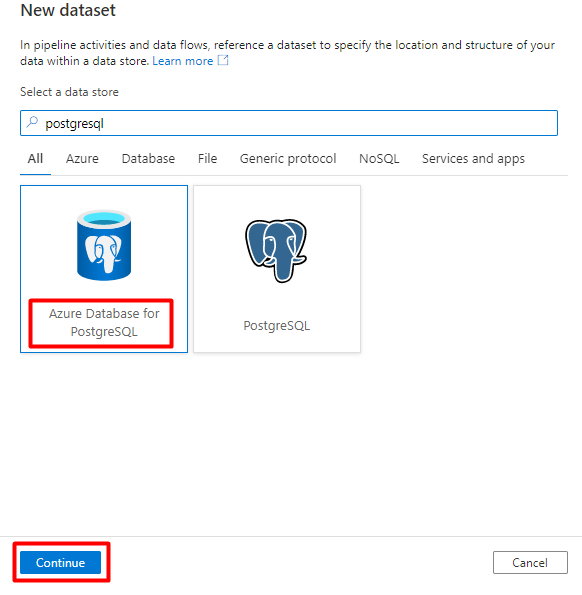
Vul de waarden voor Eigenschappen instellen in :
Kies de gekoppelde PostgreSQL-service die in stap 1 is gemaakt.
Selecteer de tabel die u wilt importeren/indexeren.
Selecteer OK.
Selecteer Opslaan.
Stap 3: een nieuwe index maken in Azure Cognitive Search
Maak een nieuwe index in uw Azure Cognitive Search-service met hetzelfde schema als het schema dat wordt gebruikt voor uw PostgreSQL-gegevens.
U kunt het doel wijzigen van de index die u momenteel gebruikt voor de PostgreSQL Power Connector. Zoek in de Azure Portal de index en selecteer vervolgens Indexdefinitie (JSON). Selecteer de definitie en kopieer deze naar de hoofdtekst van uw nieuwe indexaanvraag.

Stap 4: Azure Cognitive Search gekoppelde service configureren
Selecteer in het linkermenu het pictogram Beheren .
Selecteer onder Gekoppelde servicesde optie Nieuw.
Voer in het rechterdeelvenster in de zoekfunctie voor het gegevensarchief 'zoeken' in. Selecteer de tegel Azure Search en selecteer Doorgaan.
Vul de waarden voor Nieuwe gekoppelde service in:
- Kies het Azure-abonnement waarin uw Azure Cognitive Search-service zich bevindt.
- Kies de Azure Cognitive Search-service met de indexeerfunctie voor de Power Query connector.
- Selecteer Maken.
Stap 5: Azure Cognitive Search gegevensset configureren
Selecteer in het linkermenu Het pictogram Auteur .
Selecteer Gegevenssets en selecteer vervolgens het beletseltekenmenu Acties voor gegevenssets (
...).
Selecteer Nieuwe gegevensset.
Voer in het rechterdeelvenster in de zoekfunctie voor het gegevensarchief 'zoeken' in. Selecteer de tegel Azure Search en selecteer Doorgaan.
In Eigenschappen instellen:
Selecteer Opslaan.
Stap 6: Azure Blob Storage gekoppelde service configureren
Selecteer in het linkermenu het pictogram Beheren .
Selecteer onder Gekoppelde servicesde optie Nieuw.
Voer in het rechterdeelvenster in de zoekfunctie voor het gegevensarchief 'opslag' in. Selecteer de tegel Azure Blob Storage en selecteer Doorgaan.
Vul de waarden voor Nieuwe gekoppelde service in:
Kies het verificatietype: SAS-URI. Alleen deze methode kan worden gebruikt om gegevens uit PostgreSQL te importeren in Azure Blob Storage.
Genereer een SAS-URL voor het opslagaccount dat u gaat gebruiken voor fasering en kopieer het veld Blob SAS URL naar SAS URL.
Selecteer Maken.
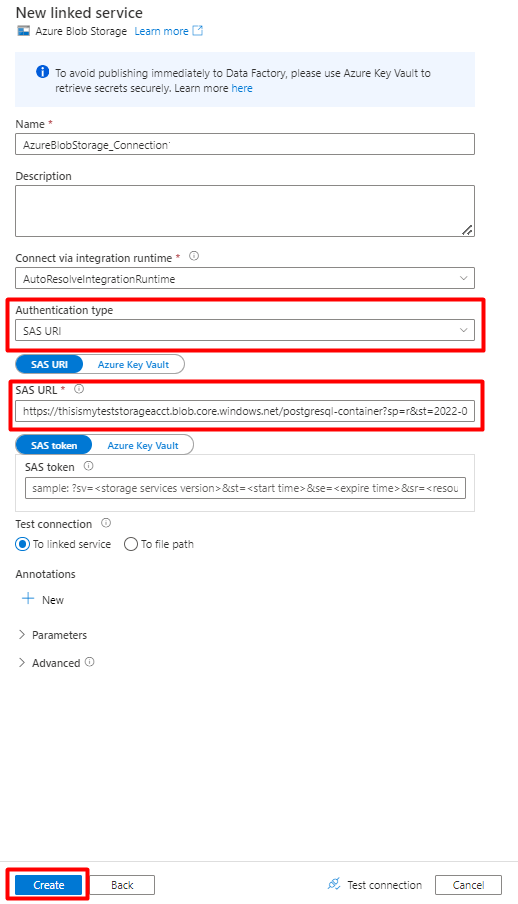
Stap 7: Opslaggegevensset configureren
Selecteer in het linkermenu Het pictogram Auteur .
