Kopiowanie i przekształcanie danych w usłudze Microsoft Fabric Lakehouse przy użyciu usługi Azure Data Factory lub Azure Synapse Analytics
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Microsoft Fabric Lakehouse to platforma architektury danych do przechowywania danych, zarządzania nimi i analizowania danych ustrukturyzowanych i nieustrukturyzowanych w jednej lokalizacji. Aby uzyskać bezproblemowy dostęp do danych we wszystkich aparatach obliczeniowych w usłudze Microsoft Fabric, przejdź do obszaru Lakehouse i tabel delty , aby dowiedzieć się więcej. Domyślnie dane są zapisywane w tabeli Lakehouse Table w kolejności wirtualnej i można przejść do pozycji Optymalizacja tabel usługi Delta Lake i Kolejność V, aby uzyskać więcej informacji.
W tym artykule opisano sposób używania działanie Kopiuj do kopiowania danych z i do usługi Microsoft Fabric Lakehouse oraz używania Przepływ danych do przekształcania danych w usłudze Microsoft Fabric Lakehouse. Aby dowiedzieć się więcej, przeczytaj artykuł wprowadzający dotyczący usługi Azure Data Factory lub Azure Synapse Analytics.
Obsługiwane możliwości
Ten łącznik usługi Microsoft Fabric Lakehouse jest obsługiwany w następujących funkcjach:
| Obsługiwane możliwości | IR |
|---|---|
| działanie Kopiuj (źródło/ujście) | (1) (2) |
| Przepływ danych mapowania (źródło/ujście) | (1) |
| Działanie Lookup | (1) (2) |
| Działanie GetMetadata | (1) (2) |
| Działanie usuwania | (1) (2) |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
Rozpocznij
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi Microsoft Fabric Lakehouse przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę Microsoft Fabric Lakehouse w interfejsie użytkownika witryny Azure Portal.
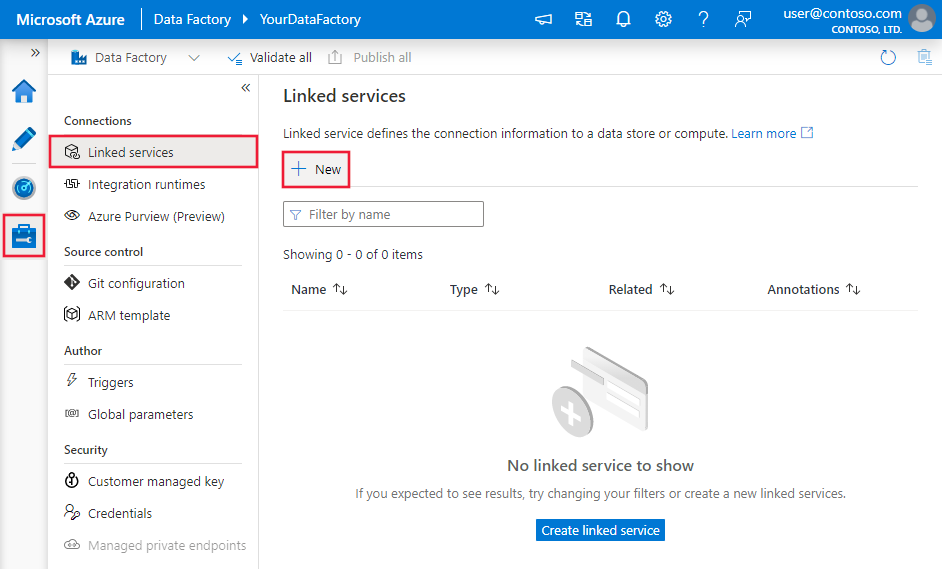
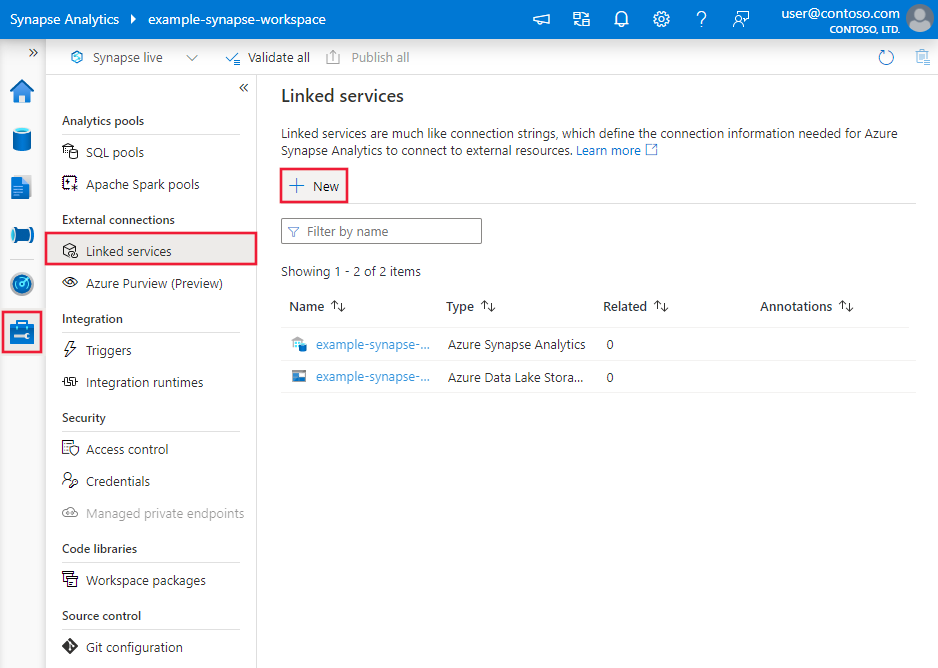
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie wybierz pozycję Nowe:
Wyszukaj pozycję Microsoft Fabric Lakehouse i wybierz łącznik.

Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.

szczegóły konfiguracji Połączenie or
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek usługi Data Factory specyficznych dla usługi Microsoft Fabric Lakehouse.
Właściwości połączonej usługi
Łącznik usługi Microsoft Fabric Lakehouse obsługuje następujące typy uwierzytelniania. Aby uzyskać szczegółowe informacje, zobacz odpowiednie sekcje:
Uwierzytelnianie nazwy głównej usługi
Aby użyć uwierzytelniania jednostki usługi, wykonaj następujące kroki.
Zarejestruj aplikację przy użyciu platformy Tożsamości Microsoft i dodaj wpis tajny klienta. Następnie zanotuj te wartości, których użyjesz do zdefiniowania połączonej usługi:
- Identyfikator aplikacji (klienta), który jest identyfikatorem jednostki usługi w połączonej usłudze.
- Wartość wpisu tajnego klienta, która jest kluczem jednostki usługi w połączonej usłudze.
- Identyfikator dzierżawy
Udziel jednostce usługi co najmniej roli Współautor w obszarze roboczym usługi Microsoft Fabric. Wykonaj te kroki:
Przejdź do obszaru roboczego usługi Microsoft Fabric, wybierz pozycję Zarządzaj dostępem na górnym pasku. Następnie wybierz pozycję Dodaj osoby lub grupy.


W okienku Dodawanie osób wprowadź nazwę główną usługi i wybierz jednostkę usługi z listy rozwijanej.
Określ rolę Współautor lub wyższy (Administracja, Członek), a następnie wybierz pozycję Dodaj.

Jednostka usługi jest wyświetlana w okienku Zarządzanie dostępem .
Te właściwości są obsługiwane w przypadku połączonej usługi:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na Lakehouse. | Tak |
| workspaceId | Identyfikator obszaru roboczego usługi Microsoft Fabric. | Tak |
| artifactId | Identyfikator obiektu Usługi Microsoft Fabric Lakehouse. | Tak |
| tenant | Określ informacje o dzierżawie (nazwę domeny lub identyfikator dzierżawy), w ramach których znajduje się aplikacja. Pobierz go, umieszczając wskaźnik myszy w prawym górnym rogu witryny Azure Portal. | Tak |
| servicePrincipalId | Określ identyfikator klienta aplikacji. | Tak |
| servicePrincipalCredentialType | Typ poświadczeń do użycia na potrzeby uwierzytelniania jednostki usługi. Dozwolone wartości to ServicePrincipalKey i ServicePrincipalCert. | Tak |
| servicePrincipalCredential | Poświadczenie jednostki usługi. W przypadku użycia klucza ServicePrincipalKey jako typu poświadczeń określ wartość klucza tajnego klienta aplikacji. Oznacz to pole jako SecureString , aby bezpiecznie je przechowywać lub odwołuje się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. Jeśli używasz klasy ServicePrincipalCert jako poświadczenia, odwołaj się do certyfikatu w usłudze Azure Key Vault i upewnij się, że typ zawartości certyfikatu to PKCS #12. |
Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime, jeśli magazyn danych znajduje się w sieci prywatnej. Jeśli nie zostanie określony, zostanie użyte domyślne środowisko Azure Integration Runtime. | Nie. |
Przykład: używanie uwierzytelniania klucza jednostki usługi
Klucz jednostki usługi można również przechowywać w usłudze Azure Key Vault.
{
"name": "MicrosoftFabricLakehouseLinkedService",
"properties": {
"type": "Lakehouse",
"typeProperties": {
"workspaceId": "<Microsoft Fabric workspace ID>",
"artifactId": "<Microsoft Fabric Lakehouse object ID>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Łącznik usługi Microsoft Fabric Lakehouse obsługuje dwa typy zestawów danych, które są zestawem danych usługi Microsoft Fabric Lakehouse Files i zestawem danych tabeli Microsoft Fabric Lakehouse. Aby uzyskać szczegółowe informacje, zobacz odpowiednie sekcje.
- Zestaw danych usługi Microsoft Fabric Lakehouse Files
- Zestaw danych tabel usługi Microsoft Fabric Lakehouse
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz Zestawy danych.
Zestaw danych usługi Microsoft Fabric Lakehouse Files
Łącznik usługi Microsoft Fabric Lakehouse obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
Następujące właściwości są obsługiwane w obszarze location ustawień w zestawie danych microsoft Fabric Lakehouse Files opartym na formacie:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze location w zestawie danych musi być ustawiona na LakehouseLocation. |
Tak |
| folderPath | Ścieżka do folderu. Jeśli chcesz używać symbolu wieloznakowego do filtrowania folderów, pomiń to ustawienie i określ je w ustawieniach źródła działań. | Nie. |
| fileName | Nazwa pliku pod danym folderPath. Jeśli chcesz używać symbolu wieloznakowego do filtrowania plików, pomiń to ustawienie i określ je w ustawieniach źródła działań. | Nie. |
Przykład:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"location": {
"type": "LakehouseLocation",
"fileName": "<file name>",
"folderPath": "<folder name>"
},
"columnDelimiter": ",",
"compressionCodec": "gzip",
"escapeChar": "\\",
"firstRowAsHeader": true,
"quoteChar": "\""
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ]
}
}
Zestaw danych tabel usługi Microsoft Fabric Lakehouse
Następujące właściwości są obsługiwane w przypadku zestawu danych tabel usługi Microsoft Fabric Lakehouse:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na LakehouseTable. | Tak |
| table | Nazwa tabeli. | Tak |
Przykład:
{
"name": "LakehouseTableDataset",
"properties": {
"type": "LakehouseTable",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"table": "<table_name>"
},
"schema": [< physical schema, optional, retrievable during authoring >]
}
}
Właściwości działania kopiowania
Właściwości działania kopiowania dla zestawu danych usługi Microsoft Fabric Lakehouse Files i zestawu danych tabeli Microsoft Fabric Lakehouse różnią się. Aby uzyskać szczegółowe informacje, zobacz odpowiednie sekcje.
- Pliki usługi Microsoft Fabric Lakehouse w działanie Kopiuj
- Tabela Usługi Microsoft Fabric Lakehouse w działanie Kopiuj
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz działanie Kopiuj konfiguracje i potoki i działania.
Pliki usługi Microsoft Fabric Lakehouse w działanie Kopiuj
Aby użyć typu zestawu danych usługi Microsoft Fabric Lakehouse Files jako źródła lub ujścia w działanie Kopiuj, przejdź do poniższych sekcji, aby uzyskać szczegółowe konfiguracje.
Microsoft Fabric Lakehouse Files jako typ źródła
Łącznik usługi Microsoft Fabric Lakehouse obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
Istnieje kilka opcji kopiowania danych z usługi Microsoft Fabric Lakehouse przy użyciu zestawu danych Microsoft Fabric Lakehouse Files:
- Skopiuj z podanej ścieżki określonej w zestawie danych.
- Filtr wieloznaczny względem ścieżki folderu lub nazwy pliku, zobacz
wildcardFolderPathiwildcardFileName. - Skopiuj pliki zdefiniowane w danym pliku tekstowym jako zestaw plików, zobacz
fileListPath.
Następujące właściwości znajdują się w storeSettings obszarze ustawień w źródle kopiowania opartym na formacie podczas korzystania z zestawu danych usługi Microsoft Fabric Lakehouse Files:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze storeSettings musi być ustawiona na LakehouseRead Ustawienia. |
Tak |
| Znajdź pliki do skopiowania: | ||
| OPCJA 1: ścieżka statyczna |
Skopiuj z folderu/ścieżki pliku określonej w zestawie danych. Jeśli chcesz skopiować wszystkie pliki z folderu, dodatkowo określ wildcardFileName jako *. |
|
| OPCJA 2: symbol wieloznaczny - symbol wieloznacznyFolderPath |
Ścieżka folderu z symbolami wieloznacznymi do filtrowania folderów źródłowych. Dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku); użyj ^ klawisza , aby uniknąć, jeśli rzeczywista nazwa folderu ma symbol wieloznaczny lub znak ucieczki wewnątrz. Zobacz więcej przykładów w przykładach filtru folderów i plików. |
Nie. |
| OPCJA 2: symbol wieloznaczny - symbol wieloznacznyFileName |
Nazwa pliku z symbolami wieloznacznymi w ramach danego folderuPath/symbol wieloznacznyFolderPath do filtrowania plików źródłowych. Dozwolone symbole wieloznaczne to: * (pasuje do zera lub większej liczby znaków) i ? (pasuje do zera lub pojedynczego znaku); użyj ^ klawisza , aby uniknąć, jeśli rzeczywista nazwa pliku ma symbol wieloznaczny lub znak ucieczki wewnątrz. Zobacz więcej przykładów w przykładach filtru folderów i plików. |
Tak |
| OPCJA 3: lista plików - fileListPath |
Wskazuje, aby skopiować dany zestaw plików. Wskaż plik tekstowy zawierający listę plików, które chcesz skopiować, jeden plik na wiersz, czyli ścieżkę względną do ścieżki skonfigurowanej w zestawie danych. W przypadku korzystania z tej opcji nie należy określać nazwy pliku w zestawie danych. Zobacz więcej przykładów na przykładach na liście plików. |
Nie. |
| Dodatkowe ustawienia: | ||
| Cykliczne | Wskazuje, czy dane są odczytywane rekursywnie z podfolderów, czy tylko z określonego folderu. Gdy rekursywna jest ustawiona na wartość true, a ujście jest magazynem opartym na plikach, pusty folder lub podfolder nie jest kopiowany ani tworzony w ujściu. Dozwolone wartości to true (wartość domyślna) i false. Ta właściwość nie ma zastosowania podczas konfigurowania fileListPathelementu . |
Nie. |
| deleteFilesAfterCompletion | Wskazuje, czy pliki binarne zostaną usunięte z magazynu źródłowego po pomyślnym przeniesieniu do magazynu docelowego. Usunięcie pliku jest na plik, więc gdy działanie kopiowania nie powiedzie się, zobaczysz, że niektóre pliki zostały już skopiowane do miejsca docelowego i usunięte ze źródła, podczas gdy inne nadal pozostają w magazynie źródłowym. Ta właściwość jest prawidłowa tylko w scenariuszu kopiowania plików binarnych. Wartość domyślna: false. |
Nie. |
| modifiedDatetimeStart | Filtr plików na podstawie atrybutu: Ostatnia modyfikacja. Pliki zostaną wybrane, jeśli ich czas ostatniej modyfikacji jest większy lub równy modifiedDatetimeStart i mniejszy niż modifiedDatetimeEnd. Czas jest stosowany do strefy czasowej UTC w formacie "2018-12-01T05:00:00Z". Właściwości mogą mieć wartość NULL, co oznacza, że do zestawu danych nie jest stosowany filtr atrybutu pliku. Jeśli modifiedDatetimeStart ma wartość datetime, ale modifiedDatetimeEnd ma wartość NULL, oznacza to, że zostaną wybrane pliki, których ostatni zmodyfikowany atrybut jest większy lub równy wartości daty/godziny. Jeśli modifiedDatetimeEnd ma wartość data/godzina, ale modifiedDatetimeStart ma wartość NULL, oznacza to, że pliki, których ostatnio zmodyfikowany atrybut jest mniejszy niż wartość daty/godziny, zostanie wybrana.Ta właściwość nie ma zastosowania podczas konfigurowania fileListPathelementu . |
Nie. |
| modifiedDatetimeEnd | Jak wyżej. | Nie. |
| enablePartitionDiscovery | W przypadku plików podzielonych na partycje określ, czy należy przeanalizować partycje ze ścieżki pliku i dodać je jako inne kolumny źródłowe. Dozwolone wartości to false (wartość domyślna) i true. |
Nie. |
| partitionRootPath | Po włączeniu odnajdywania partycji określ bezwzględną ścieżkę katalogu głównego, aby odczytywać foldery podzielone na partycje jako kolumny danych. Jeśli nie jest określony, domyślnie, — Jeśli używasz ścieżki pliku w zestawie danych lub liście plików w źródle, ścieżka główna partycji jest ścieżką skonfigurowaną w zestawie danych. — W przypadku używania filtru folderów wieloznacznych ścieżka główna partycji jest ścieżką podrzędną przed pierwszym symbolem wieloznacznymi. Załóżmy na przykład, że ścieżka w zestawie danych zostanie skonfigurowana jako "root/folder/year=2020/month=08/day=27": - Jeśli określisz ścieżkę główną partycji jako "root/folder/year=2020", działanie kopiowania generuje dwie kolejne kolumny month i day z wartością "08" i "27" odpowiednio, oprócz kolumn w plikach.— Jeśli ścieżka główna partycji nie jest określona, nie jest generowana żadna dodatkowa kolumna. |
Nie. |
| maxConcurrent Połączenie ions | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
Przykład:
"activities": [
{
"name": "CopyFromLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "LakehouseReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Microsoft Fabric Lakehouse Files jako typ ujścia
Łącznik usługi Microsoft Fabric Lakehouse obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
Następujące właściwości znajdują się w storeSettings ustawieniach ujścia kopiowania opartego na formacie podczas korzystania z zestawu danych usługi Microsoft Fabric Lakehouse Files:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type w obszarze storeSettings musi być ustawiona na LakehouseWrite Ustawienia. |
Tak |
| copyBehavior | Definiuje zachowanie kopiowania, gdy źródłem są pliki z magazynu danych opartego na plikach. Dozwolone wartości to: - PreserveHierarchy (wartość domyślna): Zachowuje hierarchię plików w folderze docelowym. Ścieżka względna pliku źródłowego do folderu źródłowego jest identyczna ze ścieżką względną pliku docelowego do folderu docelowego. - FlattenHierarchy: Wszystkie pliki z folderu źródłowego znajdują się na pierwszym poziomie folderu docelowego. Pliki docelowe mają automatycznie wygenerowane nazwy. - MergeFiles: Scala wszystkie pliki z folderu źródłowego do jednego pliku. Jeśli określono nazwę pliku, scalona nazwa pliku jest określoną nazwą. W przeciwnym razie jest to automatycznie wygenerowana nazwa pliku. |
Nie. |
| blockSizeInMB | Określ rozmiar bloku w MB używany do zapisywania danych w usłudze Microsoft Fabric Lakehouse. Dowiedz się więcej o blokowych obiektach blob. Dozwolona wartość wynosi od 4 MB do 100 MB. Domyślnie usługa ADF automatycznie określa rozmiar bloku na podstawie typu magazynu źródłowego i danych. W przypadku kopii niebinarnej do usługi Microsoft Fabric Lakehouse domyślny rozmiar bloku wynosi 100 MB, tak aby mieścił się w danych o rozmiarze co najwyżej 4,75 TB. Może to nie być optymalne, gdy dane nie są duże, zwłaszcza w przypadku korzystania z własnego środowiska Integration Runtime z niską wydajnością lub przekroczeniem limitu czasu operacji. Można jawnie określić rozmiar bloku, podczas gdy upewnij się, że parametr blockSizeInMB*50000 jest wystarczająco duży, aby przechowywać dane, w przeciwnym razie uruchomienie działania kopiowania kończy się niepowodzeniem. |
Nie. |
| maxConcurrent Połączenie ions | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | Nie. |
| metadane | Ustaw metadane niestandardowe podczas kopiowania do ujścia. Każdy obiekt w tablicy metadata reprezentuje dodatkową kolumnę. Element name definiuje nazwę klucza metadanych i value wskazuje wartość danych tego klucza. Jeśli jest używana funkcja zachowania atrybutów, określone metadane będą union/overwrite z metadanymi pliku źródłowego.Dozwolone wartości danych to: - $$LASTMODIFIED: zmienna zarezerwowana wskazuje czas ostatniej modyfikacji plików źródłowych. Zastosuj do źródła opartego na plikach tylko z formatem binarnym.-Wyrażenie - Wartość statyczna |
Nie. |
Przykład:
"activities": [
{
"name": "CopyToLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings": {
"type": "LakehouseWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
}
]
},
"formatSettings": {
"type": "ParquetWriteSettings"
}
}
}
}
]
Przykłady filtrów folderów i plików
W tej sekcji opisano wynikowe zachowanie ścieżki folderu i nazwy pliku z filtrami wieloznacznymi.
| folderPath | fileName | Cykliczne | Struktura folderu źródłowego i wynik filtru (pobierane są pliki pogrubione ) |
|---|---|---|---|
Folder* |
(Puste, użyj wartości domyślnej) | fałsz | FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
Folder* |
(Puste, użyj wartości domyślnej) | prawda | FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
Folder* |
*.csv |
fałsz | FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
Folder* |
*.csv |
prawda | FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv InnyfolderB File6.csv |
Przykłady listy plików
W tej sekcji opisano wynikowe zachowanie używania ścieżki listy plików w źródle działania kopiowania.
Zakładając, że masz następującą strukturę folderów źródłowych i chcesz skopiować pliki pogrubioną:
| Przykładowa struktura źródła | Zawartość w FileListToCopy.txt | Konfiguracja usługi ADF |
|---|---|---|
| System plików FolderA File1.csv File2.json Podfolder1 File3.csv File4.json File5.csv Metadane FileListToCopy.txt |
File1.csv Podfolder1/File3.csv Podfolder1/File5.csv |
W zestawie danych: - Ścieżka folderu: FolderAW źródle działania kopiowania: - Ścieżka listy plików: Metadata/FileListToCopy.txt Ścieżka listy plików wskazuje plik tekstowy w tym samym magazynie danych, który zawiera listę plików, które chcesz skopiować, jeden plik na wiersz ze ścieżką względną do ścieżki skonfigurowanej w zestawie danych. |
Niektóre przykłady rekursywne i copyBehavior
W tej sekcji opisano wynikowe zachowanie operacji kopiowania dla różnych kombinacji wartości cyklicznych i copyBehavior.
| Cykliczne | copyBehavior | Struktura folderu źródłowego | Wynikowy element docelowy |
|---|---|---|---|
| prawda | preserveHierarchy | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z taką samą strukturą jak źródło: Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
| prawda | flattenHierarchy | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z następującą strukturą: Folder1 automatycznie wygenerowana nazwa pliku File1 automatycznie wygenerowana nazwa dla pliku File2 automatycznie wygenerowana nazwa dla pliku File3 automatycznie wygenerowana nazwa dla pliku File4 automatycznie wygenerowana nazwa dla pliku File5 |
| prawda | mergeFiles | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z następującą strukturą: Folder1 Plik1 + Plik2 + Plik3 + Plik4 + Zawartość pliku5 są scalane w jeden plik z automatycznie wygenerowaną nazwą pliku. |
| fałsz | preserveHierarchy | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z następującą strukturą: Folder1 Plik1 Plik2 Podfolder1 z plikiem File3, File4 i File5 nie jest pobierany. |
| fałsz | flattenHierarchy | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z następującą strukturą: Folder1 automatycznie wygenerowana nazwa pliku File1 automatycznie wygenerowana nazwa dla pliku File2 Podfolder1 z plikiem File3, File4 i File5 nie jest pobierany. |
| fałsz | mergeFiles | Folder1 Plik1 Plik2 Podfolder1 Plik3 Plik4 Plik5 |
Folder docelowy1 jest tworzony z następującą strukturą: Folder1 Zawartość file1 + File2 jest scalona z jednym plikiem z automatycznie wygenerowaną nazwą pliku. automatycznie wygenerowana nazwa pliku File1 Podfolder1 z plikiem File3, File4 i File5 nie jest pobierany. |
Tabela Usługi Microsoft Fabric Lakehouse w działanie Kopiuj
Aby użyć zestawu danych tabel usługi Microsoft Fabric Lakehouse jako zestawu danych źródłowego lub ujścia w działanie Kopiuj, przejdź do poniższych sekcji, aby uzyskać szczegółowe konfiguracje.
Microsoft Fabric Lakehouse Table jako typ źródła
Aby skopiować dane z usługi Microsoft Fabric Lakehouse przy użyciu zestawu danych microsoft Fabric Lakehouse Table, ustaw właściwość type w źródle działanie Kopiuj na LakehouseTableSource. Następujące właściwości są obsługiwane w sekcji źródła działanie Kopiuj:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na LakehouseTableSource. | Tak |
| timestampAsOf | Sygnatura czasowa do wykonywania zapytań względem starszej migawki. | Nie. |
| versionAsOf | Wersja do wykonywania zapytań względem starszej migawki. | Nie. |
Przykład:
"activities":[
{
"name": "CopyFromLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "LakehouseTableSource",
"timestampAsOf": "2023-09-23T00:00:00.000Z",
"versionAsOf": 2
},
"sink": {
"type": "<sink type>"
}
}
}
]
Microsoft Fabric Lakehouse Table jako typ ujścia
Aby skopiować dane do usługi Microsoft Fabric Lakehouse przy użyciu zestawu danych microsoft Fabric Lakehouse Table, ustaw właściwość type w ujściu działania kopiowania na wartość LakehouseTableSink. Następujące właściwości są obsługiwane w sekcji ujścia działanie Kopiuj:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na LakehouseTableSink. | Tak |
Uwaga
Dane są domyślnie zapisywane w tabeli Lakehouse w kolejności wirtualnej. Aby uzyskać więcej informacji, przejdź do pozycji Optymalizacja tabel usługi Delta Lake i Kolejność wirtualna.
Przykład:
"activities":[
{
"name": "CopyToLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "LakehouseTableSink",
"tableActionOption ": "Append"
}
}
}
]
Właściwości przepływu mapowania danych
Podczas przekształcania danych w przepływie mapowania danych można odczytywać i zapisywać w plikach lub tabelach w usłudze Microsoft Fabric Lakehouse. Aby uzyskać szczegółowe informacje, zobacz odpowiednie sekcje.
- Pliki usługi Microsoft Fabric Lakehouse w przepływie danych mapowania
- Tabela Usługi Microsoft Fabric Lakehouse w przepływie danych mapowania
Aby uzyskać więcej informacji, zobacz przekształcanie źródła i przekształcanie ujścia w przepływach danych mapowania.
Pliki usługi Microsoft Fabric Lakehouse w przepływie danych mapowania
Aby użyć zestawu danych usługi Microsoft Fabric Lakehouse Files jako zestawu danych źródłowego lub ujścia w przepływie danych mapowania, przejdź do poniższych sekcji, aby uzyskać szczegółowe konfiguracje.
Microsoft Fabric Lakehouse Files jako typ źródła lub ujścia
Łącznik usługi Microsoft Fabric Lakehouse obsługuje następujące formaty plików. Zapoznaj się z każdym artykułem, aby zapoznać się z ustawieniami opartymi na formacie.
Aby użyć łącznika opartego na plikach usługi Fabric Lakehouse w wbudowanym typie zestawu danych, musisz wybrać odpowiedni typ wbudowanego zestawu danych. W zależności od formatu danych można użyć delimitedText, Avro, JSON, ORC lub Parquet.
Tabela Usługi Microsoft Fabric Lakehouse w przepływie danych mapowania
Aby użyć zestawu danych tabel usługi Microsoft Fabric Lakehouse jako zestawu danych źródłowego lub ujścia w przepływie danych mapowania, przejdź do poniższych sekcji, aby uzyskać szczegółowe konfiguracje.
Microsoft Fabric Lakehouse Table jako typ źródła
W obszarze opcji źródła nie ma konfigurowalnych właściwości.
Uwaga
Obsługa usługi CDC dla źródła tabeli Lakehouse jest obecnie niedostępna.
Microsoft Fabric Lakehouse Table jako typ ujścia
Następujące właściwości są obsługiwane w sekcji ujście mapowania Przepływ danych:
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Metoda aktualizacji | Po wybraniu opcji "Zezwalaj na wstawianie" lub zapisie w nowej tabeli delty obiekt docelowy odbiera wszystkie wiersze przychodzące niezależnie od zestawu zasad wierszy. Jeśli dane zawierają wiersze innych zasad wierszy, należy je wykluczyć przy użyciu poprzedniego przekształcenia filtru. Po wybraniu wszystkich metod aktualizacji jest wykonywane scalanie, w którym wiersze są wstawiane/usuwane/upserted/aktualizowane zgodnie z zasadami wierszy ustawionymi przy użyciu poprzedniego przekształcenia Alter Row. |
tak | true lub false |
możliwość wstawienia możliwe do usunięcia upsertable Aktualizowana |
| Zoptymalizowany zapis | Osiągnij większą przepływność operacji zapisu dzięki optymalizacji wewnętrznego mieszania w funkcjach wykonawczych platformy Spark. W związku z tym można zauważyć mniejszą liczbę partycji i plików o większym rozmiarze | nie | true lub false |
optimizedWrite: true |
| Autokompaktuj | Po zakończeniu każdej operacji zapisu platforma Spark automatycznie wykona OPTIMIZE polecenie w celu zreorganizowania danych, co w razie potrzeby spowoduje zwiększenie wydajności odczytu w przyszłości większej liczby partycji |
nie | true lub false |
autoCompact: true |
| Scal schemat | Opcja scalania schematu umożliwia ewolucję schematu, czyli wszystkie kolumny, które znajdują się w bieżącym strumieniu przychodzącym, ale nie w docelowej tabeli delty, są automatycznie dodawane do jego schematu. Ta opcja jest obsługiwana we wszystkich metodach aktualizacji. | nie | true lub false |
mergeSchema: true |
Przykład: ujście tabeli usługi Microsoft Fabric Lakehouse
sink(allowSchemaDrift: true,
validateSchema: false,
input(
CustomerID as string,
NameStyle as string,
Title as string,
FirstName as string,
MiddleName as string,
LastName as string,
Suffix as string,
CompanyName as string,
SalesPerson as string,
EmailAddress as string,
Phone as string,
PasswordHash as string,
PasswordSalt as string,
rowguid as string,
ModifiedDate as string
),
deletable:false,
insertable:true,
updateable:false,
upsertable:false,
optimizedWrite: true,
mergeSchema: true,
autoCompact: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CustomerTable
W przypadku łącznika opartego na tabelach usługi Fabric Lakehouse w wbudowanym typie zestawu danych wystarczy użyć funkcji Delta jako typu zestawu danych. Umożliwi to odczytywanie i zapisywanie danych z tabel usługi Fabric Lakehouse.
Właściwości działania wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie Wyszukiwania.
Właściwości działania GetMetadata
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie GetMetadata
Usuń właściwości działania
Aby dowiedzieć się więcej o właściwościach, zobacz Działanie Usuwania
Powiązana zawartość
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz Obsługiwane magazyny danych.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla