Kopiowanie danych do lub z systemu plików przy użyciu usługi Azure Data Factory lub Azure Synapse Analytics
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób kopiowania danych do i z systemu plików. Aby dowiedzieć się więcej, przeczytaj artykuł wprowadzający dotyczący usługi Azure Data Factory lub Azure Synapse Analytics.
Obsługiwane możliwości
Ten łącznik systemu plików jest obsługiwany w następujących funkcjach:
| Obsługiwane możliwości | IR |
|---|---|
| działanie Kopiuj (źródło/ujście) | ① ② |
| Działanie Lookup | ① ② |
| Działanie GetMetadata | ① ② |
| Działanie usuwania | ① ② |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
W szczególności ten łącznik systemu plików obsługuje następujące elementy:
- Kopiowanie plików z/do sieciowego udziału plików. Aby użyć udziału plików systemu Linux, zainstaluj narzędzie Samba na serwerze z systemem Linux.
- Kopiowanie plików przy użyciu uwierzytelniania systemu Windows .
- Kopiowanie plików zgodnie z rzeczywistym użyciem lub analizowanie/generowanie plików przy użyciu obsługiwanych formatów plików i koderów kompresji.
Wymagania wstępne
Jeśli magazyn danych znajduje się wewnątrz sieci lokalnej, sieci wirtualnej platformy Azure lub chmury prywatnej Amazon Virtual, musisz skonfigurować własne środowisko Integration Runtime , aby się z nim połączyć.
Jeśli magazyn danych jest zarządzaną usługą danych w chmurze, możesz użyć środowiska Azure Integration Runtime. Jeśli dostęp jest ograniczony do adresów IP zatwierdzonych w regułach zapory, możesz dodać adresy IP środowiska Azure Integration Runtime do listy dozwolonych.
Możesz również użyć funkcji środowiska Integration Runtime zarządzanej sieci wirtualnej w usłudze Azure Data Factory, aby uzyskać dostęp do sieci lokalnej bez instalowania i konfigurowania własnego środowiska Integration Runtime.
Aby uzyskać więcej informacji na temat mechanizmów zabezpieczeń sieci i opcji obsługiwanych przez usługę Data Factory, zobacz Strategie dostępu do danych.
Wprowadzenie
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
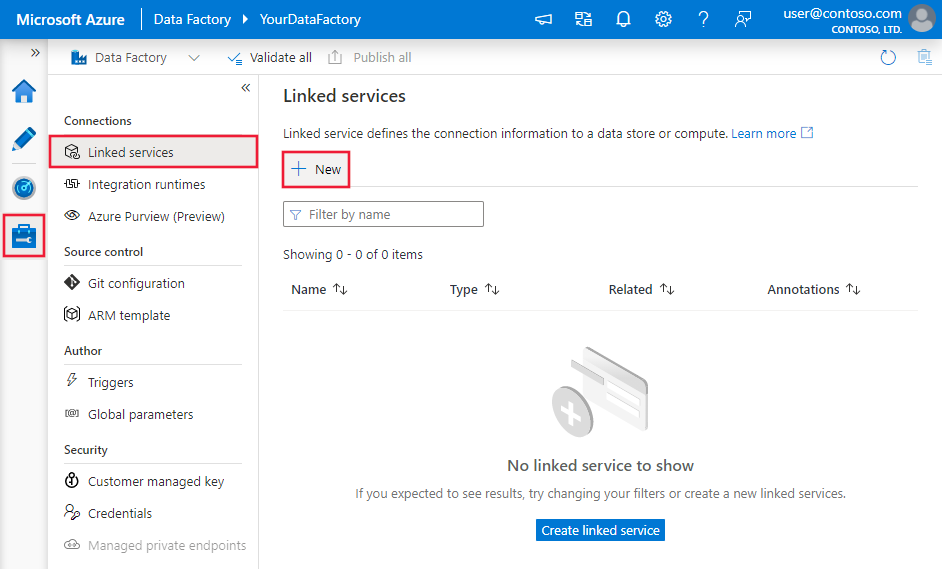
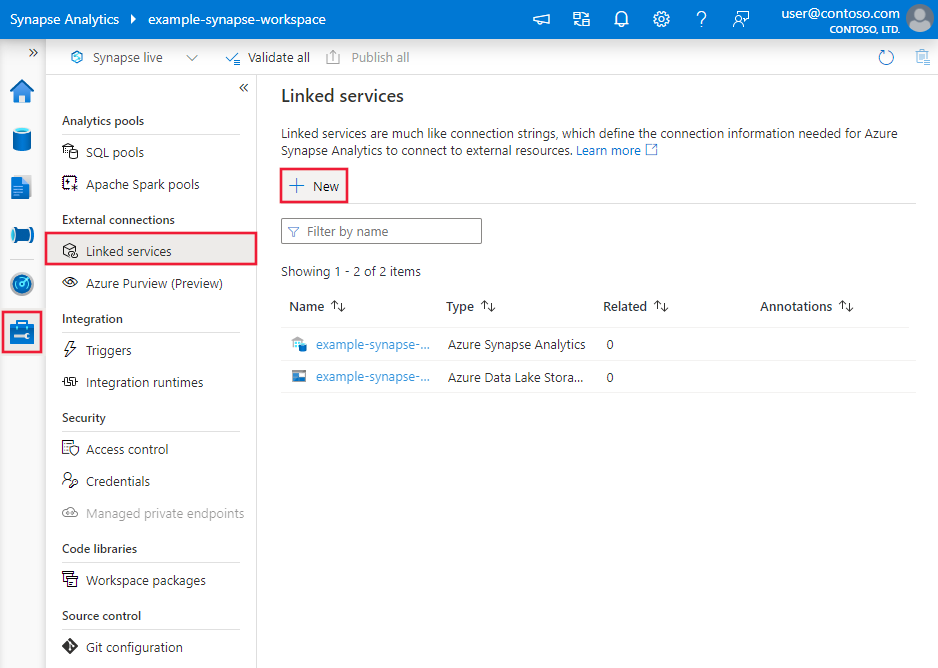
Tworzenie połączonej usługi systemu plików przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę systemu plików w interfejsie użytkownika witryny Azure Portal.