Selecteer Gegevenssets en selecteer vervolgens het beletseltekenmenu Acties voor gegevenssets (
...).
Selecteer Nieuwe gegevensset.
Voer in het rechterdeelvenster in de zoekfunctie voor het gegevensarchief 'opslag' in. Selecteer de tegel Azure Blob Storage en selecteer Doorgaan.
Selecteer DelimitedText-indeling en selecteer Doorgaan.
Selecteer in Rijscheidingstekende optie Regelinvoer (\n).
Schakel het selectievakje Eerste rij als koptekst in.
Selecteer Opslaan.
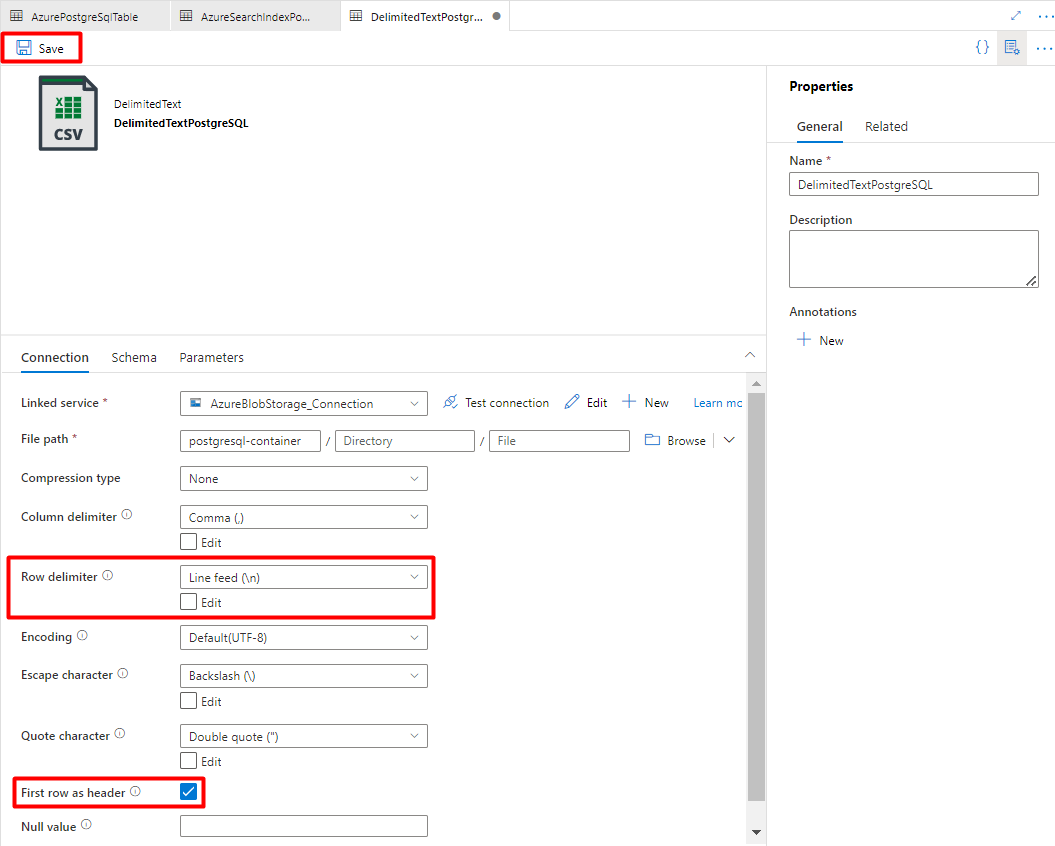
Stap 8: Pijplijn configureren
Selecteer in het linkermenu Het pictogram Auteur .
Selecteer Pijplijnen en selecteer vervolgens het beletseltekenmenu Pijplijnacties (
...).
Selecteer Nieuwe pijplijn.
Maak en configureer de Data Factory-activiteiten die kopiëren van PostgreSQL naar Azure Storage-container.
Vouw de sectie Verplaatsen & transformatie uit en sleep de activiteit Gegevens kopiëren naar het lege canvas van de pijplijneditor.
