Używanie rejestrowania selektywnego za pomocą akcji skryptu w usłudze Azure HDInsight
Dzienniki usługi Azure Monitor to usługa Azure Monitor, która monitoruje środowiska chmurowe i lokalne. Monitorowanie pomaga zachować ich dostępność i wydajność.
Dzienniki usługi Azure Monitor zbierają dane generowane przez zasoby w chmurze, zasoby w środowiskach lokalnych i inne narzędzia do monitorowania. Używa ona danych do zapewniania analizy w wielu źródłach. Aby uzyskać analizę, włącz funkcję rejestrowania selektywnego przy użyciu akcji skryptu dla usługi HDInsight w witrynie Azure Portal.
Informacje o selektywnym rejestrowaniu
Selektywne rejestrowanie jest częścią ogólnego systemu monitorowania na platformie Azure. Po połączeniu klastra z obszarem roboczym usługi Log Analytics i włączeniu rejestrowania selektywnego można zobaczyć dzienniki i metryki, takie jak dzienniki zabezpieczeń usługi HDInsight, usługa Yarn Resource Manager i metryki systemowe. Możesz monitorować obciążenia i zobaczyć, jak wpływają one na stabilność klastra.
Selektywne rejestrowanie umożliwia włączenie lub wyłączenie wszystkich tabel lub włączenie wybranych tabel w obszarze roboczym usługi Log Analytics. Można dostosować typ źródła dla każdej tabeli.
Uwaga
Jeśli usługa Log Analytics zostanie ponownie zainstalowana w klastrze, należy ponownie wyłączyć wszystkie tabele i typy dzienników. Ponowna instalacja resetuje wszystkie pliki konfiguracji do ich pierwotnego stanu.
Zagadnienia dotyczące akcji skryptu
- System monitorowania używa demona serwera metadanych (agenta monitorowania) i Fluentd do zbierania dzienników przy użyciu ujednoliconej warstwy rejestrowania.
- Selektywne rejestrowanie używa akcji skryptu do wyłączania lub włączania tabel i ich typów dzienników. Ponieważ selektywne rejestrowanie nie otwiera żadnych nowych portów ani nie zmienia żadnych istniejących ustawień zabezpieczeń, nie ma żadnych zmian zabezpieczeń.
- Akcja skryptu jest uruchamiana równolegle we wszystkich określonych węzłach i zmienia pliki konfiguracji dotyczące wyłączania lub włączania tabel i ich typów dzienników.
Wymagania wstępne
- Obszar roboczy usługi Log Analytics. Ten obszar roboczy można traktować jako unikatowe środowisko dzienników usługi Azure Monitor z własnym repozytorium danych, źródłami danych i rozwiązaniami. Aby uzyskać instrukcje, zobacz Tworzenie obszaru roboczego usługi Log Analytics.
- Klaster usługi Azure HDInsight. Obecnie można użyć funkcji rejestrowania selektywnego z następującymi typami klastrów usługi HDInsight:
- Hadoop
- HBase
- Zapytanie interakcyjne
- platforma Spark
Aby uzyskać instrukcje dotyczące tworzenia klastra usługi HDInsight, zobacz Wprowadzenie do usługi Azure HDInsight.
Włączanie lub wyłączanie dzienników przy użyciu akcji skryptu dla wielu tabel i typów dzienników
Przejdź do pozycji Akcje skryptu w klastrze i wybierz pozycję Prześlij nowy , aby rozpocząć proces tworzenia akcji skryptu.
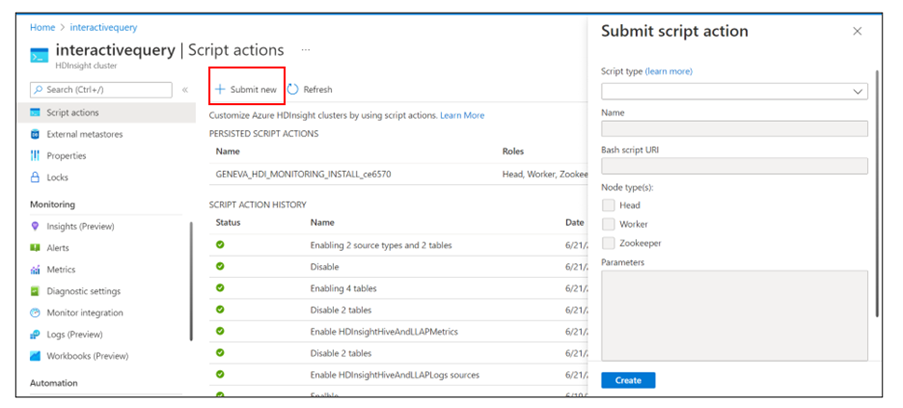
Zostanie wyświetlone okienko akcji Prześlij skrypt.