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie wybierz pozycję Nowe:
Wyszukaj plik i wybierz łącznik System plików.

Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.

szczegóły konfiguracji Połączenie or
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek potoku usługi Data Factory i Synapse specyficznych dla systemu plików.
Właściwości połączonej usługi
Następujące właściwości są obsługiwane w przypadku połączonej usługi systemu plików:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na: FileServer. | Tak |
| host | Określa ścieżkę główną folderu, który chcesz skopiować. Użyj znaku ucieczki "" dla znaków specjalnych w ciągu. Przykładowe definicje połączonej usługi i zestawu danych można znaleźć w temacie Sample linked service and dataset definitions (Przykładowe połączone definicje usług i zestawów danych). | Tak |
| Identyfikator użytkownika | Określ identyfikator użytkownika, który ma dostęp do serwera. | Tak |
| hasło | Określ hasło użytkownika (userId). Oznacz to pole jako element SecureString w celu bezpiecznego przechowywania go lub odwołuj się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. | Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Dowiedz się więcej w sekcji Wymagania wstępne . Jeśli nie zostanie określony, używa domyślnego środowiska Azure Integration Runtime. | Nie. |
Przykładowe połączone definicje usług i zestawów danych
| Scenariusz | "host" w definicji połączonej usługi | "folderPath" w definicji zestawu danych |
|---|---|---|
| Zdalny folder udostępniony: Przykłady: \\myserver\share\* lub \\myserver\share\folder\subfolder\* |
W formacie JSON: \\\\myserver\\shareW interfejsie użytkownika: \\myserver\share |
W formacie JSON: .\\ lub folder\\subfolderW interfejsie użytkownika: .\ lub folder\subfolder |
Uwaga
Podczas tworzenia za pośrednictwem interfejsu użytkownika nie trzeba wprowadzać podwójnego ukośnika odwrotnego (\\), aby uniknąć takiego jak w przypadku kodu JSON, określ pojedynczy ukośnik odwrotny.
Uwaga
Kopiowanie plików z komputera lokalnego nie jest obsługiwane w środowisku Azure Integration Runtime.
Zapoznaj się z wierszem polecenia z tego miejsca , aby włączyć dostęp do maszyny lokalnej w obszarze Self-hosted Integration Runtime. Domyślnie jest ona wyłączona.
Przykład:
{
"name": "FileLinkedService",
"properties": {
"type": "FileServer",
"typeProperties": {
"host": "<host>",
"userId": "<domain>\\<user>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz artykuł Zestawy danych.
Usługa Azure Data Factory obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
- Format Avro
- Format binarny
- Format tekstu rozdzielanego
- Format programu Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Następujące właściwości są obsługiwane w przypadku systemu plików w ustawieniach location w zestawie danych opartym na formacie:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze location w zestawie danych musi być ustawiona na FileServerLocation. |
Tak |
| folderPath | Ścieżka do folderu. Jeśli chcesz używać symbolu wieloznakowego do filtrowania folderu, pomiń to ustawienie i określ je w ustawieniach źródła działań. Aby udostępnić folder do udostępniania, należy skonfigurować lokalizację udziału plików w środowisku systemu Windows lub Linux. | Nie. |
| fileName | Nazwa pliku pod danym folderPath. Jeśli chcesz używać symbolu wieloznakowego do filtrowania plików, pomiń to ustawienie i określ je w ustawieniach źródła działań. | Nie. |
Przykład:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<File system linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "FileServerLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez źródło i ujście systemu plików.
System plików jako źródło
Usługa Azure Data Factory obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
- Format Avro
- Format binarny
- Format tekstu rozdzielanego
- Format programu Excel
- Format JSON
- Format ORC
- Format Parquet
- Format XML
Następujące właściwości są obsługiwane w systemie plików w ustawieniach storeSettings w źródle kopiowania opartym na formacie:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze storeSettings musi być ustawiona na FileServerRead Ustawienia. |
Tak |
| Znajdź pliki do skopiowania: | ||
| OPCJA 1: ścieżka statyczna |
Skopiuj z podanej ścieżki folderu/pliku określonej w zestawie danych. Jeśli chcesz skopiować wszystkie pliki z folderu, dodatkowo określ wildcardFileName jako *. |
|
| OPCJA 2: filtr po stronie serwera -Filefilter |
Filtr natywny po stronie serwera plików, który zapewnia lepszą wydajność niż filtr wieloznaczny OPTION 3. Użyj * , aby dopasować zero lub więcej znaków i ? dopasować zero lub pojedynczy znak. Dowiedz się więcej na temat składni i notatek z uwag w tej sekcji. |
Nie. |
| OPCJA 3. Filtr po stronie klienta - symbol wieloznacznyFolderPath |
Ścieżka folderu z symbolami wieloznacznymi do filtrowania folderów źródłowych. Taki filtr odbywa się w usłudze, która wylicza foldery/pliki w ramach podanej ścieżki, a następnie stosuje filtr wieloznaczny. Dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku); użyj ^ klawisza , aby uniknąć, jeśli rzeczywista nazwa folderu ma symbol wieloznaczny lub znak ucieczki wewnątrz. Zobacz więcej przykładów w przykładach filtru folderów i plików. |
Nie. |
| OPCJA 3. Filtr po stronie klienta - symbol wieloznacznyFileName |
Nazwa pliku z symbolami wieloznacznymi w ramach danego folderuPath/symbol wieloznacznyFolderPath do filtrowania plików źródłowych. Taki filtr odbywa się w usłudze, która wylicza pliki w podanej ścieżce, a następnie stosuje filtr wieloznaczny. Dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku); użyj ^ klawisza , aby uniknąć, jeśli rzeczywista nazwa pliku ma symbol wieloznaczny lub znak ucieczki wewnątrz.Zobacz więcej przykładów w przykładach filtru folderów i plików. |
Tak |
| OPCJA 3: lista plików - fileListPath |
Wskazuje, aby skopiować dany zestaw plików. Wskaż plik tekstowy zawierający listę plików, które chcesz skopiować, jeden plik na wiersz, czyli ścieżkę względną do ścieżki skonfigurowanej w zestawie danych. W przypadku korzystania z tej opcji nie należy określać nazwy pliku w zestawie danych. Zobacz więcej przykładów na przykładach na liście plików. |
Nie. |
| Dodatkowe ustawienia: | ||
| Cykliczne | Wskazuje, czy dane są odczytywane rekursywnie z podfolderów, czy tylko z określonego folderu. Gdy rekursywna jest ustawiona na wartość true, a ujście jest magazynem opartym na plikach, pusty folder lub podfolder nie jest kopiowany ani tworzony w ujściu. Dozwolone wartości to true (wartość domyślna) i false. Ta właściwość nie ma zastosowania podczas konfigurowania fileListPathelementu . |