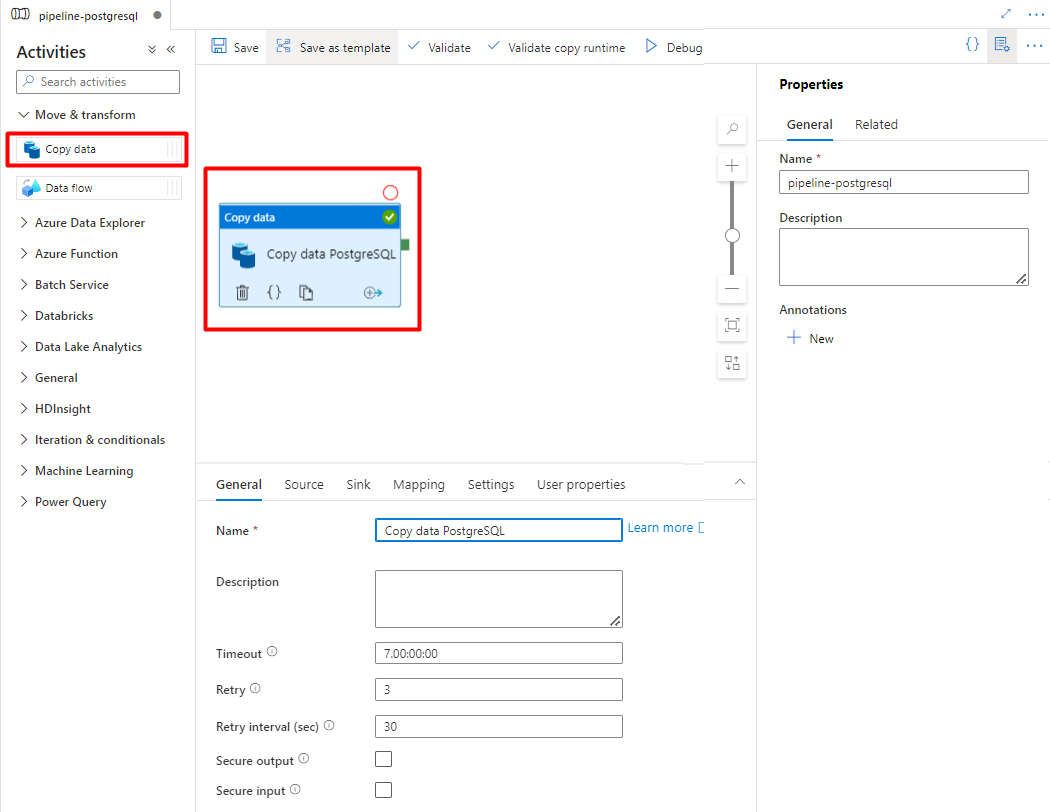
Open het tabblad Algemeen en accepteer de standaardwaarden, tenzij u de uitvoering moet aanpassen.
Selecteer op het tabblad Bron de PostgreSQL-tabel. Laat de overige opties met de standaardwaarden staan.
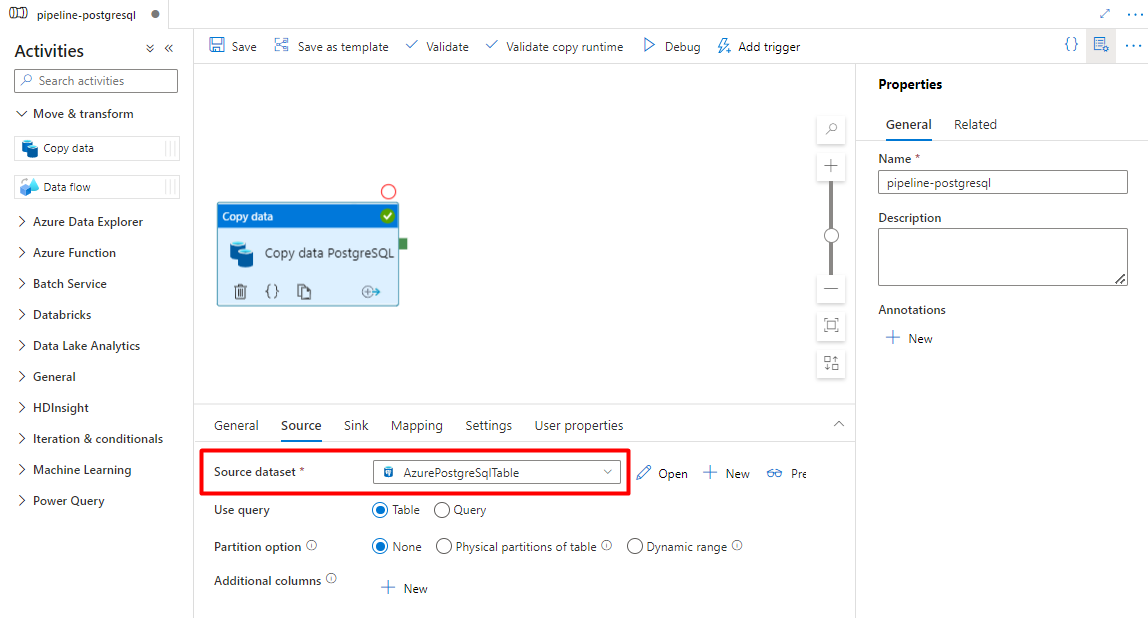
Op het tabblad Sink :
Selecteer de PostgreSQL-gegevensset Storage DelimitedText die in stap 7 is geconfigureerd.
Voeg in de bestandsextensie.csvtoe
Laat de overige opties met de standaardwaarden staan.

Selecteer Opslaan.
Configureer de activiteiten die vanuit Azure Storage naar een zoekindex kopiëren:
Vouw de sectie Verplaatsen & transformatie uit en sleep de activiteit Gegevens kopiëren naar het lege canvas van de pijplijneditor.
Laat op het tabblad Algemeen de standaardwaarden staan, tenzij u de uitvoering moet aanpassen.
Op het tabblad Bron :
- Selecteer de opslagbrongegevensset die is geconfigureerd in stap 7.
- Selecteer in het veld Type bestandspad de optie Bestandspad met jokerteken.
- Laat alle resterende velden met standaardwaarden staan.
Selecteer op het tabblad Sink uw Azure Cognitive Search-index. Laat de overige opties met de standaardwaarden staan.
Selecteer Opslaan.
Stap 9: Activiteitsvolgorde configureren
Selecteer in de editor voor het pijplijncanvas het kleine groene vierkantje aan de rand van de pijplijnactiviteit. Sleep deze naar de activiteit Indexen van opslagaccount naar Azure Cognitive Search om de uitvoeringsvolgorde in te stellen.
Selecteer Opslaan.
Stap 10: Een pijplijntrigger toevoegen
Selecteer Trigger toevoegen om de pijplijnuitvoering te plannen en selecteer Nieuw/Bewerken.
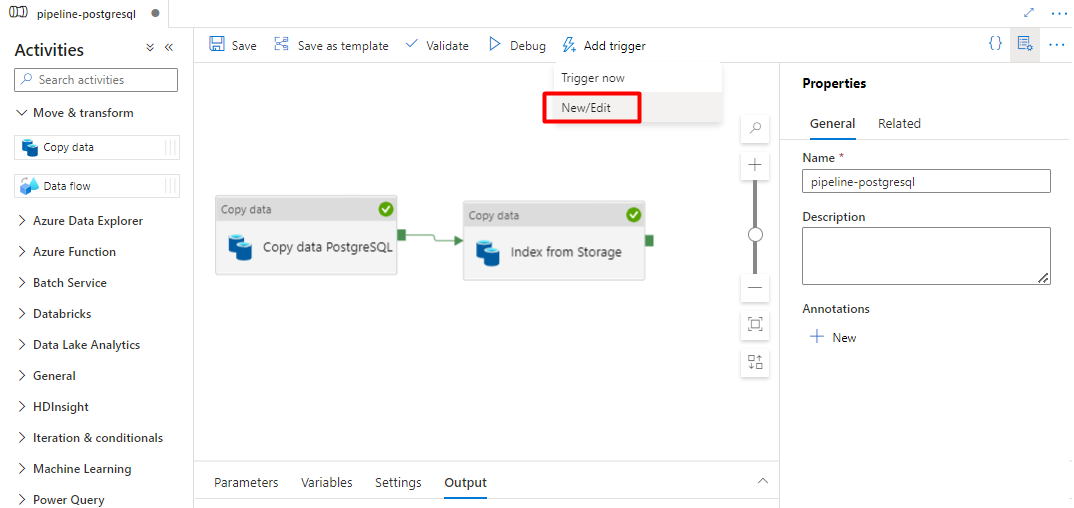
Selecteer in de vervolgkeuzelijst Trigger kiezende optie Nieuw.
Controleer de triggeropties om de pijplijn uit te voeren en selecteer OK.

Selecteer Opslaan.
Selecteer Publiceren.
Verouderde inhoud voor Power Query-connectorvoorbeeld
Een Power Query-connector wordt gebruikt met een zoekindexeerfunctie voor het automatiseren van gegevensopname uit verschillende gegevensbronnen, waaronder die van andere cloudproviders. Er wordt Power Query gebruikt om de gegevens op te halen.
Gegevensbronnen die in de preview worden ondersteund, zijn onder andere:
- Amazon Redshift
- Elasticsearch
- PostgreSQL
- Salesforce-objecten
- Salesforce-rapporten
- Smartsheet
- Snowflake
Ondersteunde functionaliteit
Power Query connectors worden gebruikt in indexeerfuncties. Een indexeerfunctie in Azure Cognitive Search is een crawler waarmee doorzoekbare gegevens en metagegevens uit een externe gegevensbron worden geëxtraheerd en een index wordt gevuld op basis van veld-naar-veldtoewijzingen tussen de index en uw gegevensbron. Deze benadering wordt ook wel een 'pull-model' genoemd, omdat de service gegevens ophaalt zonder dat u code hoeft te schrijven waarmee gegevens aan een index worden toegevoegd. Indexeerfuncties bieden gebruikers een handige manier om inhoud uit hun gegevensbron te indexeren zonder dat ze hun eigen crawler- of pushmodel hoeven te schrijven.
Indexeerfuncties die verwijzen naar Power Query gegevensbronnen, hebben hetzelfde ondersteuningsniveau voor vaardighedensets, schema's, detectielogica voor hoogwatermarkeringen en de meeste parameters die andere indexeerfuncties ondersteunen.
Vereisten
Hoewel u deze functie niet meer kunt gebruiken, had deze de volgende vereisten in de preview-versie:
Azure Cognitive Search service in een ondersteunde regio.
Preview-registratie. Deze functie moet zijn ingeschakeld op de back-end.
Azure Blob Storage account, gebruikt als intermediair voor uw gegevens. De gegevens stromen van uw gegevensbron, vervolgens naar Blob Storage en vervolgens naar de index. Deze vereiste bestaat alleen bij de eerste gated preview.
Regionale beschikbaarheid
De preview was alleen beschikbaar in zoekservices in de volgende regio's:
- Central US
- VS - oost
- VS - oost 2
- VS - noord-centraal
- Europa - noord
- VS - zuid-centraal
- VS - west-centraal
- Europa -west
- VS - west
- VS - west 2
Preview-beperkingen
In deze sectie worden de beperkingen beschreven die specifiek zijn voor de huidige versie van de preview.
Het ophalen van binaire gegevens uit uw gegevensbron wordt niet ondersteund.
Foutopsporingssessie wordt niet ondersteund.
Aan de slag met de Azure Portal
De Azure Portal biedt ondersteuning voor de Power Query connectors. Door steekproeven van gegevens te nemen en metagegevens in de container te lezen, kunt u met de wizard Gegevens importeren in Azure Cognitive Search een standaardindex maken, bronvelden toewijzen aan doelindexvelden en de index in één bewerking laden. Afhankelijk van de grootte en complexiteit van brongegevens, hebt u binnen enkele minuten een operationele zoekindex voor volledige tekst.
In de volgende video ziet u hoe u een Power Query-connector instelt in Azure Cognitive Search.
Stap 1: brongegevens voorbereiden
Zorg ervoor dat uw gegevensbron gegevens bevat. De wizard Gegevens importeren leest metagegevens en voert gegevenssampling uit om een indexschema af te stellen, maar laadt ook gegevens uit uw gegevensbron. Als de gegevens ontbreken, stopt de wizard en wordt er een fout geretourneerd.
Stap 2: de wizard Gegevens importeren starten
Nadat u bent goedgekeurd voor de preview, ontvangt u van het Azure Cognitive Search team een Azure Portal koppeling die gebruikmaakt van een functievlag, zodat u toegang hebt tot de Power Query-connectors. Open deze pagina en start de wizard vanaf de opdrachtbalk op de pagina Azure Cognitive Search service door Gegevens importeren te selecteren.
Stap 3: selecteer uw gegevensbron
Er zijn enkele gegevensbronnen waaruit u gegevens kunt ophalen met behulp van dit voorbeeld. Alle gegevensbronnen die gebruikmaken van Power Query, bevatten een 'Powered By Power Query' op hun tegel. Selecteer uw gegevensbron.
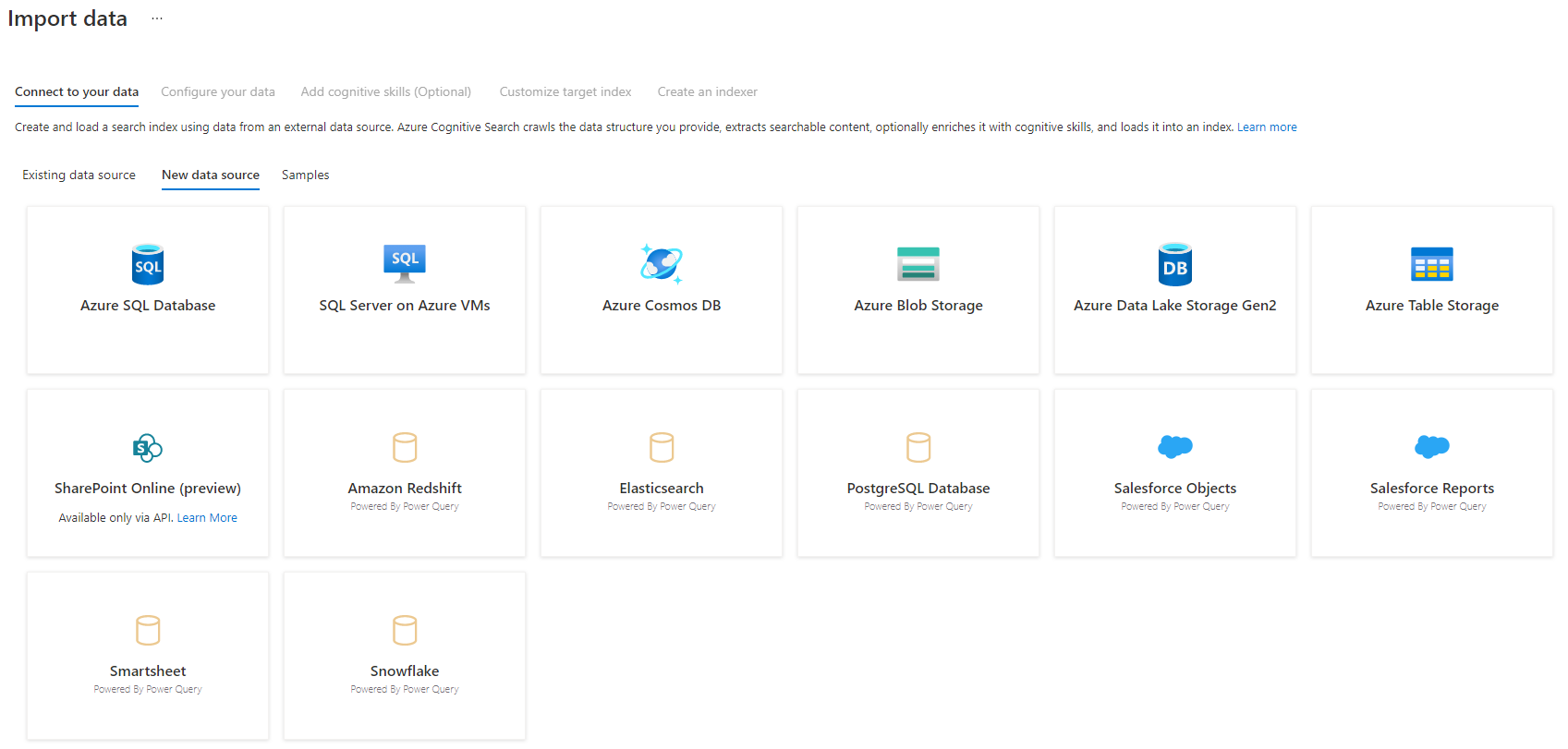
Nadat u de gegevensbron hebt geselecteerd, selecteert u Volgende: Uw gegevens configureren om naar de volgende sectie te gaan.
Stap 4: uw gegevens configureren
In deze stap configureert u de verbinding. Voor elke gegevensbron is andere informatie vereist. Voor een aantal gegevensbronnen biedt de documentatie over Power Query meer informatie over hoe u verbinding maakt met uw gegevens.
Nadat u uw verbindingsreferenties hebt opgegeven, selecteert u Volgende.
Stap 5: uw gegevens selecteren
De wizard Importeren bekijkt een voorbeeld van verschillende tabellen die beschikbaar zijn in uw gegevensbron. In deze stap controleert u een tabel die de gegevens bevat die u in de index wilt importeren.
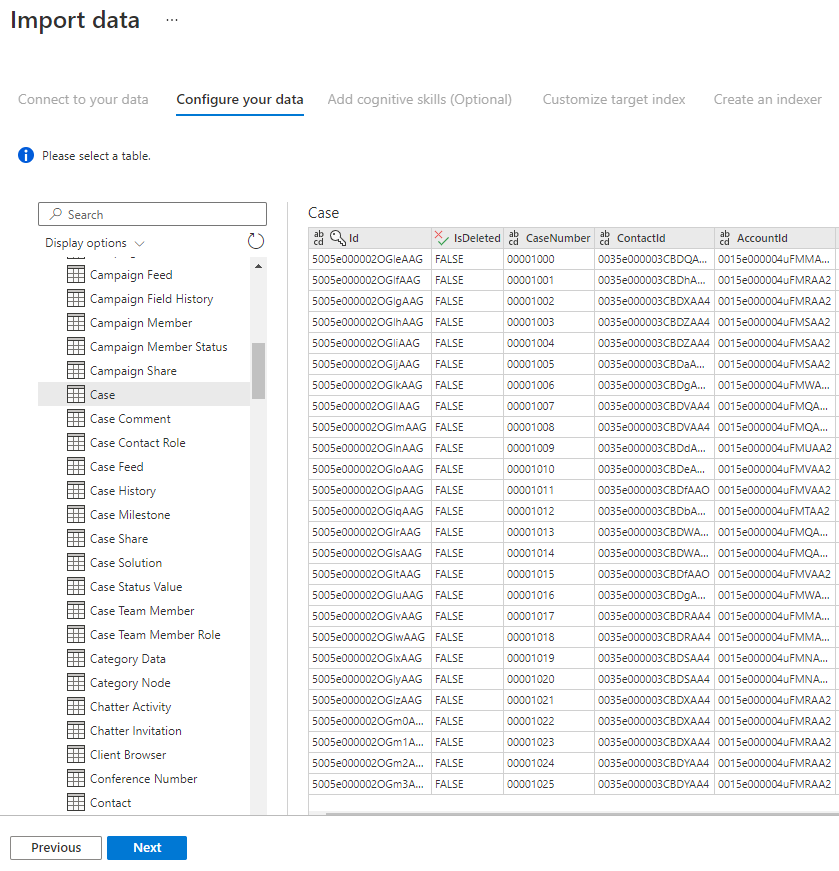
Nadat u de tabel hebt geselecteerd, selecteert u Volgende.
Stap 6: uw gegevens transformeren (optioneel)
Power Query-connectors bieden u een uitgebreide gebruikersinterface-ervaring waarmee u uw gegevens kunt bewerken, zodat u de juiste gegevens naar uw index kunt verzenden. U kunt kolommen, rijen filteren en nog veel meer verwijderen.
Het is niet vereist dat u uw gegevens transformeert voordat u deze in Azure Cognitive Search importeert.

Zie Power Query gebruiken in Power BI Desktop voor meer informatie over het transformeren van gegevens met Power Query.
Nadat de gegevens zijn getransformeerd, selecteert u Volgende.
Stap 7: Azure Blob Storage toevoegen
Voor de preview-versie van Power Query connector moet u momenteel een blobopslagaccount opgeven. Deze stap bestaat alleen met de eerste beperkte preview. Dit blob-opslagaccount fungeert als tijdelijke opslag voor gegevens die worden verplaatst van uw gegevensbron naar een Azure Cognitive Search-index.
U wordt aangeraden een opslagaccount met volledige toegang te bieden verbindingsreeks:
{ "connectionString" : "DefaultEndpointsProtocol=https;AccountName=<your storage account>;AccountKey=<your account key>;" }
U kunt de verbindingsreeks van de Azure Portal ophalen door te navigeren naar de blade > Instellingen > van het opslagaccount Sleutels (voor klassieke opslagaccounts) of Instellingen > Toegangssleutels (voor Azure Resource Manager-opslagaccounts).
Nadat u een gegevensbronnaam en verbindingsreeks hebt opgegeven, selecteert u 'Volgende: Cognitieve vaardigheden toevoegen (optioneel)'.
Stap 8: cognitieve vaardigheden toevoegen (optioneel)
AI-verrijking is een uitbreiding van indexeerfuncties die kunnen worden gebruikt om uw inhoud beter doorzoekbaar te maken.
U kunt verrijkingen toevoegen die uw scenario ten goede komen. Wanneer u klaar bent, selecteert u Volgende: Doelindex aanpassen.
Stap 9: doelindex aanpassen
Op de pagina Index ziet u een lijst met velden met een gegevenstype en een reeks selectievakjes voor het instellen van indexkenmerken. De wizard kan een lijst met velden genereren op basis van metagegevens en door steekproeven uit de brongegevens te nemen.
U kunt kenmerken bulksgewijs selecteren door het selectievakje boven aan een kenmerkkolom in te schakelen. Kies Ophalen mogelijk en Doorzoekbaar voor elk veld dat moet worden geretourneerd naar een client-app en moet worden onderworpen aan volledige tekstzoekverwerking. U zult merken dat gehele getallen geen volledige tekst of fuzzy doorzoekbaar zijn (getallen worden letterlijk geëvalueerd en zijn vaak handig in filters).
Bekijk de beschrijving van indexkenmerken en taalanalyses voor meer informatie.
Neem even de tijd om uw selecties te bekijken. Nadat u de wizard hebt uitgevoerd, worden er fysieke gegevensstructuren gemaakt en kunt u de meeste eigenschappen voor deze velden niet bewerken zonder alle objecten te verwijderen en opnieuw te maken.
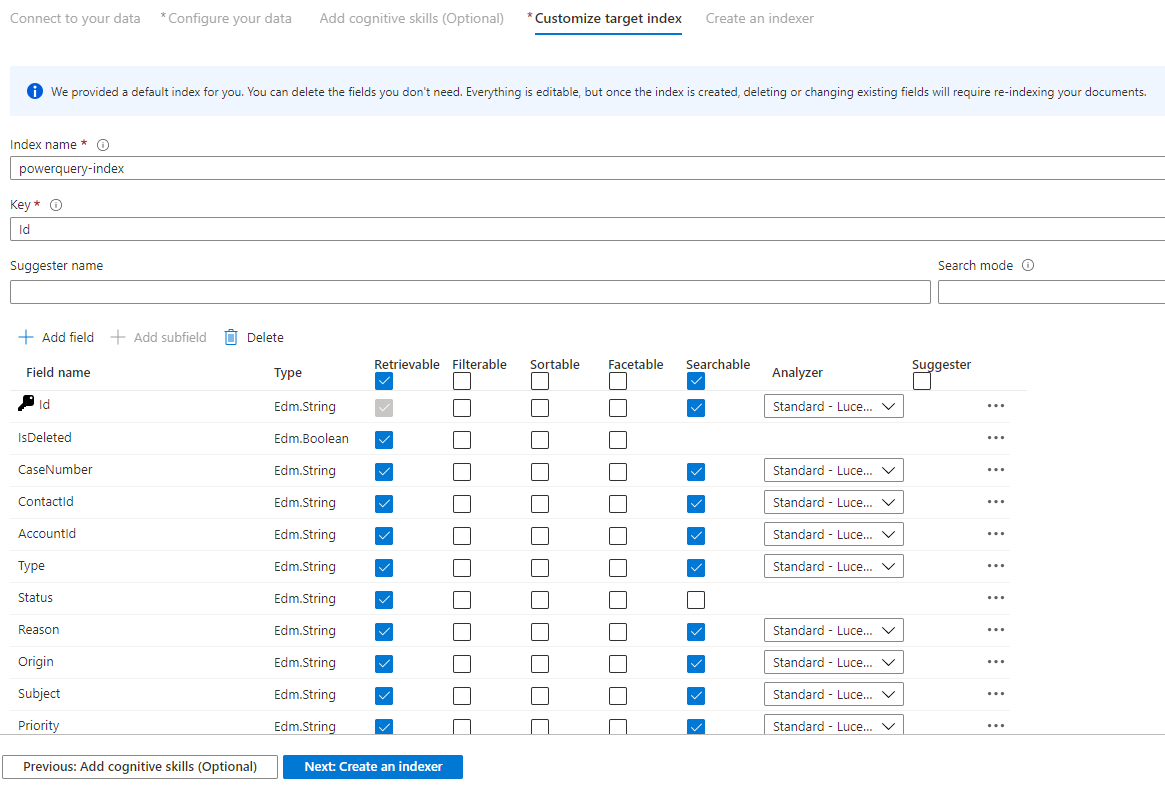
Wanneer u klaar bent, selecteert u Volgende: Een indexeerfunctie maken.
