Samouczek: trenowanie modelu w usłudze Azure Machine Edukacja
DOTYCZY: Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Dowiedz się, jak analityk danych używa usługi Azure Machine Edukacja do trenowania modelu. W tym przykładzie użyjemy skojarzonego zestawu danych karty kredytowej, aby pokazać, jak można użyć usługi Azure Machine Edukacja w celu uzyskania problemu z klasyfikacją. Celem jest przewidywanie, czy klient ma duże prawdopodobieństwo niewykonania płatności kartą kredytową.
Skrypt szkoleniowy obsługuje przygotowywanie danych, a następnie trenuje i rejestruje model. W tym samouczku przedstawiono kroki przesyłania zadania szkoleniowego opartego na chmurze (zadania polecenia). Jeśli chcesz dowiedzieć się więcej na temat ładowania danych na platformę Azure, zobacz Samouczek: przekazywanie, uzyskiwanie dostępu do danych i eksplorowanie ich w usłudze Azure Machine Edukacja. Kroki to:
- Uzyskiwanie dojścia do obszaru roboczego usługi Azure Machine Edukacja
- Tworzenie zasobu obliczeniowego i środowiska zadań
- Tworzenie skryptu szkoleniowego
- Utwórz i uruchom zadanie polecenia, aby uruchomić skrypt szkoleniowy na zasobie obliczeniowym skonfigurowanym przy użyciu odpowiedniego środowiska zadań i źródła danych
- Wyświetlanie danych wyjściowych skryptu szkoleniowego
- Wdrażanie nowo wytrenowanego modelu jako punktu końcowego
- Wywoływanie punktu końcowego usługi Azure Machine Edukacja w celu wnioskowania
W tym filmie wideo pokazano, jak rozpocząć pracę w usłudze Azure Machine Edukacja Studio, aby można było wykonać kroki opisane w samouczku. W filmie wideo pokazano, jak utworzyć notes, utworzyć wystąpienie obliczeniowe i sklonować notes. Kroki zostały również opisane w poniższych sekcjach.
Wymagania wstępne
-
Aby korzystać z usługi Azure Machine Edukacja, najpierw potrzebujesz obszaru roboczego. Jeśli go nie masz, ukończ tworzenie zasobów, aby rozpocząć tworzenie obszaru roboczego i dowiedz się więcej na temat korzystania z niego.
-
Zaloguj się do programu Studio i wybierz swój obszar roboczy, jeśli jeszcze nie jest otwarty.
-
Otwórz lub utwórz notes w obszarze roboczym:
- Utwórz nowy notes, jeśli chcesz skopiować/wkleić kod do komórek.
- Możesz też otworzyć plik tutorials/get-started-notebooks/train-model.ipynb z sekcji Przykłady programu Studio. Następnie wybierz pozycję Klonuj, aby dodać notes do plików. (Zobacz, gdzie znaleźć przykłady).
Ustawianie jądra
Na górnym pasku powyżej otwartego notesu utwórz wystąpienie obliczeniowe, jeśli jeszcze go nie masz.

Jeśli wystąpienie obliczeniowe zostanie zatrzymane, wybierz pozycję Uruchom środowisko obliczeniowe i poczekaj na jego uruchomienie.

Upewnij się, że jądro znajdujące się w prawym górnym rogu ma wartość
Python 3.10 - SDK v2. Jeśli nie, użyj listy rozwijanej, aby wybrać to jądro.
Jeśli zostanie wyświetlony baner z informacją o konieczności uwierzytelnienia, wybierz pozycję Uwierzytelnij.



Ważne
W pozostałej części tego samouczka znajdują się komórki notesu samouczka. Skopiuj je/wklej do nowego notesu lub przełącz się teraz do notesu, jeśli go sklonujesz.
Używanie zadania polecenia do trenowania modelu w usłudze Azure Machine Edukacja
Aby wytrenować model, musisz przesłać zadanie. Typ zadania, które zostanie przesłany w tym samouczku, to zadanie polecenia. Usługa Azure Machine Edukacja oferuje kilka różnych typów zadań do trenowania modeli. Użytkownicy mogą wybrać swoją metodę trenowania na podstawie złożoności modelu, rozmiaru danych i wymagań dotyczących szybkości trenowania. Z tego samouczka dowiesz się, jak przesłać zadanie polecenia w celu uruchomienia skryptu szkoleniowego.
Zadanie polecenia to funkcja, która umożliwia przesłanie niestandardowego skryptu szkoleniowego w celu wytrenowania modelu. Można to również zdefiniować jako niestandardowe zadanie trenowania. Zadanie polecenia w usłudze Azure Machine Edukacja to typ zadania, które uruchamia skrypt lub polecenie w określonym środowisku. Za pomocą zadań poleceń można trenować modele, przetwarzać dane lub dowolny inny niestandardowy kod, który chcesz wykonać w chmurze.
W tym samouczku skoncentrujemy się na użyciu zadania polecenia w celu utworzenia niestandardowego zadania szkoleniowego, którego użyjemy do wytrenowania modelu. W przypadku dowolnego niestandardowego zadania trenowania wymagane są poniższe elementy:
- Środowisko usługi
- dane
- zadanie polecenia
- skrypt trenowania
W tym samouczku udostępnimy wszystkie te elementy w naszym przykładzie: utworzenie klasyfikatora w celu przewidywania klientów, którzy mają duże prawdopodobieństwo domyślnej płatności kartą kredytową.
Tworzenie dojścia do obszaru roboczego
Zanim przejdziemy do kodu, musisz odwołać się do obszaru roboczego. Utworzysz ml_client dojście do obszaru roboczego. Następnie użyjesz narzędzia ml_client do zarządzania zasobami i zadaniami.
W następnej komórce wprowadź identyfikator subskrypcji, nazwę grupy zasobów i nazwę obszaru roboczego. Aby znaleźć następujące wartości:
- W prawym górnym rogu paska narzędzi Azure Machine Edukacja Studio wybierz nazwę obszaru roboczego.
- Skopiuj wartość obszaru roboczego, grupy zasobów i identyfikatora subskrypcji do kodu.
- Musisz skopiować jedną wartość, zamknąć obszar i wkleić, a następnie wrócić do następnego.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Uwaga
Utworzenie klasy MLClient nie spowoduje nawiązania połączenia z obszarem roboczym. Inicjowanie klienta jest leniwe, będzie czekać po raz pierwszy, aby wykonać wywołanie (nastąpi to w następnej komórce kodu).
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Tworzenie środowiska zadań
Aby uruchomić zadanie usługi Azure Machine Edukacja w zasobie obliczeniowym, potrzebne jest środowisko. Środowisko zawiera listę środowiska uruchomieniowego oprogramowania i bibliotek, które mają być zainstalowane na obliczeniach, w których będziesz trenować. Jest on podobny do środowiska python na komputerze lokalnym.
Usługa Azure Machine Edukacja udostępnia wiele wyselekcjonowanych lub gotowych środowisk, które są przydatne w przypadku typowych scenariuszy trenowania i wnioskowania.
W tym przykładzie utworzysz niestandardowe środowisko conda dla zadań przy użyciu pliku yaml conda.
Najpierw utwórz katalog do przechowywania pliku.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Poniższa komórka używa magii IPython do zapisania pliku conda w właśnie utworzonym katalogu.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=1.0.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- mlflow==2.8.0
- mlflow-skinny==2.8.0
- azureml-mlflow==1.51.0
- psutil>=5.8,<5.9
- tqdm>=4.59,<4.60
- ipykernel~=6.0
- matplotlib
Specyfikacja zawiera kilka zwykłych pakietów, które będą używane w zadaniu (numpy, pip).
Odwołaj się do tego pliku yaml , aby utworzyć i zarejestrować to środowisko niestandardowe w obszarze roboczym:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
custom_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults job",
tags={"scikit-learn": "1.0.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
custom_job_env = ml_client.environments.create_or_update(custom_job_env)
print(
f"Environment with name {custom_job_env.name} is registered to workspace, the environment version is {custom_job_env.version}"
)
Konfigurowanie zadania trenowania przy użyciu funkcji polecenia
Utworzysz zadanie polecenia usługi Azure Machine Edukacja w celu wytrenowania modelu na potrzeby przewidywania domyślnego środków. Zadanie polecenia uruchamia skrypt trenowania w określonym środowisku w określonym zasobie obliczeniowym. Środowisko i klaster obliczeniowy zostały już utworzone. Następnie utworzysz skrypt trenowania. W naszym konkretnym przypadku trenujemy nasz zestaw danych w celu utworzenia klasyfikatora przy użyciu GradientBoostingClassifier modelu.
Skrypt szkoleniowy obsługuje przygotowywanie, trenowanie i rejestrowanie wytrenowanego modelu. Metoda train_test_split obsługuje dzielenie zestawu danych na dane testowe i szkoleniowe. W tym samouczku utworzysz skrypt szkoleniowy języka Python.
Zadania poleceń można uruchamiać z poziomu interfejsu wiersza polecenia, zestawu SDK języka Python lub interfejsu studio. W tym samouczku użyjesz zestawu Azure Machine Edukacja Python SDK w wersji 2, aby utworzyć i uruchomić zadanie polecenia.
Tworzenie skryptu szkoleniowego
Zacznijmy od utworzenia skryptu szkoleniowego — pliku main.py python.
Najpierw utwórz folder źródłowy skryptu:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Ten skrypt obsługuje wstępne przetwarzanie danych, dzieląc je na dane testowe i szkolące. Następnie używa tych danych do trenowania modelu opartego na drzewie i zwracania modelu wyjściowego.
Usługa MLFlow służy do rejestrowania parametrów i metryk podczas naszego zadania. Pakiet MLFlow umożliwia śledzenie metryk i wyników dla każdego modelu trenowania platformy Azure. Najpierw użyjemy platformy MLFlow, aby uzyskać najlepszy model dla naszych danych, a następnie wyświetlimy metryki modelu w programie Azure Studio.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
#Split train and test datasets
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
W tym skrypsie po wytrenowanym modelu plik modelu jest zapisywany i rejestrowany w obszarze roboczym. Zarejestrowanie modelu umożliwia przechowywanie i przechowywanie wersji modeli w chmurze platformy Azure w obszarze roboczym. Po zarejestrowaniu modelu można znaleźć wszystkie inne zarejestrowane modele w jednym miejscu w programie Azure Studio nazywanym rejestrem modeli. Rejestr modeli ułatwia organizowanie i śledzenie wytrenowanych modeli.
Konfigurowanie polecenia
Teraz, gdy masz skrypt, który może wykonać zadanie klasyfikacji, użyj polecenia ogólnego przeznaczenia, które może uruchamiać akcje wiersza polecenia. Ta akcja wiersza polecenia może bezpośrednio wywoływać polecenia systemowe lub uruchamiając skrypt.
W tym miejscu utwórz zmienne wejściowe, aby określić dane wejściowe, współczynnik podziału, szybkość nauki i nazwę zarejestrowanego modelu. Skrypt polecenia będzie:
- Użyj utworzonego wcześniej środowiska — możesz użyć
@latestnotacji, aby wskazać najnowszą wersję środowiska po uruchomieniu polecenia. - Skonfiguruj samą akcję wiersza polecenia —
python main.pyw tym przypadku. Dane wejściowe/wyjściowe są dostępne w poleceniu${{ ... }}za pośrednictwem notacji. - Ponieważ zasób obliczeniowy nie został określony, skrypt zostanie uruchomiony w klastrze obliczeniowym bezserwerowym, który jest tworzony automatycznie.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="aml-scikit-learn@latest",
display_name="credit_default_prediction",
)
Przesyłanie zadania
Nadszedł czas, aby przesłać zadanie do uruchomienia w usłudze Azure Machine Edukacja Studio. Tym razem użyjesz polecenia create_or_update w pliku ml_client. ml_clientjest klasą klienta, która umożliwia łączenie się z subskrypcją platformy Azure przy użyciu języka Python i interakcję z usługami azure Machine Edukacja. ml_client umożliwia przesyłanie zadań przy użyciu języka Python.
ml_client.create_or_update(job)
Wyświetlanie danych wyjściowych zadania i oczekiwanie na ukończenie zadania
Wyświetl zadanie w usłudze Azure Machine Edukacja Studio, wybierając link w danych wyjściowych poprzedniej komórki. Dane wyjściowe tego zadania będą wyglądać następująco w usłudze Azure Machine Edukacja Studio. Zapoznaj się z kartami, aby uzyskać różne szczegóły, takie jak metryki, dane wyjściowe itp. Po zakończeniu zadanie zarejestruje model w obszarze roboczym w wyniku trenowania.
Ważne
Przed powrotem do tego notesu poczekaj, aż stan zadania zostanie ukończony. Uruchomienie zadania potrwa od 2 do 3 minut. Może to potrwać dłużej (do 10 minut), jeśli klaster obliczeniowy został przeskalowany w dół do zera węzłów, a środowisko niestandardowe nadal jest kompilowane.
Po uruchomieniu komórki dane wyjściowe notesu zawierają link do strony szczegółów zadania w programie Azure Studio. Alternatywnie możesz również wybrać pozycję Zadania w menu nawigacji po lewej stronie. Zadanie to grupowanie wielu przebiegów z określonego skryptu lub fragmentu kodu. Informacje dotyczące przebiegu są przechowywane w ramach tego zadania. Strona szczegółów zawiera omówienie zadania, czas jego uruchomienia, czas jego utworzenia itp. Strona zawiera również karty do innych informacji o zadaniu, takich jak metryki, dane wyjściowe i dzienniki oraz kod. Poniżej przedstawiono karty dostępne na stronie szczegółów zadania:
- Omówienie: Sekcja przeglądu zawiera podstawowe informacje o zadaniu, w tym jego stan, czas rozpoczęcia i zakończenia oraz typ zadania, które zostało uruchomione
- Dane wejściowe: sekcja danych wejściowych zawiera listę danych i kodu, które zostały użyte jako dane wejściowe zadania. Ta sekcja może obejmować zestawy danych, skrypty, konfiguracje środowiska i inne zasoby, które były używane podczas trenowania.
- Dane wyjściowe i dzienniki: karta Dane wyjściowe i dzienniki zawiera dzienniki wygenerowane podczas uruchamiania zadania. Ta karta pomaga w rozwiązywaniu problemów, jeśli coś pójdzie nie tak z tworzeniem skryptu trenowania lub modelu.
- Metryki: karta metryki przedstawia kluczowe metryki wydajności z modelu, takie jak wynik trenowania, wynik f1 i wynik precyzji.
Czyszczenie zasobów
Jeśli planujesz kontynuować korzystanie z innych samouczków, przejdź do sekcji Następne kroki.
Zatrzymywanie wystąpienia obliczeniowego
Jeśli nie zamierzasz go teraz używać, zatrzymaj wystąpienie obliczeniowe:
- W programie Studio w obszarze nawigacji po lewej stronie wybierz pozycję Obliczenia.
- Na pierwszych kartach wybierz pozycję Wystąpienia obliczeniowe
- Wybierz wystąpienie obliczeniowe na liście.
- Na górnym pasku narzędzi wybierz pozycję Zatrzymaj.
Usuwanie wszystkich zasobów
Ważne
Utworzone zasoby mogą być używane jako wymagania wstępne w innych samouczkach usługi Azure Machine Edukacja i artykułach z instrukcjami.
Jeśli nie planujesz korzystać z żadnych utworzonych zasobów, usuń je, aby nie ponosić żadnych opłat:
W witrynie Azure Portal na końcu z lewej strony wybierz pozycję Grupy zasobów.
Z listy wybierz utworzoną grupę zasobów.
Wybierz pozycję Usuń grupę zasobów.
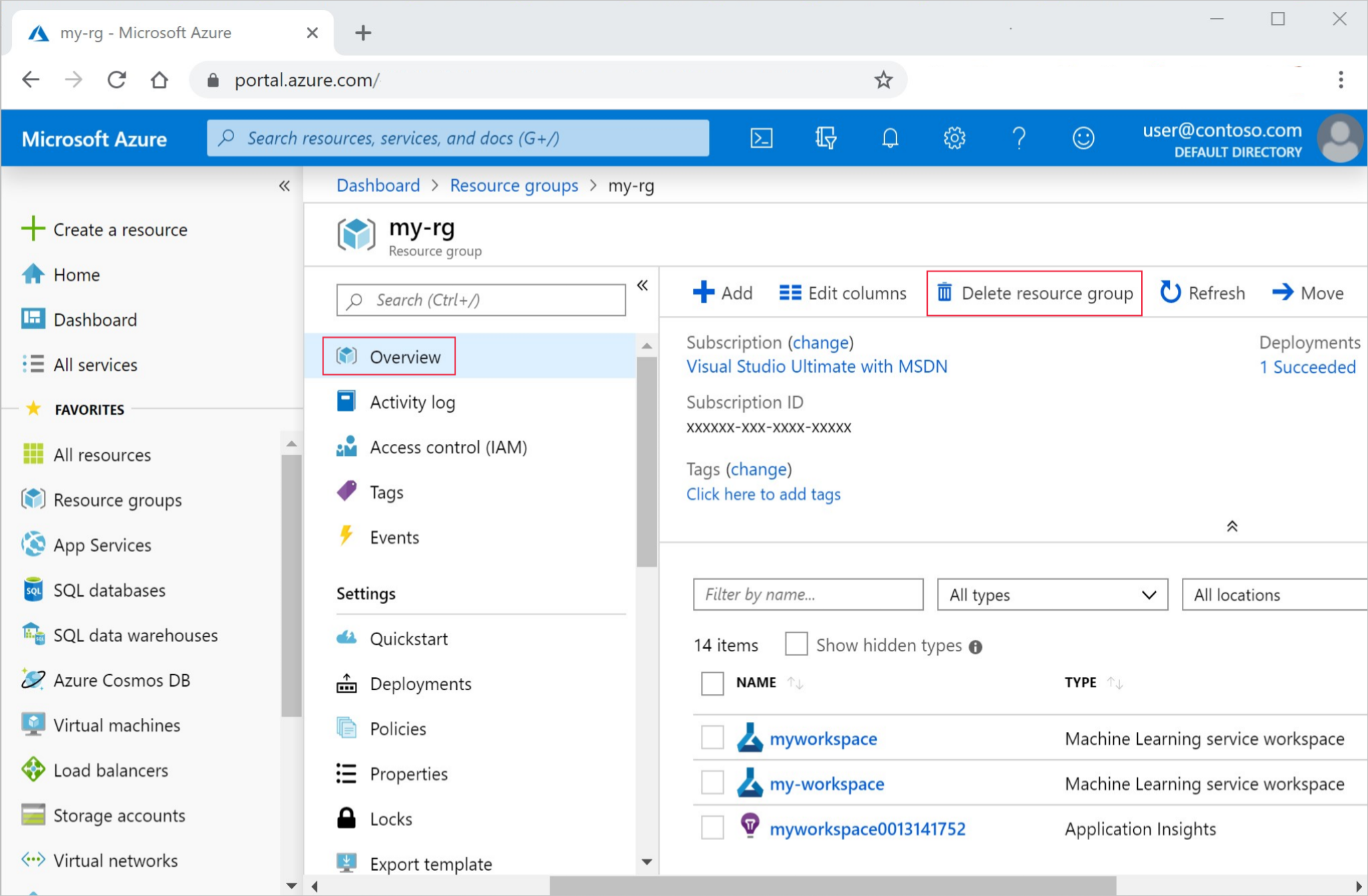
Wpisz nazwę grupy zasobów. Następnie wybierz Usuń.
Następne kroki
Dowiedz się więcej o wdrażaniu modelu
W tym samouczku użyto pliku danych online. Aby dowiedzieć się więcej na temat innych sposobów uzyskiwania dostępu do danych, zobacz Samouczek: przekazywanie, uzyskiwanie dostępu do danych i eksplorowanie ich w usłudze Azure Machine Edukacja.
Jeśli chcesz dowiedzieć się więcej o różnych sposobach trenowania modeli w usłudze Azure Machine Edukacja, zobacz Co to jest zautomatyzowane uczenie maszynowe (AutoML)?. Zautomatyzowane uczenie maszynowe to narzędzie uzupełniające, które pozwala skrócić ilość czasu, przez który analityk danych szuka modelu, który najlepiej współpracuje z danymi.
Jeśli chcesz uzyskać więcej przykładów podobnych do tego samouczka, zobacz sekcję Przykłady w programie Studio. Te same przykłady są dostępne na naszej stronie przykładów usługi GitHub. Przykłady obejmują kompletne notesy języka Python, które można uruchamiać kod i nauczyć się trenować model. Istniejące skrypty można modyfikować i uruchamiać z przykładów, w tym scenariuszy klasyfikacji, przetwarzania języka naturalnego i wykrywania anomalii.