Nie. |
| deleteFilesAfterCompletion | Wskazuje, czy pliki binarne zostaną usunięte z magazynu źródłowego po pomyślnym przeniesieniu do magazynu docelowego. Usunięcie pliku jest na plik, więc gdy działanie kopiowania zakończy się niepowodzeniem, zobaczysz, że niektóre pliki zostały już skopiowane do miejsca docelowego i usunięte ze źródła, podczas gdy inne nadal pozostają w magazynie źródłowym. Ta właściwość jest prawidłowa tylko w scenariuszu kopiowania plików binarnych. Wartość domyślna: false. |
Nie. |
| modifiedDatetimeStart | Filtr plików na podstawie atrybutu: Ostatnia modyfikacja. Pliki są wybierane, jeśli ich czas ostatniej modyfikacji jest większy lub równy modifiedDatetimeStart i mniejszy niż modifiedDatetimeEnd. Czas jest stosowany do strefy czasowej UTC w formacie "2018-12-01T05:00:00Z". Właściwości mogą mieć wartość NULL, co oznacza, że do zestawu danych nie jest stosowany filtr atrybutu pliku. Jeśli modifiedDatetimeStart ma wartość data/godzina, ale modifiedDatetimeEnd ma wartość NULL, oznacza to, że wybrano pliki, których ostatnio zmodyfikowany atrybut jest większy lub równy wartości daty/godziny. Jeśli modifiedDatetimeEnd ma wartość datetime, ale modifiedDatetimeStart ma wartość NULL, oznacza to, że pliki, których ostatnio zmodyfikowany atrybut jest mniejszy niż wartość daty/godziny, są zaznaczone.Ta właściwość nie ma zastosowania podczas konfigurowania fileListPathelementu . |
Nie. |
| modifiedDatetimeEnd | Jak wyżej. | Nie. |
| enablePartitionDiscovery | W przypadku plików podzielonych na partycje określ, czy analizować partycje ze ścieżki pliku i dodać je jako dodatkowe kolumny źródłowe. Dozwolone wartości to false (wartość domyślna) i true. |
Nie. |
| partitionRootPath | Po włączeniu odnajdywania partycji określ bezwzględną ścieżkę katalogu głównego, aby odczytywać foldery podzielone na partycje jako kolumny danych. Jeśli nie jest określony, domyślnie, — Jeśli używasz ścieżki pliku w zestawie danych lub liście plików w źródle, ścieżka główna partycji jest ścieżką skonfigurowaną w zestawie danych. — W przypadku używania filtru folderów wieloznacznych ścieżka główna partycji jest ścieżką podrzędną przed pierwszym symbolem wieloznacznymi. Załóżmy na przykład, że ścieżka w zestawie danych zostanie skonfigurowana jako "root/folder/year=2020/month=08/day=27": - Jeśli określisz ścieżkę główną partycji jako "root/folder/year=2020", działanie kopiowania generuje dwie kolejne kolumny month i day z wartością "08" i "27" odpowiednio, oprócz kolumn w plikach.— Jeśli ścieżka główna partycji nie jest określona, nie jest generowana żadna dodatkowa kolumna. |
Nie. |
| maxConcurrent Połączenie ions | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
Przykład:
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "FileServerReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
System plików jako ujście
Usługa Azure Data Factory obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
Następujące właściwości są obsługiwane w przypadku systemu plików w ustawieniach storeSettings ujścia kopiowania opartego na formacie:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze storeSettings musi być ustawiona na FileServerWrite Ustawienia. |
Tak |
| copyBehavior | Definiuje zachowanie kopiowania, gdy źródłem są pliki z magazynu danych opartego na plikach. Dozwolone wartości to: - PreserveHierarchy (wartość domyślna): Zachowuje hierarchię plików w folderze docelowym. Względna ścieżka pliku źródłowego do folderu źródłowego jest identyczna ze względną ścieżką pliku docelowego do folderu docelowego. - FlattenHierarchy: Wszystkie pliki z folderu źródłowego znajdują się na pierwszym poziomie folderu docelowego. Pliki docelowe mają automatycznie wygenerowane nazwy. - MergeFiles: Scala wszystkie pliki z folderu źródłowego do jednego pliku. Jeśli określono nazwę pliku, scalona nazwa pliku jest określoną nazwą. W przeciwnym razie jest to automatycznie wygenerowana nazwa pliku. |
Nie. |
| maxConcurrent Połączenie ions | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
Przykład:
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "FileServerWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
Przykłady filtrów folderów i plików
W tej sekcji opisano wynikowe zachowanie ścieżki folderu i nazwy pliku z filtrami wieloznacznymi.
| folderPath | fileName | Cykliczne | Struktura folderu źródłowego i wynik filtru (pobierane są pliki pogrubione ) |
|---|---|---|---|
Folder* |
(puste, użyj wartości domyślnej) | fałsz | FolderA Plik1.csv Plik2.json Podfolder1 Plik3.csv Plik4.json Plik5.csv InnyfolderB Plik6.csv |
Folder* |
(puste, użyj wartości domyślnej) | prawda | FolderA Plik1.csv Plik2.json Podfolder1 Plik3.csv Plik4.json Plik5.csv InnyfolderB Plik6.csv |
Folder* |
*.csv |
fałsz | FolderA Plik1.csv Plik2.json Podfolder1 Plik3.csv Plik4.json Plik5.csv InnyfolderB Plik6.csv |
Folder* |
*.csv |
prawda | FolderA Plik1.csv Plik2.json Podfolder1 Plik3.csv Plik4.json Plik5.csv InnyfolderB Plik6.csv |
Przykłady listy plików
W tej sekcji opisano wynikowe zachowanie używania ścieżki listy plików w źródle działania kopiowania.
Zakładając, że masz następującą strukturę folderów źródłowych i chcesz skopiować pliki pogrubioną:
| Przykładowa struktura źródła | Zawartość w pliku FileListToCopy.txt | Konfiguracja potoku |
|---|---|---|
| root FolderA Plik1.csv Plik2.json Podfolder1 Plik3.csv Plik4.json Plik5.csv Metadane FileListToCopy.txt |
Plik1.csv Podfolder1/File3.csv Podfolder1/File5.csv |
W zestawie danych: - Ścieżka folderu: root/FolderAW źródle działania kopiowania: - Ścieżka listy plików: root/Metadata/FileListToCopy.txt Ścieżka listy plików wskazuje plik tekstowy w tym samym magazynie danych, który zawiera listę plików, które chcesz skopiować, jeden plik na wiersz ze ścieżką względną do ścieżki skonfigurowanej w zestawie danych. |
przykłady rekursywne i copyBehavior
W tej sekcji opisano wynikowe zachowanie operacji kopiowania dla różnych kombinacji wartości cyklicznych i copyBehavior.
| Cykliczne | copyBehavior | Struktura folderu źródłowego | Wynikowy element docelowy |
|---|---|---|---|
| prawda | preserveHierarchy | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy Folder1 jest tworzony z taką samą strukturą jak źródło: Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5. |
| prawda | flattenHierarchy | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z następującą strukturą: Folder1 automatycznie wygenerowana nazwa pliku File1 automatycznie wygenerowana nazwa dla pliku File2 automatycznie wygenerowana nazwa dla pliku File3 automatycznie wygenerowana nazwa dla pliku File4 automatycznie wygenerowana nazwa dla pliku File5 |
| prawda | mergeFiles | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z następującą strukturą: Folder1 Plik1 + Plik2 + Plik3 + Plik4 + Zawartość pliku 5 są scalane w jeden plik z automatycznie wygenerowaną nazwą pliku |
| fałsz | preserveHierarchy | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy Folder1 jest tworzony z następującą strukturą Folder1 Plik1 Plik2 Podfolder1 z plikami File3, File4 i File5 nie są pobierane. |
| fałsz | flattenHierarchy | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy Folder1 jest tworzony z następującą strukturą Folder1 automatycznie wygenerowana nazwa pliku File1 automatycznie wygenerowana nazwa dla pliku File2 Podfolder1 z plikami File3, File4 i File5 nie są pobierane. |
| fałsz | mergeFiles | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy Folder1 jest tworzony z następującą strukturą Folder1 Zawartość file1 + File2 jest scalona z jednym plikiem z automatycznie wygenerowaną nazwą pliku. automatycznie wygenerowana nazwa pliku File1 Podfolder1 z plikami File3, File4 i File5 nie są pobierane. |
Właściwości działania wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie Wyszukiwania.
Właściwości działania GetMetadata
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie GetMetadata.
Usuń właściwości działania
Aby dowiedzieć się więcej o właściwościach, zobacz Działanie Usuń.
Starsze modele
Uwaga
Następujące modele są nadal obsługiwane zgodnie ze zgodnością z poprzednimi wersjami. Zalecamy użycie nowego modelu wymienionego w powyższych sekcjach, a interfejs użytkownika tworzenia przeszedł do generowania nowego modelu.
Starszy model zestawu danych
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na: FileShare | Tak |
| folderPath | Ścieżka do folderu. Obsługiwany jest filtr wieloznaczny, dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku); użyj klawisza ^ , aby uniknąć, jeśli rzeczywista nazwa folderu ma symbol wieloznaczny lub znak ucieczki wewnątrz. Przykłady: rootfolder/subfolder/, zobacz więcej przykładów w przykładowej połączonej usłudze i definicjach zestawu danych oraz przykładach filtru folderów i plików. |
Nie. |
| fileName | Nazwa lub filtr symboli wieloznacznych dla plików w ramach określonego "folderPath". Jeśli nie określisz wartości dla tej właściwości, zestaw danych wskazuje wszystkie pliki w folderze. W przypadku filtru dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku).- Przykład 1: "fileName": "*.csv"— Przykład 2: "fileName": "???20180427.txt"Użyj ^ polecenia , aby uniknąć, jeśli rzeczywista nazwa pliku ma symbol wieloznaczny lub znak ucieczki wewnątrz.Jeśli parametr fileName nie jest określony dla wyjściowego zestawu danych i parametr preserveHierarchy nie jest określony w ujściu działania działania kopiowania, działanie kopiowania automatycznie generuje nazwę pliku z następującym wzorcem: "Dane.[ identyfikator GUID przebiegu działania]. [IDENTYFIKATOR GUID, jeśli FlattenHierarchy]. [format, jeśli został skonfigurowany]. [kompresja, jeśli skonfigurowano]", na przykład "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz"; jeśli kopiujesz ze źródła tabelarycznego przy użyciu nazwy tabeli zamiast zapytania, wzorzec nazwy to "[nazwa tabeli].[ format]. [kompresja, jeśli została skonfigurowana]", na przykład "MyTable.csv". |
Nie. |
| modifiedDatetimeStart | Filtr plików na podstawie atrybutu: Ostatnia modyfikacja. Pliki są wybierane, jeśli ich czas ostatniej modyfikacji jest większy lub równy modifiedDatetimeStart i mniejszy niż modifiedDatetimeEnd. Czas jest stosowany do strefy czasowej UTC w formacie "2018-12-01T05:00:00Z". Należy pamiętać, że ogólna wydajność przenoszenia danych ma wpływ na włączenie tego ustawienia, gdy chcesz filtrować pliki z ogromnych ilości plików. Właściwości mogą mieć wartość NULL, co oznacza, że do zestawu danych nie jest stosowany filtr atrybutu pliku. Jeśli modifiedDatetimeStart ma wartość data/godzina, ale modifiedDatetimeEnd ma wartość NULL, oznacza to, że wybrano pliki, których ostatnio zmodyfikowany atrybut jest większy lub równy wartości daty/godziny. Jeśli modifiedDatetimeEnd ma wartość data/godzina, ale modifiedDatetimeStart ma wartość NULL, oznacza to, że pliki, których ostatnio zmodyfikowany atrybut jest mniejszy niż wartość daty/godziny, zostanie wybrana. |
Nie. |
| modifiedDatetimeEnd | Filtr plików na podstawie atrybutu: Ostatnia modyfikacja. Pliki są wybierane, jeśli ich czas ostatniej modyfikacji jest większy lub równy modifiedDatetimeStart i mniejszy niż modifiedDatetimeEnd. Czas jest stosowany do strefy czasowej UTC w formacie "2018-12-01T05:00:00Z". Należy pamiętać, że ogólna wydajność przenoszenia danych ma wpływ na włączenie tego ustawienia, gdy chcesz filtrować pliki z ogromnych ilości plików. Właściwości mogą mieć wartość NULL, co oznacza, że do zestawu danych nie jest stosowany filtr atrybutu pliku. Jeśli modifiedDatetimeStart ma wartość data/godzina, ale modifiedDatetimeEnd ma wartość NULL, oznacza to, że wybrano pliki, których ostatnio zmodyfikowany atrybut jest większy lub równy wartości daty/godziny. Jeśli modifiedDatetimeEnd ma wartość datetime, ale modifiedDatetimeStart ma wartość NULL, oznacza to, że pliki, których ostatnio zmodyfikowany atrybut jest mniejszy niż wartość daty/godziny, są zaznaczone. |
Nie. |
| format | Jeśli chcesz skopiować pliki zgodnie z rzeczywistym użyciem między magazynami opartymi na plikach (kopiowanie binarne), pomiń sekcję formatowania zarówno w definicjach zestawu danych wejściowych, jak i wyjściowych. Jeśli chcesz przeanalizować lub wygenerować pliki w określonym formacie, obsługiwane są następujące typy formatów plików: TextFormat, JsonFormat, AvroFormat, OrcFormat, ParquetFormat. Ustaw właściwość type w formacie na jedną z tych wartości. Aby uzyskać więcej informacji, zobacz sekcje Format tekstu, Format Json, Avro Format, Orc Format i Parquet Format. |
Nie (tylko w scenariuszu kopiowania binarnego) |
| kompresja | Określ typ i poziom kompresji danych. Aby uzyskać więcej informacji, zobacz Obsługiwane formaty plików i koderów kompresji. Obsługiwane typy to: GZip, Deflate, BZip2 i ZipDeflate. Obsługiwane poziomy to: Optymalne i najszybsze. |
Nie. |
Napiwek
Aby skopiować wszystkie pliki w folderze, określ tylko folderPath .
Aby skopiować pojedynczy plik o podanej nazwie, określ folderPath ze częścią folderu i fileName nazwą pliku.
Aby skopiować podzbiór plików w folderze, określ folderPath ze częścią folderu i fileName z filtrem wieloznacznymi.
Uwaga
Jeśli używasz właściwości "fileFilter" dla filtru plików, jest ona nadal obsługiwana w niezmienionej postaci, podczas gdy zaleca się użycie nowej funkcji filtrowania dodanej do ciągu "fileName".
Przykład:
{
"name": "FileSystemDataset",
"properties": {
"type": "FileShare",
"linkedServiceName":{
"referenceName": "<file system linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "folder/subfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Starszy model źródła działania kopiowania
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na: FileSystemSource | Tak |
| Cykliczne | Wskazuje, czy dane są odczytywane rekursywnie z podfolderów, czy tylko z określonego folderu. Uwaga, gdy rekursywna jest ustawiona na wartość true, a ujście jest magazynem opartym na plikach, pusty folder/podfolder nie zostanie skopiowany/utworzony w ujściu. Dozwolone wartości to: true (wartość domyślna), false |
Nie. |
| maxConcurrent Połączenie ions | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
Przykład:
"activities":[
{
"name": "CopyFromFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<file system input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "FileSystemSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Starszy model ujścia działania kopiowania
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type ujścia działania kopiowania musi być ustawiona na: FileSystemSink | Tak |
| copyBehavior | Definiuje zachowanie kopiowania, gdy źródłem są pliki z magazynu danych opartego na plikach. Dozwolone wartości to: - PreserveHierarchy (wartość domyślna): zachowuje hierarchię plików w folderze docelowym. Względna ścieżka pliku źródłowego do folderu źródłowego jest identyczna ze względną ścieżką pliku docelowego do folderu docelowego. - FlattenHierarchy: wszystkie pliki z folderu źródłowego znajdują się na pierwszym poziomie folderu docelowego. Pliki docelowe mają automatycznie wygenerowaną nazwę. - MergeFiles: scala wszystkie pliki z folderu źródłowego do jednego pliku. Podczas scalania nie jest wykonywana deduplikacja rekordów. Jeśli określono nazwę pliku, scalona nazwa pliku będzie określoną nazwą; w przeciwnym razie zostanie wygenerowana automatycznie nazwa pliku. |
Nie. |
| maxConcurrent Połączenie ions | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
Przykład:
"activities":[
{
"name": "CopyToFileSystem",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<file system output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "FileSystemSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz obsługiwane magazyny danych.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla