Metryki dla usługi Application Gateway
Usługa Application Gateway publikuje punkty danych w usłudze Azure Monitor w celu uzyskania wydajności usługi Application Gateway i wystąpień zaplecza. Te punkty danych są nazywane metrykami i są wartościami liczbowymi w uporządkowanym zestawie danych szeregów czasowych. Metryki opisują jakiś aspekt bramy aplikacji w określonym czasie. Jeśli istnieją żądania przepływające przez usługę Application Gateway, mierzy i wysyła metryki w 60-sekundowych odstępach czasu. Jeśli nie ma żadnych żądań przepływających przez usługę Application Gateway lub brak danych dla metryki, metryka nie jest zgłaszana. Aby uzyskać więcej informacji, zobacz Metryki usługi Azure Monitor.
Metryki obsługiwane przez jednostkę SKU usługi Application Gateway w wersji 2
Uwaga
Informacje dotyczące serwera proxy TLS/TCP można znaleźć w dokumentacji danych.
Metryki chronometrażu
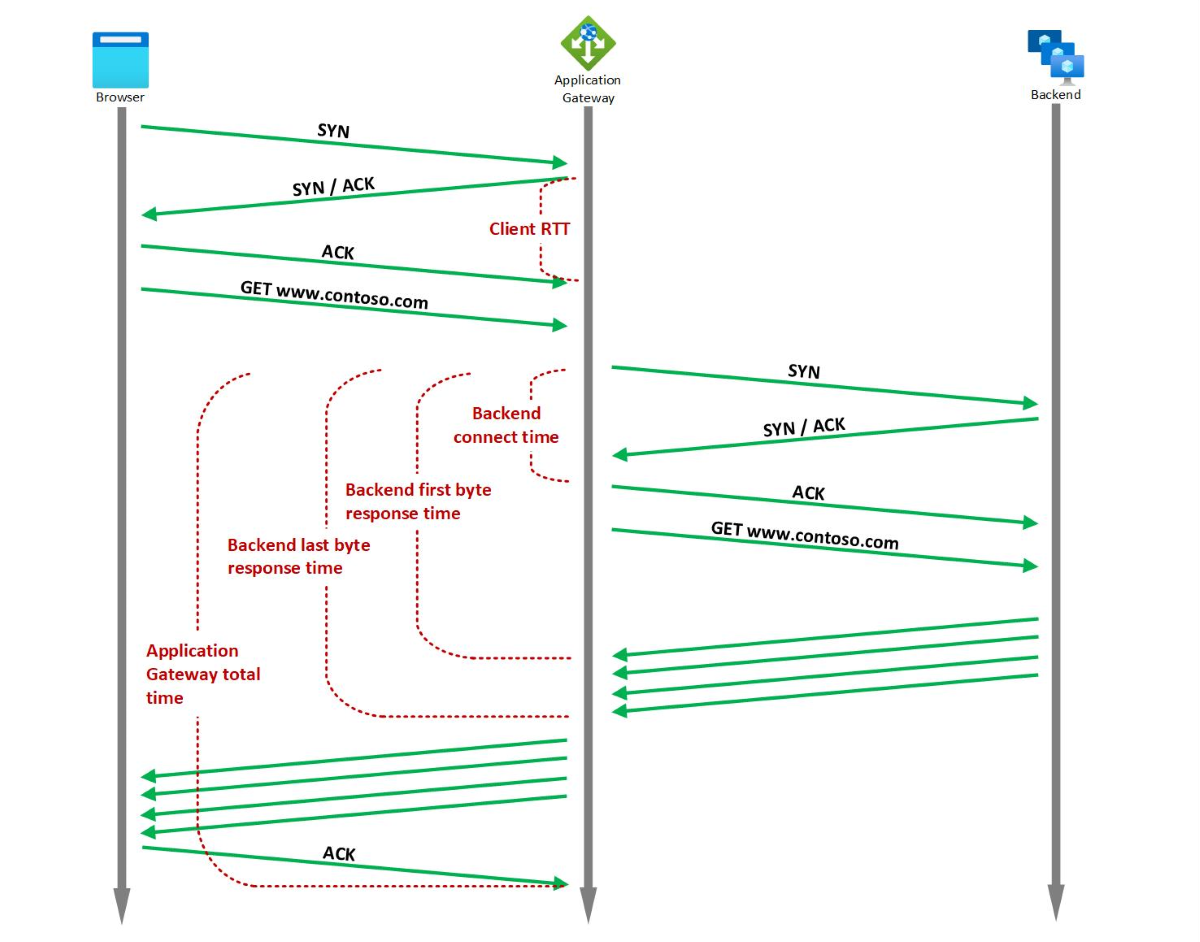
Usługa Application Gateway udostępnia kilka wbudowanych metryk chronometrażu związanych z żądaniem i odpowiedzią, które są mierzone w milisekundach.
Uwaga
Jeśli w usłudze Application Gateway istnieje więcej niż jeden odbiornik, zawsze filtruj według wymiaru odbiornika , porównując różne metryki opóźnienia w celu uzyskania znaczącego wnioskowania.
Czas połączenia zaplecza
Typ agregacji:Średnia/Maksymalna
Czas spędzony na nawiązaniu połączenia z aplikacją zaplecza.
Obejmuje on opóźnienie sieci, a także czas potrzebny na nawiązanie nowych połączeń przez stos TCP serwera zaplecza. W przypadku protokołu TLS obejmuje również czas spędzony na uzgadnianiu.
Czas odpowiedzi pierwszego bajtu zaplecza
Typ agregacji:Średnia/Maksymalna
Przedział czasu między rozpoczęciem nawiązywania połączenia z serwerem zaplecza i odbieraniem pierwszego bajtu nagłówka odpowiedzi.
Jest to przybliżona suma czasu połączenia zaplecza, czas potrzebny na dotarcie do zaplecza z usługi Application Gateway, czas potrzebny aplikacji zaplecza na odpowiedź (czas potrzebny na wygenerowanie zawartości, potencjalnie pobranie zapytań bazy danych) oraz czas potrzebny na dotarcie do usługi Application Gateway z zaplecza.
Czas odpowiedzi ostatniego bajtu zaplecza
Typ agregacji:Średnia/Maksymalna
Przedział czasu między rozpoczęciem nawiązywania połączenia z serwerem zaplecza i odbieraniem ostatniego bajtu treści odpowiedzi.
Jest to w przybliżeniu suma czasu odebrania z zaplecza pierwszego bajtu odpowiedzi oraz czasu transferu danych (ta liczba może się znacząco różnić w zależności od rozmiaru żądanych obiektów oraz opóźnienia w sieci serwera).
Łączny czas bramy aplikacji
Typ agregacji:Średnia/Maksymalna
Ta metryka przechwytuje średni/maksymalny czas potrzebny na odebranie żądania, przetworzenie i wysłanie odpowiedzi.
Jest to interwał od momentu odebrania przez usługę Application Gateway pierwszego bajtu żądania HTTP do momentu wysłania ostatniego bajtu odpowiedzi do klienta. Obejmuje to czas przetwarzania wykonywany przez usługę Application Gateway, czas odpowiedzi ostatniego bajtu zaplecza oraz czas potrzebny usłudze Application Gateway na wysłanie całej odpowiedzi.
RTT klienta
Typ agregacji:Średnia/Maksymalna
Ta metryka przechwytuje średni/maksymalny czas rundy między klientami a usługą Application Gateway.
Te metryki mogą służyć do określenia, czy zaobserwowane spowolnienie jest spowodowane siecią klienta, wydajnością usługi Application Gateway, siecią zaplecza i nasyceniem stosu TCP serwera zaplecza, wydajnością aplikacji zaplecza lub dużym rozmiarem plików.
Jeśli na przykład występuje wzrost trendu czasu pierwszego bajtu odpowiedzi zaplecza, ale trend czasu połączenia zaplecza jest stabilny, można wywnioskować, że brama aplikacji do opóźnienia zaplecza i czas potrzebny na nawiązanie połączenia jest stabilny, a wzrost jest spowodowany wzrostem czasu odpowiedzi aplikacji zaplecza. Z drugiej strony, jeśli skok czasu odpowiedzi pierwszego bajtu zaplecza jest skojarzony z odpowiednim wzrostem czasu połączenia zaplecza, można go odróżnić od sieci między usługą Application Gateway a serwerem zaplecza lub stosem TCP serwera zaplecza.
Jeśli zauważysz wzrost czasu odpowiedzi ostatniego bajtu zaplecza, ale czas odpowiedzi pierwszego bajtu zaplecza jest stabilny, może to oznaczać, że skok jest spowodowany większym żądanym plikiem.
Podobnie, jeśli łączny czas bramy aplikacji ma gwałtowny wzrost, ale czas odpowiedzi ostatniego bajtu zaplecza jest stabilny, może to być oznaką wąskiego gardła wydajności w usłudze Application Gateway lub wąskim gardłem w sieci między klientem a usługą Application Gateway. Ponadto jeśli rTT klienta ma również odpowiedni skok, oznacza to, że spadek jest spowodowany siecią między klientem a usługą Application Gateway.
Metryki usługi Application Gateway
W przypadku usługi Application Gateway dostępne są następujące metryki:
Odebrane bajty
Liczba bajtów odebranych przez usługę Application Gateway od klientów. (Raportowany na podstawie tylko "rozmiaru zawartości" żądania. Nie uwzględnia obciążeń związanych z negocjacjami protokołu TLS, nagłówkami pakietów TCP/IP ani retransmisjami, dlatego nie reprezentuje całkowitego wykorzystania przepustowości).
Wysłane bajty
Liczba bajtów wysłanych przez usługę Application Gateway do klientów. (Raportowany na podstawie tylko "rozmiaru zawartości" odpowiedzi. Nie uwzględnia nagłówków pakietów TCP/IP ani retransmisji, dlatego nie reprezentuje całkowitego wykorzystania przepustowości).
Protokół TLS klienta
Liczba żądań TLS i innych niż TLS zainicjowanych przez klienta, który nawiązał połączenie z usługą Application Gateway. Aby wyświetlić dystrybucję protokołów TLS, przefiltruj według wymiaru protokołu TLS. Ta metryka zawiera żądania obsługiwane przez bramę, takie jak przekierowania.
Bieżące jednostki pojemności
Liczba jednostek wydajności użytych do równoważenia obciążenia ruchu. Istnieją trzy czynniki determinowane do jednostki pojemności — jednostka obliczeniowa, trwałe połączenia i przepływność. Każda jednostka pojemności składa się z co najwyżej 1 jednostki obliczeniowej lub 2500 połączeń trwałych lub przepływności 2,22 Mb/s.
Bieżące jednostki obliczeniowe
Liczba wykorzystanych pojemności procesora. Czynniki wpływające na jednostki obliczeniowe to liczba połączeń TLS/s, obliczenia ponownego zapisu adresu URL oraz przetwarzanie reguł zapory aplikacji internetowej.
Bieżące połączenia
Całkowita liczba równoczesnych połączeń aktywnych od klientów do usługi Application Gateway
Szacowane rozliczane jednostki pojemności
W przypadku jednostki SKU w wersji 2 model cen zależy od użycia. Jednostki wydajności mierzą koszt w zależności od użycia, naliczany dodatkowo wobec kosztu stałego. Szacowane rozliczane jednostki pojemności wskazują liczbę jednostek pojemności, przy użyciu których szacowane są rozliczenia. Oblicza się je na podstawie większej z dwóch wartości: liczby jednostek bieżącej wydajności (jednostek wydajności wymaganych do równoważenia obciążenia ruchu) oraz jednostek stałej wydajności rozliczanej (minimalnej aprowizowanej liczby jednostek wydajności).
Żądania, które zakończyły się niepowodzeniem
Liczba żądań obsługiwanych przez usługę Application Gateway z kodami błędów serwera 5xx. Obejmuje to kody 5xx generowane z usługi Application Gateway, a także kody 5xx generowane z zaplecza. Liczbę żądań można dodatkowo filtrować, aby wyświetlić liczbę dla każdej/określonej kombinacji ustawień puli zaplecza-http.
Stałe rozliczane jednostki pojemności
Minimalna aprowizowana liczba jednostek wydajności zgodnie z ustawieniem Minimalna liczba jednostek skalowania (jedno wystąpienie przekłada się na 10 jednostek wydajności) w konfiguracji usługi Application Gateway.
Nowe połączenia na sekundę
Średnia liczba nowych połączeń TCP na sekundę ustanowionych od klientów do usługi Application Gateway i z usługi Application Gateway do elementów członkowskich zaplecza.
Stan odpowiedzi
Stan odpowiedzi HTTP zwrócony przez usługę Application Gateway. Dystrybucja kodu stanu odpowiedzi może być dodatkowo podzielona na kategorie, aby pokazać odpowiedzi w kategoriach 2xx, 3xx, 4xx i 5xx.
Throughput (Przepływność)
Liczba bajtów na sekundę obsługiwana przez usługę Application Gateway. (Raportowany na podstawie tylko "rozmiaru zawartości". Nie uwzględnia obciążeń związanych z negocjacjami protokołu TLS, nagłówkami pakietów TCP/IP ani retransmisjami, dlatego nie reprezentuje całkowitego wykorzystania przepustowości).
Łączna liczba żądań
Liczba pomyślnych żądań obsługiwanych przez usługę Application Gateway przez obiekty docelowe puli zaplecza. Strony obsługiwane bezpośrednio przez bramę, takie jak przekierowania, nie są liczone i powinny znajdować się w metryce Protokołu TLS klienta. Metryka Całkowita liczba żądań może być dodatkowo filtrowana, aby wyświetlić liczbę dla każdej/określonej kombinacji ustawień puli zaplecza-http.
Metryki zaplecza
W przypadku usługi Application Gateway dostępne są następujące metryki:
Stan odpowiedzi zaplecza
Liczba kodów stanu odpowiedzi HTTP zwracanych przez zaplecza. Nie obejmuje to żadnych kodów odpowiedzi generowanych przez usługę Application Gateway. Dystrybucja kodu stanu odpowiedzi może być dodatkowo podzielona na kategorie, aby pokazać odpowiedzi w kategoriach 2xx, 3xx, 4xx i 5xx.
Liczba hostów w dobrej kondycji
Liczba zapleczy określonych w dobrej kondycji przez sondę kondycji. Można filtrować według puli zaplecza, aby wyświetlić liczbę hostów w dobrej kondycji w określonej puli zaplecza.
Liczba hostów w złej kondycji
Liczba zapleczy, które są określane jako w złej kondycji przez sondę kondycji. Można filtrować według puli zaplecza, aby wyświetlić liczbę hostów w złej kondycji w określonej puli zaplecza.
Żądania na minutę na hosta w dobrej kondycji
Średnia liczba żądań odebranych przez każdego elementu członkowskiego w dobrej kondycji w puli zaplecza w ciągu minuty. Należy określić pulę zaplecza przy użyciu wymiaru Http Ustawienia BackendPool.
Metryki zapory aplikacji internetowej
Aby uzyskać informacje na temat monitorowania zapory aplikacji internetowej, zobacz Metryki zapory aplikacji internetowej w wersji 2
Metryki obsługiwane przez jednostkę SKU usługi Application Gateway w wersji 1
Metryki usługi Application Gateway
W przypadku usługi Application Gateway dostępne są następujące metryki:
Wykorzystanie procesora CPU
Wyświetla użycie procesorów przydzielonych do usługi Application Gateway. W normalnych warunkach użycie procesora nie powinno regularnie przekraczać 90%, ponieważ może to powodować opóźnienie w witrynach internetowych hostowanych za bramą aplikacji i zakłócać środowisko klienta. Można pośrednio kontrolować lub poprawić użycie procesora, modyfikując konfigurację usługi Application Gateway w celu zwiększenia liczby wystąpień, przechodząc na większy rozmiar jednostki SKU lub stosując oba rozwiązania jednocześnie.
Bieżące połączenia
Liczba bieżących połączeń nawiązanych z usługą Application Gateway
Żądania, które zakończyły się niepowodzeniem
Liczba żądań zakończonych niepowodzeniem z powodu problemów z połączeniem. Ta liczba obejmuje żądania, które zakończyły się niepowodzeniem z powodu przekroczenia ustawienia HTTP "Przekroczenie limitu czasu żądania" i żądań, które zakończyły się niepowodzeniem z powodu problemów z połączeniem między usługą Application Gateway i zapleczem. Ta liczba nie obejmuje niepowodzeń z powodu braku dostępnego zaplecza w dobrej kondycji. Odpowiedzi 4xx i 5xx z zaplecza nie są również traktowane jako część tej metryki.
Stan odpowiedzi
Stan odpowiedzi HTTP zwrócony przez usługę Application Gateway. Dystrybucja kodu stanu odpowiedzi może być dodatkowo podzielona na kategorie, aby pokazać odpowiedzi w kategoriach 2xx, 3xx, 4xx i 5xx.
Throughput (Przepływność)
Liczba bajtów na sekundę obsługiwana przez usługę Application Gateway
Łączna liczba żądań
Liczba pomyślnych żądań obsługiwanych przez usługę Application Gateway. Liczbę żądań można dodatkowo filtrować, aby wyświetlić liczbę dla każdej/określonej kombinacji ustawień puli zaplecza-http.
Metryki zaplecza
W przypadku usługi Application Gateway dostępne są następujące metryki:
Liczba hostów w dobrej kondycji
Liczba zapleczy określonych w dobrej kondycji przez sondę kondycji. Można filtrować według puli zaplecza, aby wyświetlić liczbę hostów w dobrej kondycji w określonej puli zaplecza.
Liczba hostów w złej kondycji
Liczba zapleczy, które są określane jako w złej kondycji przez sondę kondycji. Można filtrować według puli zaplecza, aby wyświetlić liczbę hostów w złej kondycji w określonej puli zaplecza.
Metryki zapory aplikacji internetowej
Aby uzyskać informacje na temat monitorowania zapory aplikacji internetowej, zobacz Metryki zapory aplikacji internetowej w wersji 1
Wizualizacja metryk
Przejdź do bramy aplikacji w obszarze Monitorowanie wybierz pozycję Metryki. Aby wyświetlić dostępne wartości, wybierz listę rozwijaną METRYKA.
Na poniższej ilustracji przedstawiono przykład z trzema metrykami wyświetlanymi przez ostatnie 30 minut:

Aby wyświetlić bieżącą listę metryk, zobacz Obsługiwane metryki w usłudze Azure Monitor.
Reguły alertów dotyczące metryk
Reguły alertów można uruchomić na podstawie metryk dla zasobu. Na przykład alert może wywołać element webhook lub wysłać wiadomość e-mail do administratora, jeśli przepływność bramy aplikacji jest wyższa, niższa lub na poziomie progu dla określonego okresu.
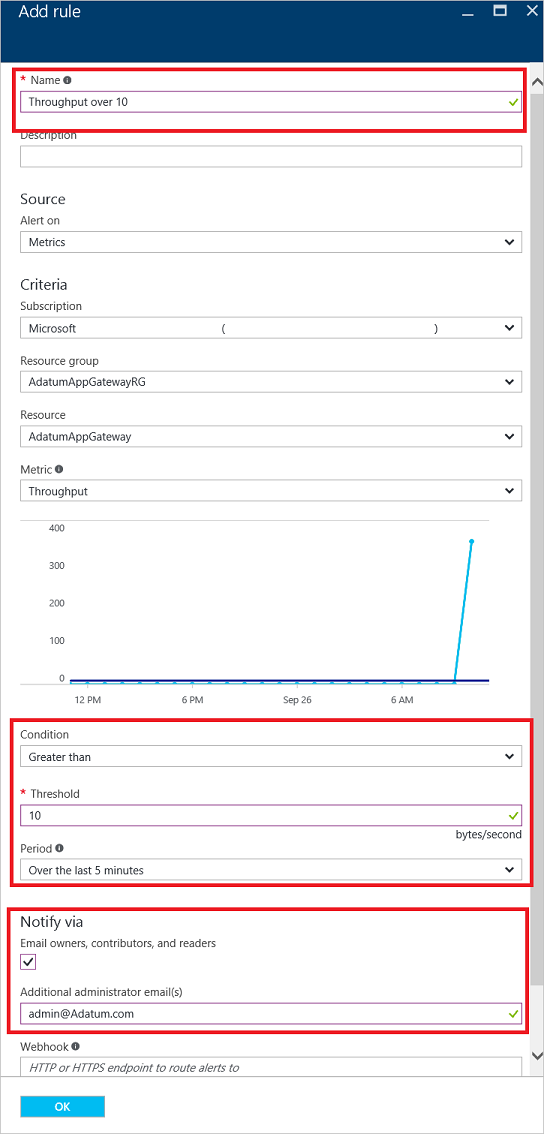
Poniższy przykład przeprowadzi Cię przez proces tworzenia reguły alertu, która wysyła wiadomość e-mail do administratora po naruszeniu progu przepływności:
wybierz pozycję Dodaj alert metryki, aby otworzyć stronę Dodawanie reguły . Możesz również uzyskać dostęp do tej strony ze strony metryk.

Na stronie Dodawanie reguły wypełnij sekcje nazwy, warunku i powiadamiania, a następnie wybierz przycisk OK.
W selektorze Warunek wybierz jedną z czterech wartości: Większe niż, Większe niż lub równe, Mniejsze niż lub Mniejsze lub równe.
W selektorze Okres wybierz okres od pięciu minut do sześciu godzin.
Jeśli wybierzesz pozycję Właściciele poczty e-mail, współautorzy i czytelnicy, wiadomość e-mail może być dynamiczna na podstawie użytkowników, którzy mają dostęp do tego zasobu. W przeciwnym razie możesz podać rozdzielaną przecinkami listę użytkowników w polu Dodatkowe adresy e-mail administratora.
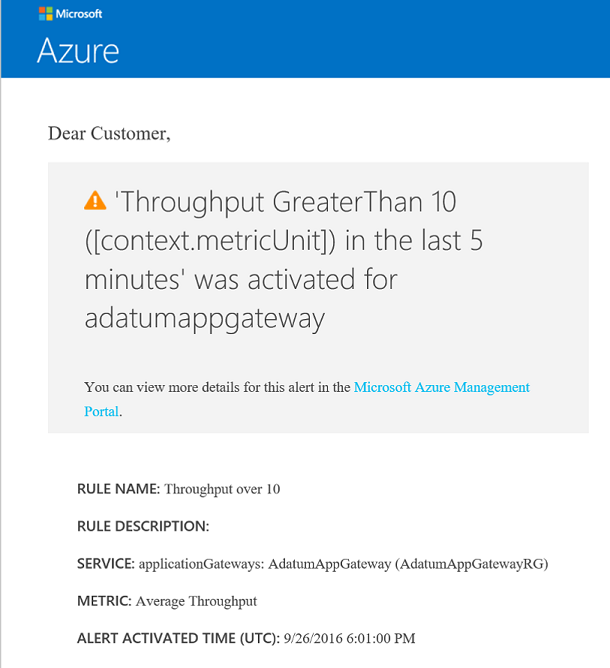
Jeśli próg zostanie naruszony, zostanie zwrócona wiadomość e-mail podobna do tej na poniższej ilustracji:
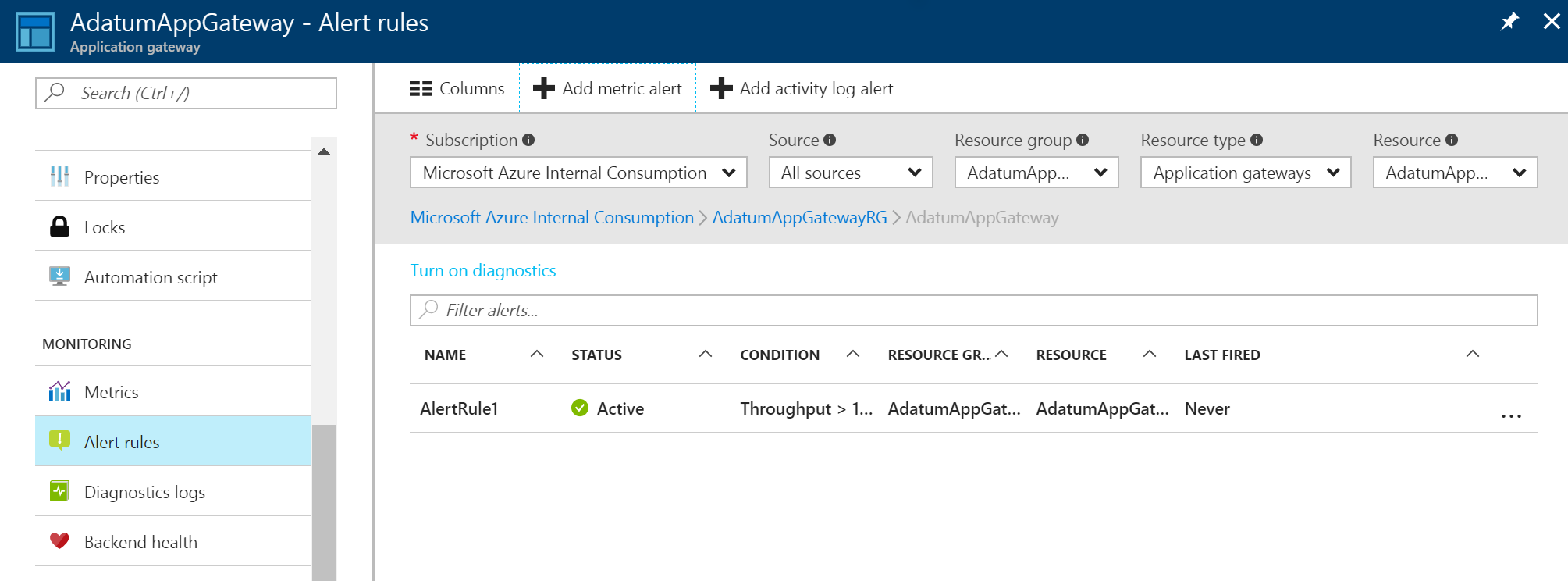
Po utworzeniu alertu dotyczącego metryk zostanie wyświetlona lista alertów. Zawiera omówienie wszystkich reguł alertów.
Aby dowiedzieć się więcej na temat powiadomień o alertach, zobacz Odbieranie powiadomień o alertach.
Aby dowiedzieć się więcej o elementach webhook i sposobie ich używania z alertami, odwiedź stronę Konfigurowanie elementu webhook w alercie metryk platformy Azure.
Następne kroki
- Wizualizowanie dzienników liczników i zdarzeń przy użyciu dzienników usługi Azure Monitor.
- Wizualizowanie dziennika aktywności platformy Azure za pomocą wpisu w blogu usługi Power BI .
- Wyświetlanie i analizowanie dzienników aktywności platformy Azure w usłudze Power BI i więcej wpisu w blogu.