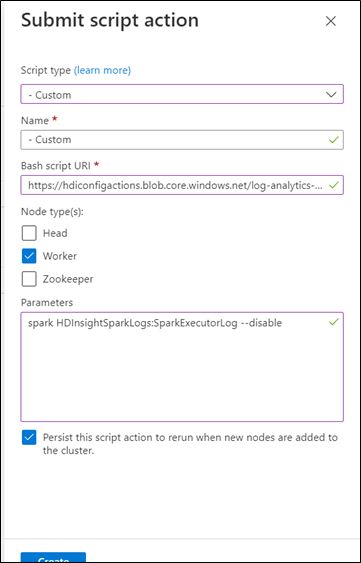
Dla typu skryptu wybierz pozycję Niestandardowe.
Nadaj skryptowi nazwę. Na przykład: Wyłącz dwie tabele i dwa źródła.
Identyfikator URI skryptu powłoki Bash musi być linkiem do selectiveLoggingScript.sh.
Wybierz wszystkie typy węzłów, które mają zastosowanie do klastra. Dostępne opcje to węzeł główny, węzeł procesu roboczego i węzeł ZooKeeper.
Zdefiniuj parametry. Przykład:
- Iskra:
spark HDInsightSparkLogs:SparkExecutorLog --disable - Zapytanie interakcyjne:
interactivehive HDInsightSparkLogs:SparkExecutorLog --enable - Hadoop:
hadoop HDInsightSparkLogs:SparkExecutorLog --disable - Hbase:
hbase HDInsightSparkLogs: HDInsightHBaseLogs --enable
Aby uzyskać więcej informacji, zobacz sekcję Składnia parametrów.
- Iskra:
Wybierz pozycję Utwórz.
Po kilku minutach obok historii akcji skryptu pojawi się zielony znacznik wyboru. Oznacza to, że skrypt został pomyślnie uruchomiony.

Zmiany zostaną wyświetlone w obszarze roboczym usługi Log Analytics.
Rozwiązywanie problemów
W obszarze roboczym usługi Log Analytics nie są wyświetlane żadne zmiany
Jeśli przesyłasz akcję skryptu, ale nie ma żadnych zmian w obszarze roboczym usługi Log Analytics:
W obszarze Pulpity nawigacyjne wybierz pozycję Strona główna systemu Ambari, aby sprawdzić informacje debugowania.
Wybierz przycisk Ustawienia.
Wybierz najnowszy skrypt uruchom w górnej części listy operacji w tle.
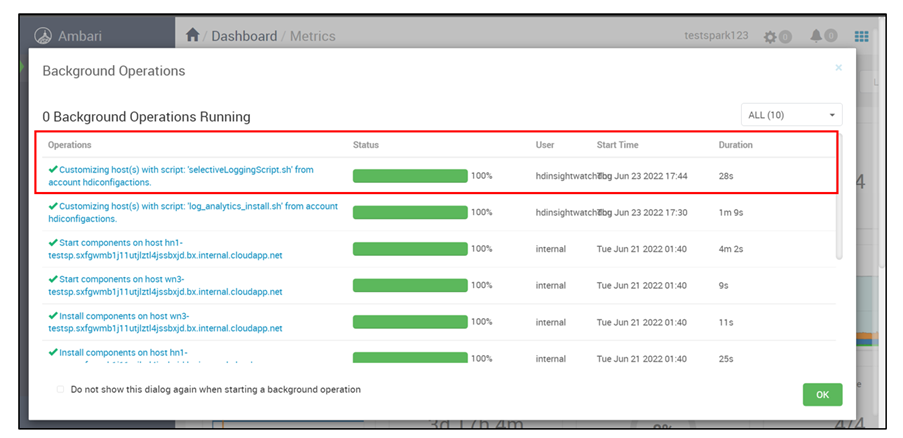
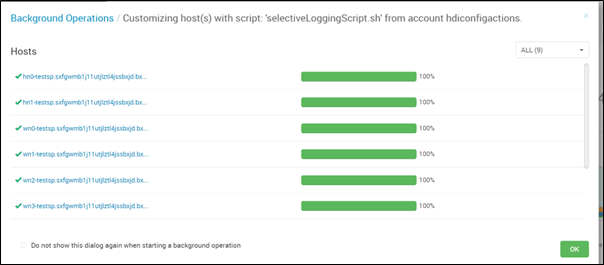
Sprawdź stan uruchomienia skryptu we wszystkich węzłach osobno.
Sprawdź, czy składnia parametrów z sekcji składni parametrów jest poprawna.
Sprawdź, czy obszar roboczy usługi Log Analytics jest połączony z klastrem i czy monitorowanie usługi Log Analytics jest włączone.
Sprawdź, czy zaznaczono akcję Utrwał ten skrypt, aby ponownie uruchomić po dodaniu nowych węzłów do klastra dla uruchomionej akcji skryptu.
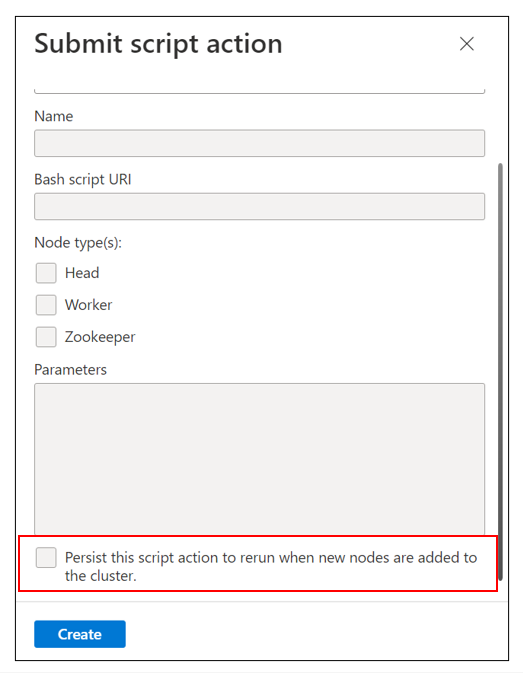
Sprawdź, czy nowy węzeł został ostatnio dodany do klastra.
Uwaga
Aby skrypt działał w najnowszym klastrze, skrypt musi być utrwalany.
Upewnij się, że wybrano wszystkie typy węzłów, które chcesz wykonać dla akcji skryptu.

Akcja skryptu nie powiodła się
Jeśli akcja skryptu wyświetla stan niepowodzenia w historii akcji skryptu:
- Sprawdź, czy składnia parametrów z sekcji składni parametrów jest poprawna.
- Sprawdź, czy link skryptu jest poprawny. Powinien to być:
https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/selectiveLoggingScripts/selectiveLoggingScript.sh.
Nazwy tabel
Klaster Spark
Poniższe nazwy tabel dotyczą różnych typów dzienników (źródeł) w tabelach platformy Spark.
| Numer źródłowy | Nazwa tabeli | Typy dzienników | opis |
|---|---|---|---|
| 1. | Alerty usługi HDInsightAmbariCluster | Brak typów dzienników | Ta tabela zawiera alerty klastra Ambari z każdego węzła w klastrze (z wyjątkiem węzłów brzegowych). Każdy alert jest rekordem w tej tabeli. |
| 2. | Metryki hdInsightAmbariSystem | Brak typów dzienników | Ta tabela zawiera metryki systemowe zebrane z systemu Ambari. Metryki pochodzą teraz z każdego węzła w klastrze (z wyjątkiem węzłów brzegowych) zamiast tylko dwóch węzłów głównych. Każda metryka jest teraz kolumną, a każda metryka jest zgłaszana raz na rekord. |
| 3. | HDInsightHadoopAnd YarnLogs | Węzeł główny: MRJobSummary, Resource Manager, TimelineServer Worker node: NodeManager | Ta tabela zawiera wszystkie dzienniki wygenerowane na podstawie platform Hadoop i YARN. |
| 4. | Dzienniki zabezpieczeń usługi HDInsight | AmbariAuditLog, AuthLog | Ta tabela zawiera rekordy z dzienników inspekcji i uwierzytelniania systemu Ambari. |
| 5. | Dzienniki usługi HDInsightSpark | Węzeł główny: JupyterLog, LivyLog, SparkThriftDriverLog Worker node: SparkExecutorLog, SparkDriverLog | Ta tabela zawiera wszystkie dzienniki związane z platformą Spark i powiązanymi składnikami: Livy i Jupyter. |
| 6. | HDInsightHadoopAnd YarnMetrics | Brak typów dzienników | Ta tabela zawiera metryki JMX z platform Hadoop i YARN. Zawiera wszystkie te same metryki JMX co stare tabele dzienników niestandardowych oraz więcej metryk, które uznaliśmy za ważne. Dodaliśmy metryki Serwer osi czasu, Menedżer węzłów i Serwer historii zadań. Zawiera jedną metryki na rekord. |
| 7. | HDInsightOozieLogs | Oozie | Ta tabela zawiera wszystkie dzienniki wygenerowane na podstawie struktury Oozie. |
Klaster zapytań interakcyjnych
Poniższe nazwy tabel dotyczą różnych typów dzienników (źródeł) w tabelach Interactive Query.
| Numer źródłowy | Nazwa tabeli | Typy dzienników | opis |
|---|---|---|---|
| 1. | HDInsightAmbariClusterAlerts | Brak typów dzienników | Ta tabela zawiera alerty klastra Ambari z każdego węzła w klastrze (z wyjątkiem węzłów brzegowych). Każdy alert jest rekordem w tej tabeli. |
| 2. | Metryki hdInsightAmbariSystem | Brak typów dzienników | Ta tabela zawiera metryki systemowe zebrane z systemu Ambari. Metryki pochodzą teraz z każdego węzła w klastrze (z wyjątkiem węzłów brzegowych) zamiast tylko dwóch węzłów głównych. Każda metryka jest teraz kolumną, a każda metryka jest zgłaszana raz na rekord. |
| 3. | HDInsightHadoopAndYarnLogs | Węzeł główny: MRJobSummary, Resource Manager, TimelineServer Worker node: NodeManager | Ta tabela zawiera wszystkie dzienniki wygenerowane na podstawie platform Hadoop i YARN. |
| 4. | HDInsightHadoopAndYarnMetrics | Brak typów dzienników | Ta tabela zawiera metryki JMX z platform Hadoop i YARN. Zawiera wszystkie te same metryki JMX co stare tabele dzienników niestandardowych oraz więcej metryk, które uznaliśmy za ważne. Dodaliśmy metryki Serwer osi czasu, Menedżer węzłów i Serwer historii zadań. Zawiera jedną metryki na rekord. |
| 5. | HDInsightHiveAndLLAPLogs | Węzeł główny: InteractiveHiveHSILog, InteractiveHiveMetastoreLog, ZeppelinLog | Ta tabela zawiera dzienniki wygenerowane na podstawie technologii Hive, LLAP i ich powiązanych składników: WebHCat i Zeppelin. |
| 6. | HDInsightHiveAndLLAPmetrics | Brak typów dzienników | Ta tabela zawiera metryki JMX z platform Hive i LLAP. Zawiera wszystkie te same metryki JMX co stare tabele dzienników niestandardowych. Zawiera jedną metryki na rekord. |
| 7. | HDInsightHiveTezAppStats | Brak typów dzienników | |
| 8. | Dzienniki zabezpieczeń usługi HDInsight | Węzeł główny: AmbariAuditLog, węzeł AuthLog ZooKeeper, węzeł procesu roboczego: AuthLog | Ta tabela zawiera rekordy z dzienników inspekcji i uwierzytelniania systemu Ambari. |
Klaster HBase
Poniższe nazwy tabel dotyczą różnych typów dzienników (źródeł) w tabelach HBase.
| Numer źródłowy | Nazwa tabeli | Typy dzienników | opis |
|---|---|---|---|
| 1. | HDInsightAmbariClusterAlerts | Brak innych typów dzienników | Ta tabela zawiera alerty klastra Ambari z każdego węzła w klastrze (z wyjątkiem węzłów brzegowych). Każdy alert jest rekordem w tej tabeli. |
| 2. | Metryki hdInsightAmbariSystem | Brak innych typów dzienników | Ta tabela zawiera metryki systemowe zebrane z systemu Ambari. Metryki pochodzą teraz z każdego węzła w klastrze (z wyjątkiem węzłów brzegowych) zamiast tylko dwóch węzłów głównych. Każda metryka jest teraz kolumną, a każda metryka jest zgłaszana raz na rekord. |
| 3. | HDInsightHadoopAndYarnLogs | Węzeł główny: MRJobSummary, Resource Manager, TimelineServer Worker node: NodeManager | Ta tabela zawiera wszystkie dzienniki wygenerowane na podstawie platform Hadoop i YARN. |
| 4. | Dzienniki zabezpieczeń usługi HDInsight | Węzeł główny: AmbariAuditLog, węzeł procesu roboczego AuthLog: węzeł AuthLog ZooKeeper: AuthLog | Ta tabela zawiera rekordy z dzienników inspekcji i uwierzytelniania systemu Ambari. |
| 5. | Dzienniki bazy danych HDInsightH | Węzeł główny: HDFSGarbageCollectorLog, węzeł roboczy HDFSNameNodeLog: PhoenixServerLog, HBaseRegionServerLog, HBaseRestServerKeeper node: HBaseMasterLog | Ta tabela zawiera dzienniki z bazy danych HBase i powiązanych składników: Phoenix i HDFS. |
| 6. | HDInsightHBaseMetrics | Brak typów dzienników | Ta tabela zawiera metryki JMX z bazy danych HBase. Zawiera wszystkie te same metryki JMX z tabel wymienionych w kolumnie Stary schemat. W przeciwieństwie do starych tabel każdy wiersz zawiera jedną metrykę. |
| 7. | Metryki HDInsightHadoopAndyarn | Brak typów dzienników | Ta tabela zawiera metryki JMX z platform Hadoop i YARN. Zawiera wszystkie te same metryki JMX co stare tabele dzienników niestandardowych oraz więcej metryk, które uznaliśmy za ważne. Dodaliśmy metryki Serwer osi czasu, Menedżer węzłów i Serwer historii zadań. Zawiera jedną metryki na rekord. |
Klaster Hadoop
Poniższe nazwy tabel dotyczą różnych typów dzienników (źródeł) w tabelach usługi Hadoop.
| Numer źródłowy | Nazwa tabeli | Typy dzienników | opis |
|---|---|---|---|
| 1. | HDInsightAmbariClusterAlerts | Brak typów dzienników | Ta tabela zawiera alerty klastra Ambari z każdego węzła w klastrze (z wyjątkiem węzłów brzegowych). Każdy alert jest rekordem w tej tabeli. |
| 2. | Metryki hdInsightAmbariSystem | Brak typów dzienników | Ta tabela zawiera metryki systemowe zebrane z systemu Ambari. Metryki pochodzą teraz z każdego węzła w klastrze (z wyjątkiem węzłów brzegowych) zamiast tylko dwóch węzłów głównych. Każda metryka jest teraz kolumną, a każda metryka jest zgłaszana raz na rekord. |
| 3. | HDInsightHadoopAndYarnLogs | Węzeł główny: MRJobSummary, Resource Manager, TimelineServer Worker node: NodeManager | Ta tabela zawiera wszystkie dzienniki wygenerowane na podstawie platform Hadoop i YARN. |
| 4. | HDInsightHadoopAndYarnMetrics | Brak typów dzienników | Ta tabela zawiera metryki JMX z platform Hadoop i YARN. Zawiera wszystkie te same metryki JMX co stare tabele dzienników niestandardowych oraz więcej metryk, które uznaliśmy za ważne. Dodaliśmy metryki Serwer osi czasu, Menedżer węzłów i Serwer historii zadań. Zawiera jedną metryki na rekord. |
| 5. | HDInsightHiveAndLLAPLogs | Węzeł główny: HiveMetastoreLog, HiveServer2Log, WebHcatLog | Ta tabela zawiera dzienniki wygenerowane na podstawie technologii Hive, LLAP i ich powiązanych składników: WebHCat i Zeppelin. |
| 6. | Metryki hive i LLAP w usłudze HDInsight | Brak typów dzienników | Ta tabela zawiera metryki JMX z platform Hive i LLAP. Zawiera wszystkie te same metryki JMX co stare tabele dzienników niestandardowych. Zawiera jedną metryki na rekord. |
| 7. | Dzienniki zabezpieczeń usługi HDInsight | Węzeł główny: AmbariAuditLog, węzeł AuthLog ZooKeeper: AuthLog | Ta tabela zawiera rekordy z dzienników inspekcji i uwierzytelniania systemu Ambari. |
Składnia parametrów
Parametry definiują typ klastra, nazwy tabel, nazwy źródłowe i akcję.
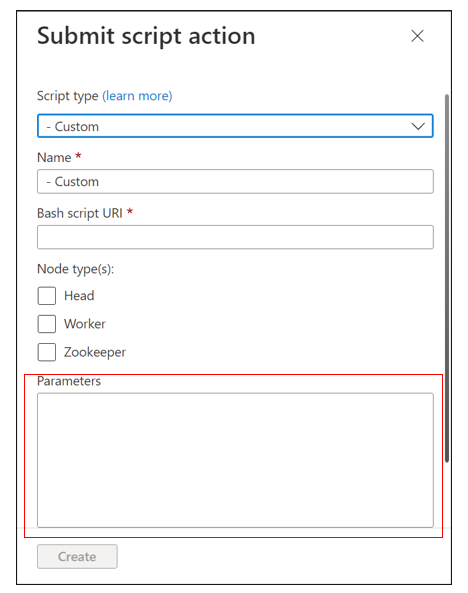
Parametr zawiera trzy części:
- Typ klastra
- Tabele i typy dzienników
- Akcja (
--disablelub--enable)
Składnia dla wielu tabel
Jeśli masz wiele tabel, są one oddzielone przecinkami. Przykład:
spark HDInsightSecurityLogs, HDInsightAmbariSystemMetrics --disable
hbase HDInsightSecurityLogs, HDInsightAmbariSystemMetrics --enable
Składnia dla wielu typów źródłowych lub typów dzienników
Jeśli masz wiele typów źródłowych lub typów dzienników, są one oddzielone spacją.
Aby wyłączyć źródło, zapisz nazwę tabeli zawierającą typy dzienników, a następnie dwukropek, a następnie nazwę rzeczywistego typu dziennika:
TableName : LogTypeName
Załóżmy na przykład, że spark HDInsightSecurityLogs jest to tabela zawierająca dwa typy dzienników: AmbariAuditLog i AuthLog. Aby wyłączyć oba typy dzienników, prawidłową składnią będzie:
spark HDInsightSecurityLogs: AmbariAuditLog AuthLog --disable
Składnia dla wielu tabel i typów źródłowych
Jeśli musisz wyłączyć dwie tabele i dwa typy źródłowe, użyj następującej składni:
- Spark:
InteractiveHiveMetastoreLogtyp dziennika wHDInsightHiveAndLLAPLogstabeli - Hbase:
InteractiveHiveHSILogtyp dziennika wHDInsightHiveAndLLAPLogstabeli - Hadoop:
HDInsightHiveAndLLAPMetricstabela - Hadoop:
HDInsightHiveTezAppStatstabela
Rozdziel tabele przecinkami. Oznacz źródła przy użyciu dwukropka po nazwie tabeli, w której się znajdują.
Prawidłowa składnia parametrów dla tych przypadków to:
interactivehive HDInsightHiveAndLLAPLogs: InteractiveHiveMetastoreLog, HDInsightHiveAndLLAPMetrics, HDInsightHiveTezAppStats, HDInsightHiveAndLLAPLogs: InteractiveHiveHSILog --enable