Modele niestandardowe: dokładność i współczynniki ufności
Ta zawartość dotyczy:![]() v4.0 (wersja zapoznawcza)
v4.0 (wersja zapoznawcza)![]() v3.1 (GA)v3.0 (GA)
v3.1 (GA)v3.0 (GA)![]()
![]() v2.1 (GA)
v2.1 (GA)
Uwaga
- Niestandardowe modele neuronowe nie zapewniają wyników dokładności podczas trenowania.
- Wyniki ufności dla tabel, wierszy tabeli i komórek tabeli są dostępne od wersji interfejsu API 2024-02-29-preview dla modeli niestandardowych.
Niestandardowe modele szablonów generują szacowany wynik dokładności podczas trenowania. Dokumenty analizowane za pomocą modelu niestandardowego dają wskaźnik ufności dla wyodrębnianych pól. W tym artykule dowiesz się, jak interpretować dokładność i wyniki ufności oraz najlepsze rozwiązania dotyczące używania tych wyników w celu zwiększenia dokładności i wyników ufności.
Wyniki dokładności
Dane wyjściowe niestandardowej build operacji modelu (w wersji 3.0) lub train (wersja 2.1) obejmują szacowany wynik dokładności. Ten wynik reprezentuje zdolność modelu do dokładnego przewidywania wartości oznaczonej etykietą w podobnym dokumencie.
Zakres wartości dokładności to wartość procentowa z zakresu od 0% (niska) do 100% (wysoka). Szacowana dokładność jest obliczana przez uruchomienie kilku różnych kombinacji danych treningowych w celu przewidywania wartości oznaczonych etykietami.
Model niestandardowy wytrenowany w usłudze Document Intelligence Studio
(faktura)
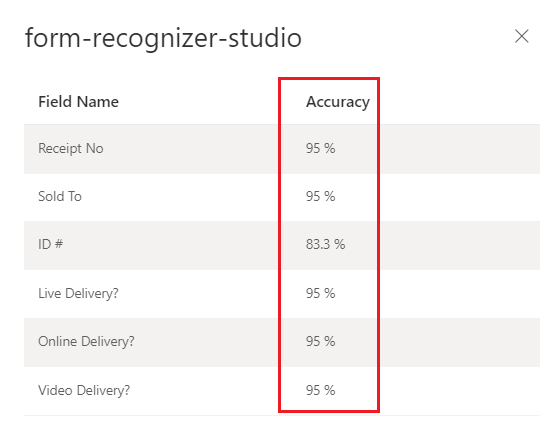
Współczynniki ufności
Uwaga
- Wyniki ufności tabel, wierszy i komórek są teraz dołączone do wersji interfejsu API 2024-02-29-preview.
- Wyniki ufności dla komórek tabeli z modeli niestandardowych są dodawane do interfejsu API, począwszy od interfejsu API 2024-02-29-preview.
Wyniki analizy dokumentów zwracają szacowaną pewność dla przewidywanych słów, par klucz-wartość, znaczniki wyboru, regiony i podpisy. Obecnie nie wszystkie pola dokumentu zwracają współczynnik ufności.
Ufność pola wskazuje szacowane prawdopodobieństwo z zakresu od 0 do 1, że przewidywanie jest poprawne. Na przykład wartość ufności 0,95 (95%) wskazuje, że przewidywanie jest prawdopodobnie poprawne 19 na 20 razy. W przypadku scenariuszy, w których dokładność jest krytyczna, można użyć do określenia, czy automatycznie zaakceptować przewidywanie, czy flagować ją do przeglądu przez człowieka.
Model faktury wstępnie utworzonej faktury w programie Document Intelligence Studio
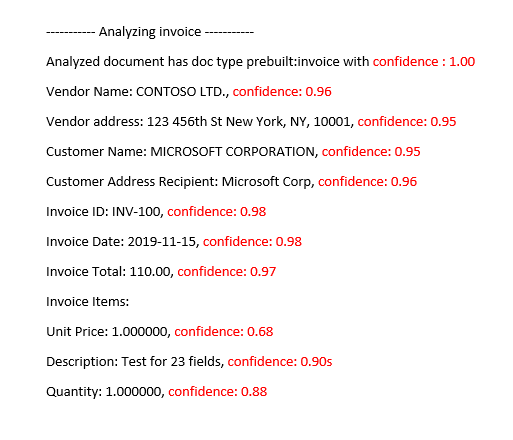
Interpretowanie dokładności i współczynników ufności dla modeli niestandardowych
Podczas interpretowania wyniku ufności z modelu niestandardowego należy wziąć pod uwagę wszystkie wyniki ufności zwrócone z modelu. Zacznijmy od listy wszystkich wyników ufności.
- Współczynnik ufności typu dokumentu: pewność typu dokumentu jest wskaźnikiem ściśle analizowanego dokumentu przypominającego dokumenty w zestawie danych trenowania. Gdy pewność typu dokumentu jest niska, wskazuje na zmiany szablonu lub strukturalne w analizowanym dokumencie. Aby poprawić pewność typu dokumentu, oznacz dokument za pomocą tej konkretnej odmiany i dodaj go do zestawu danych szkoleniowych. Po ponownym trenowaniu modelu powinno być lepiej wyposażone w obsługę tej klasy odmian.
- Pewność poziomu pola: Każde wyodrębnione pole z etykietą ma skojarzony współczynnik ufności. Ten wynik odzwierciedla pewność modelu na pozycji wyodrębnionej wartości. Podczas oceniania współczynników ufności należy również przyjrzeć się bazowemu ufności wyodrębniania, aby wygenerować kompleksowe zaufanie dla wyodrębnionego wyniku.
OCROceń wyniki wyodrębniania tekstu lub znaczników zaznaczenia w zależności od typu pola, aby wygenerować złożony wynik ufności dla pola. - Wynik ufności programu Word Każdy wyraz wyodrębniony w dokumencie ma skojarzony współczynnik ufności. Wynik reprezentuje pewność transkrypcji. Tablica stron zawiera tablicę wyrazów, a każdy wyraz ma skojarzony zakres i współczynnik ufności. Zakresy z pola niestandardowego wyodrębnione wartości są zgodne z zakresami wyodrębnionych wyrazów.
- Wskaźnik ufności znacznika wyboru: tablica stron zawiera również tablicę znaczników zaznaczenia. Każdy znacznik wyboru ma współczynnik ufności reprezentujący pewność wyboru znacznika wyboru i wykrywanie stanu zaznaczenia. Gdy pole z etykietą ma znacznik wyboru, wybór pola niestandardowego w połączeniu z ufnością znacznika wyboru jest dokładną reprezentacją ogólnej dokładności ufności.
W poniższej tabeli pokazano, jak interpretować zarówno dokładność, jak i współczynniki ufności w celu mierzenia wydajności modelu niestandardowego.
| Dokładność | Ufność | Result |
|---|---|---|
| Wys. | Wys. | • Model działa dobrze z etykietami i formatami dokumentów. • Masz zrównoważony zestaw danych treningowych. |
| Wys. | Niski | • Przeanalizowany dokument różni się od zestawu danych treningowych. • Model mógłby skorzystać z ponownego trenowania z co najmniej pięcioma dokumentami oznaczonymi etykietami. • Wyniki te mogą również wskazywać na odmianę formatu między zestawem danych trenowania a analizowanym dokumentem. Rozważ dodanie nowego modelu. |
| Niskie | Wysokie | • Ten wynik jest najbardziej mało prawdopodobny. • W przypadku wyników niskiej dokładności dodaj więcej oznaczonych danych lub podziel wizualnie odrębne dokumenty na wiele modeli. |
| Niski | Niski | • Dodaj więcej oznaczonych etykietami danych. • Podziel wizualnie odrębne dokumenty na wiele modeli. |
Ufność tabeli, wiersza i komórki
Po dodaniu tabeli, wiersza i komórki zaufania do interfejsu 2024-02-29-preview API poniżej przedstawiono kilka typowych pytań, które powinny pomóc w interpretowaniu tabeli, wierszy i wyników komórek:
Pyt.: Czy można zobaczyć wysoki współczynnik ufności dla komórek, ale niski współczynnik ufności dla wiersza?
Odpowiedź: Tak. Różne poziomy ufności tabeli (komórka, wiersz i tabela) mają na celu przechwycenie poprawności przewidywania na tym poziomie. Poprawnie przewidywana komórka, która należy do wiersza z innymi możliwymi błędami, będzie miała wysoką pewność komórki, ale pewność wiersza powinna być niska. Podobnie prawidłowy wiersz w tabeli z wyzwaniami z innymi wierszami miałby wysoką pewność wierszy, podczas gdy ogólna pewność tabeli byłaby niska.
Pyt.: Jaki jest oczekiwany współczynnik ufności podczas scalania komórek? Ponieważ scalanie powoduje zmianę liczby kolumn, na jakie mają wpływ wyniki?
1: Niezależnie od typu tabeli oczekiwania dotyczące scalonych komórek polegają na tym, że powinny mieć niższe wartości ufności. Ponadto brakuje komórki (ponieważ została scalona z sąsiadującą komórką) powinna mieć NULL również wartość o mniejszej pewności. Ile niższe mogą być te wartości, zależy od zestawu danych treningowych, ogólnego trendu zarówno scalonego, jak i brakującej komórki o niższych wynikach powinny być przechowywane.
Pyt.: Jaki jest współczynnik ufności, gdy wartość jest opcjonalna? Czy należy oczekiwać komórki z wartością i wysokim współczynnikiem NULL ufności, jeśli brakuje wartości?
1: Jeśli zestaw danych treningowych jest reprezentatywny dla opcjonalnych komórek, pomaga modelowi wiedzieć, jak często wartość ma tendencję do wyświetlania w zestawie treningowym, a tym samym tego, czego można oczekiwać podczas wnioskowania. Ta funkcja jest używana podczas obliczania pewności przewidywania lub bez przewidywania (NULL). Należy oczekiwać pustego pola z dużą pewnością dla brakujących wartości, które są przeważnie puste w zestawie treningowym.
Pyt.: Jak mają wpływ wyniki ufności, jeśli pole jest opcjonalne, a nie jest obecne lub pominięte? Czy oczekuje się, że wskaźnik ufności odpowiada na to pytanie?
1: Jeśli w wierszu brakuje wartości, komórka ma przypisaną NULL wartość i pewność siebie. Wysoki współczynnik ufności powinien oznaczać, że przewidywanie modelu (z braku wartości) jest bardziej prawdopodobne, aby było poprawne. Natomiast niski wynik powinien sygnalizować większą niepewność względem modelu (a tym samym możliwość błędu, takiego jak pominięta wartość).
Pyt.: Jakie powinny być oczekiwania dotyczące ufności komórek i pewności wierszy podczas wyodrębniania tabeli wielostronicowej z podziałem wierszy na stronach?
1: Spodziewaj się, że pewność komórki będzie wysoka, a pewność wiersza może być potencjalnie niższa niż wiersze, które nie zostały podzielone. Proporcja podzielonych wierszy w zestawie danych treningowych może mieć wpływ na współczynnik ufności. Ogólnie rzecz biorąc, wiersz podziału wygląda inaczej niż inne wiersze w tabeli (w związku z tym model jest mniej pewny, że jest poprawny).
Pyt.: Czy w przypadku tabel międzystronicowych z wierszami, które czystą końcu i zaczynają się od granic strony, czy prawidłowe jest założenie, że wyniki ufności są spójne na stronach?
Odpowiedź: Tak. Ponieważ wiersze wyglądają podobnie do kształtu i zawartości, niezależnie od tego, gdzie znajdują się w dokumencie (lub na której stronie), ich odpowiednie wyniki ufności powinny być spójne.
Pyt.: Jaki jest najlepszy sposób wykorzystania nowych wyników ufności?
O: Przyjrzyj się wszystkim poziomom ufności tabeli, zaczynając od podejścia od góry do dołu: zacznij od sprawdzenia pewności tabeli jako całości, a następnie przejdź do szczegółów na poziomie wiersza i przyjrzyj się poszczególnym wierszom, a na koniec przyjrzyj się ufnościom na poziomie komórki. W zależności od typu tabeli istnieje kilka rzeczy:
W przypadku stałych tabel pewność na poziomie komórki już przechwytuje sporo informacji na temat poprawności rzeczy. Oznacza to, że po prostu przechodząc przez każdą komórkę i patrząc na jej pewność siebie, może wystarczyć, aby określić jakość przewidywania. W przypadku tabel dynamicznych poziomy mają być oparte na sobie, więc ważniejsze jest podejście od góry do dołu.
Zapewnianie wysokiej dokładności modelu
Wariancja w strukturze wizualnej dokumentów wpływa na dokładność modelu. Zgłaszane wskaźniki dokładności mogą być niespójne, gdy analizowane dokumenty różnią się od dokumentów używanych podczas trenowania. Należy pamiętać, że zestaw dokumentów może wyglądać podobnie podczas oglądania przez ludzi, ale wyglądać niepodobnie dla modelu AI. Poniżej przedstawiono listę najlepszych rozwiązań dotyczących trenowania modeli o najwyższej dokładności. Zgodnie z tymi wytycznymi należy utworzyć model z większą dokładnością i współczynnikami ufności podczas analizy oraz zmniejszyć liczbę dokumentów oflagowanych do przeglądu przez człowieka.
Upewnij się, że wszystkie odmiany dokumentu są uwzględnione w zestawie danych treningowych. Odmiany obejmują różne formaty, na przykład cyfrowe i zeskanowane pliki PDF.
Dodaj co najmniej pięć próbek każdego typu do zestawu danych treningowych, jeśli oczekujesz, że model będzie analizować oba typy dokumentów PDF.
Oddzielaj wizualnie odrębne typy dokumentów w celu trenowania różnych modeli.
- Ogólnie rzecz biorąc, jeśli usuniesz wszystkie wprowadzone wartości użytkownika, a dokumenty będą wyglądać podobnie, musisz dodać więcej danych szkoleniowych do istniejącego modelu.
- Jeśli dokumenty są różne, podziel dane treningowe na różne foldery i wytrenuj model dla każdej odmiany. Następnie możesz utworzyć różne odmiany w jeden model.
Upewnij się, że nie masz żadnych etykiet nadmiarowych.
Upewnij się, że etykietowanie podpisów i regionów nie zawiera otaczającego tekstu.