Ogólny model dokumentów analizy dokumentów
Ważne
Począwszy od wersji 2024-02-29-preview, 2023-10-31-preview i w przyszłości, ogólny model dokumentu (wstępnie utworzony dokument) jest przestarzały. Aby wyodrębnić pary klucz-wartość, znaczniki zaznaczenia, tekst, tabele i strukturę z dokumentów, użyj następujących modeli:
| Funkcja | version | Model ID |
|---|---|---|
Layout model z włączonym opcjonalnym parametrem features=keyValuePairs ciągu zapytania. |
• v4:2024-02-29-preview • v3.1:2023-07-31 (GA) |
prebuilt-layout |
| Ogólny model dokumentu | • v3.1:2023-07-31 (GA)• v3.0:2022-08-31 (GA) • wersja 2.1 (GA) |
prebuilt-document |
Ta zawartość dotyczy:v3.1 (GA)Najnowsza wersja:![]()
![]() v4.0 (wersja zapoznawcza) | | Poprzednia wersja:
v4.0 (wersja zapoznawcza) | | Poprzednia wersja:![]() v3.0
v3.0
Ta zawartość dotyczy:![]() v3.0 (GA) | Najnowsze wersje:
v3.0 (GA) | Najnowsze wersje:![]() v4.0 (wersja zapoznawcza)
v4.0 (wersja zapoznawcza)![]() v3.1
v3.1
Model dokumentu Ogólne łączy zaawansowane funkcje optycznego rozpoznawania znaków (OCR) z modelami uczenia głębokiego w celu wyodrębniania par klucz-wartość, tabel i znaków wyboru z dokumentów. Dokument ogólny jest dostępny z interfejsami API w wersji 3.1 i 3.0. Aby uzyskać więcej informacji, zobacz nasz przewodnik migracji.
Ogólne funkcje dokumentu
Ogólny model dokumentu to wstępnie wytrenowany model; nie wymaga etykiet ani trenowania.
Pojedynczy interfejs API wyodrębnia pary klucz-wartość, znaczniki wyboru, tekst, tabele i strukturę z dokumentów.
Ogólny model dokumentów obsługuje dokumenty ustrukturyzowane, częściowo ustrukturyzowane i nieustrukturyzowane.
Znaczniki wyboru są identyfikowane jako pola o wartości
:selected:lub:unselected:.
Przykładowy dokument przetworzony w programie Document Intelligence Studio
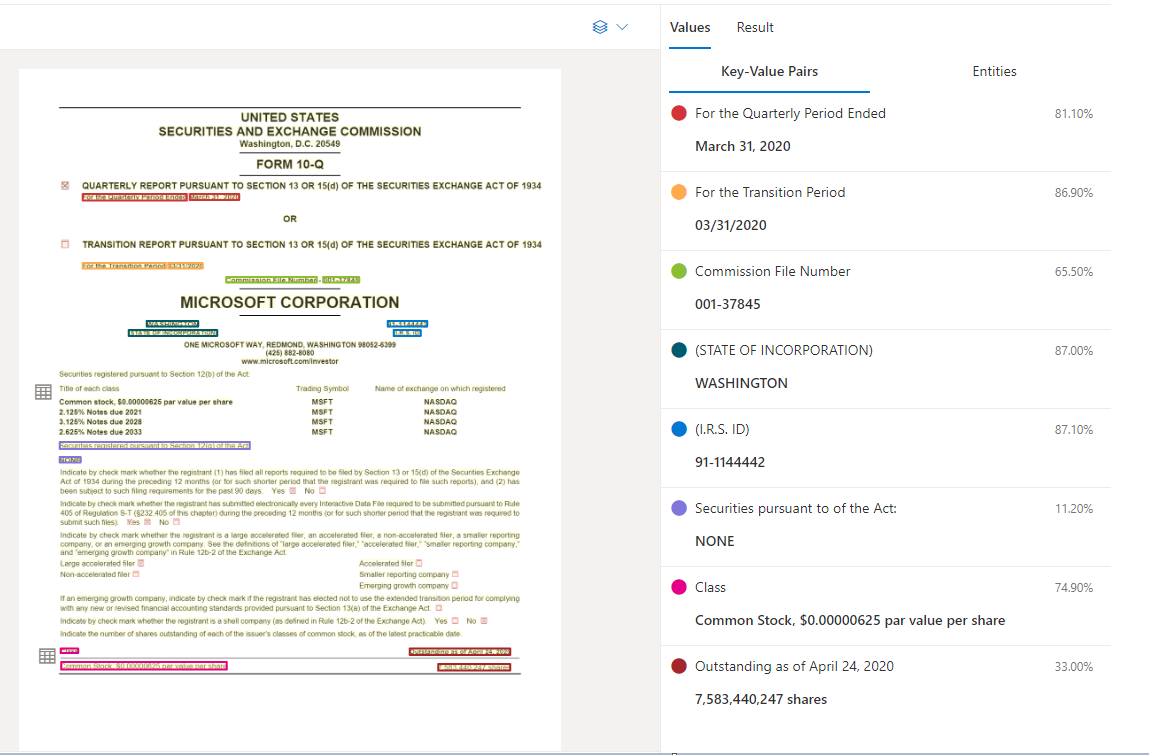
Wyodrębnianie par klucz-wartość
Interfejs API ogólnego dokumentu obsługuje większość typów formularzy i analizuje dokumenty oraz wyodrębnia klucze i skojarzone wartości. Idealnie nadaje się do wyodrębniania typowych par klucz-wartość z dokumentów. Model dokumentu ogólnego można użyć jako alternatywy do trenowania modelu niestandardowego bez etykiet.
Opcje programowania
Narzędzie Document Intelligence w wersji 3.1 obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Ogólny model dokumentu | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK |
wstępnie utworzony dokument |
Narzędzie Document Intelligence w wersji 3.0 obsługuje następujące narzędzia, aplikacje i biblioteki:
| Funkcja | Zasoby | Model ID |
|---|---|---|
| Ogólny model dokumentu | • Document Intelligence Studio • REST API • C# SDK • Python SDK• Java SDK • JavaScript SDK |
wstępnie utworzony dokument |
Wymagania dotyczące danych wejściowych
Aby uzyskać najlepsze wyniki, podaj jedno jasne zdjęcie lub wysokiej jakości skanowanie na dokument.
Obsługiwane formaty plików:
Model PDF Obraz:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) i HTMLPrzeczytaj ✔ ✔ ✔ Układ ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Dokument ogólny ✔ ✔ Wstępnie utworzona ✔ ✔ Niestandardowe wyodrębnianie ✔ ✔ Klasyfikacja niestandardowa ✔ ✔ ✔ (2024-02-29-preview) W przypadku plików PDF i TIFF można przetworzyć maksymalnie 2000 stron (w przypadku subskrypcji w warstwie Bezpłatna przetwarzane są tylko pierwsze dwie strony).
Rozmiar pliku do analizowania dokumentów wynosi 500 MB dla warstwy płatnej (S0) i 4 MB za bezpłatną (F0).
Wymiary obrazu muszą mieć od 50 x 50 pikseli do 10 000 pikseli x 10 000 pikseli.
Jeśli pliki PDF są zablokowane hasłem, przed ich przesłaniem usuń blokadę.
Minimalna wysokość tekstu do wyodrębnienia to 12 pikseli dla obrazu o rozmiarze 1024 x 768 pikseli. Ten wymiar odpowiada około
8-point text na 150 kropek na cal (DPI).W przypadku trenowania modelu niestandardowego maksymalna liczba stron dla danych szkoleniowych wynosi 500 dla niestandardowego modelu szablonu i 50 000 dla niestandardowego modelu neuronowego.
W przypadku trenowania niestandardowego modelu wyodrębniania łączny rozmiar danych treningowych wynosi 50 MB dla modelu szablonu i 1G-MB dla modelu neuronowego.
W przypadku trenowania niestandardowego modelu klasyfikacji całkowity rozmiar danych treningowych wynosi
1GBmaksymalnie 10 000 stron.
Ogólne wyodrębnianie danych modelu dokumentów
Spróbuj wyodrębnić dane z formularzy i dokumentów przy użyciu programu Document Intelligence Studio.
Potrzebne są następujące zasoby:
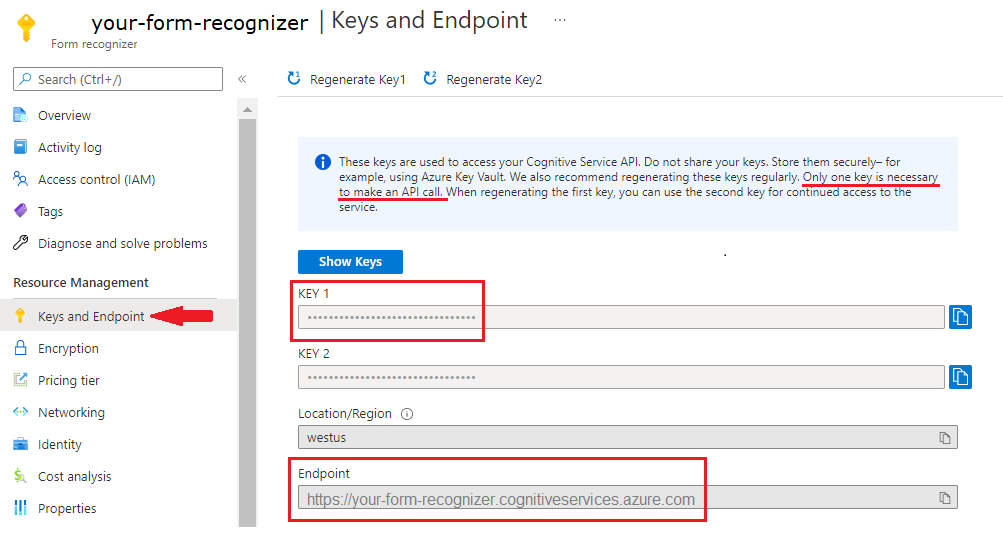
Subskrypcja platformy Azure — możesz utworzyć jedną bezpłatnie.
Wystąpienie analizy dokumentów w witrynie Azure Portal. Aby wypróbować usługę, możesz użyć bezpłatnej warstwy cenowej (
F0). Po wdrożeniu zasobu wybierz pozycję Przejdź do zasobu , aby uzyskać klucz i punkt końcowy.
Uwaga
Program Document Intelligence Studio i ogólny model dokumentów są dostępne za pomocą interfejsu API w wersji 3.0.
Na stronie głównej narzędzia Document Intelligence Studio wybierz pozycję Dokumenty ogólne.
Możesz przeanalizować przykładowy dokument lub przekazać własne pliki.
Wybierz przycisk Run analysis (Uruchom analizę), a w razie potrzeby skonfiguruj opcje Analizuj:

Pary klucz-wartość
Pary klucz-wartość są określonymi zakresami w dokumencie, które identyfikują etykietę lub klucz i powiązaną z nią odpowiedź lub wartość. W formularzu ustrukturyzowanym te pary mogą być etykietą i wartością wprowadzoną przez użytkownika dla tego pola. W dokumencie bez struktury mogą one być datą wykonania umowy na podstawie tekstu w akapicie. Model sztucznej inteligencji jest trenowany w celu wyodrębniania możliwych do zidentyfikowania kluczy i wartości w oparciu o szeroką gamę typów dokumentów, formatów i struktur.
Klucze mogą również istnieć w izolacji, gdy model wykryje, że klucz istnieje, bez skojarzonej wartości lub podczas przetwarzania pól opcjonalnych. Na przykład pole nazwy środkowej może być puste w formularzu w niektórych przypadkach. Pary klucz-wartość to zakresy tekstu zawartego w dokumencie. W przypadku dokumentów, w których ta sama wartość jest opisana na różne sposoby, na przykład klient/użytkownik, skojarzony klucz jest klientem lub użytkownikiem (na podstawie kontekstu).
Wyodrębnianie danych
| Model | Wyodrębnianie tekstu | Pary klucz-wartość | Znaczniki zaznaczenia | Tabele | Nazwy pospolite |
|---|---|---|---|---|---|
| Dokument ogólny | ✓ | ✓ | ✓ | ✓ | ✓* |
•* — dostępne tylko w wersjach interfejsu 2023-07-31 API w wersji 3.1 lub nowszej.
Obsługiwane języki i ustawienia regionalne
Zobacz naszą stronę Obsługa języka — modele analizy dokumentów, aby uzyskać pełną listę obsługiwanych języków.
Kwestie wymagające rozważenia
Ponieważ klucze są fragmentami tekstu wyodrębnianego z dokumentu, w przypadku dokumentów częściowo ustrukturyzowanych klucze muszą być mapowane na istniejący słownik kluczy.
Oczekiwano par klucz-wartość z kluczem, ale bez wartości. Jeśli na przykład użytkownik zdecydował się nie podać adresu e-mail w formularzu.
Następne kroki
Postępuj zgodnie z naszym przewodnikiem migracji do analizy dokumentów w wersji 3.1, aby dowiedzieć się, jak używać wersji 3.1 w aplikacjach i przepływach pracy.
Zapoznaj się z naszym interfejsem API REST.