Stap 10: een indexeerfunctie maken
Met de laatste stap maakt u de indexeerfunctie. Door de indexeerfunctie een naam te geven, kan deze bestaan als een zelfstandige resource, die u onafhankelijk van de index en het gegevensbronobject kunt plannen en beheren, dat in dezelfde wizardvolgorde is gemaakt.
De uitvoer van de wizard Gegevens importeren is een indexeerfunctie waarmee uw gegevensbron wordt verkend en de gegevens die u hebt geselecteerd, worden geïmporteerd in een index op Azure Cognitive Search.
Wanneer u de indexeerfunctie maakt, kunt u er desgewenst voor kiezen om de indexeerfunctie volgens een schema uit te voeren en wijzigingsdetectie toe te voegen. Als u wijzigingsdetectie wilt toevoegen, wijst u een kolom 'hoogwatermarkering' aan.
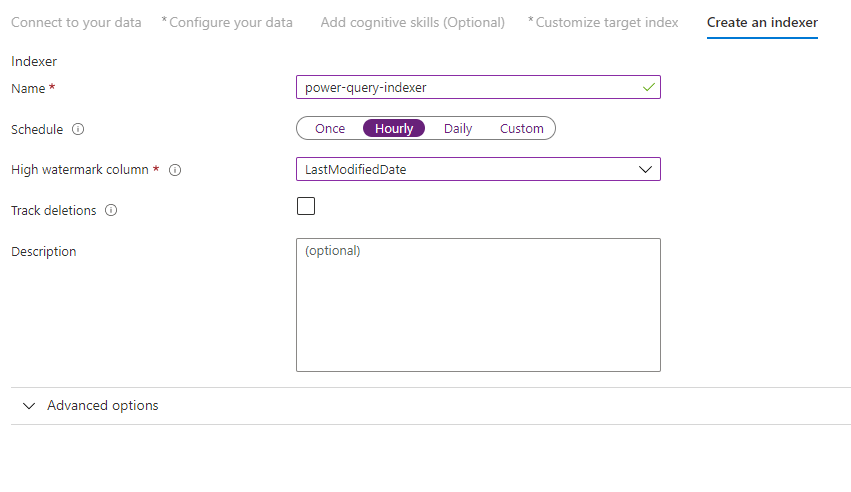
Nadat u klaar bent met het invullen van deze pagina, selecteert u Verzenden.
Beleid voor detectie van hoge watermarkeringen
Dit wijzigingsdetectiebeleid is afhankelijk van een kolom 'hoogwatermarkering' waarin de versie of het tijdstip wordt vastgelegd waarop een rij voor het laatst is bijgewerkt.
Vereisten
- Met alle invoegingen wordt een waarde voor de kolom opgegeven.
- Bij alle updates voor een item wordt ook de waarde van de kolom gewijzigd.
- De waarde van deze kolom neemt toe met elke invoeging of update.
Niet-ondersteunde kolomnamen
Veldnamen in een Azure Cognitive Search index moeten aan bepaalde vereisten voldoen. Een van deze vereisten is dat sommige tekens, zoals '/', niet zijn toegestaan. Als een kolomnaam in uw database niet aan deze vereisten voldoet, herkent de detectie van het indexschema uw kolom niet als een geldige veldnaam en wordt die kolom niet weergegeven als een voorgesteld veld voor uw index. Normaal gesproken zou het gebruik van veldtoewijzingen dit probleem oplossen, maar veldtoewijzingen worden niet ondersteund in de portal.
Als u inhoud wilt indexeren van een kolom in de tabel met een niet-ondersteunde veldnaam, wijzigt u de naam van de kolom tijdens de fase 'Uw gegevens transformeren' van het gegevensproces. U kunt bijvoorbeeld de naam van een kolom met de naam 'Factureringscode/postcode' wijzigen in 'postcode'. Door de naam van de kolom te wijzigen, herkent de detectie van het indexschema deze als een geldige veldnaam en voegt deze toe als suggestie voor uw indexdefinitie.
Volgende stappen
In dit artikel wordt uitgelegd hoe u gegevens ophaalt met behulp van de Power Query-connectors. Omdat deze preview-functie wordt stopgezet, wordt ook uitgelegd hoe u bestaande oplossingen migreert naar een ondersteund scenario.
Zie Indexeerfuncties in Azure Cognitive Search voor meer informatie over indexeerfuncties.